Hochverfügbarkeit der horizontalen SAP HANA-Skalierung unter Red Hat Enterprise Linux
Dieser Artikel beschreibt, wie man ein hochverfügbares SAP HANA-System in einer horizontale Skalierung-Konfiguration einsetzt. Konkret nutzt die Konfiguration die HANA-Systemreplikation (HSR) und Pacemaker auf Azure Red Hat Enterprise Linux Virtual Machines (VMs). Die freigegebenen Dateisysteme in der vorgestellten Architektur sind über NFS eingebunden und werden von Azure NetApp Files oder über eine NFS-Freigabe in Azure Files bereitgestellt.
In den Beispielkonfigurationen und Installationsbefehlen ist die HANA-Instanz 03 und die HANA-System-ID HN1.
Voraussetzungen
Einige Leser werden davon profitieren, eine Reihe von SAP-Hinweisen und -Ressourcen zu konsultieren, bevor sie mit den Themen in diesem Artikel weitermachen:
- SAP-Hinweis 1928533 enthält:
- Eine Liste der Azure-VM-Größen, die für die Bereitstellung von SAP-Software unterstützt werden.
- Wichtige Kapazitätsinformationen für Azure-VM-Größen
- Unterstützte SAP-Software, Betriebssystem- und Datenbankkombinationen.
- Erforderliche SAP-Kernelversion für Windows und Linux in Microsoft Azure
- SAP-Hinweis 2015553: Listet die Voraussetzungen für SAP-unterstützte SAP-Softwareimplementierungen in Azure auf.
- SAP-Hinweis [2002167]: Enthält empfohlene Betriebssystemeinstellungen für RHEL.
- SAP-Hinweis 2009879: Hat SAP HANA Richtlinien für RHEL.
- Der SAP-Hinweis 3108302 enthält SAP HANA-Leitfäden für Red Hat Enterprise Linux 9.x.
- SAP-Hinweis 2178632: Enthält detaillierte Informationen über alle Überwachungsmetriken, die für SAP in Azure gemeldet werden.
- SAP-Hinweis 2191498: Enthält die erforderliche SAP-Host-Agent-Version für Linux in Azure.
- SAP-Hinweis 2243692: Enthält Informationen zur SAP-Lizenzierung unter Linux in Azure.
- SAP-Hinweis 1999351: Enthält zusätzliche Informationen zur Fehlerbehebung für die erweiterte Azure-Überwachungserweiterung für SAP.
- SAP-Hinweis 1900823: Enthält Informationen zu den Speicheranforderungen von SAP HANA.
- SAP-Community-Wiki: Enthält alle erforderlichen SAP-Hinweise für Linux.
- Azure Virtual Machines Planung und Implementierung für SAP auf Linux.
- Azure Virtual Machines Bereitstellung für SAP auf Linux.
- Azure Virtual Machines DBMS-Bereitstellung für SAP auf Linux.
- SAP HANA Netzwerkanforderungen.
- Allgemeine RHEL-Dokumentation:
- Übersicht über die hohe Verfügbarkeit der Zusatzmodule.
- Hochverfügbare Add-on-Verwaltung.
- Hochverfügbarkeits-Zusatzreferenz.
- Red Hat Enterprise Linux Netzwerkhandbuch.
- Wie konfiguriere ich SAP HANA horizontale Skalierung-Systemreplikation in einem Pacemaker-Cluster mit HANA-Dateisystemen auf NFS-Freigaben.
- Aktiv/Aktiv (leseaktiviert) : RHEL Hochverfügbarkeit-Lösung für SAP HANA Scale-out und Systemreplikation.
- Azure-spezifische RHEL-Dokumentation:
- Azure NetApp Files Dokumentation.
- NFS v4.1-Volumes auf Azure NetApp Files für SAP HANA.
- Dokumentation zu Azure Files
Übersicht
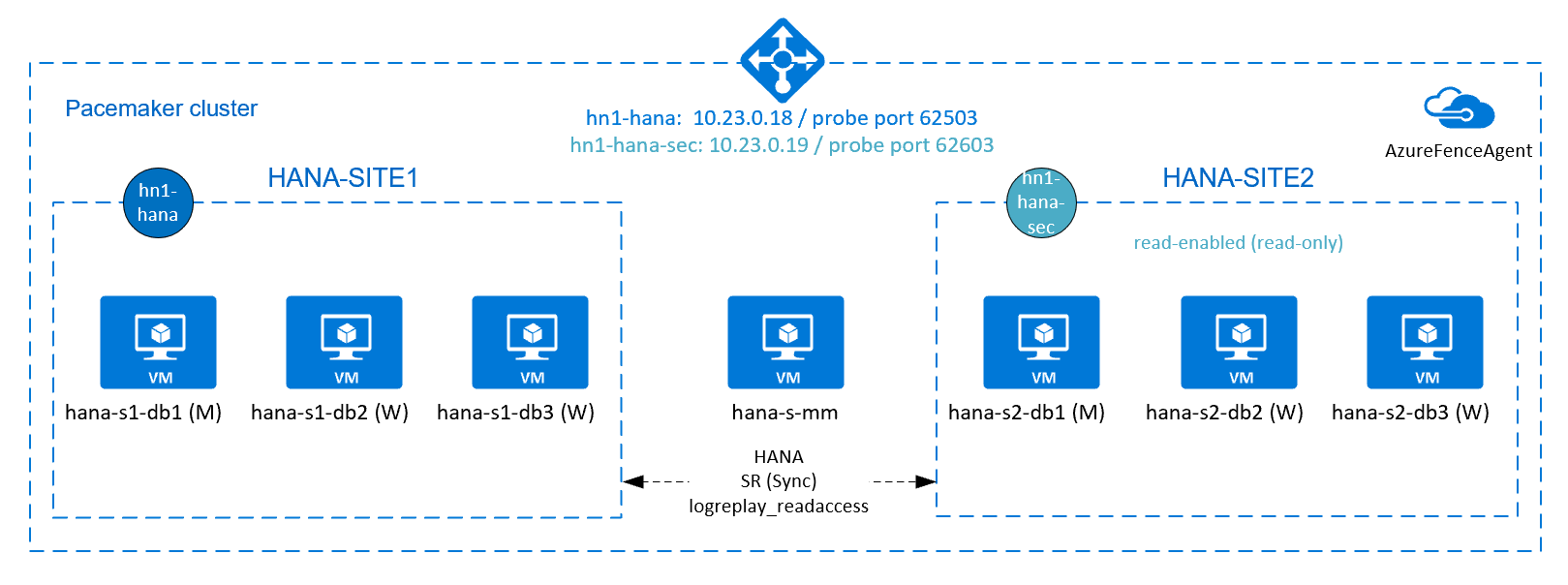
Um HANA-Hochverfügbarkeit für HANA horizontale Skalierung -Installationen zu erreichen, können Sie die HANA-Systemreplikation konfigurieren und die Lösung mit einem Pacemaker-Cluster schützen, um ein automatisches Failover zu ermöglichen. Wenn ein aktiver Knoten ausfällt, führt der Clusterknoten einen Failover zu den HANA-Ressourcen am anderen Standort aus.
Im folgenden Diagramm gibt es drei HANA-Knoten an jedem Standort und einen Majority-Maker-Knoten, um ein "Split-Brain"-Szenario zu verhindern. Die Anweisungen können angepasst werden, um mehr VMs als HANA DB-Knoten einzubeziehen.
Das freigegebene HANA-Dateisystem /hana/shared in der vorgestellten Architektur kann von Azure NetApp Files oder einer NFS-Freigabe in Azure Files bereitgestellt werden. Das freigegebene HANA-Dateisystem wird als NFS auf jedem HANA-Knoten an demselben HANA-Systemreplikationsstandort bereitgestellt. Die Dateisysteme /hana/data und /hana/log sind lokale Dateisysteme und werden nicht gemeinsam von den HANA-Datenbankknoten verwendet. SAP HANA wird im nicht freigegebenen Modus installiert.
Informationen zu empfohlenen SAP HANA-Speicherkonfigurationen finden Sie unter Speicherkonfigurationen für SAP HANA Azure VMs.
Wichtig
Wenn Sie alle HANA-Dateisysteme in Azure NetApp Files bereitstellen, wird für Produktionssysteme, bei denen die Leistung wichtig ist, empfohlen, die Verwendung einer Azure NetApp Files-Anwendungsvolumegruppe für SAP HANA zu bewerten und in Betracht zu ziehen.

Das vorstehende Diagramm zeigt drei Subnetze, die innerhalb eines virtuellen Azure-Netzwerks dargestellt werden, entsprechend den SAP HANA-Netzwerkempfehlungen:
- Für die Kundenkommunikation:
client10.23.0.0/24 - Für die interne HANA-Internode-Kommunikation:
inter10.23.1.128/26 - Für die HANA-Systemreplikation:
hsr10.23.1.192/26
Da /hana/data und /hana/log auf lokalen Datenträgern eingesetzt werden, ist es nicht erforderlich, ein separates Subnetz und separate virtuelle Netzwerkkarten für die Kommunikation mit dem Speicher einzusetzen.
Wenn Sie Azure NetApp Files verwenden, werden die NFS-Volumes für /hana/shared in einem separaten Subnetz bereitgestellt und an Azure NetApp Files delegiert: anf 10.23.1.0/26.
Einrichten der Infrastruktur
In den folgenden Anweisungen wird davon ausgegangen, dass Sie bereits die Ressourcengruppe und das Azure Virtual Network mit drei Azure Virtual Network-Subnetzen erstellt haben: client, inter und hsr.
Bereitstellen von virtuellen Linux-Computern über das Azure-Portal
Stellen Sie die virtuellen Azure-Computer bereit. Für diese Konfiguration stellen Sie sieben virtuelle Maschinen bereit:
- Drei virtuelle Maschinen, die als HANA-DB-Knoten für HANA-Replikationsstandort 1 dienen: hana-s1-db1, hana-s1-db2 und hana-s1-db3.
- Drei virtuelle Maschinen, die als HANA-DB-Knoten für HANA-Replikationsstandort 2 dienen: hana-s2-db1, hana-s2-db2 und hana-s2-db3.
- Eine kleine virtuelle Maschine, die als Mehrheitsbeschaffer dient: hana-s-mm.
Die VMs, die als SAP DB HANA-Knoten eingesetzt werden, sollten von SAP für HANA zertifiziert sein, wie im SAP HANA Hardware-Verzeichnis veröffentlicht. Wenn Sie die HANA DB-Knoten bereitstellen, stellen Sie sicher, dass Sie beschleunigtes Netzwerk wählen.
