Feature Hashing
Wichtig
Der Support für Machine Learning Studio (klassisch) endet am 31. August 2024. Es wird empfohlen, bis zu diesem Datum auf Azure Machine Learning umzustellen.
Ab dem 1. Dezember 2021 können Sie keine neuen Ressourcen in Machine Learning Studio (klassisch) mehr erstellen. Bis zum 31. August 2024 können Sie die vorhandenen Ressourcen in Machine Learning Studio (klassisch) weiterhin verwenden.
- Siehe Migrieren zu Azure Machine Learning
- Weitere Informationen zu Azure Machine Learning.
Die Dokumentation zu ML Studio (klassisch) wird nicht mehr fortgeführt und kann künftig nicht mehr aktualisiert werden.
Konvertiert mithilfe der Vowpal Wabbit-Bibliothek Textdaten in mit Ganzzahlen codierte Merkmale
Kategorie: Textanalyse
Hinweis
Giltnur für: Machine Learning Studio (klassisch)
Ähnliche Drag & Drop-Module sind im Azure Machine Learning-Designer verfügbar.
Modulübersicht
In diesem Artikel wird beschrieben, wie Sie das Featurehashing-Modul in Machine Learning Studio (klassisch) verwenden, um einen Datenstrom englischer Text in eine Reihe von Features zu transformieren, die als ganze Zahlen dargestellt werden. Anschließend können Sie dieses Hashfeature an einen Maschinellen Lernalgorithmus übergeben, um ein Textanalysemodell zu trainieren.
Die in diesem Modul bereitgestellte Featurehashfunktion basiert auf dem Vowpal Wabbit-Framework. Weitere Informationen finden Sie unter Train Vowpal Wabbit 7-4 Model or Train Vowpal Wabbit 7-10 Model.
Weitere Informationen zum Featurehashing
Feature Hashing funktioniert, indem eindeutige Token in Integerwerte umgewandelt werden. Diese Funktion verarbeitet die genauen Zeichenfolgen, die Sie als Eingabe bereitstellen, und führt keine linguistische Analyse oder Vorverarbeitung aus.
Nehmen Sie z.B. eine Reihe von einfachen Sätzen wie diese an, gefolgt von einer Stimmungsbewertung. Angenommen, Sie möchten diesen Text verwenden, um ein Modell zu erstellen.
| USERTEXT (Benutzertext) | SENTIMENT (Stimmung) |
|---|---|
| I loved this book (Ich mochte dieses Buch) | 3 |
| I hated this book (Ich habe dieses Buch gehasst) | 1 |
| This book was great (Dieses Buch war großartig) | 3 |
| I love books (Ich liebe Bücher) | 2 |
Intern erstellt das Featurehashing-Modul ein Wörterbuch von n-Gramm. Die Liste der Bigramme für dieses Dataset würde beispielsweise folgendermaßen aussehen:
| TERM (Bigramme) | FREQUENCY (Häufigkeit) |
|---|---|
| This book (Dieses Buch) | 3 |
| I loved (Ich mochte) | 1 |
| I hated (Ich habe gehasst) | 1 |
| I love (Ich liebe) | 1 |
Sie können die Größe der N-Gramme mithilfe der Eigenschaft N-grams steuern. Bei der Auswahl von Bigrammen werden auch Unigramme berechnet. Daher würde das Wörterbuch auch einzelne Begriffe wie die folgenden einschließen:
| Begriff (Unigramme) | FREQUENCY (Häufigkeit) |
|---|---|
| book (Buch) | 3 |
| I | 3 |
| books (Bücher) | 1 |
| was (war) | 1 |
Nachdem das Wörterbuch erstellt wurde, wandelt das Featurehashing-Modul die Wörterbuchbegriffe in Hashwerte um und berechnet, ob ein Feature in jedem Fall verwendet wurde. Für jede Textzeile gibt das Modul eine Reihe von Spalten aus, eine Spalte für jedes gehashte Merkmal.
Nach dem Hashing können die Merkmalsspalten beispielsweise wie folgt aussehen:
| Rating | Hashing feature 1 (Hashingmerkmal 1) | Hashing feature 2 (Hashingmerkmal 2) | Hashing feature 3 (Hashingmerkmal 3) |
|---|---|---|---|
| 4 | 1 | 1 | 0 |
| 5 | 0 | 0 | 0 |
- Wenn der Wert in der Spalte 0 ist, enthält die Zeile nicht das Hashfeature.
