Entwurfsmuster für die Tabelle
Dieser Abschnitt beschreibt einige Muster, die zur Verwendung mit Tabellenspeicherdienstlösungen geeignet sind. Darüber hinaus wird gezeigt, wie Sie einige der in anderen Artikeln zum Tabellenspeicherentwurf angesprochenen Probleme und Kompromisse praktisch behandeln können. Das folgende Diagramm fasst die Beziehungen zwischen den verschiedenen Mustern zusammen:
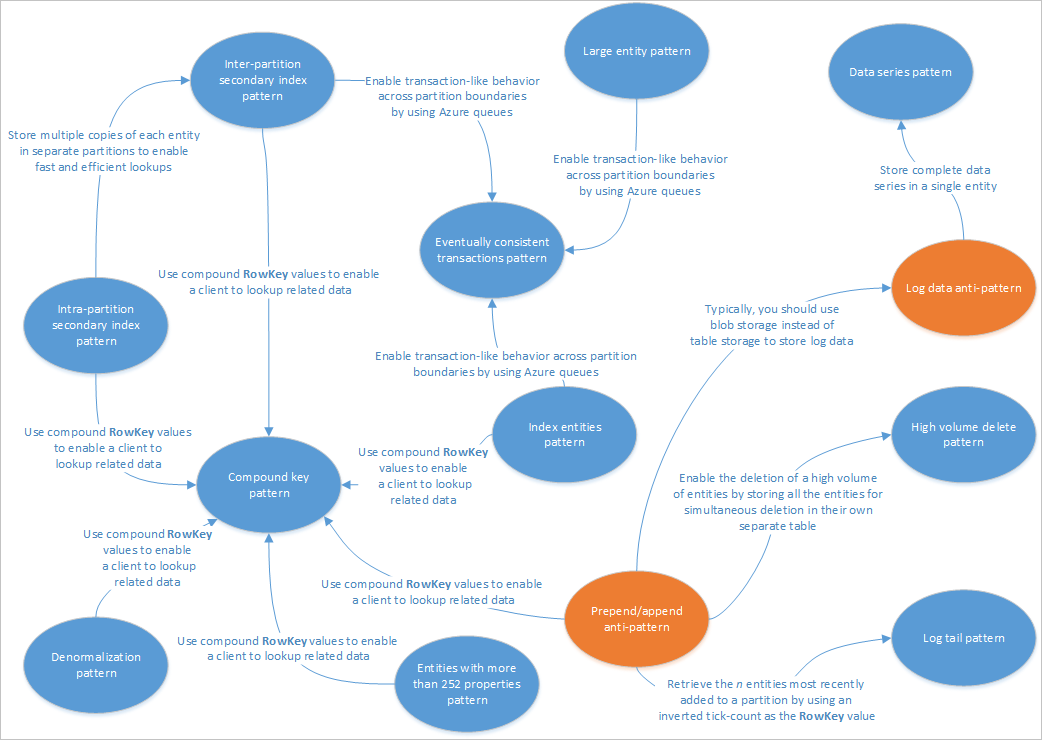
In der Muster-Karte oben werden einige Beziehungen zwischen Muster (Blau) und Antimuster (Orange) hervorgehoben, die in diesem Handbuch dokumentiert sind. Es gibt viele weitere Muster, die in Betracht gezogen werden können. Beispielsweise ist eines der Hauptszenarien für den Tabellenspeicherdienst die Verwendung des Materialized View Pattern (Muster für materialisierte Sichten) aus dem Command Query Responsibility Segregation (CQRS)-Muster.
Sekundäres Indexmuster für Intra-Partition
Speichern mehrerer Kopien jeder Entität mit unterschiedlichen RowKey-Werten (in der gleichen Partition) zur Ermöglichung schneller und effizienter Suchvorgänge und alternativer Sortierreihenfolgen mit unterschiedlichen RowKey-Werten. Updates zwischen Kopien können mithilfe von Entitätengruppentransaktionen (EGTs) konsistent gehalten werden.
Kontext und Problem
Der Tabellenspeicherdienst indiziert automatisch Entitäten mit den PartitionKey- und RowKey-Werten. Dadurch wird eine Client-Anwendung in die Lage versetzt, eine Entität effizient unter Verwendung dieser Werte abzurufen. Beispiel: Durch Verwendung der unten gezeigten Tabellenstruktur kann eine Clientanwendung eine Punktabfrage verwenden, um eine einzelne Mitarbeiterentität mit dem Abteilungsnamen und der Mitarbeiter-ID abzurufen (Werte PartitionKey und RowKey). Ein Client kann auch Entitäten abrufen, die nach Mitarbeiter-ID in jeder Abteilung sortiert sind.
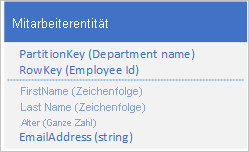
Wenn Sie auch eine Mitarbeiterentität finden möchten, die auf dem Wert einer anderen Eigenschaft basiert, wie z. B. die E-Mail-Adresse, müssen Sie einen weniger effizienten Partition-Scan verwenden, um eine Übereinstimmung zu finden. Der Grund ist, dass der Tabellenspeicherdienst keine sekundären Indizes bietet. Darüber hinaus steht keine Option zum Anfordern einer Liste der Mitarbeiter zur Verfügung, die in einer anderen Reihenfolge als in der RowKey-Reihenfolge sortiert ist.
Lösung
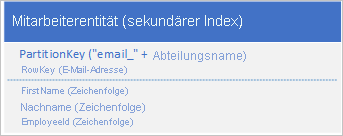
Um das Fehlen von sekundären Indizes zu umgehen, können Sie mehrere Kopien der einzelnen Entitäten speichern, wobei jede Kopie einen unterschiedlichen RowKey -Wert verwendet. Wenn Sie eine Entität mit den unten gezeigten Strukturen speichern, können Sie Mitarbeiterentitäten auf Grundlage der E-Mail-Adresse oder Mitarbeiter-ID effizient abrufen. Die Präfixwerte für RowKey („empid_“ und „email_“) ermöglichen es Ihnen, einen einzelnen Mitarbeiter oder einen Bereich von Mitarbeitern abzufragen, indem Sie einen Bereich von E-Mail-Adressen oder Mitarbeiter-IDs verwenden.

Die beiden folgenden Filterkriterien (eine Suche nach Mitarbeiter-ID und eine Suche nach E-Mail-Adresse) definieren jeweils eine Punktabfrage:
- $filter=(PartitionKey eq 'Sales') and (RowKey eq 'empid_000223')
- $filter=(PartitionKey eq 'Sales') and (RowKey eq 'email_jonesj@contoso.com')
Bei einer Abfrage nach einem Bereich von Mitarbeiterentitäten können Sie einen Bereich festlegen, der entweder nach Mitarbeiter-ID oder nach E-Mail-Adresse sortiert ist, indem Sie die Entitäten mit dem entsprechenden Präfix in RowKey abfragen.
Um alle Mitarbeiter in der Vertriebsabteilung mit einer Mitarbeiter-ID im Bereich von 000100 bis 000199 zu finden, verwenden Sie: $filter=(PartitionKey eq 'Vertrieb') und (RowKey ge 'empid_000100') und (RowKey le 'empid_000199')
Um alle Mitarbeiter in der Vertriebsabteilung mit einer E-Mail-Adresse zu finden, die mit dem Buchstaben "a" beginnt, verwenden Sie: $filter=(PartitionKey eq 'Sales') und (RowKey ge 'email_a') und (RowKey lt 'email_b')
Die in den obigen Beispielen verwendete Filtersyntax stammt aus der REST-API des Tabellenspeicherdiensts. Weitere Informationen finden Sie unter Abfragen von Entitäten.
Probleme und Überlegungen
Beachten Sie die folgenden Punkte bei der Entscheidung, wie dieses Muster implementiert werden soll:
Der Tabellenspeicher ist relativ günstig zu verwenden, sodass der Kostenaufwand für das Speichern von redundanten Daten kein wichtiger Faktor sein sollte. Sie sollten jedoch immer die Kosten für den Entwurf bewerten, basierend auf dem angenommenen Speicherbedarf und nur doppelte Entitäten hinzufügen, um die Abfragen zu unterstützen, welche die Clientanwendung ausführen wird.
Da die sekundären Index-Entitäten in derselben Partition wie die ursprünglichen Entitäten gespeichert werden, sollten Sie sicherstellen, dass Sie die Skalierbarkeitsziele für eine einzelne Partition nicht überschreiten.
Sie können die doppelten Entitäten zueinander konsistent halten mithilfe von EGTs für die automatische Aktualisierung der beiden Kopien der Entität. Dies bedeutet, dass alle Kopien einer Entität in der gleichen Partition gespeichert werden sollten. Weitere Informationen finden Sie im Abschnitt Verwenden von Entitätsgruppentransaktionen.
Der Wert, der für RowKey verwendet wird, muss für jede Entität eindeutig sein. Berücksichtigen Sie die Verwendung von zusammengesetzten Schlüsselwerten.
Das Auffüllen der numerischen Werte in RowKey (etwa bei der Mitarbeiter-ID „000223“) ermöglicht die korrekte Sortierung und Filterung anhand einer Ober- und Untergrenze.
Sie müssen nicht unbedingt alle Eigenschaften der Entität duplizieren. Beispiel: Wenn die Abfragen, mit denen die Entitäten anhand der E-Mail-Adresse in RowKey gesucht werden, nie das Alter des Mitarbeiters benötigen, könnten diese Entitäten die folgende Struktur aufweisen:
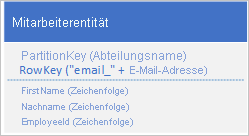
Es empfiehlt sich, in der Regel doppelte Daten zu speichern und sicherzustellen, dass Sie alle benötigten Daten mit einer einzigen Abfrage abrufen können, anstatt eine Abfrage zum Finden einer Entität und eine weitere zum Suchen nach den benötigten Daten durchzuführen.
Verwendung dieses Musters
Verwenden Sie dieses Muster, wenn Ihre Clientanwendung Entitäten abrufen muss, die eine Vielzahl verschiedener Schlüssel verwenden, wenn Ihr Client Entitäten in unterschiedlichen Sortierreihenfolgen abrufen muss, und wo Sie jede Entität unter Verwendung einer Vielzahl von eindeutigen Werten identifizieren können. Allerdings sollten Sie sicher sein, dass die Skalierungsgrenzen der Partition nicht überschritten werden, wenn Sie eine Suche nach Entitäten unter Verwendung der verschiedenen RowKey -Werte durchführen.
Zugehörige Muster und Anleitungen
Die folgenden Muster und Anleitungen können auch relevant sein, wenn dieses Muster implementiert wird:
- Sekundäres Indexmuster für Inter-Partition
- Zusammengesetzte Schlüsselmuster
- Entitätsgruppentransaktionen
- Arbeiten mit heterogenen Entitätstypen
Sekundäres Indexmuster für Inter-Partition
Das Speichern mehrerer Kopien der einzelnen Entitäten unter Verwendung verschiedener RowKey-Werte in separaten Partitionen oder in separaten Tabellen ermöglicht schnelle und effiziente Suchvorgänge und alternative Sortierreihenfolgen mit anderen RowKey-Werten.
