Leitfaden zur Net#-Spezifikationssprache für neuronale Netzwerke für Machine Learning Studio (Classic)
GILT FÜR: Machine Learning Studio (Classic)
Machine Learning Studio (Classic)  Azure Machine Learning
Azure Machine Learning
Wichtig
Der Support für Machine Learning Studio (klassisch) endet am 31. August 2024. Es wird empfohlen, bis zu diesem Datum auf Azure Machine Learning umzustellen.
Ab dem 1. Dezember 2021 können Sie keine neuen Ressourcen in Machine Learning Studio (klassisch) mehr erstellen. Bis zum 31. August 2024 können Sie die vorhandenen Ressourcen in Machine Learning Studio (klassisch) weiterhin verwenden.
Die Dokumentation zu ML Studio (klassisch) wird nicht mehr fortgeführt und kann künftig nicht mehr aktualisiert werden.
Net# ist eine von Microsoft entwickelte Sprache, mit der komplexe Architekturen neuronaler Netze wie Deep Neural Networks oder Faltungen beliebiger Dimensionen definiert werden. Sie können komplexe Strukturen verwenden, um das Lernen aus Bild-, Video- oder Audiodaten zu verbessern.
Sie können eine Net#-Architekturspezifikation in allen Modulen neuronaler Netze in Machine Learning Studio (Classic) verwenden:
- Mehrklassiges neuronales Netzwerk
- Zweiklassiges neuronales Netzwerk
- Regression mit neuronalen Netzwerken
In diesem Artikel werden die grundlegenden Konzepte und die Syntax beschrieben, die zum Entwickeln eines benutzerdefinierten neuronalen Netzwerks mit Net# benötigt werden:
- Anforderungen neuronaler Netzwerke und Definieren der primären Komponenten
- Syntax und Schlüsselwörter der Net#-Spezifikationssprache
- Beispiele von mit Net# erstellten benutzerdefinierten neuronalen Netzwerken
Neuronale Netzwerke – Grundlagen
Die Struktur eines neuronalen Netzwerks besteht aus Knoten, die in Schichten organisiert sind, sowie gewichteten Verbindungen (bzw. „Edges“) zwischen den Knoten. Die Verbindungen sind gerichtet, und jede Verbindung hat einen Quellknoten und einen Zielknoten.
Jede trainierbare Schicht (eine verdeckte Schicht oder eine Ausgabeschicht) hat mindestens ein Verbindungsbündel. Ein Verbindungsbündel besteht aus einer Quellschicht und einer Spezifikation der Verbindungen von dieser Quellschicht. Alle Verbindungen in einem bestimmten Bündel nutzen dieselbe Quell- und Zielschicht. In Net# gehört ein Verbindungsbündel zur Zielschicht des Bündels.
Net# unterstützt verschiedene Arten von Verbindungsbündeln, sodass Sie anpassen können, wie Eingaben verdeckten Schichten und Ausgaben zugeordnet werden.
Das Standardbündel ist ein vollständiges Bündel, bei dem jeder Knoten in der Quellschicht mit jedem Knoten in der Zielschicht verbunden ist.
Darüber hinaus unterstützt Net# die folgenden vier Arten erweiterter Verbindungsbündel:
Gefilterte Bündel. Sie können unter Verwendung der Positionen des Quell- und des Zielschichtknotens ein Prädikat definieren. Wenn das Prädikat "True" ist, sind die Knoten verbunden.
Konvolutionsbündel. Sie können kleine Knotenumgebungen in der Quellschicht definieren. Jeder Knoten in der Zielschicht ist mit einer Knotenumgebung in der Quellschicht verbunden.
Poolingbündel und Antwortnormalisierungsbündel. Diese ähneln insofern den Konvolutionsbündeln, als der Benutzer kleine Knotenumgebungen in der Quellschicht definiert. Der Unterschied besteht darin, dass die Gewichtungen der Kanten in diesen Paketen nicht trainierbar sind. Stattdessen wird eine vordefinierte Funktion auf die Werte des Quellknotens angewendet, um den Wert des Zielknotens zu ermitteln.
Unterstützte Anpassungen
Die Architektur der neuronalen Netzmodelle, die Sie in Machine Learning Studio (Classic) erstellen, kann mithilfe von Net# umfassend angepasst werden. Ihre Möglichkeiten:
- verdeckte Schichten erstellen und die Anzahl der Knoten in jeder Schicht steuern;
- angeben, wie Schichten miteinander verbunden werden sollen;
- spezielle Konnektivitätsstrukturen wie Konvolutionen und Bündel mit gemeinsamer Gewichtung definieren;
- verschiedene Aktivierungsfunktionen angeben.
Einzelheiten zur Syntax der Spezifikationssprache finden Sie unter Strukturspezifikation.
