Erstellen eines Synapse-Arbeitsbereichs
In diesem Tutorial erfahren Sie, wie Sie einen Synapse-Arbeitsbereich, einen dedizierten SQL-Pool und einen serverlosen Apache Spark-Pool erstellen.
Voraussetzungen
Um die Schritte dieses Tutorials ausführen zu können, benötigen Sie Zugriff auf eine Ressourcengruppe, für die Ihnen die Rolle Besitzer zugewiesen wurde. Erstellen Sie den Synapse-Arbeitsbereich in dieser Ressourcengruppe.
Erstellen eines Synapse-Arbeitsbereichs im Azure-Portal
Starten des Prozesses
- Öffnen Sie das Azure-Portal. Geben Sie in der Suchleiste Synapse ein, und drücken Sie nicht die EINGABETASTE.
- Wählen Sie in den Suchergebnissen unter Dienste den Eintrag Azure Synapse Analytics aus.
- Wählen Sie Erstellen aus, um einen Arbeitsbereich zu erstellen.
Registerkarte „Grundlegende Einstellungen“ > „Projektdetails“
Füllen Sie die folgenden Felder aus:
- Abonnement: Wählen Sie ein beliebiges Abonnement.
- Ressourcengruppe: Wählen Sie eine beliebige Ressourcengruppe.
- Verwaltete Ressourcengruppe: Lassen Sie dieses Feld leer.
Registerkarte „Grundlegende Einstellungen“ > „Details zum Arbeitsbereich“
Füllen Sie die folgenden Felder aus:
- Arbeitsbereichsname: Wählen Sie einen beliebigen global eindeutigen Namen. In diesem Tutorial wird myworkspace verwendet.
- Region: Wählen Sie die Region aus, in der Sie Ihre Clientanwendungen/-dienste (z. B. Azure-VM, Power BI, Azure Analysis Services) und Speicher platziert haben, die Daten enthalten (z. B. Azure Data Lake Storage, Azure Cosmos DB-Analysespeicher).
Hinweis
Ein Arbeitsbereich, der sich nicht am gleichen Ort wie die Clientanwendungen oder der Speicher befindet, kann die Grundursache zahlreicher Leistungsprobleme sein. Wenn Ihre Daten oder die Clients in mehreren Regionen platziert werden, können Sie separate Arbeitsbereiche in den Regionen erstellen, in denen sich auch Ihre Daten und Clients befinden.
Gehen Sie unter Data Lake Storage Gen 2 auswählen wie folgt vor:
- Wählen Sie unter Kontoname die Option Neu erstellen aus, und geben Sie für das neue Speicherkonto den Namen contosolake oder einen ähnlichen Namen ein. Dieser Name muss eindeutig sein.
- Wählen Sie unter Dateisystemname die Option Neu erstellen aus, und geben Sie den Namen Benutzer ein. Dadurch wird ein Speichercontainer namens Benutzer erstellt. Der Arbeitsbereich verwendet dieses Speicherkonto als primäres Speicherkonto für Spark-Tabellen und Spark-Anwendungsprotokolle.
- Aktivieren Sie das Kästchen „Mir die Rolle "Mitwirkender an Storage-Blobdaten" für das Data Lake Storage Gen2-Konto zuweisen“.
Abschließen des Vorgangs
Wählen Sie Bewerten + erstellen>Erstellen aus. Ihr Arbeitsbereich steht nach wenigen Minuten zur Verfügung.
Hinweis
Wie Sie Arbeitsbereichsfunktionen für einen vorhandenen dedizierten SQL-Pool (ehemals SQL DW) aktivieren, erfahren Sie unter Aktivieren von Synapse-Arbeitsbereichsfunktionen für einen dedizierten SQL-Pool (ehemals SQL DW).
Öffnen von Synapse Studio
Nachdem Ihr Azure Synapse-Arbeitsbereich erstellt wurde, haben Sie zwei Möglichkeiten zum Öffnen von Synapse Studio:
Öffnen Sie Ihren Synapse-Arbeitsbereich im Azure-Portal, und wählen Sie im Abschnitt Übersicht des Synapse-Arbeitsbereichs im Feld „Synapse Studio öffnen“ den Eintrag Öffnen aus.