- Wenn der Wert 1 ist, hat die Zeile das Merkmal enthalten.
Der Vorteil der Verwendung von Featurehashing besteht darin, dass Sie Textdokumente mit variabler Länge als numerische Featurevektoren der gleichen Länge darstellen und eine Verringerung der Dimensionalität erzielen können. Wenn Sie dagegen versucht haben, die Textspalte für schulungen zu verwenden, wird sie als kategorisierte Featurespalte mit vielen unterschiedlichen Werten behandelt.
Durch die numerischen Ausgaben ist es außerdem möglich, viele verschiedene Machine Learning-Methoden mit den Daten einzusetzen, einschließlich Klassifizierung, Clustering und Informationsabruf. Da Nachschlagevorgänge ganzzahlige Hashes anstelle von Zeichenfolgenvergleichen verwenden können, ist das Abrufen der Merkmalsgewichtungen auch wesentlich schneller.
Konfigurieren von Featurehashing
Fügen Sie das Featurehashing-Modul zu Ihrem Experiment in Studio (klassisch) hinzu.
Verbinden Sie das Dataset, das den zu analysierenden Text enthält.
Tipp
Da Feature Hashing keine lexikalischen Vorgänge wie Stammformreduktion oder Trunkierung durchführt, können Sie manchmal bessere Ergebnisse erzielen, indem Sie Textvorverarbeitung vor der Anwendung von Feature Hashing durchführen. Vorschläge finden Sie in den Abschnitten "Bewährte Methoden " und " Technische Notizen ".
Wählen Sie für Zielspalten diese Textspalten aus, die Sie in Hashfeatures konvertieren möchten.
Die Spalten müssen der Zeichenfolgendatentyp sein und als Featurespalte gekennzeichnet werden.
Wenn Sie mehrere Textspalten auswählen, die als Eingaben verwendet werden sollen, kann dies einen großen Einfluss auf die Featuredimensionalität haben. Wenn beispielsweise ein 10-Bit-Hash für eine einzelne Textspalte verwendet wird, enthält die Ausgabe 1024 Spalten. Wenn ein 10-Bit-Hash für zwei Textspalten verwendet wird, enthält die Ausgabe 2048 Spalten.
Hinweis
Standardmäßig markiert Studio (klassisch) die meisten Textspalten als Features. Wenn Sie also alle Textspalten auswählen, erhalten Sie möglicherweise zu viele Spalten, einschließlich vieler Spalten, die nicht tatsächlich frei sind. Verwenden Sie die Option " Feature löschen " in " Metadaten bearbeiten ", um zu verhindern, dass andere Textspalten hashed werden.
Verwenden Sie Hashing bitsize (Hashing-Bitgröße), um die Anzahl der Bits anzugeben, die beim Erstellen der Hashtabelle verwendet werden sollen.
Die Standardbitgröße ist 10. Für viele Probleme ist dieser Wert mehr als ausreichend, aber ob für Ihre Daten ausreichend ist, hängt von der Größe des n-Gramm-Vokabulars im Schulungstext ab. Mit einem großen Vokabular ist möglicherweise mehr Platz erforderlich, um Kollisionen zu vermeiden.
Es wird empfohlen, eine andere Anzahl von Bits für diesen Parameter zu verwenden und die Leistung der maschinellen Lernlösung zu bewerten.
Geben Sie für N-grams (N-Gramme) eine Zahl ein, die die maximale Länge der N-Gramme definiert, die dem Trainingswörterbuch hinzugefügt werden sollen. Ein N-Gramm ist eine Sequenz von N Wörtern, die als eindeutige Einheit behandelt wird.
N-Gramm = 1: Unigrams oder einzelne Wörter.
N-Gramm = 2: Bigrams oder zwei Wortsequenzen, plus Unigramme.
N-Gramm = 3: Trigrams oder drei Wortsequenzen sowie Bigrams und Unigrams.
Führen Sie das Experiment aus.