Kontext und Problem
Der Tabellenspeicherdienst indiziert automatisch Entitäten mit den PartitionKey- und RowKey-Werten. Dadurch wird eine Client-Anwendung in die Lage versetzt, eine Entität effizient unter Verwendung dieser Werte abzurufen. Beispiel: Durch Verwendung der unten gezeigten Tabellenstruktur kann eine Clientanwendung eine Punktabfrage verwenden, um eine einzelne Mitarbeiterentität mit dem Abteilungsnamen und der Mitarbeiter-ID abzurufen (Werte PartitionKey und RowKey). Ein Client kann auch Entitäten abrufen, die nach Mitarbeiter-ID in jeder Abteilung sortiert sind.

Wenn Sie auch eine Mitarbeiterentität finden möchten, die auf dem Wert einer anderen Eigenschaft basiert, wie z. B. die E-Mail-Adresse, müssen Sie einen weniger effizienten Partition-Scan verwenden, um eine Übereinstimmung zu finden. Der Grund ist, dass der Tabellenspeicherdienst keine sekundären Indizes bietet. Darüber hinaus steht keine Option zum Anfordern einer Liste der Mitarbeiter zur Verfügung, die in einer anderen Reihenfolge als in der RowKey-Reihenfolge sortiert ist.
Sie werden eine große Anzahl von Transaktionen für diese Entitäten abschätzen und möchten das Risiko minimieren, dass der Tabellenspeicherdienst Ihren Client drosselt.
Lösung
Zur Umgehung fehlender sekundärer Indizes können Sie mehrere Kopien der einzelnen Entitäten mit jeder Kopie verwenden, indem Sie unterschiedliche PartitionKey- und RowKey-Werte verwenden. Wenn Sie eine Entität mit den unten gezeigten Strukturen speichern, können Sie Mitarbeiterentitäten auf Grundlage der E-Mail-Adresse oder Mitarbeiter-ID effizient abrufen. Mithilfe der Präfixwerte für PartitionKey („empid_“ und „email_“) können Sie den gewünschten Index für eine Abfrage identifizieren.
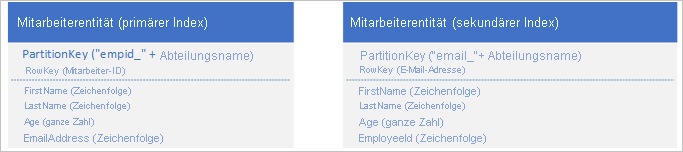
Die beiden folgenden Filterkriterien (eine Suche nach Mitarbeiter-ID und eine Suche nach E-Mail-Adresse) definieren jeweils eine Punktabfrage:
- $filter=(PartitionKey eq 'empid_Sales') and (RowKey eq '000223')
- $filter=(PartitionKey eq 'email_Sales') and (RowKey eq 'jonesj@contoso.com')
Bei einer Abfrage nach einem Bereich von Mitarbeiterentitäten können Sie einen Bereich festlegen, der entweder nach Mitarbeiter-ID oder nach E-Mail-Adresse sortiert ist, indem Sie die Entitäten mit dem entsprechenden Präfix in RowKey abfragen.
- Verwenden Sie Folgendes, um alle Mitarbeiter in der Vertriebsabteilung mit einer Mitarbeiter-ID im Bereich von 000100 bis 000199 zu suchen und nach Mitarbeiter-ID zu sortieren: $filter=(PartitionKey eq 'empid_Vertrieb') und (RowKey ge '000100') und (RowKey le '000199').
- Um alle Mitarbeiter in der Vertriebsabteilung mit einer E-Mail-Adresse zu finden, die mit dem Buchstaben "a" beginnt, und die in E-Mail-Adressen-Reihenfolge sortiert sind, verwenden Sie: $filter=(PartitionKey eq 'email_Sales') und (RowKey ge 'a') und (RowKey lt 'b')
Die in den obigen Beispielen verwendete Filtersyntax stammt aus der REST-API des Tabellenspeicherdiensts. Weitere Informationen finden Sie unter Abfragen von Entitäten.
Probleme und Überlegungen
Beachten Sie die folgenden Punkte bei der Entscheidung, wie dieses Muster implementiert werden soll:
Sie können die doppelten Entitäten "Eventually Consistent" halten, indem Sie das Eventual Consistency Transaktionsmuster verwenden, um die primären und sekundären Indexentitäten zu verwalten.
Der Tabellenspeicher ist relativ günstig zu verwenden, sodass der Kostenaufwand für das Speichern von redundanten Daten kein wichtiger Faktor sein sollte. Sie sollten jedoch immer die Kosten für den Entwurf bewerten, basierend auf dem angenommenen Speicherbedarf und nur doppelte Entitäten hinzufügen, um die Abfragen zu unterstützen, welche die Clientanwendung ausführen wird.
Der Wert, der für RowKey verwendet wird, muss für jede Entität eindeutig sein. Berücksichtigen Sie die Verwendung von zusammengesetzten Schlüsselwerten.
Das Auffüllen der numerischen Werte in RowKey (etwa bei der Mitarbeiter-ID „000223“) ermöglicht die korrekte Sortierung und Filterung anhand einer Ober- und Untergrenze.
Sie müssen nicht unbedingt alle Eigenschaften der Entität duplizieren. Beispiel: Wenn die Abfragen, mit denen die Entitäten anhand der E-Mail-Adresse in RowKey gesucht werden, nie das Alter des Mitarbeiters benötigen, könnten diese Entitäten die folgende Struktur aufweisen:
Es ist in der Regel besser, doppelte Daten zu speichern und sicherzustellen, dass Sie alle benötigten Daten mit einer einzigen Abfrage abrufen können, anstatt eine Abfrage zum Finden einer Entität unter Verwendung des sekundären Indexes und eine weitere Abfrage zum Suchen nach den benötigten Daten im primären Index durchzuführen.
Verwendung dieses Musters
Verwenden Sie dieses Muster, wenn Ihre Clientanwendung Entitäten abrufen muss, die eine Vielzahl verschiedener Schlüssel verwenden, wenn Ihr Client Entitäten in unterschiedlichen Sortierreihenfolgen abrufen muss, und wo Sie jede Entität unter Verwendung einer Vielzahl von eindeutigen Werten identifizieren können. Verwenden Sie dieses Muster, wenn Sie ein Überschreiten der Skalierungsgrenzen der Partition verhindern möchten, wenn Sie Entitätssuchvorgänge mit den verschiedenen RowKey -Werten ausführen.
Zugehörige Muster und Anleitungen
Die folgenden Muster und Anleitungen können auch relevant sein, wenn dieses Muster implementiert wird:
- Eventual Consistency Transaktionsmuster
- Sekundäres Indexmuster für Intra-Partition
- Zusammengesetzte Schlüsselmuster
- Entitätsgruppentransaktionen
- Arbeiten mit heterogenen Entitätstypen
Eventual Consistency-Transaktionsmuster
Aktivieren Sie Eventual Consistency über Partitions- oder Speichersystemgrenzen hinweg, indem Sie Azure-Warteschlangen verwenden.
Kontext und Problem
EGTs ermöglichen atomische Transaktionen über mehrere Entitäten, die den gleichen Partitionsschlüssel gemeinsam nutzen. Aus Gründen der Leistung und Skalierbarkeit möchten Sie Entitäten speichern, die Anforderungen an die Datenkonsistenz in separaten Partitionen oder in einem separaten Speichersystem haben. In diesem Fall können keine EGTs zur Gewährleistung der Konsistenz verwendet werden. Beispiel: Sie haben eine Anforderung, bei der in den folgenden Fällen Eventual Consistency beibehalten werden muss:
- Entitäten, die in zwei verschiedenen Partitionen in derselben Tabelle, in verschiedenen Tabellen oder in verschiedenen Speicherkonten gespeichert sind.
- Eine Entität, die im Tabellenspeicherdienst gespeichert ist und einen Blob, der im Blob-Dienst gespeichert ist.
- Eine Entität, die im Tabellenspeicherdienst gespeichert ist und eine Datei in einem Dateisystem.
- Speicherung einer Entität im Tabellenspeicherdienst, der jedoch mithilfe des Azure Cognitive Search-Dienstes indiziert ist.
Lösung
Mithilfe von Azure-Warteschlangen können Sie eine Lösung implementieren, die Eventual Consistency über zwei oder mehr Partitionen oder Speichersysteme bietet. Zur Veranschaulichung dieses Ansatzes gehen Sie davon aus, dass Sie eine Anforderung haben, veraltete Mitarbeiterentitäten archivieren zu können. Alte Mitarbeiterentitäten werden selten abgefragt und sollten aus allen Aktivitäten ausgeschlossen werden, die sich mit den aktuellen Mitarbeitern beschäftigen. Um diese Anforderung zu implementieren, speichern Sie die aktiven Mitarbeiter in der Tabelle Aktuell und ehemalige Mitarbeiter in der Tabelle Archiv. Zum Archivieren eines Mitarbeiters löschen Sie die Entität aus der Tabelle Aktuell und fügen die Entität der Tabelle Archiv hinzu. Für diese beiden Vorgänge kann allerdings keine EGT verwendet werden. Um das Risiko zu vermeiden, das aufgrund eines Fehlers eine Entität in beiden oder in keiner Tabelle angezeigt wird, muss der Archivierungsvorgang letztendlich Eventual Consistency aufweisen. Das folgende Sequenzdiagramm beschreibt die Schritte bei diesem Vorgang. Mehr Details zu Ausnahmepfaden werden im folgenden Text zur Verfügung gestellt.
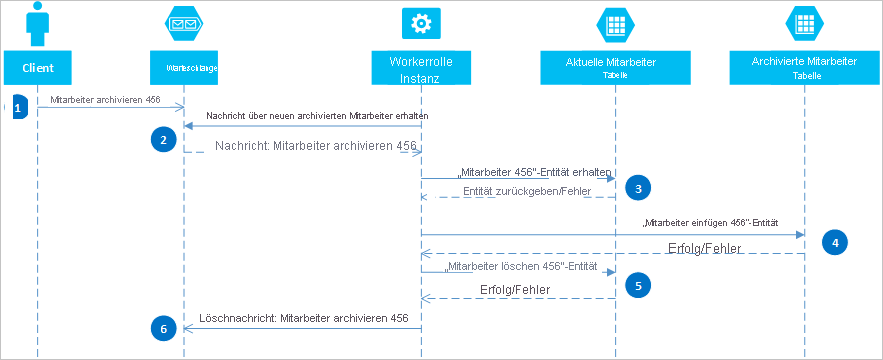
Ein Client startet den Archiv-Vorgang, indem er eine Meldung auf einer Azure-Warteschlange ablegt. In diesem Beispiel wird Mitarbeiter #456 archiviert. Eine Workerrolle fragt die Warteschlange auf neue Meldungen ab. Wird eine gefunden, liest sie die Meldung und hinterlässt eine verborgene Kopie in der Warteschlange. Die Workerrolle ruft als Nächstes eine Kopie der Entität aus der Tabelle Aktuell ab, fügt eine Kopie in die Tabelle Archiv ein und löscht dann die ursprüngliche Entität aus der Tabelle Aktuell. Falls keine Fehler in den vorangegangenen Schritten aufgetreten sind, löscht die Workerrolle schlussendlich die verborgene Nachricht aus der Warteschlange.
