Integration von Prompt Flow mit LLM-basierten Anwendungs-DevOps
In diesem Artikel erfahren Sie mehr über die Integration des Eingabeaufforderungsflows in LLM-basierten DevOps-Anwendungen in Azure Machine Learning. Der Eingabeaufforderungsflow bietet eine entwickler- und benutzerfreundliche Code-First-Erfahrung für die Flowentwicklung und -iterierung mit Ihrem gesamten LLM-basierten Anwendungsentwicklungsworkflow.
Es bietet ein Eingabeaufforderungsflow-SDK und eine CLI, eine VS-Codeerweiterung und die neue Benutzeroberfläche des Flowordner-Explorers, um die lokale Entwicklung von Flows, das lokale Auslösen von Flowausführungen und Auswertungsausführungen sowie den Übergang von Flows von lokalen zu Cloudumgebungen (Azure Machine Learning-Arbeitsbereich) zu erleichtern.
In dieser Dokumentation geht es darum, wie Sie die Funktionen der Eingabeaufforderungsflow-Codeerfahrung und von DevOps effektiv kombinieren, um Ihre LLM-basierten Workflows für die Anwendungsentwicklung zu verbessern.

Einführung der „Code-first“-Erfahrung im Prompt Flow
Bei der Entwicklung von Anwendungen mit LLM ist es üblich, einen standardisierten Anwendungsentwicklungsprozess zu verwenden, der Coderepositorys und CI/CD-Pipelines umfasst. Diese Integration ermöglicht einen optimierten Entwicklungsprozess, Versionskontrolle und Zusammenarbeit zwischen Teammitgliedern.
Entwickler mit Erfahrung in der Code-Entwicklung, die einen effizienteren LLMOps-Iterationsprozess anstreben, können von den folgenden Schlüsselfunktionen und Vorteilen der Eingabeaufforderungsflow-Codeerfahrung profitieren:
- Flowversionsverwaltung im Coderepository. Sie können Ihren Flow im YAML-Format definieren, das an den Quelldateien, auf die verwiesen wird, in einer Ordnerstruktur ausgerichtet bleiben kann.
- Integrieren der Flowausführung in die CI/CD-Pipeline. Sie können Flowausführungen mit der CLI oder dem SDK für den Eingabeaufforderungsflow auslösen, die nahtlos in Ihre CI/CD-Pipeline und Ihren Übermittlungsprozess integriert werden können.
- Reibungsloser Übergang von lokal zur Cloud. Sie können Ihren Flowordner für die Versionskontrolle, lokale Entwicklung und Freigabe ganz einfach in Ihr lokales oder Cloudrepository exportieren. Auf ähnliche Weise kann der Flowordner mühelos zurück in die Cloud importiert werden, um weitere Erstellungen, Tests und Bereitstellungen in Cloudressourcen durchzuführen.
Zugreifen auf die Codedefinition des Eingabeaufforderungsflows
Jedem Eingabeaufforderungsflow ist eine Flowordnerstruktur zugeordnet, die wichtige Dateien zum Definieren des Flows in der Codeordnerstruktur enthält. Diese Ordnerstruktur organisiert Ihren Flow und ermöglicht reibungslosere Übergänge.
Azure Machine Learning bietet ein freigegebenes Dateisystem für alle Arbeitsbereichsbenutzer. Beim Erstellen eines Flows wird automatisch ein entsprechender Flowordner generiert und dort gespeichert, der sich im Verzeichnis Users/<username>/promptflow befindet.

Flowordnerstruktur
Übersicht über die Flowordnerstruktur und die darin enthaltenen Schlüsseldateien:
- flow.dag.yaml: Diese primäre Flowdefinitionsdatei im YAML-Format enthält Informationen zu Eingaben, Ausgaben, Knoten, Tools und Varianten, die im Flow verwendet werden. Sie ist für die Erstellung und Definition des Eingabeaufforderungsflows von wesentlicher Bedeutung.
- Quellcodedateien (.py, .jinja2): Der Flowordner enthält auch vom Benutzer verwaltete Quellcodedateien, auf die von den Tools/Knoten im Flow verwiesen wird.
- Auf Dateien im Python-Format (.py) kann das Python-Tool zum Definieren benutzerdefinierter Python-Logik verweisen.
- Das Eingabeaufforderungstool oder das LLM-Tool zum Definieren des Eingabeaufforderungskontexts kann auf Dateien im Jinja 2-Format (.jinja2) verweisen.
- Nicht-Quelldateien: Der Flowordner kann auch Nicht-Quelldateien enthalten, z. B. Hilfsprogrammdateien und Datendateien, die in den Quelldateien enthalten sein können.
Nachdem der Flow erstellt wurde, können Sie zur Flow-Erstellungsseite navigieren, um die Flowdateien im richtigen Datei-Explorer anzuzeigen und zu betreiben. Dadurch können Sie Ihre Dateien anzeigen, bearbeiten und verwalten. Alle an den Dateien vorgenommenen Änderungen werden direkt im Dateifreigabespeicher wiedergegeben.

