Service Fabric-Architektur
Service Fabric besteht aus Subsystemen, die auf verschiedenen Ebenen liegen. Diese Subsysteme ermöglichen Ihnen, Anwendungen mit folgenden Eigenschaften zu schreiben:
- Hoch verfügbar
- Skalierbar
- Verwaltbar
- Testbar
Das folgende Diagramm zeigt die wichtigsten Service Fabric-Subsysteme.
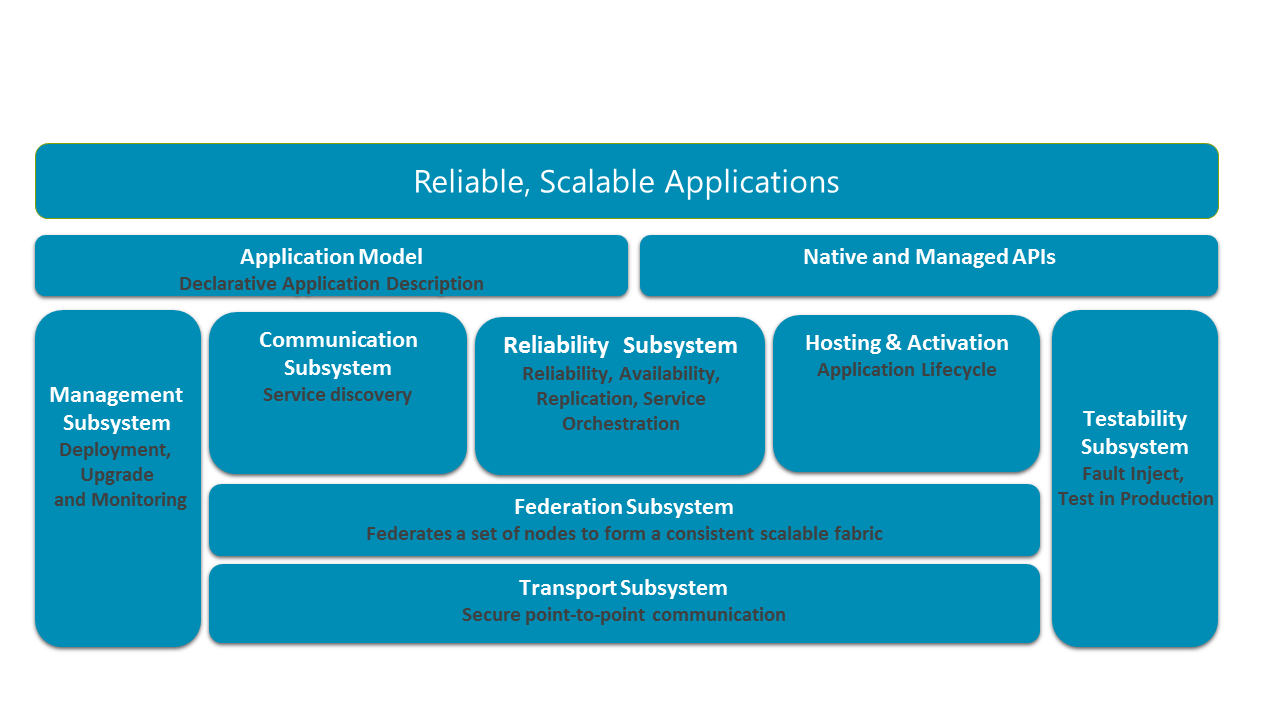
In einem verteilten System ist die Fähigkeit zur sicheren Kommunikation zwischen den Knoten in einem Cluster entscheidend. An der Basis des Stapels befindet sich das Transportsubsystem, das eine sichere Kommunikation zwischen Knoten bereitstellt. Über dem Transportsubsystem liegt das Verbundsubsystem, das die verschiedenen Knoten zu einer einzelnen Entität (einem sogenannten Cluster) verbindet. So kann Service Fabric Fehler erkennen, eine übergeordnete Instanz wählen (Leader Election) und Daten konsistent weiterleiten. Über dem Verbundsystem liegt das Zuverlässigkeitssubsystem, das für die Zuverlässigkeit der Service Fabric-Dienste verantwortlich ist. Hierbei werden Mechanismen wie Replikation, Ressourcenverwaltung und Failover genutzt. Über dem Verbundsubsystem liegt außerdem das Hosting- und Aktivierungssubsystem, das den Lebenszyklus einer Anwendung auf einem einzelnen Knoten verwaltet. Das Verwaltungssubsystem verwaltet den Lebenszyklus von Anwendungen und Diensten. Das Prüfbarkeitssubsystem unterstützt Anwendungsentwickler beim Testen von Diensten mit simulierten Fehlern, bevor die Anwendungen und Dienste in der Produktionsumgebung bereitgestellt werden und danach. Service Fabric bietet die Möglichkeit, Dienstspeicherorte über das Kommunikationssubsystem aufzulösen. Die für Entwickler verfügbaren Anwendungsprogrammiermodelle liegen zusammen mit dem Anwendungsmodell über diesen Subsystemen, um Tooling zu ermöglichen.