Beispiele für die Definition neuronaler Netzwerke für einige gängige Aufgaben aus dem Bereich Machine Learning (sowohl einfach als auch komplex) finden Sie unter Beispiele.
Allgemeine Anforderungen
- Es müssen genau eine Ausgabeschicht, mindestens eine Eingabeschicht und null oder mehr verdeckte Schichten vorhanden sein.
- Jede Schicht verfügt über eine feste Anzahl von Knoten, die konzeptionell in einem rechteckigen Array beliebiger Dimensionen angeordnet sind.
- Eingabeschichten sind keine trainierten Parameter zugeordnet; sie stellen den Eintrittspunkt von Instanzdaten in das Netzwerk dar.
- Trainierbaren Schichten (verdeckten Schichten und Ausgabeschichten) sind trainierte Parameter zugeordnet, die als Gewichtungen und Biase bezeichnet werden.
- Die Quell- und Zielknoten müssen sich in verschiedenen Schichten befinden.
- Verbindungen müssen azyklisch sein, anders ausgedrückt, sie dürfen keine Kette von Verbindungen bilden, die zurück zum ursprünglichen Quellknoten führen.
- Die Ausgabeschicht darf keine Quellschicht eines Verbindungsbündels sein.
Strukturspezifikation
Die Strukturspezifikation eines neuronalen Netzwerks besteht aus drei Abschnitten: der Konstantendeklaration, der Schichtdeklaration und der Verbindungsdeklaration. Es gibt auch einen optionalen Abschnitt für eine Deklaration der gemeinsamen Nutzung. Die Abschnitte können in beliebiger Reihenfolge angegeben werden.
Konstantendeklaration
Eine Konstantendeklaration ist optional. Sie bietet die Möglichkeit, Werte zu definieren, die an anderer Stelle in der Definition des neuronalen Netzwerks verwendet werden. Die Deklarationsanweisung besteht aus einem Bezeichner (ID), gefolgt von einem Gleichheitszeichen und einem Wertausdruck.
Mit der folgenden Anweisung wird beispielsweise die Konstante x definiert:
Const X = 28;
Um zwei oder mehr Konstanten gleichzeitig zu definieren, schließen Sie die Bezeichnernamen und -werte in geschweifte Klammern ein, und verwenden Sie Semikolons als Trennzeichen. Beispiel:
Const { X = 28; Y = 4; }
Bei der rechten Seite eines Zuweisungsausdrucks kann es sich um eine ganze Zahl, eine reelle Zahl, einen booleschen Wert (True oder False) oder einen mathematischen Ausdruck handeln. Beispiel:
Const { X = 17 * 2; Y = true; }
Schichtdeklaration
Die Schichtdeklaration ist erforderlich. Sie definiert die Größe und die Quelle der Schicht, einschließlich ihrer Verbindungsbündel und Attribute. Die Deklarationsanweisung beginnt mit den Namen der Schicht (input, hidden oder output), gefolgt von den Dimensionen der Schicht (ein Tupel positiver ganzer Zahlen). Beispiel:
input Data auto;
hidden Hidden[5,20] from Data all;
output Result[2] from Hidden all;
- Das Produkt der Dimensionen ist die Anzahl von Knoten in der Schicht. In diesem Beispiel liegen zwei Dimensionen [5,20] vor, d. h., die Schicht hat 100 Knoten.
- Die Schichten können in beliebiger Reihenfolge deklariert werden, mit einer Ausnahme: Wenn mehrere Eingabeschichten definiert werden, muss die Reihenfolge ihrer Deklaration mit der Reihenfolge der Features in den Eingabedaten übereinstimmen.
Um die Anzahl von Knoten in einer Schicht automatisch bestimmen zu lassen, verwenden Sie das Schlüsselwort auto. Die Wirkung des Schlüsselworts auto ist je nach Schicht unterschiedlich:
- In der Deklaration einer Eingabeschicht entspricht die Anzahl der Knoten der Anzahl von Features in den Eingabedaten.
- In der Deklaration einer verdeckten Schicht entspricht die Anzahl der Knoten der Zahl, die vom Parameterwert für Anzahl der verborgenen Knoten angegeben wird.
- In der Deklaration einer Ausgabeschicht beträgt die Anzahl der Knoten 2 für eine Zwei-Klassen-Klassifikation und 1 für Regression; für eine Klassifikation mehrerer Klassen ist sie gleich der Anzahl der Ausgabeknoten.
Im folgenden Beispiel einer Netzwerkdefinition wird die Größe aller Schichten automatisch bestimmt:
input Data auto;
hidden Hidden auto from Data all;
output Result auto from Hidden all;
Eine Schichtdeklaration für eine trainierbare Schicht (verdeckte Schichten oder Ausgabeschichten) kann optional die Ausgabefunktion (auch als Aktivierungsfunktion bezeichnet) enthalten. Standardmäßig lautet sie sigmoid für Klassifikationsmodelle und linear für Regressionsmodelle. Auch bei Verwendung der Standardwerte können Sie die Aktivierungsfunktion explizit angeben, falls dies aus Gründen der Klarheit gewünscht ist.
