Erstellen und Ausführen von Machine Learning-Pipelines mit dem Azure Machine Learning SDK
GILT FÜR: Python SDK azureml v1
Python SDK azureml v1
In diesem Artikel erfahren Sie, wie Sie Pipelines des maschinellen Lernens mit dem Azure Machine Learning SDK erstellen und ausführen. Verwenden Sie ML-Pipelines zum Erstellen eines Workflows, der verschiedene ML-Phasen zusammenfügt. Veröffentlichen Sie diese Pipeline dann für den späteren Zugriff oder die Freigabe für andere. Verfolgen Sie ML-Pipelines nach, um zu sehen, wie Ihr Modell in der echten Welt funktioniert, und Datenabweichung zu erkennen. ML-Pipelines eignen sich ideal für Szenarien mit Batchbewertungen, in denen verschiedene Berechnungen ausgeführt, Schritte wiederverwendet statt wiederholt ausgeführt und ML-Workflows für andere Personen freigegeben werden.
Dieser Artikel ist kein Tutorial. Eine Anleitung zum Erstellen Ihrer ersten Pipeline finden Sie unter Tutorial: Erstellen einer Azure Machine Learning-Pipeline für die Batchbewertung oder Verwenden von automatisiertem ML in einer Azure Machine Learning-Pipeline in Python.
Sie können zwar zur CI/CD-Automatisierung von ML-Aufgaben eine andere Art von Pipeline verwenden, die als Azure-Pipeline bezeichnet wird, aber dieser Pipelinetyp wird nicht in Ihrem Arbeitsbereich gespeichert. Vergleichen Sie diese unterschiedlichen Pipelines.
Die von Ihnen erstellten ML-Pipelines sind für die Mitglieder Ihres Azure Machine Learning-Arbeitsbereichs sichtbar.
ML-Pipelines werden für Computeziele ausgeführt (siehe Was sind Computeziele in Azure Machine Learning?). Pipelines können Daten in unterstützten Azure Storage-Speicherorten lesen und schreiben.
Wenn Sie nicht über ein Azure-Abonnement verfügen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen. Probieren Sie die kostenlose oder kostenpflichtige Version von Azure Machine Learning aus.
Voraussetzungen
Ein Azure Machine Learning-Arbeitsbereich. Erstellen von Arbeitsbereichsressourcen
Konfigurieren Sie Ihre Entwicklungsumgebung für die Installation des Azure Machine Learning SDK, oder verwenden Sie eine Azure Machine Learning-Computeinstanz mit bereits installiertem SDK.
Beginnen Sie mit dem Anfügen Ihres Arbeitsbereichs:
import azureml.core
from azureml.core import Workspace, Datastore
ws = Workspace.from_config()
Einrichten von Machine Learning-Ressourcen
Erstellen Sie die Ressourcen, die zum Ausführen einer ML-Pipeline erforderlich sind:
Richten Sie einen Datenspeicher ein, über den auf die in den Pipelineschritten benötigten Daten zugegriffen werden kann.
Konfigurieren Sie ein
Dataset-Objekt, um auf beständige Daten zu verweisen, die sich in einem Datenspeicher befinden oder dort zugänglich sind. Konfigurieren Sie einOutputFileDatasetConfig-Objekt für temporäre Daten, die zwischen den Pipelineschritten übermittelt werden.Richten Sie die Computeziele ein, auf denen Ihre Pipelineschritte ausgeführt werden.
Einrichten eines Datenspeichers
Ein Datenspeicher speichert die Daten für den Zugriff durch die Pipeline. Jeder Arbeitsbereich verfügt über einen Standarddatenspeicher. Sie können mehrere Datenspeicher registrieren.
Wenn Sie Ihren Arbeitsbereich erstellen, werden Azure Files und Azure Blob Storage an den Arbeitsbereich angefügt. Ein Standarddatenspeicher wird registriert, um eine Verbindung mit Azure Blob Storage herzustellen. Weitere Informationen finden Sie unter Entscheidung zwischen Azure-Blobs, Azure Files und Azure-Datenträgern.
