Einführung in die Service Fabric-Integritätsüberwachung
Mit Azure Service Fabric wird ein Integritätsmodell eingeführt, das eine umfassende, flexible und erweiterbare Integritätsevaluierung und -berichterstellung bietet. Mithilfe dieses Modells lässt sich der Zustand des Clusters und der darin ausgeführten Dienste nahezu in Echtzeit überwachen. Sie können mühelos Integritätsdaten ermitteln und potenzielle Probleme beheben, bevor sie sich ausbreiten und umfangreiche Ausfälle verursachen. In einem typischen Modell senden die Dienste Berichte basierend auf ihren lokalen Informationen. Anhand dieser Informationen wird ein Gesamtüberblick auf Clusterebene erstellt.
Die Service Fabric-Komponenten verwenden dieses umfangreiche Integritätsmodell, um ihren aktuellen Zustand zu melden. Sie können den gleichen Mechanismus verwenden, um Integritätsberichte für Anwendungen zu erstellen. Wenn Sie in hochwertige Integritätsberichte zur Erfassung Ihrer individuellen Bedingungen investieren, können Sie Probleme für Ihre ausgeführte Anwendung viel leichter erkennen und beheben.
Hinweis
Das Integritätssubsystem wurde ursprünglich für das Überwachen von Upgrades eingeführt. Service Fabric bietet überwachte Anwendungs- und Clusterupgrades mit uneingeschränkter Verfügbarkeit, ohne Ausfallzeit und mit minimaler oder sogar ganz ohne Benutzerinteraktion. Um diese Ziele zu erreichen, überprüft das Upgrade die Integrität anhand der konfigurierten Aktualisierungsrichtlinien. Ein Upgrade kann nur dann fortgesetzt werden, wenn die gewünschten Schwellenwerte für die Integrität berücksichtigt werden. Werden die Schwellenwerte nicht erfüllt, wird entweder automatisch ein Rollback des Upgrades durchgeführt oder das Upgrade angehalten, damit Administratoren das Problem beheben können. Weitere Informationen zu Anwendungsupgrades finden Sie in diesem Artikel.
Integritätsspeicher
Der Integritätsspeicher speichert integritätsbezogene Informationen zu Entitäten im Cluster, um Informationen auf einfache Weise abrufen und evaluieren zu können. Er ist als persistent zustandsbehafteter Service Fabric-Dienst implementiert, um Hochverfügbarkeit und Skalierbarkeit zu bieten. Der Integritätsspeicher ist Teil der Anwendung fabric:/System und verfügbar, sobald der Cluster eingerichtet wurde und ausgeführt wird.
Integritätsentitäten und Hierarchie
Die Integritätsentitäten werden in einer logischen Hierarchie organisiert, die Interaktionen und Abhängigkeiten zwischen verschiedenen Entitäten erfasst. Der Integritätsspeicher erstellt die Entitäten und die Hierarchie basierend auf den von den Service Fabric-Komponenten gesendeten Berichten automatisch.
Die Integritätsentitäten spiegeln die Service Fabric-Entitäten wider. (Beispielsweise entspricht die Integritätsentität einer Anwendung einer im Cluster bereitgestellten Anwendungsinstanz, und die Integritätsentität eines Knotens entspricht einem Service Fabric-Clusterknoten.) Die Integritätshierarchie erfasst die Interaktionen der Systementitäten, und dies ist die Grundlage für die erweiterte Integritätsevaluierung. Informationen zu den grundlegenden Service Fabric-Konzepten finden Sie unter Technische Übersicht über Service Fabric. Weitere Informationen zu Anwendungen finden Sie unter Service Fabric-Anwendungsmodell.
Die Integritätsentitäten und die Hierarchie ermöglichen das effektive Melden, Debuggen und Überwachen des Clusters und der Anwendungen. Das Integritätsmodell ermöglicht eine exakte, differenzierte Darstellung der Integrität der zahlreichen beweglichen Bestandteile eines Clusters.
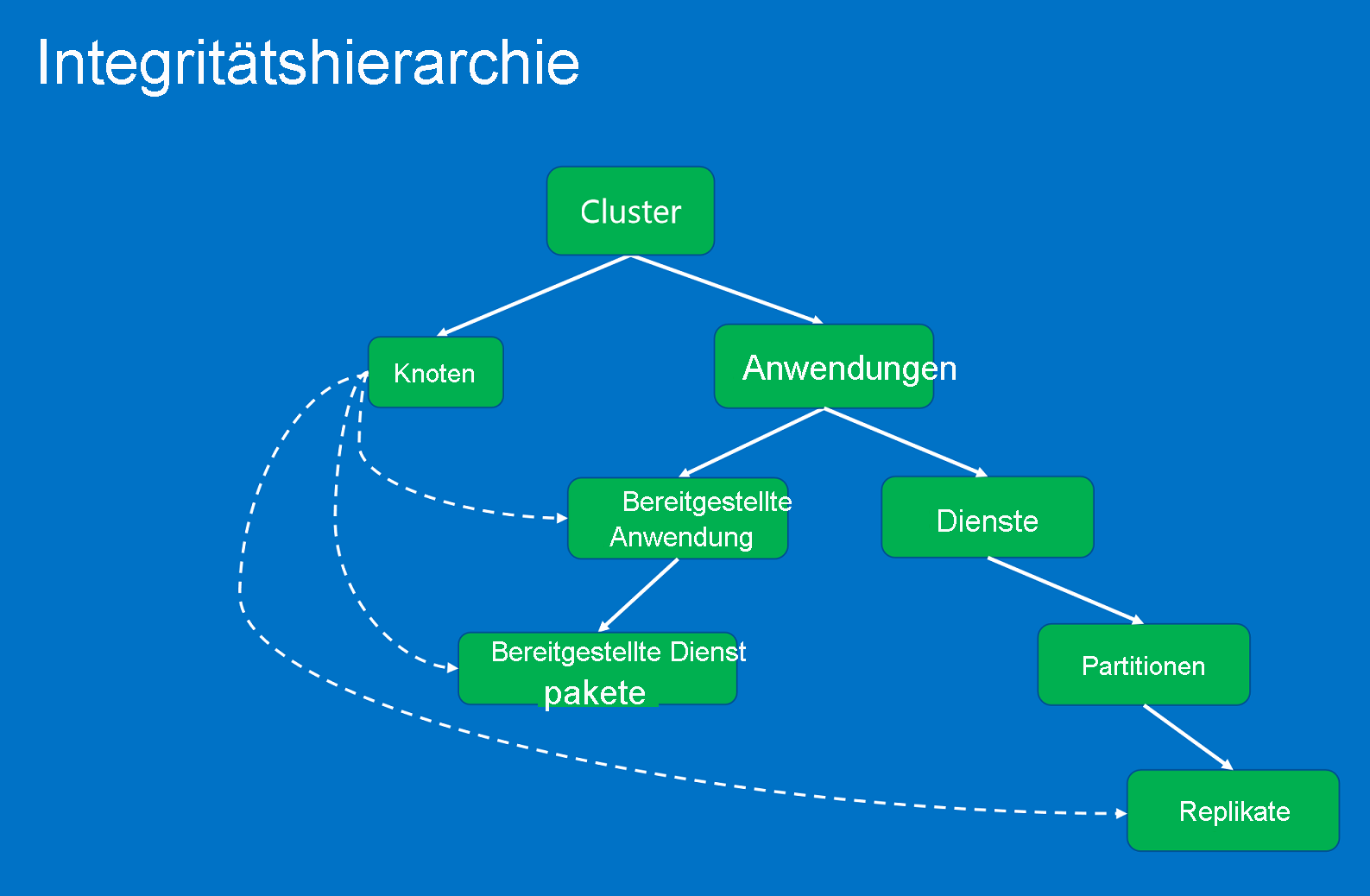 Die Integritätseinheiten, die in einer Hierarchie auf der Grundlage von Beziehungen zwischen übergeordneten und untergeordneten Elementen organisiert sind.
Die Integritätseinheiten, die in einer Hierarchie auf der Grundlage von Beziehungen zwischen übergeordneten und untergeordneten Elementen organisiert sind.
