Beheben von Fehlern beim Ausführen eines Failovers einer VMware-VM oder eines physischen Computers nach Azure
Achtung
Dieser Artikel bezieht sich auf CentOS, eine Linux-Distribution, die sich dem End-of-Life-Status (EOL) nähert. Sie sollten Ihre Nutzung entsprechend planen. Weitere Informationen finden Sie im CentOS End-of-Life-Leitfaden.
Bei einem Failover eines virtuellen Computers nach Azure tritt eventuell einer der folgenden Fehler auf. Gehen Sie für die Problembehandlung gemäß den für den jeweiligen Fehlerzustand beschriebenen Schritten vor.
Fehler beim Failover mit der Fehler-ID 28031
Site Recovery konnte eine VM, für die ein Failover ausgeführt wurde, nicht in Azure erstellen. Dies kann aus einem der folgenden Gründe auftreten:
Das verfügbare Kontingent reicht nicht zum Erstellen des virtuellen Computers: Sie können das verfügbare Kontingent unter „Abonnement“ > „Nutzung + Kontingente“ prüfen. Sie können eine neue Supportanfrage eröffnen, um das Kontingent zu erhöhen.
Sie versuchen, ein Failover für VMs unterschiedlicher Größensätze in derselben Verfügbarkeitsgruppe durchzuführen. Verwenden Sie unbedingt dieselben Größen Familien für alle virtuellen Computer in derselben Verfügbarkeitsgruppe. Sie können die Größe ändern, indem Sie zu den Einstellungen Compute des virtuellen Computers navigieren. Wiederholen Sie das Failover anschließend.
Eine Richtlinie für das Abonnement verhindert die Erstellung einer VM. Ändern Sie die Richtlinie, um das Erstellen eines virtuellen Computers zuzulassen, und wiederholen dann das Failover.
Fehler beim Failover mit der Fehler-ID 28092
Site Recovery konnte für die VM, für die ein Failover ausgeführt wurde, keine Netzwerkschnittstelle erstellen. Stellen Sie sicher, dass Sie in Ihrem Abonnement über ein ausreichendes Kontingent zum Erstellen von Netzwerkschnittstellen verfügen. Sie können das verfügbare Kontingent unter „Abonnement“ > „Nutzung + Kontingente“ prüfen. Sie können eine neue Supportanfrage eröffnen, um das Kontingent zu erhöhen. Wenn Sie über ein ausreichendes Kontingent verfügen, ist dies möglicherweise nur ein vorübergehendes Problem. Wiederholen Sie den Vorgang. Wenn das Problem auch nach Wiederholungen weiter besteht, hinterlassen Sie am Ende dieses Dokuments einen Kommentar.
Fehler beim Failover mit der Fehler-ID 70038
Site Recovery konnte eine klassische VM, für die ein Failover ausgeführt wurde, nicht in Azure erstellen. Dies kann mehrere Ursachen haben:
- Eine der Ressourcen – z.B. ein virtuelles Netzwerk, das für die Erstellung des virtuellen Computers erforderlich ist – ist nicht vorhanden. Erstellen Sie das virtuelle Netzwerk wie in den Netzwerk-Einstellungen des virtuellen Computers angegeben oder ändern Sie die Einstellung in ein virtuelles Netzwerk, das bereits vorhanden ist. Wiederholen Sie dann das Failover.
Fehler beim Failover mit der Fehler-ID 170010
Site Recovery konnte eine VM, für die ein Failover ausgeführt wurde, nicht in Azure erstellen. Dies kann passieren, wenn bei einer internen Hydration für den lokalen virtuellen Computer ein Fehler auftritt.
Um einen Computer in Azure aufzurufen, erfordert die Azure-Umgebung, dass sich einige der Treiber im Boot-Startzustand befinden und Dienste wie DHCP im Autostartzustand sind. Durch die Hydration zum Zeitpunkt des Failover wird der Startuptyp von atapi-, intelide-, storflt-, vmbus- und storvsc-Treibern in Bootstart umgewandelt. Außerdem wird der Starttyp einiger Dienste wie DHCP in Autostart konvertiert. Aufgrund umgebungsspezifischer Probleme können bei dieser Aktivität Fehler auftreten.