Für den Major Maker Node können Sie eine kleine VM einsetzen, da diese VM keine SAP HANA-Ressourcen ausführt. Der Majority Maker VM wird in der Clusterkonfiguration verwendet, um eine ungerade Anzahl von Clusterknoten in einem Split-Brain-Szenario zu erreichen. Der virtuelle Majority Maker-Computer benötigt in diesem Beispiel nur eine virtuelle Netzwerkschnittstelle im Subnetz
client.Stellen Sie lokal verwaltete Datenträger für
/hana/dataund/hana/logbereit. Die empfohlene Mindestspeicherkonfiguration für/hana/dataund/hana/logist in der Speicherkonfigurationen für SAP HANA Azure VMs beschrieben.Stellen Sie die primäre Netzwerkschnittstelle für die einzelnen virtuellen Computer im
client-Subnetz des virtuellen Netzwerks bereit. Wenn der virtuelle Computer über das Azure-Portal bereitgestellt wird, erfolgt die automatische Generierung des Namens der Netzwerkschnittstelle. In diesem Artikel werden die automatisch generierten primären Netzwerkschnittstellen als hana-s1-db1-client, hana-s1-db2-client, hana-s1-db3-client und so weiter bezeichnet. Diese Netzwerkschnittstellen sind mit demclientAzure-Subnetz für virtuelle Netzwerke angeschlossen.Wichtig
Vergewissern Sie sich, dass das von Ihnen gewählte Betriebssystem für SAP HANA auf den von Ihnen verwendeten VM-Typen SAP-zertifiziert ist. Eine Liste der von SAP HANA zertifizierten VM-Typen und Betriebssystemversionen für diese Typen finden Sie unter SAP HANA zertifizierte IaaS-Plattformen. Gehen Sie in die Details des aufgeführten VM-Typs, um die vollständige Liste der von SAP HANA unterstützten Betriebssystemversionen für diesen Typ zu erhalten.
Erstellen Sie sechs Netzwerkschnittstellen, eine für jeden virtuellen HANA DB-Computer im
inter-Subnetz des virtuellen Netzwerks (in diesem Beispiel hana-s1-db1-inter, hana-s1-db2-inter, hana-s1-db3-inter, hana-s2-db1-inter, hana-s2-db2-inter und hana-s2-db3-inter).Erstellen Sie sechs Netzwerkschnittstellen, eine für jeden virtuellen HANA DB-Computer im
hsr-Subnetz des virtuellen Netzwerks (in diesem Beispiel hana-s1-db1-hsr, hana-s1-db2-hsr, hana-s1-db3-hsr, hana-s2-db1-hsr, hana-s2-db2-hsr und hana-s2-db3-hsr).Fügen Sie die neu erstellten virtuellen Netzwerkschnittstellen an die entsprechenden virtuellen Computer an:
- Navigieren Sie im Azure-Portal zum virtuellen Computer.
- Wählen Sie im linken Fensterbereich die Optionen Virtuelle Maschinen. Filtern Sie nach dem Namen des virtuellen Computers (z. B. hana-s1-db1), und wählen Sie dann den virtuellen Computer aus.
- Wählen Sie im Fenster Übersicht die Option Anhalten, um die Zuordnung der virtuellen Maschine aufzuheben.
- Wählen Sie Netzwerk aus, und fügen Sie dann die Netzwerkschnittstelle an. Wählen Sie in der Dropdown-Liste Netzwerkschnittstelle anschließen die bereits erstellten Netzwerkschnittstellen für die Subnetze
interundhsr. - Wählen Sie Speichern aus.
- Wiederholen Sie die Schritte b bis e für die übrigen VMs (in diesem Beispiel hana-s1-db2, hana-s1-db3, hana-s2-db1, hana-s2-db2 und hana-s2-db3).
- Lassen Sie die virtuellen Maschinen vorerst im gestoppten Zustand.
Aktivieren Sie beschleunigte Vernetzung für die zusätzlichen Netzwerkschnittstellen für die Subnetze
interundhsr, indem Sie wie folgt vorgehen:Öffnen Sie Azure Cloud Shell im Azure-Portal.
Führen Sie die folgenden Befehle aus, um die beschleunigte Vernetzung für die zusätzlichen Netzwerkschnittstellen zu aktivieren, die mit den Subnetzen
interundhsrverbunden sind.az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db1-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db2-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db3-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db1-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db2-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db3-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db1-hsr --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db2-hsr --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db3-hsr --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db1-hsr --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db2-hsr --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db3-hsr --accelerated-networking true
Starten Sie die virtuellen HANA DB-Maschinen.
Konfigurieren von Azure Load Balancer
Während der VM-Konfiguration können Sie im Abschnitt „Netzwerk“ einen Lastenausgleich erstellen oder einen vorhandenen Lastenausgleich auswählen. Führen Sie die folgenden Schritte aus, um den Standardlastenausgleich für das Hochverfügbarkeitssetup der HANA-Datenbank einzurichten.
Hinweis
- Wählen Sie für die HANA-Skalierung die NIC für das Subnetz
clientaus, wenn Sie die VMs im Back-End-Pool hinzufügen. - Der vollständige Befehlssatz in der Azure-Befehlszeilenschnittstelle und in PowerShell fügt die VMs mit der primären NIC im Back-End-Pool hinzu.
Führen Sie die unter Erstellen eines Lastenausgleichs beschriebenen Schritte aus, um über das Azure-Portal einen Standardlastenausgleich für ein SAP-Hochverfügbarkeitssystem einzurichten. Berücksichtigen Sie beim Einrichten des Lastenausgleichs die folgenden Punkte:
- Front-End-IP-Konfiguration: Erstellen Sie eine IP-Adresse für das Front-End. Wählen Sie dasselbe virtuelle Netzwerk und Subnetz aus wie für Ihre Datenbank-VMs.
- Back-End-Pool: Erstellen Sie einen Back-End-Pool, und fügen Sie Datenbank-VMs hinzu.
- Regeln für eingehenden Datenverkehr: Erstellen Sie eine Lastenausgleichsregel. Führen Sie die gleichen Schritte für beide Lastenausgleichsregeln aus.
- Front-End-IP-Adresse: Wählen Sie eine Front-End-IP-Adresse aus.
- Back-End-Pool: Wählen Sie einen Back-End-Pool aus.
- Hochverfügbarkeitsports: Wählen Sie diese Option aus.
- Protokoll: Wählen Sie TCP.
- Integritätstest: Erstellen Sie einen Integritätstest mit folgenden Details:
- Protokoll: Wählen Sie TCP.
- Port: Beispielsweise 625<Instanznr.>
- Intervall: Geben Sie 5 ein.
- Testschwellenwert: Geben Sie 2 ein.
- Leerlauftimeout (Minuten): Geben Sie 30 ein.
- Floating IP aktivieren: Wählen Sie diese Option aus.
Hinweis
Die Konfigurationseigenschaft numberOfProbes für Integritätstests (im Portal als Fehlerschwellenwert bezeichnet) wird nicht berücksichtigt. Legen Sie die probeThreshold-Eigenschaft auf 2 fest, um die Anzahl erfolgreicher oder nicht erfolgreicher aufeinanderfolgender Integritätstests zu steuern. Diese Eigenschaft kann derzeit nicht über das Azure-Portal festgelegt werden. Verwenden Sie daher entweder die Azure-Befehlszeilenschnittstelle oder den PowerShell-Befehl.
Wichtig
Floating IP wird bei einer NIC-Sekundär-IP-Konfiguration in Load-Balancing-Szenarien nicht unterstützt. Einzelheiten finden Sie unter Azure Load Balancer Einschränkungen. Wenn Sie eine zusätzliche IP-Adresse für die VM benötigen, setzen Sie eine zweite Netzwerkkarte ein.
Hinweis
Wenn Sie den Standard-Load-Balancer verwenden, sollten Sie sich der folgenden Einschränkung bewusst sein. Wenn Sie VMs ohne öffentliche IP-Adressen im Backend-Pool eines internen Load Balancers platzieren, gibt es keine ausgehende Internet-Konnektivität. Um das Routing zu öffentlichen Endpunkten zu ermöglichen, müssen Sie eine zusätzliche Konfiguration vornehmen. Weitere Informationen finden Sie unter Konnektivität öffentlicher Endpunkte für VMs, die Azure Load Balancer Standard in SAP-Hochverfügbarkeitsszenarios verwenden.
Wichtig
Aktivieren Sie keine TCP-Zeitstempel auf Azure-VMs, die sich hinter Azure Load Balancer befinden. Die Aktivierung von TCP-Zeitstempeln führt dazu, dass die Health Probes fehlschlagen. Setzen Sie den Parameter net.ipv4.tcp_timestamps auf 0. Details finden Sie unter Load Balancer Health Probes und SAP Hinweis 2382421.
Bereitstellen von NFS
Es gibt zwei Optionen für die Bereitstellung von für Azure natives NFS für /hana/shared. Sie können das NFS-Volume in Azure NetApp Files oder in einer NFS-Freigabe in Azure Files bereitstellen. Azure Files unterstützt das NFSv4.1-Protokoll. NFS in Azure NetApp Files unterstützt sowohl NFSv4.1 als auch NFSv3.
In den nächsten Abschnitten werden die Schritte zum Bereitstellen von NFS beschrieben – Sie müssen nur eine der Optionen auswählen.
Tipp
Sie haben sich entschieden, /hana/shared in einer NFS-Freigabe in Azure Files oder das NFS-Volume in Azure NetApp Files bereitzustellen.
Bereitstellen der Infrastruktur für Azure NetApp Files
Stellen Sie die Azure NetApp Files Volumes für das Dateisystem /hana/shared bereit. Sie benötigen ein separates /hana/shared Volume für jeden HANA-Systemreplikationsstandort. Weitere Informationen finden Sie unter Einrichten der Infrastruktur für Azure NetApp Files.
In diesem Beispiel verwenden Sie die folgenden Azure NetApp Files Volumes:
- Volume „HN1-shared-s1 (nfs://10.23.1.7/HN1-shared-s1)“
- Volume „HN1-shared-s2 (nfs://10.23.1.7/HN1-shared-s2)“
Bereitstellen von NFS in der Azure Files-Infrastruktur
Stellen Sie Azure Files NFS-Freigaben für das /hana/shared-Dateisystem bereit. Sie benötigen eine separate Azure Files-NFS-Freigabe /hana/shared für jeden Replikationsstandort des HANA-Systems. Weitere Informationen finden Sie unter Erstellen einer NFS-Freigabe.
In diesem Beispiel wurden die folgenden Azure Files-NFS-Freigaben verwendet:
- share hn1-shared-s1 (sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s1)
- share hn1-shared-s2 (sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s2)
Konfiguration und Vorbereitung des Betriebssystems
Die Anweisungen in den nächsten Abschnitten weisen eine der folgenden Abkürzungen auf:
- [A] : Gilt für alle Knoten
- [AH]: gilt für alle HANA DB-Knoten
- [M]: gilt für den Majority Maker-Knoten
- [AH1]: gilt für alle HANA DB-Knoten an STANDORT 1
- [AH2]: gilt für alle HANA DB-Knoten an STANDORT 2
- [1]: gilt nur für HANA DB-Knoten 1, STANDORT 1
- [2]: gilt nur für HANA DB-Knoten 1, STANDORT 2
Konfigurieren Sie Ihr Betriebssystem wie folgt und bereiten Sie es vor:
[A] Verwalten Sie die Hostdateien auf den virtuellen Computern. Schließen Sie Einträge für alle Subnetze ein. Für dieses Beispiel werden die folgenden Einträge zu
/etc/hostshinzugefügt.# Client subnet 10.23.0.11 hana-s1-db1 10.23.0.12 hana-s1-db1 10.23.0.13 hana-s1-db2 10.23.0.14 hana-s2-db1 10.23.0.15 hana-s2-db2 10.23.0.16 hana-s2-db3 10.23.0.17 hana-s-mm # Internode subnet 10.23.1.138 hana-s1-db1-inter 10.23.1.139 hana-s1-db2-inter 10.23.1.140 hana-s1-db3-inter 10.23.1.141 hana-s2-db1-inter 10.23.1.142 hana-s2-db2-inter 10.23.1.143 hana-s2-db3-inter # HSR subnet 10.23.1.202 hana-s1-db1-hsr 10.23.1.203 hana-s1-db2-hsr 10.23.1.204 hana-s1-db3-hsr 10.23.1.205 hana-s2-db1-hsr 10.23.1.206 hana-s2-db2-hsr 10.23.1.207 hana-s2-db3-hsr[A] Erstellen Sie die Konfigurationsdatei /etc/sysctl.d/ms-az.conf mit Microsoft für Azure-Konfigurationseinstellungen.
vi /etc/sysctl.d/ms-az.conf # Add the following entries in the configuration file net.ipv6.conf.all.disable_ipv6 = 1 net.ipv4.tcp_max_syn_backlog = 16348 net.ipv4.conf.all.rp_filter = 0 sunrpc.tcp_slot_table_entries = 128 vm.swappiness=10Tipp
Vermeiden Sie es,
net.ipv4.ip_local_port_rangeundnet.ipv4.ip_local_reserved_portsexplizit in densysctlKonfigurationsdateien zu setzen, damit der SAP-Host-Agent die Portbereiche verwalten kann. Weitere Einzelheiten finden Sie im SAP-Hinweis 2382421.[A] Installieren Sie das NFS-Clientpaket.
yum install nfs-utils[AH] Red Hat für HANA-Konfiguration.