In diesem Beispiel fügt Schritt 4 den Mitarbeiter in die Tabelle Archiv ein. Es könnte den Mitarbeiter einem Blob im Blob-Dienst oder einer Datei in einem Dateisystem hinzufügen.
Wiederherstellung bei Fehlern
Für den Fall, dass die Workerrolle den Archivierungsvorgang neu starten muss, müssen die Vorgänge in den Schritten 4 und 5idempotent sein. Bei Verwendung des Tabellenspeicherdiensts müssen Sie für Schritt 4 einen Vorgang vom Typ „Einfügen oder Ersetzen“ und für Schritt 5 in der verwendeten Clientbibliothek einen Vorgang vom Typ „Löschen, falls vorhanden“ ausführen. Wenn Sie ein anderes Speichersystem verwenden, müssen Sie einen entsprechenden idempotenten Vorgang verwenden.
Wenn die Workerrolle Schritt 6niemals abschließt, erscheint nach einem Timeout die Meldung wieder in der Warteschlange, damit die Workerrolle versuchen kann, sie erneut zu verarbeiten. Die Workerrolle kann überprüfen, wie oft eine Meldung in der Warteschlange gelesen wurde und bei Bedarf markieren, dass dies eine "unzustellbare" Meldung ist und sie zur Untersuchung an eine eigene Warteschlange senden. Weitere Informationen zum Lesen von Warteschlangenmeldungen und zur Überprüfung des Zählers für Entfernungsvorgänge aus der Warteschlange finden Sie unter Get Messages.
Einige Fehler aus der Tabelle und den Warteschlangendiensten sind vorübergehende Fehler. Ihre Clientanwendung sollte diese über eine geeignete Wiederholungslogik bedienen können.
Probleme und Überlegungen
Beachten Sie die folgenden Punkte bei der Entscheidung, wie dieses Muster implementiert werden soll:
- Diese Lösung bietet keine Transaktionsisolation. Dadurch kann beispielsweise ein Client die Tabellen Aktuell und Archiv lesen, wenn sich die Workerrolle zwischen den Schritten 4 und 5 befindet, und eine inkonsistente Darstellung der Daten erhalten. Die Daten sind irgendwann konsistent.
- Sie müssen darauf achten, dass die Schritte 4 und 5 idempotent sind, um Eventual Consistency zu gewährleisten.
- Sie können die Lösung skalieren, indem Sie mehrerer Warteschlangen und Workerrollen-Instanzen verwenden.
Verwendung dieses Musters
Verwenden Sie dieses Muster, um Eventual Consistency zwischen Entitäten zu gewährleisten, die in verschiedenen Partitionen oder Tabellen vorhanden sind. Sie können dieses Muster zur Gewährleistung von Eventual Consistency für alle Vorgänge zum Tabellenspeicherdienst, Blob-Dienst und andere Nicht-Azure Tabellenspeicher-Datenquellen wie Datenbank oder Dateisystem verwenden.
Zugehörige Muster und Anleitungen
Die folgenden Muster und Anleitungen können auch relevant sein, wenn dieses Muster implementiert wird:
- Entitätsgruppentransaktionen
- Zusammenführen oder ersetzen
Hinweis
Falls Transaktionsisolation für Ihre Lösung wichtig ist, sollten Sie einen Neuentwurf Ihrer Tabellen erwägen, damit Sie EGTs verwenden können.
Muster für Indexentitäten
Verwalten von Index-Entitäten, um effiziente Suchvorgänge zu ermöglichen, die Listen mit Entitäten zurückgeben.
Kontext und Problem
Der Tabellenspeicherdienst indiziert automatisch Entitäten mit den PartitionKey- und RowKey-Werten. Dadurch kann eine Clientanwendung, eine Entität effizient mithilfe einer Punktabfrage abrufen. Beispiel: Durch Verwendung der unten gezeigten Tabellenstruktur kann eine Clientanwendung eine einzelne Mitarbeiterentität effizient abrufen, indem der Abteilungsname und die Mitarbeiter-ID verwendet werden (PartitionKey und RowKey).

Wenn Sie auch in der Lage sein möchten, eine Liste der Mitarbeiterentitäten abzurufen, die auf dem Wert einer anderen nicht eindeutigen Eigenschaft basiert, z. B. Nachname, müssen Sie einen weniger effizienten Partition-Scan verwenden, um Übereinstimmungen zu finden, anstatt einen Index zum direkt Nachschlagen zu verwenden. Der Grund ist, dass der Tabellenspeicherdienst keine sekundären Indizes bietet.
Lösung
Um die Suche nach dem Nachnamen mit der oben dargestellten Entitätsstruktur zu aktivieren, müssen Sie die Listen der Mitarbeiter-IDs verwalten. Wenn Sie die Mitarbeiterentitäten mit einem bestimmten Nachnamen aufrufen möchten, z.B. Jones, müssen Sie zuerst die Liste der Mitarbeiter-IDs für die Mitarbeiter finden, deren Nachname Jones ist und dann diese Mitarbeiterentitäten abrufen. Es gibt drei wichtige Optionen zur Speicherung der Listen mit den Mitarbeiter-IDs:
- Verwenden von Blob-Speicher.
- Erstellen von Index-Entitäten in der gleichen Partition wie für die Mitarbeiterentitäten.
- Erstellen von Index-Entitäten in einer separaten Partition oder Tabelle.
Option 1: Verwenden von Blobspeicher
Für die erste Option erstellen Sie ein Blob für jeden eindeutigen Nachnamen und speichern in jedem Blob eine Liste mit den Werten PartitionKey (Abteilung) und RowKey (Mitarbeiter-ID) für die Mitarbeiter mit diesem Nachnamen. Beim Hinzufügen oder Löschen eines Mitarbeiters sollten Sie sicherstellen, dass der Inhalt des relevanten Blob schließlich konsistent mit den Mitarbeiterentitäten ist.
Option 2: Erstellen von Indexentitäten in der gleichen Partition
Verwenden Sie für die zweite Option die Index-Entitäten, die folgende Daten speichern:
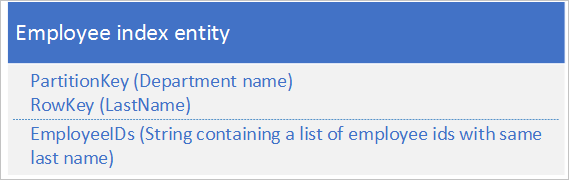
Die Eigenschaft EmployeeIDs enthält eine Liste der Mitarbeiter-IDs für Mitarbeiter, deren Nachname in RowKey gespeichert ist.
Wenn Sie die zweite Option verwenden, beschreiben die folgenden Schritte den Prozess, den Sie befolgen sollten, wenn Sie einen neuen Mitarbeiter hinzufügen. In diesem Beispiel werden wir einen Mitarbeiter mit der ID 000152 und einen Nachnamen Jones in der Vertriebsabteilung hinzufügen:
- Rufen Sie die Indexentität mit dem PartitionKey-Wert „Sales“ und dem RowKey-Wert „Jones“ ab. Speichern Sie das ETag der Entität, die in Schritt 2 verwendet wird.
- Erstellen Sie eine Entitätsgruppentransaktion (also einen Batchvorgang), mit der die neue Mitarbeiterentität eingefügt wird (PartitionKey= „Vertrieb“ und RowKey = „000152“), und aktualisieren Sie die Indexentität (PartitionKey = „Vertrieb“ und RowKey = „Jones“) durch Hinzufügen der neuen Mitarbeiter-ID zur Liste im Feld „EmployeeIDs“. Weitere Informationen zu Entitätsgruppentransaktionen finden Sie unter „Entitätsgruppentransaktionen“.
- Falls die Entitätsgruppentransaktion aufgrund eines Fehlers der vollständigen Nebenläufigkeit (jemand hat gerade die Indexentität geändert) nicht erfolgreich ist, müssen Sie erneut mit Schritt 1 beginnen.
Wenn Sie die zweite Option verwenden, können Sie einen ähnlichen Ansatz beim Löschen eines Mitarbeiters wählen. Das Ändern des Nachnamen des Mitarbeiters ist etwas komplexer, da Sie eine Entitätsgruppentransaktion ausführen müssen, die drei Entitäten aktualisiert: die Mitarbeiterentität, die Indexentität für den alten Nachnamen und die Indexentität für den neuen Nachnamen. Sie müssen jede Entität abrufen, bevor Sie Änderungen vornehmen, um die ETag-Werte abzurufen, mit denen Sie dann die Updates unter Verwendung von optimistischer Nebenläufigkeit ausführen.
Wenn Sie die zweite Option verwenden, beschreiben die folgenden Schritte den Prozess, den Sie befolgen sollten, wenn Sie alle Mitarbeiter mit einem bestimmten Nachnamen in einer Abteilung nachschlagen. In diesem Beispiel schlagen wir alle Mitarbeiter in der Vertriebsabteilung mit dem Nachnamen Jones nach:
- Rufen Sie die Indexentität mit dem PartitionKey-Wert „Sales“ und dem RowKey-Wert „Jones“ ab.
- Analysieren Sie die Liste der Mitarbeiter-IDs im Feld EmployeeIDs.
- Falls Sie zusätzliche Informationen zu den einzelnen Mitarbeitern benötigen (etwa ihre E-Mail-Adressen), rufen Sie die einzelnen Mitarbeiterentitäten mit dem PartitionKey-Wert „Sales“ und den RowKey-Werten aus der Liste der Mitarbeiter ab, die Sie in Schritt 2 abgerufen haben.
Option 3: Erstellen von Indexentitäten in einer separaten Partition oder Tabelle
Verwenden Sie für die dritte Option Index-Entitäten, die folgende Daten speichern:

Die Eigenschaft EmployeeDetails enthält eine Liste mit Paaren aus Mitarbeiter-IDs und Abteilungsnamen für Mitarbeiter mit dem in RowKey gespeicherten Nachnamen.
Mit der dritten Option können Sie keine EGTs zur Aufrechterhaltung der Konsistenz verwenden, da sich die Index-Entitäten in einer anderen Partition wie die Mitarbeiterentitäten befinden. Stellen Sie sicher, dass die Index-Entitäten Eventual Consistency mit den Mitarbeiterentitäten aufweisen.
Probleme und Überlegungen
Beachten Sie die folgenden Punkte bei der Entscheidung, wie dieses Muster implementiert werden soll:
- Diese Lösung erfordert mindestens zwei Abfragen zum Abrufen von übereinstimmenden Entitäten: eine zur Abfrage der Indexentitäten, um eine Liste mit RowKey -Werten zu erhalten, und dann Abfragen zum Abruf jeder Entität aus der Liste.
- Angesichts der Tatsache, dass eine einzelne Entität eine Maximalgröße von 1 MB hat, wird bei den Optionen 2 und 3 der Lösungen angenommen, dass die Liste der Mitarbeiter-IDs für einen angegebenen Nachnamen nie größer als 1 MB ist. Wenn die Liste der Mitarbeiter-IDs aller Voraussicht nach größer als 1 MB wird, verwenden Sie die Option Nr. 1 und speichern Sie die Indexdaten im Blobspeicher.
