Beispiele für Pipelines und Datasets für Azure Machine Learning Designer
Verwenden Sie die integrierten Beispiele in Azure Machine Learning-Designer, um die Erstellung eigener Machine Learning-Pipelines zu beschleunigen. Das GitHub-Repository des Azure Machine Learning-Designers enthält eine ausführliche Dokumentation mit grundlegenden Informationen zu einigen gängigen Machine Learning-Szenarien.
Voraussetzungen
- Ein Azure-Abonnement. Wenn Sie kein Azure-Abonnement besitzen, erstellen Sie ein kostenloses Konto.
- Ein Azure Machine Learning-Arbeitsbereich
Wichtig
Falls die in diesem Dokument erwähnten grafischen Elemente bei Ihnen nicht angezeigt werden, z. B. Schaltflächen in Studio oder Designer, verfügen Sie unter Umständen nicht über die richtige Berechtigungsebene. Wenden Sie sich an Ihren Azure-Abonnementadministrator, um sich zu vergewissern, dass Ihnen die richtige Zugriffsebene gewährt wurde. Weitere Informationen finden Sie unter Verwalten von Benutzern und Rollen.
Verwenden von Beispielpipelines
Der Designer speichert eine Kopie der Beispielpipelines in Ihrem Studio-Arbeitsbereich. Sie können die Pipeline an Ihre Anforderungen anpassen und als eigene Pipeline speichern. Verwenden Sie sie als Ausgangspunkt, um Ihre Projekte zu beschleunigen.
So verwenden Sie ein Beispiel im Designer:
Melden Sie sich bei ml.azure.com an, und wählen Sie den gewünschten Arbeitsbereich aus.
Wählen Sie Designer aus.
Wählen Sie im Abschnitt Neue Pipeline eine Beispielpipeline aus.
Wählen Sie Mehr Stichproben anzeigen aus, um eine vollständige Liste mit Beispielen anzuzeigen.
Zum Ausführen einer Pipeline müssen Sie zuerst das Standardcomputeziel für die Pipelineausführung festlegen.
Wählen Sie rechts neben der Canvas im Bereich Einstellungen die Option Computeziel auswählen aus.
Wählen Sie im angezeigten Dialogfeld ein vorhandenes Computeziel aus, oder erstellen Sie ein neues. Wählen Sie Speichern aus.
Wählen Sie oben auf der Leinwand Senden aus, um einen Pipeline-Auftrag zu senden.
Abhängig von der Beispielpipeline und den Compute-Einstellungen kann es einige Zeit dauern, bis Jobs abgeschlossen sind. In den Standardcomputeeinstellungen ist eine minimale Knotengröße von 0 festgelegt. Das bedeutet, dass der Designer Ressourcen nach dem Leerlauf zuordnen muss. Wiederholte Pipeline-Aufträge nehmen weniger Zeit in Anspruch, da die Rechenressourcen bereits zugewiesen sind. Außerdem verwendet der Designer für jede Komponente zwischengespeicherte Ergebnisse, um die Effizienz weiter zu steigern.
Nach Abschluss der Pipelineausführung können Sie die Pipeline überprüfen und die Ausgabe der einzelnen Komponenten anzeigen, um weitere Informationen zu erhalten. Führen Sie die folgenden Schritte aus, um die Komponentenausgaben anzuzeigen:
- Klicken Sie auf der Canvas mit der rechten Maustaste auf die Komponente, deren Ausgabe Sie sehen möchten.
- Wählen Sie Visualisieren aus.
Verwenden Sie die Beispiele als Ausgangspunkt für einige der gängigsten Machine Learning-Szenarien.
Regression
Durchsuchen Sie diese integrierten Regressionsbeispiele.
| Beispieltitel | BESCHREIBUNG |
|---|---|
| Regression - Automobile Price Prediction (Basic) (Regression: Automobilpreisvorhersage (Standard)) | Dient zum Vorhersagen von Automobilpreisen mittels linearer Regression. |
| Regression - Automobile Price Prediction (Advanced) (Regression: Automobilpreisvorhersage (Erweitert)) | Dient zum Vorhersagen von Automobilpreisen mittels Entscheidungsstruktur und Boosted Decision Tree-Regressoren. Vergleichen Sie die Modelle, um den besten Algorithmus zu ermitteln. |
Klassifizierung
Durchsuchen Sie diese integrierten Klassifizierungsbeispiele. Sie können die Beispiele öffnen und sich die Komponentenkommentare im Designer ansehen, um mehr über die Beispiele zu erfahren.
