Funktionsüberladung
Mit C++ können Sie mehrere Funktionen desselben Namens im selben Bereich angeben. Diese Funktionen werden als überladene Funktionen oder Überladungen bezeichnet. Überladene Funktionen ermöglichen es Ihnen, je nach Typen und Anzahl der Argumente unterschiedliche Semantik für eine Funktion zu liefern.
Betrachten Sie z. B. eine print Funktion, die ein std::string Argument verwendet. Diese Funktion kann sehr unterschiedliche Aufgaben ausführen als eine Funktion, die ein Argument vom Typ doubleverwendet. Die Überladung verhindert, dass Sie Namen wie print_string z. B. oder print_double. Zur Kompilierungszeit wählt der Compiler aus, welche Überladung basierend auf den Typen und der Anzahl von Argumenten verwendet werden soll, die vom Aufrufer übergeben werden. Wenn Sie die Funktion aufrufen print(42.0), wird die void print(double d) Funktion aufgerufen. Wenn Sie aufrufen print("hello world"), wird die void print(std::string) Überladung aufgerufen.
Sie können sowohl Memberfunktionen als auch kostenlose Funktionen überladen. Die folgende Tabelle zeigt, welche Teile einer Funktionsdeklaration C++ verwendet, um zwischen Gruppen von Funktionen mit demselben Namen im selben Bereich zu unterscheiden.
Überlegungen zur Überladung
| Funktionsdeklarationselement | Wird für Überladungen verwendet? |
|---|---|
| Funktionsrückgabetyp | Nein |
| Anzahl der Argumente | Ja |
| Typ der Argumente | Ja |
| Vorhandensein oder Abwesenheit von Auslassungszeichen | Ja |
Verwendung von typedef Namen |
Nein |
| Nicht angegebene Arraygrenzen | Nein |
const oder volatile |
Ja, wenn sie auf die gesamte Funktion angewendet wird |
Referenzqualifizierer (& und &&) |
Ja |
Beispiel
Das folgende Beispiel veranschaulicht, wie Sie Funktionsüberladungen verwenden können:
// function_overloading.cpp
// compile with: /EHsc
#include <iostream>
#include <math.h>
#include <string>
// Prototype three print functions.
int print(std::string s); // Print a string.
int print(double dvalue); // Print a double.
int print(double dvalue, int prec); // Print a double with a
// given precision.
using namespace std;
int main(int argc, char *argv[])
{
const double d = 893094.2987;
if (argc < 2)
{
// These calls to print invoke print( char *s ).
print("This program requires one argument.");
print("The argument specifies the number of");
print("digits precision for the second number");
print("printed.");
exit(0);
}
// Invoke print( double dvalue ).
print(d);
// Invoke print( double dvalue, int prec ).
print(d, atoi(argv[1]));
}
// Print a string.
int print(string s)
{
cout << s << endl;
return cout.good();
}
// Print a double in default precision.
int print(double dvalue)
{
cout << dvalue << endl;
return cout.good();
}
// Print a double in specified precision.
// Positive numbers for precision indicate how many digits
// precision after the decimal point to show. Negative
// numbers for precision indicate where to round the number
// to the left of the decimal point.
int print(double dvalue, int prec)
{
// Use table-lookup for rounding/truncation.
static const double rgPow10[] = {
10E-7, 10E-6, 10E-5, 10E-4, 10E-3, 10E-2, 10E-1,
10E0, 10E1, 10E2, 10E3, 10E4, 10E5, 10E6 };
const int iPowZero = 6;
// If precision out of range, just print the number.
if (prec < -6 || prec > 7)
{
return print(dvalue);
}
// Scale, truncate, then rescale.
dvalue = floor(dvalue / rgPow10[iPowZero - prec]) *
rgPow10[iPowZero - prec];
cout << dvalue << endl;
return cout.good();
}
Der vorherige Code zeigt Überladungen der print Funktion im Dateibereich.
Das Standardargument wird nicht als Teil des Funktionstyps betrachtet. Daher wird sie nicht zum Auswählen überladener Funktionen verwendet. Zwei Funktionen, die sich nur bei den Standardargumenten unterscheiden, werden als mehrfache Definitionen und nicht als überladene Funktionen betrachtet.
Standardargumente können für überladene Operatoren nicht bereitgestellt werden.