Um den Starttyp der Treiber für das Windows-Gastbetriebssystem manuell zu ändern, führen Sie die folgenden Schritte aus:
Laden Sie das „no-hydration“- Skript herunter, und führen Sie es folgendermaßen aus: Dieses Skript überprüft, ob für die VM eine Hydration erforderlich ist.
.\Script-no-hydration.ps1Es wird folgendes Ergebnis ausgegeben, wenn eine Hydration erforderlich ist:
REGISTRY::HKEY_LOCAL_MACHINE\SYSTEM\ControlSet001\services\storvsc start = 3 expected value = 0 This system doesn't meet no-hydration requirement.Wenn für die VM keine Hydration erforderlich ist, gibt das Skript folgendes Ergebnis aus: „Für dieses System ist keine Hydration erforderlich“. In diesem Fall befinden sich alle Treiber und Dienste im von Azure geforderten Zustand und eine Hydration auf der VM ist nicht erforderlich.
Führen Sie das „no-hydration-set“-Skript wie folgt aus, wenn die VM die Anforderung nicht erfüllt und eine Hydration erforderlich ist.
.\Script-no-hydration.ps1 -setDamit wird der Startuptyp der Treiber konvertiert und das folgende Ergebnis wird ausgegeben:
REGISTRY::HKEY_LOCAL_MACHINE\SYSTEM\ControlSet001\services\storvsc start = 3 expected value = 0 Updating registry: REGISTRY::HKEY_LOCAL_MACHINE\SYSTEM\ControlSet001\services\storvsc start = 0 This system is now no-hydration compatible.
Fehler beim Failover: Replikat-IP-Adressen für den Netzwerkadapter der VM sind ungültig.
Der Testfailover- oder Failovervorgang kann für einen Computer mit dem Fehler „Mindestens eine Replikat-IP-Adresse für den Netzwerkadapter der VM ist ungültig" fehlschlagen, wenn die ordnungsgemäße Bereinigung eines vorherigen Testfailovervorgangs nicht erfolgt ist. Aus diesem Grund ist der Testcomputer möglicherweise noch in der Azure-Umgebung vorhanden und verwendet möglicherweise dieselbe IP-Adresse. Dies bewirkt, dass die Zielkonfiguration der VM kritisch wird.
Um dieses Problem zu beheben, stellen Sie sicher, dass eine vollständige Testfailoverbereinigung ausgeführt wurde, damit der Failover- oder Testfailovervorgang erfolgreich ausgeführt werden kann.
Fehler beim Verbindungsaufbau über RDP/SSH mit dem virtuellen Computer (VM), für den ein Failover ausgeführt wurde, aufgrund ausgegrauter Schaltfläche „Verbinden“ auf der VM
Ausführliche Anweisungen zur Behandlung von RDP-Problemen finden Sie in der Dokumentation hier.
Ausführliche Anweisungen zur Behandlung von SSH-Problemen finden Sie in der Dokumentation hier.
Wenn die Schaltfläche Verbinden auf der Failover-VM in Azure ausgegraut ist und Sie nicht über ExpressRoute oder Site-to-Site-VPN mit Azure verbunden sind, gehen Sie wie folgt vor:
- Navigieren Sie zu VM>Netzwerk, und klicken Sie auf den Namen der jeweiligen Netzwerkschnittstelle.
