Schnellstart: Integrierte Vektorisierung (Vorschau)
Wichtig
Der Assistent zum Importieren und Vektorisieren von Daten befindet sich in der öffentlichen Vorschau unter Ergänzende Nutzungsbedingungen. Er zielt auf die REST-API 2023-10-01-Vorschauversion ab.
Erste Schritte mit der integrierten Vektorisierung (Vorschau) mithilfe des Assistenten zum Importieren und Vektorisieren von Daten im Azure-Portal. Dieser Assistent ruft ein Azure OpenAI-Texteinbettungsmodell auf, um Inhalte während der Indizierung und für Abfragen zu vektorisieren.
In dieser Vorschauversion des Assistenten:
Quelldaten sind nur Blobs, wobei der standardmäßige Analysemodus (ein Suchdokument pro Blob) verwendet wird.
Das Indexschema ist nicht konfigurierbar. Zu den Quellfeldern gehören
content(aufgeteilt und vektorisiert),metadata_storage_namefür den Titel und einmetadata_storage_pathfür den Dokumentschlüssel, der im Index alsparent_idangegeben wird.Die Vektorisierung ist Azure OpenAI-exklusiv (text-embedding-ada-002) und verwendet den HNSW-Algorithmus mit Standardwerten.
Die Aufteilung (Chunking) ist nicht konfigurierbar. Die effektiven Einstellungen sind:
textSplitMode: "pages", maximumPageLength: 2000, pageOverlapLength: 500
Voraussetzungen
Ein Azure-Abonnement. Erstellen Sie ein kostenloses Konto.
Azure AI Search, in jeder Region und auf jeder Ebene. Die meisten vorhandenen Dienste unterstützen die Vektorsuche. Bei einer kleinen Teilmenge der Dienste, die vor Januar 2019 erstellt wurden, schlägt die Erstellung eines Indexes mit Vektorfeldern fehl. In dieser Situation muss ein neuer Dienst erstellt werden.
Azure OpenAI-Endpunkt mit einer Bereitstellung von text-embedding-ada-002 und einem API-Schlüssel oder Berechtigungen von Cognitive Services OpenAI User für das Hochladen von Daten. Sie können nur einen Vektorizer in dieser Vorschau auswählen, und der Vektorizer muss Azure OpenAI sein.
Azure Storage-Konto, Standardleistung (allgemeine v2), Hot- und Cool-Zugriffsebenen.
Blobs, die nur Textinhalte, unstrukturierte Dokumente und Metadaten bereitstellen. In dieser Vorschau muss Ihre Datenquelle Azure-Blobs sein.
Leseberechtigungen für Azure Storage. Eine Speicherverbindungszeichenfolge, die einen Zugriffsschlüssel enthält, bietet Ihnen Lesezugriff auf Speicherinhalte. Wenn Sie stattdessen Microsoft Entra-Anmeldungen und -Rollen verwenden, stellen Sie sicher, dass die verwaltete Identität des Suchdiensts über die Storage-Blobdatenleser-Berechtigungen verfügt.
Alle Komponenten (Datenquellen- und Einbettungsendpunkt) müssen den öffentlichen Zugriff für die Portalknoten aktiviert haben, um darauf zugreifen zu können. Andernfalls schlägt der Assistent fehl. Nachdem der Assistent ausgeführt wurde, können Firewalls und private Endpunkte in den verschiedenen Integrationskomponenten zur Sicherheit aktiviert werden. Wenn bereits private Endpunkte vorhanden sind und nicht deaktiviert werden können, besteht die alternative Möglichkeit darin, den entsprechenden End-to-End-Flow von einem Skript oder Programm aus einem virtuellen Computer innerhalb desselben VNET wie der private Endpunkt auszuführen. Hier ist ein Python-Codebeispiel für die integrierte Vektorisierung. In demselben GitHub-Repository sind Beispiele in anderen Programmiersprachen.
Überprüfen des Speicherplatzes
Viele Kunden beginnen mit dem kostenlosen Dienst (Free). Der kostenlose Tarif ist auf drei Indizes, drei Datenquellen, drei Skillsets und drei Indexer beschränkt. Stellen Sie sicher, dass Sie über ausreichend Platz für zusätzliche Elemente verfügen, bevor Sie beginnen. In diesem Schnellstart wird jeweils eines dieser Objekte erstellt.
