Extrahieren von Text und Informationen aus Bildern in der KI-Anreicherung
Durch die KI-Anreicherung bietet Ihnen Azure KI Search mehrere Optionen zum Erstellen und Extrahieren von durchsuchbarem Text aus Bildern, einschließlich:
- OCR für die optische Zeichenerkennung von Text und Ziffern
- Bildanalyse, die Bilder durch visuelle Features beschreibt
- Benutzerdefinierte Qualifikationen zum Aufrufen einer externen Bildverarbeitung, die Sie bereitstellen möchten
Über OCR können Sie Text aus Fotos oder Bildern extrahieren, die alphanumerischen Text enthalten, z. B. das Wort "STOP" in einem Stoppzeichen. Mit der Bildanalyse können Sie eine Textdarstellung eines Bilds generieren, z. B. "Dandelion" für ein Foto eines Dandelions oder die Farbe "Gelb". Des Weiteren können Sie Metadaten des Bilds extrahieren (beispielsweise die Größe).
Dieser Artikel behandelt die Grundlagen der Arbeit mit Bildern und beschreibt auch mehrere übliche Szenarien, wie die Arbeit mit eingebetteten Bildern, benutzerdefinierten Fertigkeiten und die Überlagerung von Visualisierungen auf Originalbildern.
Um mit Bildinhalten in einem Skillset arbeiten zu können, benötigen Sie:
- Quelldateien, die Bilder enthalten
- Ein Suchindexer, der für Bildaktionen konfiguriert ist
- Ein Skillset mit integrierten oder benutzerdefinierten Qualifikationen, die OCR oder Bildanalyse aufrufen
- Ein Suchindex mit Feldern zum Empfangen der analysierten Textausgabe sowie Ausgabefeldzuordnungen im Indexer, die eine Zuordnung herstellen.
Optional können Sie Projektionen definieren, um bild analysierte Ausgaben für Data Mining-Szenarien in einen Wissensspeicher zu übernehmen.
Einrichten von Quelldateien
Die Bildverarbeitung ist indexergesteuert, was bedeutet, dass die Roheingaben sich an einer unterstützten Datenquelle befinden müssen.
- Bildanalyse unterstützt JPEG, PNG, GIF und BMP.
- Die optische Zeichenerkennung (Optical Character Recognition, OCR) unterstützt JPEG, PNG, BMP und TIF.
Bilder können eigenständige Binärdateien oder in Dokumente eingebettet sein (PDF-, RTF- und Microsoft-Anwendungsdateien). Maximal 1000 Bilder können aus einem bestimmten Dokument extrahiert werden. Wenn mehr als 1000 Bilder in einem Dokument vorhanden sind, werden die ersten 1000 extrahiert und dann eine Warnung generiert.
Azure Blob Storage ist der am häufigsten verwendete Speicher für die Bildverarbeitung in Azure KI Search. Es gibt drei Hauptaufgaben im Zusammenhang mit dem Abrufen von Bildern aus einem Blobcontainer:
Aktivieren des Zugriffs auf Inhalte im Container. Wenn Sie einen Verbindungszeichenfolge mit vollständigem Zugriff verwenden, der einen Schlüssel enthält, erhält der Schlüssel die Berechtigung für den Inhalt. Alternativ können Sie sich mithilfe von Microsoft Entra ID authentifizieren oder als vertrauenswürdiger Dienst verbinden.
Erstellen Sie eine Datenquelle vom Typ "azureblob", die eine Verbindung mit dem Blobcontainer herstellt, in dem Ihre Dateien gespeichert sind.
Überprüfen Sie Dienstebenenbeschränkungen, um sicherzustellen, dass Ihre Quelldaten unter der maximalen Größe und den Mengenbeschränkungen für Indexer und Anreicherung liegen.
Konfigurieren von Indexern für die Bildverarbeitung
Aktivieren Sie nach dem Einrichten der Quelldateien die Bildnormalisierung, indem Sie den Parameter in der imageAction Indexerkonfiguration festlegen. Mit der Bildnormalisierung können Bilder für die nachgeschaltete Verarbeitung einheitlicher werden. Die Bildnormalisierung umfasst die folgenden Vorgänge:
- Große Bilder werden auf eine maximale Höhe und Breite angepasst, um sie einheitlich zu gestalten.
- Bei Bildern mit Metadaten zur Ausrichtung wird die Bilddrehung angepasst, um vertikales Laden zu ermöglichen.