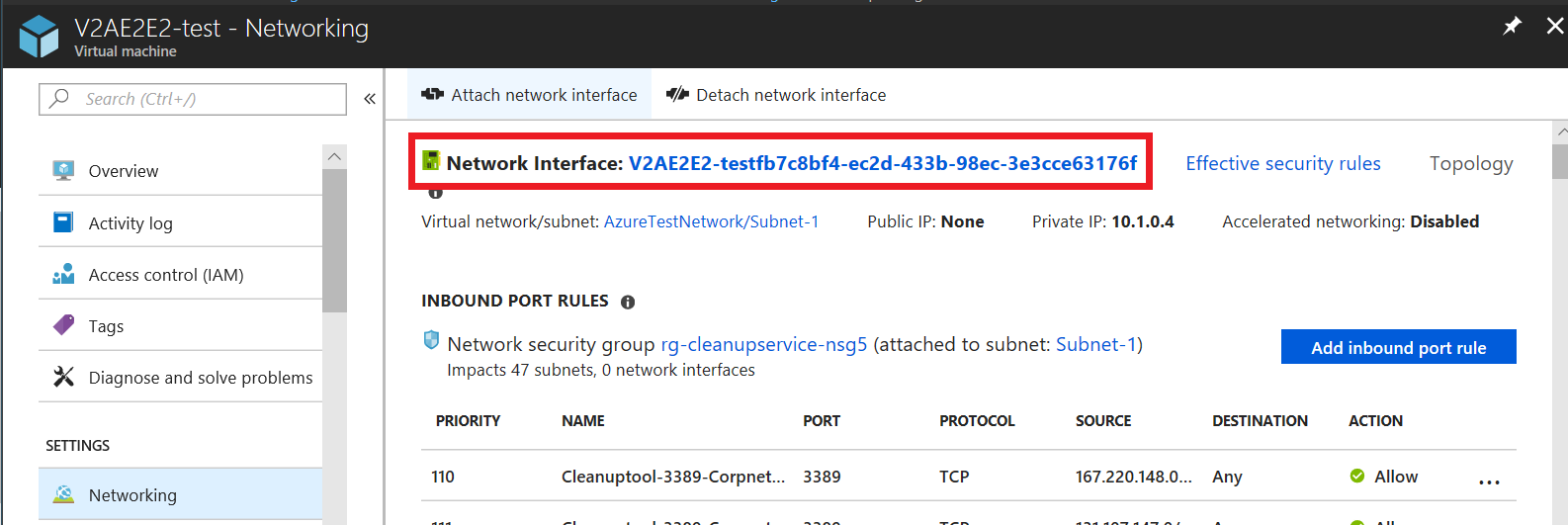
- Navigieren Sie zu IP-Konfigurationen, und wählen Sie dann das Namensfeld der gewünschten IP-Konfiguration.
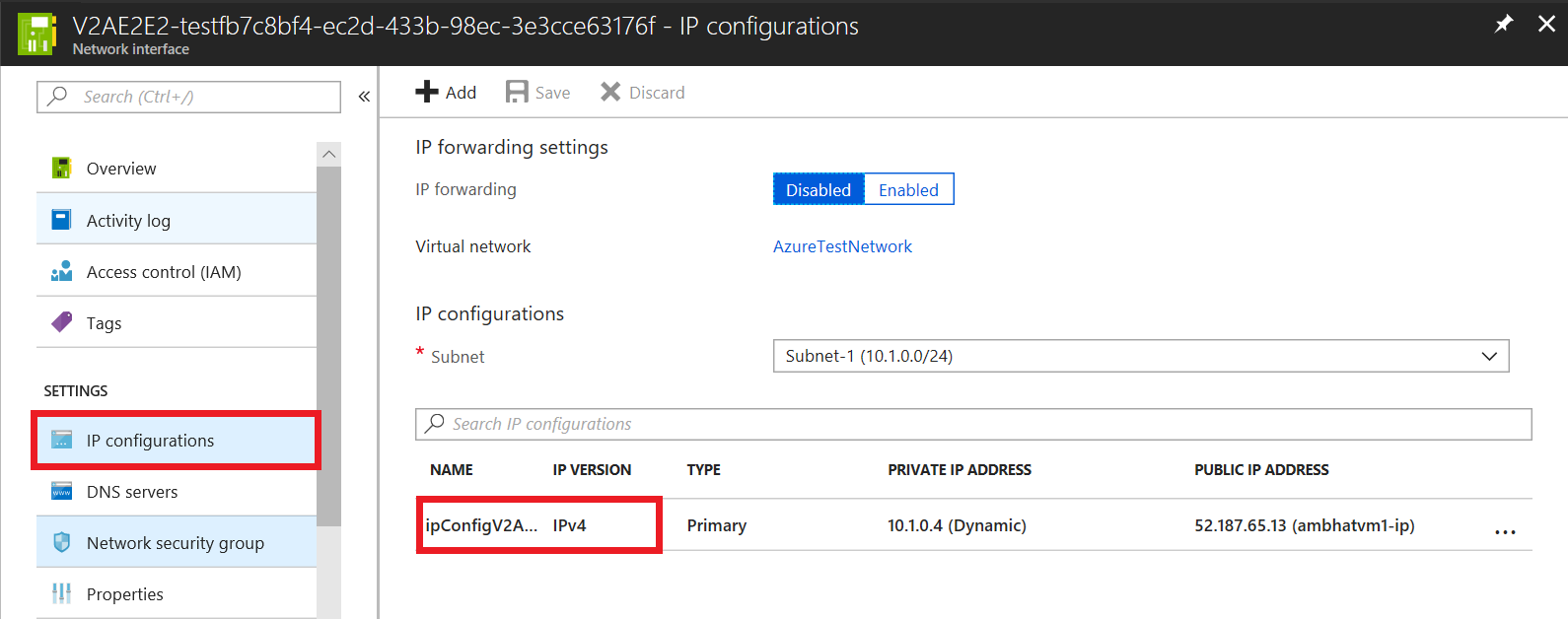
