Einrichten von AutoML zum Trainieren eines Zeitreihenvorhersagemodells mit SDK und CLI
GILT FÜR: Azure CLI ML-Erweiterung v2 (aktuell)Python SDK azure-ai-ml v2 (aktuell)
Azure CLI ML-Erweiterung v2 (aktuell)Python SDK azure-ai-ml v2 (aktuell)
In diesem Artikel erfahren Sie, wie Sie AutoML für Zeitreihenvorhersagen mit automatisiertem ML von Azure Machine Learning im Azure Machine Learning Python SDK einrichten.
Dazu gehen Sie wie folgt vor:
- Aufbereiten von Daten für das Training.
- Konfigurieren spezifischer Zeitreihenparameter in einem Vorhersageauftrag.
- Orchestrieren Sie Training, Rückschlüsse und Modellauswertung mithilfe von Komponenten und Pipelines.
Für ein Vorgehen mit wenig Code folgen Sie dem Tutorial: Vorhersage des Bedarfs mithilfe von automatisiertem maschinellem Lernen für ein Zeitreihenvorhersagebeispiel mit automatisiertem ML im Azure Machine Learning Studio.
AutoML verwendet Standardmodelle des maschinellen Lernens zusammen mit bekannten Zeitreihenmodellen, um Vorhersagen zu erstellen. Unser Ansatz umfasst Verlaufsinformationen über die Zielvariable, benutzerseitig bereitgestellte Features in den Eingabedaten und automatisch entwickelte Features. Die Algorithmen zur Modellsuche versuchen dann, ein Modell mit der besten Vorhersagegenauigkeit zu finden. Weitere Einzelheiten finden Sie in unseren Artikeln über Vorhersagemethodik und Modellsuche.
Voraussetzungen
Für diesen Artikel ist Folgendes erforderlich:
Ein Azure Machine Learning-Arbeitsbereich. Informationen zum Erstellen des Arbeitsbereichs finden Sie unter Schnellstart: So erstellen Sie Arbeitsbereichsressourcen, die Sie für die ersten Schritte mit Azure Machine Learning benötigen.
Die Möglichkeit, Trainingsaufträge für AutoML zu starten. Weitere Informationen finden Sie in der Anleitung zum Einrichten von AutoML.
Trainings- und Überprüfungsdaten
Eingabedaten für AutoML-Vorhersagen müssen gültige Zeitreihen im tabellarischen Format enthalten. Jede Variable muss über eine eigene entsprechende Spalte in der Datentabelle verfügen. AutoML erfordert mindestens zwei Spalten: eine Zeitspalte, die die Zeitachse darstellt, und die Zielspalte, die die zu prognostizierende Menge darstellt. Andere Spalten können als Prädiktoren dienen. Weitere Informationen finden Sie unter Verwendung Ihrer Daten durch AutoML.
Wichtig
Stellen Sie beim Trainieren eines Modells für die Vorhersage zukünftiger Werte sicher, dass alle während des Trainings verwendeten Features beim Ausführen von Vorhersagen für Ihren gewünschten Vorhersagehorizont verwendet werden können.
Die Trainingsgenauigkeit lässt sich beispielsweise durch die Einbeziehung eines Features für den aktuellen Aktienkurs erheblich verbessern. Wenn Sie bei Ihrer Vorhersage allerdings einen Vorhersagehorizont verwenden, der weit in der Zukunft liegt, lassen sich zukünftige Aktienkurse für zukünftige Zeitreihenpunkte ggf. nicht präzise vorhersagen, was sich nachteilig auf die Modellgenauigkeit auswirken kann.
AutoML-Vorhersageaufträge erfordern, dass Ihre Trainingsdaten als MLTable-Objekt dargestellt werden. Eine MLTable gibt eine Datenquelle und Schritte zum Laden der Daten an. Weitere Informationen und Anwendungsfälle finden Sie in der Schrittanleitung für MLTable. Angenommen, Ihre Trainingsdaten sind in einer CSV-Datei in einem lokalen Verzeichnis enthalten, ./train_data/timeseries_train.csv.
Sie können eine MLTable mit dem mltable Python SDK erstellen, wie im folgenden Beispiel gezeigt:
import mltable
paths = [
{'file': './train_data/timeseries_train.csv'}
]
train_table = mltable.from_delimited_files(paths)
train_table.save('./train_data')
Mit diesem Code wird eine neue Datei, ./train_data/MLTable, erstellt, die das Dateiformat und die Ladeanweisungen enthält.
Sie definieren nun ein Eingabedatenobjekt, das zum Starten eines Trainingsauftrags erforderlich ist, indem Sie das Azure Machine Learning Python SDK wie folgt verwenden:
from azure.ai.ml.constants import AssetTypes
from azure.ai.ml import Input
# Training MLTable defined locally, with local data to be uploaded
my_training_data_input = Input(
type=AssetTypes.MLTABLE, path="./train_data"
)
Sie geben Validierungsdaten auf ähnliche Weise an, indem Sie eine MLTable erstellen und eine Eingabe für Validierungsdaten angeben. Wenn Sie keine Validierungsdaten bereitstellen, erstellt AutoML automatisch Kreuzvalidierungsaufteilungen Ihrer Trainingsdaten, die für die Modellauswahl verwendet werden sollen. Weitere Informationen finden Sie in dem Artikel Auswahl von Vorhersagemodellen. Lesen Sie auch den Artikel Anforderungen an die Trainingsdatenlänge, um zu erfahren, wie viele Trainingsdaten Sie benötigen, um ein Vorhersagemodell erfolgreich zu trainieren.
Erfahren Sie mehr darüber, wie AutoML die Kreuzvalidierung anwendet, um eine Überanpassung von Modellen zu verhindern.