Transportsubsystem
Das Transportsubsystem implementiert einen Punkt-zu-Punkt-Kanal für die Datagramkommunikation. Dieser Kanal wird für die Kommunikation in Service Fabric-Clustern und zwischen Service Fabric-Clustern und -Clients verwendet. Der Kanal unterstützt unidirektionale Kommunikationsmodelle sowie solche nach dem Muster „Anforderung/Antwort“ und bildet so die Grundlage für das Implementieren von Broadcast und Multicast in der Verbundebene. Das Transportsubsystem sichert die Kommunikation mithilfe von X509-Zertifikaten oder der Windows-Sicherheit. Dieses Subsystem wird intern von Service Fabric verwendet und steht Entwicklern bei der Anwendungsprogrammierung nicht direkt zur Verfügung.
Verbundsubsystem
Um die Bedeutung einer Gruppe von Knoten in einem verteilten System beurteilen zu können, müssen Sie das gesamte System als Ganzes verstehen. Das Verbundsubsystem verwendet die vom Transportsubsystem bereitgestellten Kommunikationsstammfunktionen und fügt die verschiedenen Knoten zu einem einzelnen einheitlichen Cluster zusammen, der als Ganzes betrachtet wird. Es stellt die Stammfunktionen des verteilten Systems bereit, die von den anderen Subsystemen benötigt werden, d. h. Fehlererkennung, Leader Election und konsistente Weiterleitung. Das Verbundsubsystem baut auf verteilten Hashtabellen mit einem 128-Bit-Tokenbereich auf. Das Subsystem erstellt eine Ringtopologie über die Knoten, wobei jedem Knoten im Ring eine Teilmenge des Tokenspeichers zugeordnet wird. Zur Fehlererkennung verwendet die Ebene einen Leasing-Mechanismus, der auf Überwachung von Heart Beats und Vermittlung basiert. Das Verbundsubsystem stellt mit komplexen Beitritts- und Austrittsprotokollen sicher, dass jeweils nur ein Benutzer im Besitz des Tokens sein kann. Dies ist die Voraussetzung, um Leader Election und konsistente Weiterleitung garantieren zu können.
Zuverlässigkeitssubsystem
Das Zuverlässigkeitssubsystem stellt den Mechanismus für den Hochverfügbarkeitsstatus des Service Fabric-Diensts bereit. Hierbei werden der Replicator, der Failover-Manager und der Resource Balancer verwendet.
- Der Replicator stellt sicher, dass Statusänderungen im primären Dienstreplikat automatisch in sekundären Replikaten repliziert werden, um Konsistenz zwischen den primären und sekundären Replikaten in einer Replikatgruppe zu gewährleisten. Der Replicator ist für die Quorumverwaltung zwischen den Replikaten in der Replikatgruppe verantwortlich. Er interagiert mit der Failovereinheit, um die Liste der zu replizierenden Vorgänge abzurufen. Der Agent für die Neukonfiguration stellt die Konfiguration der Replikatgruppe bereit. Diese Konfiguration gibt an, auf welche Replikate die Vorgänge repliziert werden sollen. Der standardmäßige Replikator in Service Fabric heißt Fabric Replicator. Die Programmierungsmodell-API kann den Fabric Replicator verwenden, um hoch verfügbare und zuverlässige Dienste zu entwickeln.
- Der Failover-Manager stellt sicher, dass die Last automatisch auf die verfügbaren Knoten umverteilt wird, wenn Konten einem Cluster hinzugefügt oder aus dem Cluster entfernt werden. Fällt ein Knoten im Cluster aus, konfiguriert der Cluster die Dienstreplikate automatisch neu, um Verfügbarkeit zu gewährleisten.
- Resource Manager platziert Dienstreplikate in Fehlerdomänen im Cluster und stellt sicher, dass alle Failovereinheiten betriebsbereit sind. Der Ressourcen-Manager verteilt außerdem Dienstressourcen über den zugrunde liegenden gemeinsam verwendeten Pool von Clusterknoten, um eine optimale einheitliche Lastenverteilung zu erzielen.