- Um die öffentliche IP-Adresse zu aktivieren, wählen Sie Aktivieren.
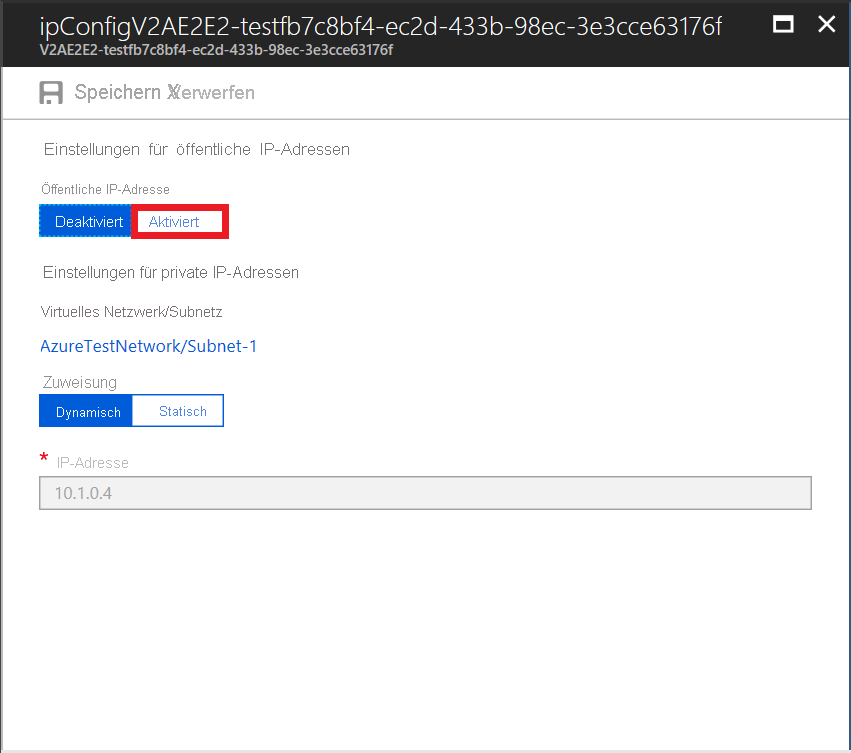
- Klicken Sie auf Erforderliche Einstellungen konfigurieren>Neue erstellen.