Die folgenden Ausgabefunktionen werden unterstützt:
- sigmoid
- linear
- softmax
- rlinear
- square
- sqrt
- srlinear
- abs
- tanh
- brlinear
Die folgende Deklaration verwendet beispielsweise die Funktion softmax:
output Result [100] softmax from Hidden all;
Verbindungsdeklaration
Unmittelbar nachdem Sie die trainierbare Schicht deklariert haben, müssen Sie Verbindungen zwischen den definierten Verbindungen deklarieren. Die Deklaration des Verbindungsbündels beginnt mit dem Schlüsselwort from, gefolgt vom Namen der Quellschicht des Bündels und der Art des zu erstellenden Verbindungsbündels.
Derzeit werden fünf Arten von Verbindungsbündeln unterstützt:
- Vollständige Bündel; diese werden mit dem Schlüsselwort
allangegeben. - Gefilterte Bündel; diese werden mit dem Schlüsselwort
wheregefolgt von einem Prädikatausdruck angegeben. - Konvolutionsbündel; diese werden mit dem Schlüsselwort
convolvegefolgt von den Konvolutionsattributen angegeben. - Poolingbündel; diese werden mit dem Schlüsselwort max pool oder mean pool angegeben.
- Antwortnormalisierungsbündel; diese werden mit dem Schlüsselwort response norm angegeben.
Vollständige Bündel
Ein vollständiges Verbindungsbündel enthält eine Verbindung von jedem Knoten in der Quellschicht zu jedem Knoten in der Zielschicht. Dies ist der standardmäßige Netzwerkverbindungstyp.
Gefilterte Bündel
Die Spezifikation eines gefilterten Verbindungsbündels enthält ein Prädikat, das syntaktisch ganz ähnlich wie ein C#-Lambdaausdruck angegeben wird. Im folgenden Beispiel werden zwei gefilterte Bündel definiert:
input Pixels [10, 20];
hidden ByRow[10, 12] from Pixels where (s,d) => s[0] == d[0];
hidden ByCol[5, 20] from Pixels where (s,d) => abs(s[1] - d[1]) <= 1;
Im Prädikat für
ByRowistsein Parameter, der einen Index in das rechteckige Knotenarray der EingabeschichtPixelsdarstellt, unddist ein Parameter, der einen Index in das Knotenarray der verdeckten SchichtByRowdarstellt. Der Typ vonsunddist jeweils ein Tupel mit ganzen Zahlen der Länge 2. Konzeptionell erstreckt sichsüber alle Paare mit ganzen Zahlen mit0 <= s[0] < 10und0 <= s[1] < 20, währenddsich über alle Paare mit ganzen Zahlen mit0 <= d[0] < 10und0 <= d[1] < 12erstreckt.Auf der rechten Seite des Prädikatausdrucks befindet sich eine Bedingung. In diesem Beispiel ist für jeden Wert von
sundd, bei dem die Bedingung „true“ ist, ein Edgeelement vom Quellschichtknoten zum Zielschichtknoten vorhanden. Der Filterausdruck gibt somit an, dass das Bündel immer dann, wenn s[0] gleich d[0] ist, eine Verbindung von dem durchsdefinierten Knoten zu dem durchddefinierten Knoten enthält.
Optional können Sie einen Satz Gewichtungen für ein gefiltertes Bündel angeben. Der Wert für das Attribut Weights muss ein Tupel mit Gleitkommawerten sein, dessen Länge der Anzahl der vom Bündel definierten Verbindungen entspricht. Standardmäßig werden Gewichtungen nach dem Zufallsprinzip generiert.
Gewichtungswerte werden nach dem Zielknotenindex gruppiert. Wenn der erste Zielknoten mit K Quellknoten verbunden ist, sind die ersten K Elemente des Tupels Weights also die Gewichtungen für den ersten Zielknoten in der Reihenfolge des Quellindex. Gleiches gilt für die restlichen Zielknoten.
Es ist möglich, Gewichtungen direkt als Konstantenwerte anzugeben. Falls die Gewichtungen vorher entsprechend eingerichtet wurden, können Sie sie mit der folgenden Syntax als Einschränkungen angeben:
const Weights_1 = [0.0188045055, 0.130500451, ...]
Konvolutionsbündel
Wenn die Trainingsdaten eine homogene Struktur aufweisen, werden Konvolutionsverbindungen üblicherweise eingesetzt, um übergeordnete Merkmale der Daten zu ermitteln. So kann beispielsweise in Bild-, Audio- oder Videodaten die räumliche oder zeitliche Dimensionalität ziemlich einheitlich sein.