# Default datastore
def_data_store = ws.get_default_datastore()
# Get the blob storage associated with the workspace
def_blob_store = Datastore(ws, "workspaceblobstore")
# Get file storage associated with the workspace
def_file_store = Datastore(ws, "workspacefilestore")
Die Schritte nutzen im Allgemeinen Daten und erzeugen Ausgabedaten. Ein Schritt kann Daten wie ein Modell, ein Verzeichnis mit Modell- und abhängigen Dateien oder temporäre Daten erstellen. Diese Daten stehen dann später für weitere Schritte in der Pipeline zur Verfügung. Weitere Informationen zum Verbinden Ihrer Pipeline mit Ihren Daten finden Sie in den Artikeln Zugreifen auf Daten und Registrieren von Datasets.
Konfigurieren von Daten mithilfe von Dataset- und OutputFileDatasetConfig-Objekten
Zum Bereitstellen von Daten für eine Pipeline wird vorzugsweise ein Dataset-Objekt verwendet. Das Dataset-Objekt verweist auf Daten, die sich in einem Datenspeicher befinden oder über diesen oder über eine Web-URL zugänglich sind. Die Dataset-Klasse ist abstrakt. Daher erstellen Sie eine Instanz von FileDataset (die auf eine oder mehrere Dateien verweist) oder TabularDataset, die aus einer oder mehreren Dateien mit durch Trennzeichen getrennten Spalten von Daten erstellt wird.
Sie erstellen ein Dataset mit Methoden wie from_files oder from_delimited_files.
from azureml.core import Dataset
my_dataset = Dataset.File.from_files([(def_blob_store, 'train-images/')])
Zwischendaten (oder die Ausgabe eines Schritts) werden durch ein OutputFileDatasetConfig-Objekt dargestellt. output_data1 wird als Ausgabe eines Schritts produziert. Optional können diese Daten durch Aufruf vonregister_on_complete als Dataset registriert werden. Wenn Sie ein OutputFileDatasetConfig-Objekt in einem Schritt erstellen und als Eingabe für einen anderen Schritt verwenden, entsteht durch die Datenabhängigkeit zwischen den Schritten eine implizite Ausführungsreihenfolge in der Pipeline.
OutputFileDatasetConfig-Objekte geben ein Verzeichnis zurück, und schreiben ihre Ausgaben standardmäßig in den Standarddatenspeicher des Arbeitsbereichs.
from azureml.data import OutputFileDatasetConfig
output_data1 = OutputFileDatasetConfig(destination = (datastore, 'outputdataset/{run-id}'))
output_data_dataset = output_data1.register_on_complete(name = 'prepared_output_data')
Wichtig
Zwischengespeicherte Daten, die mit OutputFileDatasetConfig gespeichert wurden, werden von Azure nicht automatisch gelöscht.
Sie sollten zwischengespeicherte Daten entweder programmgesteuert am Ende einer Pipelineausführung löschen, einen Datenspeicher mit einer Richtlinie für die Kurzzeitdatenaufbewahrung verwenden oder regelmäßig eine manuelle Bereinigung durchführen.
Tipp
Laden Sie nur Dateien hoch, die für den derzeitigen Auftrag relevant sind. Bei Änderungen an Dateien im Datenverzeichnis wird der Schritt bei der nächsten Ausführung der Pipeline erneut ausgeführt. Dies gilt selbst dann, wenn die Wiederverwendung festgelegt wurde.
Einrichten von Computezielen
In Azure Machine Learning bezieht sich der Begriff Compute (oder Computeziel) auf die Computer oder Cluster, die die Berechnungsschritte in Ihrer Machine Learning-Pipeline durchführen. Eine vollständige Liste der Computeziele finden Sie unter Computeziele für das Modelltraining, und Informationen zum Erstellen und Anfügen an Ihren Arbeitsbereich finden Sie unter Erstellen von Computezielen. Das Verfahren zum Erstellen und/oder Anfügen eines Computeziels ist immer dasselbe, ganz gleich, ob Sie ein Modell trainieren oder einen Pipelineschritt ausführen. Verwenden Sie nach dem Erstellen und Anfügen des Computeziels das ComputeTarget-Objekt in Ihrem Pipelineschritt.