- Bei Verwendung der Option Nr. 2 (Verwendung von EGTs zum Hinzufügen und Löschen von Mitarbeitern und Ändern des Nachnamens eines Mitarbeiters) müssen Sie bewerten, ob die Transaktionsmenge sich den Skalierungsgrenzen in einer gegebenen Partition nähert. Wenn dies der Fall ist, sollten Sie eine Lösung mit Eventual Consistency (Option Nr. 1 oder Nr. 3) erwägen, die Warteschlangen zur Behandlung der Update-Anforderungen verwendet und Ihnen das Speichern Ihrer Index-Entitäten in einer von den Mitarbeiterentitäten separaten Partition ermöglicht.
- In Option Nr. 2 in dieser Lösung wird davon ausgegangen, dass Sie innerhalb einer Abteilung nach Nachnamen nachschlagen möchten: z. B. eine Liste von Mitarbeitern abrufen mit einem Nachnamen Jones in der Vertriebsabteilung. Wenn Sie eine Suche aller Mitarbeiter mit einem Nachnamen Jones in der gesamten Organisation durchführen möchten, verwenden Sie entweder die Option Nr. 1 oder Nr. 3.
- Sie können eine auf einer Warteschlange basierende Lösung implementieren, die letztliche Konsistenz bietet (weitere Details finden Sie unter Eventual Consistency-Transaktionsmuster ).
Verwendung dieses Musters
Verwenden Sie dieses Muster, wenn Sie eine Reihe von Entitäten nachschlagen möchten, die einen gemeinsamen Eigenschaftswert haben, z.B. alle Mitarbeiter mit dem Nachnamen Jones.
Zugehörige Muster und Anleitungen
Die folgenden Muster und Anleitungen können auch relevant sein, wenn dieses Muster implementiert wird:
- Zusammengesetzte Schlüsselmuster
- Eventual Consistency Transaktionsmuster
- Entitätsgruppentransaktionen
- Arbeiten mit heterogenen Entitätstypen
Denormalisierungsmuster
Kombinieren Sie zugehörige Daten zusammen in eine einzelne Entität, mit der Sie alle Daten abrufen, die Sie mit einer einzelnen Abfrage benötigen.
Kontext und Problem
In einer relationalen Datenbank normalisieren Sie typischerweise Daten, um Duplizierungen zu entfernen, die zu Abfragen führen, die Daten aus mehreren Tabellen abrufen. Wenn Sie Ihre Daten in Azure-Tabellen normalisieren, müssen Sie mehrere Roundtrips vom Client zum Server durchlaufen, um Ihre zugeordneten Daten abzurufen. Beispiel: Bei der folgenden Tabellenstruktur benötigen Sie zwei Roundtrips zum Abrufen der Details für eine Abteilung. Mit dem ersten Roundtrip wird die Abteilungsentität mit der Manager-ID abgerufen. Mit dem zweiten werden die Details des Managers aus einer Mitarbeiterentität angefordert.

Lösung
Anstatt die Daten in zwei separaten Entitäten zu speichern, denormalisieren Sie die Daten und bewahren eine Kopie der Details des Managers in der Abteilungsentität auf. Beispiel:
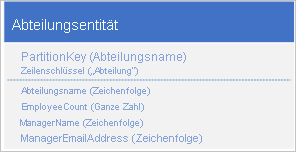
Sie können von Abteilungsentitäten, die mit diesen Eigenschaften gespeichert sind, jetzt alle benötigten Details zu einer Abteilung abrufen, indem Sie eine Punktabfrage verwenden.
Probleme und Überlegungen
Beachten Sie die folgenden Punkte bei der Entscheidung, wie dieses Muster implementiert werden soll:
- Im Zusammenhang mit dem zweifachen Speichern von Daten fallen Mehrkosten an. Der Leistungsvorteil (der sich aus weniger Anforderungen an den Speicherdienst ergibt) überwiegt in der Regel die marginal höheren Speicherkosten (und diese Kosten werden teilweise durch eine Reduzierung der Anzahl der Transaktionen ausgeglichen, die Sie benötigen, um die Details einer Abteilung abrufen).
- Sie müssen die Konsistenz der beiden Entitäten verwalten, die Informationen über Manager speichern. Sie können das Konsistenzproblem behandeln, indem Sie EGTs zum Aktualisieren von mehreren Entitäten in einer einzelnen atomischen Transaktion verwenden. In diesem Fall werden die Abteilungsentität und die Mitarbeiterentität für den Manager der Abteilung in der gleichen Partition gespeichert.
Verwendung dieses Musters
Verwenden Sie dieses Muster, wenn Sie häufig nach zugeordneten Informationen suchen müssen. Dieses Muster reduziert die Anzahl der Abfragen, die Ihr Client vornehmen muss, um die benötigten Daten abzurufen.
Zugehörige Muster und Anleitungen
Die folgenden Muster und Anleitungen können auch relevant sein, wenn dieses Muster implementiert wird:
- Zusammengesetzte Schlüsselmuster
- Entitätsgruppentransaktionen
- Arbeiten mit heterogenen Entitätstypen
Zusammengesetzte Schlüsselmuster
Verwenden Sie zusammengesetzte RowKey -Werte, damit der Client in der Lage ist, mit einer einzelnen Punktabfrage nach verknüpften Daten zu suchen.
Kontext und Problem
In einer relationalen Datenbank ist es natürlich, Verknüpfungen in Abfragen zu verwenden, um zugehörige Datenelemente in einer einzelnen Abfrage an den Client zurückzugeben. Beispiel: Sie können die Mitarbeiter-ID verwenden, um in einer Liste von verknüpften Entitäten zu suchen, die Leistungs- und Review-Daten für diesen Mitarbeiter enthalten.
Angenommen, Sie speichern Mitarbeiterentitäten im Tabellenspeicherdienst mithilfe der folgenden Struktur:
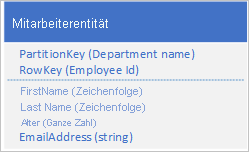
Sie müssen auch Vergangenheitsdaten speichern, die im Zusammenhang mit Überprüfungen und Leistung für jedes Jahr, in dem der Mitarbeiter für Ihre Organisation gearbeitet hat, stehen und Sie müssen auf diese Informationen nach Jahr zugreifen können. Eine Möglichkeit ist, eine weitere Tabelle zu erstellen, in der Entitäten mit der folgenden Struktur gespeichert werden:

Beachten Sie, dass Sie bei diesem Ansatz entscheiden könnten, dass Sie einige Informationen (z. B. Vorname und Nachname) in die neue Entität duplizieren, um zu ermöglichen, dass Sie Ihre Daten mit einer einzelnen Anforderung abrufen. Sie können jedoch keine starke Konsistenz beibehalten, da Sie keine EGT verwenden können, die beide Entitäten nicht trennbar aktualisiert.
Lösung
Speichern Sie einen neuen Entitätstyp in der ursprünglichen Tabelle unter Verwendung von Entitäten mit der folgenden Struktur ab:
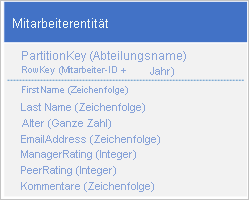
Beachten Sie, dass RowKey jetzt ein Schlüssel ist, der sich aus der Mitarbeiter-ID und dem Jahr der Review-Daten zusammensetzt und der es Ihnen ermöglicht, die Leistungs- und Review-Daten des Mitarbeiters mit einer einzigen Anforderung für eine einzelne Entität abzurufen.
Im folgende Beispiel wird erläutert, wie Sie alle Review-Daten für einen bestimmten Mitarbeiter (z. B. Mitarbeiter 000123 in der Vertriebsabteilung) abrufen können:
$filter=(PartitionKey eq 'Sales') und (RowKey ge 'empid_000123') und (RowKey lt '000123_2012')&$select=RowKey,Manager Rating,Peer Rating,Comments
Probleme und Überlegungen
Beachten Sie die folgenden Punkte bei der Entscheidung, wie dieses Muster implementiert werden soll:
- Sie sollten ein geeignetes Trennzeichen verwenden, um die Analyse des RowKey-Werts zu erleichtern (beispielsweise 000123_2012).
- Sie speichern diese Entität auch in der gleichen Partition wie andere Entitäten mit verknüpften Daten für denselben Mitarbeiter, was bedeutet, dass Sie EGTs verwenden können, um starke Konsistenz zu gewährleisten.
- Sie sollten berücksichtigen, wie oft Sie die Daten abfragen, um zu bestimmen, ob dieses Muster geeignet ist. Beispiel: Wenn Sie auf die Review-Daten selten und auf die wichtigsten Mitarbeiterdaten häufig zugreifen, sollten Sie diese als separate Entitäten beibehalten.
Verwendung dieses Musters
Verwenden Sie dieses Muster, wenn Sie eine oder mehrere Entitäten, die Sie häufig abfragen, speichern müssen.
Zugehörige Muster und Anleitungen
Die folgenden Muster und Anleitungen können auch relevant sein, wenn dieses Muster implementiert wird:
- Entitätsgruppentransaktionen
- Arbeiten mit heterogenen Entitätstypen
- Eventual Consistency Transaktionsmuster
Log Tail-Muster
Abrufen der n Entitäten, die zuletzt einer Partition hinzugefügt wurden, indem Sie einen RowKey -Wert verwenden, mit dem nach Datum und Uhrzeit in umgekehrter Reihenfolge sortiert wird.
Kontext und Problem
Eine gängige Anforderung ist, die zuletzt erstellten Entitäten abzurufen, z.B. die letzten 10 Kostenabrechnungen, die von einem Mitarbeiter übermittelt wurden. Tabellenabfragen unterstützen einen $top-Abfragevorgang, um die ersten n Entitäten einer Menge zurückzugeben. Es gibt keinen entsprechenden Abfragevorgang, mit dem die letzten n Entitäten einer Menge zurückgegeben werden können.
Lösung
Speichern von Entitäten unter Verwendung eines RowKey-Werts, der von Natur aus in umgekehrter Datum-/Zeit-Reihenfolge sortiert wird. Damit ist der neueste Eintrag immer der erste Eintrag in der Tabelle.
Beispiel: Um die 10 neuesten Kostenabrechnungen, die von einem Mitarbeiter übermittelt wurden, abrufen zu können, können Sie einen umgekehrten Tick-Wert verwenden, der aus dem aktuellen Wert für Datum/Uhrzeit abgeleitet ist. Das folgende C#-Codebeispiel zeigt eine Möglichkeit, einen geeigneten "invertierten Ticks"-Wert für einen RowKey zu erstellen, der von der neuesten bis zur ältesten Information sortiert:
string invertedTicks = string.Format("{0:D19}", DateTime.MaxValue.Ticks - DateTime.UtcNow.Ticks);
Sie können wieder zum Wert Datum/Uhrzeit mithilfe des folgenden Codes zurückkehren:
DateTime dt = new DateTime(DateTime.MaxValue.Ticks - Int64.Parse(invertedTicks));
Die Tabellenabfrage sieht folgendermaßen aus:
https://myaccount.table.core.windows.net/EmployeeExpense(PartitionKey='empid')?$top=10
Probleme und Überlegungen
Beachten Sie die folgenden Punkte bei der Entscheidung, wie dieses Muster implementiert werden soll:
- Sie müssen den umgekehrten Tick-Wert mit führenden Nullen auffüllen, um sicherzustellen, dass der Zeichenfolgewert wie erwartet sortiert.