Zu den Integritätsentitäten zählen Folgende:
- Cluster. Stellt die Integrität eines Service Fabric-Clusters dar. Clusterintegritätsberichte beschreiben Bedingungen, die Auswirkungen auf den gesamten Cluster haben. Diese Bedingungen wirken sich auf mehrere Entitäten im Cluster oder auf den Cluster selbst aus. Aufgrund des Zustands kann der Reporter das Problem nicht auf ein oder mehrere fehlerhafte untergeordnete Elemente eingrenzen. Beispiele hierfür sind das Split-Brain-Syndrom des Clusters aufgrund von Problemen mit der Netzwerkpartitionierung oder der Kommunikation.
- Node: Stellt die Integrität eines Service Fabric-Knotens dar. In Knotenintegritätsberichten werden Bedingungen beschrieben, die sich auf die Knotenfunktionen auswirken. Sie wirken sich normalerweise auf alle bereitgestellten Entitäten aus, die darauf ausgeführt werden. Beispiele hierfür sind Knoten ohne verbleibenden Festplattenplatz (oder andere computerweite Eigenschaften, z.B. Arbeitsspeicher, Verbindungen) oder der Ausfall eines Knotens. Die Knotenentität wird anhand des Knotennamens (Zeichenfolge) identifiziert.
- Anwendung. Stellt die Integrität einer im Cluster ausgeführten Anwendungsinstanz dar. In Berichten zur Anwendungsintegrität werden Bedingungen beschrieben, die sich auf die Gesamtintegrität der Anwendung auswirken. Sie können nicht auf einzelne untergeordnete Elemente (Dienste oder bereitgestellte Anwendungen) eingegrenzt werden. Ein Beispiel hierfür ist die End-to-End-Interaktion zwischen verschiedenen Diensten in der Anwendung. Die Anwendungsentität wird anhand des Anwendungsnamens (URI) identifiziert.
- Dienst. Stellt die Integrität eines im Cluster ausgeführten Diensts dar. In Berichten zur Dienstintegrität werden Bedingungen beschrieben, die sich auf die Gesamtintegrität des Diensts auswirken. Der Reporter kann das Problem nicht auf eine fehlerhafte Partition oder ein fehlerhaftes Replikat eingrenzen. Ein Beispiel hierfür ist eine Dienstkonfiguration (z. B. ein Port oder eine externe Dateifreigabe), die in allen Partitionen Probleme verursacht. Die Dienstentität wird anhand des Dienstnamens (URI) identifiziert.
- Partition. Stellt die Integrität einer Dienstpartition dar. Partitionsintegritätsberichte beschreiben Bedingungen, die Auswirkungen auf die gesamte Replikatgruppe haben. Beispiele hierfür sind eine Anzahl der Replikate unterhalb der Zielanzahl und eine Partition mit Quorumverlust. Die Entität für die Partition wird anhand der Partitions-ID (GUID) identifiziert.
- Replica: Stellt die Integrität eines zustandsbehafteten Dienstreplikats oder einer zustandslosen Dienstinstanz dar. Dies ist die kleinste Einheit einer Anwendung, für die Watchdogs und Systemkomponenten Berichte erstellen können. Das Replikat ist die kleinste Einheit, für das Watchdogs und Systemkomponenten Berichte für eine Anwendung erstellen können. Beispiele für zustandsbehaftete Dienste sind ein primäres Replikat, das Vorgänge nicht an sekundäre Replikate replizieren kann, oder eine langsame Replikation. Die Replikatentität wird anhand der Partitions-ID (GUID) und der Replikat- bzw. Instanz-ID (lang) identifiziert.
- DeployedApplication. Stellt die Integrität einer auf einem Knoten ausgeführten Anwendung dar. Integritätsberichte zu bereitgestellten Anwendungen beschreiben Bedingungen, die sich auf die Anwendung auf dem Knoten beziehen; das Eingrenzen auf Dienstpakete, die im gleichen Knoten bereitgestellt sind, ist nicht möglich. Beispiele: Fehler, wenn das Anwendungspaket nicht auf den Knoten heruntergeladen werden kann, oder Probleme beim Einrichten der Sicherheitsprinzipale der Anwendung auf dem Knoten. Die bereitgestellte Anwendung wird anhand des Anwendungsnamens (URI) und des Knotennamens (Zeichenfolge) identifiziert.