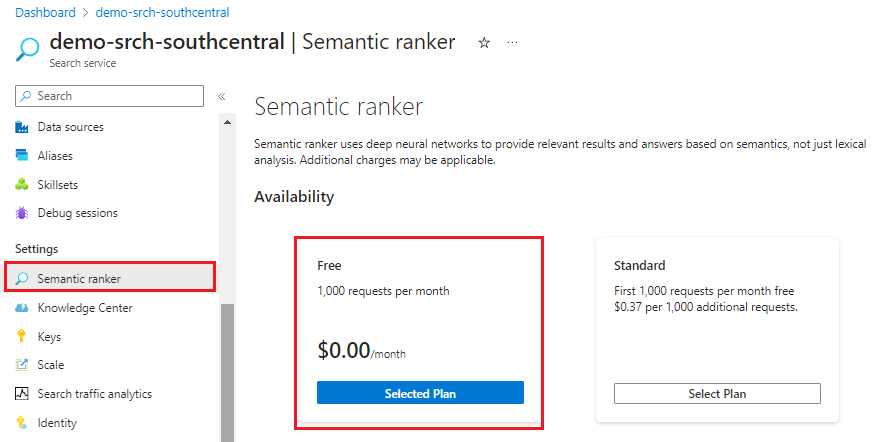
Überprüfen auf semantische Rangfolge
Dieser Assistent unterstützt die semantische Rangfolge, aber nur mit dem Tarif „Basic“ und höher, und nur, wenn die semantische Rangfolge bereits für Ihren Suchdienst aktiviert ist. Wenn Sie einen abrechenbaren Tarif verwenden, überprüfen Sie, ob die semantische Rangfolge aktiviert ist.
Vorbereiten der Beispieldaten
Dieser Abschnitt verweist auf Daten, die für diese Schnellstartanleitung funktionieren.
Melden Sie sich mit Ihrem Azure-Konto beim Azure-Portal an und wechseln Sie zu Ihrem Azure Storage-Konto.
Wählen Sie im Navigationsbereich unter Datenspeicher die Option Container aus.
Erstellen Sie einen neuen Container, und laden Sie dann die PDF-Dokumente für den Integritätsplan hoch, die für diese Schnellstartanleitung verwendet werden.
Bevor Sie das Azure Storage-Konto im Azure-Portal verlassen, erteilen Sie die Storage-Blob-Datenleseberechtigungen, vorausgesetzt, Sie möchten rollenbasierten Zugriff. Oder rufen Sie eine Verbindungszeichenfolge mit dem Speicherkonto von der Access-Schlüsselseite ab.
Abrufen von Verbindungsdetails für Azure OpenAI
Der Assistent benötigt einen Endpunkt, eine Bereitstellung von text-embedding-ada-002 und entweder einen API-Schlüssel oder eine verwaltete Suchdienstidentität mit Cognitive Services OpenAI User-Berechtigungen.
Melden Sie sich mit Ihrem Azure-Konto beim Azure-Portal an und wechseln Sie zu Ihrer Azure OpenAI-Ressource.
Kopieren Sie unter Schlüssel und Verwaltung den Endpunkt.
Kopieren Sie auf derselben Seite einen Schlüssel, oder überprüfen Sie das Zugriffssteuerelement, um Ihrer Suchdienstidentität Rollenmitglieder zuzuweisen.
Wählen Sie unter Modellbereitstellungen die Option Bereitstellungen verwalten aus, um Azure AI Studio zu öffnen. Kopieren Sie den Bereitstellungsnamen von text-embedding-ada-002.
Starten des Assistenten
Navigieren Sie zunächst zu Ihrem Azure AI Search-Dienst im Azure-Portal, und öffnen Sie den Assistenten zum Importieren und Vektorisieren von Daten.
Melden Sie sich mit Ihrem Azure-Konto beim Azure Portal an und wechseln Sie zu Ihrem Azure AI Search-Dienst.
Wählen Sie auf der Seite Übersicht die Option Importieren und Vektorisieren von Daten aus.