Wenn der „Rohdatenmodus“ aktiviert ist, können Sie den Rohinhalt der Dateien im Datei-Editor anzeigen und bearbeiten, einschließlich der Flowdefinitionsdatei flow.dag.yaml und der Quelldateien.


Alternativ können Sie direkt im Azure Machine Learning-Notebook auf alle Flowordner zugreifen.

Versionsverwaltung des Eingabeaufforderungsflows im Code-Repository
Um Ihren Flow in Ihr Coderepository einzuchecken, können Sie den Flowordner ganz einfach von der Flowerstellungsseite in Ihr lokales System exportieren. Dadurch wird ein Paket mit allen Dateien aus dem Explorer auf Ihren lokalen Computer heruntergeladen, das Sie dann in Ihr Coderepository einchecken können.

Weitere Informationen zur DevOps-Integration in Azure Machine Learning finden Sie unter Git-Integration in Azure Machine Learning.
Übermitteln von Ausführungen aus dem lokalen Repository an die Cloud
Voraussetzungen
Schließen Sie den Abschnitt Ressourcen erstellen, um loszulegen ab, wenn Sie noch keinen Azure Machine Learning-Arbeitsbereich haben.
Eine Python-Umgebung, in der Sie Azure Machine Learning Python SDK v2 installiert haben – Installationsanleitungen. Diese Umgebung dient der Definition und Steuerung Ihrer Azure Machine Learning-Ressourcen und ist von der zur Laufzeit verwendeten Umgebung getrennt. Weitere Informationen finden Sie unter Laufzeitverwaltung für Prompt Flow Engineering.
Installieren des Eingabeaufforderungsflow-SDK
pip install -r ../../examples/requirements.txt
Herstellen einer Verbindung mit einem Azure Machine Learning-Arbeitsbereich
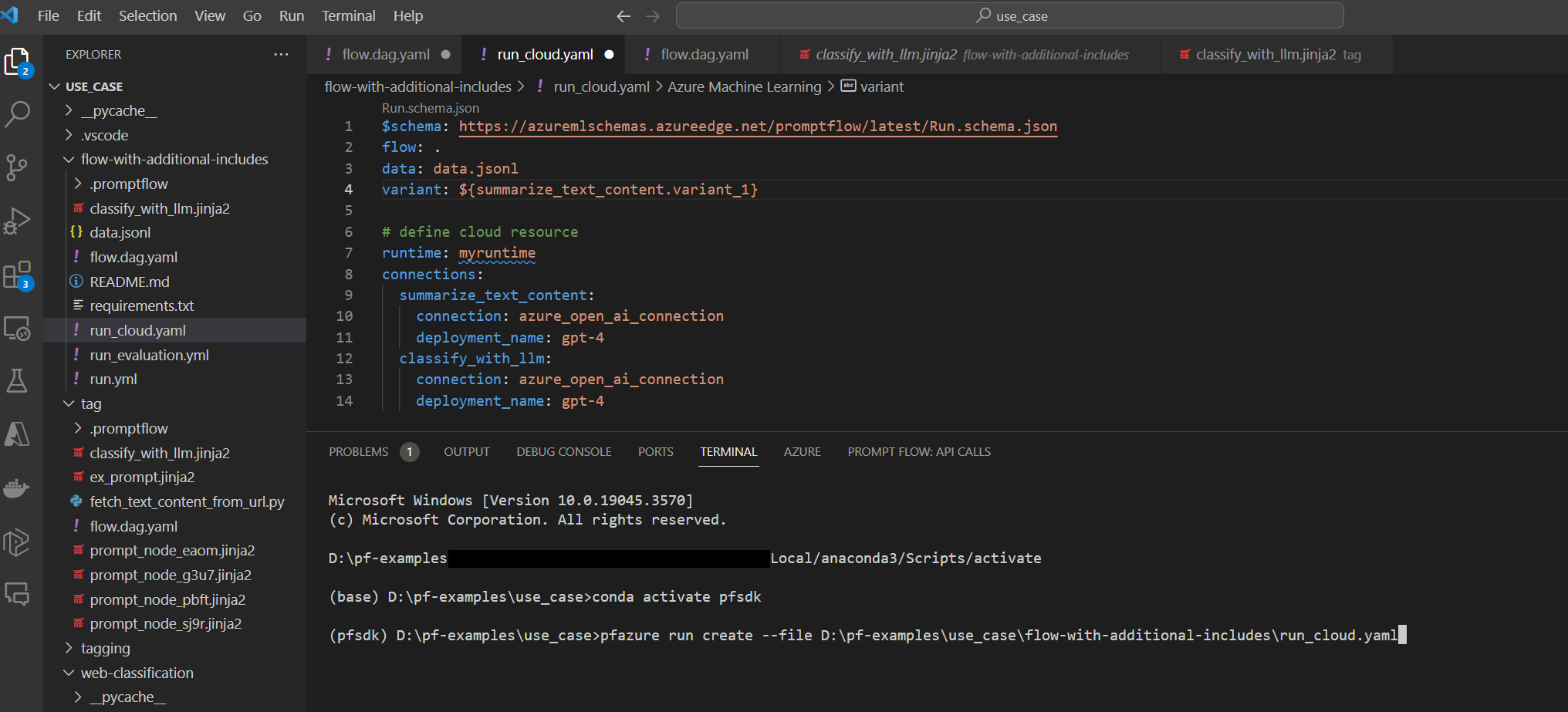
Bereiten Sie run.yml vor, um die Konfiguration für diesen Flow in der Cloud zu definieren.
$schema: https://azuremlschemas.azureedge.net/promptflow/latest/Run.schema.json
flow: <path_to_flow>
data: <path_to_flow>/data.jsonl
column_mapping:
url: ${data.url}
# define cloud resource
# if omitted, it will use the automatic runtime, you can also specify the runtime name, specify automatic will also use the automatic runtime.
runtime: <runtime_name>
# define instance type only work for automatic runtime, will be ignored if you specify the runtime name.
# resources:
# instance_type: <instance_type>
# overrides connections
connections:
classify_with_llm:
connection: <connection_name>
deployment_name: <deployment_name>
summarize_text_content:
connection: <connection_name>
deployment_name: <deployment_name>
Sie können den Verbindungs- und Bereitstellungsnamen für jedes Tool im Flow angeben. Wenn Sie den Verbindungs- und Bereitstellungsnamen nicht angeben, wird die eine Verbindung und Bereitstellung in der Datei flow.dag.yaml verwendet. So formatieren Sie Verbindungen:
...
connections:
<node_name>:
connection: <connection_name>
deployment_name: <deployment_name>
...
pfazure run create --file run.yml