| Beispieltitel | BESCHREIBUNG |
|---|---|
| Binary Classification with Feature Selection - Income Prediction (Binäre Klassifizierung mit Featureauswahl: Vorhersage des Einkommens) | Dient zum Vorhersagen des Einkommens (hoch oder gering) mittels Two-Class Boosted Decision Tree. Für die Featureauswahl wird die Pearson-Korrelation verwendet. |
| Binary Classification with custom Python script - Credit Risk Prediction (Binäre Klassifizierung mit benutzerdefiniertem Python-Skript: Vorhersage des Kreditrisikos) | Dient zum Klassifizieren des Risikos von Kreditanträgen (hoch oder gering). Zur Gewichtung Ihrer Daten wird die Komponente „Python-Skript ausführen“ verwendet. |
| Binary Classification - Customer Relationship Prediction (Binäre Klassifizierung: Vorhersage von Kundenbeziehungen) | Dient zum Vorhersagen der Kundenabwanderung mittels Two-Class Boosted Decision Tree. Für das Sampling verzerrter Daten wird SMOTE verwendet. |
| Text Classification - Wikipedia SP 500 Dataset (Textklassifizierung: Wikipedia SP 500-Dataset) | Dient zum Klassifizieren von Unternehmenstypen aus Wikipedia-Artikeln mittels logistischer Regression mit mehreren Klassen. |
| Klassifizierung mit mehreren Klassen: Buchstabenerkennung | Dient zum Erstellen eines Ensembles von binären Klassifizierern für die Klassifizierung geschriebener Buchstaben. |
Maschinelles Sehen
Durchsuchen Sie diese integrierten Beispiele für maschinelles Sehen. Sie können die Beispiele öffnen und sich die Komponentenkommentare im Designer ansehen, um mehr über die Beispiele zu erfahren.
| Beispieltitel | BESCHREIBUNG |
|---|---|
| Bildklassifizierung mithilfe von DenseNet | Verwenden Sie Komponenten für maschinelles Sehen zum Erstellen eines Bildklassifizierungsmodells, das auf PyTorch DenseNet basiert. |
Empfehlung (Recommender)
Durchsuchen Sie diese integrierten Empfehlungsbeispiele. Sie können die Beispiele öffnen und sich die Komponentenkommentare im Designer ansehen, um mehr über die Beispiele zu erfahren.
| Beispieltitel | Beschreibung |
|---|---|
| Wide & Deep based Recommendation - Restaurant Rating Prediction (Auf Wide & Deep basierende Empfehlung: Vorhersage einer Restaurantbewertung) | Erstellen Sie eine Engine für Restaurantempfehlungen aus Features und Bewertungen von Restaurants und Benutzern. |
| Empfehlung: Filmbewertungstweets | Dient zum Erstellen einer Filmempfehlungsengine auf der Grundlage von Merkmalen und Bewertungen von Filmen und Benutzern. |
Hilfsprogramm
Hier finden Sie weitere Informationen zu den Beispielen, mit denen ML-Hilfsprogramme und -Features veranschaulicht werden. Sie können die Beispiele öffnen und sich die Komponentenkommentare im Designer ansehen, um mehr über die Beispiele zu erfahren.