Wichtig
Das Ausführen von Verwaltungsvorgängen auf Computezielen wird innerhalb von Remoteaufträgen nicht unterstützt. Da Pipelines für maschinelles Lernen als Remoteauftrag übermittelt werden, sollten Sie innerhalb der Pipeline keine Verwaltungsvorgänge auf Computeziele anwenden.
Azure Machine Learning Compute
Sie können eine Azure Machine Learning-Computeressource zum Ausführen Ihrer Schritte erstellen. Der Code für andere Computeziele ist ähnlich, je nach Typ mit etwas anderen Parametern.
from azureml.core.compute import ComputeTarget, AmlCompute
compute_name = "aml-compute"
vm_size = "STANDARD_NC6"
if compute_name in ws.compute_targets:
compute_target = ws.compute_targets[compute_name]
if compute_target and type(compute_target) is AmlCompute:
print('Found compute target: ' + compute_name)
else:
print('Creating a new compute target...')
provisioning_config = AmlCompute.provisioning_configuration(vm_size=vm_size, # STANDARD_NC6 is GPU-enabled
min_nodes=0,
max_nodes=4)
# create the compute target
compute_target = ComputeTarget.create(
ws, compute_name, provisioning_config)
# Can poll for a minimum number of nodes and for a specific timeout.
# If no min node count is provided it will use the scale settings for the cluster
compute_target.wait_for_completion(
show_output=True, min_node_count=None, timeout_in_minutes=20)
# For a more detailed view of current cluster status, use the 'status' property
print(compute_target.status.serialize())
Konfigurieren der Umgebung für die Trainingsausführung
Im nächsten Schritt wird sichergestellt, dass die Remotetrainingsausführung über alle Abhängigkeiten verfügt, die für die Trainingsschritte erforderlich sind. Abhängigkeiten und der Laufzeitkontext werden festgelegt, indem ein RunConfiguration-Objekt erstellt und konfiguriert wird.
from azureml.core.runconfig import RunConfiguration
from azureml.core.conda_dependencies import CondaDependencies
from azureml.core import Environment
aml_run_config = RunConfiguration()
# `compute_target` as defined in "Azure Machine Learning compute" section above
aml_run_config.target = compute_target
USE_CURATED_ENV = True
if USE_CURATED_ENV :
curated_environment = Environment.get(workspace=ws, name="AzureML-sklearn-0.24-ubuntu18.04-py37-cpu")
aml_run_config.environment = curated_environment
else:
aml_run_config.environment.python.user_managed_dependencies = False
# Add some packages relied on by data prep step
aml_run_config.environment.python.conda_dependencies = CondaDependencies.create(
conda_packages=['pandas','scikit-learn'],
pip_packages=['azureml-sdk', 'azureml-dataset-runtime[fuse,pandas]'],
pin_sdk_version=False)
Der obige Code zeigt zwei Optionen für die Behandlung von Abhängigkeiten. In dieser Darstellung basiert die Konfiguration bei USE_CURATED_ENV = True auf einer zusammengestellten Umgebung. Zusammengestellte Umgebungen sind bereits vorkonfiguriert und weisen gemeinsame voneinander abhängige Bibliotheken auf. Somit können sie schneller online gestellt werden. Für zusammengestellte Umgebungen sind in Microsoft Container Registry vorab erstellte Docker-Images vorhanden. Weitere Informationen finden Sie unter Azure Machine Learning – zusammengestellte Umgebungen.
Wenn Sie USE_CURATED_ENV in False ändern, wird ein Pfad durchlaufen, der das Muster zum expliziten Festlegen Ihrer Abhängigkeiten zeigt. In diesem Szenario wird ein neues benutzerdefiniertes Docker-Image erstellt und bei einer Azure Container Registry-Instanz in Ihrer Ressourcengruppe registriert (siehe Einführung in private Docker-Containerregistrierungen in Azure). Das Erstellen und Registrieren dieses Images kann längere Zeit dauern.
