Kostenverwaltung für serverlose SQL-Pools in Azure Synapse Analytics
In diesem Artikel wird erläutert, wie Sie Kosten für einen serverlosen SQL-Pool in Azure Synapse Analytics abschätzen und verwalten können:
- Schätzen der Menge verarbeiteter Daten vor dem Absenden einer Abfrage
- Verwenden der Kostenkontrollfunktion zum Festlegen des Budgets
Beachten Sie, dass die Kosten für einen serverlosen SQL-Pool in Azure Synapse Analytics nur einen Teil der monatlichen Kosten Ihrer Azure-Rechnung darstellen. Bei Verwendung anderer Azure-Dienste werden Ihnen alle Azure-Dienste und -Ressourcen berechnet, die unter Ihrem Azure-Abonnement genutzt werden, z. B. auch Drittanbieterdienste. In diesem Artikel wird erläutert, wie Sie Kosten für einen serverlosen SQL-Pool in Azure Synapse Analytics planen und verwalten können.
Verarbeitete Datenmenge
Verarbeitete Daten ist die Datenmenge, die vom System temporär gespeichert wird, während eine Abfrage ausgeführt wird. Verarbeitete Daten bestehen aus folgenden Mengen:
- Menge der aus dem Speicher gelesenen Daten. Diese Menge umfasst:
- Während des Lesens von Daten gelesene Daten.
- Während des Lesens von Metadaten gelesene Daten (für Dateiformate, die Metadaten enthalten, z. B. Parquet).
- Menge von Daten in Zwischenergebnissen. Diese Daten werden zwischen Knoten übertragen, während die Abfrage ausgeführt wird. Sie umfassen die Datenübertragung an Ihren Endpunkt in unkomprimiertem Format.
- Menge der in den Speicher geschriebenen Daten. Wenn Sie Ihr Resultset mit CETAS in den Speicher exportieren, wird die Menge der geschriebenen Ausgabedaten der Menge der verarbeiteten Daten für den SELECT-Teil von CETAS hinzugefügt.
Das Lesen von Dateien aus dem Speicher ist hochgradig optimiert. Der Prozess verwendet:
- Vorabruf, wodurch sich die Menge der gelesenen Daten möglicherweise etwas erhöht. Wenn eine Abfrage eine ganze Datei liest, kommt es zu keiner Erhöhung der Datenmenge. Wird eine Datei teilweise gelesen, wie z. B. bei Top N-Abfragen, werden durch den Vorabruf etwas mehr Daten gelesen.
- Einen optimierten CSV-Parser (durch Trennzeichen getrennte Werte). Wenn Sie PARSER_VERSION='2.0' zum Lesen von CSV-Dateien verwenden, erhöhen sich die aus dem Speicher gelesenen Datenmenge leicht. Ein optimierter CSV-Parser liest Dateien parallel in Blöcken gleicher Größe. Blöcke enthalten nicht notwendigerweise ganze Zeilen. Um sicherzustellen, dass alle Zeilen analysiert werden, liest der optimierte CSV-Parser auch kleine Fragmente angrenzender Blöcke. Durch diesen Prozess wird die Datenmenge leicht erhöht.
Statistik
Der Abfrageoptimierer für serverlose SQL-Pools verwendet Statistiken, um optimale Abfrageausführungspläne zu generieren. Sie können Statistiken manuell erstellen. Andernfalls erstellt der serverlose SQL-Pool diese automatisch. In beiden Fällen werden Statistiken erstellt, indem eine gesonderte Abfrage ausgeführt wird, die eine bestimmte Spalte mit einer vorgegebenen Stichprobenrate zurückgibt. Dieser Abfrage ist eine Menge verarbeiteter Daten zugeordnet.
Wenn Sie dieselbe oder eine andere Abfrage ausführen, die von erstellten Statistiken profitieren würde, werden Statistiken nach Möglichkeit wiederverwendet. Bei der Erstellung von Statistiken werden keine zusätzlichen Daten verarbeitet.