| Beispieltitel | BESCHREIBUNG |
|---|---|
| Binary Classification using Vowpal Wabbit Model - Adult Income Prediction (Binäre Klassifizierung mithilfe des Vowpal Wabbit-Modells: Vorhersage des Einkommens von Erwachsenen) | Vowpal Wabbit ist ein Machine Learning-System, das die Grenzen von maschinellem Lernen weiter hinausschiebt und dazu verschiedene Verfahren einsetzt, wie z. B. Online, Hashing, Allreduce, Reductions, Learning2Search, Active und Interactive Learning. Dieses Beispiel zeigt, wie das Vowpal Wabbit-Modell verwendet wird, um ein binäres Klassifizierungsmodell zu erstellen. |
| Use custom R script - Flight Delay Prediction (Verwenden eines benutzerdefinierten R-Skripts: Vorhersage von Flugverspätungen) | Verwenden Sie das angepasste R-Skript, um vorherzusagen, ob ein geplanter Passagierflug mehr als 15 Minuten verspätet sein wird. |
| Kreuzvalidierung für binäre Klassifizierung: Vorhersage des Einkommens von Erwachsenen | Dient zum Erstellen eines binären Klassifizierers für das Einkommen von Erwachsenen mittels Kreuzvalidierung. |
| Permutation Feature Importance (PFI) | Dient zum Berechnen von Wichtigkeitsbewertungen für das Testdataset mittels Permutation Feature Importance. |
| Optimierungsparameter für binäre Klassifizierung: Vorhersage des Einkommens von Erwachsenen | Dient zum Ermitteln optimaler Hyperparameter für die Erstellung eines binären Klassifizierers unter Verwendung von „Tune Model Hyperparameters“. |
Datasets
Beim Erstellen einer neuen Pipeline in Azure Machine Learning-Designer ist eine Reihe von Beispieldatasets standardmäßig enthalten. Diese Beispieldatasets werden von den Beispielpipelines auf der Designerstartseite verwendet.
Die Beispieldatasets sind unter der Kategorie Datasets-Beispiele verfügbar. Sie finden diese in der Komponentenpalette links von der Canvas im Designer. Sie können alle diese Datasets für Ihre eigene Pipeline verwenden, indem Sie sie auf die Canvas ziehen.
| Datasetname | Datasetbeschreibung |
|---|---|
| Dataset "Adult Census Income Binary Classification" | Eine Teilmenge der Volkszählungsdatenbank von 1994, die arbeitende Erwachsene (älter als 16 Jahre) mit einem bereinigten Einkommensindex von > 100 verwendet. Verwendung: Klassifizierung von Personen mithilfe von demografischen Daten für die Vorhersage, ob eine Person mehr als 50.000 pro Jahr verdient. Zugrunde liegende Untersuchungen: Kohavi, R., Becker, B., (1996). UCI Machine Learning Repository. Irvine, CA: University of California, School of Information and Computer Science |
| Automobile price data (Raw) | Informationen zu Automobilen nach Marke und Modell, einschließlich Preis und Merkmalen wie Zylinderanzahl und Verbrauch sowie einer Risikoeinstufung der Versicherung. Der Risikobewertung ist anfänglich mit dem Fahrzeugpreis verknüpft. Sie wird dann in einem Prozess, den Versicherungsfachleute als „Symbolisierung“ bezeichnen, an das tatsächliche Risiko angepasst. Der Wert +3 weist auf ein Fahrzeug mit hohem Risiko hin, während der Wert -3 auf ein voraussichtlich sicheres Fahrzeug hinweist. Verwendung: Vorhersage der Risikoeinstufung nach Merkmalen unter Verwendung der Regression oder multivariaten Klassifizierung. Zugrunde liegende Untersuchungen: Schlimmer, J.C. (1987). UCI Machine Learning Repository. Irvine, CA: University of California, School of Information and Computer Science |