Verwaltungssubsystem
Das Verwaltungssubsystem stellt den End-to-End-Dienst und die Lebenszyklusverwaltung für Anwendungen bereit. PowerShell-Cmdlets und Verwaltungs-APIs ermöglichen das Vorbereiten, Bereitstellen, Patchen, Upgraden und Löschen von Anwendungen ohne Verfügbarkeitsverlust. Das Verwaltungssubsystem nutzt hierzu folgende Dienste:
- Cluster Manager: Der primäre Dienst, der mit dem Failover-Manager aus dem Zuverlässigkeitssubsystem interagiert, um die Anwendungen auf den Knoten gemäß den Einschränkungen für die Dienstplatzierung zu platzieren. Der Ressourcen-Manager im Failoversubsystem stellt sicher, dass die Einschränkungen immer eingehalten werden. Der Cluster-Manager verwaltet den Lebenszyklus der Anwendungen von der Bereitstellung bis zum Aufheben der Bereitstellung. Er ist im Health Manager integriert, um sicherzustellen, dass die Anwendungsverfügbarkeit aus der Perspektive der semantischen Integrität während eines Upgrades nicht beeinträchtigt wird.
- Health Manager: Dieser Dienst ermöglicht die Überwachung der Integrität von Anwendungen, Diensten und Clusterentitäten. Clusterentitäten (z. B. Knoten, Dienstpartitionen und Replikate) können Zustandsinformationen melden, die dann im zentralen Integritätsspeicher aggregiert werden. Diese Integritätsinformationen bieten eine allgemeine Momentaufnahme der Integrität der Dienste und Knoten, die auf mehreren Knoten im Cluster verteilt sind. Anhand dieser Informationen können Sie erforderliche Korrekturmaßnahmen treffen. Zum Abfragen von Integritätsereignissen, die an das Integritätssubsystem gemeldet wurden, werden Integritätsabfrage-APIs verwendet. Die Integritätsabfrage-APIs geben die im Integritätsspeicher gespeicherten rohen Integritätsdaten oder die aggregierten, interpretierten Integritätsdaten für eine bestimmte Clusterentität zurück.
- Imagespeicher: Dieser Dienst ermöglicht das Speichern und Verteilen von Anwendungsbinärdateien. Der Dienst bietet einen einfachen verteilten Dateispeicher, in den die Anwendungen hochgeladen bzw. aus dem die Anwendungen heruntergeladen werden.
Hostingsubsystem
Der Cluster Manager informiert das Hostingsubsystem (auf jedem Knoten ausgeführt) über die Dienste, die er für das Verwalten eines bestimmten Knotens benötigt. Das Hostingsubsystem verwaltet dann die Lebenszyklus der Anwendung auf diesem Knoten. Es interagiert mit den Zuverlässigkeits- und Integritätskomponenten, um sicherzustellen, dass die Replikate ordnungsgemäß platziert sind und deren Integrität gewährleistet ist.
Kommunikationssubsystem
Dieses Subsystem sorgt mithilfe des Naming-Diensts für zuverlässiges Messaging und Diensterkennung. Der Naming-Dienst löst die Dienstnamen in einen Speicherort im Cluster auf und ermöglicht Benutzern, Dienstnamen und -eigenschaften zu verwalten. Durch Verwendung des Naming-Diensts können Clients mit allen Knoten im Cluster sicher kommunizieren, um Dienstnamen aufzulösen und Dienstmetadaten abzurufen. Service Fabric-Benutzer können mithilfe einer einfachen Naming-Client-API Dienste und Clients entwickeln, die den aktuellen Netzwerkstandort unabhängig von Knotendynamik oder Clustergröße auflösen können.
Prüfbarkeitssubsystem
Das Prüfbarkeitssubsystem besteht aus mehreren Tools, die speziell zum Testen von mit Service Fabric erstellten Diensten entwickelt wurden. Mit den Tools können Entwickler leicht aussagekräftige Fehler hervorrufen und Testszenarien ausführen, um die vielen Zustände und Übergänge zu schaffen und zu überprüfen, die für einen Dienst während seiner Lebensdauer gelten können. Dabei ist jederzeit für die erforderliche Kontrolle und Sicherheit gesorgt. Das Prüfbarkeitssubsystem bietet außerdem einen Mechanismus für das Ausführen langer Testläufe, in denen mehrere mögliche Fehler ohne Verfügbarkeitsverlust durchlaufen werden. Hierfür wird Ihnen eine Testproduktionsumgebung bereitgestellt.