Konfigurieren Sie RHEL, wie im Red Hat Kundenportal und in den folgenden SAP-Hinweisen beschrieben:
- 2292690 – SAP HANA DB: Recommended OS Settings for RHEL 7 (2292690 – SAP HANA DB: Empfohlene Betriebssystemeinstellungen für RHEL 7)
- 2777782 - SAP HANA DB: Empfohlene Betriebssystemeinstellungen für RHEL 8
- 2455582 – Linux: Running SAP applications compiled with GCC 6.x (Linux – Ausführen von mit GCC 6.x kompilierten SAP-Anwendungen)
- 2593824 – Linux: Ausführen von mit GCC 7.x kompilierten SAP-Anwendungen
- 2886607 – Linux: Ausführen von mit GCC 9.x kompilierten SAP-Anwendungen
Vorbereiten der Dateisysteme
Die folgenden Abschnitte enthalten Schritte zur Vorbereitung Ihrer Dateisysteme. Sie haben sich entschieden, „/hana/shared“ in einer NFS-Freigabe in Azure Files oder das NFS-Volume in Azure NetApp Files bereitzustellen.
Einbinden der freigegebenen Dateisysteme (Azure NetApp Files NFS)
In diesem Beispiel werden die freigegebenen HANA-Dateisysteme in Azure NetApp Files bereitgestellt und über NFSv4.1 eingebunden. Führen Sie die Schritte in diesem Abschnitt nur aus, wenn Sie NFS in Azure NetApp Files verwenden.
[A] Vorbereiten des Betriebssystems für die Ausführung von SAP HANA in NetApp Systems mit NFS, wie in SAP-Hinweis 3024346 – Linux-Kerneleinstellungen für NetApp NFS beschrieben. Erstellen Sie die Konfigurationsdatei /etc/sysctl.d/91-NetApp-HANA.conf für die NetApp-Konfigurationseinstellungen.
vi /etc/sysctl.d/91-NetApp-HANA.conf # Add the following entries in the configuration file net.core.rmem_max = 16777216 net.core.wmem_max = 16777216 net.ipv4.tcp_rmem = 4096 131072 16777216 net.ipv4.tcp_wmem = 4096 16384 16777216 net.core.netdev_max_backlog = 300000 net.ipv4.tcp_slow_start_after_idle=0 net.ipv4.tcp_no_metrics_save = 1 net.ipv4.tcp_moderate_rcvbuf = 1 net.ipv4.tcp_window_scaling = 1 net.ipv4.tcp_sack = 1[A] Passen Sie die sunrpc-Einstellungen an, wie im SAP-Hinweis 3024346 – Linux-Kerneleinstellungen für NetApp NFS empfohlen.
vi /etc/modprobe.d/sunrpc.conf # Insert the following line options sunrpc tcp_max_slot_table_entries=128[AH] Erstellen Sie Bereitstellungspunkte für die HANA-Datenbankvolumes.
mkdir -p /hana/shared[AH] Überprüfen Sie die Einstellung für die NFS-Domäne. Stellen Sie sicher, dass die Domäne als Standarddomäne von Azure NetApp Files konfiguriert ist:
defaultv4iddomain.com. Stellen Sie sicher, dass die Zuordnung aufnobodyeingestellt ist.
(Dieser Schritt ist nur erforderlich, wenn Sie Azure NetAppFiles NFS v4.1 verwenden).Wichtig
Stellen Sie sicher, dass die NFS-Domäne in
/etc/idmapd.confauf der VM so festgelegt ist, dass sie mit der Standarddomänenkonfiguration für Azure NetApp Files übereinstimmt:defaultv4iddomain.com. Wenn die Domänenkonfiguration auf dem NFS-Client und dem NFS-Server nicht übereinstimmt, werden die Berechtigungen für Dateien auf Azure NetApp-Volumes, die auf den VMs eingehängt sind, alsnobodyangezeigt.sudo cat /etc/idmapd.conf # Example [General] Domain = defaultv4iddomain.com [Mapping] Nobody-User = nobody Nobody-Group = nobody[AH] Überprüfen Sie
nfs4_disable_idmapping. Diese Angabe sollte aufY(Ja) festgelegt sein. Führen Sie den Einbindungsbefehl aus, um beinfs4_disable_idmappingdie Verzeichnisstruktur zu erstellen. Sie können das Verzeichnis unter /sys/modules nicht manuell erstellen, da der Zugriff für den Kernel oder die Treiber reserviert ist.
Dieser Schritt ist nur erforderlich, wenn Sie Azure NetAppFiles NFSv4.1 verwenden.# Check nfs4_disable_idmapping cat /sys/module/nfs/parameters/nfs4_disable_idmapping # If you need to set nfs4_disable_idmapping to Y mkdir /mnt/tmp mount 10.9.0.4:/HN1-shared /mnt/tmp umount /mnt/tmp echo "Y" > /sys/module/nfs/parameters/nfs4_disable_idmapping # Make the configuration permanent echo "options nfs nfs4_disable_idmapping=Y" >> /etc/modprobe.d/nfs.confWeitere Informationen zur Änderung des
nfs4_disable_idmappingParameters finden Sie im Red Hat Kundenportal.[AH1] Binden Sie die freigegebenen Azure NetApp Files-Volumes auf den virtuellen HANA DB-Computern von STANDORT 1 ein.
sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.23.1.7:/HN1-shared-s1 /hana/shared[AH2] Binden Sie die freigegebenen Azure NetApp Files-Volumes auf den virtuellen HANA DB-Computern von STANDORT 2 ein.
sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.23.1.7:/HN1-shared-s2 /hana/shared[AH] Überprüfen Sie, ob die entsprechenden
/hana/shared/Dateisysteme auf allen HANA DB VMs mit der NFS-Protokollversion NFSv4 eingehängt sind.sudo nfsstat -m # Verify that flag vers is set to 4.1 # Example from SITE 1, hana-s1-db1 /hana/shared from 10.23.1.7:/HN1-shared-s1 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.11,local_lock=none,addr=10.23.1.7 # Example from SITE 2, hana-s2-db1 /hana/shared from 10.23.1.7:/HN1-shared-s2 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.14,local_lock=none,addr=10.23.1.7
Einbinden der freigegebenen Dateisysteme (Azure Files NFS)
In diesem Beispiel werden die freigegebenen HANA-Dateisysteme in NFS in Azure Files bereitgestellt. Führen Sie die Schritte in diesem Abschnitt nur aus, wenn Sie NFS in Azure Files verwenden.
[AH] Erstellen Sie Bereitstellungspunkte für die HANA-Datenbankvolumes.
mkdir -p /hana/shared[AH1] Binden Sie die freigegebenen Azure NetApp Files-Volumes auf den virtuellen HANA DB-Computern von STANDORT 1 ein.
sudo vi /etc/fstab # Add the following entry sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s1 /hana/shared nfs nfsvers=4.1,sec=sys 0 0 # Mount all volumes sudo mount -a[AH2] Binden Sie die freigegebenen Azure NetApp Files-Volumes auf den virtuellen HANA DB-Computern von STANDORT 2 ein.
sudo vi /etc/fstab # Add the following entries sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s2 /hana/shared nfs nfsvers=4.1,sec=sys 0 0 # Mount the volume sudo mount -a[AH] Überprüfen Sie, ob die entsprechenden
/hana/shared/-Dateisysteme auf allen virtuellen HANA DB-Computern mit NFS-Protokollversion NFSv4.1 eingebunden sind.sudo nfsstat -m # Example from SITE 1, hana-s1-db1 sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s1 Flags: rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.19,local_lock=none,addr=10.23.0.35 # Example from SITE 2, hana-s2-db1 sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s2 Flags: rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.22,local_lock=none,addr=10.23.0.35
Vorbereiten der Daten und Protokollieren lokaler Dateisysteme
In der vorgestellten Konfiguration stellen Sie die Dateisysteme /hana/data und /hana/log auf einem verwalteten Datenträger bereit und verbinden diese Dateisysteme lokal mit jeder HANA DB VM. Führen Sie die folgenden Schritte aus, um die lokalen Daten- und Protokollvolumes auf jeder virtuellen HANA DB-Maschine zu erstellen.
Richten Sie das Layout des Datenträgers mit Logical Volume Manager (LVM) ein. Im folgenden Beispiel wird davon ausgegangen, dass an jede virtuelle HANA-Maschine drei Datenträger angeschlossen sind und dass diese Datenträger zur Erstellung von zwei Volumes verwendet werden.
[AH] Auflisten aller verfügbaren Datenträger:
ls /dev/disk/azure/scsi1/lun*Beispielausgabe:
/dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 /dev/disk/azure/scsi1/lun2[AH] Erstellen Sie physische Volumes für alle Datenträger, die Sie verwenden möchten:
sudo pvcreate /dev/disk/azure/scsi1/lun0 sudo pvcreate /dev/disk/azure/scsi1/lun1 sudo pvcreate /dev/disk/azure/scsi1/lun2[AH] Erstellen Sie eine Volumegruppe für die Datendateien. Erstellen Sie eine Volumegruppe für Protokolldateien und eine für das freigegebene Verzeichnis von SAP HANA:
sudo vgcreate vg_hana_data_HN1 /dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 sudo vgcreate vg_hana_log_HN1 /dev/disk/azure/scsi1/lun2[AH] Erstellen Sie die logischen Volumes. Ein lineares Volumen wird erstellt, wenn Sie
lvcreateohne den-iSchalter verwenden. Für eine bessere E/A-Leistung wird empfohlen, ein Striped-Volume zu erstellen. Passen Sie die Stripe-Größen an die in SAP HANA VM-Speicherkonfigurationen dokumentierten Werte an. Das-i-Argument sollte die Anzahl der zugrunde liegenden physischen Volumes und das-I-Argument die Stripegröße sein. In diesem Artikel werden zwei physische Volumes für das Data-Volume verwendet, daher wird das Schalterargument-iauf2gesetzt. Die Stripe-Größe für das Datenvolumen ist256 KiB. Für das Log-Volume wird ein physisches Volume verwendet, so dass Sie keine expliziten-i- oder-I-Schalter für die Log-Volume-Befehle verwenden müssen.Wichtig
Verwenden Sie den Schalter
-iund setzen Sie ihn auf die Nummer des zugrunde liegenden physischen Volumes, wenn Sie mehr als ein physisches Volume für jedes Daten- oder Log-Volume verwenden. Verwenden Sie den Schalter-I, um die Stripe-Größe anzugeben, wenn Sie ein Striping-Volume erstellen. Informationen zu empfohlenen Speicherkonfigurationen, einschließlich Stripegrößen und Anzahl der Datenträger, finden Sie unter SAP HANA VM-Speicherkonfigurationen.sudo lvcreate -i 2 -I 256 -l 100%FREE -n hana_data vg_hana_data_HN1 sudo lvcreate -l 100%FREE -n hana_log vg_hana_log_HN1 sudo mkfs.xfs /dev/vg_hana_data_HN1/hana_data sudo mkfs.xfs /dev/vg_hana_log_HN1/hana_log[AH] Erstellen Sie die Bereitstellungsverzeichnisse, und kopieren Sie die UUID aller logischen Volumes:
sudo mkdir -p /hana/data/HN1 sudo mkdir -p /hana/log/HN1 # Write down the ID of /dev/vg_hana_data_HN1/hana_data and /dev/vg_hana_log_HN1/hana_log sudo blkid[AH] Erstellen Sie
fstab-Einträge für die logischen Volumes, und binden Sie Folgendes an:sudo vi /etc/fstabFügen Sie die folgende Zeile in die Datei
/etc/fstabein:/dev/disk/by-uuid/UUID of /dev/mapper/vg_hana_data_HN1-hana_data /hana/data/HN1 xfs defaults,nofail 0 2 /dev/disk/by-uuid/UUID of /dev/mapper/vg_hana_log_HN1-hana_log /hana/log/HN1 xfs defaults,nofail 0 2Stellen Sie die neuen Volumes bereit:
sudo mount -a
Installation
In diesem Beispiel für die Bereitstellung von SAP HANA in einer horizontale Skalierung-Konfiguration mit HSR auf Azure-VMs verwenden Sie HANA 2.0 SP4.