- Sie müssen die Skalierbarkeitsziele auf der Ebene einer Partition kennen. Vorsicht, keine Hotspot-Partitionen erstellen.
Verwendung dieses Musters
Verwenden Sie dieses Muster, wenn Sie auf Entitäten in umgekehrter Datum/Uhrzeit-Reihenfolge oder auf die zuletzt hinzugefügten Entitäten zugreifen müssen.
Zugehörige Muster und Anleitungen
Die folgenden Muster und Anleitungen können auch relevant sein, wenn dieses Muster implementiert wird:
Muster für das Löschen hoher Volumen
Aktivieren Sie das Löschen einer hohen Anzahl von Entitäten, indem Sie alle Entitäten zum gleichzeitigen Löschen in ihrer eigenen separaten Tabelle speichern. Löschen Sie die Entitäten durch Löschen der Tabelle.
Kontext und Problem
Viele Anwendungen löschen alte Daten, die für eine Clientanwendung nicht mehr verfügbar sein müssen oder von der Anwendung auf einem anderen Speichermedium archiviert wurden. Sie kennzeichnen solche Daten in der Regel mit einem Datum. Sie haben z. B. eine Anforderung zum Löschen von Datensätzen aller Anmeldeanforderungen, die älter 60 Tage sind.
Ein möglicher Entwurf ist die Verwendung von Datum und Uhrzeit der Anmeldeanforderung in RowKey:
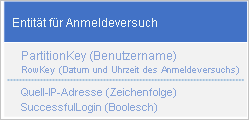
Dieser Ansatz vermeidet Partition-Hotspots, da die Anwendung Anmeldeentitäten für jeden Benutzer in eine separate Partition einfügen und löschen kann. Allerdings kann dieser Ansatz teuer und zeitaufwendig sein, wenn die Anzahl Ihrer Entitäten groß ist, da Sie zunächst einen Tabellen-Scan ausführen müssen, um die zu löschenden Entitäten zu identifizieren. Danach müssen Sie jede alte Entität löschen. Sie können die Anzahl der Roundtrips zum Server reduzieren, die zum Löschen der alten Entitäten notwendig sind, indem Sie mehrere Löschanforderungen in EGTs stapeln.
Lösung
Verwenden Sie für Anmeldeversuche jeden Tag eine separate Tabelle. Sie können den oben genannten Entitätsentwurf verwenden, um beim Einfügen von Entitäten Hotspots zu vermeiden. Löschen von alten Entitäten ist jetzt einfach eine Frage des Löschens von einer Tabelle pro Tag (ein einzelner Speichervorgang), statt jeden Tag Hunderte und Tausende von individuellen Anmeldeentitäten zu suchen und zu löschen.
Probleme und Überlegungen
Beachten Sie die folgenden Punkte bei der Entscheidung, wie dieses Muster implementiert werden soll:
- Unterstützt der Entwurf Ihrer Anwendung andere Möglichkeiten einer Datenverwendung, z. B. die Suche nach bestimmten Entitäten, die Verknüpfung mit anderen Daten oder das Generieren von zusammengefassten Informationen?
- Vermeidet Ihren Entwurf Hotspots, wenn Sie neue Entitäten einfügen?
- Rechnen Sie mit einer Verzögerungszeit, wenn Sie denselben Tabellennamen nach dem Löschen wiederverwenden möchten. Es empfiehlt sich, immer einen eindeutigen Tabellennamen zu verwenden.
- Rechnen Sie mit einer Drosselung, wenn Sie zuerst eine neue Tabelle verwenden, während der Dienst die Zugriffsmuster lernt und die Partitionen auf den Knoten verteilt. Sie sollten berücksichtigen, wie häufig Sie neue Tabellen erstellen müssen.
Verwendung dieses Musters
Verwenden Sie dieses Muster, wenn Sie eine große Anzahl von Entitäten haben, die gleichzeitig gelöscht werden müssen.
Zugehörige Muster und Anleitungen
Die folgenden Muster und Anleitungen können auch relevant sein, wenn dieses Muster implementiert wird:
- Entitätsgruppentransaktionen
- Ändern von Entitäten
Datenreihenmuster
Speichern Sie vollständige Datenreihen in einer einzelnen Entität, um die Anzahl der von Ihnen vorgenommenen Anforderungen zu minimieren.
Kontext und Problem
Ein häufiges Szenario für eine Anwendung ist, eine Datenreihe zu speichern, die in der Regel auf einmal abgerufen werden muss. Beispiel: Ihre Anwendung erfasst, wie viele Chatnachrichten jeder Mitarbeiter pro Stunde sendet. Diese Informationen verwenden Sie dann, um zu zeichnen, wie viele Meldungen jeder Benutzer in den vergangenen 24 Stunden gesendet hat. Ein Entwurf könnte sein, für jeden Mitarbeiter 24 Entitäten zu speichern:
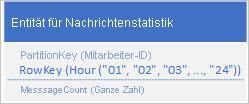
Bei diesem Entwurf können Sie problemlos die Entität finden und aktualisieren, um sie für jeden Mitarbeiter immer dann zu aktualisieren, wenn die Anwendung den Meldungszählerwert aktualisieren muss. Allerdings müssen Sie zum Abrufen der Informationen, mit der ein Diagramm der Aktivität für die vergangenen 24 Stunden zu zeichnen ist, 24 Entitäten abrufen.
Lösung
Verwenden Sie den folgenden Entwurf mit einer separaten Eigenschaft,um den Meldungszähler für jede Stunde zu speichern:
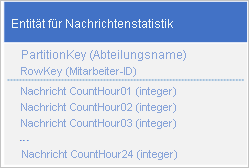
Bei diesem Entwurf können Sie mit einem Zusammenführungsvorgang den Meldungszähler für einen Mitarbeiter für eine bestimmte Stunde aktualisieren. Nun können Sie alle Informationen, die Sie zum Zeichnen des Diagramms benötigen, mit einer Anforderung für eine einzelne Entität abrufen.
Probleme und Überlegungen
Beachten Sie die folgenden Punkte bei der Entscheidung, wie dieses Muster implementiert werden soll:
- Wenn eine vollständige Datenreihe nicht in eine einzelne Entität passt (eine Entität kann bis zu 252 Eigenschaften haben), verwenden Sie einen alternativen Datenspeicher, z. B einen Blob.
- Wenn bei Ihnen mehrere Clients gleichzeitig eine Entität aktualisieren, müssen Sie ETag verwenden, um vollständige optimistische Nebenläufigkeit zu implementieren. Wenn Sie viele Clients haben, können eine Vielzahl von Konflikten auftreten.
Verwendung dieses Musters
Verwenden Sie dieses Muster, wenn Sie eine Datenreihe aktualisieren und abrufen müssen, die einer einzelnen Entität zugeordnet ist.
Zugehörige Muster und Anleitungen
Die folgenden Muster und Anleitungen können auch relevant sein, wenn dieses Muster implementiert wird:
- Muster für große Entitäten
- Zusammenführen oder ersetzen
- Eventual Consistency-Transaktionsmuster (wenn Sie die Datenreihe in einem Blob speichern)
Breite Entitätenmuster
Verwenden Sie mehrere physische Entitäten, um logische Entitäten mit mehr als 252 Eigenschaften zu speichern.
Kontext und Problem
Eine einzelne Entität kann nicht mehr als 252 Eigenschaften (mit Ausnahme der obligatorischen Systemeigenschaften) beinhalten und nicht mehr als 1 MB Daten insgesamt speichern. In einer relationalen Datenbank würden Sie in der Regel die Grenzen umgehen können bezüglich der Größe einer Zeile, indem Sie eine neue Tabelle hinzufügen und eine 1:1-Beziehung erzwingen.
Lösung
Durch Verwendung des Tabellenspeicherdienstes können Sie mehrere Entitäten speichern, um ein einzelnes großes Geschäftsobjekt mit mehr als 252 Eigenschaften darzustellen. Beispiel: Wenn Sie die Anzahl der Chatnachrichten, die von jedem Mitarbeiter in den letzten 365 Tagen gesendet wurde, speichern möchten, können Sie den folgenden Entwurf verwenden, der zwei Entitäten mit unterschiedlichen Schemas verwendet:

Falls Sie eine Änderung vornehmen müssen, die eine Aktualisierung beider Entitäten erfordert, um sie synchron zu halten, können Sie ein EGT verwenden. Ansonsten können Sie einen einzelnen Zusammenführungsvorgang verwenden, um den Meldungszähler für einen bestimmten Tag zu aktualisieren. Um alle Daten für einen einzelnen Mitarbeiter abzurufen, müssen Sie beide Entitäten abrufen, was Sie mit zwei effizienten Anforderungen durchführen können, die beide einen PartitionKey- und einen RowKey-Wert verwenden.
Probleme und Überlegungen
Beachten Sie die folgenden Punkte bei der Entscheidung, wie dieses Muster implementiert werden soll:
- Der Abruf einer vollständigen logischen Entität umfasst mindestens zwei Speichertransaktionen, jeweils eine zum Abrufen der einzelnen physischen Entitäten.
Verwendung dieses Musters
Verwenden Sie dieses Muster, wenn Sie Entitäten speichern müssen, deren Größe oder Anzahl an Eigenschaften die Grenzwerte für eine einzelne Entität im Tabellenspeicherdienst überschreiten.
Zugehörige Muster und Anleitungen
Die folgenden Muster und Anleitungen können auch relevant sein, wenn dieses Muster implementiert wird:
- Entitätsgruppentransaktionen
- Zusammenführen oder ersetzen
Muster für große Entitäten
Verwenden Sie Blob-Speicher zum Speichern großer Eigenschaftswerte.
Kontext und Problem
Eine einzelne Entität kann nicht mehr als 1 MB Daten insgesamt speichern. Wenn eine oder mehrere Ihrer Eigenschaften Werte speichern, die dazu führen, dass die Gesamtgröße der Entität diesen Wert überschreitet, können Sie nicht die gesamte Entität im Tabellenspeicherdienst speichern.
Lösung
Wenn Ihre Entität 1 MB Größe überschreitet, da eine oder mehrere Eigenschaften eine große Datenmenge enthalten, können Sie die Daten im Blob-Dienst und anschließend die Adresse des BLOBs in einer Eigenschaft der Entität speichern. Beispiel: Sie können das Foto des Mitarbeiters im Blob-Speicher und eine Verknüpfung zu dem Foto in der Photo -Eigenschaft der Mitarbeiterentität speichern:
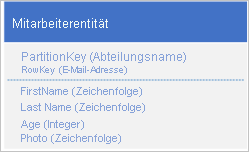
Probleme und Überlegungen
Beachten Sie die folgenden Punkte bei der Entscheidung, wie dieses Muster implementiert werden soll:
- Um "Eventual Consistency" zwischen der Entität im Tabellenspeicherdienst und den Daten im Blob-Dienst beizubehalten, verwenden Sie das Eventual Consistency-Transaktionsmuster zur Verwaltung der Entitäten.
- Das Abrufen einer vollständigen Entität umfasst mindestens zwei Speichertransaktionen: eine zum Abrufen der Entität und eine zum Abrufen der Blob-Daten.