- DeployedServicePackage. Stellt die Integrität des Dienstpakets dar, das auf einem Knoten im Cluster ausgeführt wird. Es beschreibt Bedingungen, die sich auf das Dienstpaket beziehen und keine Auswirkungen auf andere Dienstpakete haben, die für die gleiche Anwendung auf demselben Knoten bereitgestellt sind. Beispiele hierfür sind ein Codepaket im Dienstpaket, das nicht gestartet werden kann, und ein Konfigurationspaket, das nicht gelesen werden kann. Das bereitgestellte Dienstpaket wird anhand von Anwendungsname (URI), Knotenname (Zeichenfolge), Dienstmanifestname (Zeichenfolge) und Dienstpaketaktivierungs-ID (Zeichenfolge) identifiziert.
Die Granularität des Integritätsmodells erleichtert das Erkennen und Beheben von Problemen. Wenn ein Dienst beispielsweise nicht reagiert, kann gemeldet werden, dass die Anwendungsinstanz nicht „integer“ (also fehlerhaft) ist. Eine Berichterstellung auf dieser Ebene ist nicht optimal, da das Problem unter Umständen nicht alle Dienste innerhalb dieser Anwendung betrifft. Der Bericht sollte auf den fehlerhaften Dienst oder eine bestimmte untergeordnete Partition angewendet werden, falls weitere Informationen auf diese Partition hindeuten. Die Daten werden automatisch in der Hierarchie angezeigt, und eine fehlerhafte Partition wird auf Dienst- und Anwendungsebene sichtbar gemacht. Durch diese Aggregierung kann die zugrunde liegende Ursache des Problems schneller ermittelt und behoben werden.
Die Integritätshierarchie besteht aus Beziehungen zwischen übergeordneten und untergeordneten Elementen. Ein Cluster besteht aus Knoten und Anwendungen. Anwendungen verfügen über Dienste und bereitgestellte Anwendungen. Bereitgestellte Anwendungen verfügen über bereitgestellte Pakete. Dienste verfügen über Partitionen, wobei jede Partition über ein oder mehrere Replikate verfügt. Zwischen Knoten und bereitgestellten Entitäten besteht eine besondere Beziehung. Ein von der übergeordneten Systemkomponente (Failover-Manager-Dienst) als fehlerhaft gemeldeter Knoten hat Auswirkungen auf die darauf bereitgestellten Anwendungen, Dienstpakete und Replikate.
Die Integritätshierarchie stellt den aktuellen Zustand des Systems basierend auf den aktuellen Integritätsberichten dar, d. h., die Informationen sind nahezu in Echtzeit verfügbar. Interne und externe Watchdogs können auf der Grundlage von anwendungsspezifischer Logik oder benutzerdefinierten überwachten Bedingungen Berichte zu den gleichen Entitäten erstellen. Benutzerberichte können zusammen mit den Systemberichten verwendet werden.
Setzen Sie sich bei der Gestaltung eines umfangreichen Clouddiensts mit der Frage auseinander, wie Integritätsprobleme gemeldet und behandelt werden sollen. Diese vorab geleistete Investition vereinfacht das Debuggen, die Überwachung und den Betrieb des Diensts.
Integritätszustände
Service Fabric verwendet drei Zustände, um die Integrität einer Entität zu beschreiben: „OK“, „Warning“ und „Error“. In jedem Bericht, der an den Integritätsspeicher gesendet wird, ist einer der Zustände angegeben. Das Ergebnis der Integritätsevaluierung ist einer dieser Zustände.
Mögliche Integritätszustände :
- OK. Die Entität ist fehlerfrei. Es wurden keine bekannten Probleme für das Element oder eines seiner untergeordneten Elemente (falls zutreffend) gemeldet.
- Warnung. Die Entität weist einige Probleme auf, kann jedoch weiterhin ordnungsgemäß funktionieren. Beispiel: Es treten Verzögerungen auf, diese bewirken jedoch bislang noch keine Funktionsprobleme. In einigen Fällen kann die Warnungsbedingung ohne externe Eingriffe von selbst aufgehoben werden. In diesen Fällen bewirken Integritätsberichte die Bekanntgabe des Problems und bieten Einblicke in die stattfindenden Vorgänge. In anderen Fällen kann sich die Warnungsbedingung ohne Benutzereingriff zu einem schwerwiegenden Problem entwickeln.
- Error. Die Entität ist fehlerhaft. Eine fehlerhafte Entität funktioniert nicht richtig, und der fehlerhafte Zustand der Entität muss durch einen Benutzereingriff behoben werden.
- Unknown. Die Entität ist im Integritätsspeicher nicht vorhanden. Dieses Ergebnis kann über die verteilten Abfragen abgerufen werden, mit denen Ergebnisse mehrerer Komponenten zusammengeführt werden. Die Abfrage zum Abrufen der Knotenliste wird beispielsweise an FailoverManager, ClusterManager und HealthManager gesendet, die Abfrage zum Abrufen der Anwendungsliste dagegen wird an ClusterManager und HealthManager gesendet. Diese Abfragen führen die Ergebnisse aus mehreren Systemkomponenten zusammen. Gibt eine andere Systemkomponente eine Entität zurück, die im Integritätsspeicher nicht vorhanden ist, besitzt das zusammengeführte Ergebnis einen unbekannten Integritätszustand. Eine Entität befindet sich nicht im Speicher, da Integritätsberichte noch nicht verarbeitet wurden oder die Entität nach dem Löschen bereinigt wurde.
Integritätsrichtlinien
Der Integritätsspeicher wendet Integritätsrichtlinien an, um basierend auf den Berichten und untergeordneten Elementen einer Entität festzustellen, ob die Entität fehlerfrei ist.