Vorbereiten der HANA-Installation
[AH] Legen Sie vor der HANA-Installation das Stammkennwort fest. Nachdem die Installation abgeschlossen wurde, können Sie das Stammkennwort deaktivieren. Führen Sie als
rootden Befehlpasswdaus, um das Passwort festzulegen.[1,2] Ändern Sie die Berechtigungen für
/hana/shared.chmod 775 /hana/shared[1] Überprüfen Sie, ob Sie sich über eine sichere Shell (SSH) bei hana-s1-db2 und hana-s1-db3 anmelden können, ohne nach einem Passwort gefragt zu werden. Wenn das nicht der Fall ist, tauschen Sie
sshSchlüssel aus, wie in Verwendung der schlüsselbasierten Authentifizierung dokumentiert.ssh root@hana-s1-db2 ssh root@hana-s1-db3[2] Überprüfen Sie, ob Sie sich bei hana-s2-db2 und hana-s2-db3 über SSH anmelden können, ohne zur Eingabe eines Passworts aufgefordert zu werden. Wenn das nicht der Fall ist, tauschen Sie
sshSchlüssel aus, wie in Verwendung der schlüsselbasierten Authentifizierung dokumentiert.ssh root@hana-s2-db2 ssh root@hana-s2-db3[AH] Installieren Sie zusätzliche Pakete, die für HANA 2.0 SP4 erforderlich sind. Weitere Informationen finden Sie im SAP-Hinweis 2593824 für RHEL 7.
# If using RHEL 7 yum install libgcc_s1 libstdc++6 compat-sap-c++-7 libatomic1 # If using RHEL 8 yum install libatomic libtool-ltdl.x86_64[A] Deaktivieren Sie die Firewall vorübergehend, damit sie die HANA-Installation nicht stört. Sie können sie nach der HANA-Installation wieder aktivieren.
# Execute as root systemctl stop firewalld systemctl disable firewalld
HANA-Installation auf dem ersten Knoten an jedem Standort
[1] Installieren Sie SAP HANA, indem Sie den Anweisungen im SAP HANA 2.0 Installations- und Update-Leitfaden folgen. Die folgenden Anweisungen zeigen die SAP HANA-Installation auf dem ersten Knoten auf SITE 1.
Starten Sie das Programm
hdblcmalsrootaus dem Verzeichnis der HANA-Installationssoftware. Verwenden Sie den Parameterinternal_networkund übergeben Sie den Adressraum für das Subnetz, der für die interne HANA-Internode-Kommunikation verwendet wird../hdblcm --internal_network=10.23.1.128/26Geben Sie an der Eingabeaufforderung folgende Werte ein:
- Für Wählen Sie eine Aktion, geben Sie 1 (für installieren).
- Für Zusätzliche Komponenten für die Installation, geben Sie 2, 3 ein.
- Drücken Sie für den Installationspfad die Eingabetaste (die Standardeinstellung ist /hana/shared).
- Drücken Sie für Lokaler Hostname die Eingabetaste, um die Standardeinstellung zu übernehmen.
- Für Möchten Sie dem System Hosts hinzufügen? , geben Sie n ein.
- Für SAP HANA System ID, geben Sie HN1 ein.
- Für Instanznummer [00], geben Sie 03 ein.
- Für Lokale Host-Arbeitergruppe [Standard] drücken Sie die Eingabetaste, um den Standard zu übernehmen.
- Für Systemnutzung wählen / Index [4] eingeben, 4 (für benutzerdefiniert).
- Für Speicherort der Datenvolumes [/hana/data/HN1] drücken Sie die Eingabetaste, um die Vorgabe zu übernehmen.
- Für Location of Log Volumes [/hana/log/HN1] drücken Sie die Eingabetaste, um die Vorgabe zu übernehmen.
- Für Möchten Sie die maximale Speicherbelegung beschränken? [n]: Geben Sie n ein.
- Für Zertifikat Hostname Für Host hana-s1-db1 [hana-s1-db1], drücken Sie die Eingabetaste, um die Vorgabe zu übernehmen.
- Geben Sie für SAP Host Agent User (sapadm) Passwort das Passwort ein.
- Geben Sie für Bestätigen Sie das SAP Host Agent User (sapadm) Passwort das Passwort ein.
- Geben Sie für Systemadministrator (hn1adm) Passwort das Passwort ein.
- Für Systemadministrator-Home-Verzeichnis [/usr/sap/HN1/home] drücken Sie die Eingabetaste, um die Vorgabe zu übernehmen.
- Für Systemadministrator-Anmeldeshell [/bin/sh] drücken Sie die Eingabetaste, um die Vorgabe zu übernehmen.
- Für Systemadministrator-Benutzer-ID [1001], drücken Sie die Eingabetaste, um die Vorgabe zu übernehmen.
- Für Eingabe ID der Benutzergruppe (sapsys) [79], drücken Sie die Eingabetaste, um die Vorgabe zu übernehmen.
- Geben Sie für Systemdatenbank-Benutzer (System) Passwort das Passwort des Systems ein.
- Geben Sie für Bestätigen Sie das Passwort des Systemdatenbankbenutzers (System) das Passwort des Systems ein.
- Für Soll das System nach dem Neustart des Computers neu starten? [n]: Geben Sie n ein.
- Für Möchten Sie fortfahren (j/n) , bestätigen Sie die Zusammenfassung und wenn alles gut aussieht, geben Sie j ein.
[2] Wiederholen Sie den vorhergehenden Schritt, um SAP HANA auf dem ersten Knoten an STANDORT 2 zu installieren.
[1,2] Überprüfen Sie global.ini.
Zeigen Sie global.ini an und stellen Sie sicher, dass die Konfiguration für die interne SAP HANA-Internode-Kommunikation vorhanden ist. Überprüfen Sie den Abschnitt
communication. Dieser sollte den Adressraum für dasinter-Subnetz enthalten, undlisteninterfacesollte auf.internalfestgelegt sein. Überprüfen Sie den Abschnittinternal_hostname_resolution. Er sollte die IP-Adressen für die virtuellen HANA-Computer enthalten, die zuminter-Subnetz gehören.sudo cat /usr/sap/HN1/SYS/global/hdb/custom/config/global.ini # Example from SITE1 [communication] internal_network = 10.23.1.128/26 listeninterface = .internal [internal_hostname_resolution] 10.23.1.138 = hana-s1-db1 10.23.1.139 = hana-s1-db2 10.23.1.140 = hana-s1-db3[1,2] Bereiten Sie global.ini für die Installation in einer nicht gemeinsam genutzten Umgebung vor, wie in SAP-Hinweis 2080991 beschrieben.
sudo vi /usr/sap/HN1/SYS/global/hdb/custom/config/global.ini [persistence] basepath_shared = no[1,2] Starten Sie SAP HANA neu, um die Änderungen zu aktivieren.
sudo -u hn1adm /usr/sap/hostctrl/exe/sapcontrol -nr 03 -function StopSystem sudo -u hn1adm /usr/sap/hostctrl/exe/sapcontrol -nr 03 -function StartSystem[1,2] Vergewissern Sie sich, dass die Client-Schnittstelle die IP-Adressen aus dem Subnetz
clientfür die Kommunikation verwendet.# Execute as hn1adm /usr/sap/HN1/HDB03/exe/hdbsql -u SYSTEM -p "password" -i 03 -d SYSTEMDB 'select * from SYS.M_HOST_INFORMATION'|grep net_publicname # Expected result - example from SITE 2 "hana-s2-db1","net_publicname","10.23.0.14"Informationen zur Verifizierung der Konfiguration finden Sie im SAP-Hinweis 2183363 - Konfiguration des internen SAP HANA-Netzwerks.
[AH] Ändern Sie die Berechtigungen für die Daten- und Protokollverzeichnisse, um einen HANA-Installationsfehler zu vermeiden.
sudo chmod o+w -R /hana/data /hana/log[1] Installieren Sie die sekundären HANA-Knoten. Die Beispielanweisungen in diesem Schritt beziehen sich auf STANDORT 1.
Starten Sie das residente Programm
hdblcmalsroot.cd /hana/shared/HN1/hdblcm ./hdblcmGeben Sie an der Eingabeaufforderung folgende Werte ein:
- Für Wählen Sie eine Aktion, geben Sie 2 (für Hosts hinzufügen).
- Für Geben Sie durch Komma getrennte Hostnamen ein, die Sie hinzufügen möchten, geben Sie hana-s1-db2, hana-s1-db3 ein.
- Für Zusätzliche Komponenten für die Installation, geben Sie 2, 3 ein.
- Geben Sie für den Root-Benutzernamen [root] ein und drücken Sie die Eingabetaste, um die Standardeinstellung zu übernehmen.
- Für Wählen Sie Rollen für den Host 'hana-s1-db2' [1] , wählen Sie 1 (für Arbeiter).
- Für Geben Sie die Host-Ausfallsicherungsgruppe für den Host 'hana-s1-db2' [Standard] ein, drücken Sie die Eingabetaste, um den Standard zu akzeptieren.
- Für Geben Sie die Nummer der Speicherpartition für den Host „hana-s1-db2“ [<<automatisch zuweisen>>] ein: Drücken Sie die EINGABETASTE, um die Standardeinstellung zu übernehmen.
- Geben Sie für Arbeitergruppe für Host 'hana-s1-db2' [Standard] ein und drücken Sie die Eingabetaste, um den Standard zu akzeptieren.
- Für Wählen Sie Rollen für den Host 'hana-s1-db3' [1] , wählen Sie 1 (für Arbeiter).
- Für Geben Sie die Host-Failover-Gruppe für den Host 'hana-s1-db3' [Standard] ein und drücken Sie die Eingabetaste, um den Standard zu akzeptieren.
