Beispiel: Erstellen und Bereitstellen einer benutzerdefinierten Qualifikation mit Azure Machine Learning (archiviert)
Dieses Beispiel ist archiviert und nicht mehr unterstützt. Es wurde erläutert, wie Sie mithilfe von Azure Machine Learning einen benutzerdefinierten Skill erstellen, um aspektbasierte Stimmungen aus den Überprüfungen zu extrahieren. Dies ermöglichte es, die Zuordnung positiver und negativer Stimmungen innerhalb derselben Überprüfung korrekt identifizierten Entitäten wie Mitarbeitern, Raum, Lobby oder Pool zuzuordnen.
Zum Trainieren des aspektbasierten Stimmungsmodells in Azure Machine Learning verwenden Sie das NLP-Projektrepository. Das Modell wird dann als Endpunkt in einem Azure Kubernetes-Cluster bereitgestellt. Nach der Bereitstellung wird der Endpunkt der Anreicherungspipeline als AML-Skill hinzugefügt, um die Verwendung durch den Cognitive Search-Dienst zu ermöglichen.
Es werden zwei Datasets bereitgestellt. Wenn Sie das Modell selbst trainieren möchten, wird die Datei „hotel_reviews_1000.csv“ benötigt. Möchten Sie den Trainingsschritt überspringen? Laden Sie die Datei „hotel_reviews_100.csv“ herunter.
- Erstellen einer Azure Cognitive Search-Instanz
- Erstellen eines Azure Machine Learning-Arbeitsbereichs (Suchdienst und Arbeitsbereich sollten sich unter demselben Abonnement befinden)
- Trainieren und Bereitstellen eines Modells in einem Azure Kubernetes-Cluster
- Verknüpfen einer KI-Anreicherungspipeline mit dem bereitgestellten Modell
- Erfassen der Ausgabe aus dem bereitgestellten Modell als benutzerdefinierter Skill
Wichtig
Dieser Skill befindet sich in der Public Preview-Phase und unterliegt den zusätzlichen Nutzungsbedingungen. Die Vorschau-REST-API unterstützt diesen Skill.
Voraussetzungen
- Azure-Abonnement – rufen Sie ein kostenloses Abonnement ab.
- Cognitive Search-Dienst
- Cognitive Services-Ressource
- Azure Storage-Konto)
- Azure Machine Learning-Arbeitsbereich
Einrichten
- Klonen Sie den Inhalt desselben Beispielrepositorys, oder laden Sie ihn herunter.
- Wenn der Download eine ZIP-Datei ist, extrahieren Sie den Inhalt. Stellen Sie sicher, dass die Dateien schreibgeschützt sind.
- Kopieren Sie beim Einrichten der Azure-Konten und -Dienste die Namen und Schlüssel in eine Textdatei, auf die leicht zugegriffen werden kann. Die Namen und Schlüssel werden der ersten Zelle in dem Notebook hinzugefügt, in dem Variablen für den Zugriff auf die Azure-Dienste definiert wurden.
- Wenn Sie mit Azure Machine Learning und dessen Anforderungen nicht vertraut sind, sollten Sie zuerst diese Dokumente lesen:
- Konfigurieren einer Entwicklungsumgebung für Azure Machine Learning
- Erstellen und Verwalten von Azure Machine Learning-Arbeitsbereichen im Azure-Portal
- Erwägen Sie beim Konfigurieren der Entwicklungsumgebung für Azure Machine Learning die Verwendung der cloudbasierten Compute-Instanz, damit Sie schneller und einfacher beginnen können.
- Laden Sie die Datasetdatei in einen Container im Speicherkonto hoch. Die größere Datei ist erforderlich, wenn Sie den Trainingsschritt im Notebook ausführen möchten. Wenn Sie den Trainingsschritt lieber überspringen möchten, wird die kleinere Datei empfohlen.
Öffnen des Notebooks und Herstellen einer Verbindung mit Azure-Diensten
- Fügen Sie alle erforderlichen Informationen für die Variablen, die Zugriff auf die Azure-Dienste ermöglichen, in die erste Zelle ein, und führen Sie die Zelle aus.
- Wenn Sie die zweite Zelle ausführen, wird bestätigt, dass Sie eine Verbindung mit dem Suchdienst für Ihr Abonnement hergestellt haben.
- In den Abschnitten 1.1 – 1.5 werden der Suchdienst, Datenspeicher, Skillset, Index und Indexer erstellt.
An diesem Punkt können Sie die Schritte zum Erstellen des Trainingsdatasets und zum Experimentieren in Azure Machine Learning wahlweise überspringen und direkt mit dem Registrieren der beiden Modelle fortfahren, die im Ordner „Modelle“ des GitHub-Repositorys bereitgestellt werden. Wenn Sie diese Schritte überspringen, springen Sie im Notebook zu Abschnitt 3.5, „Schreiben eines Bewertungsskripts“. Dadurch sparen Sie Zeit, weil die Schritte zum Herunter- und Hochladen von Daten bis zu 30 Minuten dauern können.
Erstellen und Trainieren der Modelle
Abschnitt 2 enthält sechs Zellen zum Herunterladen der Glove-Einbettungsdatei aus dem NLP-Projektrepository. Nach dem Herunterladen wird die Datei in den Azure Machine Learning-Datenspeicher hochgeladen. Die ZIP-Datei ist ungefähr 2 G groß, und die Ausführung dieser Aufgaben dauert eine Zeitlang. Nach dem Hochladen werden die Trainingsdaten extrahiert, und jetzt können Sie mit Abschnitt 3 fortfahren.