Wenn Statistiken für eine Parquet-Spalte erstellt werden, wird nur die relevante Spalte aus den Dateien gelesen. Wenn Statistiken für eine CSV-Spalte erstellt werden, werden ganze Dateien gelesen und analysiert.
Runden
Die Menge verarbeiteter Daten wird pro Abfrage auf den nächsten MB-Wert aufgerundet. Für jede Abfrage werden mindestens 10 MB verarbeitete Daten veranschlagt.
Was verarbeitete Daten nicht enthalten
- Metadaten auf Serverebene (z. B. Anmeldungen, Rollen und Anmeldeinformationen auf Serverebene).
- Datenbanken, die Sie in Ihrem Endpunkt erstellen. Diese Datenbanken enthalten nur Metadaten (z. B. Benutzer, Rollen, Schemas, Sichten, Inline-Tabellenwertfunktionen [TVFs], gespeicherte Prozeduren, datenbankweit gültige Anmeldeinformationen, externe Datenquellen, externe Dateiformate und externe Tabellen).
- Wenn Sie den Schemarückschluss verwenden, werden Dateifragmente gelesen, um Spaltennamen und Datentypen abzuleiten, und die Menge der gelesenen Daten wird der Menge verarbeiteter Daten hinzugefügt.
- DDL-Anweisungen (Data Definition Language, Datendefinitionssprache), mit Ausnahme der CREATE STATISTICS-Anweisung, weil sie Daten aus dem Speicher auf Grundlage des angegebenen Stichprobenprozentsatzes verarbeitet.
- Reine Metadatenabfragen.
Verringern der Menge verarbeiteter Daten
Sie können die Menge verarbeiteter Daten pro Abfrage optimieren und die Leistung verbessern, indem Sie Ihre Daten partitionieren und in ein komprimiertes, spaltenbasiertes Format wie Parquet umwandeln.
Beispiele
Stellen Sie sich drei Tabellen vor.
- Die Tabelle „population_csv“ basiert auf 5 TB CSV-Dateien. Die Dateien sind in fünf gleich großen Spalten angeordnet.
- Die Tabelle „population_parquet“ enthält dieselben Daten wie die Tabelle „population_csv“. Sie basiert auf 1 TB Parquet-Dateien. Diese Tabelle ist kleiner als die vorherige, da die Daten im Parquet-Format komprimiert werden.
- Die Tabelle „very_small_csv“ basiert auf 100 KB CSV-Dateien.
Abfrage 1: SELECT SUM(population) FROM population_csv
Diese Abfrage liest und analysiert ganze Dateien, um Werte für die Spalte „population“ abzurufen. Knoten verarbeiten Fragmente dieser Tabelle, und die „population“-Summe für jedes Fragment wird zwischen den Knoten übertragen. Die endgültige Summe wird an Ihren Endpunkt übertragen.
Diese Abfrage verarbeitet 5 TB Daten, zuzüglich einer kleinen zusätzlichen Datenmenge für die Übertragung von Summen von Fragmenten.
Abfrage 2: SELECT SUM(population) FROM population_parquet
Wenn Sie komprimierte und spaltenbasierte Formate wie Parquet abfragen, werden weniger Daten als in Abfrage 1 gelesen. Dieses Ergebnis wird angezeigt, weil der serverlose SQL-Pool anstelle der gesamten Datei eine einzelne komprimierte Spalte liest. In diesem Fall werden 0,2 TB gelesen. (Fünf gleich große Spalten sind jeweils 0,2 TB groß.) Knoten verarbeiten Fragmente dieser Tabelle, und die „population“-Summe für jedes Fragment wird zwischen den Knoten übertragen. Die endgültige Summe wird an Ihren Endpunkt übertragen.
Diese Abfrage verarbeitet 0,2 TB Daten, zuzüglich einer kleinen zusätzlichen Datenmenge für die Übertragung von Summen von Fragmenten.