Computeziel zum Ausführen des Experiments
Automatisiertes ML verwendet Azure Machine Learning Compute, eine vollständig verwaltete Computeressource, um den Trainingsauftrag auszuführen. In den folgenden Beispielen wird ein Computecluster mit dem Namen cpu-compute erstellt:
from azure.ai.ml.entities import AmlCompute
# specify aml compute name.
cpu_compute_target = "cpu-cluster"
try:
ml_client.compute.get(cpu_compute_target)
except Exception:
print("Creating a new cpu compute target...")
compute = AmlCompute(
name=cpu_compute_target, size="STANDARD_D2_V2", min_instances=0, max_instances=4
)
ml_client.compute.begin_create_or_update(compute).result()Konfigurieren des Experiments
Sie verwenden die automl factory-Funktionen, um Vorhersageaufträge im Python SDK zu konfigurieren. Das folgende Beispiel zeigt, wie Sie einen Vorhersageauftrag erstellen, indem Sie die primäre Metrik und Grenzwerte für die Trainingsausführung festlegen:
from azure.ai.ml import automl
# note that the below is a code snippet -- you might have to modify the variable values to run it successfully
forecasting_job = automl.forecasting(
compute="cpu-compute",
experiment_name="sdk-v2-automl-forecasting-job",
training_data=my_training_data_input,
target_column_name=target_column_name,
primary_metric="normalized_root_mean_squared_error",
n_cross_validations="auto",
)
# Limits are all optional
forecasting_job.set_limits(
timeout_minutes=120,
trial_timeout_minutes=30,
max_concurrent_trials=4,
)
Einstellungen für den Vorhersageauftrag
Vorhersageaufgaben verfügen über viele Einstellungen, die spezifisch für die Vorhersage sind. Die grundlegendsten dieser Einstellungen sind der Name der Zeitspalte in den Trainingsdaten und der Vorhersagehorizont.
Verwenden Sie die ForecastingJob-Methoden, um diese Einstellungen zu konfigurieren:
# Forecasting specific configuration
forecasting_job.set_forecast_settings(
time_column_name=time_column_name,
forecast_horizon=24
)
Der Name der Zeitspalte ist eine obligatorische Einstellung, und Sie sollten den Vorhersagezeitraum generell entsprechend Ihrem Vorhersageszenario festlegen. Wenn Ihre Daten mehrere Zeitreihen enthalten, können Sie die Namen der Zeitreihen-ID-Spalten angeben. Diese Spalten definieren, wenn sie gruppiert sind, die einzelnen Reihen. Nehmen Sie beispielsweise an, dass Sie über Daten verfügen, die aus stündlichen Verkäufen von verschiedenen Geschäften und Marken bestehen. Das folgende Beispiel zeigt, wie Sie die die Zeitreihen-ID-Spalten unter der Annahme festgelegen, dass die Daten Spalten mit den Namen „store“ und „brand“ enthalten:
# Forecasting specific configuration
# Add time series IDs for store and brand
forecasting_job.set_forecast_settings(
..., # other settings
time_series_id_column_names=['store', 'brand']
)
AutoML versucht, Zeitreihen-ID-Spalten in Ihren Daten automatisch zu erkennen, wenn keine angegeben sind.
Andere Einstellungen sind optional und werden im nächsten Abschnitt überprüft.
Optionale Einstellungen für den Vorhersageauftrag
Für Vorhersageaufgaben sind optionale Konfigurationen verfügbar, z. B. das Aktivieren von Deep Learning und das Angeben einer rollierenden Zielfensteraggregation. Eine vollständige Liste der Parameter finden Sie in der Referenzdokumentation zur Vorhersage.
Modellsucheinstellungen
Es gibt zwei optionale Einstellungen, die den Modellbereich steuern, in dem AutoML nach dem besten Modell sucht: allowed_training_algorithms und blocked_training_algorithms. Um den Suchbereich auf einen bestimmten Satz von Modellklassen einzuschränken, verwenden Sie den Parameter allowed_training_algorithms wie im folgenden Beispiel:
# Only search ExponentialSmoothing and ElasticNet models
forecasting_job.set_training(
allowed_training_algorithms=["ExponentialSmoothing", "ElasticNet"]
)
In diesem Fall sucht der Vorhersageauftrag nur über die Modellklassen „Exponential Smoothing“ und „Elastic Net“. Um eine bestimmte Gruppe von Modellklassen aus dem Suchraum zu entfernen, verwenden Sie blocked_training_algorithms wie im folgenden Beispiel:
# Search over all model classes except Prophet
forecasting_job.set_training(
blocked_training_algorithms=["Prophet"]
)
Nun durchsucht der Auftrag alle Modellklassen mit Ausnahme von Prophet. Eine Liste der Vorhersagemodellnamen, die in allowed_training_algorithms und blocked_training_algorithms akzeptiert werden, finden Sie in der Referenzdokumentation Trainingseigenschaften. Einer der beiden Punkte allowed_training_algorithms und blocked_training_algorithms, aber nicht beide, können auf eine Trainingsausführung angewendet werden.
Aktivieren von Deep Learning
AutoML wird mit einem benutzerdefinierten DNN-Modell (Deep Neural Network) mit dem Namen TCNForecaster ausgeliefert. Bei diesem Modell handelt es sich um ein temporales Faltungsnetzwerk (temporal convolutional network, TCN), das gängige Methoden der Bildgebungsaufgabe auf die Zeitreihenmodellierung anwendet. Eindimensionale „kausale“ Faltungen bilden das Rückgrat des Netzes und ermöglichen es dem Modell, komplexe Muster über lange Zeiträume im Trainingsverlauf zu lernen. Ausführlichere Informationen finden Sie in unserem TCNForecaster-Artikel.