Metadatenanpassungen werden in einem komplexen Typ erfasst, der für jedes Bild erstellt wird. Sie können die Imagenormalisierungsanforderung nicht deaktivieren. Qualifikationen, die Bilder wie OCR und Bildanalyse durchlaufen, erwarten normalisierte Bilder.
Erstellen oder Aktualisieren eines Indexers zum Festlegen der Konfigurationseigenschaften:
{ "parameters": { "configuration": { "dataToExtract": "contentAndMetadata", "parsingMode": "default", "imageAction": "generateNormalizedImages" } } }Legen Sie
dataToExtractaufcontentAndMetadatafest (erforderlich).Stellen Sie sicher, dass der
parsingModeStandardwert (erforderlich) festgelegt ist.Dieser Parameter bestimmt die Granularität der im Index erstellten Suchdokumente. Der Standardmodus richtet eine 1:1-Entsprechung ein, sodass ein Blob zu einem Suchdokument führt. Wenn Dokumente groß sind oder Qualifikationen kleinere Textbrocken erfordern, können Sie die Qualifikation Textaufteilung hinzufügen, die ein Dokument zu Verarbeitungszwecken in Paging unterteilt. Für Suchszenarien ist jedoch ein Blob pro Dokument erforderlich, wenn die Anreicherung die Bildverarbeitung umfasst.
Legen Sie
imageActionfest, um den normalized_images-Knoten in einer Anreicherungsstruktur zu aktivieren (erforderlich):generateNormalizedImagesum ein Array normalisierter Bilder im Rahmen der Dokumententschlüsselung zu generieren.generateNormalizedImagePerPage(gilt nur für PDF), um ein Array normalisierter Bilder zu generieren, wobei jede Seite in der PDF-Datei in einem Ausgabebild gerendert wird. Bei Nicht-PDF-Dateien ist das Verhalten dieses Parameters ähnlich wie bei „generateNormalizedImages“. Beachten Sie jedoch, dass die Einstellung "generateNormalizedImagePerPage" den Indizierungsvorgang weniger leistungsfähig machen kann (insbesondere für große Dokumente), da mehrere Bilder generiert werden müssen.
Passen Sie optional die Breite oder Höhe der generierten normalisierten Bilder an:
normalizedImageMaxWidth(in Pixeln). Der Standardwert ist 2000. Der Maximalwert ist 10000.normalizedImageMaxHeight(in Pixeln). Der Standardwert ist 2000. Der Maximalwert ist 10000.
Der Standardwert von 2.000 Pixeln für die maximale Breite und Höhe der normalisierten Bilder basiert auf der maximal unterstützten Größe der OCR-Qualifikation und der Bildanalysequalifikation. Die OCR-Qualifikation unterstützt eine maximale Breite und Höhe von 4.200 für nicht englische Sprachen und 10.000 für Englisch. Wenn Sie die maximalen Grenzwerte erhöhen, können bei größeren Images je nach Skillsetdefinition und Sprache der Dokumente Fehler bei der Verarbeitung auftreten.
Optional können Sie Dateitypkriterien festlegen, wenn die Arbeitsauslastung auf einen bestimmten Dateityp abzielt. Die Konfiguration des Blob-Indexers umfasst Einstellungen für das Ein- und Ausschließen von Dateien. Sie können Dateien herausfiltern, die Sie nicht möchten.