Argumentabgleich
Der Compiler wählt aus, welche überladene Funktion aufgerufen werden soll, basierend auf der besten Übereinstimmung zwischen den Funktionsdeklarationen im aktuellen Bereich mit den argumenten, die im Funktionsaufruf angegeben werden. Wenn eine passende Funktion gefunden wird, wird diese Funktion aufgerufen. "Geeignet" in diesem Zusammenhang bedeutet entweder:
Ein exakte Übereinstimmung wurde gefunden.
Eine triviale Konvertierung wurde ausgeführt.
Eine ganzzahlige Heraufstufung wurde ausgeführt.
Eine Standardkonvertierung zum gewünschten Argumenttyp ist vorhanden.
Eine benutzerdefinierte Konvertierung (entweder ein Konvertierungsoperator oder ein Konstruktor) in den gewünschten Argumenttyp ist vorhanden.
Es wurden durch Ellipsen dargestellte Argumente gefunden.
Der Compiler erstellt einen Satz Kandidatenfunktionen für jedes Argument. Kandidatenfunktionen sind Funktionen, in denen das tatsächliche Argument an dieser Position in den Typ des formalen Arguments konvertiert werden kann.
Ein Satz von „am besten passenden Funktionen“ wird für jedes Argument erstellt, und die ausgewählte Funktion ist die Schnittmenge aller Sätze. Wenn die Schnittmenge mehr als eine Funktion enthält, ist das Überladen mehrdeutig und generiert einen Fehler. Die schließlich ausgewählte Funktion ist immer eine bessere Übereinstimmung als jede andere Funktion in der Gruppe für mindestens ein Argument. Wenn kein eindeutiger Gewinner vorhanden ist, generiert der Funktionsaufruf einen Compilerfehler.
Berücksichtigen Sie die folgenden Deklarationen (Funktionen sind zur Identifikation der folgenden Erläuterung als Variant 1, Variant 2 und Variant 3 gekennzeichnet):
Fraction &Add( Fraction &f, long l ); // Variant 1
Fraction &Add( long l, Fraction &f ); // Variant 2
Fraction &Add( Fraction &f, Fraction &f ); // Variant 3
Fraction F1, F2;
Betrachten Sie folgende Anweisung:
F1 = Add( F2, 23 );
Die vorhergehende Anweisung erstellt zwei Sätze:
Set 1: Candidate functions that have first argument of type Fraction |
Set 2: Kandidatenfunktionen, deren zweites Argument in Typ konvertiert werden kann int |
|---|---|
| Variant 1 | Variante 1 (int kann in eine Standardkonvertierung konvertiert long werden) |
| Variant 3 |
Funktionen in Set 2 sind Funktionen, die implizite Konvertierungen vom tatsächlichen Parametertyp in den formalen Parametertyp aufweisen. Eine dieser Funktionen weist die kleinsten "Kosten" auf, um den tatsächlichen Parametertyp in den entsprechenden formalen Parametertyp zu konvertieren.
Die Schnittmenge dieser beiden Sätze ist "Variant 1". Ein Beispiel für einen mehrdeutigen Funktionsaufruf ist:
F1 = Add( 3, 6 );
Der vorhergehende Funktionsaufruf erstellt die folgenden Sätze:
Set 1: Candidate Functions That Have First Argument of Type int |
Set 2: Candidate Functions That Have Second Argument of Type int |
|---|---|
Variante 2 (int kann in eine Standardkonvertierung konvertiert long werden) |
Variante 1 (int kann in eine Standardkonvertierung konvertiert long werden) |
Da die Schnittmenge dieser beiden Sätze leer ist, generiert der Compiler eine Fehlermeldung.
Für den Argumentabgleich wird eine Funktion mit n Standardargumenten als n+1 separate Funktionen behandelt, die jeweils eine andere Anzahl von Argumenten aufweisen.
Die Auslassungspunkte (...) fungieren als Wild Karte; sie entspricht jedem tatsächlichen Argument. Es kann zu vielen mehrdeutigen Sätzen führen, wenn Sie Ihre überladenen Funktionssätze nicht mit extremer Sorgfalt entwerfen.