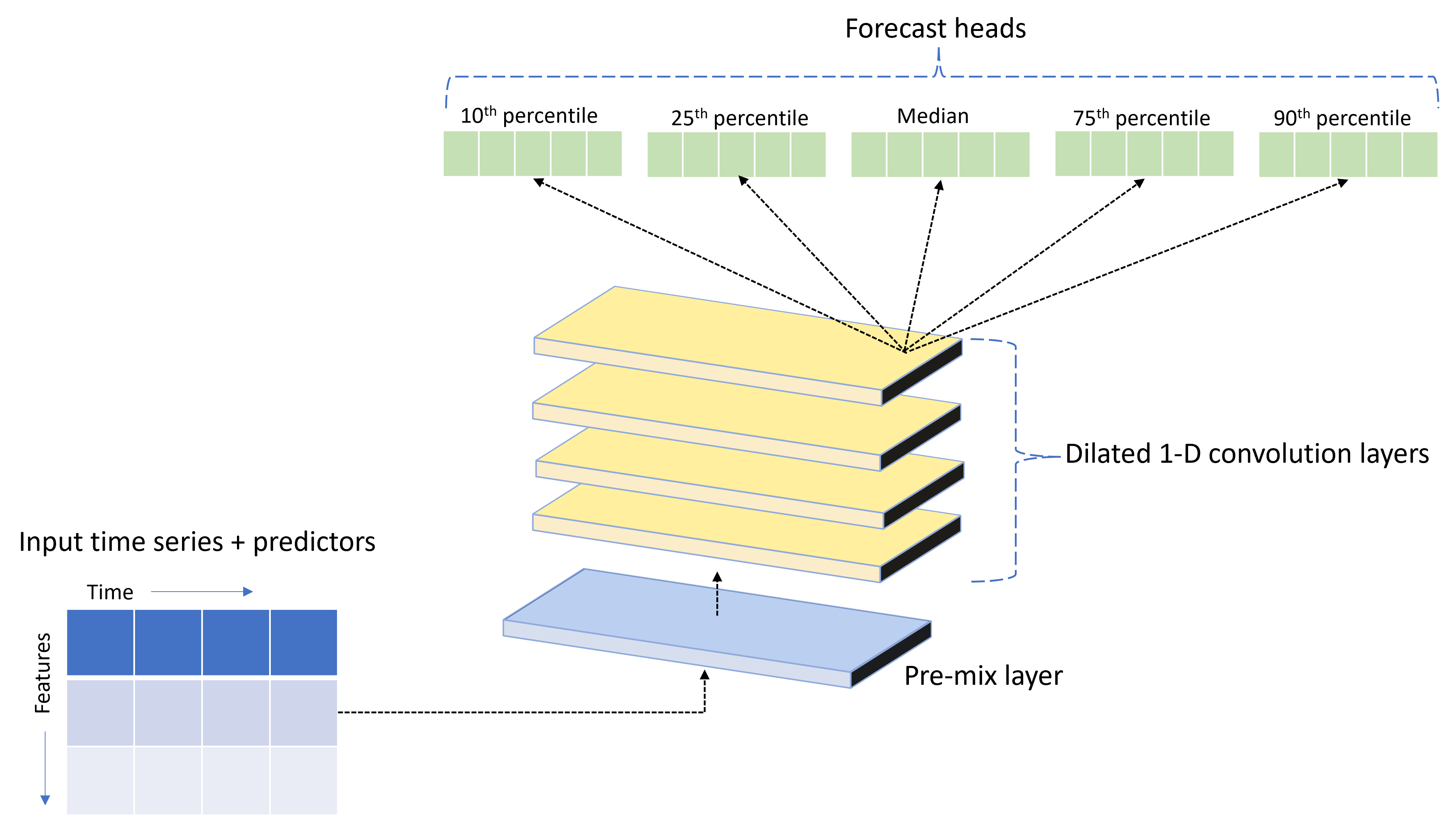
TCNForecaster erreicht häufig eine höhere Genauigkeit als Standard-Zeitreihenmodelle, wenn Tausende oder mehr Beobachtungen im Trainingsverlauf vorhanden sind. Allerdings dauert es aufgrund der höheren Kapazität auch länger, um TCNForecaster-Modelle zu trainieren und auszuprobieren (Sweeping).
Sie können den TCNForecaster in AutoML aktivieren, indem Sie das Flag enable_dnn_training in der Trainingskonfiguration wie folgt festlegen:
# Include TCNForecaster models in the model search
forecasting_job.set_training(
enable_dnn_training=True
)
Standardmäßig ist das Training von TCNForecaster auf einen einzelnen Computeknoten und eine einzelne GPU (falls verfügbar) pro Modelltest beschränkt. Für große Datenszenarien empfehlen wir, jeden TCNForecaster-Test auf mehrere Kerne/GPUs und Knoten zu verteilen. Weitere Informationen und Codebeispiele finden Sie in unserem Artikel zum Thema Verteiltes Training.
Informationen zum Aktivieren von DNN für ein AutoML-Experiment, das in Azure Machine Learning Studio erstellt wurde, finden Sie in der Schrittanleitung für Aufgabentypeinstellungen in Studio.
Hinweis
- Wenn Sie DNN für mit dem SDK erstellte Experimente aktivieren, sind Erläuterungen des besten Modells deaktiviert.
- Die DNN-Unterstützung für Vorhersagen in Automated Machine Learning wird für in Databricks initiierte Läufe nicht unterstützt.
- GPU-Computetypen werden empfohlen, wenn das DNN-Training aktiviert ist.
Features für verzögerte und rollierende Fenster
Aktuelle Werte des Ziels sind häufig wirkungsvolle Features in einem Vorhersagemodell. Dementsprechend kann AutoML Features für zeitverzögerte und rollierende Fensteraggregationen erstellen, um die Modellgenauigkeit zu verbessern.
Betrachten Sie ein Szenario zur Vorhersage des Energiebedarfs, in dem Wetterdaten und der historische Bedarf verfügbar sind. Die Tabelle zeigt die resultierende Featureentwicklung, die auftritt, wenn die Fensteraggregation über die letzten drei Stunden angewendet wird. Spalten für die Werte minimum, maximum und sum werden in einem gleitenden Fenster über drei Einträge basierend auf den definierten Einstellungen generiert. Für die Beobachtungen am „8. September 2017, 4:00 Uhr“ werden die Werte „maximum“, „minimum“ und „sum“ mithilfe der Bedarfswerte für den 8. September 2017, 1:00 Uhr bis 3:00 Uhr, berechnet. Dieses drei Stunden umfassende Fenster wird verschoben, um die verbleibenden Zeilen mit Daten aufzufüllen. Weitere Einzelheiten und Beispiele finden Sie im Artikel zum Verzögerungsfeature.

Sie können die Features für zeitverzögerte und rollierende Fensteraggregationen für das Ziel aktivieren, indem Sie die Größe des rollierenden Fensters (im vorherigen Beispiel drei) und die zu erstellenden Verzögerungsordnungen festlegen. Sie können auch Verzögerungen für Features mit der feature_lags-Einstellung festlegen. Im folgenden Beispiel legen wir alle diese Einstellungen auf auto fest, sodass AutoML die Einstellungen automatisch durch Analyse der Korrelationsstruktur Ihrer Daten bestimmt:
forecasting_job.set_forecast_settings(
..., # other settings
target_lags='auto',
target_rolling_window_size='auto',
feature_lags='auto'
)
Verarbeitung kurzer Reihen
Beim automatisierten ML gilt eine Zeitreihe als kurze Reihe, wenn nicht genügend Datenpunkte vorhanden sind, um die Trainings- und Validierungsphasen der Modellentwicklung durchzuführen. Weitere Informationen zu Längenanforderungen finden Sie unter Anforderungen an die Trainingsdatenlänge.