- Für Geben Sie die Nummer der Speicherpartition für den Host „hana-s1-db3“ [<<automatisch zuweisen>>] ein: Drücken Sie die EINGABETASTE, um die Standardeinstellung zu übernehmen.
- Geben Sie für Arbeitergruppe für Host 'hana-s1-db3' [Standard] ein und drücken Sie die Eingabetaste, um den Standard zu akzeptieren.
- Geben Sie für Systemadministrator (hn1adm) Passwort das Passwort ein.
- Geben Sie für Enter SAP Host Agent User (sapadm) Passwort das Passwort ein.
- Geben Sie für Bestätigen Sie das SAP Host Agent User (sapadm) Passwort das Passwort ein.
- Für Zertifikat Hostname Für Host hana-s1-db2 [hana-s1-db2], drücken Sie die Eingabetaste, um die Vorgabe zu übernehmen.
- Für Zertifikat Hostname Für Host hana-s1-db3 [hana-s1-db3], drücken Sie die Eingabetaste, um die Vorgabe zu übernehmen.
- Für Möchten Sie fortfahren (j/n) , bestätigen Sie die Zusammenfassung und wenn alles gut aussieht, geben Sie j ein.
[2] Wiederholen Sie den vorhergehenden Schritt, um die sekundären SAP HANA-Knoten auf STANDORT 2 zu installieren.
Konfigurieren Sie die SAP HANA 2.0 Systemreplikation
Mit den folgenden Schritten können Sie die Systemreplikation einrichten:
[1] Konfigurieren Sie die Systemreplikation auf SITE 1:
Sichern Sie die Datenbanken als hn1adm:
hdbsql -d SYSTEMDB -u SYSTEM -p "passwd" -i 03 "BACKUP DATA USING FILE ('initialbackupSYS')" hdbsql -d HN1 -u SYSTEM -p "passwd" -i 03 "BACKUP DATA USING FILE ('initialbackupHN1')"Kopieren Sie die PKI-Systemdateien auf den sekundären Standort:
scp /usr/sap/HN1/SYS/global/security/rsecssfs/data/SSFS_HN1.DAT hana-s2-db1:/usr/sap/HN1/SYS/global/security/rsecssfs/data/ scp /usr/sap/HN1/SYS/global/security/rsecssfs/key/SSFS_HN1.KEY hana-s2-db1:/usr/sap/HN1/SYS/global/security/rsecssfs/key/Erstellen Sie den primären Standort:
hdbnsutil -sr_enable --name=HANA_S1[2] Konfigurieren Sie die Systemreplikation auf SITE 2:
Registrieren Sie den zweiten Standort zum Starten der Replikation. Führen Sie den folgenden Befehl als „<hanasid>adm“ aus:
sapcontrol -nr 03 -function StopWait 600 10 hdbnsutil -sr_register --remoteHost=hana-s1-db1 --remoteInstance=03 --replicationMode=sync --name=HANA_S2 sapcontrol -nr 03 -function StartSystem[1] Überprüfen Sie den Replikationsstatus und warten Sie, bis alle Datenbanken synchronisiert sind.
sudo su - hn1adm -c "python /usr/sap/HN1/HDB03/exe/python_support/systemReplicationStatus.py" # | Database | Host | Port | Service Name | Volume ID | Site ID | Site Name | Secondary | Secondary | Secondary | Secondary | Secondary | Replication | Replication | Replication | # | | | | | | | | Host | Port | Site ID | Site Name | Active Status | Mode | Status | Status Details | # | -------- | ------------- | ----- | ------------ | --------- | ------- | --------- | ------------- | --------- | --------- | --------- | ------------- | ----------- | ----------- | -------------- | # | HN1 | hana-s1-db3 | 30303 | indexserver | 5 | 1 | HANA_S1 | hana-s2-db3 | 30303 | 2 | HANA_S2 | YES | SYNC | ACTIVE | | # | SYSTEMDB | hana-s1-db1 | 30301 | nameserver | 1 | 1 | HANA_S1 | hana-s2-db1 | 30301 | 2 | HANA_S2 | YES | SYNC | ACTIVE | | # | HN1 | hana-s1-db1 | 30307 | xsengine | 2 | 1 | HANA_S1 | hana-s2-db1 | 30307 | 2 | HANA_S2 | YES | SYNC | ACTIVE | | # | HN1 | hana-s1-db1 | 30303 | indexserver | 3 | 1 | HANA_S1 | hana-s2-db1 | 30303 | 2 | HANA_S2 | YES | SYNC | ACTIVE | | # | HN1 | hana-s1-db2 | 30303 | indexserver | 4 | 1 | HANA_S1 | hana-s2-db2 | 30303 | 2 | HANA_S2 | YES | SYNC | ACTIVE | | # # status system replication site "2": ACTIVE # overall system replication status: ACTIVE # # Local System Replication State # # mode: PRIMARY # site id: 1 # site name: HANA_S1[1,2] Ändern Sie die HANA-Konfiguration so, dass die Kommunikation für die HANA-Systemreplikation über die virtuellen Netzwerkschnittstellen der HANA-Systemreplikation geleitet wird.
Stoppen Sie HANA an beiden Standorten.
sudo -u hn1adm /usr/sap/hostctrl/exe/sapcontrol -nr 03 -function StopSystem HDBBearbeiten Sie global.ini, um die Hostzuordnung für die HANA-Systemreplikation hinzuzufügen. Verwenden Sie die IP-Adressen aus dem Subnetz
hsr.sudo vi /usr/sap/HN1/SYS/global/hdb/custom/config/global.ini #Add the section [system_replication_hostname_resolution] 10.23.1.202 = hana-s1-db1 10.23.1.203 = hana-s1-db2 10.23.1.204 = hana-s1-db3 10.23.1.205 = hana-s2-db1 10.23.1.206 = hana-s2-db2 10.23.1.207 = hana-s2-db3Starten Sie HANA an beiden Standorten.
sudo -u hn1adm /usr/sap/hostctrl/exe/sapcontrol -nr 03 -function StartSystem HDB
Weitere Informationen finden Sie unter Hostnamenauflösung für Systemreplikation.
[AH] Aktivieren Sie die Firewall wieder und öffnen Sie die erforderlichen Ports.
Aktivieren Sie die Firewall wieder.
# Execute as root systemctl start firewalld systemctl enable firewalldÖffnen Sie die erforderlichen Firewallports. Sie müssen die Ports für Ihre HANA-Instanznummer anpassen.
Wichtig
Erstellen Sie Firewall-Regeln, um die HANA-Internode-Kommunikation und den Client-Datenverkehr zuzulassen. Die erforderlichen Ports sind auf TCP/IP-Ports aller SAP-Produkte aufgeführt. Die folgenden Befehle dienen lediglich als Beispiel. In diesem Szenario verwenden Sie die Systemnummer 03.
# Execute as root sudo firewall-cmd --zone=public --add-port={30301,30303,30306,30307,30313,30315,30317,30340,30341,30342,1128,1129,40302,40301,40307,40303,40340,50313,50314,30310,30302}/tcp --permanent sudo firewall-cmd --zone=public --add-port={30301,30303,30306,30307,30313,30315,30317,30340,30341,30342,1128,1129,40302,40301,40307,40303,40340,50313,50314,30310,30302}/tcp
Erstellen eines Pacemaker-Clusters
Um einen einfachen Pacemaker-Cluster zu erstellen, befolgen Sie die Schritte in Einrichten von Pacemaker unter Red Hat Enterprise Linux in Azure. Beziehen Sie alle virtuellen Computer ein, einschließlich Majority Maker im Cluster.
Wichtig
Setzen Sie quorum expected-votes nicht auf 2. Dies ist kein Zwei-Knoten-Cluster. Vergewissern Sie sich, dass die Clustereigenschaft concurrent-fencing aktiviert ist, damit das Knotenfencing deserialisiert wird.
Erstellen von Dateisystemressourcen
Für den nächsten Teil dieses Prozesses müssen Sie Dateisystemressourcen erstellen. Gehen Sie dazu wie folgt vor:
[1,2] Beenden Sie SAP HANA an beiden Replikationsstandorten. Starten Sie die Ausführung als „<sid>adm“.
sapcontrol -nr 03 -function StopSystem[AH] Trennen Sie das Dateisystem
/hana/shared, das für die Installation auf allen HANA DB VMs vorübergehend eingehängt wurde. Bevor Sie es aushängen können, müssen Sie alle Prozesse und Sitzungen stoppen, die das Dateisystem verwenden.umount /hana/shared[1] Erstellen Sie die Dateisystem-Cluster-Ressourcen für
/hana/sharedim deaktivierten Zustand. Sie verwenden--disabled, weil Sie die Ortsbeschränkungen definieren müssen, bevor die Montierungen aktiviert werden.
Sie haben sich entschieden, „/hana/shared“ in einer NFS-Freigabe in Azure Files oder das NFS-Volume in Azure NetApp Files bereitzustellen.In diesem Beispiel werden die Dateisysteme für „/hana/shared“ in Azure NetApp Files bereitgestellt und über NFSv4.1 eingebunden. Führen Sie die Schritte in diesem Abschnitt nur aus, wenn Sie NFS in Azure NetApp Files verwenden.
# /hana/shared file system for site 1 pcs resource create fs_hana_shared_s1 --disabled ocf:heartbeat:Filesystem device=10.23.1.7:/HN1-shared-s1 directory=/hana/shared \ fstype=nfs options='defaults,rw,hard,timeo=600,rsize=262144,wsize=262144,proto=tcp,noatime,sec=sys,nfsvers=4.1,lock,_netdev' op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 \ op start interval=0 timeout=120 op stop interval=0 timeout=120 # /hana/shared file system for site 2 pcs resource create fs_hana_shared_s2 --disabled ocf:heartbeat:Filesystem device=10.23.1.7:/HN1-shared-s1 directory=/hana/shared \ fstype=nfs options='defaults,rw,hard,timeo=600,rsize=262144,wsize=262144,proto=tcp,noatime,sec=sys,nfsvers=4.1,lock,_netdev' op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 \ op start interval=0 timeout=120 op stop interval=0 timeout=120 # clone the /hana/shared file system resources for both site1 and site2 pcs resource clone fs_hana_shared_s1 meta clone-node-max=1 interleave=true pcs resource clone fs_hana_shared_s2 meta clone-node-max=1 interleave=true
Die vorgeschlagenen Timeoutwerte ermöglichen den Clusterressourcen, eine protokollspezifische Pause im Zusammenhang mit NFSv4.1-Leaseverlängerungen in Azure NetApp Files zu überstehen. Weitere Informationen finden Sie unter Bewährte Methode für NFS in NetApp.
In diesem Beispiel wird das Dateisystem „/hana/shared“ über NFS in Azure Files bereitgestellt. Führen Sie die Schritte in diesem Abschnitt nur aus, wenn Sie NFS in Azure Files verwenden.