| CRM Appetency Bezeichnungen freigegeben | Beschriftungen vom KDD Cup 2009 (Kundenbeziehungsprognose, orange_small_train_appetency.labels). |
| CRM Codeänderung Bezeichnungen freigegeben | Beschriftungen vom KDD Cup 2009 (Kundenbeziehungsprognose, orange_small_train_churn.labels). |
| CRM-Dataset gemeinsam genutzt | Diese Daten stammen vom KDD Cup 2009, Kundenbeziehungsprognose (orange_small_train.data.zip). Das DataSet enthält 50.000 Kunden des französischen Telekommunikationsunternehmens Orange. Jeder Kunde verfügt über 230 anonymisierte Merkmale, von denen 190 numerisch und 40 kategorisch sortiert sind. Die Merkmale sind sehr karg. |
| CRM Upselling Bezeichnungen freigegeben | Beschriftungen vom KDD Cup 2009 (Kundenbeziehungsprognose, orange_large_train_upselling.labels |
| Flugverspätungsdaten | Pünktlichkeitsratendaten zu Passagierflügen aus der TranStats-Datensammlung des US-Verkehrsministeriums (On-Time). Das DataSet deckt den Zeitraum April bis Oktober 2013 ab. Das Dataset wurde vor dem Hochladen im Designer wie folgt verarbeitet: - Das Dataset wurde gefiltert, damit nur die 70 verkehrsreichsten Flughäfen in Kontinental-USA enthalten waren - Ausgefallene Flüge wurden als um mehr als 15 Minuten verspätet gekennzeichnet. - Umgeleitete Flüge wurden herausgefiltert. - Folgende Spalten wurden ausgewählt: Year, Month, DayofMonth, DayOfWeek, Carrier, OriginAirportID, DestAirportID, CRSDepTime, DepDelay, DepDel15, CRSArrTime, ArrDelay, ArrDel15, Canceled |
| Deutsche Kreditkarte UCI-Dataset | Das DataSet „UCI Statlog“ (deutsche Kreditkarte) (Statlog+German+Credit+Data), das die Datei „german.data“ verwendet. Dieses DataSet klassifiziert Personen anhand verschiedener Attribute in hohes und niedriges Kreditrisiko. Jedes Beispiel stellt eine Person dar. Insgesamt existieren 20 numerische und kategorische Merkmale sowie eine binäre Beschriftung (der Wert für das Kreditrisiko). Hohe Kreditrisiken tragen die Beschriftung = 2, während geringe Kreditrisiken die Beschriftung = 1 tragen. Die Belastung für die falsche Klassifizierung eines Beispiels mit geringem Risiko beträgt 1, während die Belastung für die falsche Klassifizierung eines Beispiels mit hohem Risiko 5 beträgt. |
| IMDB-Filmtitel | Das Dataset enthält Informationen über Filme, die in Tweets auf Twitter bewertet wurden: Film-ID in der IMDB, Filmname, Genre und Produktionsjahr. Das DataSet enthält 17.000 Filme. Das Dataset wurde im Dokument „S. Dooms, T. De Pessemier und L. Martens. MovieTweetings: a Movie Rating Dataset Collected From Twitter. Workshop on Crowdsourcing and Human Computation for Recommender Systems, CrowdRec at RecSys 2013“ eingeführt. |
| Filmbewertungen | Das Dataset ist eine erweiterte Version des Films Tweetings Datasets. Das Dataset enthält 170K Bewertungen für Filme, extrahiert aus gut strukturierten Tweets auf Twitter. Jede Instanz stellt einen Tweet dar und ist ein Tupel: Benutzer-ID, IMDB Film-ID, Bewertung, Timestamp, Anzahl von Favoriten für diesen Tweet und Anzahl der Retweets dieses Tweets. Das Dataset wurde von A. Said, S. Dooms, B. Loni und D. Tikk für Recommender Systems Challenge 2014 zur Verfügung gestellt. |