AutoML verfügt über mehrere Aktionen, die für kurze Serien ausgeführt werden können. Diese Aktionen können mit der Einstellung short_series_handling_config konfiguriert werden. Der Standardwert ist „auto“. In der folgenden Tabelle werden die Einstellungen beschrieben:
| Einstellung | BESCHREIBUNG |
|---|---|
auto |
Der Standardwert für die Verarbeitung kurzer Reihen. - Wenn alle Reihen kurz sind, werden die Daten aufgefüllt. - Wenn nicht alle Reihen kurz sind, werden die kurzen Reihen gelöscht. |
pad |
Wenn short_series_handling_config = pad festgelegt ist, fügt das automatisierte maschinelle Lernen allen gefundenen kurzen Reihen Zufallswerte hinzu. Im Folgenden sind die Spaltentypen und die Werte aufgeführt, mit denen sie aufgefüllt werden: – Objektspalten mit nicht numerischen Werten – Numerische Spalten mit 0 – Boolesche/logische Spalten mit „False“ - Die Zielspalte wird mit zielgerichteten Stördaten (White Noise) aufgefüllt. |
drop |
Wenn short_series_handling_config = drop festgelegt ist, werden die kurzen Reihen vom automatisierten maschinellen Lernen gelöscht und nicht für Trainings- oder Vorhersagezwecke verwendet. Bei Vorhersagen für diese Reihen werden NaN-Werte zurückgegeben. |
None |
Es werden keine Reihen aufgefüllt oder gelöscht. |
Im folgenden Beispiel wird die Kurzserienbehandlung so festgelegt, dass alle kurzen Serien auf die Mindestlänge aufgefüllt werden:
forecasting_job.set_forecast_settings(
..., # other settings
short_series_handling_config='pad'
)
Warnung
Das Auffüllen kann sich auf die Genauigkeit des resultierenden Modells auswirken, da wir künstliche Daten einführen, um Fehler beim Training zu vermeiden. Wenn viele der Reihen kurz sind, kann sich dies auch auf die Erklärbarkeit der Ergebnisse auswirken.
Häufigkeit und Zieldatenaggregation
Verwenden Sie die Optionen für Häufigkeit und Datenaggregation, um Fehler zu vermeiden, die durch unregelmäßige Daten verursacht werden. Ihre Daten sind unregelmäßig, wenn sie nicht einem festgelegten Zeitrhythmus folgen, z. B. stündlich oder täglich. Point-of-Sales-Daten sind ein gutes Beispiel für unregelmäßige Daten. In diesen Fällen kann AutoML Ihre Daten auf eine gewünschte Häufigkeit aggregieren und dann ein Vorhersagemodell aus den Aggregaten erstellen.
Sie müssen die Einstellungen frequency und target_aggregate_function festlegen, um unregelmäßige Daten zu verarbeiten. Die Häufigkeitseinstellung akzeptiert Pandas DateOffset-Zeichenfolgen als Eingabe. Unterstützte Werte für die Aggregationsfunktion sind:
| Funktion | BESCHREIBUNG |
|---|---|
sum |
Summe der Zielwerte |
mean |
Mittelwert oder Durchschnitt der Zielwerte |
min |
Minimalwert eines Ziels |
max |
Maximalwert eines Ziels |
- Die Zielspaltenwerte werden gemäß dem angegebenen Vorgang aggregiert. „sum“ eignet sich für die meisten Szenarien.
- Numerische Vorhersagespalten in den Daten werden nach Summe, Mittelwert, Minimalwert und Maximalwert aggregiert. Deshalb werden durch automatisiertes ML neue Spalten mit dem Namen der Aggregationsfunktion als Suffix erstellt und der ausgewählte Aggregationsvorgang angewendet.
- Bei kategorischen Vorhersagespalten werden die Daten nach Modus aggregiert. Dies ist die auffälligste Kategorie im Fenster.
- Datumsvorhersagespalten werden nach Minimalwert, Maximalwert und Modus aggregiert.
Im folgenden Beispiel wird die Häufigkeit auf stündlich und die Aggregationsfunktion auf Summierung festgelegt:
# Aggregate the data to hourly frequency
forecasting_job.set_forecast_settings(
..., # other settings
frequency='H',
target_aggregate_function='sum'
)
Benutzerdefinierte Einstellungen für die Kreuzvalidierung
Es gibt zwei anpassbare Einstellungen, die die Kreuzvalidierung für Vorhersageaufträge steuern: die Anzahl der Faltungen, n_cross_validations, und die Schrittgröße, die den Zeitversatz zwischen den Faltungen definiert, cv_step_size. Weitere Informationen zur Bedeutung dieser Parameter finden Sie unter Auswahl des Vorhersagemodells. Standardmäßig legt AutoML beide Einstellungen automatisch basierend auf den Merkmalen Ihrer Daten fest, aber fortgeschrittene Benutzer können sie auch manuell festlegen. Angenommen, Sie verfügen über tägliche Verkaufsdaten und möchten, dass Ihr Validierungssetup aus fünf Faltungen mit einem Sieben-Tage-Versatz zwischen benachbarten Faltungen bestehen soll. Der folgende Beispielcode zeigt, wie diese festgelegt werden können:
from azure.ai.ml import automl
# Create a job with five CV folds
forecasting_job = automl.forecasting(
..., # other training parameters
n_cross_validations=5,
)
# Set the step size between folds to seven days
forecasting_job.set_forecast_settings(
..., # other settings
cv_step_size=7
)
Benutzerdefinierte Featurisierung
Standardmäßig erweitert AutoML Trainingsdaten mit technischen Features, um die Genauigkeit der Modelle zu erhöhen. Weitere Informationen finden Sie unter Automatisiertes Feature-Engineering. Einige der Vorverarbeitungsschritte können mithilfe der Konfiguration der Featurisierung für den Vorhersageauftrag angepasst werden.