Ergebnisse
Nach Abschluss der Verarbeitung gibt das Modul ein transformiertes Dataset aus, in dem die ursprüngliche Textspalte in mehrere Spalten umgewandelt wurde, die jeweils ein Merkmal im Text darstellen. Je nachdem, wie groß das Wörterbuch ist, kann das resultierende Dataset extrem groß sein:
| Column name 1 (Spaltenname 1) | Column type 2 (Spaltentyp 2) |
|---|---|
| USERTEXT (Benutzertext) | Ursprüngliche Datenspalte |
| SENTIMENT (Stimmung) | Ursprüngliche Datenspalte |
| USERTEXT - Hashing feature 1 (Hashingmerkmal 1) | Gehashte Merkmalsspalte |
| USERTEXT - Hashing feature 2 (Hashingmerkmal 2) | Gehashte Merkmalsspalte |
| USERTEXT - Hashing feature n (Hashingmerkmal n) | Gehashte Merkmalsspalte |
| USERTEXT - Hashing feature 1024 (Hashingmerkmal 1024) | Gehashte Merkmalsspalte |
Nachdem Sie das transformierte Dataset erstellt haben, können Sie sie als Eingabe für das Train-Modellmodul verwenden, zusammen mit einem guten Klassifizierungsmodell, z. B. Zwei-Klassen-SupportVektorcomputer.
Bewährte Methoden
Einige bewährte Methoden, die Sie beim Modellieren von Textdaten verwenden können, werden im folgenden Diagramm veranschaulicht, das ein Experiment darstellt.
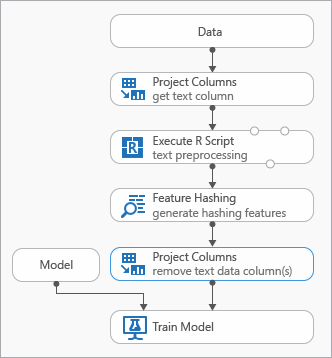
Möglicherweise müssen Sie das Modul Execute R Script vor Verwendung von Feature Hashing hinzufügen, um den Eingabetext vorzuverarbeiten. Mit R-Skript haben Sie auch die Flexibilität, benutzerdefinierte Vokabular oder benutzerdefinierte Transformationen zu verwenden.
Sie sollten nach dem Feature-Hashing-Modul eine Auswahlspalten im Datasetmodul hinzufügen, um die Textspalten aus dem Ausgabedatensatz zu entfernen. Sie benötigen die Textspalten nicht, nachdem die Hashingfeatures generiert wurden.
Alternativ können Sie das Modul " Metadaten bearbeiten" verwenden, um das Featureattribut aus der Textspalte zu löschen.
Berücksichtigen Sie auch die Verwendung dieser Textvorverarbeitungsoptionen, um Ergebnisse zu vereinfachen und die Genauigkeit zu verbessern:
- Wortbruch
- Entfernen von Wörtern beenden
- Groß-/Kleinschreibung
- Entfernen von Interpunktion und Sonderzeichen
- Sich.
Der optimale Satz von Vorverarbeitungsmethoden, der in jeder individuellen Lösung zum Einsatz kommt, hängt vom Fachgebiet, dem Vokabular und den Geschäftsanforderungen ab. Es wird empfohlen, mit Ihren Daten zu experimentieren, um zu sehen, welche benutzerdefinierten Textverarbeitungsmethoden am effektivsten sind.
Beispiele
Beispiele für die Verwendung von Feature-Hashing für Textanalyse finden Sie im Azure AI-Katalog:
News-Kategorisierung: Verwendet Feature-Hashing zum Klassifizieren von Artikeln in eine vordefinierte Liste von Kategorien.
Ähnliche Unternehmen: Verwendet den Text von Wikipedia-Artikeln, um Unternehmen zu kategorisieren.
Textklassifizierung: In diesem fünfteiligen Beispiel werden Text aus Twitter-Nachrichten verwendet, um eine Stimmungsanalyse durchzuführen.
Technische Hinweise
Dieser Abschnitt enthält Implementierungsdetails, Tipps und Antworten auf häufig gestellte Fragen.
Tipp
Zusätzlich zum Verwenden von Feature-Hashing möchten Sie möglicherweise andere Methoden verwenden, um Features aus Text zu extrahieren. Beispiel:
- Verwenden Sie das Preprocess Text-Modul , um Artefakte wie Rechtschreibfehler zu entfernen oder textvorbereitendes Hashing zu vereinfachen.
- Verwenden Sie "Schlüsselausdrücke extrahieren" zum Extrahieren von Ausdrücken mit natürlicher Sprache.
- Verwenden Sie die benannte Entitätserkennung , um wichtige Entitäten zu identifizieren.