Konvolutionsbündel verwenden rechteckige Kernel, die durch die Dimensionen geschoben werden. Im Wesentlichen definiert jeder Kernel einen Satz von Gewichtungen, die in lokalen Umgebungen angewendet werden. Diese werden als Kernelanwendungen bezeichnet. Jede Kernelanwendung entspricht einem Knoten in der Quellschicht, der als zentraler Knoten bezeichnet wird. Die Gewichtungen eines Kernels werden von vielen Verbindungen gemeinsam verwendet. In einem Konvolutionsbündel ist jeder Kernel rechteckig, und alle Kernelanwendungen sind gleich groß.
Konvolutionsbündel unterstützen die folgenden Attribute:
InputShape definiert die Dimensionalität der Quellschicht für die Zwecke dieses Konvolutionsbündels. Der Wert muss ein Tupel positiver ganzer Zahlen sein. Das Produkt der ganzen Zahlen muss gleich der Anzahl der Knoten in der Quellschicht sein, eine weitergehende Übereinstimmung mit der für die Quellschicht deklarierten Dimensionalität ist jedoch nicht erforderlich. Die Länge dieses Tupels stellt den Wert für die Arität des Konvolutionsbündels dar. Arität bezieht sich in der Regel auf die Anzahl von Argumenten oder Operanden, die eine Funktion enthalten kann.
Die Form und Positionen der Kernel können mit den Attributen KernelShape, Stride, Padding, LowerPad und UpperPad definiert werden:
KernelShape (erforderlich): Definiert die Dimensionalität jedes Kernels für das Konvolutionsbündel. Der Wert muss ein Tupel positiver ganzer Zahlen sein, dessen Länge der Arität des Bündels entspricht. Jede Komponente dieses Tupels darf nicht größer als die entsprechende Komponente von InputShape sein.
Stride (optional): Definiert die gleitenden Schrittgrößen der Konvolution (eine Schrittgröße für jede Dimension), also den Abstand zwischen den zentralen Knoten. Der Wert muss ein Tupel positiver ganzer Zahlen sein, dessen Länge der Arität des Bündels entspricht. Jede Komponente dieses Tupels darf nicht größer als die entsprechende Komponente von KernelShape sein. Der Standardwert ist ein Tupel, in dem alle Komponenten gleich eins sind.
Sharing (optional): Definiert die gemeinsame Nutzung von Gewichtungen für jede Dimension der Konvolution. Der Wert kann ein einzelner boolescher Wert oder ein Tupel boolescher Werte sein, dessen Länge der Arität des Bündels entspricht. Ein einzelner boolescher Wert wird zu einem Tupel der richtigen Länge erweitert, in dem alle Komponenten gleich dem angegebenen Wert sind. Der Standardwert ist ein Tupel, in dem alle Werte "True" sind.
MapCount (optional): Definiert die Anzahl der Featurezuordnungen für das Konvolutionsbündel. Der Wert kann eine einzelne positive ganze Zahl oder ein Tupel positiver ganzer Zahlen sein, dessen Länge der Arität des Bündels entspricht. Ein einzelner ganzzahliger Wert wird zu einem Tupel der richtigen Länge erweitert, in dem die ersten Komponenten gleich dem angegebenen Wert und alle übrigen Komponenten gleich eins sind. Der Standardwert ist eins. Die Gesamtanzahl an Featurezuordnungen ist das Produkt der Komponenten des Tupels. Die Faktorisierung dieser Gesamtanzahl über alle Komponenten legt fest, wie die Featurezuordnungswerte in den Zielknoten gruppiert werden.
Weights (optional): Definiert die anfänglichen Gewichtungen für das Bündel. Der Wert muss ein Tupel von Gleitkommawerten sein, dessen Länge der Anzahl der Kernel mal der Anzahl der Gewichtungen pro Kernel entspricht, wie weiter unten in diesem Artikel definiert. Die Standardgewichtungen werden nach dem Zufallsprinzip generiert.
Es gibt zwei Gruppen von Eigenschaften zum Steuern der Auffüllung, die sich gegenseitig ausschließen:
Padding (optional): Legt fest, ob die Eingabe unter Verwendung eines Standardauffüllungsschemas aufgefüllt werden soll. Der Wert kann ein einzelner boolescher Wert oder ein Tupel boolescher Werte sein, dessen Länge der Arität des Bündels entspricht.
Ein einzelner boolescher Wert wird zu einem Tupel der richtigen Länge erweitert, in dem alle Komponenten gleich dem angegebenen Wert sind.