Unterstützte Anpassungen für Vorhersagen sind in der folgenden Tabelle aufgeführt:
| Anpassung | BESCHREIBUNG | Tastatur |
|---|---|---|
| Aktualisierung des Spaltenzwecks | Außerkraftsetzen des automatisch erkannten Featuretyps für die angegebene Spalte | „Categorical“, „DateTime“, „Numeric“ |
| Aktualisierung von Transformationsparametern | Aktualisieren der Parameter für den angegebenen Imputer. | {"strategy": "constant", "fill_value": <value>}, {"strategy": "median"}, {"strategy": "ffill"} |
Nehmen Sie z. B. an, Sie haben ein Bedarfsszenario für den Einzelhandel, in dem die Daten Preise, ein „Im Angebot“-Flag und einen Produkttyp enthalten. Das folgende Beispiel zeigt, wie Sie für diese Features benutzerdefinierte Typen und Imputer festlegen können:
from azure.ai.ml.automl import ColumnTransformer
# Customize imputation methods for price and is_on_sale features
# Median value imputation for price, constant value of zero for is_on_sale
transformer_params = {
"imputer": [
ColumnTransformer(fields=["price"], parameters={"strategy": "median"}),
ColumnTransformer(fields=["is_on_sale"], parameters={"strategy": "constant", "fill_value": 0}),
],
}
# Set the featurization
# Ensure that product_type feature is interpreted as categorical
forecasting_job.set_featurization(
mode="custom",
transformer_params=transformer_params,
column_name_and_types={"product_type": "Categorical"},
)
Wenn Sie Azure Machine Learning Studio für Ihr Experiment verwenden, finden Sie weitere Informationen unter Anpassen der Featurisierung in Studio.
Übermitteln eines Vorhersageauftrags
Nachdem Sie alle Einstellungen konfiguriert haben, starten Sie den Vorhersageauftrag wie folgt:
# Submit the AutoML job
returned_job = ml_client.jobs.create_or_update(
forecasting_job
)
print(f"Created job: {returned_job}")
# Get a URL for the job in the AML studio user interface
returned_job.services["Studio"].endpoint
Sobald der Auftrag übermittelt wurde, stellt AutoML Computeressourcen bereit, wendet Featurisierung und andere Vorbereitungsschritte auf die Eingabedaten an und beginnt dann mit dem Sweeping über die Vorhersagemodelle. Weitere Einzelheiten finden Sie in unseren Artikeln über Vorhersagemethodik und Modellsuche.
Orchestrieren von Training, Rückschluss und Auswertung mit Komponenten und Pipelines
Wichtig
Dieses Feature ist zurzeit als öffentliche Preview verfügbar. Diese Vorschauversion wird ohne Vereinbarung zum Servicelevel bereitgestellt und ist nicht für Produktionsworkloads vorgesehen. Manche Features werden möglicherweise nicht unterstützt oder sind nur eingeschränkt verwendbar.
Weitere Informationen finden Sie unter Zusätzliche Nutzungsbestimmungen für Microsoft Azure-Vorschauen.
Ihr ML-Workflow erfordert wahrscheinlich mehr als nur Training. Rückschlüsse oder das Abrufen von Modellvorhersagen zu neueren Daten und die Auswertung der Modellgenauigkeit anhand eines Testsatzes mit bekannten Zielwerten sind weitere gängige Aufgaben, die Sie in AzureML zusammen mit Trainingsaufträgen orchestrieren können. Zur Unterstützung von Rückschluss- und Auswertungsaufgaben bietet AzureML Komponenten, die eigenständige Codesegmente sind, die einen Schritt in einer AzureML-Pipeline ausführen.
Im folgenden Beispiel rufen wir den Komponentencode aus einer Clientregistrierung ab:
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
# Get a credential for access to the AzureML registry
try:
credential = DefaultAzureCredential()
# Check if we can get token successfully.
credential.get_token("https://management.azure.com/.default")
except Exception as ex:
# Fall back to InteractiveBrowserCredential in case DefaultAzureCredential fails
credential = InteractiveBrowserCredential()
# Create a client for accessing assets in the AzureML preview registry
ml_client_registry = MLClient(
credential=credential,
registry_name="azureml-preview"
)
# Create a client for accessing assets in the AzureML preview registry
ml_client_metrics_registry = MLClient(
credential=credential,
registry_name="azureml"
)
# Get an inference component from the registry
inference_component = ml_client_registry.components.get(
name="automl_forecasting_inference",
label="latest"
)
# Get a component for computing evaluation metrics from the registry
compute_metrics_component = ml_client_metrics_registry.components.get(
name="compute_metrics",
label="latest"
)
Als nächstes definieren wir eine Factoryfunktion, die Pipelines erstellt, die Training, Rückschlüsse und Metrikberechnungen orchestrieren. Im Abschnitt Trainingskonfiguration finden Sie weitere Einzelheiten zu den Trainingseinstellungen.
from azure.ai.ml import automl
from azure.ai.ml.constants import AssetTypes
from azure.ai.ml.dsl import pipeline
@pipeline(description="AutoML Forecasting Pipeline")
def forecasting_train_and_evaluate_factory(
train_data_input,
test_data_input,
target_column_name,
time_column_name,
forecast_horizon,
primary_metric='normalized_root_mean_squared_error',
cv_folds='auto'
):
# Configure the training node of the pipeline
training_node = automl.forecasting(
training_data=train_data_input,
target_column_name=target_column_name,
primary_metric=primary_metric,
n_cross_validations=cv_folds,
outputs={"best_model": Output(type=AssetTypes.MLFLOW_MODEL)},
)
training_node.set_forecasting_settings(
time_column_name=time_column_name,
forecast_horizon=max_horizon,
frequency=frequency,
# other settings
...
)
training_node.set_training(
# training parameters
...
)
training_node.set_limits(
# limit settings
...
)
# Configure the inference node to make rolling forecasts on the test set
inference_node = inference_component(
test_data=test_data_input,
model_path=training_node.outputs.best_model,
target_column_name=target_column_name,
forecast_mode='rolling',
forecast_step=1
)
# Configure the metrics calculation node
compute_metrics_node = compute_metrics_component(
task="tabular-forecasting",
ground_truth=inference_node.outputs.inference_output_file,
prediction=inference_node.outputs.inference_output_file,
evaluation_config=inference_node.outputs.evaluation_config_output_file
)
# return a dictionary with the evaluation metrics and the raw test set forecasts
return {
"metrics_result": compute_metrics_node.outputs.evaluation_result,
"rolling_fcst_result": inference_node.outputs.inference_output_file
}
Jetzt definieren wir die Eingaben für die Trainings- und Testdaten unter der Annahme, dass sie in den lokalen Ordnern ./train_data und ./test_data enthalten sind:
my_train_data_input = Input(
type=AssetTypes.MLTABLE,
path="./train_data"
)
my_test_data_input = Input(
type=AssetTypes.URI_FOLDER,
path='./test_data',
)
Schließlich konstruieren wir die Pipeline, legen ihre standardmäßige Compute-Instanz fest und übermitteln den Auftrag:
pipeline_job = forecasting_train_and_evaluate_factory(
my_train_data_input,
my_test_data_input,
target_column_name,
time_column_name,
forecast_horizon
)
# set pipeline level compute
pipeline_job.settings.default_compute = compute_name
# submit the pipeline job
returned_pipeline_job = ml_client.jobs.create_or_update(
pipeline_job,
experiment_name=experiment_name
)
returned_pipeline_job
Nach der Übermittlung führt die Pipeline nacheinander das AutoML-Training, den rollierenden Auswertungsrückschluss und die Metrikberechnung aus. Sie können die Ausführung in der Studio-Benutzeroberfläche überwachen und überprüfen. Wenn die Ausführung abgeschlossen ist, können die rollierenden Vorhersagen und die Auswertungsmetriken in das lokale Arbeitsverzeichnis heruntergeladen werden:
# Download the metrics json
ml_client.jobs.download(returned_pipeline_job.name, download_path=".", output_name='metrics_result')
# Download the rolling forecasts
ml_client.jobs.download(returned_pipeline_job.name, download_path=".", output_name='rolling_fcst_result')
Dann finden Sie die Metrikergebnisse in ./named-outputs/metrics_results/evaluationResult/metrics.json und die Vorhersagen im JSON-Zeilenformat in ./named-outputs/rolling_fcst_result/inference_output_file.