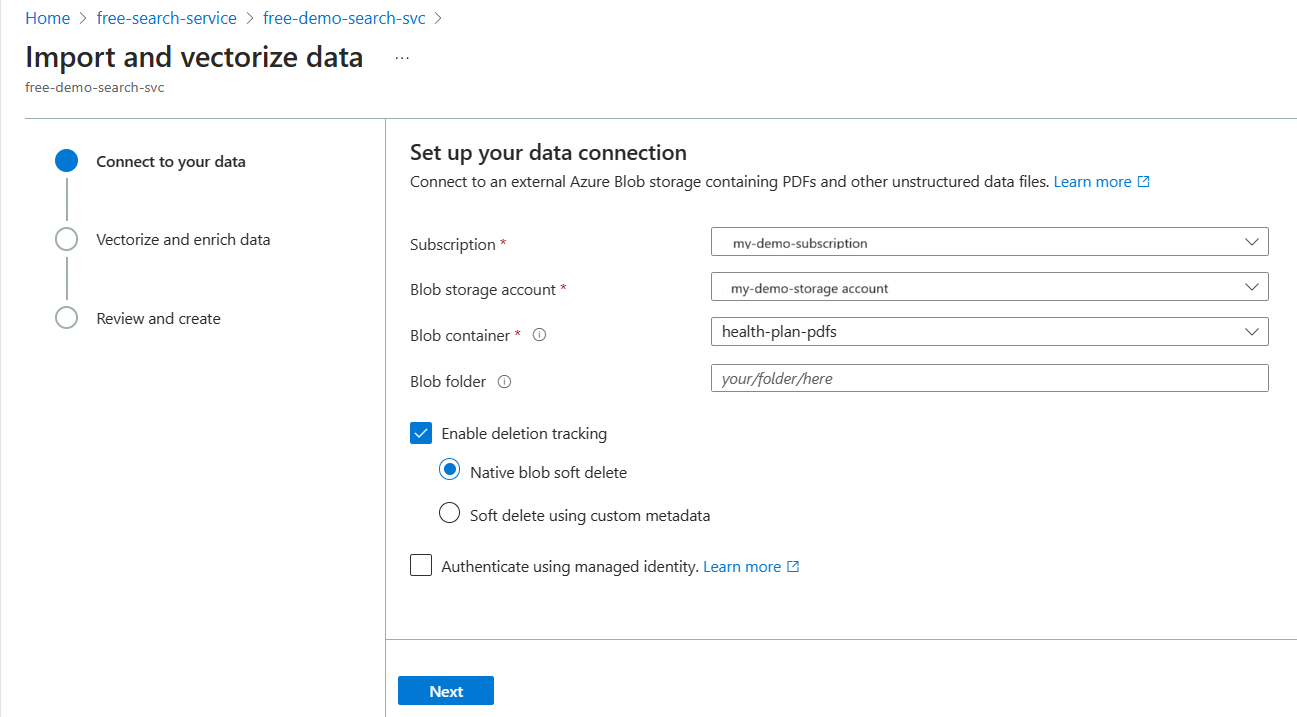
Herstellen einer Verbindung mit Ihren Daten
Der nächste Schritt besteht darin, eine Verbindung mit einer Datenquelle herzustellen, die für den Suchindex verwendet werden soll.
Erweitern Sie im Assistenten für Datenimport und -vektorisierung auf der Registerkarte Mit Ihren Daten verbinden die Dropdownliste Datenquelle, und wählen Sie Azure Blob Storage aus.
Geben Sie das Azure-Abonnement, das Speicherkonto und den Container an, der die Daten bereitstellt.
Stellen Sie für die Verbindung entweder eine Vollzugriffsverbindungszeichenfolge bereit, die einen Schlüssel enthält, oder geben Sie eine verwaltete Identität an, die über Berechtigungen für den Speicher-Blob-Datenleser für den Container verfügt.
Geben Sie an, ob Sie Löscherkennung wollen:
Wählen Sie Weiter: Vektorisieren und Anreichern, aus, um den Vorgang fortzusetzen.