Navigieren Sie zu
https://web.azuresynapse.net, und melden Sie sich bei Ihrem Arbeitsbereich an.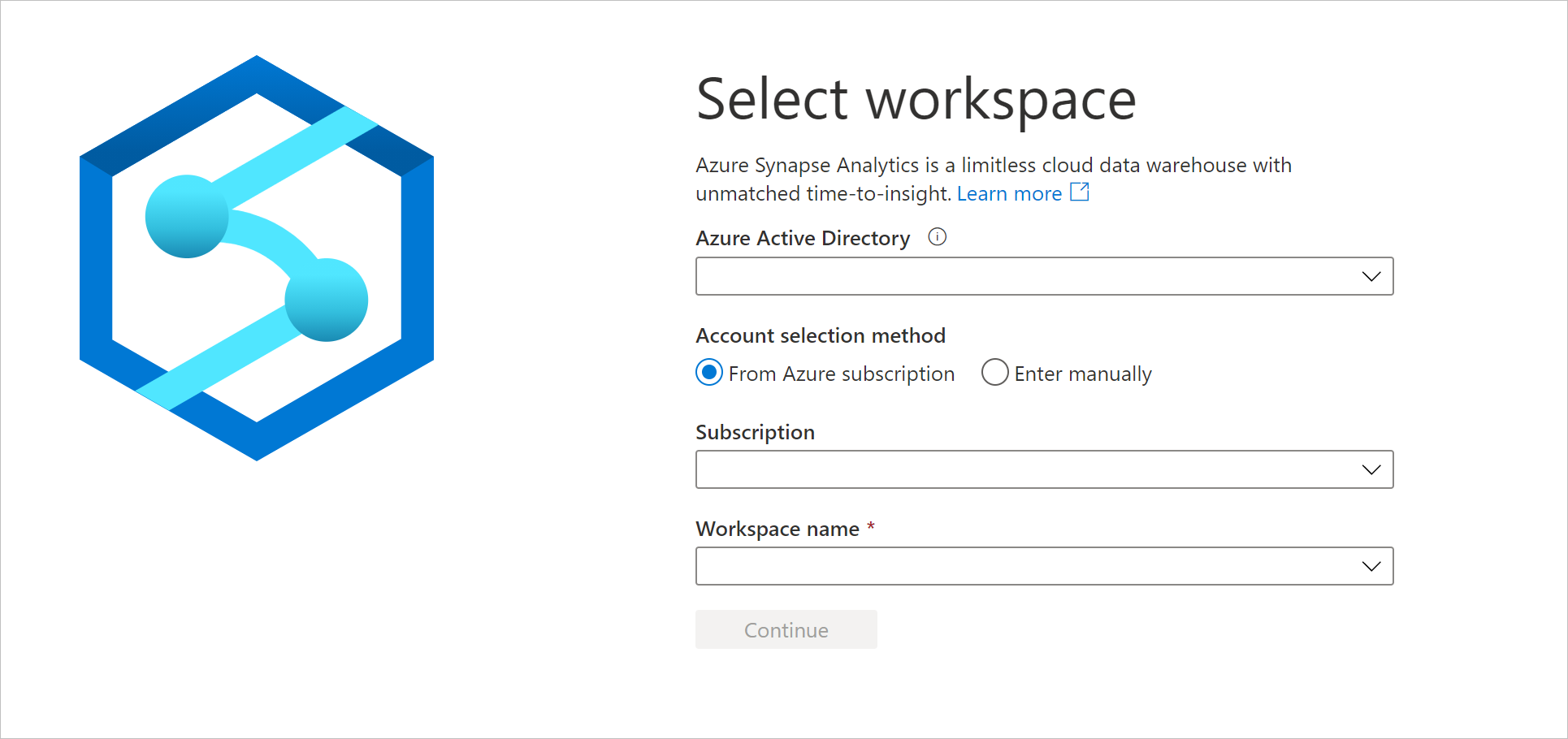
Hinweis
Um sich bei Ihrem Arbeitsbereich anzumelden, gibt es zwei Kontoauswahlmethoden. Eine stammt aus dem Azure-Abonnement und die andere ist die manuelle Eingabe. Wenn Sie über die Synapse Azure-Rolle oder Azure-Rollen auf höherer Ebene verfügen, können Sie beide Methoden verwenden, um sich beim Arbeitsbereich anzumelden. Wenn Sie nicht über eine der zugehörigen Azure-Rollen verfügen und Ihnen eine RBAC-Rolle von Synapse gewährt wurde, können Sie sich nur mit der manuellen Eingabe beim Arbeitsbereich anmelden. Weitere Informationen zur rollenbasierten Zugriffssteuerung für Synapse finden Sie unter Informationen zu der rollenbasierte Zugriffssteuerung von Synapse (RBAC).
Platzieren von Beispieldaten im primären Speicherkonto
In diesem Leitfaden zu den ersten Schritten verwenden Sie für viele Beispiele ein kleines Beispieldataset mit 100.000 Zeilen mit NYC Taxi-Daten. Sie beginnen damit, das Dataset im primären Speicherkonto zu platzieren, das Sie für den Arbeitsbereich erstellt haben.
- Laden Sie das Dataset „NYC Taxi – Green Trip“ auf Ihren Computer herunter. Navigieren Sie über den obigen Link zum ursprünglichen Speicherort des Datasets, wählen Sie ein bestimmtes Jahr aus, und laden Sie die Fahrtenaufzeichnungen für „Green Taxi“ im Parquet-Format herunter.
- Benennen Sie die heruntergeladene Datei in NYCTripSmall.parquet um.
- Navigieren Sie in Synapse Studio zum Hub Daten.
- Wählen Sie Mit Link aus.
- In der Kategorie Azure Data Lake Storage Gen2 wird ein Element mit einem Namen wie myworkspace (Primär – contosolake) angezeigt.
- Wählen Sie den Container mit dem Namen Benutzer (Primär) aus.
- Wählen Sie Hochladen und dann die von Ihnen heruntergeladene Datei
NYCTripSmall.parquetaus.
Nach dem Hochladen der Parquet-Datei ist sie über zwei entsprechende URIs verfügbar:
https://contosolake.dfs.core.windows.net/users/NYCTripSmall.parquetabfss://users@contosolake.dfs.core.windows.net/NYCTripSmall.parquet
Ersetzen Sie in den folgenden Beispielen in diesem Tutorial contosolake auf der Benutzeroberfläche durch den Namen des primären Speicherkontos, das Sie für Ihren Arbeitsbereich ausgewählt haben.