Hinweis
Integritätsrichtlinien werden im Clustermanifest (für die Integritätsevaluierung von Cluster und Knoten) oder im Anwendungsmanifest (für die Evaluierung einer Anwendung und der untergeordneten Elemente) angegeben. Integritätsevaluierungsanforderungen können auch benutzerdefinierte Richtlinien zur Integritätsevaluierung übergeben, die nur für diese eine Evaluierung verwendet werden.
Standardmäßig wendet Service Fabric strenge Regeln (alles muss fehlerfrei sein) auf hierarchische Beziehungen von über- und untergeordneten Elementen an. Wenn auch nur eines der untergeordneten Elemente ein fehlerhaftes Ereignis aufweist, wird das übergeordnete Element als fehlerhaft angesehen.
Clusterintegritätsrichtlinie
Die Clusterintegritätsrichtlinie wird zum Auswerten des Integritätszustands des Clusters und der Knoten verwendet. Die Richtlinie kann im Clustermanifest definiert werden. Falls sie nicht vorhanden ist, wird die Standardrichtlinie (keine Fehler zulässig) verwendet.
Die Clusterintegritätsrichtlinie enthält Folgendes:
ConsiderWarningAsError. Gibt an, ob während der Integritätsevaluierung Integritätsberichte mit dem Ergebnis „Warning“ als Fehler zu behandeln sind. Standardwert: false.
MaxPercentUnhealthyApplications. Gibt den maximal tolerierten Prozentsatz an Anwendungen an, die fehlerhaft sein können, bevor der Cluster als fehlerhaft behandelt wird.
MaxPercentUnhealthyNodes. Gibt den maximal tolerierten Prozentsatz an Knoten an, die fehlerhaft sein können, bevor der Cluster als fehlerhaft behandelt wird. Beim Konfigurieren dieses Prozentsatzes muss berücksichtigt werden, dass in großen Clustern immer einige Knoten inaktiv oder aufgrund von Wartungsarbeiten nicht verfügbar sind.
ApplicationTypeHealthPolicyMap. Die Zuordnung der Anwendungstyp-Integritätsrichtlinie kann während der Clusterintegritätsevaluierung verwendet werden, um spezielle Anwendungstypen zu beschreiben. Standardmäßig werden alle Anwendungen in einen Pool eingefügt und anhand von MaxPercentUnhealthyApplications bewertet. Sollte bei bestimmten Anwendungstypen eine abweichende Behandlung erforderlich sein, können diese vom globalen Pool ausgenommen werden. Sie werden dann stattdessen auf der Grundlage der Prozentwerte bewertet, die dem Namen ihres Anwendungstyps in der Zuordnung zugeordnet sind. Beispielsweise enthält ein Cluster Tausende von Anwendungen mit unterschiedlichen Typen und wenige Steueranwendungsinstanzen eines besonderen Anwendungstyps. Die Steueranwendungen dürfen niemals einen Fehlerstatus aufweisen. Sie können den globalen MaxPercentUnhealthyApplications-Wert auf 20 Prozent festlegen, um einige Fehler zu tolerieren, für den Anwendungstyp „ControlApplicationType“ muss der MaxPercentUnhealthyApplications-Wert jedoch auf „0“ festgelegt werden. Wenn einige der zahlreichen Anwendungen fehlerhaft sind, aber unter dem globalen Prozentsatz für fehlerhafte Anwendungen liegen, wird der Cluster mit einer Warnung ausgewertet. Der Integritätszustand „Warnung“ wirkt sich nicht auf ein Clusterupgrade oder auf andere Überwachungen aus, die durch den Integritätszustand „Fehler“ ausgelöst werden. Weist aber auch nur eine einzelne Steueranwendung den Zustand „Fehler“ auf, ist der gesamte Cluster fehlerhaft, was je nach Upgradekonfiguration zu einem Rollback oder zum Anhalten des Clusters führt. Für die in der Zuordnung definierten Anwendungstypen werden alle Anwendungsinstanzen aus dem globalen Anwendungspool entfernt. Sie werden anhand des speziellen MaxPercentUnhealthyApplications-Werts aus der Zuordnung basierend auf der Gesamtanzahl von Anwendungen des Anwendungstyps ausgewertet. Die restlichen Anwendungen verbleiben im globalen Pool und werden mit MaxPercentUnhealthyApplications ausgewertet.
Das folgende Beispiel zeigt einen Auszug aus einem Clustermanifest. Ordnen Sie dem Parameternamen „ApplicationTypeMaxPercentUnhealthyApplications-“ gefolgt von dem Namen des Anwendungstyps als Präfixe zu, um Einträge in der Anwendungstypzuordnung zu definieren.
<FabricSettings> <Section Name="HealthManager/ClusterHealthPolicy"> <Parameter Name="ConsiderWarningAsError" Value="False" /> <Parameter Name="MaxPercentUnhealthyApplications" Value="20" /> <Parameter Name="MaxPercentUnhealthyNodes" Value="20" /> <Parameter Name="ApplicationTypeMaxPercentUnhealthyApplications-ControlApplicationType" Value="0" /> </Section> </FabricSettings>NodeTypeHealthPolicyMap. Die Zuordnung der Knotentyp-Integritätsrichtlinie kann während der Clusterintegritätsevaluierung verwendet werden, um spezielle Knotentypen zu beschreiben. Die Knotentypen werden auf der Grundlage der Prozentwerte bewertet, die dem Namen ihres Knotentyps in der Zuordnung zugeordnet sind. Das Festlegen dieses Werts hat keine Auswirkung auf den globalen Pool von Knoten, der fürMaxPercentUnhealthyNodesverwendet wird. Ein Cluster hat z. B. Hunderte von Knoten verschiedener Typen und einige Knotentypen, die wichtige Aufgaben hosten. Es sollten keine Knoten mit diesem Typ ausfallen. Sie können die globalenMaxPercentUnhealthyNodesauf 20 % festlegen, um einige Ausfälle bei allen Knoten zuzulassen, für den KnotentypSpecialNodeTypelegen SieMaxPercentUnhealthyNodesjedoch auf 0 fest. Wenn einige der zahlreichen Knoten fehlerhaft sind, aber unter dem globalen Prozentsatz für fehlerhafte Knoten liegen, ergibt die Auswertung des Clusters, dass er sich im Integritätszustand „Warnung“ befindet. Der Integritätszustand „Warnung“ wirkt sich nicht auf ein Clusterupgrade oder auf andere Überwachungen aus, die durch den Integritätszustand „Fehler“ ausgelöst werden. Aber auch ein Knoten vom TypSpecialNodeTypemit dem Integritätszustand „Fehler“ führt dazu, dass der Cluster fehlerhaft ist, und löst je nach Upgradekonfiguration ein Rollback aus oder hält das Clusterupgrade an. Umgekehrt würde das Festlegen des globalenMaxPercentUnhealthyNodesauf 0 und das Festlegen des maximalen Prozentsatzes fehlerhafterSpecialNodeType-Knoten auf 100 mit einem Knoten vom TypSpecialNodeTypein einem Fehlerzustand weiterhin den Cluster in einen Fehlerzustand versetzen, da die globale Einschränkung in diesem Fall strenger ist.Das folgende Beispiel zeigt einen Auszug aus einem Clustermanifest. Zum Definieren von Einträgen in der Knotentypzuordnung stellen Sie dem Parameternamen das Präfix „NodeTypeMaxPercentUnhealthyNodes-“ gefolgt vom Knotentypnamen voran.