{ "parameters" : { "configuration" : { "indexedFileNameExtensions" : ".pdf, .docx", "excludedFileNameExtensions" : ".png, .jpeg" } } }
Informationen zu normalisierten Bildern
Wenn imageAction dieser Wert auf einen anderen Wert als "none" festgelegt ist, enthält das neue feld normalized_images ein Array von Bildern. Jedes Bild ist ein komplexer Typ mit folgenden Elementen:
| Bildelement | Beschreibung |
|---|---|
| data | Base64-codierte Zeichenfolge mit dem normalisierten Bild im JPEG-Format. |
| width | Breite des normalisierten Bilds (in Pixel). |
| height | Höhe des normalisierten Bilds (in Pixel). |
| originalWidth | Ursprüngliche Breite des Bilds vor der Normalisierung. |
| originalHeight | Ursprüngliche Höhe des Bilds vor der Normalisierung. |
| rotationFromOriginal | Drehung gegen den Uhrzeigersinn zur Erstellung des normalisierten Bilds (in Grad). Der Wert muss zwischen 0 und 360 Grad liegen. In diesem Schritt werden die durch eine Kamera oder einen Scanner generierten Metadaten aus dem Bild gelesen. Der Wert ist in der Regel ein Vielfaches von 90 Grad. |
| contentOffset | Das Zeichenoffset in dem Inhaltsfeld, aus dem das Bild extrahiert wurde. Dieses Feld ist nur für Dateien mit eingebetteten Bildern relevant. Der ContentOffset für Bilder, die aus PDF-Dokumenten extrahiert wurden, befindet sich immer am Ende des Texts auf der Seite, aus der es im Dokument extrahiert wurde. Dies bedeutet, dass Bilder nach dem gesamten Text auf dieser Seite angezeigt werden, unabhängig von der ursprünglichen Position des Bilds auf der Seite. |
| pageNumber | Wenn das Bild aus einer PDF-Datei extrahiert oder gerendert wurde, enthält dieses Feld die Seitenzahl in der PDF-Datei, aus der es extrahiert oder gerendert wurde, beginnend bei 1. Wenn das Bild nicht aus einer PDF-Datei stammt, ist dieses Feld 0. |
Beispielwert von normalized_images:
[
{
"data": "BASE64 ENCODED STRING OF A JPEG IMAGE",
"width": 500,
"height": 300,
"originalWidth": 5000,
"originalHeight": 3000,
"rotationFromOriginal": 90,
"contentOffset": 500,
"pageNumber": 2
}
]
Definieren von Skillsets für die Bildverarbeitung
Dieser Abschnitt ergänzt den Artikel zur Referenz der Qualifikationen durch eine ganzheitliche Einführung in Qualifikationseingaben, -ausgaben und -muster, da sie sich auf die Bildverarbeitung beziehen.
Erstellen oder aktualisieren Sie ein Skillset, um Qualifikationen hinzuzufügen.
Fügen Sie Vorlagen für OCR und Bildanalyse aus dem Portal hinzu, oder kopieren Sie die Definitionen aus der Referenzdokumentation zu Qualifikationen. Fügen Sie sie in das Kompetenz-Array Ihrer Skillset-Definition ein.
Falls erforderlich, schließen Sie den Schlüssel für mehrere Dienste in die Azure KI Services-Eigenschaft des Skillsets ein. Azure KI Search führt Aufrufe zu einer abrechenbaren Azure KI Services-Ressource für OCR und Bildanalyse für Transaktionen aus, die den kostenlosen Grenzwert überschreiten (20 pro Indexer pro Tag). Azure KI Services müssen sich in derselben Region wie Ihr Suchdienst befinden.
Wenn Originalbilder in PDF-Dateien oder Anwendungsdateien wie PPTX oder DOCX eingebettet sind, müssen Sie den Skill „Textzusammenführung“ hinzufügen, wenn Sie Bild und Text zusammen ausgeben möchten. Die Arbeit mit eingebetteten Bildern wird weiter in diesem Artikel erläutert.
Sobald das grundlegende Framework Ihres Skillset erstellt wurde und Azure KI Services konfiguriert ist, können Sie sich auf jeden einzelnen Bildskill konzentrieren, Eingaben und Quellkontext definieren und Ausgaben zu Feldern in einem Index oder Wissensspeicher zuordnen.
Hinweis
Im REST-Tutorial: Verwenden von REST und KI zum Generieren durchsuchbarer Inhalte aus Azure-Blobs finden Sie ein Beispiel-Skillset, das die Bildverarbeitung mit der Nachverarbeitung natürlicher Sprache kombiniert. Es wird gezeigt, wie die Ausgabe der Qualifikationsbilderstellung in die Entitätserkennung und Schlüsselbegriffserkennung übertragen wird.
Informationen zu Eingaben für die Bildverarbeitung
Wie bereits erwähnt, werden Bilder während der Dokumententschlüsselung extrahiert und dann als vorläufiger Schritt normalisiert. Die normalisierten Bilder sind die Eingaben für jede Bildverarbeitungs-Qualifikation und werden immer auf eine von zwei Arten in einer angereicherten Dokumentstruktur dargestellt:
/document/normalized_images/*ist für Dokumente, die als Ganzes verarbeitet werden./document/normalized_images/*/pagesist für Dokumente, die in Blöcken (Seiten) verarbeitet werden.
Unabhängig davon, ob Sie OCR und bildanalyse in derselben verwenden, weisen Eingaben praktisch die gleiche Konstruktion auf:
{
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [ ]
},
{
"@odata.type": "#Microsoft.Skills.Vision.ImageAnalysisSkill",
"context": "/document/normalized_images/*",
"visualFeatures": [ "tags", "description" ],
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [ ]
}
Zuordnen von Ausgaben zu Suchfeldern
In einem Skillset ist die Ausgabe von Bildanalyse und OCR-Fähigkeiten immer Text. Ausgabetext wird als Knoten in einer internen erweiterten Dokumentstruktur dargestellt, und jeder Knoten muss Feldern in einem Suchindex oder Projektionen in einem Wissensspeicher zugeordnet werden, um den Inhalt in Ihrer App verfügbar zu machen.