| Wetter-Dataset | Stündliche flächenbasierte Wetterbeobachtungen aus NOAA (zusammengeführte Daten von 201304 bis 201310). Die Wetterdaten umfassen Beobachtungen der Wetterstationen von Flughäfen für den Zeitraum April bis Oktober 2013. Das Dataset wurde vor dem Hochladen im Designer wie folgt verarbeitet: - Die IDs der Wetterstationen wurden den entsprechenden Flughafen-IDs zugeordnet - Wetterstationen, die nicht zu den 70 verkehrsreichsten Flughäfen gehören, wurden herausgefiltert - Die Datumsspalte wurde in separate Jahres-, Monats- und Tagesspalten aufgeteilt - Folgende Spalten wurden ausgewählt: AirportID, Year, Month, Day, Time, TimeZone, SkyCondition, Visibility, WeatherType, DryBulbFarenheit, DryBulbCelsius, WetBulbFarenheit, WetBulbCelsius, DewPointFarenheit, DewPointCelsius, RelativeHumidity, WindSpeed, WindDirection, ValueForWindCharacter, StationPressure, PressureTendency, PressureChange, SeaLevelPressure, RecordType, HourlyPrecip, Altimeter |
| Wikipedia SP 500 Dataset | Die Daten stammen aus Wikipedia (https://www.wikipedia.org/) und basieren auf Artikeln der einzelnen S&P-500-Unternehmen, die als XML-Daten gespeichert wurden. Das Dataset wurde vor dem Hochladen im Designer wie folgt verarbeitet: - Extrahieren der Textinhalte für die einzelnen Unternehmen - Entfernen der Wiki-Formatierung - Entfernen aller nicht alphanumerischen Zeichen - Konvertieren sämtlicher Texte in Kleinbuchstaben - Bekannte Firmenkategorien wurden hinzugefügt Beachten Sie, dass für einige Unternehmen keine Artikel gefunden werden konnten, daher ist die Anzahl der Datensätze kleiner als 500. |
| Daten zu Restaurantmerkmalen | Eine Sammlung von Metadaten zu Restaurants und ihren Merkmalen wie Speisetyp, Stil und Lage. Verwendung: Verwenden Sie dieses Dataset in Kombination mit den anderen beiden Restaurantdatasets, um ein Empfehlungssystem zu trainieren und zu testen. Zugrunde liegende Untersuchungen: Bache, K. und Lichman, M. (2013). UCI Machine Learning Repository. Irvine, CA: University of California, School of Information and Computer Science |
| Restaurantbewertungen | Enthält von Benutzern abgegebene Bewertungen für Restaurants auf einer Skala von 0 bis 2. Verwendung: Verwenden Sie dieses Dataset in Kombination mit den anderen beiden Restaurantdatasets, um ein Empfehlungssystem zu trainieren und zu testen. Zugrunde liegende Untersuchungen: Bache, K. und Lichman, M. (2013). UCI Machine Learning Repository. Irvine, CA: University of California, School of Information and Computer Science |
| Daten zu Restaurantkunden | Eine Sammlung von Metadaten zu Kunden, einschließlich Demografie und Präferenzen. Verwendung: Verwenden Sie dieses Dataset in Kombination mit den anderen beiden Restaurantdatasets, um ein Empfehlungssystem zu trainieren und zu testen. Zugrunde liegende Untersuchungen: Bache, K. und Lichman, M. (2013). UCI Machine Learning Repository Irvine, CA: University of California, School of Information and Computer Science |
Bereinigen von Ressourcen
Wichtig
Sie können die von Ihnen bei der Vorbereitung erstellten Ressourcen auch in anderen Tutorials und Anleitungen für Azure Machine Learning verwenden.
Alles löschen
Wenn Sie die erstellten Ressourcen nicht mehr benötigen, löschen Sie die gesamte Ressourcengruppe, damit Ihnen keine Kosten entstehen.
Wählen Sie im Azure-Portal links im Fenster Ressourcengruppen aus.
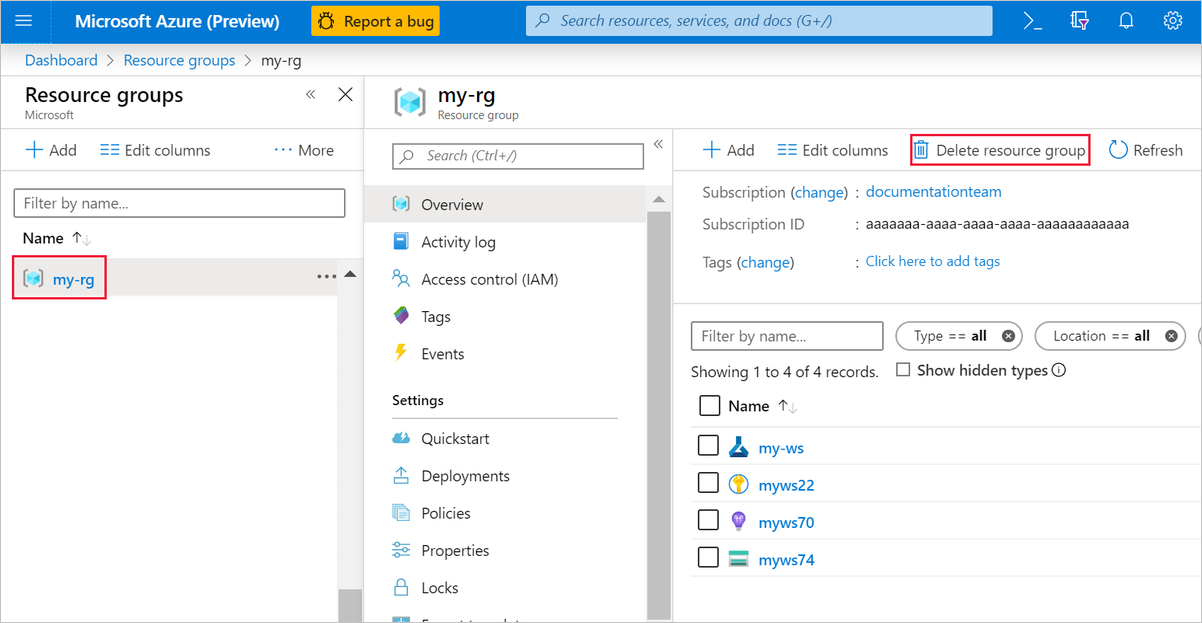
Wählen Sie in der Liste die Ressourcengruppe aus, die Sie erstellt haben.