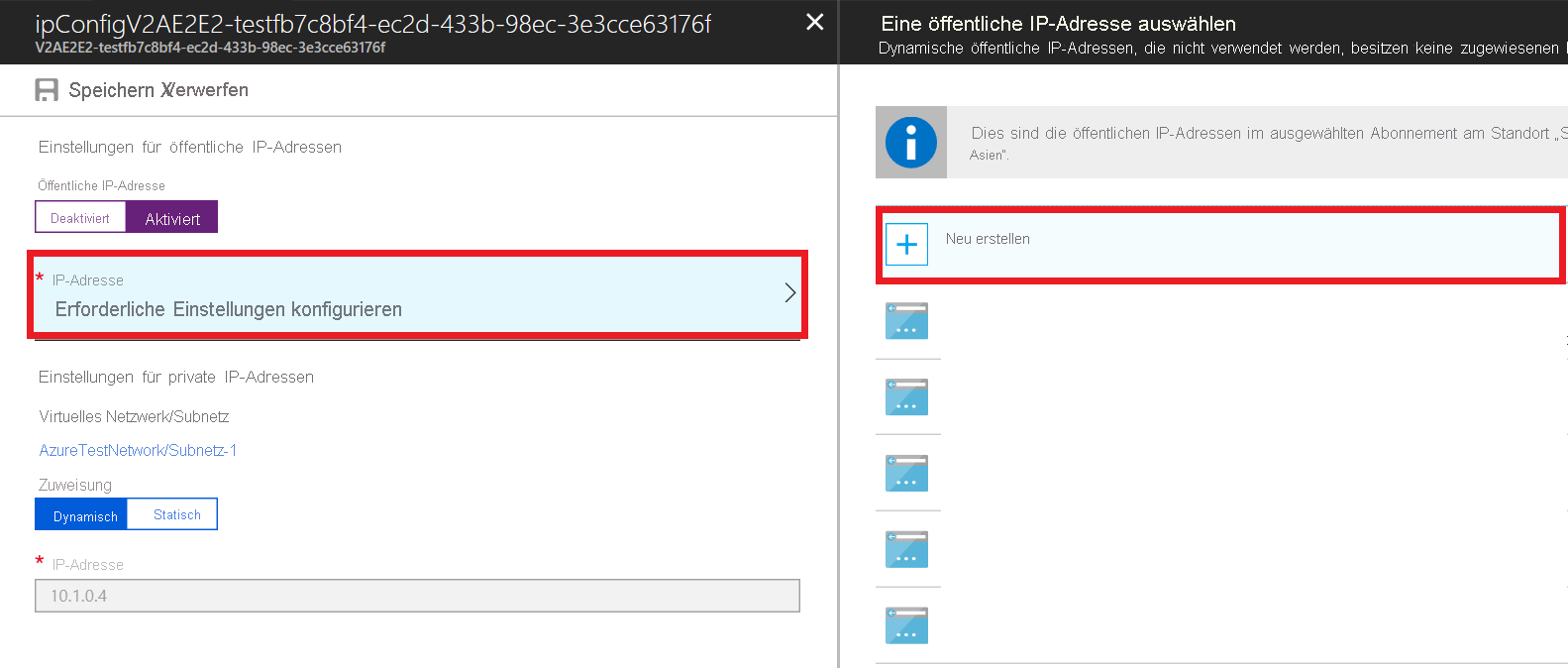
- Geben Sie den Namen der öffentlichen Adresse ein, wählen Sie die Standardoptionen für SKU und Zuweisung, und wählen Sie dann OK.
- Um die Änderungen nun zu speichern, wählen Sie Speichern.
- Schließen Sie die Bereiche, und navigieren Sie zum Abschnitt Übersicht des virtuellen Computers, mit dem per RDP eine Verbindung hergestellt werden soll.