Verwendung dieses Musters
Verwenden Sie dieses Muster, wenn Sie Entitäten speichern müssen, deren Größe die Grenzwerte für eine einzelne Entität im Tabellenspeicherdienst überschreitet.
Zugehörige Muster und Anleitungen
Die folgenden Muster und Anleitungen können auch relevant sein, wenn dieses Muster implementiert wird:
Antimuster voranstellen/anfügen
Erhöhen Sie die Skalierbarkeit, wenn Sie eine große Anzahl von Einfügungen vornehmen möchten, indem Sie die Einfügungen auf mehrere Partitionen verteilen.
Kontext und Problem
Voranstellen oder Anfügen von Entitäten an Ihre gespeicherten Entitäten führen in der Regel dazu, dass in der Anwendung neue Entitäten auf die erste oder letzte Partition aus einer Folge von Partitionen hinzugefügt werden. In diesem Fall finden alle Einfügungen zu einem beliebigen Zeitpunkt in der gleichen Partition statt und erzeugen einen Hotspot, der Lastenausgleich-Einfügungen durch den Tabellenspeicherdienst für mehrere Knoten verhindert und wahrscheinlich dazu führt, dass Ihre Anwendung die Skalierbarkeitsziele der Partition erreicht. Beispiel: Wenn Sie eine Anwendung haben, die Zugriffe auf Netzwerk und Ressourcen von Mitarbeitern protokolliert, könnte eine wie unten gezeigte Entitätsstruktur dazu führen, dass die Partition zur laufenden Stunde zum Hotspot wird, wenn das Transaktionsvolumen das Skalierbarkeitsziel für eine einzelne Partition erreicht:

Lösung
Die folgende alternative Entitätsstruktur vermeidet einen Hotspot auf einer bestimmten Partition, wenn die Anwendung Ereignisse protokolliert:

Beachten Sie, dass in diesem Beispiel sowohl der PartitionKey- als auch der RowKey-Wert ein Verbundschlüssel ist. PartitionKey verwendet sowohl die Abteilung als auch die Mitarbeiter-ID, um die Protokollierung auf mehrere Partitionen zu verteilen.
Probleme und Überlegungen
Beachten Sie die folgenden Punkte bei der Entscheidung, wie dieses Muster implementiert werden soll:
- Unterstützt die alternative Schlüssel-Struktur, die das Erstellen von Hot-Partitionen bei Einfügungen vermeidet, die Abfragen effizient, die von der Clientanwendung vorgenommen werden?
- Bedeutet die erwartete Anzahl von Transaktionen, dass Sie wahrscheinlich die Skalierbarkeitsziele für eine einzelne Partition erreichen und vom Speicherdienst gedrosselt werden?
Verwendung dieses Musters
Vermeiden Sie die Voranstellen/Anfügen-Antimuster, wenn die Anzahl an Transaktionen wahrscheinlich dazu führen wird, dass beim Zugriff auf eine Hot-Partition vom Speicherdienst eine Drosselung erfolgt.
Zugehörige Muster und Anleitungen
Die folgenden Muster und Anleitungen können auch relevant sein, wenn dieses Muster implementiert wird:
Log-Anti-Muster
Sie sollten in der Regel den Blob-Dienst anstelle des Tabellenspeicherdienstes zum Speichern von Protokolldaten verwenden.
Kontext und Problem
Eine allgemeiner Anwendungsfall für Protokolldaten ist, eine Auswahl von Protokolleinträgen für einen bestimmten Datum/Uhrzeitbereich abzurufen. Beispielsweise finden Sie alle Fehler und kritische Meldungen, die Ihre Anwendung zwischen 15:04 und 15:06 an einem bestimmten Datum protokolliert hat. Es empfiehlt sich nicht, das Datum und die Uhrzeit der Protokollmeldung zu verwenden, um die Partition zu bestimmen, in der die Protokolleinträge gespeichert werden sollen. Dies führt zu einer Hot-Partition, da alle Protokolleinträge jederzeit den gleichen PartitionKey-Wert gemeinsam nutzen. (Weitere Informationen finden Sie im Abschnitt Antimuster voranstellen/anfügen.) Beispiel: Das folgende Entitätsschema für eine Protokollmeldung resultiert in einer Hot-Partition, da die Anwendung alle Protokollmeldungen in die Partition für das aktuelle Datum und Stunde schreibt:
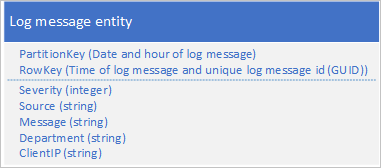
In diesem Beispiel beinhaltet RowKey Datum und Uhrzeit der Protokollmeldung, um sicherzustellen, dass die Protokollmeldungen nach Datum und Uhrzeit sortiert gespeichert werden, sowie eine Meldungs-ID für den Fall, dass mehrere Protokollmeldungen dasselbe Datum und dieselbe Uhrzeit aufweisen.
Ein anderer Ansatz ist die Verwendung von PartitionKey , der sicherstellt, dass die Anwendung Meldungen über einen Bereich von Partitionen schreibt. Beispiel: Wenn die Quelle der Protokollmeldung einen Weg bietet, Meldungen über viele Partitionen zu verteilen, können Sie das folgende Entitätsschema verwenden:

Das Problem mit diesem Schema ist jedoch, dass Sie zum Abrufen der gesamten Protokollmeldungen für eine bestimmte Zeitspanne jede Partition in der Tabelle durchsuchen müssen.
Lösung
Der vorherige Abschnitt hat das Problem bei dem Versuch hervorgehoben, den Tabellenspeicherdienst zum Speichern von Protokolleinträgen zu verwenden und schlug zwei nicht zufriedenstellende Entwürfe vor. Eine Lösung führte zu einer Hot-Partition mit dem Risiko einer schlechten Leistung beim Schreiben von Protokollmeldungen. Die andere Lösung führte zu einer schlechten Leistung bei Abfragen aufgrund der Anforderung, jede Partition in der Tabelle zum Abrufen von Protokollmeldungen für eine bestimmte Zeitspanne zu scannen. BLOB-Speicher bietet eine bessere Lösung für diese Art Szenario und dies ist die Funktionsweise, wie Azure Storage Analytics die gesammelten Protokolldaten speichert.
In diesem Abschnitt wird erläutert, wie Storage Analytics Protokolldaten im Blob-Speicher speichert, als anschauliches Beispiel zu diesem Ansatz, um Daten zu speichern, die Sie in der Regel nach Bereich abfragen.
Storage Analytics speichert Protokollmeldungen in einem Trennzeichen-getrennten Format in mehrere Blobs. Das Trennzeichen-getrennte Format erleichtert es einer Clientanwendung, die Daten in der Protokollmeldung zu analysieren.
Storage Analytics verwendet eine Namenskonvention für Blobs, die es Ihnen ermöglicht, einen Blob (oder Blobs) zu finden, der die Protokollmeldungen enthält, nach denen Sie suchen. Beispiel: Ein Blob mit dem Namen "queue/2014/07/31/1800/000001.log" enthält die Protokollmeldungen, die dem Warteschlangendienst für die Stunde zugeordnet sind, beginnend um 18:00 Uhr am 31. Juli 2014. Die "000001" zeigt an, dass dies die erste Protokolldatei für diesen Zeitraum ist. Storage Analytics zeichnet auch die Zeitstempel der Protokollmeldungen von Vor- und Nachname an, die in der Datei als Teil der Blob-Metadaten gespeichert sind. Die API für Blobspeicher ermöglicht Ihnen, Blobs in einem Container zu finden, die auf einem Namenspräfix basieren. Um alle Blobs zu finden, die Protokolldaten für die Warteschlange für die Stunde beinhalten, die um 18:00 Uhr beginnt, können Sie das Präfix „queue/2014/07/31/1800“ verwenden.
Storage Analytics puffert Protokollmeldungen intern, und aktualisiert dann den geeigneten Blob oder erstellt einen neuen Blob mit dem neuesten Satz Protokolleinträge. Dies reduziert die Anzahl der Schreibvorgänge, die für den Blob-Dienst ausgeführt werden müssen.
Wenn Sie eine ähnliche Lösung in Ihre eigene Anwendung implementieren, müssen Sie berücksichtigen, wie Sie den Kompromiss zwischen Zuverlässigkeit (sofortiges Schreiben jedes Protokolleintrags in den Blob-Speicher) und Kosten und Skalierbarkeit (Pufferung der Aktualisierungen in Ihrer Anwendung und Schreiben im Stapel zum Blob-Speicher) verwalten.
Probleme und Überlegungen
Beachten Sie die folgenden Punkte bei der Entscheidung, wie Sie Protokolldaten speichern:
- Wenn Sie einen Tabellenentwurf erstellen, der potenzielle Hot-Partitionen vermeidet, werden Sie feststellen, dass Sie auf Ihre Protokolldaten nicht effizient zugreifen können.
- Zur Verarbeitung von Protokolldaten muss ein Client häufig viele Datensätze laden.
- Obwohl Protokolldaten häufig strukturiert sind, ist Blob-Speicher möglicherweise eine bessere Lösung.
Überlegungen zur Implementierung
Dieser Abschnitt beschreibt einige Überlegungen, die Sie berücksichtigen sollten, wenn Sie die in den vorherigen Abschnitten beschriebenen Muster implementieren. In diesem Abschnitt werden hauptsächlich Beispiele verwendet, die in C# geschrieben sind und die Speicherclientbibliothek (Version 4.3.0 zum Redaktionszeitpunkt) verwenden.
Abrufen von Entitäten
Wie im Abschnitt „Entwurf für Abfragen“ erläutert, ist die effizienteste Abfrage eine Punktabfrage. In einigen Szenarien müssen Sie jedoch mehrere Entitäten abrufen. Dieser Abschnitt beschreibt einige allgemeine Ansätze zum Abrufen von Entitäten mithilfe der Speicherclientbibliothek.
Ausführen einer Punktabfrage mithilfe der Speicherclientbibliothek
Die einfachste Möglichkeit zum Ausführen einer Punktabfrage ist die Verwendung der Methode GetEntityAsync, wie im folgenden C#-Codeausschnitt gezeigt, der eine Entität mit dem PartitionKey-Wert „Sales“ und dem RowKey-Wert „212“ abruft:
EmployeeEntity employee = await employeeTable.GetEntityAsync<EmployeeEntity>("Sales", "212");
Beachten Sie, dass in diesem Beispiel erwartet wird, dass die abgerufene Entität den Typ EmployeeEntityhat.
Abrufen von mehreren Entitäten mithilfe von LINQ
Sie können mithilfe von LINQ mehrere Entitäten aus dem Tabellenspeicherdienst abrufen, wenn Sie mit der Standardbibliothek für Tabellen in Microsoft Azure Cosmos DB arbeiten.
dotnet add package Azure.Data.Tables
Geben Sie Namespaces an, damit die folgenden Beispiele funktionieren:
using System.Linq;
using Azure.Data.Tables
Das Abrufen von mehreren Entitäten erfolgt durch Angeben einer Abfrage mit einer filter-Klausel. Um einen Tabellenscan zu vermeiden, sollten Sie immer den PartitionKey-Wert in die filter-Klausel einschließen. Um Tabellen- und Partitionsscans zu vermeiden, sollten Sie möglichst auch den RowKey-Wert einschließen. Der Tabellenspeicherdienst unterstützt eine begrenzte Anzahl von Vergleichsoperatoren (größer als, größer oder gleich, kleiner als, kleiner oder gleich, gleich und ungleich), die in der filter-Klausel verwendet werden können.