Klicken Sie auf Ressourcengruppe löschen.
Durch das Löschen einer Ressourcengruppe werden auch alle im Designer erstellten Ressourcen gelöscht.
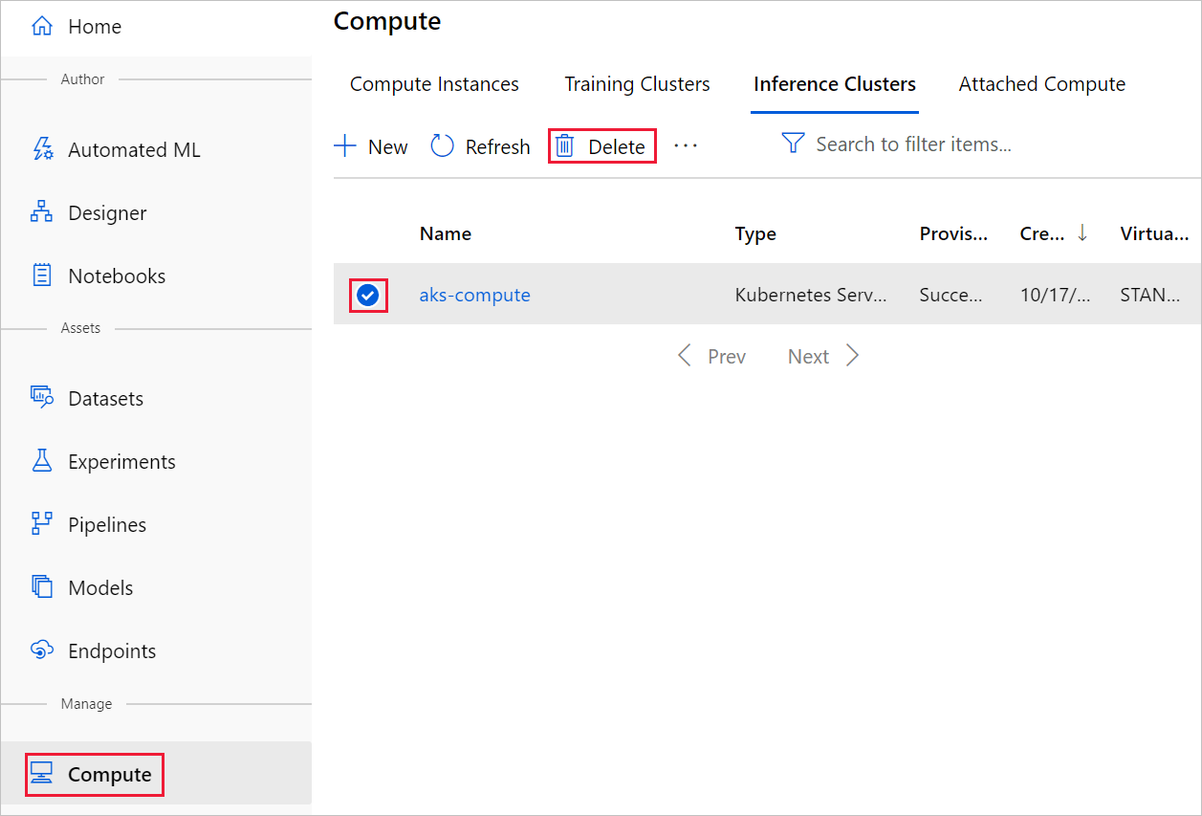
Löschen einzelner Objekte
In dem Designer, in dem Sie Ihr Experiment erstellt haben, können Sie einzelne Ressourcen löschen, indem Sie erst die gewünschten Ressourcen und dann die Schaltfläche Löschen auswählen.