Überprüfen Sie im Skillset den
outputsAbschnitt jeder Fähigkeit, um zu bestimmen, welche Knoten im erweiterten Dokument vorhanden sind:{ "@odata.type": "#Microsoft.Skills.Vision.OcrSkill", "context": "/document/normalized_images/*", "detectOrientation": true, "inputs": [ ], "outputs": [ { "name": "text", "targetName": "text" }, { "name": "layoutText", "targetName": "layoutText" } ] }Erstellen oder aktualisieren Sie einen Suchindex, um Felder hinzuzufügen, um die Skillausgaben zu akzeptieren.
Im folgenden Feldsammlungsbeispiel ist "content" Blob-Inhalt. „Metadata_storage_name" gibt den Namen der Datei zurück (stellen Sie sicher, dass sie "abrufbar" ist). „Metadata_storage_path" ist der eindeutige Pfad des Blobs und ist der Standarddokumentschlüssel. "Merged_content" wird aus der Textzusammenführung ausgegeben (nützlich, wenn Bilder eingebettet werden).
„Text" und „layoutText" sind Skillausgaben und müssen eine Zeichenfolgenauflistung sein, um die gesamte OCR-generierte Ausgabe für das gesamte Dokument erfassen zu können.
"fields": [ { "name": "content", "type": "Edm.String", "filterable": false, "retrievable": true, "searchable": true, "sortable": false }, { "name": "metadata_storage_name", "type": "Edm.String", "filterable": true, "retrievable": true, "searchable": true, "sortable": false }, { "name": "metadata_storage_path", "type": "Edm.String", "filterable": false, "key": true, "retrievable": true, "searchable": false, "sortable": false }, { "name": "merged_content", "type": "Edm.String", "filterable": false, "retrievable": true, "searchable": true, "sortable": false }, { "name": "text", "type": "Collection(Edm.String)", "filterable": false, "retrievable": true, "searchable": true }, { "name": "layoutText", "type": "Collection(Edm.String)", "filterable": false, "retrievable": true, "searchable": true } ],Aktualisieren Sie den Indexer, um die Skillsetausgabe (Knoten in einer Anreicherungsstruktur) Indexfeldern zuzuordnen.
Angereicherte Dokumente sind intern. Um die Knoten in einer erweiterten Dokumentstruktur zu externalisieren, richten Sie eine Ausgabefeldzuordnung ein, die angibt, welches Indexfeld Knoteninhalte empfängt. Auf angereicherte Daten wird von Ihrer App über ein Indexfeld zugegriffen. Das folgende Beispiel zeigt einen "Text"-Knoten (OCR-Ausgabe) in einem erweiterten Dokument, das einem "Text"-Feld in einem Suchindex zugeordnet ist.
"outputFieldMappings": [ { "sourceFieldName": "/document/normalized_images/*/text", "targetFieldName": "text" }, { "sourceFieldName": "/document/normalized_images/*/layoutText", "targetFieldName": "layoutText" } ]Führen Sie den Indexer aus, um den Abruf, die Bildverarbeitung und die Indizierung von Quelldokumenten aufzurufen.
Überprüfen der Ergebnisse
Führen Sie eine Abfrage für den Index aus, um die Ergebnisse der Bildverarbeitung zu überprüfen. Verwenden Sie den Such-Explorer als Suchclient oder ein beliebiges Tool, das HTTP-Anforderungen sendet. Die folgende Abfrage wählt Felder aus, die die Ausgabe der Bildverarbeitung enthalten.
POST /indexes/[index name]/docs/search?api-version=[api-version]
{
"search": "*",
"select": "metadata_storage_name, text, layoutText, imageCaption, imageTags"
}
OCR erkennt Text in Bilddateien. Dies bedeutet, dass OCR-Felder ("Text" und "layoutText") leer sind, wenn Quelldokumente reinen Text oder reine Bilder sind. Ebenso sind Bildanalysefelder ("imageCaption" und "imageTags") leer, wenn Quelldokumenteingaben ausschließlich Text sind. Die Indizierungsausführung gibt Warnungen aus, wenn bildgebende Eingaben leer sind. Solche Warnungen sind zu erwarten, wenn Knoten im angereicherten Dokument nicht aufgefüllt werden. Denken Sie daran, dass Sie mithilfe der Blobindizierung Dateitypen einschließen oder ausschließen können, wenn Sie isoliert mit Inhaltstypen arbeiten möchten. Sie können diese Einstellung verwenden, um während der Indexer-Ausführung Rauschen zu reduzieren.