# /hana/shared file system for site 1 pcs resource create fs_hana_shared_s1 --disabled ocf:heartbeat:Filesystem device=sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s1 directory=/hana/shared \ fstype=nfs options='defaults,rw,hard,proto=tcp,noatime,nfsvers=4.1,lock' op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 \ op start interval=0 timeout=120 op stop interval=0 timeout=120 # /hana/shared file system for site 2 pcs resource create fs_hana_shared_s2 --disabled ocf:heartbeat:Filesystem device=sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s2 directory=/hana/shared \ fstype=nfs options='defaults,rw,hard,proto=tcp,noatime,nfsvers=4.1,lock' op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 \ op start interval=0 timeout=120 op stop interval=0 timeout=120 # clone the /hana/shared file system resources for both site1 and site2 pcs resource clone fs_hana_shared_s1 meta clone-node-max=1 interleave=true pcs resource clone fs_hana_shared_s2 meta clone-node-max=1 interleave=trueDas Attribut
OCF_CHECK_LEVEL=20wird der Überwachungsoperation hinzugefügt, so dass die Überwachungsoperationen einen Lese-/Schreibtest des Dateisystems durchführen. Ohne dieses Attribut überprüft der Überwachungsvorgang nur, ob das Dateisystem eingebunden ist. Dies kann ein Problem darstellen, denn wenn die Verbindung unterbrochen wird, kann das Dateisystem eingehängt bleiben, obwohl es nicht zugänglich ist.Das Attribut
on-fail=fencewird auch dem Überwachungsvorgang hinzugefügt. Durch diese Option wird ein Knoten sofort eingegrenzt, wenn beim Überwachungsvorgang für diesen Knoten ein Fehler auftritt. Ohne diese Option werden standardmäßig alle von der ausgefallenen Ressource abhängigen Ressourcen gestoppt, dann die ausgefallene Ressource neu gestartet und anschließend alle von der ausgefallenen Ressource abhängigen Ressourcen gestartet. Dieses Verhalten kann nicht nur sehr lange dauern, wenn eine SAP HANA-Ressource von der ausgefallenen Ressource abhängt, sondern es kann auch ganz ausfallen. Die SAP HANA-Ressource kann nicht erfolgreich gestoppt werden, wenn die NFS-Freigabe mit den HANA-Binärdateien unzugänglich ist.Die Timeouts in den oben beschriebenen Konfigurationen müssen möglicherweise an das spezifische SAP-Setup angepasst werden.
[1] Konfigurieren und überprüfen Sie die Knotenattribute. Allen SAP HANA DB-Knoten am Replikationsstandort 1 wird das Attribut
S1zugewiesen, und allen SAP HANA DB-Knoten am Replikationsstandort 2 wird das AttributS2zugewiesen.# HANA replication site 1 pcs node attribute hana-s1-db1 NFS_SID_SITE=S1 pcs node attribute hana-s1-db2 NFS_SID_SITE=S1 pcs node attribute hana-s1-db3 NFS_SID_SITE=S1 # HANA replication site 2 pcs node attribute hana-s2-db1 NFS_SID_SITE=S2 pcs node attribute hana-s2-db2 NFS_SID_SITE=S2 pcs node attribute hana-s2-db3 NFS_SID_SITE=S2 # To verify the attribute assignment to nodes execute pcs node attribute[1] Konfigurieren Sie die Beschränkungen, die bestimmen, wo die NFS-Dateisysteme eingehängt werden, und aktivieren Sie die Dateisystemressourcen.
# Configure the constraints pcs constraint location fs_hana_shared_s1-clone rule resource-discovery=never score=-INFINITY NFS_SID_SITE ne S1 pcs constraint location fs_hana_shared_s2-clone rule resource-discovery=never score=-INFINITY NFS_SID_SITE ne S2 # Enable the file system resources pcs resource enable fs_hana_shared_s1 pcs resource enable fs_hana_shared_s2Wenn Sie die Dateisystemressourcen aktivieren, wird der Cluster die
/hana/shared-Dateisysteme einbinden.[AH] Stellen Sie sicher, dass die Azure NetApp Files Volumes unter
/hana/sharedauf allen HANA DB VMs an beiden Standorten eingehängt sind.Beispiel bei Verwendung von Azure NetApp Files:
sudo nfsstat -m # Verify that flag vers is set to 4.1 # Example from SITE 1, hana-s1-db1 /hana/shared from 10.23.1.7:/HN1-shared-s1 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.11,local_lock=none,addr=10.23.1.7 # Example from SITE 2, hana-s2-db1 /hana/shared from 10.23.1.7:/HN1-shared-s2 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.14,local_lock=none,addr=10.23.1.7Beispiel bei Verwendung von Azure Files-NFS:
sudo nfsstat -m # Example from SITE 1, hana-s1-db1 sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s1 Flags: rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.19,local_lock=none,addr=10.23.0.35 # Example from SITE 2, hana-s2-db1 sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s2 Flags: rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.22,local_lock=none,addr=10.23.0.35
[1] Konfigurieren und klonen Sie die Attribut-Ressourcen und konfigurieren Sie die Constraints wie folgt:
# Configure the attribute resources pcs resource create hana_nfs_s1_active ocf:pacemaker:attribute active_value=true inactive_value=false name=hana_nfs_s1_active pcs resource create hana_nfs_s2_active ocf:pacemaker:attribute active_value=true inactive_value=false name=hana_nfs_s2_active # Clone the attribute resources pcs resource clone hana_nfs_s1_active meta clone-node-max=1 interleave=true pcs resource clone hana_nfs_s2_active meta clone-node-max=1 interleave=true # Configure the constraints, which will set the attribute values pcs constraint order fs_hana_shared_s1-clone then hana_nfs_s1_active-clone pcs constraint order fs_hana_shared_s2-clone then hana_nfs_s2_active-cloneTipp
Wenn Ihre Konfiguration andere Dateisysteme als /
hana/sharedenthält und diese Dateisysteme per NFS eingebunden sind, fügen Sie die Optionsequential=falsehinzu. Diese Option stellt sicher, dass es keine Ordnungsabhängigkeiten zwischen den Dateisystemen gibt. Alle per NFS eingehängten Dateisysteme müssen vor der entsprechenden Attributressource beginnen, aber sie müssen nicht in einer bestimmten Reihenfolge relativ zueinander beginnen. Weitere Informationen finden Sie unter Wie konfiguriere ich SAP HANA horizontale Skalierung HSR in einem Pacemaker-Cluster, wenn die HANA-Dateisysteme NFS-Freigaben sind.[1] Versetzen Sie Pacemaker in den Wartungsmodus, um die Erstellung der HANA-Cluster-Ressourcen vorzubereiten.
pcs property set maintenance-mode=true
Erstellen von SAP HANA-Clusterressourcen
Jetzt können Sie die Cluster-Ressourcen erstellen:
[A] Installieren Sie den HANA-Ressourcen-Agent für die horizontale Skalierung auf allen Clusterknoten, einschließlich Majority Maker.
yum install -y resource-agents-sap-hana-scaleoutHinweis
Die minimal unterstützte Version des Pakets
resource-agents-sap-hana-scaleoutfür Ihre Betriebssystemversion finden Sie unter Support-Richtlinien für RHEL Hochverfügbarkeit-Cluster - Verwaltung von SAP HANA in einem Cluster .[1,2] Installieren Sie den HANA-Systemreplikations-Hook auf einem HANA-DB-Knoten an jedem Systemreplikationsstandort. SAP HANA sollte immer noch nicht verfügbar sein.
Bereiten Sie den Hook als
rootvor.mkdir -p /hana/shared/myHooks cp /usr/share/SAPHanaSR-ScaleOut/SAPHanaSR.py /hana/shared/myHooks chown -R hn1adm:sapsys /hana/shared/myHooksEinstellen
global.ini.# add to global.ini [ha_dr_provider_SAPHanaSR] provider = SAPHanaSR path = /hana/shared/myHooks execution_order = 1 [trace] ha_dr_saphanasr = info
[AH] Der Cluster erfordert eine sudoers-Konfiguration auf dem Clusterknoten für <sid>adm. In diesem Beispiel erreichen Sie dies, indem Sie eine neue Datei anlegen. Führen Sie die Befehle als
rootaus.sudo visudo -f /etc/sudoers.d/20-saphana # Insert the following lines and then save Cmnd_Alias SOK = /usr/sbin/crm_attribute -n hana_hn1_glob_srHook -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL = /usr/sbin/crm_attribute -n hana_hn1_glob_srHook -v SFAIL -t crm_config -s SAPHanaSR hn1adm ALL=(ALL) NOPASSWD: SOK, SFAIL Defaults!SOK, SFAIL !requiretty[1,2] Starten Sie SAP HANA an beiden Replikationsstandorten. Starten Sie die Ausführung als „<sid>adm“.
sapcontrol -nr 03 -function StartSystem[1] Überprüfen Sie die Installation des Hooks. Starten Sie die Ausführung als „<sid>adm“ am aktiven HANA-Systemreplikationsstandort.
cdtrace awk '/ha_dr_SAPHanaSR.*crm_attribute/ \ { printf "%s %s %s %s\n",$2,$3,$5,$16 }' nameserver_* # Example entries # 2020-07-21 22:04:32.364379 ha_dr_SAPHanaSR SFAIL # 2020-07-21 22:04:46.905661 ha_dr_SAPHanaSR SFAIL # 2020-07-21 22:04:52.092016 ha_dr_SAPHanaSR SFAIL # 2020-07-21 22:04:52.782774 ha_dr_SAPHanaSR SFAIL # 2020-07-21 22:04:53.117492 ha_dr_SAPHanaSR SFAIL # 2020-07-21 22:06:35.599324 ha_dr_SAPHanaSR SOK[1] Erstellen Sie die HANA-Clusterressourcen. Führen Sie die folgenden Befehle als
rootaus.Stellen Sie sicher, dass sich der Cluster bereits im Wartungsmodus befindet.
Als nächstes erstellen Sie die HANA-Topologieressource.
Wenn Sie einen RHEL 7.x-Cluster erstellen, verwenden Sie die folgenden Befehle:pcs resource create SAPHanaTopology_HN1_HDB03 SAPHanaTopologyScaleOut \ SID=HN1 InstanceNumber=03 \ op start timeout=600 op stop timeout=300 op monitor interval=10 timeout=600 pcs resource clone SAPHanaTopology_HN1_HDB03 meta clone-node-max=1 interleave=trueWenn Sie einen Cluster mit RHEL >= 8.x erstellen, verwenden Sie die folgenden Befehle:
pcs resource create SAPHanaTopology_HN1_HDB03 SAPHanaTopology \ SID=HN1 InstanceNumber=03 meta clone-node-max=1 interleave=true \ op methods interval=0s timeout=5 \ op start timeout=600 op stop timeout=300 op monitor interval=10 timeout=600 pcs resource clone SAPHanaTopology_HN1_HDB03 meta clone-node-max=1 interleave=trueErstellen Sie die HANA-Instanzressource.
Hinweis
In diesem Artikel wird ein Begriff verwendet, der von Microsoft nicht mehr genutzt wird. Sobald der Begriff aus der Software entfernt wird, wird er auch aus diesem Artikel entfernt.