Wenn der Wert einer Dimension "True" ist, wird die Quelle in dieser Dimension logisch mit Nullwertzellen aufgefüllt, um zusätzliche Kernelanwendungen zu unterstützen, sodass die zentralen Knoten des ersten und letzten Kernels in dieser Dimension den ersten und letzten Knoten in dieser Dimension in der Zielschicht darstellen. Die Anzahl von „Dummy“-Knoten in jeder Dimension wird somit automatisch bestimmt, um genau
(InputShape[d] - 1) / Stride[d] + 1Kernel in die aufgefüllte Quellschicht aufzunehmen.Wenn der Wert einer Dimension "False" ist, werden die Kernel so definiert, dass die Anzahl der ausgelassenen Knoten auf jeder Seite gleich ist (bis zu einer Differenz von 1). Der Standardwert dieses Attributs ist ein Tupel, in dem alle Komponenten "False" sind.
UpperPad und LowerPad (optional): Ermöglichen eine bessere Steuerung des zu verwendenden Umfangs der Auffüllung. Wichtig: Diese Attribute können nur dann definiert werden, wenn die Padding-Eigenschaft oben nicht definiert wurde. Die Werte sollten Tupel ganzer Zahlen sein, deren Längen der Arität des Bündels entsprechen. Wenn diese Attribute angegeben werden, werden am unteren und oberen Ende jeder Dimension der Eingabeschicht „Dummy“-Knoten hinzugefügt. Die Anzahl der Knoten, die dem unteren und oberen Ende der Dimension hinzugefügt werden, wird durch LowerPad[i] bzw. UpperPad[i] festgelegt.
Um sicherzustellen, dass Kernel nur "realen" Knoten und nicht "Dummy"-Knoten entsprechen, müssen die folgenden Bedingungen erfüllt sein:
Jede Komponente von LowerPad muss kleiner als (aber nicht gleich)
KernelShape[d]/2sein.Jede Komponente von UpperPad darf nicht größer als
KernelShape[d]/2sein.Der Standardwert dieser Attribute ist ein Tupel, in dem alle Komponenten gleich 0 sind.
Die Einstellung Padding = „true“ lässt so viel Auffüllung wie nötig zu, um das „Zentrum“ des Kernels innerhalb der „tatsächlichen“ Eingabe zu halten. Dadurch wird die Formel für die Berechnung der Ausgabegröße etwas geändert. In der Regel wird die Ausgabegröße D als
D = (I - K) / S + 1berechnet, wobeiIdie Eingabegröße,Kdie Kernelgröße,S„STRIDE“ und/die Division ganzer Zahlen (Runden in Richtung Null) ist. Wenn Sie UpperPad = [1, 1] festlegen, ist die EingabegrößeItatsächlich 29, weshalbD = (29 - 5) / 2 + 1 = 13gilt. Aber wenn Padding „true“ ist, wirdItatsächlich durchK - 1erhöht. Daher giltD = ((28 + 4) - 5) / 2 + 1 = 27 / 2 + 1 = 13 + 1 = 14. Durch Angeben von Werten für UpperPad und LowerPad erhalten Sie wesentlich mehr Kontrolle über die Auffüllung, als wenn nur „Padding = true“ festgelegt wird.
Weitere Informationen zu Konvolutionsnetzwerken und ihren Anwendungsmöglichkeiten finden Sie in den folgenden Artikeln (in englischer Sprache):
- http://d2l.ai/chapter_convolutional-neural-networks/lenet.html
- https://research.microsoft.com/pubs/68920/icdar03.pdf
Poolingbündel
Ein Poolingbündel wendet Geometrie ähnlich wie Konvolutionskonnektivität an, verwendet aber vordefinierte Funktionen für Quellknotenwerte, um die Zielknotenwerte abzuleiten. Daher haben Poolingbündel keinen trainierbaren Zustand (Gewichtungen oder Biase). Poolingbündel unterstützen alle Konvolutionsattribute mit Ausnahme von Sharing, MapCount und Weights.
Normalerweise überlappen sich die Kernel, die von nebeneinander liegenden Poolingeinheiten zusammengefasst werden, nicht. Wenn Stride[d] in jeder Dimension gleich KernelShape[d] ist, entsteht die herkömmliche lokale Poolingschicht, die üblicherweise in neuronalen Konvolutionsnetzwerken verwendet wird. Jeder Zielknoten berechnet das Maximum oder den Mittelwert der Aktivitäten seines Kernels in der Quellschicht.
Im folgenden Beispiel wird ein Poolingbündel veranschaulicht:
hidden P1 [5, 12, 12]
from C1 max pool {
InputShape = [ 5, 24, 24];
KernelShape = [ 1, 2, 2];
Stride = [ 1, 2, 2];
}
- Die Arität des Bündels ist 3 (die Länge der Tupel
InputShape,KernelShapeundStride). - Die Anzahl von Knoten in der Quellschicht beträgt
5 * 24 * 24 = 2880. - Dies ist eine herkömmliche lokale Poolingschicht, da KernelShape und Stride gleich sind.
- Die Anzahl von Knoten in der Zielschicht beträgt
5 * 12 * 12 = 1440.