Abfrage 3: SELECT * FROM population_parquet
Diese Abfrage liest alle Spalten und überträgt alle Daten in einem unkomprimierten Format. Wenn das Komprimierungsformat 5:1 ist, verarbeitet die Abfrage 6 TB, weil sie 1 TB liest und 5 TB unkomprimierte Daten überträgt.
Abfrage 4: SELECT COUNT(*) FROM very_small_csv
Diese Abfrage liest ganze Dateien. Die Gesamtgröße der Dateien im Speicher für diese Tabelle beträgt 100 KB. Knoten verarbeiten Fragmente dieser Tabelle, und die Summe für jedes Fragment wird zwischen den Knoten übertragen. Die endgültige Summe wird an Ihren Endpunkt übertragen.
Diese Abfrage verarbeitet etwas mehr als 100 KB an Daten. Die Menge der für diese Abfrage verarbeiteten Daten wird auf 10 MB aufgerundet, wie im Abschnitt Runden dieses Artikels angegeben.
Kostenkontrolle
Mit der Kostenkontrollfunktion in serverlosen SQL-Pools können Sie das Budget für die Menge verarbeiteter Daten festlegen. Sie können das Budget in TB an Daten festlegen, die für einen Tag, eine Woche oder einen Monat verarbeitet werden. Sie können gleichzeitig ein oder mehrere Budgets festlegen. Zum Konfigurieren der Kostenkontrolle für einen serverlosen SQL-Pool können Sie Synapse Studio oder T-SQL verwenden.
Konfigurieren der Kostenkontrolle für einen serverlosen SQL-Pool in Synapse Studio
Um die Kostenkontrolle für den serverlosen SQL-Pool in Synapse Studio zu konfigurieren, navigieren Sie im Menü auf der linken Seite zu „Element verwalten“, und wählen Sie dann unter „Analysepools“ die Option „SQL-Poolelement“ aus. Wenn Sie mit dem Mauszeiger auf einen serverlosen SQL-Pool zeigen, wird ein Symbol für Kostenkontrolle angezeigt. Klicken Sie auf dieses Symbol.
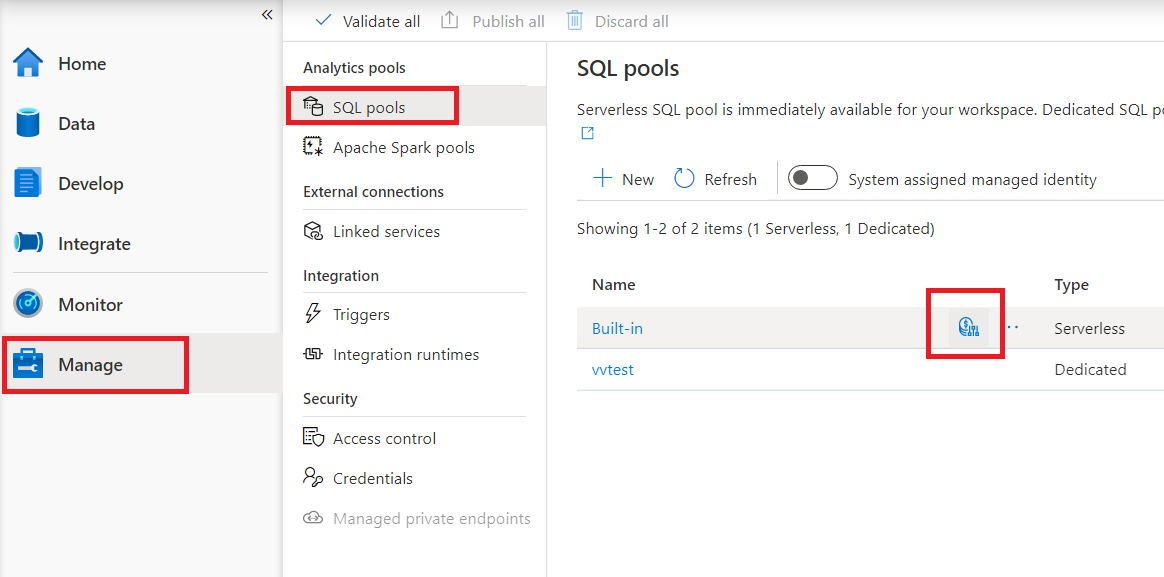
Nachdem Sie auf das Kostenkontrolle-Symbol geklickt haben, wird eine Seitenleiste angezeigt:
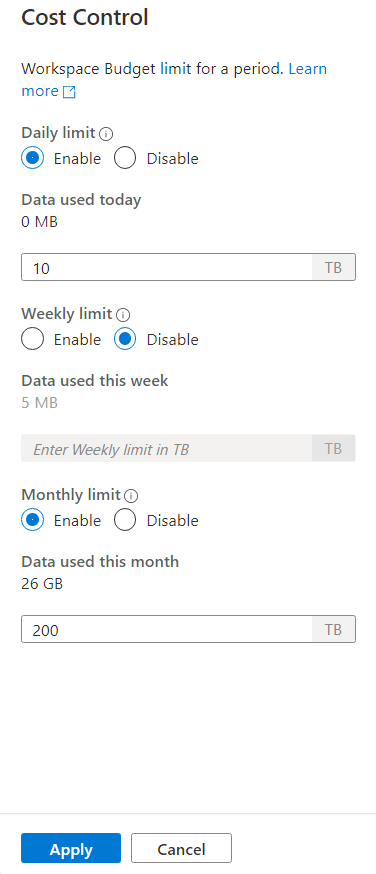