Bereiten Sie run_evaluation.yml vor, um die Konfiguration für diesen Evaluierungsflow in der Cloud zu definieren.
$schema: https://azuremlschemas.azureedge.net/promptflow/latest/Run.schema.json
flow: <path_to_flow>
data: <path_to_flow>/data.jsonl
run: <id of web-classification flow run>
column_mapping:
groundtruth: ${data.answer}
prediction: ${run.outputs.category}
# define cloud resource
# if omitted, it will use the automatic runtime, you can also specify the runtime name, specif automatic will also use the automatic runtime.
runtime: <runtime_name>
# define instance type only work for automatic runtime, will be ignored if you specify the runtime name.
# resources:
# instance_type: <instance_type>
# overrides connections
connections:
classify_with_llm:
connection: <connection_name>
deployment_name: <deployment_name>
summarize_text_content:
connection: <connection_name>
deployment_name: <deployment_name>
pfazure run create --file run_evaluation.yml
Anzeigen von Ausführungsergebnissen im Azure Machine Learning-Arbeitsbereich
Die Übermittlung der Ablaufausführung an die Cloud gibt die Portal-URL der Ausführung zurück. Sie können die URI-Ansicht der Ausführungsergebnisse im Portal öffnen.
Sie können auch den folgenden Befehl verwenden, um Ergebnisse für Ausführungen anzuzeigen.
Streamen der Protokolle
pfazure run stream --name <run_name>
Anzeigen von Ausführungsausgaben
pfazure run show-details --name <run_name>
Anzeigen von Metriken der Auswertungsausführung
pfazure run show-metrics --name <evaluation_run_name>
Wichtig
Weitere Informationen finden Sie in der Prompt Flow CLI-Dokumentation für Azure.
Iterative Entwicklung durch Feinabstimmung
Lokale Entwicklung und Tests
Während der iterativen Entwicklung, wenn Sie Ihre Flows oder Eingabeaufforderungen verfeinern und feinabstimmen, kann es von Vorteil sein, mehrere Iterationen lokal in Ihrem Coderepository durchzuführen. Die Community-Version, VS Code-Erweiterung für Promptflows und das lokale SDK und die lokale CLI für Promptflows werden bereitgestellt, um die rein lokale Entwicklung und das Testen ohne Azure-Anbindung zu erleichtern.
VS Code-Erweiterung für den Eingabeaufforderungsflow
Wenn Sie die Prompt Flow VS Code-Erweiterung installiert haben, können Sie Ihren Flow ganz einfach lokal im VS Code-Editor verfassen und so eine ähnliche Benutzeroberfläche wie in der Cloud nutzen.
So verwenden Sie die Erweiterung:
- Öffnen Sie einen Eingabeaufforderungsflowordner in VS Code Desktop.
- Öffnen Sie die Datei „flow.dag.yaml“ in der Notebookansicht.
- Verwenden Sie den visuellen Editor, um alle erforderlichen Änderungen an Ihrem Flow vorzunehmen, z. B. Optimieren der Eingabeaufforderungen in Varianten oder Hinzufügen weiterer Tools.
- Um ihren Flow zu testen, wählen Sie oben im visuellen Editor die Schaltfläche Flow ausführen aus. Dadurch wird ein Flowtest ausgelöst.