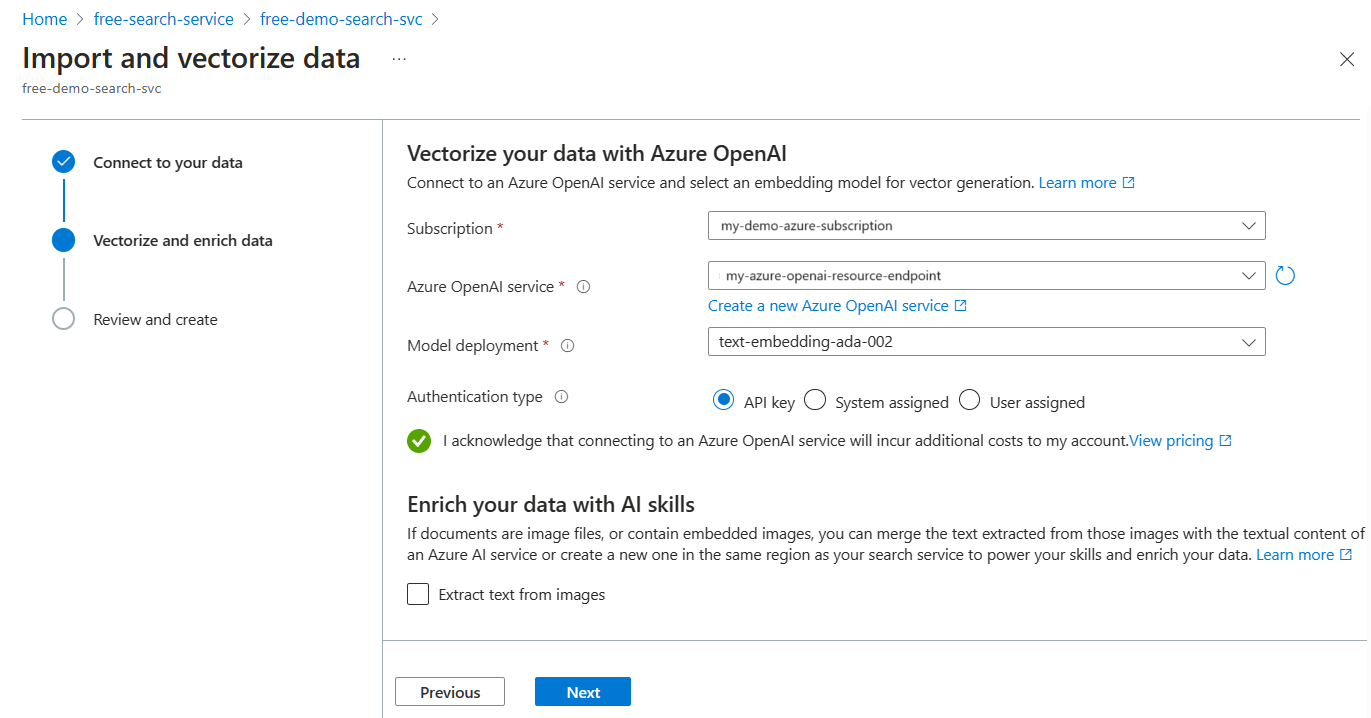
Anreichern und Vektorisieren ihrer Daten
Geben Sie in diesem Schritt das Einbettungsmodell an, das zum Vektorisieren der aufgeteilten Daten verwendet wird.
Geben Sie den Namen der Abonnement-, Endpunkt-, API-Schlüssel- und Modellbereitstellung an.
Optional können Sie binäre Bilder (z. B. gescannte Dokumentdateien) knacken und OCR verwenden, um Text zu erkennen.
Optional können Sie eine semantische Rangfolge hinzufügen, um die Ergebnisse am Ende der Abfrageausführung neu zu ranken, wobei die semantisch relevantesten Übereinstimmungen nach oben gestellt werden.
Geben Sie einen Laufzeitzeitplan für den Indexer an.
Wählen Sie Weiter: Erstellen und Überprüfen aus, um den Vorgang fortzusetzen.
Ausführen des Assistenten
In diesem Schritt werden die folgenden Objekte erstellt:
Datenquellenverbindung mit Ihrem BLOB-Container.
Index mit Vektorfeldern, Vektorizern, Vektorprofilen, Vektoralgorithmen. Sie werden nicht aufgefordert, den Standardindex während des Assistentenworkflows zu entwerfen oder zu ändern. Indizes entsprechen der 2023-10-01-Vorschauversion.
Skillset mit Teilungsfertigkeit für Aufteilung und AzureOpenAIEmbeddingModel für die Vektorisierung.
Indexer mit Feldzuordnungen und Ausgabefeldzuordnungen (falls zutreffend).
Wenn Fehler auftreten, überprüfen Sie zuerst die Berechtigungen. Sie benötigen Cognitive Services OpenAI-Benutzer für Azure OpenAI und Storage-Blobdatenleser in Azure Storage. Ihre Blobs müssen unstrukturiert sein (Datenblöcke werden aus der content-Eigenschaft des Blobs abgerufen).