Eine alternative Abfrage zum Überprüfen der Ergebnisse kann die Felder "content" und "merged_content" enthalten. Beachten Sie, dass diese Felder Inhalte für jede BLOB-Datei enthalten, auch wenn keine Bildverarbeitung ausgeführt wurde.
Informationen zu Skillausgaben
Zu den Skillausgaben gehören "text" (OCR), "layoutText" (OCR), "merged_content", "captions" (Bildanalyse), "tags" (Bildanalyse):
"text" speichert DIE OCR-generierte Ausgabe. Dieser Knoten sollte dem Feld vom Typ
Collection(Edm.String)zugeordnet werden. Pro Suchdokument gibt es ein "Text"-Feld, das aus durch Kommas getrennten Zeichenfolgen für Dokumente besteht, die mehrere Bilder enthalten. Die folgende Abbildung zeigt die OCR-Ausgabe für drei Dokumente. Zuerst ist ein Dokument, das eine Datei ohne Bilder enthält. Zweitens ist ein Dokument (Bilddatei) mit einem Wort, "Microsoft". Drittens ist ein Dokument mit mehreren Bildern, einige ohne Text ("",)."value": [ { "@search.score": 1, "metadata_storage_name": "facts-about-microsoft.html", "text": [] }, { "@search.score": 1, "metadata_storage_name": "guthrie.jpg", "text": [ "Microsoft" ] }, { "@search.score": 1, "metadata_storage_name": "Azure AI services and Content Intelligence.pptx", "text": [ "", "Microsoft", "", "", "", "Azure AI Search and Augmentation Combining Microsoft Azure AI services and Azure Search" ] } ]"layoutText" speichert OCR-generierte Informationen zur Textposition auf der Seite, die in Bezug auf Begrenzungsfelder und Koordinaten des normalisierten Bilds beschrieben werden. Dieser Knoten sollte dem Feld vom Typ
Collection(Edm.String)zugeordnet werden. Pro Suchdokument gibt es ein "layoutText"-Feld, das aus durch Kommas getrennten Zeichenfolgen besteht."merged_content" speichert die Ausgabe einer Textzusammenführungs-Qualifikation. Dabei sollte es sich um ein großes Feld vom Typ
Edm.Stringmit rohem Text aus dem Quelldokument mit eingebettetem "Text" anstelle eines Bilds handelt. Wenn Dateien nur textgeschützt sind, haben OCR und Bildanalyse nichts zu tun, und "merged_content" ist identisch mit "Content" (eine BLOB-Eigenschaft, die den Inhalt des Blobs enthält)."imageCaption" erfasst eine Beschreibung eines Bilds als Einzelpersonentags und eine längere Textbeschreibung.
"imageTags" speichert Tags zu einem Bild als Sammlung von Schlüsselwörtern, eine Sammlung für alle Bilder im Quelldokument.
Der folgende Screenshot ist eine Abbildung einer PDF, die Text und eingebettete Bilder enthält. Die Dokumententschlüsselung erkannte drei eingebettete Bilder: eine Gruppe Möwen, Karte, Adler. Anderer Text im Beispiel (einschließlich Titel, Überschriften und Textkörper) wurde als Text extrahiert und von der Bildverarbeitung ausgeschlossen.
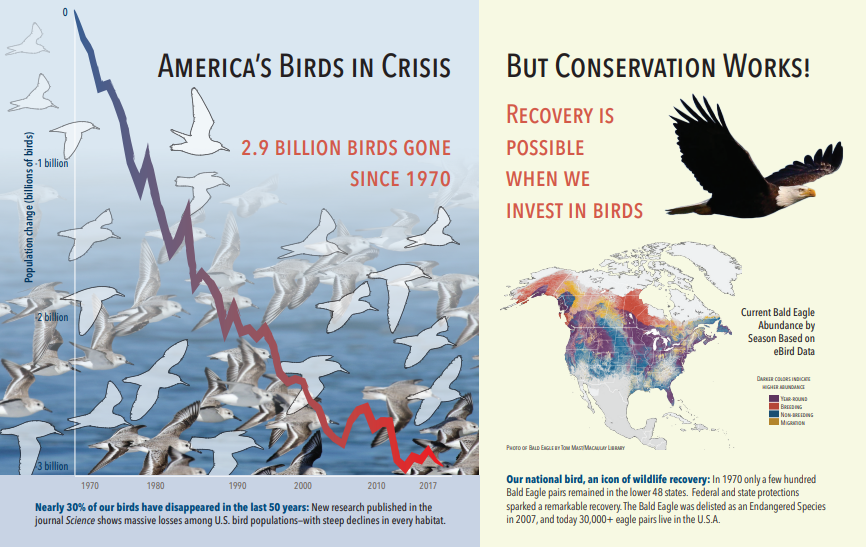
Die Ausgabe der Bildanalyse wird im folgenden JSON-Code veranschaulicht (Suchergebnis). Mit der Qualifikationsdefinition können Sie angeben, welche visuellen Funktionen von Interesse sind. In diesem Beispiel wurden Tags und Beschreibungen erstellt, es gibt jedoch weitere Ausgaben, aus denen Sie auswählen können.