Lokales SDK und lokale CLI für Promptflows
Wenn Sie Jupyter, PyCharm, Visual Studio oder andere IDEs lieber verwenden möchten, können Sie die YAML-Definition direkt in der Datei flow.dag.yaml ändern.

Sie können dann einen einzelnen Durchlauf zum Testen auslösen, indem Sie entweder die Prompt Flow CLI oder das SDK verwenden.
Angenommen, Sie befinden sich im Arbeitsverzeichnis <path-to-the-sample-repo>/examples/flows/standard/
pf flow test --flow web-classification # "web-classification" is the directory name


Dadurch können Sie Änderungen schnell vornehmen und testen, ohne jedes Mal das Standard-Coderepository aktualisieren zu müssen. Sobald Sie mit den Ergebnissen Ihrer lokalen Tests zufrieden sind, können Sie die Ausführungen vom lokalen Repository in die Cloud übertragen, um dort Experimente durchzuführen.
Weitere Details und Anleitungen zur Verwendung der lokalen Versionen finden Sie in der prompt flow GitHub Community.
Zurück zur Studio-Benutzeroberfläche für fortlaufende Entwicklung
Alternativ haben Sie die Möglichkeit, zur Studio-Benutzeroberfläche zurückzukehren, indem Sie die Cloudressourcen und -benutzeroberfläche verwenden, um Änderungen an Ihrem Flow auf der Flowerstellungsseite vorzunehmen.
Um weiter zu entwickeln und mit der aktuellsten Version der Flowdateien zu arbeiten, können Sie auf das Terminal im Notebook zugreifen und die neuesten Änderungen der Flowdateien aus Ihrem Repository abrufen.
Wenn Sie es vorziehen, weiterhin auf der Studio-Benutzeroberfläche zu arbeiten, können Sie außerdem einen lokalen Flowordner direkt als neuen Entwurfsflow importieren. Dadurch können Sie nahtlos zwischen lokaler und Cloudentwicklung wechseln.