Das hier erstellte Computeziel wird automatisch auf null Knoten skaliert, wenn es nicht verwendet wird. Diese Aktion wird durchgeführt, um Gebühren zu minimieren. Wenn Sie das Computeziel löschen möchten, führen Sie die folgenden Schritte aus:
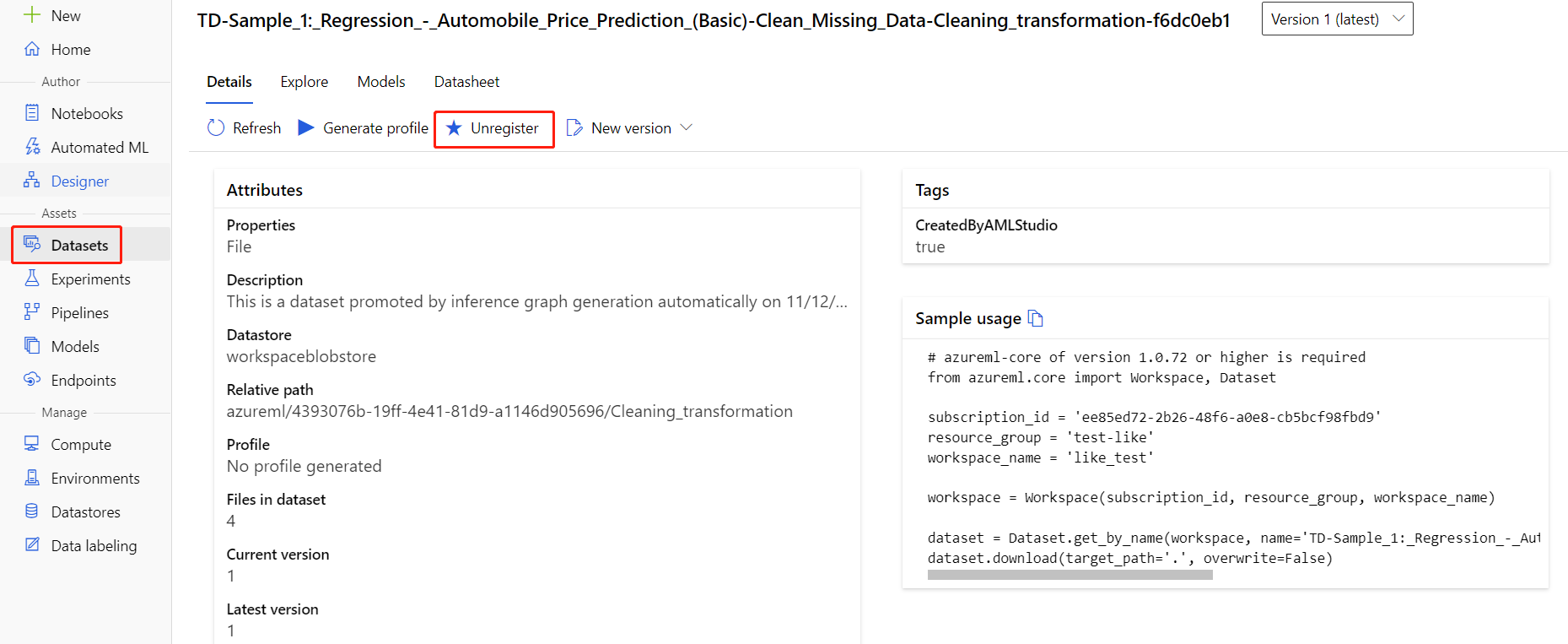
Die Registrierung von Datasets im Arbeitsbereich kann aufgehoben werden, indem Sie die einzelnen Datasets und anschließend Registrierung aufheben auswählen.
Zum Löschen eines Datasets wechseln Sie im Azure-Portal oder Azure Storage-Explorer zum Speicherkonto, und löschen Sie diese Ressourcen manuell.
Nächste Schritte
Die Grundlagen von Predictive Analytics und maschinellem Lernen werden hier erläutert: Tutorial: Prognostizieren von Automobilpreisen mit dem Designer.