Verbindung nicht möglich/RDP/SSH – VMConnect-Schaltfläche verfügbar
Wenn die Schaltfläche Verbinden auf dem fehlerhaften virtuellen Computer in Azure verfügbar ist (nicht abgeblendet), überprüfen Sie Startdiagnose auf Ihrem virtuellen Computer, und suchen Sie nach den in diesem Artikel aufgeführten Fehlern.
Falls die VM nicht gestartet wurde, führen Sie ein Failover auf einen früheren Wiederherstellungspunkt aus.
Wird die Anwendung auf der VM nicht gestartet, führen Sie ein Failover auf einen anwendungskonsistenten Wiederherstellungspunkt aus.
Ist der virtuelle Computer Mitglied einer Domäne, stellen Sie sicher, dass der Domänencontroller ordnungsgemäß funktioniert. Dies kann durch Ausführen der unten angegebenen Schritte geschehen:
a. Erstellen Sie einen neuen virtuellen Computer im selben Netzwerk.
b. Stellen Sie sicher, dass dieser derselben Domäne beitreten kann, in der die fehlerhafte VM erwartet wird.
c. Funktioniert der Domänencontroller nicht ordnungsgemäß, melden Sie sich bei dem virtuellen Computer, für den ein Failover ausgeführt wurde, mit einem lokalen Administratorkonto an.
Vergewissern Sie sich bei Verwendung eines benutzerdefinierten DNS-Servers, dass dieser erreichbar ist. Dies kann durch Ausführen der unten angegebenen Schritte geschehen:
a. Erstellen Sie einen neuen virtuellen Computer im selben Netzwerk.
b. Überprüfen Sie, ob der virtuelle Computer Namen mit dem benutzerdefinierten DNS-Server auflösen kann.
Hinweis
Der Azure-VM-Agent muss vor dem Failover auf dem virtuellen Computer installiert werden, wenn Sie andere Einstellungen als die Startdiagnose aktivieren möchten.
Serielle Konsole kann nach einem Failover eines UEFI-basierten Computers in Azure nicht geöffnet werden
Wenn Sie eine Verbindung mit dem Computer über RDP herstellen, aber die serielle Konsole nicht öffnen können, führen Sie die folgenden Schritte aus:
Wenn das Betriebssystem des Computers Red Hat oder Oracle Linux 7.*/8.0 ist, führen Sie den folgenden Befehl auf der Azure-Failover-VM mit root-Berechtigungen aus. Starten Sie die VM nach dem Befehl neu.
grub2-mkconfig -o /boot/efi/EFI/redhat/grub.cfgWenn das Betriebssystem des Computers CentOS 7.* ist, führen Sie den folgenden Befehl auf der Azure-Failover-VM mit root-Berechtigungen aus. Starten Sie die VM nach dem Befehl neu.
grub2-mkconfig -o /boot/efi/EFI/centos/grub.cfg
Nachricht über unerwartetes Herunterfahren (Ereignis-ID 6008)
Wenn beim Starten einer Windows-VM nach dem Failover auf der wiederhergestellten VM eine Nachricht über ein unerwartetes Herunterfahren ausgegeben wird, bedeutet dies, dass der Status des Herunterfahrens der VM nicht in dem für das Failover verwendeten Wiederherstellungspunkt erfasst wurde. Dies geschieht, wenn Sie eine Wiederherstellung zu einem Zeitpunkt durchführen, zu dem die VM nicht vollständig heruntergefahren war.
Normalerweise ist das kein Anlass zur Sorge und kann in der Regel für ungeplante Failover ignoriert werden. Stellen Sie im Fall eines geplanten Failovers sicher, dass der virtuelle Computer vor dem Failover ordnungsgemäß heruntergefahren wird, und lassen Sie genügend Zeit, damit ausstehende lokale Daten zur Replikation an Azure gesendet werden können. Verwenden Sie dann die Option Neueste auf dem Bildschirm Failover, damit alle ausstehenden Daten in Azure in einem Wiederherstellungspunkt verarbeitet werden, der dann für VM-Failover verwendet wird.