Im folgenden Beispiel ist employeeTable ein TableClient-Objekt. In diesem Beispiel werden alle Mitarbeiter gesucht, deren Nachname mit „B“ beginnt (vorausgesetzt, in RowKey ist der Nachname gespeichert) und die der Vertriebsabteilung angehören (vorausgesetzt, in PartitionKey ist der Name der Abteilung gespeichert):
var employees = employeeTable.Query<EmployeeEntity>(e => (e.PartitionKey == "Sales" && e.RowKey.CompareTo("B") >= 0 && e.RowKey.CompareTo("C") < 0));
Beachten Sie, dass die Abfrage aus Effizienzgründen sowohl einen RowKey- als auch einen PartitionKey-Wert enthält.
Das folgende Codebeispiel zeigt die entsprechende Funktion ohne Verwendung von LINQ-Syntax:
var employees = employeeTable.Query<EmployeeEntity>(filter: $"PartitionKey eq 'Sales' and RowKey ge 'B' and RowKey lt 'C'");
Hinweis
Die Query-Beispielmethoden enthalten drei Filterbedingungen.
Abrufen einer großen Anzahl von Entitäten aus einer Abfrage
Eine optimale Abfrage gibt auf der Grundlage eines PartitionKey- und eines RowKey-Werts eine einzelne Entität zurück. In einigen Szenarien haben Sie jedoch möglicherweise eine Anforderung, um viele Entitäten von der gleichen Partition oder sogar von vielen Partitionen zurückzugeben.
In solchen Szenarien sollten Sie die Leistung Ihrer Anwendung immer vollständig testen.
Eine Abfrage für den Tabellenspeicherdienst kann maximal 1000 Entitäten gleichzeitig zurückgeben und für maximal fünf Sekunden ausgeführt werden. Wenn der Ergebnissatz mehr als 1.000 Entitäten enthält, wenn die Abfrage nicht innerhalb von fünf Sekunden abgeschlossen wurde oder die Abfrage die Partitionsgrenzen überschreitet, gibt der Tabellenspeicherdienst ein Fortsetzungstoken zurück, das der Clientanwendung ermöglicht, den nächsten Satz Entitäten anzufordern. Weitere Informationen über die Funktionsweise von Fortsetzungstoken finden Sie unter Abfragetimeout und Paginierung.
Wenn Sie die Clientbibliothek für Azure-Tabellen verwenden, kann diese automatisch Fortsetzungstoken für Sie verarbeiten, da sie Entitäten aus dem Tabellenspeicherdienst zurückgibt. Das folgende C#-Codebeispiel verwendet die Clientbibliothek und verarbeitet Fortsetzungstoken automatisch, wenn diese vom Tabellenspeicherdienst in einer Antwort zurückgegeben werden:
var employees = employeeTable.Query<EmployeeEntity>("PartitionKey eq 'Sales'")
foreach (var emp in employees)
{
// ...
}
Sie können auch die maximale Anzahl von Entitäten angeben, die pro Seite zurückgegeben werden. Im folgenden Beispiel wird gezeigt, wie Sie Entitäten mit maxPerPage abfragen:
var employees = employeeTable.Query<EmployeeEntity>(maxPerPage: 10);
// Iterate the Pageable object by page
foreach (var page in employees.AsPages())
{
// Iterate the entities returned for this page
foreach (var emp in page.Values)
{
// ...
}
}
In komplexeren Szenarien sollten Sie das vom Dienst zurückgegebene Fortsetzungstoken speichern, damit Ihr Code genau steuert, wann die nächsten Seiten abgerufen werden. Das folgende Beispiel zeigt ein grundlegendes Szenario, wie das Token abgerufen und auf paginierte Ergebnisse angewendet werden kann:
string continuationToken = null;
bool moreResultsAvailable = true;
while (moreResultsAvailable)
{
var page = employeeTable
.Query<EmployeeEntity>()
.AsPages(continuationToken, pageSizeHint: 10)
.FirstOrDefault(); // pageSizeHint limits the number of results in a single page, so we only enumerate the first page
if (page == null)
break;
// Get the continuation token from the page
// Note: This value can be stored so that the next page query can be executed later
continuationToken = page.ContinuationToken;
var pageResults = page.Values;
moreResultsAvailable = pageResults.Any() && continuationToken != null;
// Iterate the results for this page
foreach (var result in pageResults)
{
// ...
}
}
Durch die explizite Verwendung von Fortsetzungstoken können Sie steuern, wann Ihre Anwendung das nächste Datensegment abruft. Beispiel: Wenn Ihre Clientanwendung Benutzer in die Lage versetzt, durch die Entitäten zu blättern, die in einer Tabelle gespeichert sind, kann ein Benutzer sich entscheiden, nicht durch alle über die Abfrage abgerufenen Entitäten zu blättern. Somit würde Ihre Anwendung nur einen Fortsetzungstoken verwenden, um das nächste Segment abzurufen, wenn der Benutzer mit dem Blättern durch alle Entitäten im aktuellen Segment fertig ist. Dieser Ansatz hat mehrere Vorteile:
- Er versetzt Sie in die Lage, die Datenmenge für den Abruf vom Tabellenspeicherdienst zu begrenzen, die sie über das Netzwerk verschieben.
- Er versetzt Sie in die Lage, asynchrone I/O in .NET auszuführen.
- Sie können den Fortsetzungstoken in einen permanenten Speicher serialisieren, damit bei einem Absturz der Anwendung fortgesetzt werden kann.
Hinweis
Ein Fortsetzungstoken gibt in der Regel ein Segment mit 1.000 Entitäten oder weniger zurück. Dies ist auch der Fall, wenn Sie die Anzahl von Einträgen, die eine Abfrage zurückgibt, begrenzen, indem Sie Take verwenden, um die ersten n Entitäten zurückzugeben, die mit Ihren Suchkriterien übereinstimmen. Der Tabellenspeicherdienst kann ein Segment zurückgeben, das weniger als n Entitäten enthält, sowie ein Fortsetzungstoken, mit dem Sie die restlichen Entitäten abrufen können.
Serverseitige Projektion
Eine einzelne Entität kann bis zu 255 Eigenschaften haben und bis zu 1 MB groß sein. Wenn Sie die Tabelle durchsuchen und Entitäten abrufen, benötigen Sie möglicherweise nicht alle Eigenschaften und Sie können unnötiges Übertragen von Daten vermeiden (trägt zum Verringern der Latenz und Kosten bei). Sie können auch eine serverseitige Projektion verwenden, um nur die benötigten Eigenschaften zu übertragen. Das folgende Beispiel ruft nur die Email-Eigenschaft (zusammen mit PartitionKey, RowKey, Timestamp und ETag) aus den Entitäten ab, die durch die Abfrage ausgewählt werden.
var subsetResults = query{
for employee in employeeTable.Query<EmployeeEntity>("PartitionKey eq 'Sales'") do
select employee.Email
}
foreach (var e in subsetResults)
{
Console.WriteLine("RowKey: {0}, EmployeeEmail: {1}", e.RowKey, e.Email);
}
Beachten Sie, dass der RowKey -Wert auch dann verfügbar ist, wenn er nicht in der Liste der abzurufenden Eigenschaften enthalten war.
Ändern von Entitäten
Die Speicherclientbibliothek versetzt Sie in die Lage, Ihre im Tabellenspeicherdienst gespeicherten Entitäten durch Einfügen, Löschen und Aktualisieren zu ändern. Sie können EGTs verwenden, um mehrere Einfüge-, Aktualisierungs- und Löschvorgänge zu stapeln und so die Anzahl der benötigten Roundtrips zu reduzieren und die Leistung Ihrer Lösung zu verbessern.
Ausnahmen, die ausgelöst werden, wenn die Speicherclientbibliothek eine EGT ausführt, enthalten normalerweise den Index der Entität, die einen Fehler bei der Stapelverarbeitung verursacht hat. Dies ist hilfreich, wenn Sie Code debuggen, der EGTs verwendet.
Sie sollten auch berücksichtigen, wie Ihr Design beeinflusst wird und wie Ihre Anwendung Nebenläufigkeit und Aktualisierungsvorgänge handhabt.
Verwalten von Nebenläufigkeit
Der Tabellenspeicherdienst implementiert standardmäßig Prüfungen der optimistischen Nebenläufigkeit auf der Ebene der einzelnen Entitäten für die Vorgänge Einfügen, Zusammenführen und Löschen, obwohl es für einen Client möglich ist, das Umgehen dieser Prüfungen durch den Tabellenspeicherdienst zu erzwingen. Weitere Informationen zur Verwaltung von Nebenläufigkeit durch den Tabellenspeicherdienst finden Sie unter Verwalten von Nebenläufigkeit in Microsoft Azure Storage.
Zusammenführen oder ersetzen
Die Replace-Methode der TableOperation-Klasse ersetzt immer die vollständige Entität im Tabellenspeicherdienst. Wenn Sie keine Eigenschaft in die Anforderung einschließen und diese Eigenschaft in der gespeicherten Entität existiert, entfernt die Anforderung diese Eigenschaft von der gespeicherten Entität. Sie müssen alle Eigenschaften in die Anforderung mit einschließen, wenn Sie nicht möchten, dass eine Eigenschaft aus einer gespeicherten Entität explizit entfernen wird.
Sie können die Merge-Methode der TableOperation-Klasse verwenden, um die Datenmenge zu reduzieren, die Sie an den Tabellenspeicherdienst senden, wenn Sie eine Entität aktualisieren möchten. Die Merge -Methode ersetzt alle Eigenschaften in der gespeicherten Entität mit Eigenschaftswerten aus der Entität, die in der Anforderung enthalten ist, behält aber alle Eigenschaften in der gespeicherten Entität bei, die in der Anforderung nicht enthalten sind. Dies ist hilfreich, wenn Sie große Entitäten haben und nur eine kleine Anzahl von Eigenschaften in einer Anforderung aktualisieren müssen.
Hinweis
Die Replace- und die Merge-Methode sind nicht erfolgreich, wenn die Entität nicht vorhanden ist. Als Alternative können Sie die InsertOrReplace-Methode und die InsertOrMerge-Methode verwenden, die eine neue Entität erstellen, falls keine vorhanden ist.
Arbeiten mit heterogenen Entitätstypen
Der Tabellenspeicherdienst ist ein schemaloser Tabellenspeicher. Das bedeutet, dass eine einzelne Tabelle Entitäten mehrerer Typen speichern kann, sodass Ihr Entwurf von einem hohen Maß an Flexibilität profitiert. Das folgende Beispiel veranschaulicht eine Tabelle, in der sowohl Mitarbeiter- als auch Abteilungsentitäten gespeichert sind:
| PartitionKey | Zeilenschlüssel | Timestamp | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||
| |||||||||||
|
|||||||||||
|
Trotzdem muss jede Entität über PartitionKey-, RowKey- und Timestamp-Werte verfügen, kann aber einen beliebigen Satz von Eigenschaften besitzen. Darüber hinaus gibt es nichts, was den Typ einer Entität anzeigen kann, es sei denn, Sie entscheiden sich dafür, diese Information irgendwo zu speichern. Es gibt zwei Optionen für die Identifizierung des Entitätstyps:
- Voranstellen des Entitätstyps vor den RowKey-Wert (oder möglicherweise den PartitionKey-Wert). Beispielsweise EMPLOYEE_000123 oder DEPARTMENT_SALES als RowKey-Werte.