Weitere Einzelheiten zur rollierenden Auswertung finden Sie in unserem Artikel Auswertung des Vorhersagemodells.
Vorhersage im großen Stil: Viele Modelle
Wichtig
Dieses Feature ist zurzeit als öffentliche Preview verfügbar. Diese Vorschauversion wird ohne Vereinbarung zum Servicelevel bereitgestellt und ist nicht für Produktionsworkloads vorgesehen. Manche Features werden möglicherweise nicht unterstützt oder sind nur eingeschränkt verwendbar.
Weitere Informationen finden Sie unter Zusätzliche Nutzungsbestimmungen für Microsoft Azure-Vorschauen.
Die vielen Modellkomponenten in AutoML ermöglichen es Ihnen, Millionen von Modellen parallel zu trainieren und zu verwalten. Weitere Informationen zu den Konzepten für viele Modelle finden Sie im Artikelabschnitt Viele Modelle.
Trainingskonfiguration für viele Modelle
Die Komponente für das Training von vielen Modellen akzeptiert eine Konfigurationsdatei im YAML-Format mit AutoML-Trainingseinstellungen. Die Komponente wendet diese Einstellungen auf jede AutoML-Instanz an, die sie startet. Diese YAML-Datei hat die gleiche Spezifikation wie der Forecasting Job-Auftrag sowie die zusätzlichen Parameter partition_column_names und allow_multi_partitions.
| Parameter | Beschreibung |
|---|---|
| partition_column_names | Spaltennamen in den Daten, die, wenn sie gruppiert sind, die Datenpartitionen definieren. Die Trainingskomponente für viele Modelle startet einen unabhängigen Trainingsauftrag in jeder Partition. |
| allow_multi_partitions | Ein optionales Flag, das das Training eines Modells pro Partition ermöglicht, wenn jede Partition mehr als eine eindeutige Zeitreihe enthält. Der Standardwert ist Falsch. |
Das folgende Beispiel stellt eine Konfigurationsvorlage bereit:
$schema: https://azuremlsdk2.blob.core.windows.net/preview/0.0.1/autoMLJob.schema.json
type: automl
description: A time series forecasting job config
compute: azureml:<cluster-name>
task: forecasting
primary_metric: normalized_root_mean_squared_error
target_column_name: sales
n_cross_validations: 3
forecasting:
time_column_name: date
time_series_id_column_names: ["state", "store"]
forecast_horizon: 28
training:
blocked_training_algorithms: ["ExtremeRandomTrees"]
limits:
timeout_minutes: 15
max_trials: 10
max_concurrent_trials: 4
max_cores_per_trial: -1
trial_timeout_minutes: 15
enable_early_termination: true
partition_column_names: ["state", "store"]
allow_multi_partitions: false
In den folgenden Beispielen gehen wir davon aus, dass die Konfiguration im Pfad ./automl_settings_mm.yml gespeichert ist.
Pipeline für viele Modelle
Als nächstes definieren wir eine Factoryfunktion, die Pipelines für die Orchestrierung von Training, Rückschlüssen und Metrikberechnungen für viele Modelle erstellt. Die Parameter dieser Factoryfunktion sind in der folgenden Tabelle aufgeführt:
| Parameter | Beschreibung |
|---|---|
| max_nodes | Anzahl der Computeknoten, die für den Trainingsauftrag verwendet werden sollen |
| max_concurrency_per_node | Anzahl der AutoML-Prozesse, die auf jedem Knoten ausgeführt werden. Die Gesamtparallelität von Aufträgen für viele Modelle ist also max_nodes * max_concurrency_per_node. |
| parallel_step_timeout_in_seconds | In Sekunden angegebener Timeout für die Komponente „Viele Modelle“. |
| retrain_failed_models | Flag zum Aktivieren des erneuten Trainings für fehlerhafte Modelle. Dies ist nützlich, wenn Sie zuvor Ausführungen für viele Modelle durchgeführt haben, die zu fehlerhaften AutoML-Aufträgen für einige Datenpartitionen geführt haben. Wenn dieses Flag aktiviert ist, starten viele Modelle nur Trainingsaufträge für zuvor fehlerhafte Partitionen. |
| forecast_mode | Rückschlussmodus für die Modellauswertung. Gültige Werte sind "recursive" und „rolling“. Weitere Informationen finden Sie im Artikel Modellauswertung. |
| forecast_step | Schrittweite für die rollierende Vorhersage. Weitere Informationen finden Sie im Artikel Modellauswertung. |
Das folgende Beispiel veranschaulicht eine Factorymethode zur Erstellung von Trainings- und Modellauswertungspipelines für viele Modelle:
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
# Get a credential for access to the AzureML registry
try:
credential = DefaultAzureCredential()