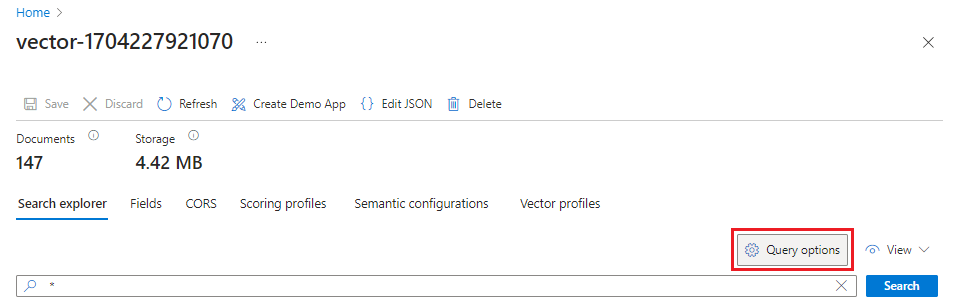
Überprüfen der Ergebnisse
Der Such-Explorer akzeptiert Textzeichenfolgen als Eingabe und vektorisiert dann den Text für die Ausführung von Vektorabfragen.
Wählen Sie Ihren Index aus.
Wählen Sie optional Abfrageoptionen aus, und blenden Sie Vektorwerte in den Suchergebnissen aus. Durch diesen Schritt werden die Suchergebnisse übersichtlicher.
Wählen Sie JSON-Ansicht aus, damit Sie Text für Ihre Vektorabfrage im text-Vektorabfrageparameter eingeben können.
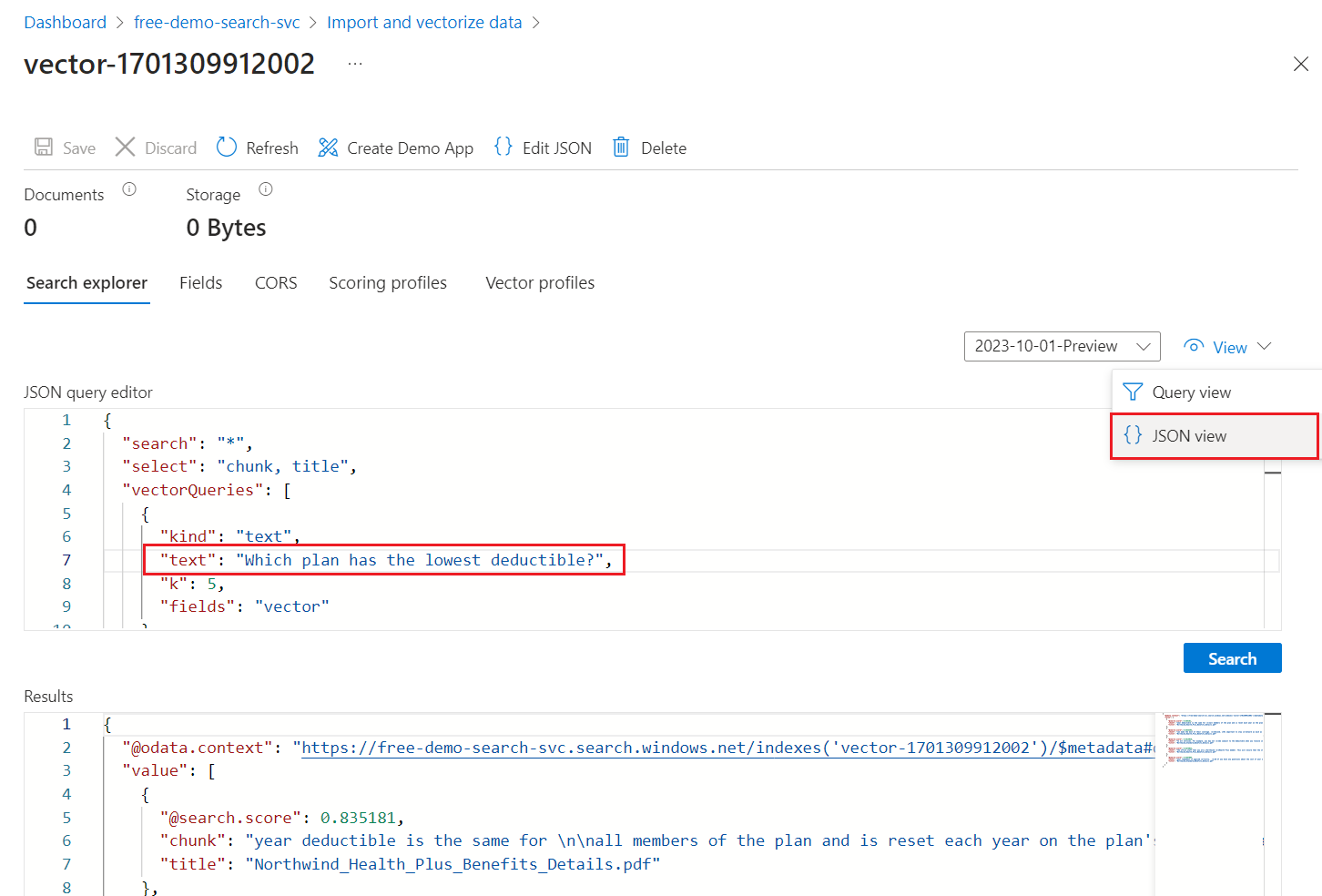
Dieser Assistent enthält eine Standardabfrage, die eine Vektorabfrage im Feld „vector“ ausgibt und die fünf nächsten Nachbarn zurückgibt. Wenn Sie Vektorwerte ausblenden, enthält Ihre Standardabfrage eine select-Anweisung, die das Vektorfeld aus den Suchergebnissen ausschließt.