CI/CD-Integration
CI: Auslösen von Flowausführungen in der CI-Pipeline
Nachdem Sie Ihren Flow erfolgreich entwickelt und getestet und als erste Version eingecheckt haben, sind Sie bereit für die nächste Optimierungs- und Testiteration. In diesem Stadium können Sie mithilfe der Prompt Flow CLI Ablaufläufe, einschließlich Batch-Tests und Evaluierungsläufe, auslösen. Dies kann als automatisierter Workflow in Ihrer Continuous Integration(CI)-Pipeline dienen.
Während des gesamten Lebenszyklus Ihrer Flowiterationen können mehrere Vorgänge automatisiert werden:
- Prompt Flow nach einem Pull Request ausführen
- Ausführen einer Promptflowauswertung, um hochwertige Ergebnisse sicherzustellen
- Registrieren von Promptflowmodellen
- Bereitstellung von Promptflowmodellen
Eine umfassende Anleitung für eine End-to-End-MLOps-Pipeline, die einen Webklassifizierungs-Flow ausführt, finden Sie unter Einrichten von End-to-End-LLMOps mit Prompt Flow und GitHub und dem GitHub-Demoprojekt.
CD: Continuous Deployment
Der letzte Schritt für die Produktion besteht darin, Ihren Flow als Onlineendpunkt in Azure Machine Learning bereitzustellen. Dadurch können Sie Ihren Flow in Ihre Anwendung integrieren und für die Verwendung zur Verfügung stellen.
Weitere Informationen zum Bereitstellen Ihres Flows finden Sie unter Bereitstellen von Flows für einen verwalteten Azure Machine Learning-Onlineendpunkt für Rückschlüsse in Echtzeit mit CLI und SDK.
Zusammenarbeit an der Flussentwicklung in der Produktion
Im Zusammenhang mit der Entwicklung einer LLM-basierten Anwendung mit zeitnahem Ablauf ist die Zusammenarbeit zwischen den Teammitgliedern oft unerlässlich. Teammitglieder können an der gleichen Ablauferstellung und -tests beteiligt sein, an verschiedenen Facetten des Flusses arbeiten oder iterative Änderungen und Verbesserungen gleichzeitig vornehmen.
Diese Zusammenarbeit erfordert einen effizienten und optimierten Ansatz für die Freigabe von Code, das Nachverfolgen von Änderungen, das Verwalten von Versionen und die Integration dieser Änderungen in das endgültige Projekt.
Die Einführung des Prompt Flow SDK/CLI und der Visual Studio Code Extension als Teil der Code-Erfahrung von Prompt Flow erleichtert die Zusammenarbeit bei der Flow-Entwicklung innerhalb Ihres Code-Repositorys. Es ist ratsam, ein cloudbasiertes Code-Repository wie GitHub oder Azure DevOps zu verwenden, um Änderungen nachzuverfolgen, Versionen zu verwalten und diese Änderungen in das endgültige Projekt zu integrieren.
Bewährte Methode für die gemeinsame Entwicklung
Erstellen und einzelnes Testen Ihres Flusses lokal – Code-Repository und VSC-Erweiterung
- Der erste Schritt dieses kollaborativen Prozesses besteht in der Verwendung eines Code-Repositorys als Basis für Ihren Projektcode, der auch den Prompt-Flow-Code enthält.
- Dieses zentrale Repository ermöglicht eine effiziente Organisation, das Nachverfolgen aller Codeänderungen und die Zusammenarbeit zwischen Teammitgliedern.
- Nachdem das Repository eingerichtet wurde, können Teammitglieder die VSC-Erweiterung für die lokale Erstellung und einzelne Eingabetests des Flows nutzen.
- Diese standardisierte integrierte Entwicklungsumgebung fördert die Zusammenarbeit zwischen mehreren Mitgliedern, die an verschiedenen Aspekten des Flusses arbeiten.

- Diese standardisierte integrierte Entwicklungsumgebung fördert die Zusammenarbeit zwischen mehreren Mitgliedern, die an verschiedenen Aspekten des Flusses arbeiten.
- Der erste Schritt dieses kollaborativen Prozesses besteht in der Verwendung eines Code-Repositorys als Basis für Ihren Projektcode, der auch den Prompt-Flow-Code enthält.
Cloud-basierte experimentelle Batch-Tests und -Bewertung - Prompt Flow CLI/SDK und Workspace Portal UI
- Nach der lokalen Entwicklungs- und Testphase können Flowentwickler die pfazure CLI oder das SDK verwenden, um Batchläufe und Auswertungsläufe von den lokalen Flussdateien an die Cloud zu übermitteln.
- Diese Aktion bietet eine Möglichkeit für die Nutzung von Cloudressourcen, Ergebnisse dauerhaft und effizient mit einer Portal-UI im Azure Machine Learning-Arbeitsbereich zu speichern. Dieser Schritt ermöglicht den Cloudressourcenverbrauch, einschließlich Compute und Speicher, und einen weiteren Endpunkt für Bereitstellungen.
- Diese Aktion bietet eine Möglichkeit für die Nutzung von Cloudressourcen, Ergebnisse dauerhaft und effizient mit einer Portal-UI im Azure Machine Learning-Arbeitsbereich zu speichern. Dieser Schritt ermöglicht den Cloudressourcenverbrauch, einschließlich Compute und Speicher, und einen weiteren Endpunkt für Bereitstellungen.
- Nach der Übermittlung an die Cloud können die Teammitglieder auf die Benutzeroberfläche des Cloud-Portals zugreifen, um die Ergebnisse anzuzeigen und die Experimente effizient zu verwalten.
- Dieser Cloudarbeitsbereich bietet einen zentralen Ort zum Sammeln und Verwalten aller Ausführungsverlaufsprotokolle, Protokolle, Momentaufnahmen, umfassender Ergebnisse, einschließlich der Eingaben und Ausgaben auf Instanzebene.