Hinweis
Die Mehrdeutigkeit überladener Funktionen kann erst bestimmt werden, wenn ein Funktionsaufruf auftritt. An diesem Punkt werden die Sätze für jedes Argument im Funktionsaufruf erstellt, und Sie können bestimmen, ob eine eindeutige Überladung vorhanden ist. Dies bedeutet, dass Mehrdeutigkeiten in Ihrem Code neu Standard können, bis sie von einem bestimmten Funktionsaufruf aufgerufen werden.
Unterschiede bei Argumenttypen
Überladene Funktionen unterscheiden zwischen Argumenttypen, die verschiedene Initialisierer erfordern. Daher gelten ein Argument eines angegebenen Typs und ein Verweis auf diesen Typ für den Zweck des Überladens als identisch. Sie werden als identisch betrachtet, da sie dieselben Initialisierer verwenden. max( double, double ) wird beispielsweise identisch mit max( double &, double & ) betrachtet. Das Deklarieren von zwei solcher Funktionen verursacht einen Fehler.
Aus demselben Grund werden Funktionsargumente eines typs geändert const oder volatile nicht anders behandelt als der Basistyp zum Zwecke der Überladung.
Der Funktionsüberlastungsmechanismus kann jedoch zwischen Verweisen unterscheiden, die nach const und volatile nach dem Basistyp qualifiziert sind. Es ermöglicht Code wie die folgenden:
// argument_type_differences.cpp
// compile with: /EHsc /W3
// C4521 expected
#include <iostream>
using namespace std;
class Over {
public:
Over() { cout << "Over default constructor\n"; }
Over( Over &o ) { cout << "Over&\n"; }
Over( const Over &co ) { cout << "const Over&\n"; }
Over( volatile Over &vo ) { cout << "volatile Over&\n"; }
};
int main() {
Over o1; // Calls default constructor.
Over o2( o1 ); // Calls Over( Over& ).
const Over o3; // Calls default constructor.
Over o4( o3 ); // Calls Over( const Over& ).
volatile Over o5; // Calls default constructor.
Over o6( o5 ); // Calls Over( volatile Over& ).
}
Ausgabe
Over default constructor
Over&
Over default constructor
const Over&
Over default constructor
volatile Over&
Zeiger auf const und volatile Objekte werden auch von Zeigern bis zum Basistyp für überladene Zwecke betrachtet.
Argumentübereinstimmung und Konvertierungen
Wenn der Compiler versucht, die tatsächlichen Argumente mit den Argumenten in Funktionsdeklarationen abzugleichen, kann er Standardkonvertierungen oder benutzerdefinierte Konvertierungen bereitstellen, um den korrekten Typ zu erhalten, wenn keine genaue Übereinstimmung gefunden wird. Die Anwendung von Konvertierungen unterliegt diesen Regeln:
Sequenzen von Konvertierungen, die mehr als eine benutzerdefinierte Konvertierung enthalten, werden nicht berücksichtigt.
Sequenzen von Konvertierungen, die durch entfernen von Zwischenkonvertierungen gekürzt werden können, werden nicht berücksichtigt.
Die resultierende Abfolge der Konvertierungen wird, falls vorhanden, als beste Abgleichssequenz bezeichnet. Es gibt verschiedene Möglichkeiten, ein Objekt vom Typ int mithilfe von Standardkonvertierungen in Typ unsigned long zu konvertieren (in Standardkonvertierungen beschrieben):
Konvertieren von in
intlongund dann vonlongzuunsigned long.Konvertieren von
intinunsigned long.
Obwohl die erste Sequenz das gewünschte Ziel erreicht, ist sie nicht die beste Abgleichssequenz, da eine kürzere Sequenz vorhanden ist.
Die folgende Tabelle zeigt eine Gruppe von Konvertierungen, die als triviale Konvertierungen bezeichnet werden. Triviale Konvertierungen haben einen begrenzten Effekt darauf, welche Sequenz der Compiler als beste Übereinstimmung auswäht. Die Auswirkung von trivialen Konvertierungen wird nach der Tabelle beschrieben.