Die Ausgabe „imageCaption" ist ein Array von Beschreibungen, eines pro Bild, das durch „Tags" gekennzeichnet ist, bestehend aus einzelnen Wörtern und längeren Ausdrücken, die das Bild beschreiben. Beachten sie die Tags, die aus „eine Gruppe Möwen schwimmt im Wasser“ oder „eine Nahaufnahme eines Vogels“ besteht.
Die Ausgabe von „imageTags" ist ein Array von Tags, die in der Reihenfolge der Erstellung aufgeführt sind. Beachten Sie, dass Tags wiederholt werden. Es gibt keine Aggregation oder Gruppierung.
"imageCaption": [
"{\"tags\":[\"bird\",\"outdoor\",\"water\",\"flock\",\"many\",\"lot\",\"bunch\",\"group\",\"several\",\"gathered\",\"pond\",\"lake\",\"different\",\"family\",\"flying\",\"standing\",\"little\",\"air\",\"beach\",\"swimming\",\"large\",\"dog\",\"landing\",\"jumping\",\"playing\"],\"captions\":[{\"text\":\"a flock of seagulls are swimming in the water\",\"confidence\":0.70419257326275686}]}",
"{\"tags\":[\"map\"],\"captions\":[{\"text\":\"map\",\"confidence\":0.99942880868911743}]}",
"{\"tags\":[\"animal\",\"bird\",\"raptor\",\"eagle\",\"sitting\",\"table\"],\"captions\":[{\"text\":\"a close up of a bird\",\"confidence\":0.89643581933539462}]}",
. . .
"imageTags": [
"bird",
"outdoor",
"water",
"flock",
"animal",
"bunch",
"group",
"several",
"drink",
"gathered",
"pond",
"different",
"family",
"same",
"map",
"text",
"animal",
"bird",
"bird of prey",
"eagle"
. . .
Szenario: Eingebettete Bilder in PDFs
Wenn die zu verarbeitenden Bilder in andere Dateien eingebettet sind, z. B. PDF oder DOCX, extrahiert die Anreicherungspipeline nur die Bilder und übergibt sie dann zur Verarbeitung an OCR oder Bildanalyse. Die Bildextraktion erfolgt während der Dokumentspaltungsphase, und sobald die Bilder getrennt sind, werden sie getrennt Standard es sei denn, Sie verbinden die verarbeitete Ausgabe explizit wieder in den Quelltext.
Textzusammenführung wird verwendet, um die Bildverarbeitungsausgabe wieder in das Dokument zu integrieren. Obwohl die Textzusammenführung keine harte Anforderung ist, wird sie häufig aufgerufen, sodass die Bildausgabe (OCR-Text, OCR layoutText, Bildtags, Bild-Untertitel s) wieder in das Dokument eingeführt werden kann. Je nach Skill ersetzt die Bildausgabe ein eingebettetes binäres Bild durch ein direktes Textäquivalent. Die Ausgabe der Bildanalyse kann am Bildspeicherort zusammengeführt werden. Die OCR-Ausgabe wird immer am Ende jeder Seite angezeigt.
Der folgende Workflow beschreibt den Prozess der Bildextraktion, -analyse, -zusammenführung und wie die Pipeline erweitert wird, um bildverarbeitete Ausgaben in andere textbasierte Qualifikationen wie Entitätserkennung oder Textübersetzung zu pushen.