Erstellen Ihrer Pipelineschritte
Nachdem Sie die Computeressource und die Umgebung erstellt haben, können Sie die Schritte Ihrer Pipeline definieren. Über das Azure Machine Learning SDK werden viele integrierte Schritte zur Verfügung gestellt. Diese können Sie in der Referenzdokumentation für das azureml.pipeline.steps-Paket einsehen. Die flexibelste Klasse ist PythonScriptStep, die ein Python-Skript ausführt.
from azureml.pipeline.steps import PythonScriptStep
dataprep_source_dir = "./dataprep_src"
entry_point = "prepare.py"
# `my_dataset` as defined above
ds_input = my_dataset.as_named_input('input1')
# `output_data1`, `compute_target`, `aml_run_config` as defined above
data_prep_step = PythonScriptStep(
script_name=entry_point,
source_directory=dataprep_source_dir,
arguments=["--input", ds_input.as_download(), "--output", output_data1],
compute_target=compute_target,
runconfig=aml_run_config,
allow_reuse=True
)
Im obigen Code wird ein gängiger erster Pipelineschritt gezeigt. Ihr Datenaufbereitungscode befindet sich in einem Unterverzeichnis (in diesem Beispiel "prepare.py" im Verzeichnis "./dataprep.src"). Im Rahmen des Pipelineerstellungsprozesses wird dieses Verzeichnis in einer ZIP-Datei komprimiert und in compute_target hochgeladen. Der Schritt führt das Skript dann als Wert für script_name aus.
Mit den arguments-Werten werden die Ein- und Ausgaben des Schritts festgelegt. Im obigen Beispiel stellt das my_dataset-Dataset die Baselinedaten dar. Die entsprechenden Daten werden in die Computeressource heruntergeladen, da der Code diese als as_download() angibt. Das Skript prepare.py führt alle Datentransformationsaufgaben durch, die für die aktuelle Aufgabe geeignet sind, und gibt die Daten in output_data1 mit dem Typ OutputFileDatasetConfig aus. Weitere Informationen finden Sie unter Verschieben von Daten in und zwischen ML-Pipelineschritten (Python).
Der Schritt wird auf dem von compute_target definierten Computer mit der Konfiguration aml_run_config ausgeführt.
Die Wiederverwendung von vorherigen Ergebnissen (allow_reuse) ist entscheidend, wenn Pipelines in einer Umgebung für Zusammenarbeit verwendet werden, da die Beseitigung von nicht benötigten erneuten Ausführungen die Flexibilität erhöht. Die Wiederverwendung ist das Standardverhalten, wenn „script_name“ und die Eingaben und Parameter eines Schritts gleich bleiben. Wenn die Wiederverwendung zugelassen wird, werden die Ergebnisse der vorherigen Ausführung direkt an den nächsten Schritt gesendet. Wenn allow_reuse auf False festgelegt ist, wird während der Pipelineausführung immer eine neue Ausführung für diesen Schritt generiert.
Es ist möglich, eine Pipeline mit einem einzigen Schritt zu erstellen, jedoch sollten Sie Ihren Gesamtprozess fast immer in mehrere Schritte unterteilen. Beispielsweise können Sie über Schritte für die Datenaufbereitung, das Training, einen Modellvergleich und die Bereitstellung verfügen. Beispielsweise könnte man sich vorstellen, dass der nächste Schritt nach dem oben angegebenen data_prep_step das Training ist:
train_source_dir = "./train_src"
train_entry_point = "train.py"
training_results = OutputFileDatasetConfig(name = "training_results",
destination = def_blob_store)
train_step = PythonScriptStep(
script_name=train_entry_point,
source_directory=train_source_dir,
arguments=["--prepped_data", output_data1.as_input(), "--training_results", training_results],
compute_target=compute_target,
runconfig=aml_run_config,
allow_reuse=True
)
Der obige Code ist dem Code des Datenaufbereitungsschritts sehr ähnlich. Der Trainingscode befindet sich in einem separaten Verzeichnis zu dem des Datenaufbereitungscodes. In der OutputFileDatasetConfig-Ausgabe des Datenaufbereitungsschritts wird output_data1 als Eingabe für den Trainingsschritt verwendet. Das neue OutputFileDatasetConfig-Objekt training_results wird erstellt, um die Ergebnisse für einen späteren Vergleichs- oder Bereitstellungsschritt zu speichern.