<FabricSettings> <Section Name="HealthManager/ClusterHealthPolicy"> <Parameter Name="ConsiderWarningAsError" Value="False" /> <Parameter Name="MaxPercentUnhealthyApplications" Value="20" /> <Parameter Name="MaxPercentUnhealthyNodes" Value="20" /> <Parameter Name="NodeTypeMaxPercentUnhealthyNodes-SpecialNodeType" Value="0" /> </Section> </FabricSettings>
Anwendungsintegritätsrichtlinie
Die Anwendungsintegritätsrichtlinie beschreibt, wie die Auswertung von Ereignissen und Aggregationen der Zustände von untergeordneten Elementen für eine Anwendung und ihre untergeordneten Elemente erfolgen soll. Diese Richtlinie kann im Anwendungsmanifest ( ApplicationManifest.xml) im Anwendungspaket definiert werden. Wenn keine Richtlinien angegeben sind, geht Service Fabric davon aus, dass die Entität fehlerhaft ist, sofern sie über einen Integritätsbericht oder ein untergeordnetes Element mit dem Integritätsstatus „Warning“ oder „Error“ verfügt. Die folgenden Richtlinien sind konfigurierbar:
- ConsiderWarningAsError. Gibt an, ob während der Integritätsevaluierung Integritätsberichte mit dem Ergebnis „Warning“ als Fehler zu behandeln sind. Standardwert: false.
- MaxPercentUnhealthyDeployedApplications. Gibt den maximal tolerierten Prozentsatz an bereitgestellten Anwendungen an, die fehlerhaft sein können, bevor eine Anwendung als fehlerhaft behandelt wird. Zur Berechnung dieses Prozentsatzes wird die Anzahl fehlerhafter bereitgestellter Anwendungen durch die Anzahl von Knoten geteilt, auf denen die Anwendungen derzeit im Cluster bereitgestellt sind. Die Berechnung wird aufgerundet, um einen Fehler auf einer kleinen Anzahl von Knoten zu tolerieren. Standardprozentsatz : null.
- DefaultServiceTypeHealthPolicy. Gibt die standardmäßige Diensttyp-Integritätsrichtlinie an, die die Standardintegritätsrichtlinie für alle Diensttypen in der Anwendung ersetzt.
- ServiceTypeHealthPolicyMap. Bietet eine Übersicht über Dienstintegritätsrichtlinien pro Diensttyp. Diese Richtlinien ersetzen die standardmäßigen Diensttyp-Integritätsrichtlinien für die angegebenen Diensttypen. Wenn also beispielsweise eine Anwendung einen zustandslosen Gatewaydiensttyp und einen zustandsbehafteten Engine-Diensttyp besitzt, können Sie für deren Evaluierung unterschiedliche Integritätsrichtlinien konfigurieren. Wenn Sie die Richtlinie pro Diensttyp angeben, können Sie die Integrität des Diensts genauer steuern.
Diensttyp-Integritätsrichtlinie
Die Diensttyp-Integritätsrichtlinie gibt an, wie die Dienste und die untergeordneten Elemente von Diensten ausgewertet und aggregiert werden sollen. Die Richtlinie enthält Folgendes:
- MaxPercentUnhealthyPartitionsPerService. Gibt den maximal tolerierten Prozentsatz an fehlerhaften Partitionen an, ab dem ein Dienst als fehlerhaft angesehen wird. Standardprozentsatz : null.
- MaxPercentUnhealthyReplicasPerPartition. Gibt den maximal tolerierten Prozentsatz an fehlerhaften Replikaten an, ab dem eine Partition als fehlerhaft angesehen wird. Standardprozentsatz : null.
- MaxPercentUnhealthyServices. Gibt den maximal tolerierten Prozentsatz an fehlerhaften Diensten an, ab dem eine Anwendung als fehlerhaft angesehen wird. Standardprozentsatz : null.
Das folgende Beispiel zeigt einen Auszug aus einem Anwendungsmanifest:
<Policies>
<HealthPolicy ConsiderWarningAsError="true" MaxPercentUnhealthyDeployedApplications="20">
<DefaultServiceTypeHealthPolicy
MaxPercentUnhealthyServices="0"
MaxPercentUnhealthyPartitionsPerService="10"
MaxPercentUnhealthyReplicasPerPartition="0"/>
<ServiceTypeHealthPolicy ServiceTypeName="FrontEndServiceType"
MaxPercentUnhealthyServices="0"
MaxPercentUnhealthyPartitionsPerService="20"
MaxPercentUnhealthyReplicasPerPartition="0"/>
<ServiceTypeHealthPolicy ServiceTypeName="BackEndServiceType"
MaxPercentUnhealthyServices="20"
MaxPercentUnhealthyPartitionsPerService="0"
MaxPercentUnhealthyReplicasPerPartition="0">
</ServiceTypeHealthPolicy>
</HealthPolicy>
</Policies>
Integritätsevaluierung
Benutzer und automatisierte Dienste können die Integrität einer beliebigen Entität jederzeit evaluieren. Um die Integrität einer Entität zu evaluieren, aggregiert der Integritätsspeicher alle Integritätsberichte für die Entität und wertet alle untergeordneten Elemente (falls zutreffend) aus. Der Algorithmus für die Integritätsaggregation verwendet Integritätsrichtlinien, die angeben, wie Integritätsberichte ausgewertet und die Zustände untergeordneter Elemente aggregiert werden sollen (falls zutreffend).