Trainieren des aspektbasierten Stimmungsmodells und Bereitstellen Ihres Endpunkts
In Abschnitt 3 des Notebooks werden Sie die in Abschnitt 2 erstellten Modelle trainieren, registrieren und als Endpunkt in einem Azure Kubernetes-Cluster bereitstellen. Wenn Sie mit Azure Kubernetes nicht vertraut sind, müssen Sie unbedingt die folgenden Artikel lesen, bevor Sie einen Rückschlusscluster zu erstellen versuchen:
- Übersicht über Azure Kubernetes Service
- Grundlegende Kubernetes-Konzepte für Azure Kubernetes Service (AKS)
- Kontingente, Größeneinschränkungen für virtuelle Computer und regionale Verfügbarkeit in Azure Kubernetes Service (AKS)
Das Erstellen und Bereitstellen des Rückschlussclusters kann bis zu 30 Minuten dauern. Es wird empfohlen, den Webdienst zu testen, bevor Sie mit den abschließenden Schritten fortfahren, Ihr Skillset aktualisieren und den Indexer ausführen.
Aktualisieren des Skillsets
Abschnitt 4 im Notebook enthält vier Zellen zum Aktualisieren des Skillsets und Indexers. Alternativ können Sie über das Portal den neuen Skill auswählen, auf das Skillset anwenden, und dann den Indexer ausführen, um den Suchdienst zu aktualisieren.
Wechseln Sie im Portal zu „Skillset“, und wählen Sie den Link „Skillsetdefinition (JSON)“ aus. Im Portal wird der JSON-Code Ihres Skillsets angezeigt, der in den ersten Zellen des Notebooks erstellt wurde. Rechts neben der Anzeige gibt es ein Dropdownmenü, in dem Sie die Vorlage für Skillsetdefinition auswählen können. Wählen Sie die Vorlage „Azure Machine Learning (AML)“ aus. Geben Sie den Namen des Azure ML-Arbeitsbereichs und den Endpunkt für das Modell an, das für den Rückschlusscluster bereitgestellt wird. Die Vorlage wird mit dem Endpunkt-URI und dem Schlüssel aktualisiert.
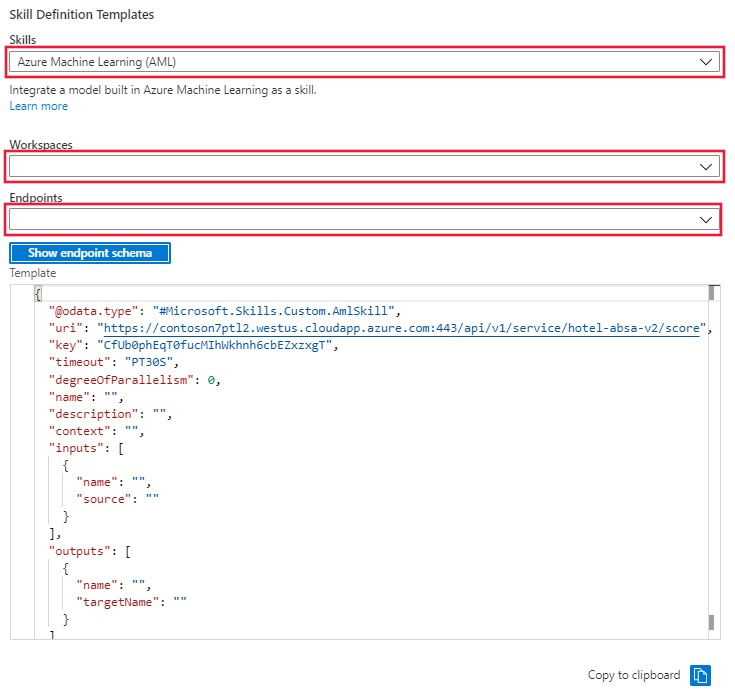
Kopieren Sie die Vorlage für Skillsetdefinition aus dem Fenster, und fügen Sie sie links in die Skillsetdefinition ein. Bearbeiten Sie die Vorlage, um die fehlenden Werte für Folgendes bereitzustellen:
- Name
- BESCHREIBUNG
- Kontext
- 'inputs'-Name und -Quelle
- 'outputs'-Name und targetName (Zielname)
Speichern Sie das Skillset.
Nachdem Sie das Skillset gespeichert haben, wechseln Sie zum Indexer, und wählen Sie den Link „Indexer-Definition (JSON)“ aus. Im Portal wird der JSON-Code des Indexers angezeigt, der in den ersten Zellen des Notebooks erstellt wurde. Die Ausgabefeldzuordnungen müssen mit zusätzlichen Feldzuordnungen aktualisiert werden, um sicherzustellen, dass der Indexer sie ordnungsgemäß verarbeiten und übergeben kann. Speichern Sie die Änderungen, und wählen Sie dann „Ausführen“ aus.
Bereinigen von Ressourcen
Wenn Sie in Ihrem eigenen Abonnement arbeiten, sollten Sie sich am Ende eines Projekts überlegen, ob Sie die erstellten Ressourcen noch benötigen. Ressourcen, die weiterhin ausgeführt werden, können Sie Geld kosten. Sie können entweder einzelne Ressourcen oder aber die Ressourcengruppe löschen, um den gesamten Ressourcensatz zu entfernen.
Ressourcen können im Portal über den Link Alle Ressourcen oder Ressourcengruppen im linken Navigationsbereich gesucht und verwaltet werden.
Denken Sie bei Verwendung eines kostenlosen Diensts an die Beschränkung auf maximal drei Indizes, Indexer und Datenquellen. Sie können einzelne Elemente über das Portal löschen, um unter dem Limit zu bleiben.