# Check if we can get token successfully.
credential.get_token("https://management.azure.com/.default")
except Exception as ex:
# Fall back to InteractiveBrowserCredential in case DefaultAzureCredential fails
credential = InteractiveBrowserCredential()
# Get a many models training component
mm_train_component = ml_client_registry.components.get(
name='automl_many_models_training',
version='latest'
)
# Get a many models inference component
mm_inference_component = ml_client_registry.components.get(
name='automl_many_models_inference',
version='latest'
)
# Get a component for computing evaluation metrics
compute_metrics_component = ml_client_metrics_registry.components.get(
name="compute_metrics",
label="latest"
)
@pipeline(description="AutoML Many Models Forecasting Pipeline")
def many_models_train_evaluate_factory(
train_data_input,
test_data_input,
automl_config_input,
compute_name,
max_concurrency_per_node=4,
parallel_step_timeout_in_seconds=3700,
max_nodes=4,
retrain_failed_model=False,
forecast_mode="rolling",
forecast_step=1
):
mm_train_node = mm_train_component(
raw_data=train_data_input,
automl_config=automl_config_input,
max_nodes=max_nodes,
max_concurrency_per_node=max_concurrency_per_node,
parallel_step_timeout_in_seconds=parallel_step_timeout_in_seconds,
retrain_failed_model=retrain_failed_model,
compute_name=compute_name
)
mm_inference_node = mm_inference_component(
raw_data=test_data_input,
max_nodes=max_nodes,
max_concurrency_per_node=max_concurrency_per_node,
parallel_step_timeout_in_seconds=parallel_step_timeout_in_seconds,
optional_train_metadata=mm_train_node.outputs.run_output,
forecast_mode=forecast_mode,
forecast_step=forecast_step,
compute_name=compute_name
)
compute_metrics_node = compute_metrics_component(
task="tabular-forecasting",
prediction=mm_inference_node.outputs.evaluation_data,
ground_truth=mm_inference_node.outputs.evaluation_data,
evaluation_config=mm_inference_node.outputs.evaluation_configs
)
# Return the metrics results from the rolling evaluation
return {
"metrics_result": compute_metrics_node.outputs.evaluation_result
}
Jetzt konstruieren wir die Pipeline über die Factoryfunktion, wobei wir davon ausgehen, dass sich die Trainings- und Testdaten in den lokalen Ordnern ./data/train bzw. ./data/test befinden. Schließlich legen wir den Standardcompute fest und übermitteln den Auftrag wie im folgenden Beispiel:
pipeline_job = many_models_train_evaluate_factory(
train_data_input=Input(
type="uri_folder",
path="./data/train"
),
test_data_input=Input(
type="uri_folder",
path="./data/test"
),
automl_config=Input(
type="uri_file",
path="./automl_settings_mm.yml"
),
compute_name="<cluster name>"
)
pipeline_job.settings.default_compute = "<cluster name>"
returned_pipeline_job = ml_client.jobs.create_or_update(
pipeline_job,
experiment_name=experiment_name,
)
ml_client.jobs.stream(returned_pipeline_job.name)
Nach Beendigung des Auftrags können die Auswertungsmetriken mithilfe des gleichen Verfahrens wie in der Pipeline für einzelne Trainingsausführung lokal heruntergeladen werden.
Ein ausführlicheres Beispiel finden Sie auch im Notebook zur Bedarfsvorhersage mit vielen Modellen.
Hinweis
Die Trainings- und Rückschlusskomponenten für viele Modelle partitionieren Ihre Daten entsprechend der partition_column_names-Einstellung, sodass sich jede Partition in einer eigenen Datei befindet. Dieser Prozess kann sehr langsam sein oder fehlschlagen, wenn die Daten sehr umfangreich sind. In diesem Fall empfehlen wir Ihnen, Ihre Daten manuell zu partitionieren, bevor Sie das Training oder den Rückschluss für viele Modelle ausführen.
Vorhersage im großen Stil: Hierarchische Zeitreihen
Wichtig
Dieses Feature ist zurzeit als öffentliche Preview verfügbar. Diese Vorschauversion wird ohne Vereinbarung zum Servicelevel bereitgestellt und ist nicht für Produktionsworkloads vorgesehen. Manche Features werden möglicherweise nicht unterstützt oder sind nur eingeschränkt verwendbar.
Weitere Informationen finden Sie unter Zusätzliche Nutzungsbestimmungen für Microsoft Azure-Vorschauen.
Mit den Komponenten für hierarchische Zeitreihen (Hierarchical Time Series, HTS) in AutoML können Sie eine große Anzahl von Modellen anhand von Daten mit hierarchischer Struktur trainieren. Weitere Informationen finden Sie im Artikelabschnitt HTS.
HTS-Trainingskonfiguration
Die HTS-Trainingskomponente akzeptiert eine Konfigurationsdatei im YAML-Format mit AutoML-Trainingseinstellungen. Die Komponente wendet diese Einstellungen auf jede AutoML-Instanz an, die sie startet. Diese YAML-Datei hat dieselbe Spezifikation wie der Vorhersageauftrag sowie zusätzliche Parameter in Bezug auf die Hierarchieinformationen:
| Parameter | Beschreibung |
|---|---|
| hierarchy_column_names | Eine Liste von Spaltennamen in den Daten, die die hierarchische Struktur der Daten definieren. Die Reihenfolge der Spalten in dieser Liste bestimmt die Hierarchieebenen. Der Grad der Aggregation nimmt mit dem Listenindex ab. Das heißt, die letzte Spalte in der Liste definiert die Blattebene (die am stärksten disaggregierte Ebene) der Hierarchie. |
| hierarchy_training_level | Die Hierarchieebene, die für das Training des Vorhersagemodells verwendet werden soll. |
Das folgende Beispiel zeigt eine Beispielkonfiguration:
$schema: https://azuremlsdk2.blob.core.windows.net/preview/0.0.1/autoMLJob.schema.json
type: automl
description: A time series forecasting job config
compute: azureml:cluster-name
task: forecasting
primary_metric: normalized_root_mean_squared_error
log_verbosity: info
target_column_name: sales
n_cross_validations: 3
forecasting:
time_column_name: "date"
time_series_id_column_names: ["state", "store", "SKU"]
forecast_horizon: 28
training:
blocked_training_algorithms: ["ExtremeRandomTrees"]
limits:
timeout_minutes: 15
max_trials: 10
max_concurrent_trials: 4
max_cores_per_trial: -1
trial_timeout_minutes: 15
enable_early_termination: true
hierarchy_column_names: ["state", "store", "SKU"]
hierarchy_training_level: "store"
In den folgenden Beispielen gehen wir davon aus, dass die Konfiguration im Pfad ./automl_settings_hts.yml gespeichert ist.