Nach dem Herstellen einer Verbindung mit der Datenquelle lädt und entpackt der Indexer Quelldokumente, extrahiert Bilder und Text und warteschlanget jeden Inhaltstyp zur Verarbeitung in die Warteschlange. Ein angereichertes Dokument, das nur aus einem Stammknoten (
"document") besteht, wird erstellt.Bilder in der Warteschlange werden normalisiert und als
"document/normalized_images"Knoten an angereicherte Dokumente übergeben.Bildanreicherungen werden unter Verwendung von
"/document/normalized_images"als Eingabe ausgeführt.Bildausgabeen werden in die erweiterte Dokumentstruktur übergeben, wobei jede Ausgabe als separater Knoten ausgegeben wird. Ausgaben variieren je nach Qualifikation (Text und LayoutText für OCR, Tags und Beschriftungen für die Bildanalyse).
Optional, aber empfohlen, wenn Suchdokumente text- und bildursprungsbasierten Text zusammen enthalten sollen, wird Textzusammenführung ausgeführt, wobei die Textdarstellung dieser Bilder mit dem aus der Datei extrahierten Rohtext kombiniert wird. Textblöcke werden in eine einzelne große Zeichenfolge konsolidiert, in der der Text zuerst in die Zeichenfolge eingefügt wird, und dann in der OCR-Textausgabe oder Bildtags und Untertitel.
Die Ausgabe von Textzusammenführung ist jetzt der endgültige Text, der für alle Downstreamqualifikationen analysiert werden soll, die textverarbeitungsbereit sind. Wenn Ihr Skillset z. B. sowohl OCR als auch Entitätserkennung enthält, sollte die Eingabe für die Entitätserkennung
"document/merged_text"(targetName der Textzusammenführungs-Skillausgabe) lauten.Nachdem alle Qualifikationen ausgeführt wurden, ist das angereicherte Dokument abgeschlossen. Im letzten Schritt verweisen Indexer auf Ausgabefeldzuordnungen, um angereicherte Inhalte an einzelne Felder im Suchindex zu senden.
Das folgende Beispiel-Skillset erstellt ein "merged_text" Feld, das den ursprünglichen Text Ihres Dokuments mit eingebetteten OCRed-Text anstelle eingebetteter Bilder enthält. Sie enthält auch eine Qualifikation für die Entitätserkennung, die "merged_text" als Eingabe verwendet.
Syntax des Anforderungstexts
{
"description": "Extract text from images and merge with content text to produce merged_text",
"skills":
[
{
"description": "Extract text (plain and structured) from image.",
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"defaultLanguageCode": "en",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.MergeSkill",
"description": "Create merged_text, which includes all the textual representation of each image inserted at the right location in the content field.",
"context": "/document",
"insertPreTag": " ",
"insertPostTag": " ",
"inputs": [
{
"name":"text", "source": "/document/content"
},
{
"name": "itemsToInsert", "source": "/document/normalized_images/*/text"
},
{
"name":"offsets", "source": "/document/normalized_images/*/contentOffset"
}
],
"outputs": [
{
"name": "mergedText", "targetName" : "merged_text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"context": "/document",
"categories": [ "Person"],
"defaultLanguageCode": "en",
"minimumPrecision": 0.5,
"inputs": [
{
"name": "text", "source": "/document/merged_text"
}
],
"outputs": [
{
"name": "persons", "targetName": "people"
}
]
}
]
}
Nachdem Sie nun ein merged_text Feld haben, können Sie es als durchsuchbares Feld in Ihrer Indexerdefinition zuordnen. Der gesamte Inhalt Ihrer Dateien – einschließlich des Texts der Bilder – wird somit durchsuchbar.
Szenario: Visualisieren von Begrenzungsfeldern
Ein weiteres gängiges Szenario ist die Visualisierung der Layoutinformationen von Suchergebnissen. So können Sie beispielsweise in Ihren Suchergebnissen den Ort in einem Bild hervorheben, an dem ein Textelement gefunden wurde.
Da der OCR-Schritt für die normalisierten Bilder ausgeführt wird, befinden sich die Layoutkoordinaten im normalisierten Bildbereich, aber wenn Sie das ursprüngliche Bild anzeigen müssen, konvertieren Sie Koordinatenpunkte im Layout in das ursprüngliche Bildkoordinatensystem.
Der folgende Algorithmus veranschaulicht das Muster:
/// <summary>
/// Converts a point in the normalized coordinate space to the original coordinate space.
/// This method assumes the rotation angles are multiples of 90 degrees.