Andere Codebeispiele finden Sie unter Erstellen einer ML-Pipeline mit zwei Schritten und Schreiben von Daten in Datenspeicher nach Abschluss der Ausführung.
Nachdem Sie die Schritte definiert haben, erstellen Sie die Pipeline mit einigen oder allen dieser Schritte.
Hinweis
Es werden keine Dateien oder Daten in Azure Machine Learning hochgeladen, wenn Sie die Schritte definieren oder die Pipeline erstellen. Die Dateien werden hochgeladen, wenn Sie Experiment.submit() aufrufen.
# list of steps to run (`compare_step` definition not shown)
compare_models = [data_prep_step, train_step, compare_step]
from azureml.pipeline.core import Pipeline
# Build the pipeline
pipeline1 = Pipeline(workspace=ws, steps=[compare_models])
Verwenden eines Datasets
Auf der Grundlage von Azure Blob Storage, Azure Files, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, Azure SQL-Datenbank und Azure Database for PostgreSQL erstellte Datasets können für jeden Pipelineschritt als Eingabe verwendet werden. Sie können die Ausgabe in DataTransferStep oder DatabricksStep schreiben oder OutputFileDatasetConfig verwenden, wenn Sie Daten in einen bestimmten Datenspeicher schreiben möchten.
Wichtig
Das Schreiben von Ausgabedaten in einen Datenspeicher mit OutputFileDatasetConfig wird nur für Azure-Blob-, Azure-Dateifreigabe-, ADLS Gen1- und Gen2-Datenspeicher unterstützt.
dataset_consuming_step = PythonScriptStep(
script_name="iris_train.py",
inputs=[iris_tabular_dataset.as_named_input("iris_data")],
compute_target=compute_target,
source_directory=project_folder
)
Anschließend rufen Sie mit dem Wörterbuch Run.input_datasets das Dataset in der Pipeline ab.
# iris_train.py
from azureml.core import Run, Dataset
run_context = Run.get_context()
iris_dataset = run_context.input_datasets['iris_data']
dataframe = iris_dataset.to_pandas_dataframe()
Die Zeile Run.get_context() verdient besondere Beachtung. Diese Funktion ruft ein Run-Objekt ab, das die aktuelle experimentelle Ausführung darstellt. Im obigen Beispiel verwenden wir die Funktion zum Abrufen eines registrierten Datasets. Das Run-Objekt wird auch häufig verwendet, um das Experiment selbst und den Arbeitsbereich abzurufen, in dem sich das Experiment befindet:
# Within a PythonScriptStep
ws = Run.get_context().experiment.workspace
Weitere Details, einschließlich alternativer Verfahren zum Übergeben von Daten und Zugreifen auf Daten, finden Sie unter Moving data into and between ML pipeline steps (Python) (Verschieben von Daten in und zwischen ML-Pipelineschritten (Python), in englischer Sprache).
Zwischenspeichern und Wiederverwenden
Zur Optimierung und Anpassung des Verhaltens Ihrer Pipelines können Sie einige Optionen für die Zwischenspeicherung und Wiederverwendung nutzen. Sie haben beispielsweise folgende Optionen:
- Deaktivieren Sie die standardmäßige Wiederverwendung der Ausgabe nach Ausführung des Schritts, indem Sie bei der Schrittdefinition
allow_reuse=Falsefestlegen. Die Wiederverwendung ist entscheidend, wenn Pipelines in einer Umgebung für die Zusammenarbeit verwendet werden, weil die Beseitigung von nicht benötigten Ausführungen zu einer höheren Flexibilität führt. Sie können die Wiederverwendung aber auch deaktivieren. - Erzwingen Sie die erneute Generierung der Ausgabe für alle Schritte einer Ausführung mit
pipeline_run = exp.submit(pipeline, regenerate_outputs=True).