Triviale Konvertierungen
| Argumenttyp | Konvertierter Typ |
|---|---|
type-name |
type-name& |
type-name& |
type-name |
type-name[] |
type-name* |
type-name(argument-list) |
(*type-name)(argument-list) |
type-name |
const type-name |
type-name |
volatile type-name |
type-name* |
const type-name* |
type-name* |
volatile type-name* |
Die Reihenfolge für Konvertierungen lautet wie folgt:
Genaue Übereinstimmung. Ein genaue Übereinstimmung zwischen den Typen, mit denen die Funktion aufgerufen wird und den Typen, die im Funktionsprototyp deklariert werden, ist immer die beste Übereinstimmung. Sequenzen von trivialen Konvertierungen werden als exakte Übereinstimmungen klassifiziert. Sequenzen, die keine dieser Konvertierungen machen, werden jedoch als besser betrachtet als Sequenzen, die konvertiert werden:
Von Zeiger, zum Zeiger auf (
type-name*bisconst type-name*const).Von Zeiger, zum Zeiger auf (
type-name*bisvolatile type-name*volatile).Von Bezug zu Bezug auf
const(type-name&bisconst type-name&).Von Bezug zu Bezug auf
volatile(type-name&bisvolatile type&).
Übereinstimmung mithilfe von Erweiterungen. Jede Sequenz, die nicht als exakte Übereinstimmung klassifiziert wird, die nur integrale Werbung, Konvertierungen von
floatindoubleund triviale Konvertierungen enthält, wird als Übereinstimmung mit Werbeaktionen klassifiziert. Obwohl eine Übereinstimmung mit Erweiterungen besser ist als eine Übereinstimmung, die Standardkonvertierungen verwendet, ist sie nicht so gut wie eine genaue Übereinstimmung.Übereinstimmung mithilfe von Standardkonvertierungen. Jede beliebige Sequenz, die nicht als genaue Übereinstimmung klassifiziert wird, oder eine Übereinstimmung mithilfe von Erweiterungen, die nur Standardkonvertierungen und triviale Konvertierungen enthält, wird als Übereinstimmung mithilfe von Standardkonvertierungen klassifiziert. In dieser Kategorie gelten die folgenden Regeln:
Die Konvertierung von einem Zeiger in eine abgeleitete Klasse in einen Zeiger auf eine direkte oder indirekte Basisklasse ist vorzuziehen, in
void *oderconst void *.Die Konvertierung von einem Zeiger auf eine abgeleitete Klasse in einen Zeiger auf eine Basisklasse erzeugt eine bessere Übereinstimmung, je näher die Basisklasse der direkten Basisklasse ist. Angenommen, die Klassenhierarchie ist wie in der folgenden Abbildung dargestellt:

Diagramm mit bevorzugten Konvertierungen.
Die Konvertierung von Typ D* in Typ C* ist der Konvertierung von Typ D* in Typ B* vorzuziehen. Entsprechend ist die Konvertierung von Typ D* in Typ B* der Konvertierung von Typ D* in Typ A* vorzuziehen.
Die gleiche Regel gilt für Verweiskonvertierungen. Die Konvertierung von Typ D& in Typ C& ist der Konvertierung von Typ D& in Typ B& usw. vorzuziehen.
Die gleiche Regel gilt für pointer-to-member-Konvertierungen. Die Konvertierung von Typ T D::* in Typ T C::* ist der Konvertierung von Typ T D::* in Typ T B::* und so weiter vorzuziehen (wobei T der Typ des Members ist).
Die vorhergehende Regel gilt nur für einen bestimmten Ableitungspfad. Betrachten Sie das Diagramm, das in der folgenden Abbildung dargestellt wird.
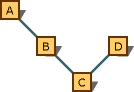
Diagramm mit mehrfacher Vererbung, das bevorzugte Konvertierungen anzeigt.
Die Konvertierung von Typ C* in Typ B* ist der Konvertierung von Typ C* in Typ A* vorzuziehen. Der Grund liegt darin, dass sie sich auf dem gleichen Pfad befinden, und B* näher liegt. Die Konvertierung von Typ C* zu Typ D* ist jedoch nicht der Konvertierung in den Typ A*vorzuziehen. Es gibt keine Einstellung, da die Konvertierungen unterschiedlichen Pfaden folgen.
Übereinstimmung mit benutzerdefinierten Konvertierungen. Diese Sequenz kann nicht als genaue Übereinstimmung, eine Übereinstimmung mit Werbeaktionen oder eine Übereinstimmung mit Standardkonvertierungen klassifiziert werden. Um als Übereinstimmung mit benutzerdefinierten Konvertierungen klassifiziert zu werden, darf die Sequenz nur benutzerdefinierte Konvertierungen, Standardkonvertierungen oder triviale Konvertierungen enthalten. Eine Übereinstimmung mit benutzerdefinierten Konvertierungen wird als eine bessere Übereinstimmung als eine Übereinstimmung mit den Auslassungspunkten (
...) betrachtet, aber nicht so gut wie eine Übereinstimmung mit Standardkonvertierungen.Übereinstimmung mit einem Auslassungszeichen. Jede beliebige Sequenz, die Auslassungszeichen in der Deklaration entspricht, wird als Übereinstimmung mit einem Auslassungszeichen klassifiziert. Es gilt als die schwächste Übereinstimmung.