/// </summary>
public static Point GetOriginalCoordinates(Point normalized,
int originalWidth,
int originalHeight,
int width,
int height,
double rotationFromOriginal)
{
Point original = new Point();
double angle = rotationFromOriginal % 360;
if (angle == 0 )
{
original.X = normalized.X;
original.Y = normalized.Y;
} else if (angle == 90)
{
original.X = normalized.Y;
original.Y = (width - normalized.X);
} else if (angle == 180)
{
original.X = (width - normalized.X);
original.Y = (height - normalized.Y);
} else if (angle == 270)
{
original.X = height - normalized.Y;
original.Y = normalized.X;
}
double scalingFactor = (angle % 180 == 0) ? originalHeight / height : originalHeight / width;
original.X = (int) (original.X * scalingFactor);
original.Y = (int)(original.Y * scalingFactor);
return original;
}
Szenario: Benutzerdefinierte Bildqualifikationen
Bilder können auch an benutzerdefinierte Skills übergeben und von benutzerdefinierten Skills zurückgegeben werden. Das Skillset codiert das Bild, das an den benutzerdefinierten Qualifikation übergeben wird, mit Base64. Um das Image innerhalb des benutzerdefinierten Skills zu verwenden, legen Sie "/document/normalized_images/*/data" als Eingabe für den benutzerdefinierten Skill fest. Decodieren Sie in dem Code des benutzerdefinierten Skills die Zeichenfolge mit Base64, bevor Sie sie in ein Bild konvertieren. Um ein Bild an das Skillset zurückzugeben, codieren Sie es mit Base64, bevor Sie es an das Skillset zurückgeben.
Das Bild wird als Objekt mit den folgenden Eigenschaften zurückgegeben:
{
"$type": "file",
"data": "base64String"
}
Das Repository mit Azure Search-Python-Beispielen enthält ein vollständiges in Python implementiertes Beispiel für einen benutzerdefinierten Skill, der Bilder anreichert.
Übergeben von Bildern an benutzerdefinierte Skills
Für Szenarios, in denen Sie einen benutzerdefinierten Skill für Bilder erfordern, können Sie Bilder an den benutzerdefinierten Skill übergeben, damit dieser Text oder Bilder zurückgibt. Das folgende Skillset stammt aus einem Beispiel.
Das folgende Skillset erfasst das normalisierte Bild (das bei der Dokumententschlüsselung abgerufen wird) und gibt Segmente des Bilds aus.
Beispielskillset
{
"description": "Extract text from images and merge with content text to produce merged_text",
"skills":
[
{
"@odata.type": "#Microsoft.Skills.Custom.WebApiSkill",
"name": "ImageSkill",
"description": "Segment Images",
"context": "/document/normalized_images/*",
"uri": "https://your.custom.skill.url",
"httpMethod": "POST",
"timeout": "PT30S",
"batchSize": 100,
"degreeOfParallelism": 1,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "slices",
"targetName": "slices"
}
],
"httpHeaders": {}
}
]
}
Beispiel einer benutzerdefinierten Qualifikation
Der benutzerdefinierte Skill selbst ist extern vom Skillset. In diesem Fall handelt es sich um Python-Code, der zuerst den Batch von Anforderungsdatensätzen im benutzerdefinierten Qualifikationsformat durchläuft und dann die base64-codierte Zeichenfolge in ein Bild konvertiert.
# deserialize the request, for each item in the batch
for value in values:
data = value['data']
base64String = data["image"]["data"]
base64Bytes = base64String.encode('utf-8')
inputBytes = base64.b64decode(base64Bytes)
# Use numpy to convert the string to an image
jpg_as_np = np.frombuffer(inputBytes, dtype=np.uint8)
# you now have an image to work with
Ähnlich gilt, wenn Sie ein Bild zurückgeben möchten, geben Sie eine mit Base64 verschlüsselte Zeichenfolge in einem JSON-Objekt mit der $type-Eigenschaft file zurück.
def base64EncodeImage(image):
is_success, im_buf_arr = cv2.imencode(".jpg", image)
byte_im = im_buf_arr.tobytes()
base64Bytes = base64.b64encode(byte_im)
base64String = base64Bytes.decode('utf-8')
return base64String
base64String = base64EncodeImage(jpg_as_np)
result = {
"$type": "file",
"data": base64String
}
Siehe auch
- Create Indexer (Azure Search Service REST api-version=2017-11-11-Preview) (Erstellen eines Indexers (REST-API für den Azure Search-Dienst: Version 2017-11-11-Preview))
- Skill für Bildanalyse
- OCR cognitive skill (Kognitive Qualifikation: OCR)
- Text Merge cognitive skill (Kognitive Qualifikation: Textzusammenführung)
- Definieren eines Skillsets
- Zuordnen angereicherter Felder