- In der Ausführungsliste, in der alle Ausführungshistorien während der Entwicklung aufgezeichnet werden, können Teammitglieder die Ergebnisse verschiedener Läufe problemlos vergleichen und dabei die Qualitätsanalyse unterstützen und notwendige Anpassungen vornehmen.


- Dieser Cloudarbeitsbereich bietet einen zentralen Ort zum Sammeln und Verwalten aller Ausführungsverlaufsprotokolle, Protokolle, Momentaufnahmen, umfassender Ergebnisse, einschließlich der Eingaben und Ausgaben auf Instanzebene.
- Nach der lokalen Entwicklungs- und Testphase können Flowentwickler die pfazure CLI oder das SDK verwenden, um Batchläufe und Auswertungsläufe von den lokalen Flussdateien an die Cloud zu übermitteln.
Lokale iterative Entwicklung oder Bereitstellung einer einzelnen Benutzeroberfläche für die Produktion
- Nach der Analyse von Experimenten können Teammitglieder zur weiteren Entwicklung und Feinabstimmung zum Code-Repository zurückkehren. Nachfolgende Ausführungen können dann iterativ an die Cloud übermittelt werden.
- Dieser iterative Ansatz sorgt für eine konsistente Verbesserung, bis das Team mit der Qualität zufrieden ist, die für die Produktion bereit ist.
- Sobald das Team voll auf die Qualität des Flusses vertraut ist, kann es nahtlos über einen Benutzeroberflächen-Assistenten als Onlineendpunkt in Azure Machine Learning bereitgestellt werden. Sobald das Team völlig sicher in der Qualität des Flusses ist, kann es nahtlos über einen Assistenten zur Bereitstellung der Benutzeroberfläche als Online-Endpunkt in einer robusten Cloudumgebung in die Produktion überstellt werden.
- Diese Bereitstellung auf einem Onlineendpunkt kann auf einer Momentaufnahme der Ausführung basieren, sodass stabile und sichere Bereitstellung, weitere Ressourcenzuweisungen und Nutzungsnachverfolgung sowie Protokollüberwachung in der Cloud möglich sind.


- Diese Bereitstellung auf einem Onlineendpunkt kann auf einer Momentaufnahme der Ausführung basieren, sodass stabile und sichere Bereitstellung, weitere Ressourcenzuweisungen und Nutzungsnachverfolgung sowie Protokollüberwachung in der Cloud möglich sind.
- Nach der Analyse von Experimenten können Teammitglieder zur weiteren Entwicklung und Feinabstimmung zum Code-Repository zurückkehren. Nachfolgende Ausführungen können dann iterativ an die Cloud übermittelt werden.







Warum wir die Verwendung des Code-Repositorys für die gemeinsame Entwicklung empfehlen
Für die iterative Entwicklung ist eine Kombination aus einer lokalen Entwicklungsumgebung und einem Versionssteuerungssystem wie Git in der Regel effektiver. Sie können Änderungen vornehmen und Ihren Code lokal testen und dann die Änderungen an Git übernehmen. Dadurch wird ein fortlaufender Datensatz Ihrer Änderungen erstellt und bietet die Möglichkeit, bei Bedarf auf frühere Versionen zurückgesetzt zu werden.
Wenn die Freigabe von Flüssen in verschiedenen Umgebungen erforderlich ist, ist die Verwendung eines cloudbasierten Code-Repositorys wie GitHub oder Azure Repos ratsam. Auf diese Weise können Sie von jedem Ort aus auf die neueste Version Ihres Codes zugreifen und Tools für die Zusammenarbeit und die Codeverwaltung bieten.
Durch die Befolgung dieser Best Practice können Teams eine nahtlose, effiziente und produktive Umgebung für die zeitnahe Entwicklung von Abläufen schaffen.