Machine Learning Studio (klassisch) stellt eine Textklassifizierungsvorlage bereit, die Sie durch die Verwendung des Feature-Hashing-Moduls für die Featureextraktion führt.
Details zur Implementierung
Das Feature Hashing-Modul verwendet ein schnelles maschinelles Lernframework namens Vowpal Wabbit, das Featurewörter in Speicherindizes mithilfe einer beliebten Open Source Hashfunktion namens Murmurhash3 hasht. Diese Hashfunktion ist ein nicht kryptografischer Hashalgorithmus, der Texteingaben zu ganzen Zahlen zuordnet. Er ist beliebt, weil er bei einer zufälligen Verteilung von Schlüsseln eine gute Leistung bietet. Im Gegensatz zu kryptografischen Hashfunktionen kann es von einem Gegner leicht umgekehrt werden, sodass es für kryptografische Zwecke nicht geeignet ist.
Das Hashing dient der Konvertierung von Textdokumenten mit variabler Länge in numerische Merkmalsvektoren gleicher Länge, um die Dimensionalität zu reduzieren und die Suche nach Merkmalsgewichtungen zu beschleunigen.
Jedes Hashing-Feature stellt eine oder mehrere n-Gramm-Textfeatures dar (Unigrams oder einzelne Wörter, Bi-Gramm, Tri-Gramm usw.), abhängig von der Anzahl der Bits (dargestellt als k) und der Anzahl der als Parameter angegebenen n-Gramm. Es stellt Namen für die Computerarchitektur dar, die nicht signiertes Wort mit dem Murmurhash v3 (nur 32-Bit-Algorithmus) verwendet wird, der dann mit (2^k)-1 versehen ist. Das heißt, der Hashwert wird auf die ersten k-Unteren-Reihenfolge-Bits projiziert, und die verbleibenden Bits werden null entfernt. Wenn die angegebene Anzahl von Bits 14 beträgt, kann die Hashtabelle 214-1 (oder 16.383) Einträge enthalten.
Für viele Probleme ist die Standardhashtabelle (Bitsize = 10) mehr als ausreichend; Je nach Größe des n-Gramm-Vokabulars im Schulungstext ist jedoch möglicherweise mehr Platz erforderlich, um Kollisionen zu vermeiden. Es wird empfohlen, eine andere Anzahl von Bits für den Hashing-Bitsize-Parameter zu verwenden und die Leistung der Machine Learning-Lösung zu bewerten.
Erwartete Eingaben
| Name | type | BESCHREIBUNG |
|---|---|---|
| Dataset | Datentabelle | Eingabedataset |
Modulparameter
| Name | Range | type | Standard | BESCHREIBUNG |
|---|---|---|---|---|
| Target columns | Any | ColumnSelection | StringFeature | Wählen Sie die Spalten aus, auf die Hashing angewendet wird. |
| Hashing bitsize | [1;31] | Integer | 10 | Geben Sie die Anzahl der Bits an, die beim Hashing der ausgewählten Spalten verwendet werden soll. |
| N-grams | [0;10] | Integer | 2 | Geben Sie die Anzahl der während des Hashings generierten N-Gramm an. Standardmäßig werden sowohl Monogramme als auch Bigramme extrahiert. |
Ausgaben
| Name | type | BESCHREIBUNG |
|---|---|---|
| Transformiertes Dataset | Datentabelle | Ausgabedataset mit Hashspalten |
Ausnahmen
| Ausnahme | Beschreibung |
|---|---|
| Fehler 0001 | Eine Ausnahme tritt auf, wenn eine oder mehrere angegebene Spalten des Datasets nicht gefunden werden konnten. |
| Fehler 0003 | Eine Ausnahme tritt auf, wenn mindestens eine Eingabe NULL oder leer ist. |
| Fehler 0004 | Eine Ausnahme tritt auf, wenn der Parameter kleiner als oder gleich dem bestimmten Wert ist. |
| Fehler 0017 | Die Ausnahme tritt auf, wenn eine oder mehrere angegebene Spalten einen Typ aufweisen, der im aktuellen Modul nicht unterstützt wird. |
Eine Liste der Fehler, die für Studio-Module (klassische) spezifisch sind, finden Sie unter Machine Learning Fehlercodes.
Eine Liste der API-Ausnahmen finden Sie unter Machine Learning REST-API-Fehlercodes.