Weitere Informationen zu Poolingschichten finden Sie in den folgenden Artikeln (in englischer Sprache):
- https://www.cs.toronto.edu/~hinton/absps/imagenet.pdf (Abschnitt 3.4)
- https://cs.nyu.edu/~koray/publis/lecun-iscas-10.pdf
- https://cs.nyu.edu/~koray/publis/jarrett-iccv-09.pdf
Antwortnormalisierungsbündel
Antwortnormalisierung ist ein lokales Normalisierungsschema, das von Geoffrey Hinton, et al, in diesem Dokument ImageNet Classification with Deep Convolutional Neural Networks (ImageNet-Klassifizierung mit umfassenden neuronalen Faltungsnetzen) eingeführt wurde.
Die Antwortnormalisierung unterstützt die Generalisierung in neuronalen Netzwerken. Wenn ein Neuron auf einem sehr hohen Aktivierungsniveau auslöst, unterdrückt eine lokale Antwortnormalisierungsschicht das Aktivierungsniveau der umgebenden Neuronen. Hierfür werden drei Parameter (α, β und k) und eine Konvolutionsstruktur (oder „Nachbarschaftsform“) verwendet. Jedes Neuron in der Zielschicht y entspricht einem Neuron x in der Quellschicht. Das Aktivierungsniveau y wird durch die folgende Formel angegeben, wobei f das Aktivierungsniveau eines Neurons und Nx der Kernel (bzw. der Satz mit den Neuronen in der Umgebung von x) ist. Dies wird durch die folgende Konvolutionsstruktur definiert:
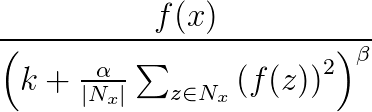
Antwortnormalisierungsbündel unterstützen alle Konvolutionsattribute mit Ausnahme von Sharing, MapCount und Weights.
Wenn der Kernel Neuronen in derselben Zuordnung wie x enthält, wird das Normalisierungsschema als zuordnungsinterne Normalisierung bezeichnet. Um diese Art von Normalisierung zu definieren, muss die erste Koordinate in InputShape den Wert 1 haben.
Wenn der Kernel Neuronen an derselben räumlichen Position wie x enthält, die Neuronen sich aber in anderen Zuordnungen befinden, wird das Normalisierungsschema als zuordnungsübergreifende Normalisierung bezeichnet. Diese Art der Antwortnormalisierung implementiert eine Form von lateraler Hemmung, inspiriert durch den in echten Neuronen gefundenen Typ; dies sorgt für einen Wettbewerb um hohe Aktivierungsniveaus zwischen den in unterschiedlichen Zuordnungen berechneten Neuronenausgaben. Um eine zuordnungsübergreifende Normalisierung zu definieren, muss die erste Koordinate eine ganze Zahl größer als eins und nicht größer als die Anzahl der Zuordnungen sein; der Rest der Koordinaten muss den Wert 1 haben.
Da Antwortnormalisierungsbündel zur Bestimmung des Zielknotenwerts eine vordefinierte Funktion auf Quellknotenwerte anwenden, haben sie keinen trainierbaren Zustand (Gewichtungen oder Biase).
Hinweis
Die Knoten in der Zielschicht entsprechen Neuronen, die die zentralen Knoten der Kernel darstellen. Beispiel: Wenn KernelShape[d] ungerade ist, entspricht KernelShape[d]/2 dem zentralen Kernelknoten. Wenn KernelShape[d] gerade ist, befindet sich der zentrale Knoten bei KernelShape[d]/2 - 1. Wenn Padding[d] „False“ ist, haben der erste und der letzte Knoten für KernelShape[d]/2 daher keinen entsprechenden Knoten in der Zielschicht. Um diese Situation zu vermeiden, definieren Sie Padding als [true, true, …, true].
Zusätzlich zu den vier weiter oben beschriebenen Attributen unterstützen Antwortnormalisierungsbündel auch die folgenden Attribute:
- Alpha (erforderlich): Gibt einen Gleitkommawert an, der in der vorstehenden Formel
αentspricht. - Beta (erforderlich): Gibt einen Gleitkommawert an, der in der vorstehenden Formel
βentspricht. - Offset (optional): Gibt einen Gleitkommawert an, der in der vorstehenden Formel
kentspricht. Der Standardwert lautet 1.
Das folgende Beispiel definiert ein Antwortnormalisierungsbündel mit diesen Attributen:
hidden RN1 [5, 10, 10]
from P1 response norm {
InputShape = [ 5, 12, 12];
KernelShape = [ 1, 3, 3];
Alpha = 0.001;
Beta = 0.75;
}
- Die Quellschicht enthält fünf Zuordnungen, jede mit einer Dimension von 12×12, also insgesamt 1440 Knoten.