Datenspeicher kann nicht ausgewählt werden
Dieses Problem wird angezeigt, wenn Sie den Datenspeicher im Azure-Portal nicht sehen können, wenn Sie versuchen, die VM, für die ein Failover ausgeführt wurde, erneut zu schützen. Der Grund: Das Masterziel wird unter vCenter-Instanzen, die Azure Site Recovery hinzugefügt wurden, nicht als VM erkannt.
Weitere Informationen zum erneuten Schützen eines virtuellen Computers finden Sie unter Erneutes Schützen und Ausführen eines Failbacks für Computer auf einen lokalen Standort nach einem Failover auf Azure.
So lösen Sie das Problem:
Erstellen Sie das Masterziel manuell in der vCenter-Instanz, die Ihren Quellcomputer verwaltet. Der Datenspeicher ist nach der nächsten vCenter-Ermittlung und Fabric-Aktualisierung verfügbar.
Hinweis
Ermittlung und Fabric-Aktualisierung können bis zu 30 Minuten dauern.
TLS-Fehler 35 bei der Linux-Masterzielregistrierung beim Konfigurationsserver
Die Azure Site Recovery-Masterzielregistrierung beim Konfigurationsserver ist nicht erfolgreich, da auf dem Masterziel der authentifizierte Proxy aktiviert ist.
Dieser Fehler wird durch folgende Zeichenfolgen im Installationsprotokoll angegeben:
RegisterHostStaticInfo encountered exception config/talwrapper.cpp(107)[post] CurlWrapper Post failed : server : 10.38.229.221, port : 443, phpUrl : request_handler.php, secure : true, ignoreCurlPartialError : false with error: [at curlwrapperlib/curlwrapper.cpp:processCurlResponse:231] failed to post request: (35) - SSL connect error.
So lösen Sie das Problem:
Öffnen Sie auf dem virtuellen Konfigurationsservercomputer eine Eingabeaufforderung, und überprüfen Sie die Proxyeinstellungen mithilfe folgender Befehle:
cat /etc/environment echo $http_proxy echo $https_proxy
Sollte in der Ausgabe der vorherigen Befehle angegeben sein, dass die Einstellung „http_proxy“ oder „https_proxy“ definiert ist, verwenden Sie eine der folgenden Methoden, um die Blockierung der Masterzielkommunikation mit dem Konfigurationsserver zu beseitigen:
Laden Sie das PsExec-Tool herunter.
Verwenden Sie das Tool, um auf den Systembenutzerkontext zuzugreifen und zu ermitteln, ob die Proxyadresse konfiguriert ist.
Ist der Proxy konfiguriert, öffnen Sie Internet Explorer mithilfe des PsExec-Tools in einem Systembenutzerkontext.
psexec -s -i "%programfiles%\Internet Explorer\iexplore.exe"
So stellen Sie sicher, dass der Masterzielserver mit dem Konfigurationsserver kommunizieren kann:
- Ändern Sie die Proxyeinstellungen in Internet Explorer, um die IP-Adresse des Masterzielservers über den Proxy zu umgehen.
oder - Deaktivieren Sie den Proxy auf dem Masterzielserver.
- Ändern Sie die Proxyeinstellungen in Internet Explorer, um die IP-Adresse des Masterzielservers über den Proxy zu umgehen.
Nächste Schritte
- Beheben von Fehlern bei der RDP-Verbindung mit einem virtuellen Windows-Computer
- Beheben von Fehlern bei der SSH-Verbindung mit einem virtuellen Linux-Computer
Wenn Sie weitere Hilfe benötigen, veröffentlichen Sie Ihre Anfrage auf der Microsoft F&A-Seite für Site Recovery, oder hinterlassen einen Kommentar am Ende dieses Dokuments. Wir verfügen über eine aktive Community, die Sie unterstützen kann.