Was ist Azure Synapse Analytics?
Azure Synapse ist ein integrierter Unternehmensanalysedienst zur schnelleren Gewinnung von Erkenntnissen aus Data Warehouses und Big Data-Systemen. In Azure Synapse ist die jeweils beste Technologie aus unterschiedlichen Bereichen vereint: SQL-Technologie für Data Warehousing in Unternehmen, Spark-Technologie für Big Data-Zwecke, Data Explorer für die Analyse von Protokollen und Zeitreihen, Pipelines für die Datenintegration und ETL/ELT sowie eine tiefe Integration in andere Azure-Dienste, z. B. Power BI, Cosmos DB und Azure ML.
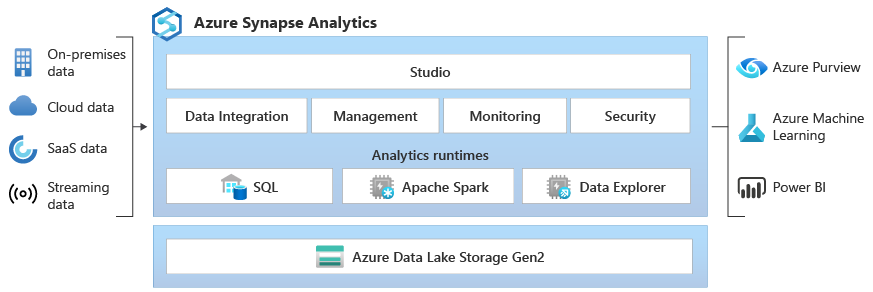
Branchenführendes SQL
Synapse SQL ist ein System für verteilte Abfragen für T-SQL, mit dem Data Warehousing- und Datenvirtualisierungsszenarien realisiert werden können und T-SQL auf Streaming- und Machine Learning-Szenarien erweitert wird.
- Synapse SQL bietet sowohl serverlose als auch dedizierte Ressourcenmodelle. Erstellen Sie dedizierte SQL-Pools zur Reservierung von Rechenleistung für in SQL-Tabellen gespeicherte Daten, um von planbarer Leistung und planbaren Kosten zu profitieren. Für ungeplante Workloads oder Workloads mit Bedarfsspitzen kann der stets verfügbare, serverlose SQL-Endpunkt verwendet werden.
- Nutzen Sie die integrierten Streamingfunktionen, um Daten aus Clouddatenquellen in SQL-Tabellen zu übertragen.
- Integrieren Sie mithilfe von Machine Learning-Modellen KI in SQL, um Daten per T-SQL-Vorhersagefunktion (PREDICT) zu bewerten.
Branchenübliches Apache Spark
Apache Spark für Azure Synapse bietet eine tiefe und nahtlose Integration von Apache Spark – der beliebtesten Open-Source-basierten Big Data-Engine für Datenaufbereitung, Datentechnik, ETL und maschinelles Lernen.
- ML-Modelle mit SparkML-Algorithmen und AzureML-Integration für Apache Spark 3.1 mit integrierter Unterstützung für Linux Foundation Delta Lake.
- Vereinfachtes Ressourcenmodell, bei dem Sie sich nicht mehr mit der Verwaltung von Clustern auseinandersetzen müssen
- Schneller Spark-Start und aggressive automatische Skalierung
- Nutzung Ihrer C#-Kenntnisse und Wiederverwendung von bereits vorhandenem .NET-Code in einer Spark-Anwendung dank integrierter Unterstützung von .NET für Spark
Arbeiten mit Data Lake
Azure Synapse beseitigt die herkömmlichen Technologiebarrieren bei der gemeinsamen Verwendung von SQL und Spark. Beide Lösungen können nach Bedarf und Kenntnisstand miteinander kombiniert werden.
- Tabellen, die auf Dateien im Data Lake definiert sind, werden nahtlos entweder von Spark oder Hive genutzt.
- SQL und Spark können zur direkten Erkundung und Analyse von gespeicherten Parquet-, CSV-, TSV- und JSON-Dateien im Data Lake verwendet werden.
- Schnelles, skalierbares Laden von Daten zwischen SQL- und Spark-Datenbanken
Integrierte Datenintegration
In Azure Synapse sind die gleiche Datenintegrationsengine und die gleichen Umgebungen integriert wie in Azure Data Factory, was die Erstellung umfangreicher bedarfsorientierter ETL-Pipelines ermöglicht, ohne Azure Synapse Analytics zu verlassen.
- Erfassen von Daten aus über 90 Datenquellen
- Kein Programmieraufwand für ETL dank Datenflussaktivitäten
- Orchestrieren von Notebooks, Spark-Aufträgen, gespeicherten Prozeduren, SQL-Skripts und mehr
Data Explorer (Vorschau)
Azure Synapse Data Explorer bietet der Kundschaft eine interaktive Abfrage, um Erkenntnisse aus Protokoll- und Telemetriedaten zu gewinnen. Um vorhandene SQL- und Apache Spark-Analyseruntime-Engines zu ergänzen, ist die Analyseruntime von Data Explorer für effiziente Protokollanalysen mit leistungsstarker Indizierungstechnologie optimiert, um Freitextdaten und halbstrukturierte Daten automatisch zu indizieren, die häufig in den Telemetriedaten zu finden sind.
Verwenden Sie Data Explorer als Datenplattform zum Erstellen von Protokollanalyse- und IoT-Analyselösungen nahezu in Echtzeit für Folgendes:
- Konsolidieren und Korrelieren von Protokoll- und Ereignisdaten über lokale Datenquellen, Clouddatenquellen und Drittanbieterdatenquellen hinweg
- Beschleunigen Ihrer KI-Ops-Journey (Mustererkennung, Anomalieerkennung, Vorhersagen usw.)
- Ersetzen infrastrukturbasierter Protokollsuchlösungen, um Kosten zu sparen und die Produktivität zu steigern
- Erstellen einer IoT Analytics-Lösung für Ihre IoT-Daten
- Erstellen von SaaS-Analyselösungen, um Ihrer internen und externen Kundschaft Dienste bereitzustellen
Einheitliche Benutzeroberfläche
Mit Synapse Studio erhalten Unternehmen eine zentrale Benutzeroberfläche für die Erstellung von Lösungen sowie für Verwaltungs- und Schutzfunktionen.
- Ausführen wichtiger Aufgaben: Erfassen, Untersuchen, Vorbereiten, Orchestrieren, Visualisieren
- Überwachen von Ressourcen, Verbrauch und Benutzer*innen in SQL, Spark und Data Explorer
- Verwenden der rollenbasierten Zugriffssteuerung zum Vereinfachen des Zugriffs auf Analyseressourcen
- Schreiben von SQL-, Spark- oder KQL-Code und Integrieren in CI/CD-Prozesse des Unternehmens
Mit der Synapse-Community in Kontakt treten
- Microsoft Q&A: Stellen Sie technische Fragen.
- Stack Overflow: Stellen Sie Fragen zur Entwicklung.