- Verwenden Sie eine separate Eigenschaft zum Aufzeichnen des Entitätstyps, wie in der folgenden Tabelle dargestellt.
| PartitionKey | Zeilenschlüssel | Timestamp | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||||
| |||||||||||||
|
|||||||||||||
|
Die erste Option mit dem vorangestellten Entitätstyp vor den RowKeyist sinnvoll, wenn eine Möglichkeit besteht, dass zwei Entitäten mit unterschiedlichen Typen über denselben Schlüsselwert verfügen können. Hier werden auch Entitäten des gleichen Typs in der Partition zusammen gruppiert.
Die in diesem Abschnitt beschriebenen Verfahren sind besonders wichtig für die Erörterung der Vererbungsbeziehungen weiter oben in diesem Handbuch (Artikel Modellieren von Beziehungen).
Hinweis
Sie sollten die Angabe einer Versionsnummer im Wert des Entitätstyps berücksichtigen, um der Clientanwendung zu ermöglichen, POCO-Objekte zu entwickeln und mit verschiedenen Versionen zu arbeiten.
Im restlichen Teil dieses Abschnitts werden einige Funktionen der Speicherclientbibliothek beschrieben, mit denen die Arbeit mit mehreren Entitätstypen in derselben Tabelle erleichtert wird.
Abrufen von heterogenen Entitätstypen
Wenn Sie die Tabellenclientbibliothek verwenden, stehen Ihnen drei Optionen für die Arbeit mit mehreren Entitätstypen zur Verfügung.
Wenn Sie den Entitätstyp kennen, der mit bestimmten RowKey- und PartitionKey-Werten gespeichert ist, können Sie diesen angeben, wenn Sie die Entität wie in den vorherigen beiden Beispielen dargestellt abrufen. In diesen Beispielen werden Entitäten vom Typ EmployeeEntity abgerufen: Ausführen einer Punktabfrage mithilfe der Speicherclientbibliothek und Abrufen von mehreren Entitäten mithilfe von LINQ.
Die zweite Option ist die Verwendung des TableEntity -Typs (ein Eigenschaftenbehälter) anstelle eines konkreten POCO-Entitätstyps (diese Option kann auch die Leistung verbessern, da keine Notwendigkeit zum Serialisieren und Deserialisieren der Entität in .NET-Typen besteht). Der folgende C#-Code ruft möglicherweise mehrere Entitäten mit unterschiedlichen Typen aus der Tabelle ab, gibt jedoch alle Entitäten als TableEntity-Instanzen zurück. Anschließend bestimmt er mithilfe der EventType -Eigenschaft den Typ von jeder Entität:
Pageable<TableEntity> entities = employeeTable.Query<TableEntity>(x =>
x.PartitionKey == "Sales" && x.RowKey.CompareTo("B") >= 0 && x.RowKey.CompareTo("F") <= 0)
foreach (var entity in entities)
{
if (entity.GetString("EntityType") == "Employee")
{
// use entityTypeProperty, RowKey, PartitionKey, Etag, and Timestamp
}
}
Um andere Eigenschaften abzurufen, müssen Sie die GetString-Methode in der entity der TableEntity-Klasse verwenden.
Ändern von heterogenen Entitätstypen
Zum Löschen einer Entität müssen Sie den Typ wissen. Sie wissen den Typ einer Entität immer, wenn sie ihn Einfügen. Sie können jedoch den TableEntity-Typ verwenden, um eine Entität zu aktualisieren, ohne deren Typ zu kennen und ohne eine POCO-Entitätsklasse zu verwenden. Im folgenden Codebeispiel wird eine einzelne Entität abgerufen und überprüft, ob die EmployeeCount-Eigenschaft vorhanden ist, bevor sie aktualisiert wird.
var result = employeeTable.GetEntity<TableEntity>(partitionKey, rowKey);
TableEntity department = result.Value;
if (department.GetInt32("EmployeeCount") == null)
{
throw new InvalidOperationException("Invalid entity, EmployeeCount property not found.");
}
employeeTable.UpdateEntity(department, ETag.All, TableUpdateMode.Merge);
Steuern des Zugriffs mit Shared Access Signatures
Sie können Shared Access Signature (SAS)-Token verwenden, um Clientanwendungen zu ermöglichen, Tabellenentitäten zu ändern (und abzufragen) ohne die Notwendigkeit, Ihren Speicherkontoschlüssel in Ihren Code einzuschließen. Es gibt in der Regel drei Hauptvorteile, wenn Sie SAS in Ihrer Anwendung verwenden:
- Sie müssen Ihren Speicherkontoschlüssel nicht auf eine unsichere Plattform (z. B. ein mobiles Gerät) verteilen, um auf das Gerät zuzugreifen und Entitäten im Tabellenspeicherdienst zu ändern.
- Sie können einige der Aufgaben auslagern, die Web- und Workerrollen beim Verwalten von Entitäten in Client-Geräten durchführen, z. B. für Computer der Endbenutzer und mobile Geräte.
- Sie können einen eingeschränkten und einen zeitbegrenzten Satz von Berechtigungen für einen Client zuweisen (z. B. den schreibgeschützten Zugriff auf bestimmte Ressourcen).
Weitere Informationen zur Verwendung von SAS-Token mit dem Tabellenspeicherdienst finden Sie unter Verwenden von Shared Access Signatures (SAS).
Sie müssen jedoch weiterhin die SAS-Token generieren, die eine Clientanwendung für die Entitäten im Tabellenspeicherdienst gewähren. Sie sollten dies in einer Umgebung tun, die sicheren Zugriff auf Ihre Speicherkontoschlüssel gewährleistet. In der Regel verwenden Sie eine Web- oder Worker-Rolle zum Generieren der SAS-Token und übermittelt sie an die Client-Anwendungen, die Zugriff auf Ihre Entitäten benötigen. Da immer noch Aufwand zum Generieren und Bereitstellen von SAS-Token für Clients notwendig ist, sollten Sie erwägen, wie Sie diesen Aufwand am besten reduzieren, besonders in Szenarien mit großen Datenmengen.
Es ist möglich, einen SAS-Token zu generieren, der Zugriff auf eine Teilmenge der Entitäten in einer Tabelle erteilt. Standardmäßig erstellen Sie ein SAS-Token für die gesamte Tabelle, aber Sie können auch angeben, dass dem SAS-Token entweder Zugriff auf einen Bereich von PartitionKey-Werten oder einen Bereich von PartitionKey- und RowKey-Werten gewährt wird. Sie können auswählen, ob Sie SAS-Token für einzelne Benutzer des Systems in einer Art generieren, das jedes Benutzer-SAS-Token nur Zugriff auf ihre eigenen Entitäten im Tabellenspeicherdienst ermöglicht.
Asynchrone und parallele Vorgänge
Angenommen, Sie verteilen Ihre Anfragen über mehrere Partitionen. In diesem Fall können Sie Durchsatz und Client-Reaktionsfähigkeit mithilfe von asynchronen oder parallelen Abfragen verbessern. Beispiel: Sie haben möglicherweise zwei oder mehr Workerrollen-Instanzen, die auf die Tabellen parallel zugreifen. Sie können einzelne Worker-Rollen haben, die für bestimmte Gruppen von Partitionen zuständig sind oder einfach mehrere Workerrollen-Instanzen, von denen jede auf alle Partitionen in einer Tabelle zugreifen kann.
Innerhalb einer Client-Instanz können Sie den Durchsatz verbessern, indem Sie Speichervorgänge asynchron ausführen. Die Speicherclientbibliothek erleichtert das Schreiben von asynchronen Abfragen und Änderungen. Beispiel: Sie können mit der synchronen Methode starten, mit der alle Entitäten in einer Partition wie im folgenden C#-Code gezeigt abgerufen werden:
private static void ManyEntitiesQuery(TableClient employeeTable, string department)
{
TableContinuationToken continuationToken = null;
do
{
var employees = employeeTable.Query<EmployeeEntity>($"PartitionKey eq {department}");
foreach (var emp in employees.AsPages())
{
// ...
continuationToken = emp.ContinuationToken;
}
} while (continuationToken != null);
}
Sie können diesen Code einfach ändern, damit die Abfrage wie folgt asynchron ausgeführt wird:
private static async Task ManyEntitiesQueryAsync(TableClient employeeTable, string department)
{
TableContinuationToken continuationToken = null;
do
{
var employees = await employeeTable.QueryAsync<EmployeeEntity>($"PartitionKey eq {department}");
foreach (var emp in employees.AsPages())
{
// ...
continuationToken = emp.ContinuationToken;
}
} while (continuationToken != null);
}
In diesem Asynchron-Beispiel sehen Sie die folgenden Änderungen zur synchronen Version:
- Die Methodensignatur enthält jetzt den async-Modifizierer und gibt eine Task-Instanz zurück.
- Anstatt die Query-Methode zum Abrufen von Ergebnissen aufzurufen, ruft die Methode jetzt die QueryAsync-Methode auf und verwendet den await-Modifizierer, um Ergebnisse asynchron abzurufen.
Die Clientanwendung kann diese Methode mehrmals aufrufen (mit unterschiedlichen Werten für den department-Parameter). Damit wird jede Abfrage in einem separaten Thread ausgeführt.
Sie können Entitäten auch asynchron einfügen, aktualisieren und löschen. Das folgende C#-Beispiel zeigt eine einfache, synchrone Methode zum Einfügen oder Ersetzen einer Mitarbeiterentität:
private static void SimpleEmployeeUpsert(
TableClient employeeTable,
EmployeeEntity employee)
{
var result = employeeTable.UpdateEntity(employee, Azure.ETag.All, TableUpdateMode.Replace);
Console.WriteLine("HTTP Status: {0}", result.Status);
}
Sie können diesen Code einfach ändern, damit das Update wie folgt asynchron ausgeführt wird:
private static async Task SimpleEmployeeUpsertAsync(
TableClient employeeTable,
EmployeeEntity employee)
{
var result = await employeeTable.UpdateEntityAsync(employee, Azure.ETag.All, TableUpdateMode.Replace);
Console.WriteLine("HTTP Status: {0}", result.Result.Status);
}
In diesem Asynchron-Beispiel sehen Sie die folgenden Änderungen zur synchronen Version:
- Die Methodensignatur enthält jetzt den async-Modifizierer und gibt eine Task-Instanz zurück.
- Statt die Execute-Methode aufzurufen, um die Entität zu aktualisieren, ruft die Methode jetzt die ExecuteAsync-Methode auf und verwendet den await-Modifizierer, um Ergebnisse asynchron abzurufen.
Die Clientanwendung kann mehrere asynchrone Methoden wie diese aufrufen und jeder Methodenaufruf wird auf einem separaten Thread ausgeführt.