- Der Wert von KernelShape gibt an, dass es sich hierbei um eine Schicht mit zuordnungsinterner Normalisierung handelt, bei der die Umgebung ein 3x3-Rechteck ist.
- Der Standardwert von Padding ist „False“, sodass die Zielschicht nur 10 Knoten in jeder Dimension hat. Um einen Knoten in die Zielschicht entsprechend jedem Knoten in der Quellschicht einzuschließen, fügen Sie Padding = [true, true, true] hinzu, und ändern Sie die Größe von RN1 in [5, 12, 12].
Deklaration der gemeinsamen Nutzung
In Net# wird optional die Definition mehrerer Bündel mit gemeinsamen Gewichtungen unterstützt. Die Gewichtungen zweier beliebiger Bündel können gemeinsam genutzt werden, sofern die Struktur der Bündel identisch ist. Die folgende Syntax definiert Bündel mit gemeinsamen Gewichtungen:
share-declaration:
share { layer-list }
share { bundle-list }
share { bias-list }
layer-list:
layer-name , layer-name
layer-list , layer-name
bundle-list:
bundle-spec , bundle-spec
bundle-list , bundle-spec
bundle-spec:
layer-name => layer-name
bias-list:
bias-spec , bias-spec
bias-list , bias-spec
bias-spec:
1 => layer-name
layer-name:
identifier
Die folgende Deklaration der gemeinsamen Nutzung beispielsweise nennt Schichtnamen und gibt an, dass sowohl die Gewichtungen als auch die Biase gemeinsam genutzt werden sollen:
Const {
InputSize = 37;
HiddenSize = 50;
}
input {
Data1 [InputSize];
Data2 [InputSize];
}
hidden {
H1 [HiddenSize] from Data1 all;
H2 [HiddenSize] from Data2 all;
}
output Result [2] {
from H1 all;
from H2 all;
}
share { H1, H2 } // share both weights and biases
- Die Eingabefeatures werden in zwei gleich große Eingabeschichten partitioniert.
- Anschließend berechnen die verdeckten Schichten Features höherer Ebene in den zwei Eingabeschichten.
- Die Deklaration der gemeinsamen Nutzung gibt an, dass H1 und H2 auf die gleiche Weise aus den jeweiligen Eingaben berechnet werden müssen.
Alternativ kann dies wie folgt mit zwei separaten Deklarationen der gemeinsamen Nutzung angegeben werden:
share { Data1 => H1, Data2 => H2 } // share weights
<!-- -->
share { 1 => H1, 1 => H2 } // share biases
Die Kurzform kann nur verwendet werden, wenn die Schichten ein einziges Bündel enthalten. Generell gilt, dass die gemeinsame Nutzung nur möglich ist, wenn die relevante Struktur identisch ist, d. h. die gleiche Größe, die gleiche Konvolutionsgeometrie usw. aufweist.
Beispiele für die Net#-Verwendung
In diesem Abschnitt finden Sie einige Beispiele dafür, wie Sie mit Net# verdeckte Schichten hinzufügen, die Interaktion der verdeckten Schichten mit anderen Schichten definieren und Konvolutionsnetzwerke erstellen können.
Definieren eines einfachen benutzerdefinierten neuronalen Netzwerks: „Hello World“-Beispiel
Dieses einfache Beispiel zeigt, wie ein neuronales Netzwerkmodell mit einer einzigen verdeckten Schicht erstellt wird.
input Data auto;
hidden H [200] from Data all;
output Out [10] sigmoid from H all;
Das Beispiel veranschaulicht die Verwendung einiger grundlegender Befehle wie folgt:
- Die erste Zeile definiert die Eingabeschicht (mit dem Namen
Data). Wenn Sie das Schlüsselwortautoverwenden, bezieht das neuronale Netzwerk automatisch alle Featurespalten in die Eingabebeispiele ein. - In der zweiten Zeile wird die verdeckte Schicht erstellt. Die verdeckte Schicht hat 200 Knoten und erhält den Namen
H. Diese Schicht ist vollständig mit der Eingabeschicht verbunden. - In der dritten Zeile wird die Ausgabeschicht definiert. Sie erhält den Namen
Outund enthält zehn Ausgabeknoten. Wenn das neuronale Netzwerk für die Klassifizierung verwendet wird, ist ein Ausgabeknoten pro Klasse vorhanden. Das Schlüsselwort sigmoid gibt die auf die Ausgabeschicht angewendete Ausgabefunktion an.
Definieren von mehreren verborgenen Schichten: Beispiel Computer Vision
Das folgende Beispiel zeigt die Definition eines etwas komplexeren neuronalen Netzwerks mit mehreren benutzerdefinierten verdeckten Schichten.