Standardmäßig ist allow_reuse für Schritte aktiviert, und das in der Schrittdefinition angegebene source_directory verfügt über einen Hashwert. Wenn das Skript für einen Schritt unverändert bleibt (script_name, Eingaben und Parameter), und sich sonst nichts im source_directory geändert hat, wird also die Ausgabe eines vorherigen Schritts wiederverwendet, der Auftrag wird nicht an den Computevorgang übermittelt, und die Ergebnisse der vorherigen Ausführung sind stattdessen sofort für den nächsten Schritt verfügbar.
step = PythonScriptStep(name="Hello World",
script_name="hello_world.py",
compute_target=aml_compute,
source_directory=source_directory,
allow_reuse=False,
hash_paths=['hello_world.ipynb'])
Hinweis
Wenn sich die Namen der Dateneingaben ändern, wird der Schritt erneut ausgeführt, auch wenn sich die zugrunde liegenden Daten nicht geändert haben. Sie müssen das Feld name der Eingabedaten explizit festlegen (data.as_input(name=...)). Wenn Sie diesen Wert nicht explizit festlegen, wird das Feld name auf eine zufällige GUID festgelegt, und die Ergebnisse des Schritts werden nicht wiederverwendet.
Übermitteln der Pipeline
Wenn Sie die Pipeline übermitteln, prüft Azure Machine Learning die Abhängigkeiten für die einzelnen Schritte und lädt eine Momentaufnahme des als Quellverzeichnis angegebenen Ordners hoch. Wenn kein Quellverzeichnis angegeben ist, wird das aktuelle lokale Verzeichnis hochgeladen. Die Momentaufnahme wird auch als Teil des Experiments in Ihrem Arbeitsbereich gespeichert.
Wichtig
Um zu verhindern, dass nicht benötigte Dateien in die Momentaufnahme eingeschlossen werden, erstellen Sie im Verzeichnis eine Ignore-Datei (.gitignore oder .amlignore). Fügen Sie dieser Datei die Dateien und Verzeichnisse hinzu, die ignoriert werden sollen. Weitere Informationen zur Syntax, die in dieser Datei zu verwenden ist, finden Sie unter Syntax und Muster für .gitignore. Die .amlignore-Datei verwendet die gleiche Syntax. Wenn beide Dateien vorhanden sind, wird die Datei .amlignore verwendet, und die Datei .gitignore wird nicht verwendet.
Weitere Informationen finden Sie unter Momentaufnahmen.
from azureml.core import Experiment
# Submit the pipeline to be run
pipeline_run1 = Experiment(ws, 'Compare_Models_Exp').submit(pipeline1)
pipeline_run1.wait_for_completion()
Wenn Sie eine Pipeline erstmals ausführen, geht Azure Machine Learning folgendermaßen vor:
Die Momentaufnahme des Projekts wird aus dem Blobspeicher, der dem Arbeitsbereich zugeordnet ist, auf das Computeziel heruntergeladen.
Für jeden Schritt in der Pipeline wird ein Docker-Image erstellt.
Das Docker-Image für die einzelnen Schritte wird aus der Containerregistrierung auf das Computeziel heruntergeladen.
Konfiguriert den Zugriff auf das
Dataset-Objekt und dasOutputFileDatasetConfig-Objekt. Im Zugriffsmodusas_mount()wird FUSE zum Bereitstellen des virtuellen Zugriffs verwendet. Wenn das Einbinden nicht unterstützt wird oder der Benutzer als Zugriffsmodusas_upload()angegeben hat, werden die Daten stattdessen in das Computeziel kopiert.Der Schritt wird in dem in der Schrittdefinition angegebenen Computeziel ausgeführt.
Artefakte wie Protokolle, stdout und stderr, Metriken und Ausgaben, die durch den Schritt angegeben werden, werden erstellt. Diese Artefakte werden dann hochgeladen und im Standarddatenspeicher des Benutzers gespeichert.
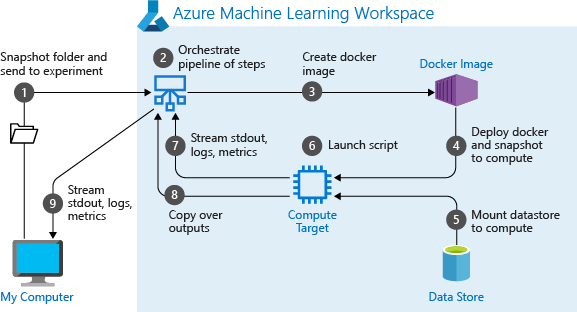
Weitere Informationen finden Sie in der Referenz zur Experiment-Klasse.