Benutzerdefinierte Konvertierungen werden angewendet, wenn keine integrierte Erweiterung oder Konvertierung vorhanden ist. Diese Konvertierungen werden basierend auf dem Typ des übereinstimmenden Arguments ausgewählt. Betrachten Sie folgenden Code:
// argument_matching1.cpp
class UDC
{
public:
operator int()
{
return 0;
}
operator long();
};
void Print( int i )
{
};
UDC udc;
int main()
{
Print( udc );
}
Die verfügbaren benutzerdefinierten Konvertierungen für die Klasse UDC stammen vom Typ int und Typ long. Deshalb berücksichtigt der Compiler Konvertierungen für den Typ des Objekts, das abgeglichen wird: UDC. Eine konvertierung, die int vorhanden ist und ausgewählt ist.
Während des Prozesseses zum Zuordnen von Argumenten können Standardkonvertierungen sowohl auf das Argument als auch auf das Ergebnis einer benutzerdefinierten Konvertierung angewendet werden. Daher funktioniert der folgende Code:
void LogToFile( long l );
...
UDC udc;
LogToFile( udc );
In diesem Beispiel ruft der Compiler eine benutzerdefinierte Konvertierung auf, operator longum in Typ longzu konvertierenudc. Wenn keine benutzerdefinierte Konvertierung in Typ long definiert wurde, würde der Compiler zuerst den Typ UDC mithilfe der benutzerdefinierten operator int Konvertierung in typ int konvertieren. Anschließend würde die Standardkonvertierung vom Typ int auf den Typ long angewendet, um dem Argument in der Deklaration zu entsprechen.
Wenn benutzerdefinierte Konvertierungen erforderlich sind, um einem Argument zu entsprechen, werden die Standardkonvertierungen beim Auswerten der besten Übereinstimmung nicht verwendet. Auch wenn mehr als eine Kandidatenfunktion eine benutzerdefinierte Konvertierung erfordert, werden die Funktionen als gleich angesehen. Beispiel:
// argument_matching2.cpp
// C2668 expected
class UDC1
{
public:
UDC1( int ); // User-defined conversion from int.
};
class UDC2
{
public:
UDC2( long ); // User-defined conversion from long.
};
void Func( UDC1 );
void Func( UDC2 );
int main()
{
Func( 1 );
}
Beide Versionen erfordern Func eine benutzerdefinierte Konvertierung zum Konvertieren des Typs int in das Klassentypargument. Mögliche Konversionen sind:
Konvertieren sie vom Typ
intin den TypUDC1(eine benutzerdefinierte Konvertierung).Konvertieren Sie von Typ
intin Typlong; konvertieren Sie dann in TypUDC2(eine Konvertierung in zwei Schritten).
Obwohl die zweite Konvertierung sowohl eine Standardkonvertierung als auch die benutzerdefinierte Konvertierung erfordert, werden die beiden Konvertierungen weiterhin als gleich angesehen.
Hinweis
Benutzerdefinierte Konvertierungen werden als Konvertierung durch Konstruktion oder Konvertierung durch Initialisierung betrachtet. Der Compiler berücksichtigt beide Methoden gleich, wenn sie die beste Übereinstimmung bestimmt.
Argumentabgleich und Zeiger this
Klassenmememmfunktionen werden unterschiedlich behandelt, je nachdem, ob sie als staticdeklariert werden. static Funktionen verfügen nicht über ein implizites Argument, das den this Zeiger bereitstellt, sodass sie als ein argument weniger als reguläre Memberfunktionen betrachtet werden. Andernfalls werden sie identisch deklariert.
Memberfunktionen, die keinen static konkludenten Zeiger this benötigen, um dem Objekttyp zu entsprechen, über den die Funktion aufgerufen wird. Oder für überladene Operatoren muss das erste Argument mit dem Objekt übereinstimmen, auf das der Operator angewendet wird. Weitere Informationen zu überladenen Operatoren finden Sie unter überladene Operatoren.