Aggregation von Integritätsberichten
Eine Entität kann mehrere Integritätsberichte aufweisen, die von unterschiedlichen Berichterstattern (Systemkomponenten oder Watchdogs) für verschiedene Eigenschaften gesendet wurden. Die Aggregation verwendet die zugehörigen Integritätsrichtlinien, insbesondere das ConsiderWarningAsError-Element einer Anwendungs- oder Clusterintegritätsrichtlinie. „ConsiderWarningAsError“ gibt an, wie Warnungen ausgewertet werden sollen.
Der aggregierte Integritätszustand wird durch die schlechtesten Integritätsberichte für die Entität ausgelöst. Wenn mindestens ein Integritätsbericht mit dem Ergebnis „Error“ vorliegt, lautet der aggregierte Integritätszustand „Error“.
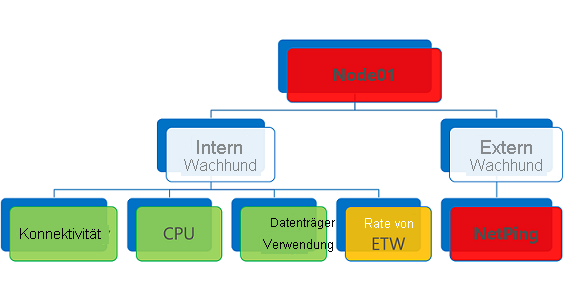
Eine Integritätsentität, für die mindestens ein Integritätsbericht mit dem Ergebnis „Error“ vorliegt, wird als fehlerhaft interpretiert. Gleiches gilt für einen abgelaufen Integritätsbericht (unabhängig von dessen Integritätszustand).
Wenn keine Fehler berichtet werden und eine oder mehrere Warnungen vorliegen, lautet der aggregierte Integritätszustand je nach Flag der ConsiderWarningsAsError-Richtlinie entweder „Warning“ oder „Error“.
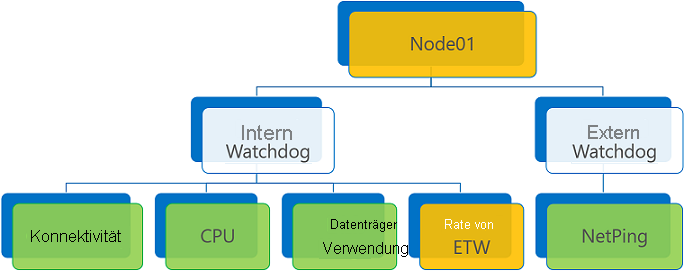
Aggregation der Integritätsberichte mit dem Ergebnis „Warning“ und der Einstellung „false“ (Standard) für ConsiderWarningAsError
Aggregation der untergeordneten Integrität
Der aggregierte Integritätszustand einer Entität spiegelt die Zustände der untergeordneten Elemente wider (falls zutreffend). Der Algorithmus zum Aggregieren von Integritätszuständen untergeordneter Elemente verwendet die Integritätsrichtlinien basierend auf dem Entitätstyp.

Aggregation untergeordneter Elemente basierend auf Integritätsrichtlinien
Nachdem der Integritätsspeicher alle untergeordneten Elemente ausgewertet hat, werden deren Integritätszustände auf der Grundlage des konfigurierten maximalen Prozentsatzes für fehlerhafte untergeordnete Elemente aggregiert. Dieser Prozentsatz wird der Richtlinie auf der Grundlage der Entität und der Art des untergeordneten Elements entnommen.
- Wenn alle untergeordneten Elemente den Zustand „OK“ aufweisen, lautet der aggregierte Integritätszustand „OK“.
- Wenn sowohl untergeordnete Elemente mit dem Status „OK“ als auch mit dem Status „Warning“ vorliegen, lautet der aggregierte Integritätszustand „Warning“.
- Wenn untergeordnete Elemente mit dem Status „Error“ vorliegen und der maximal zulässige Prozentsatz für fehlerhafte untergeordnete Elemente überschritten wird, lautet der aggregierte Integritätszustand des übergeordneten Elements „Error“.
- Wenn untergeordnete Elemente mit dem Zustand „Error“ vorliegen und der maximal zulässige Prozentsatz für fehlerhafte untergeordnete Elemente nicht überschritten wird, lautet der aggregierte Integritätszustand des übergeordneten Elements „Warning“.
Integritätsberichterstellung
Berichte für Service Fabric-Entitäten können von Systemkomponenten, System Fabric-Anwendungen und internen/externen Watchdogs erstellt werden. Die Berichterstatter führen eine lokale Ermittlung der Integrität der überwachten Entitäten basierend auf den Bedingungen durch, die sie überwachen. Globale Zustände oder aggregierte Daten werden von den Berichterstattern nicht berücksichtigt. Das Ziel sind einfache Berichterstatter und keine komplexen Gebilde, die zahlreiche Aspekte prüfen müssen, um zu entscheiden, welche Informationen gesendet werden sollen.
Um die Integritätsdaten an den Integritätsspeicher zu senden, muss ein Berichterstatter die betroffene Entität identifizieren und einen Integritätsbericht erstellen. Um den Bericht zu senden, verwenden Sie die FabricClient.HealthClient.ReportHealth-API, die in den Objekten Partition bzw. CodePackageActivationContext verfügbar gemachten Berichtsintegritäts-APIs, PowerShell-Cmdlets oder REST.
Integritätsberichte
Die Integritätsberichte für die einzelnen Entitäten im Cluster enthalten die folgenden Informationen:
SourceId. Eine Zeichenfolge, die den Berichterstatter des Integritätsereignisses eindeutig identifiziert.
