Übersicht über die Architektur des Clusterressourcen-Managers
Der Clusterressourcen-Manager von Service Fabric ist ein zentraler Dienst, der im Cluster ausgeführt wird. Er verwaltet den gewünschten Status des Diensts im Cluster, insbesondere in Bezug auf Ressourcenverbrauch und Platzierungsregeln.
Um die Ressourcen in Ihrem Cluster zu verwalten, benötigt der Clusterressourcen-Manager von Service Fabric verschiedene Informationen:
- Die derzeit vorhandenen Dienste
- Den aktuellen (oder standardmäßigen) Ressourcenverbrauch der einzelnen Dienste
- Die verbleibende Clusterkapazität
- Die Kapazität der Knoten im Cluster
- Die Menge der Ressourcen, die von den einzelnen Knoten verbraucht werden
Die Ressourcennutzung eines bestimmten Diensts kann sich mit der Zeit ändern, und Dienste beanspruchen meist mehr als nur einen Ressourcentyp. Dienstübergreifend können sowohl reale, physische als auch logische Ressourcen gemessen werden. Dienste können physische Metriken wie Arbeitsspeicher- oder Datenträgerspeichernutzung nachverfolgen. Häufiger benötigen Dienste logische Metriken, z.B. „WorkQueueDepth“ oder „TotalRequests“. In einem Cluster können sowohl logische als auch physische Metriken verwendet werden. Metriken können für viele Dienste gemeinsam oder speziell für einen bestimmten Dienst verwendet werden.
Weitere Überlegungen
Die Besitzer und die Operatoren des Clusters können sich von den Dienst- und Anwendungsautoren unterscheiden; zumindest kann es sich um bestimmte Personen handeln, die verschiedene Rollen ausführen. Beim Entwickeln Ihrer Anwendung sind Ihnen einige ihrer Anforderungen bereits bekannt. Sie kennen annähernd die verbrauchten Ressourcen und wissen, wie unterschiedliche Dienste bereitgestellt werden sollten. Auf der Webebene müssen beispielsweise Knoten ausgeführt werden, die für das Internet verfügbar sind, während dies für die Datenbankdienste nicht der Fall ist. Ein weiteres Beispiel: Für die Webdienste gelten möglicherweise CPU- und Netzwerkbeschränkungen, während bei Diensten der Datenebene eher Arbeitsspeicherverbrauch und Datenträgernutzung eine Rolle spielen. Die Person, die sich an einem Livestandort für diesen Dienst in der Produktion mit einem Incident befasst oder ein Upgrade für den Service verwaltet, hat jedoch ganz andere Aufgaben und benötigt andere Tools.
Sowohl der Cluster als auch die Dienste sind dynamisch:
- Die Anzahl von Knoten im Cluster kann steigen und sinken.
- Knoten von verschiedenen Größen und Typen können hinzukommen und entfernt werden.
- Dienste können erstellt oder entfernt werden, und ihre gewünschten Ressourcenzuteilungen und Platzierungsregeln können geändert werden.
- Upgrades oder andere Verwaltungsvorgänge können im Cluster auf der Anwendungs- oder der Infrastrukturebene erfolgen.
- Ausfälle können jederzeit auftreten.
Komponenten und Datenfluss des Clusterressourcen-Managers
Der Clusterressourcen-Manager muss die Anforderungen der einzelnen Dienste sowie die Nutzung von Ressourcen durch die einzelnen Dienstobjekte in diesen Diensten verfolgen. Der Clusterressourcen-Manager besteht aus zwei konzeptionellen Teilen: aus Agents, die auf den einzelnen Knoten ausgeführt werden, und aus einem fehlertoleranten Dienst. Die Agents auf den einzelnen Knoten verfolgen Auslastungsberichte von Diensten, fassen sie zusammen und übermitteln sie in regelmäßigen Abständen. Der Clusterressourcen-Manager-Dienst aggregiert alle Informationen von den lokalen Agents und reagiert basierend auf seiner aktuellen Konfiguration.