Um ein oder mehrere Budgets festzulegen, klicken Sie zunächst auf das Optionsfeld „Aktivieren“ für ein Budget, das Sie festlegen möchten, und geben Sie dann den ganzzahligen Wert in das Textfeld ein. Die Einheit für den Wert ist TB. Nachdem Sie die gewünschten Budgets konfiguriert haben, klicken Sie am unteren Rand der Seitenleiste auf die Schaltfläche „Anwenden“. Das war‘s – Ihr Budget ist nun festgelegt.
Konfigurieren der Kostenkontrolle für einen serverlosen SQL-Pool in T-SQL
Zum Konfigurieren der Kostenkontrolle für einen serverlosen SQL-Pool in T-SQL müssen Sie mindestens eine der folgenden gespeicherten Prozeduren ausführen.
sp_set_data_processed_limit
@type = N'daily',
@limit_tb = 1
sp_set_data_processed_limit
@type= N'weekly',
@limit_tb = 2
sp_set_data_processed_limit
@type= N'monthly',
@limit_tb = 3334
Um die aktuelle Konfiguration anzuzeigen, führen Sie die folgende T-SQL-Anweisung aus:
SELECT * FROM sys.configurations
WHERE name like 'Data processed %';
Um anzuzeigen, wie viele Daten während des aktuellen Tags, der Woche oder des Monats verarbeitet wurden, führen Sie die folgende T-SQL-Anweisung aus:
SELECT * FROM sys.dm_external_data_processed
Überschreiten der in der Kostenkontrolle definierten Grenzwerte
Wenn während der Abfrageausführung ein Grenzwert überschritten wird, wird die Abfrage nicht beendet.
Bei Überschreiten eines Grenzwerts wird die neue Abfrage mit einer Fehlermeldung abgelehnt, die Details zum Zeitraum, zum definierten Grenzwert für diesen Zeitraum und zu den für diesen Zeitraum verarbeiteten Daten enthält. Wenn z. B. eine neue Abfrage ausgeführt wird, bei der das wöchentliche Limit auf 1 TB festgelegt und überschritten wurde, lautet die Fehlermeldung wie folgt:
Query is rejected because SQL Serverless budget limit for a period is exceeded. (Period = Weekly: Limit = 1 TB, Data processed = 1 TB))
Nächste Schritte
Informationen zur Optimierung der Leistung Ihrer Abfragen finden Sie unter Bewährte Methoden für serverlose SQL-Pools.