Wenn Sie einen RHEL 7.x-Cluster erstellen, verwenden Sie die folgenden Befehle:
pcs resource create SAPHana_HN1_HDB03 SAPHanaController \ SID=HN1 InstanceNumber=03 PREFER_SITE_TAKEOVER=true DUPLICATE_PRIMARY_TIMEOUT=7200 AUTOMATED_REGISTER=false \ op start interval=0 timeout=3600 op stop interval=0 timeout=3600 op promote interval=0 timeout=3600 \ op monitor interval=60 role="Master" timeout=700 op monitor interval=61 role="Slave" timeout=700 pcs resource master msl_SAPHana_HN1_HDB03 SAPHana_HN1_HDB03 \ meta master-max="1" clone-node-max=1 interleave=trueWenn Sie einen Cluster mit RHEL >= 8.x erstellen, verwenden Sie die folgenden Befehle:
pcs resource create SAPHana_HN1_HDB03 SAPHanaController \ SID=HN1 InstanceNumber=03 PREFER_SITE_TAKEOVER=true DUPLICATE_PRIMARY_TIMEOUT=7200 AUTOMATED_REGISTER=false \ op demote interval=0s timeout=320 op methods interval=0s timeout=5 \ op start interval=0 timeout=3600 op stop interval=0 timeout=3600 op promote interval=0 timeout=3600 \ op monitor interval=60 role="Master" timeout=700 op monitor interval=61 role="Slave" timeout=700 pcs resource promotable SAPHana_HN1_HDB03 \ meta master-max="1" clone-node-max=1 interleave=trueWichtig
Es ist eine gute Idee,
AUTOMATED_REGISTERauffalsezu setzen, während Sie Failover-Tests durchführen, um zu verhindern, dass sich eine ausgefallene primäre Instanz automatisch als sekundäre registriert. Setzen Sie nach dem Test am bestenAUTOMATED_REGISTERauftrue, damit die Systemreplikation nach der Übernahme automatisch fortgesetzt werden kann.Erstellen Sie die virtuelle IP und die zugehörigen Ressourcen.
pcs resource create vip_HN1_03 ocf:heartbeat:IPaddr2 ip=10.23.0.18 op monitor interval="10s" timeout="20s" sudo pcs resource create nc_HN1_03 azure-lb port=62503 sudo pcs resource group add g_ip_HN1_03 nc_HN1_03 vip_HN1_03Erstellen Sie die Cluster-Constraints.
Wenn Sie einen RHEL 7.x-Cluster erstellen, verwenden Sie die folgenden Befehle:
#Start HANA topology, before the HANA instance pcs constraint order SAPHanaTopology_HN1_HDB03-clone then msl_SAPHana_HN1_HDB03 pcs constraint colocation add g_ip_HN1_03 with master msl_SAPHana_HN1_HDB03 4000 #HANA resources are only allowed to run on a node, if the node's NFS file systems are mounted. The constraint also avoids the majority maker node pcs constraint location SAPHanaTopology_HN1_HDB03-clone rule resource-discovery=never score=-INFINITY hana_nfs_s1_active ne true and hana_nfs_s2_active ne trueWenn Sie einen Cluster mit RHEL >= 8.x erstellen, verwenden Sie die folgenden Befehle:
#Start HANA topology, before the HANA instance pcs constraint order SAPHanaTopology_HN1_HDB03-clone then SAPHana_HN1_HDB03-clone pcs constraint colocation add g_ip_HN1_03 with master SAPHana_HN1_HDB03-clone 4000 #HANA resources are only allowed to run on a node, if the node's NFS file systems are mounted. The constraint also avoids the majority maker node pcs constraint location SAPHanaTopology_HN1_HDB03-clone rule resource-discovery=never score=-INFINITY hana_nfs_s1_active ne true and hana_nfs_s2_active ne true
[1] Beenden Sie für den Cluster den Wartungsmodus. Vergewissern Sie sich, dass der Cluster-Status
okist und dass alle Ressourcen gestartet sind.sudo pcs property set maintenance-mode=false #If there are failed cluster resources, you may need to run the next command pcs resource cleanupHinweis
Die Zeitüberschreitungen in der vorstehenden Konfiguration sind nur Beispiele und müssen möglicherweise an die spezifische HANA-Einrichtung angepasst werden. Sie müssen beispielsweise den Start-Timeout erhöhen, wenn es länger dauert, die SAP HANA-Datenbank zu starten.
Konfigurieren Sie die aktive/lesefähige Systemreplikation von HANA
Ab SAP HANA 2.0 SPS 01 erlaubt SAP aktive/lesefähige Setups für die SAP HANA-Systemreplikation. Mit dieser Fähigkeit können Sie die sekundären Systeme der SAP HANA-Systemreplikation aktiv für leseintensive Workloads nutzen. Um ein solches Setup in einem Cluster zu unterstützen, benötigen Sie eine zweite virtuelle IP-Adresse, über die Clients auf die sekundäre, lesefähige SAP HANA-Datenbank zugreifen können. Um sicherzustellen, dass der sekundäre Replikationsstandort auch nach einer Übernahme noch erreichbar ist, muss der Cluster die virtuelle IP-Adresse mit der sekundären der SAP HANA-Ressource verschieben.
Dieser Abschnitt beschreibt die zusätzlichen Schritte, die Sie unternehmen müssen, um diese Art der Systemreplikation in einem Red Hat Hochverfügbarkeitscluster mit einer zweiten virtuellen IP-Adresse zu verwalten.
Bevor Sie fortfahren, stellen Sie sicher, dass Sie einen Red Hat-Hochverfügbarkeitscluster, der eine SAP HANA-Datenbank verwaltet, vollständig konfiguriert haben, wie weiter oben in diesem Artikel beschrieben.
Zusätzliche Einrichtung in Azure Load Balancer für aktive/lesefähige Einrichtung
Um mit der Bereitstellung Ihrer zweiten virtuellen IP fortzufahren, stellen Sie sicher, dass Sie Azure Load Balancer wie in Konfigurieren von Azure Load Balancer beschrieben konfiguriert haben.
Für den Standard-Loadbalancer führen Sie die folgenden zusätzlichen Schritte auf demselben Loadbalancer aus, den Sie im vorherigen Abschnitt erstellt haben.
Erstellen eines zweiten Front-End-IP-Pools:
- Öffnen Sie den Lastenausgleich, und wählen Sie den Front-End-IP-Pool und dann Hinzufügen aus.
- Geben Sie den Namen des zweiten Front-End-IP-Pools ein (z. B. hana-secondaryIP).
- Setzen Sie Zuweisung auf Statisch, und geben Sie die IP-Adresse ein (zum Beispiel 10.23.0.19).
- Klicken Sie auf OK.
- Notieren Sie nach Erstellen des neuen Front-End-IP-Pools dessen IP-Adresse.
Erstellen Sie als Nächstes einen Integritätstest:
- Öffnen Sie den Lastenausgleich, und wählen Sie Integritätstests und dann Hinzufügen aus.
- Geben Sie den Namen des neuen Integritätstests ein (z. B. hana-secondaryhp).
- Wählen Sie TCP als Protokoll und den Port 62603 aus. Behalten Sie für das Intervall den Wert „5“ und als Fehlerschwellenwert „2“ bei.
- Klicken Sie auf OK.
Erstellen Sie als Nächstes die Lastenausgleichsregeln:
- Öffnen Sie den Lastenausgleich, und wählen Sie Lastenausgleichsregeln und dann Hinzufügen aus.
- Geben Sie den Namen der neuen Lastenausgleichsregel ein (z. B. hana-secondarylb).
- Wählen Sie die Front-End-IP-Adresse, den Back-End-Pool und die zuvor erstellte Integritätsprüfung aus (zum Beispiel hana-secondaryIP, hana-backend und hana-secondaryhp).
- Wählen Sie HA-Ports aus.
- Achten Sie darauf, dass Sie „Floating IP“ aktivieren.
- Klicken Sie auf OK.
Konfigurieren Sie die aktive/lesefähige Systemreplikation von HANA
Die Schritte zur Konfiguration der HANA-Systemreplikation sind im Abschnitt Konfiguration der SAP HANA 2.0-Systemreplikation beschrieben. Wenn Sie ein lesefähiges sekundäres Szenario einrichten, führen Sie während der Konfiguration der Systemreplikation auf dem zweiten Knoten folgenden Befehl als hanasidadm aus:
sapcontrol -nr 03 -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hana-s1-db1 --remoteInstance=03 --replicationMode=sync --name=HANA_S2 --operationMode=logreplay_readaccess
Hinzufügen einer sekundären virtuellen IP-Adressressressressource für eine aktive/leseaktivierte Einrichtung
Sie können die zweite virtuelle IP und die zusätzlichen Beschränkungen mit den folgenden Befehlen konfigurieren. Wenn die sekundäre Instanz ausgefallen ist, wird die sekundäre virtuelle IP auf die primäre umgestellt.
pcs property set maintenance-mode=true
pcs resource create secvip_HN1_03 ocf:heartbeat:IPaddr2 ip="10.23.0.19"
pcs resource create secnc_HN1_03 ocf:heartbeat:azure-lb port=62603
pcs resource group add g_secip_HN1_03 secnc_HN1_03 secvip_HN1_03
# RHEL 8.x:
pcs constraint location g_ip_HN1_03 rule score=500 role=master hana_hn1_roles eq "master1:master:worker:master" and hana_hn1_clone_state eq PROMOTED
pcs constraint location g_secip_HN1_03 rule score=50 hana_hn1_roles eq 'master1:master:worker:master'
pcs constraint order promote SAPHana_HN1_HDB03-clone then start g_ip_HN1_03
pcs constraint order start g_ip_HN1_03 then start g_secip_HN1_03
pcs constraint colocation add g_secip_HN1_03 with Slave SAPHana_HN1_HDB03-clone 5
# RHEL 7.x:
pcs constraint location g_ip_HN1_03 rule score=500 role=master hana_hn1_roles eq "master1:master:worker:master" and hana_hn1_clone_state eq PROMOTED
pcs constraint location g_secip_HN1_03 rule score=50 hana_hn1_roles eq 'master1:master:worker:master'
pcs constraint order promote msl_SAPHana_HN1_HDB03 then start g_ip_HN1_03
pcs constraint order start g_ip_HN1_03 then start g_secip_HN1_03
pcs constraint colocation add g_secip_HN1_03 with Slave msl_SAPHana_HN1_HDB03 5
pcs property set maintenance-mode=false
Vergewissern Sie sich, dass der Cluster-Status ok ist und dass alle Ressourcen gestartet sind. Die zweite virtuelle IP wird auf dem sekundären Standort zusammen mit der sekundären SAP HANA-Ressource ausgeführt.
# Example output from crm_mon
#Online: [ hana-s-mm hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ]
#
#Active resources:
#
#rsc_st_azure (stonith:fence_azure_arm): Started hana-s-mm
#Clone Set: fs_hana_shared_s1-clone [fs_hana_shared_s1]
# Started: [ hana--s1-db1 hana-s1-db2 hana-s1-db3 ]
#Clone Set: fs_hana_shared_s2-clone [fs_hana_shared_s2]
# Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ]
#Clone Set: hana_nfs_s1_active-clone [hana_nfs_s1_active]
# Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ]
#Clone Set: hana_nfs_s2_active-clone [hana_nfs_s2_active]
# Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ]
#Clone Set: SAPHanaTopology_HN1_HDB03-clone [SAPHanaTopology_HN1_HDB03]
# Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ]
#Master/Slave Set: msl_SAPHana_HN1_HDB03 [SAPHana_HN1_HDB03]
# Masters: [ hana-s1-db1 ]
# Slaves: [ hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ]
#Resource Group: g_ip_HN1_03
# nc_HN1_03 (ocf::heartbeat:azure-lb): Started hana-s1-db1
# vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hana-s1-db1
#Resource Group: g_secip_HN1_03
# secnc_HN1_03 (ocf::heartbeat:azure-lb): Started hana-s2-db1
# secvip_HN1_03 (ocf::heartbeat:IPaddr2): Started hana-s2-db1
Im nächsten Abschnitt finden Sie eine Reihe typischer Failover-Tests, die Sie durchführen können.