Betrachten Sie das folgende Diagramm:
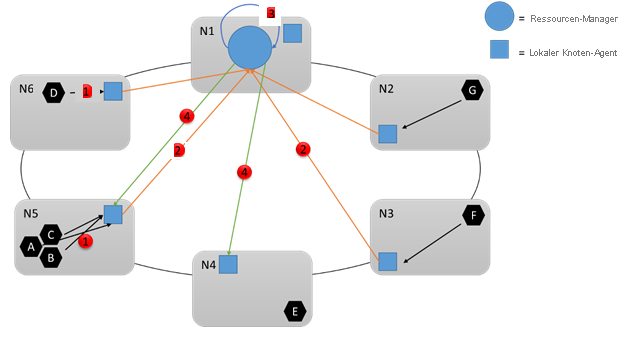
Es gibt viele Änderungen, die während der Laufzeit auftreten können. Nehmen wir beispielsweise an, dass sich der Umfang der Ressourcen ändert, die von manchen Diensten genutzt werden, dass einige Dienste ausfallen und dass einige Knoten dem Cluster beitreten oder ihn verlassen. Alle Änderungen auf einem Knoten werden gesammelt und regelmäßig an den zentralen Clusterressourcen-Manager-Dienst (1,2) gesendet, wo sie erneut zusammengefasst, analysiert und gespeichert werden. Mit einem Intervall von einigen wenigen Sekunden untersucht dieser Dienst die Änderungen und ermittelt, ob Aktionen erforderlich sind (3). Er könnte z.B. feststellen, dass dem Cluster einige leere Knoten hinzugefügt wurden. Er entscheidet daher, einige Dienste auf diese Knoten zu verschieben. Der Clusterressourcen-Manager könnte aber auch bemerken, dass ein bestimmter Knoten überlastet ist oder dass bestimmte Dienste ausgefallen sind oder gelöscht wurden, und Ressourcen an anderer Stelle freigeben.
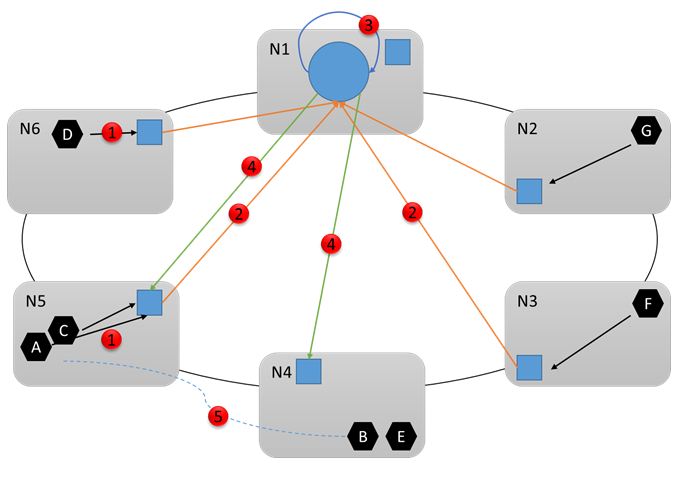
Betrachten Sie das folgende Diagramm, und sehen Sie sich an, was als Nächstes geschieht. Nehmen wir an, der Clusterressourcen-Manager ermittelt, dass Änderungen erforderlich sind. Er koordiniert sich mit anderen Systemdiensten (insbesondere dem Failover-Manager), um die erforderlichen Änderungen vorzunehmen. Anschließend werden die notwendigen Befehle an die entsprechenden Knoten gesendet (4). Angenommen, der Ressourcen-Manager hat festgestellt, dass Node5 überlastet war und daher entschieden, Dienst B von Node5 auf Node4 zu verschieben. Am Ende der Neukonfiguration (5) sieht der Cluster folgendermaßen aus:
Nächste Schritte
- Der Clusterressourcen-Manager bietet zahlreiche Optionen zum Beschreiben des Clusters. Weitere Informationen hierzu finden Sie in diesem Artikel zum Beschreiben eines Service Fabric-Clusters.
- Die primären Aufgaben des Clusterressourcen-Managers bestehen im erneuten Ausgleichen des Clusters und im Erzwingen von Platzierungsregeln. Weitere Informationen zum Konfigurieren dieses Verhaltens finden Sie unter Lastenausgleich für Service Fabric-Cluster