Entitätsbezeichner. Identifiziert die Entität, für die der Bericht erstellt wird. Er unterscheidet sich abhängig vom Entitätstyp:
- Cluster: Keine.
- Knoten: Knotenname (Zeichenfolge).
- Anwendung: Anwendungsname (URI). Stellt den Namen der im Cluster bereitgestellten Anwendungsinstanz dar.
- Dienst: Dienstname (URI). Stellt den Namen der im Cluster bereitgestellten Dienstinstanz dar.
- Partition: Partitions-ID (GUID). Stellt den eindeutigen Bezeichner der Partition dar.
- Replikat: Die ID des zustandsbehafteten Dienstreplikats oder die ID der zustandslosen Dienstinstanz (INT64).
- DeployedApplication: Anwendungsname (URI) und Knotenname (Zeichenfolge).
- DeployedServicePackage: Anwendungsname (URI), Knotenname (Zeichenfolge) und Dienstmanifestname (Zeichenfolge).
Eigenschaft. Ein Zeichenfolge (keine feste Enumeration), mit der Berichtersteller das Integritätsereignis für eine bestimmte Eigenschaft der Entität kategorisieren. Beispiel: Reporter A kann einen Integritätsbericht für die Eigenschaft „Storage“ von Node01 erstellen, und Reporter B kann einen Integritätsbericht für die Eigenschaft „Connectivity“ von Node01 erstellen. Im Integritätsspeicher werden diese Berichte als separate Integritätsereignisse für die Entität „Node01“ behandelt.
Beschreibung. Eine Zeichenfolge, die es einem Berichterstatter ermöglicht, detaillierte Informationen zum Integritätsereignis bereitzustellen. Die Verwendung von SourceId, Property und HealthState reicht in der Regel aus, um den Bericht vollständig zu beschreiben. Mit der Beschreibung werden dem Bericht für Menschen lesbare Informationen hinzugefügt. Der Text macht den Integritätsbericht für Administratoren und Benutzer leichter verständlich.
HealthState. Eine Enumeration, die den Integritätszustand des Berichts beschreibt. Zulässige Werte sind "Ok", "Warning" und "Error".
TimeToLive. Ein Zeitraum, der angibt, wie lange der Integritätsbericht gültig ist. In Kombination mit RemoveWhenExpired weist dieser Wert den Integritätsspeicher an, wie abgelaufene Ereignisse ausgewertet werden sollen. Der Zeitraum ist standardmäßig unendlich, und der Bericht ist immer gültig.
RemoveWhenExpired. Ein boolescher Wert. Wenn dieser Wert auf „true“ festgelegt ist, wird der abgelaufene Integritätsbericht automatisch aus dem Integritätsspeicher entfernt, und der Bericht wirkt sich nicht auf die Integritätsevaluierung der Entität aus. Wird verwendet, wenn der Bericht nur für einen bestimmten Zeitraum gilt und der Berichterstatter den Bericht nicht explizit bereinigen muss. Das Verfahren wird auch zum Löschen von Berichten aus dem Integritätsspeicher verwendet (z. B. wird ein Watchdog geändert und beendet das Senden von Berichten für die vorherige Quelle und Eigenschaft). Hierbei kann ein Bericht mit einer kurzen TimeToLive zusammen mit RemoveWhenExpired gesendet werden, um alle vorherigen Zustände aus dem Integritätsspeicher zu löschen. Wenn der Wert auf „false“ festgelegt ist, wird der abgelaufene Bericht bei der Integritätsevaluierung als Fehler („Error“) behandelt. Mit dem Wert „false“ wird für den Integritätsspeicher angegeben, dass die Quelle regelmäßig Berichte zu dieser Eigenschaft senden soll. Wenn dies nicht der Fall ist, muss ein Fehler für den Watchdog vorliegen. Die Integrität des Watchdogs wird berücksichtigt, indem das Ereignis als Fehler behandelt wird.
SequenceNumber. Eine positive ganze Zahl, mit der die Reihenfolge der Berichte dargestellt wird und die daher stetig erhöht wird. Der Wert wird vom Integritätsspeicher verwendet, um überfällige Berichte zu ermitteln, die wegen Netzwerkverzögerungen oder anderen Problemen verspätet empfangen werden. Ein Bericht wird abgelehnt, wenn die Sequenznummer kleiner oder gleich der zuletzt angewendeten Nummer für dieselbe Entität, Quelle und Eigenschaft ist. Wenn sie nicht angegeben wird, wird die Sequenznummer automatisch generiert. Die Sequenznummer muss nur angegeben werden, wenn Berichte zu Statusübergängen erstellt werden. In diesem Fall muss für die Quelle gespeichert werden, welche Berichte gesendet werden, und die Informationen müssen für die Wiederherstellung bei einem Failover vorgehalten werden.
Die vier Informationselemente – SourceId, Entitätsbezeichner, Property und HealthState – sind für jeden Integritätsbericht erforderlich. Die SourceId-Zeichenfolge darf nicht mit dem Präfix System. beginnen, da dieses Präfix Systemberichten vorbehalten ist. Für eine Entität wird für dieselbe Quelle und Eigenschaft nur ein Bericht verwendet. Mehrere Berichte für die gleiche Quelle und Eigenschaft überschreiben sich gegenseitig – entweder aufseiten des Integritätsclients (bei einem Batch) oder aufseiten des Integritätsspeichers. Das Überschreiben erfolgt anhand von Sequenznummern. Neuere Berichte (mit höheren Sequenznummern) überschreiben ältere Berichte.
Integritätsereignisse
Intern werden im Integritätsspeicher Integritätsereignissegespeichert, die alle Informationen aus den Berichten sowie zusätzliche Metadaten enthalten. Die Metadaten enthalten auch den Zeitpunkt, zu dem der Bericht an den Integritätsclient übergeben wurde, sowie den Zeitpunkt der Änderung auf der Serverseite. Die Integritätsereignisse werden von Integritätsabfragenzurückgegeben.
Die hinzugefügten Metadaten enthalten Folgendes:
- SourceUtcTimestamp. Gibt den Zeitpunkt an, an dem der Bericht an den Integritätsclient übergeben wurde (Coordinated Universal Time).