Im Gegensatz zu anderen Argumenten in überladenen Funktionen führt der Compiler keine temporären Objekte ein und versucht beim Versuch, das this Zeigerargument zuzuordnen, keine Konvertierungen.
Wenn der Memberauswahloperator für den -> Zugriff auf eine Memberfunktion der Klasse class_nameverwendet wird, weist das this Zeigerargument einen Typ von class_name * const. Wenn die Member als const oder volatile, die Typen deklariert sind const class_name * const bzw volatile class_name * const. sind.
Der Memberauswahloperator . funktioniert genau auf die gleiche Weise, außer dass ein impliziter &-Operator (address-of) dem Objektnamen vorangestellt ist. Im folgenden Beispiel wird gezeigt, wie dies funktioniert:
// Expression encountered in code
obj.name
// How the compiler treats it
(&obj)->name
Der linke Operand der Operatoren ->* und .* (Zeiger auf Member) wird hinsichtlich der Argumentübereinstimmung genauso wie der .-Operator und der ->-Operator (Memberauswahl) behandelt.
Referenzqualifizierer für Memberfunktionen
Referenzqualifizierer ermöglichen es, eine Memberfunktion basierend darauf zu überladen, ob das objekt, auf this das verwiesen wird, ein Rvalue oder ein lvalue ist. Verwenden Sie dieses Feature, um unnötige Kopiervorgänge in Szenarien zu vermeiden, in denen Sie keinen Zeigerzugriff auf die Daten bereitstellen möchten. Nehmen Wir beispielsweise an, dass die Klasse C einige Daten im Konstruktor initialisiert und eine Kopie dieser Daten in der Memberfunktion get_data()zurückgibt. Wenn ein Objekt vom Typ C ein Wert ist, der gerade zerstört werden soll, wählt der Compiler die get_data() && Überladung aus, die anstelle der Kopien der Daten verschoben wird.
#include <iostream>
#include <vector>
using namespace std;
class C
{
public:
C() {/*expensive initialization*/}
vector<unsigned> get_data() &
{
cout << "lvalue\n";
return _data;
}
vector<unsigned> get_data() &&
{
cout << "rvalue\n";
return std::move(_data);
}
private:
vector<unsigned> _data;
};
int main()
{
C c;
auto v = c.get_data(); // get a copy. prints "lvalue".
auto v2 = C().get_data(); // get the original. prints "rvalue"
return 0;
}
Einschränkungen beim Überladen
Mehrere Einschränkungen steuern eine akzeptable Gruppe von überladenen Funktionen:
Zwei beliebige Funktionen in einer Gruppe von überladenen Funktionen müssen unterschiedliche Argumentlisten haben.
Überladungsfunktionen mit Argumentlisten derselben Typen, basierend auf dem Rückgabetyp allein, ist ein Fehler.
Microsoft-spezifisch
Sie können basierend auf dem Rückgabetyp, insbesondere basierend auf dem angegebenen Speichermodellmodifizierer, überladen
operator newwerden.Ende Microsoft-spezifisch
Memberfunktionen können nicht nur überladen werden, weil eine ist
staticund die andere nichtstatic.typedefDeklarationen definieren keine neuen Typen; sie führen Synonyme für vorhandene Typen ein. Sie wirken sich nicht auf den Überlastungsmechanismus aus. Betrachten Sie folgenden Code:typedef char * PSTR; void Print( char *szToPrint ); void Print( PSTR szToPrint );Die vorhergehenden zwei Funktionen verfügen über identische Argumentlisten.
PSTRist ein Synonym für typchar *. Im Memberbereich generiert dieser Code einen Fehler.Aufgelistete Typen sind verschiedene Typen und können verwendet werden, um zwischen überladenen Funktionen zu unterscheiden.