// Define the input layers
input Pixels [10, 20];
input MetaData [7];
// Define the first two hidden layers, using data only from the Pixels input
hidden ByRow [10, 12] from Pixels where (s,d) => s[0] == d[0];
hidden ByCol [5, 20] from Pixels where (s,d) => abs(s[1] - d[1]) <= 1;
// Define the third hidden layer, which uses as source the hidden layers ByRow and ByCol
hidden Gather [100]
{
from ByRow all;
from ByCol all;
}
// Define the output layer and its sources
output Result [10]
{
from Gather all;
from MetaData all;
}
Dieses Beispiel veranschaulicht mehrere Funktionen der Spezifikationssprache für neuronale Netzwerke:
- Die Struktur hat zwei Eingabeschichten:
PixelsundMetaData. - Die Schicht
Pixelsist eine Quellschicht für zwei Verbindungsbündel mit den ZielschichtenByRowundByCol. - Die Schichten
GatherundResultsind Zielschichten in mehreren Verbindungsbündeln. - Die Ausgabeschicht
Resultist eine Zielschicht in zwei Verbindungsbündeln: eines hat die verdeckte Schicht der zweiten Ebene (Gather) als Zielschicht, das andere hat die Eingabeschicht (MetaData) als Zielschicht. - Die verdeckten Schichten
ByRowundByColgeben gefilterte Konnektivität mithilfe von Prädikatausdrücken an. Genauer gesagt: Der Knoten inByRowan Position [x, y] ist mit den Knoten inPixelsdadurch verbunden, dass seine erste Indexkoordinate gleich der ersten Koordinate des Knotens (x) ist. Ebenso ist der Knoten inByColan Position [x, y] mit den Knoten inPixelsdadurch verbunden, dass seine zweite Indexkoordinate innerhalb der zweiten Koordinate (y) eines der Knoten liegt.
Definieren eines Konvolutionsnetzwerks für Multi-Klassen-Klassifizierung: Beispiel Ziffernerkennung
Die Definition des folgenden Netzwerks zur Erkennung von Ziffern veranschaulicht einige fortgeschrittene Techniken für die Anpassung eines neuronalen Netzwerks.
input Image [29, 29];
hidden Conv1 [5, 13, 13] from Image convolve
{
InputShape = [29, 29];
KernelShape = [ 5, 5];
Stride = [ 2, 2];
MapCount = 5;
}
hidden Conv2 [50, 5, 5]
from Conv1 convolve
{
InputShape = [ 5, 13, 13];
KernelShape = [ 1, 5, 5];
Stride = [ 1, 2, 2];
Sharing = [false, true, true];
MapCount = 10;
}
hidden Hid3 [100] from Conv2 all;
output Digit [10] from Hid3 all;
Die Struktur umfasst nur eine Eingabeschicht:
Image.Das Schlüsselwort
convolvegibt an, dass die Schichten mit den NamenConv1undConv2Konvolutionsschichten sind. Auf jede dieser Schichtdeklarationen folgt eine Liste der Konvolutionsattribute.Das Netzwerk hat eine dritte verdeckte Schicht:
Hid3. Diese ist vollständig mit der zweiten verdeckten SchichtConv2verbunden.Die Ausgabeschicht
Digitist nur mit der dritten verdeckten Schicht (Hid3) verbunden. Das Schlüsselwortallgibt an, dass die Ausgabeschicht vollständig mitHid3verbunden ist.Die Arität der Konvolution ist 3: die Länge der Tupel
InputShape,KernelShape,StrideundSharing.Die Anzahl von Gewichtungen pro Kernel beträgt
1 + KernelShape\[0] * KernelShape\[1] * KernelShape\[2] = 1 + 1 * 5 * 5 = 26. Oder26 * 50 = 1300.Sie können die Knoten in jeder verdeckten Schicht wie folgt berechnen:
NodeCount\[0] = (5 - 1) / 1 + 1 = 5NodeCount\[1] = (13 - 5) / 2 + 1 = 5NodeCount\[2] = (13 - 5) / 2 + 1 = 5Die Gesamtzahl der Knoten kann anhand der deklarierten Dimensionalität der Schicht [50, 5, 5] wie folgt berechnet werden:
MapCount * NodeCount\[0] * NodeCount\[1] * NodeCount\[2] = 10 * 5 * 5 * 5Da
Sharing[d]nur fürd == 0„False“ ist, beträgt die KernelanzahlMapCount * NodeCount\[0] = 10 * 5 = 50.
Danksagungen
Die Net#-Sprache zum Anpassen der Architektur von neuronalen Netzwerken wurde bei Microsoft von Shon Katzenberger (Architect, Machine Learning) und Alexey Kamenev (Software Engineer, Microsoft Research) entwickelt. Sie wird für interne Machine Learning-Projekte und -Anwendungen verwendet, die von der Bilderkennung bis zur Textanalyse reichen. Weitere Informationen finden Sie unter Neuronale Netze in Machine Learning Studio – Einführung in Net#.