{ "select": "chunk_id,parent_id,chunk,title", "vectorQueries": [ { "kind": "text", "text": "*", "k": 5, "fields": "vector" } ] }Ersetzen Sie den Text
"*"durch eine Frage im Zusammenhang mit Gesundheitsplänen, z. B. Welcher Plan hat die niedrigste Eigenbeteiligung?.Wählen Sie Suchen aus, um die Abfrage auszuführen.
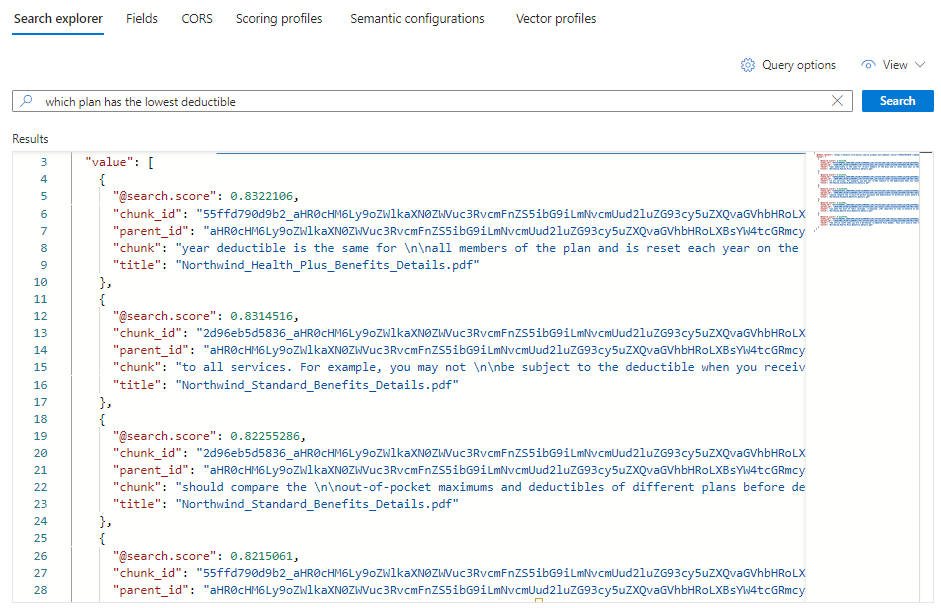
Es sollten fünf Übereinstimmungen angezeigt werden, wobei jedes Dokument ein Block der ursprünglichen PDF-Datei ist. Das Titelfeld zeigt an, aus welcher PDF-Datei der Block stammt.
Um alle Blöcke aus einem bestimmten Dokument anzuzeigen, fügen Sie einen Filter für das Titelfeld für eine bestimmte PDF-Datei hinzu:
{ "select": "chunk_id,parent_id,chunk,title", "filter": "title eq 'Benefit_Options.pdf'", "count": true, "vectorQueries": [ { "kind": "text", "text": "*", "k": 5, "fields": "vector" } ] }
Bereinigung
Azure AI Search ist eine abrechenbare Ressource. Wenn sie nicht mehr benötigt wird, löschen Sie sie aus Ihrem Abonnement, um Gebühren zu vermeiden.
Nächste Schritte
In dieser Schnellstartanleitung haben Sie den Assistenten zum Importieren und Vektorisieren von Daten eingeführt, der alle Objekte erstellt, die für die integrierte Vektorisierung erforderlich sind. Wenn Sie jeden Schritt im Detail untersuchen möchten, probieren Sie eines der integrierten Vektorisierungsbeispiele aus.