HTS-Pipeline
Als nächstes definieren wir eine Factoryfunktion, die Pipelines für die Orchestrierung von Training, Rückschlüssen und Metrikberechnungen für HTS erstellt. Die Parameter dieser Factoryfunktion sind in der folgenden Tabelle aufgeführt:
| Parameter | Beschreibung |
|---|---|
| forecast_level | Die Ebene der Hierarchie, für die Vorhersagen abgerufen werden sollen. |
| allocation_method | Zuordnungsmethode, die beim Disaggregieren von Vorhersagen zu verwenden ist. Gültige Werte sind "proportions_of_historical_average" und "average_historical_proportions". |
| max_nodes | Anzahl der Computeknoten, die für den Trainingsauftrag verwendet werden sollen |
| max_concurrency_per_node | Anzahl der AutoML-Prozesse, die auf jedem Knoten ausgeführt werden. Die Gesamtparallelität eines HTS-Auftrags ist also max_nodes * max_concurrency_per_node. |
| parallel_step_timeout_in_seconds | In Sekunden angegebener Timeout für die Komponente „Viele Modelle“. |
| forecast_mode | Rückschlussmodus für die Modellauswertung. Gültige Werte sind "recursive" und „rolling“. Weitere Informationen finden Sie im Artikel Modellauswertung. |
| forecast_step | Schrittweite für die rollierende Vorhersage. Weitere Informationen finden Sie im Artikel Modellauswertung. |
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
# Get a credential for access to the AzureML registry
try:
credential = DefaultAzureCredential()
# Check if we can get token successfully.
credential.get_token("https://management.azure.com/.default")
except Exception as ex:
# Fall back to InteractiveBrowserCredential in case DefaultAzureCredential fails
credential = InteractiveBrowserCredential()
# Get a HTS training component
hts_train_component = ml_client_registry.components.get(
name='automl_hts_training',
version='latest'
)
# Get a HTS inference component
hts_inference_component = ml_client_registry.components.get(
name='automl_hts_inference',
version='latest'
)
# Get a component for computing evaluation metrics
compute_metrics_component = ml_client_metrics_registry.components.get(
name="compute_metrics",
label="latest"
)
@pipeline(description="AutoML HTS Forecasting Pipeline")
def hts_train_evaluate_factory(
train_data_input,
test_data_input,
automl_config_input,
max_concurrency_per_node=4,
parallel_step_timeout_in_seconds=3700,
max_nodes=4,
forecast_mode="rolling",
forecast_step=1,
forecast_level="SKU",
allocation_method='proportions_of_historical_average'
):
hts_train = hts_train_component(
raw_data=train_data_input,
automl_config=automl_config_input,
max_concurrency_per_node=max_concurrency_per_node,
parallel_step_timeout_in_seconds=parallel_step_timeout_in_seconds,
max_nodes=max_nodes
)
hts_inference = hts_inference_component(
raw_data=test_data_input,
max_nodes=max_nodes,
max_concurrency_per_node=max_concurrency_per_node,
parallel_step_timeout_in_seconds=parallel_step_timeout_in_seconds,
optional_train_metadata=hts_train.outputs.run_output,
forecast_level=forecast_level,
allocation_method=allocation_method,
forecast_mode=forecast_mode,
forecast_step=forecast_step
)
compute_metrics_node = compute_metrics_component(
task="tabular-forecasting",
prediction=hts_inference.outputs.evaluation_data,
ground_truth=hts_inference.outputs.evaluation_data,
evaluation_config=hts_inference.outputs.evaluation_configs
)
# Return the metrics results from the rolling evaluation
return {
"metrics_result": compute_metrics_node.outputs.evaluation_result
}
Jetzt konstruieren wir die Pipeline über die Factoryfunktion, wobei wir davon ausgehen, dass sich die Trainings- und Testdaten in den lokalen Ordnern ./data/train bzw. ./data/test befinden. Schließlich legen wir den Standardcompute fest und übermitteln den Auftrag wie im folgenden Beispiel:
pipeline_job = hts_train_evaluate_factory(
train_data_input=Input(
type="uri_folder",
path="./data/train"
),
test_data_input=Input(
type="uri_folder",
path="./data/test"
),
automl_config=Input(
type="uri_file",
path="./automl_settings_hts.yml"
)
)
pipeline_job.settings.default_compute = "cluster-name"
returned_pipeline_job = ml_client.jobs.create_or_update(
pipeline_job,
experiment_name=experiment_name,
)
ml_client.jobs.stream(returned_pipeline_job.name)
Nach Beendigung des Auftrags können die Auswertungsmetriken mithilfe des gleichen Verfahrens wie in der Pipeline für einzelne Trainingsausführung lokal heruntergeladen werden.
Ein ausführlicheres Beispiel finden Sie auch im Notebook zur Bedarfsvorhersage mit hierarchischen Zeitreihen.
Hinweis
Die Trainings- und Rückschlusskomponenten für HTS partitionieren Ihre Daten entsprechend der hierarchy_column_names-Einstellung, sodass sich jede Partition in einer eigenen Datei befindet. Dieser Prozess kann sehr langsam sein oder fehlschlagen, wenn die Daten sehr umfangreich sind. In diesem Fall empfehlen wir Ihnen, Ihre Daten manuell zu partitionieren, bevor Sie das Training oder den Rückschluss für HTS ausführen.
Vorhersagen im großen Stil: Verteiltes DNN-Training
- Informationen dazu, wie verteiltes Training für Vorhersageaufgaben funktioniert, finden Sie in unserem Artikel Vorhersagen im großen Stil.
- Codebeispiele finden Sie in unserem Artikelabschnitt Einrichten des verteilten Trainings für Tabellendaten.
Beispielnotebooks
Sehen Sie sich die Notebooks zum Vorhersagebeispiel an. Dort finden Sie ausführliche Codebeispiele zu einer erweiterten Vorhersagekonfiguration, einschließlich:
- Beispiele für Bedarfsvorhersagepipeline
- Deep Learning-Modelle
- Feiertagserkennung und Featurisierung
- Manuelle Konfiguration für Verzögerungen und Aggregationsfunktionen für rollierende Fenster
Nächste Schritte
- Erfahren Sie mehr darüber, Wie Sie ein automatisiertes ML-Modell an einem Online-Endpunkt bereitstellt.
- Informieren Sie sich über Interpretierbarkeit: Modellerklärungen beim automatisierten maschinellen Lernen (Vorschau).
- Erfahren Sie, wie automatisiertes ML Vorhersagemodelle erstellt.
- Erfahren Sie mehr über Vorhersagen im großen Stil.
- Erfahren Sie, wie Sie AutoML für verschiedene Vorhersageszenarien konfigurieren.
- Erfahren Sie mehr über Rückschlüsse und Auswertungen von Vorhersagemodellen.