Verwenden von Pipelineparametern für Argumente, die sich beim Ziehen von Rückschlüssen ändern
Manchmal beziehen sich die Argumente für einzelne Schritte innerhalb einer Pipeline auf den Entwicklungs- und Trainingszeitraum: Dinge wie Trainingsraten und Momentum oder Pfade zu Daten- oder Konfigurationsdateien. Wenn ein Modell bereitgestellt ist, sollten Sie jedoch die Argumente (d. h. die von Ihnen erstellte Abfrage, die das Modell beantworten soll) für den Rückschluss dynamisch übergeben. Sie sollten diese Argumenttypen als Pipelineparameter festlegen. Verwenden Sie hierzu in Python die azureml.pipeline.core.PipelineParameter-Klasse, wie im folgenden Codeausschnitt gezeigt:
from azureml.pipeline.core import PipelineParameter
pipeline_param = PipelineParameter(name="pipeline_arg", default_value="default_val")
train_step = PythonScriptStep(script_name="train.py",
arguments=["--param1", pipeline_param],
target=compute_target,
source_directory=project_folder)
Funktionsweise von Python-Umgebungen mit Pipelineparametern
Wie bereits unter Konfigurieren der Umgebung für die Trainingsausführung erläutert, werden Abhängigkeiten für Umgebungsstatus und Python-Bibliotheken mithilfe eines Environment-Objekts angegeben. Im Allgemeinen können Sie ein vorhandenes Environment-Objekt angeben, indem Sie auf seinen Namen und optional auf eine Version verweisen:
aml_run_config = RunConfiguration()
aml_run_config.environment.name = 'MyEnvironment'
aml_run_config.environment.version = '1.0'
Wenn Sie jedoch PipelineParameter-Objekte verwenden möchten, um Variablen zur Laufzeit dynamisch für die Pipelineschritte festzulegen, können Sie nicht auf ein vorhandenes Environment-Objekt verweisen. Wenn Sie PipelineParameter-Objekte verwenden möchten, müssen Sie stattdessen das Feld environment von RunConfiguration auf ein Environment-Objekt festlegen. Sie müssen sicherstellen, dass für solch ein Environment-Objekt die Abhängigkeiten von externen Python-Paketen ordnungsgemäß festgelegt sind.
Anzeigen der Ergebnisse einer Pipeline
Hier finden Sie die Liste aller Ihrer Pipelines und deren Ausführungsdetails in Studio:
Melden Sie sich bei Azure Machine Learning Studio an.
Wählen Sie auf der linken Seite Pipelines aus, um alle Pipelineausführungen anzuzeigen.
Wählen Sie eine bestimmte Pipeline aus, um die Ausführungsergebnisse anzuzeigen.
Git-Nachverfolgung und -Integration
Wenn Sie eine Trainingsausführung starten, bei der das Quellverzeichnis ein lokales Git-Repository ist, werden Informationen über das Repository im Ausführungsverlauf gespeichert. Weitere Informationen finden Sie unter Git-Integration für Azure Machine Learning.
Nächste Schritte
- Informationen zum Freigeben Ihrer Pipeline für Kollegen oder Kunden finden Sie unter Veröffentlichen von Pipelines des maschinellen Lernens.
- Verwenden Sie diese Jupyter Notebooks auf GitHub, um Pipelines des maschinellen Lernens eingehender zu erkunden.
- Hinweise zu den Paketen azureml-pipelines-core und azureml-pipelines-steps finden Sie in der SDK-Referenzhilfe.
- Tipps zum Debuggen und zur Problembehandlung bei Pipelines finden Sie in der Schrittanleitung.
- Informationen zum Ausführen von Notebooks finden Sie im Artikel Verwenden von Jupyter-Notebooks zum Erkunden des Azure Machine Learning-Diensts.