Wenn Sie einen HANA-Cluster testen, der mit einer leseaktivierten sekundären IP konfiguriert ist, sollten Sie das folgende Verhalten der zweiten virtuellen IP beachten:
Wenn die Clusterressource SAPHANA_HN1_HDB03 zum sekundären Standort (S2) wechselt, wechselt die zweite virtuelle IP zum anderen Standort, hana-s1-db1. Wenn Sie
AUTOMATED_REGISTER="false"konfiguriert haben und die HANA-Systemreplikation nicht automatisch registriert wird, dann läuft die zweite virtuelle IP auf hana-s2-db1.Wenn Sie einen Serverabsturz testen, laufen die zweite virtuelle IP-Ressource (secvip_HN1_03) und die Azure Load Balancer Port-Ressource (secnc_HN1_03) auf dem primären Server neben den primären virtuellen IP-Ressourcen. Während der sekundäre Server ausgefallen ist, stellen die Anwendungen, die mit einer HANA-Datenbank mit Lesezugriff verbunden sind, eine Verbindung mit der primären HANA-Datenbank her. Dies ist das erwartete Verhalten. Sie ermöglicht den Betrieb von Anwendungen, die mit der lesefähigen HANA-Datenbank verbunden sind, während ein sekundärer Server nicht verfügbar ist.
Während Failover und Fallback können die bestehenden Verbindungen für Anwendungen, die die zweite virtuelle IP zur Verbindung mit der HANA-Datenbank verwenden, unterbrochen werden.
Testen des SAP HANA-Failovers
Bevor Sie einen Test starten, überprüfen Sie den Cluster und den Replikationsstatus des SAP HANA-Systems.
Überprüfen Sie, ob es keine fehlgeschlagenen Cluster-Aktionen gibt.
#Verify that there are no failed cluster actions pcs status # Example #Stack: corosync #Current DC: hana-s-mm (version 1.1.19-8.el7_6.5-c3c624ea3d) - partition with quorum #Last updated: Thu Sep 24 06:00:20 2020 #Last change: Thu Sep 24 05:59:17 2020 by root via crm_attribute on hana-s1-db1 # #7 nodes configured #45 resources configured # #Online: [ hana-s-mm hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # #Active resources: # #rsc_st_azure (stonith:fence_azure_arm): Started hana-s-mm #Clone Set: fs_hana_shared_s1-clone [fs_hana_shared_s1] # Started: [ hana--s1-db1 hana-s1-db2 hana-s1-db3 ] #Clone Set: fs_hana_shared_s2-clone [fs_hana_shared_s2] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] #Clone Set: hana_nfs_s1_active-clone [hana_nfs_s1_active] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ] #Clone Set: hana_nfs_s2_active-clone [hana_nfs_s2_active] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] #Clone Set: SAPHanaTopology_HN1_HDB03-clone [SAPHanaTopology_HN1_HDB03] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] #Master/Slave Set: msl_SAPHana_HN1_HDB03 [SAPHana_HN1_HDB03] # Masters: [ hana-s1-db1 ] # Slaves: [ hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] #Resource Group: g_ip_HN1_03 # nc_HN1_03 (ocf::heartbeat:azure-lb): Started hana-s1-db1 # vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hana-s1-db1Überprüfen Sie, ob die SAP HANA-Systemreplikation synchron ist.
# Verify HANA HSR is in sync sudo su - hn1adm -c "python /usr/sap/HN1/HDB03/exe/python_support/systemReplicationStatus.py" #| Database | Host | Port | Service Name | Volume ID | Site ID | Site Name | Secondary | Secondary| Secondary | Secondary | Secondary | Replication | Replication | Replication | #| | | | | | | | Host | Port | Site ID | Site Name | Active Status | Mode | Status | Status Details | #| -------- | ----------- | ----- | ------------ | --------- | ------- | --------- | ------------- | -------- | --------- | --------- | ------------- | ----------- | ----------- | -------------- | #| HN1 | hana-s1-db3 | 30303 | indexserver | 5 | 2 | HANA_S1 | hana-s2-db3 | 30303 | 1 | HANA_S2 | YES | SYNC | ACTIVE | | #| HN1 | hana-s1-db2 | 30303 | indexserver | 4 | 2 | HANA_S1 | hana-s2-db2 | 30303 | 1 | HANA_S2 | YES | SYNC | ACTIVE | | #| SYSTEMDB | hana-s1-db1 | 30301 | nameserver | 1 | 2 | HANA_S1 | hana-s2-db1 | 30301 | 1 | HANA_S2 | YES | SYNC | ACTIVE | | #| HN1 | hana-s1-db1 | 30307 | xsengine | 2 | 2 | HANA_S1 | hana-s2-db1 | 30307 | 1 | HANA_S2 | YES | SYNC | ACTIVE | | #| HN1 | hana-s1-db1 | 30303 | indexserver | 3 | 2 | HANA_S1 | hana-s2-db1 | 30303 | 1 | HANA_S2 | YES | SYNC | ACTIVE | | #status system replication site "1": ACTIVE #overall system replication status: ACTIVE #Local System Replication State #~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ #mode: PRIMARY #site id: 1 #site name: HANA_S1
Überprüfen Sie die Clusterkonfiguration auf ein Fehlerszenario, bei dem ein Knoten den Zugriff auf die NFS-Freigabe (
/hana/shared) verliert.Die SAP HANA-Ressourcenagenten hängen von Binärdateien ab, die auf
/hana/sharedgespeichert sind, um Operationen während des Failover durchzuführen. Das Dateisystem/hana/sharedist in der dargestellten Konfiguration über NFS eingebunden. Ein Test, der durchgeführt werden kann, besteht darin, eine temporäre Firewallregel zu erstellen, um den Zugriff auf das in NFS eingebundene Dateisystem/hana/sharedauf einer der VMs des primären Standorts zu blockieren. Auf diese Weise lässt sich überprüfen, ob der Cluster ein Failover ausführen wird, wenn der Zugriff auf/hana/sharedam aktiven Systemreplikationsstandort verloren geht.Erwartetes Ergebnis: Wenn Sie den Zugriff auf das in NFS eingebundene Dateisystem
/hana/sharedauf einer der VMs des primären Standorts blockieren, schlägt der Überwachungsvorgang fehl, der Lese-/Schreibvorgänge für das Dateisystem ausführt, weil er nicht auf das Dateisystem zugreifen kann und ein HANA-Ressourcenfailover auslöst. Dasselbe Ergebnis ist zu erwarten, wenn der HANA-Knoten den Zugriff auf die NFS-Freigabe verliert.Sie können den Zustand der Cluster-Ressourcen überprüfen, indem Sie
crm_monoderpcs statusausführen. Zustand der Ressource vor dem Starten des Tests:# Output of crm_mon #7 nodes configured #45 resources configured #Online: [ hana-s-mm hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # #Active resources: #rsc_st_azure (stonith:fence_azure_arm): Started hana-s-mm # Clone Set: fs_hana_shared_s1-clone [fs_hana_shared_s1] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ] # Clone Set: fs_hana_shared_s2-clone [fs_hana_shared_s2] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Clone Set: hana_nfs_s1_active-clone [hana_nfs_s1_active] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ] # Clone Set: hana_nfs_s2_active-clone [hana_nfs_s2_active] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Clone Set: SAPHanaTopology_HN1_HDB03-clone [SAPHanaTopology_HN1_HDB03] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Master/Slave Set: msl_SAPHana_HN1_HDB03 [SAPHana_HN1_HDB03] # Masters: [ hana-s1-db1 ] # Slaves: [ hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Resource Group: g_ip_HN1_03 # nc_HN1_03 (ocf::heartbeat:azure-lb): Started hana-s1-db1 # vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hana-s1-db1So simulieren Sie ein Failover für
/hana/shared:- Wenn Sie NFS in ANF verwenden, bestätigen Sie zunächst die IP-Adresse für das ANF-Volume
/hana/sharedam primären Standort. Dazu können Sie den Befehldf -kh|grep /hana/sharedausführen. - Wenn Sie NFS in Azure Files verwenden, bestimmen Sie zunächst die IP-Adresse des privaten Endpunkts für Ihr Speicherkonto.
Richten Sie dann eine temporäre Firewallregel ein, um den Zugriff auf die IP-Adresse des NFS-Dateisystems
/hana/sharedzu blockieren, indem Sie auf einer der VMs des primären HANA-Systemreplikationsstandorts den folgenden Befehl ausführen.In diesem Beispiel wurde der Befehl auf „hana-s1-db1“ für das ANF-Volume
/hana/sharedausgeführt.iptables -A INPUT -s 10.23.1.7 -j DROP; iptables -A OUTPUT -d 10.23.1.7 -j DROPDie HANA-VM, die den Zugriff auf
/hana/sharedverloren hat, sollte neu gestartet oder gestoppt werden, je nach Clusterkonfiguration. Die Clusterressourcen werden zum anderen Replikationsstandort des HANA-Systems migriert.Wenn der Cluster auf der neu gestarteten VM noch nicht gestartet wurde, starten Sie den Cluster mit folgendem Befehl:
# Start the cluster pcs cluster startBeim Start des Clusters wird das Dateisystem
/hana/sharedautomatisch eingehängt. Wenn SieAUTOMATED_REGISTER="false"einstellen, müssen Sie die SAP HANA-Systemreplikation auf dem sekundären Standort konfigurieren. In diesem Fall können Sie diese Befehle ausführen, um SAP HANA als sekundär zu rekonfigurieren.# Execute on the secondary su - hn1adm # Make sure HANA is not running on the secondary site. If it is started, stop HANA sapcontrol -nr 03 -function StopWait 600 10 # Register the HANA secondary site hdbnsutil -sr_register --name=HANA_S1 --remoteHost=hana-s2-db1 --remoteInstance=03 --replicationMode=sync # Switch back to root and clean up failed resources pcs resource cleanup SAPHana_HN1_HDB03Der Zustand der Ressourcen nach dem Test:
# Output of crm_mon #7 nodes configured #45 resources configured #Online: [ hana-s-mm hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] #Active resources: #rsc_st_azure (stonith:fence_azure_arm): Started hana-s-mm # Clone Set: fs_hana_shared_s1-clone [fs_hana_shared_s1] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ] # Clone Set: fs_hana_shared_s2-clone [fs_hana_shared_s2] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Clone Set: hana_nfs_s1_active-clone [hana_nfs_s1_active] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ] # Clone Set: hana_nfs_s2_active-clone [hana_nfs_s2_active] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Clone Set: SAPHanaTopology_HN1_HDB03-clone [SAPHanaTopology_HN1_HDB03] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Master/Slave Set: msl_SAPHana_HN1_HDB03 [SAPHana_HN1_HDB03] # Masters: [ hana-s2-db1 ] # Slaves: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db2 hana-s2-db3 ] # Resource Group: g_ip_HN1_03 # nc_HN1_03 (ocf::heartbeat:azure-lb): Started hana-s2-db1 # vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hana-s2-db1- Wenn Sie NFS in ANF verwenden, bestätigen Sie zunächst die IP-Adresse für das ANF-Volume
Es ist ratsam, die SAP HANA-Cluster-Konfiguration gründlich zu testen, indem Sie auch die in Hochverfügbarkeit für SAP HANA auf Azure VMs auf RHEL dokumentierten Tests durchführen.
Nächste Schritte
- Azure Virtual Machines – Planung und Implementierung für SAP
- Azure Virtual Machines – Bereitstellung für SAP
- Azure Virtual Machines – DBMS-Bereitstellung für SAP
- NFS v4.1-Volumes unter Azure NetApp Files für SAP HANA
- Wie Sie Hochverfügbarkeit einrichten und die Wiederherstellung von SAP HANA auf Azure VMs planen können, erfahren Sie unter Hochverfügbarkeit von SAP HANA auf Azure VMs.