Die Typen "Array von" und "Zeiger auf" gelten als identisch für die Unterscheidung zwischen überladenen Funktionen, aber nur für eindimensionale Arrays. Diese überladenen Funktionen verursachen einen Konflikt und generieren eine Fehlermeldung:
void Print( char *szToPrint ); void Print( char szToPrint[] );Bei Arrays mit höherer Dimension werden die zweiten und späteren Dimensionen als Teil des Typs betrachtet. Sie werden bei der Unterscheidung zwischen überladenen Funktionen verwendet:
void Print( char szToPrint[] ); void Print( char szToPrint[][7] ); void Print( char szToPrint[][9][42] );
Überladung, Außerkraftsetzung und Ausblenden
Alle zwei Funktionsdeklarationen desselben Namens im selben Bereich können auf dieselbe Funktion oder auf zwei diskrete überladene Funktionen verweisen. Wenn die Argumentlisten der Deklarationen Argumente äquivalenter Typen enthalten (wie im vorherigen Abschnitt beschrieben), beziehen sich die Funktionsdeklarationen auf die gleiche Funktion. Andernfalls beziehen sie sich auf zwei separate Funktionen, die mithilfe des Überladens ausgewählt werden.
Der Klassenumfang wird streng eingehalten. Eine in einer Basisklasse deklarierte Funktion befindet sich nicht im gleichen Bereich wie eine Funktion, die in einer abgeleiteten Klasse deklariert ist. Wenn eine Funktion in einer abgeleiteten Klasse mit demselben Namen wie eine virtual Funktion in der Basisklasse deklariert wird, überschreibt die abgeleitete Klassenfunktion die Basisklassenfunktion. Weitere Informationen finden Sie unter "Virtuelle Funktionen".
Wenn die Basisklassenfunktion nicht als virtualdeklariert wird, wird die abgeleitete Klassenfunktion dazu verwendet, sie auszublenden. Sowohl überschreiben als auch ausblenden unterscheiden sich von Überladungen.
Blockbereich wird streng beachtet. Eine im Dateibereich deklarierte Funktion befindet sich nicht im gleichen Bereich wie eine lokal deklarierte Funktion. Wenn eine lokal deklarierte Funktion den gleichen Namen wie eine Funktion besitzt, die im Dateibereich deklariert wird, blendet die lokal deklarierte Funktion die Funktion im Dateibereich aus, und es erfolgt keine Überladung. Beispiel:
// declaration_matching1.cpp
// compile with: /EHsc
#include <iostream>
using namespace std;
void func( int i )
{
cout << "Called file-scoped func : " << i << endl;
}
void func( char *sz )
{
cout << "Called locally declared func : " << sz << endl;
}
int main()
{
// Declare func local to main.
extern void func( char *sz );
func( 3 ); // C2664 Error. func( int ) is hidden.
func( "s" );
}
Der vorhergehende Code zeigt zwei Definitionen der Funktion func. Die Definition, für die ein Argument vom Typ char * verwendet wird, ist aufgrund der extern Anweisung lokalmain. Daher ist die Definition, die ein Argument vom Typ int akzeptiert, ausgeblendet, und der erste Aufruf func ist fehlerhaft.
Für überladene Memberfunktionen können verschiedenen Versionen der Funktion unterschiedliche Zugriffsrechte zugewiesen werden. Sie gelten weiterhin als im Rahmen der eingeschlossenen Klasse und sind somit überladene Funktionen. Betrachten Sie den folgenden Code, in dem die Memberfunktion Deposit überladen wird. Eine Version ist öffentlich, die andere privat.
Der Zweck dieses Beispiels ist es, eine Account-Klasse bereitzustellen, in der ein korrektes Kennwort erforderlich ist, um Eingaben vorzunehmen. Dies geschieht mithilfe der Überladung.
Der Aufruf in DepositAccount::Deposit aufruft die Private Member-Funktion. Dieser Aufruf ist richtig, da es sich um Account::Deposit eine Memberfunktion handelt und Zugriff auf die privaten Member der Klasse hat.
// declaration_matching2.cpp
class Account
{
public:
Account()
{
}
double Deposit( double dAmount, char *szPassword );
private:
double Deposit( double dAmount )
{
return 0.0;
}
int Validate( char *szPassword )
{
return 0;
}
};
int main()
{
// Allocate a new object of type Account.
Account *pAcct = new Account;
// Deposit $57.22. Error: calls a private function.
// pAcct->Deposit( 57.22 );
// Deposit $57.22 and supply a password. OK: calls a
// public function.
pAcct->Deposit( 52.77, "pswd" );
}
double Account::Deposit( double dAmount, char *szPassword )
{
if ( Validate( szPassword ) )
return Deposit( dAmount );
else
return 0.0;
}
Siehe auch
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für