- LastModifiedUtcTimestamp. Gibt die Uhrzeit der letzten Änderung des Berichts auf der Serverseite (Coordinated Universal Time) an.
- IsExpired. Ein Flag, mit dem angegeben wird, ob der Bericht zum Zeitpunkt der Ausführung der Abfrage durch den Integritätsspeicher bereits abgelaufen war. Ein Ereignis kann nur ablaufen, wenn RemoveWhenExpired auf „false“ festgelegt ist. Andernfalls wird das Ereignis von der Abfrage nicht zurückgegeben und aus dem Speicher entfernt.
- LastOkTransitionAt, LastWarningTransitionAt, LastErrorTransitionAt. Zeitpunkt des letzten Übergangs des Zustands „OK“/„Warning“/„Error“. Diese Felder geben den Verlauf der Integritätszustandsübergänge für das Ereignis an.
Die Felder für die Zustandsübergänge können für erweiterte Warnungen verwendet werden und geben Verlaufsinformationen für das Integritätsereignis an. Sie ermöglichen beispielsweise folgende Szenarien:
- Warnung ausgeben, wenn der Zustand einer Eigenschaft länger als X Minuten den Zustand „Warning/Error“ aufweist: Die zeitlich begrenzte Überprüfung der Bedingung ermöglicht die Vermeidung von Warnungen bei vorübergehenden Bedingungen. So kann beispielsweise eine Warnung, wenn der Gesundheitszustand seit mehr als fünf Minuten auf Warnung steht, als (HealthState == Warning and Now - LastWarningTransitionTime > 5 Minuten) interpretiert werden.
- Warnung nur zu Bedingungen ausgeben, die sich in den letzten X Minuten geändert haben: Wenn ein Bericht schon vor dem angegebenen Zeitpunkt den Zustand „Error“ erreicht hat, kann er ignoriert werden, da dies bereits signalisiert wurde.
- Beim Wechsel des Zustands einer Eigenschaft zwischen „Warning“ und „Error“ bestimmen, wie lange die Eigenschaft fehlerhaft (nicht „OK“) war. So kann beispielsweise eine Warnung, wenn die Eigenschaft seit mehr als fünf Minuten nicht mehr gesund ist, als (HealthState != Ok und Now - LastOkTransitionTime > 5 Minuten) interpretiert werden.
Beispiel: Melden und Evaluieren der Anwendungsintegrität
Im folgenden Beispiel wird über PowerShell ein Integritätsbericht zur Anwendung fabric:/WordCount aus der Quelle MyWatchdog gesendet. Der Integritätsbericht enthält Informationen zur Integritätseigenschaft „Availability“, die den Integritätszustand „Error“ und den TimeToLive-Wert „Infinite“ aufweist. Anschließend wird die Anwendungsintegrität abgefragt. Die Abfrage gibt den aggregierten Integritätszustand „Error“ und die gemeldeten Integritätsereignisse in der Liste mit den Integritätsereignissen zurück.
PS C:\> Send-ServiceFabricApplicationHealthReport –ApplicationName fabric:/WordCount –SourceId "MyWatchdog" –HealthProperty "Availability" –HealthState Error
PS C:\> Get-ServiceFabricApplicationHealth fabric:/WordCount -ExcludeHealthStatistics
ApplicationName : fabric:/WordCount
AggregatedHealthState : Error
UnhealthyEvaluations :
Error event: SourceId='MyWatchdog', Property='Availability'.
ServiceHealthStates :
ServiceName : fabric:/WordCount/WordCountService
AggregatedHealthState : Error
ServiceName : fabric:/WordCount/WordCountWebService
AggregatedHealthState : Ok
DeployedApplicationHealthStates :
ApplicationName : fabric:/WordCount
NodeName : _Node_0
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_2
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_3
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_4
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_1
AggregatedHealthState : Ok
HealthEvents :
SourceId : System.CM
Property : State
HealthState : Ok
SequenceNumber : 360
SentAt : 3/22/2016 7:56:53 PM
ReceivedAt : 3/22/2016 7:56:53 PM
TTL : Infinite
Description : Application has been created.
RemoveWhenExpired : False
IsExpired : False
Transitions : Error->Ok = 3/22/2016 7:56:53 PM, LastWarning = 1/1/0001 12:00:00 AM
SourceId : MyWatchdog
Property : Availability
HealthState : Error
SequenceNumber : 131032204762818013
SentAt : 3/23/2016 3:27:56 PM
ReceivedAt : 3/23/2016 3:27:56 PM
TTL : Infinite
Description :
RemoveWhenExpired : False
IsExpired : False
Transitions : Ok->Error = 3/23/2016 3:27:56 PM, LastWarning = 1/1/0001 12:00:00 AM
Verwendung des Integritätsmodells
Das Integritätsmodell ermöglicht die Skalierung der Clouddienste und der zugrundeliegenden Service Fabric-Plattform, da die Überwachung und Ermittlung der Integrität auf verschiedene Überwachungselemente im Cluster verteilt werden. Andere Systeme verfügen über einen einzelnen zentralen Dienst auf Clusterebene, der alle potenziell nützlichen Informationen analysiert, die von Diensten ausgegeben werden. Dieser Ansatz beeinträchtigt die Skalierbarkeit. Außerdem können keine spezifischen Informationen gesammelt werden, um die Grundursache von Problemen oder potenziellen Problemen so weit wie möglich einzugrenzen.
Das Integritätsmodell wird hauptsächlich für die Überwachung und Diagnose, Evaluierung der Cluster- und Anwendungsintegrität und Überwachung von Upgrades verwendet. Andere Dienste nutzen die Integritätsdaten, um automatische Reparaturen durchzuführen, Verläufe der Clusterintegrität zu erstellen und Warnungen bei bestimmten Bedingungen auszugeben.
Nächste Schritte
Anzeigen von Service Fabric-Integritätsberichten
Verwenden von Systemintegritätsberichten für die Problembehandlung
Melden und Überprüfen der Dienstintegrität
Hinzufügen von benutzerdefinierten Service Fabric-Integritätsberichten