Verwenden von Kacheln
Sie können Kacheln verwenden, um die Beschleunigung der App zu maximieren. Bei der Tilung werden Threads in gleich rechteckige Teilmengen oder Kacheln unterteilt. Wenn Sie eine geeignete Flächengröße und Kachelalgorithmus verwenden, können Sie noch mehr Beschleunigung aus dem C++ AMPcode abrufen. Die grundlegenden Komponenten des Kachelns sind:
tile_static-Variablen. Der wichtigste Vorteil des Kachelns liegt in der Leistungssteigerung durch dentile_static-Zugriff. Zugriff auf Daten imtile_static-Arbeitsspeicher kann erheblich schneller sein als ein Zugriff auf Daten im globalen Namensbereich (array-Objekte oderarray_view-Objekte). Eine Instanz einertile_static-Variable wird für jeden Tile erstellt, und alle Threads in den Tile haben Zugriff auf die Variable. In einem typischen Kachelalgorithmus werden Daten einmalig vom globalen Speicher in dentile_static-Speicher kopiert und darauf dann mehrfach vomtile_static-Speicher zugegriffen.tile_barrier::wait-Methode. Ein Aufruf von
tile_barrier::waithält die Ausführung des aktuellen Threads an, bis alle Threads in derselben Kachel den Aufruftile_barrier::waiterhalten. Sie können die Reihenfolge der Ausführung der Threads nicht sicherstellen, nur das keine Threads in der Kachel nach dem Aufruftile_barrier::waitweiter ausgeführt werden, bis alle Threads den Aufruf erhalten haben. Dies bedeutet, dass durch die Verwendung dertile_barrier::wait-Methode die Möglichkeit entsteht, Aufgaben statt threadbezogen kachelbasiert durchzuführen. Ein typischer unterteilender Algorithmus verfügt über Code zum Initialisieren destile_static-Speichers für die gesamte Kachel, gefolgt von einem Aufruf vontile_barrier::wait. Nachtile_barrier::waitfolgender Code enthält Berechnungen, die Zugriff auf alletile_static-Werte benötigen.Lokale und globale Indizierung. Sie haben Zugriff auf den Index des Threads, relativ zum vollständigen
array_view-Objekt oder dasarray-Objekt und dem Index relativ zur Kachel. Das Verwenden des lokalen Index kann den Code besser lesbar machen und einfacher zu debuggen. Üblicherweise verwenden Sie lokale Indizierung zum Zugreifen auf dietile_static-Variablen und globale Indizierung für den Zugriff aufarray-Variablen undarray_view-Variablen.tiled_extent Klasse und tiled_index Klasse. Sie verwenden ein
tiled_extent-Objekt anstelle einesextent-Objekts imparallel_for_each- Aufruf. Sie verwenden eintiled_index-Objekt anstelle einesindex-Objekts imparallel_for_each- Aufruf.
Um die Vorteile des Kachelns zu nutzen, muss Ihr Algorithmus die zu verarbeitende Berechnungsdomäne in Kacheln partitionieren und anschließend die Kacheldaten in tile_static-Variablen für einen schnelleren Zugriff kopieren.
Beispiel von globalen, gekachelten und lokalen Indizes
Hinweis
C++AMP-Header sind ab Visual Studio 2022, Version 17.0, veraltet.
Wenn Alle AMP-Header eingeschlossen werden, werden Buildfehler generiert. Definieren Sie _SILENCE_AMP_DEPRECATION_WARNINGS , bevor Sie AMP-Header einschließen, um die Warnungen zu stillen.
Das folgende Diagramm stellt eine 8 x 9-Datenmatrix dar, die in einer 2 x 3-Kachelgruppe angeordnet wird.
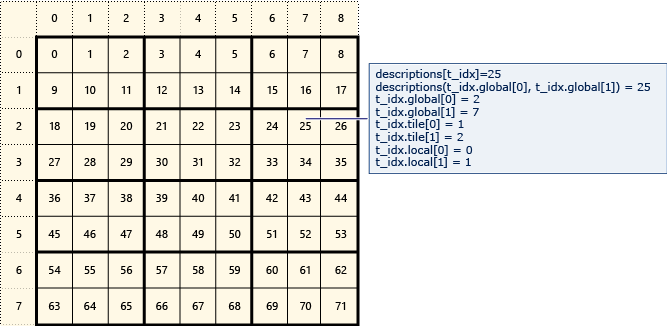
Im folgenden Beispiel werden globale, unterteilte und lokale Indizes dieser gekachelten Matrix. Zum Erstellen eines array_view-Objekts werden Elemente des Description-Typs verwendet. Die Description enthält die globalen, unterteilten und lokalen Indizes des Elements in der Matrix. Der Code im Aufruf von parallel_for_each legt die Werte von globalen, unterteilten und lokalen Indizes für jedes Element fest. Die Ausgabe zeigt die Werte in den Description-Strukturen an.
#include <iostream>
#include <iomanip>
#include <Windows.h>
#include <amp.h>
using namespace concurrency;
const int ROWS = 8;
const int COLS = 9;
// tileRow and tileColumn specify the tile that each thread is in.
// globalRow and globalColumn specify the location of the thread in the array_view.
// localRow and localColumn specify the location of the thread relative to the tile.
struct Description {
int value;
int tileRow;
int tileColumn;
int globalRow;
int globalColumn;
int localRow;
int localColumn;
};
// A helper function for formatting the output.
void SetConsoleColor(int color) {
int colorValue = (color == 0) 4 : 2;
SetConsoleTextAttribute(GetStdHandle(STD_OUTPUT_HANDLE), colorValue);
}
// A helper function for formatting the output.
void SetConsoleSize(int height, int width) {
COORD coord;
coord.X = width;
coord.Y = height;
SetConsoleScreenBufferSize(GetStdHandle(STD_OUTPUT_HANDLE), coord);
SMALL_RECT* rect = new SMALL_RECT();
rect->Left = 0;
rect->Top = 0;
rect->Right = width;
rect->Bottom = height;
SetConsoleWindowInfo(GetStdHandle(STD_OUTPUT_HANDLE), true, rect);
}
// This method creates an 8x9 matrix of Description structures.
// In the call to parallel_for_each, the structure is updated
// with tile, global, and local indices.
void TilingDescription() {
// Create 72 (8x9) Description structures.
std::vector<Description> descs;
for (int i = 0; i < ROWS * COLS; i++) {
Description d = {i, 0, 0, 0, 0, 0, 0};
descs.push_back(d);
}
// Create an array_view from the Description structures.
extent<2> matrix(ROWS, COLS);
array_view<Description, 2> descriptions(matrix, descs);
// Update each Description with the tile, global, and local indices.
parallel_for_each(descriptions.extent.tile< 2, 3>(),
[=] (tiled_index< 2, 3> t_idx) restrict(amp)
{
descriptions[t_idx].globalRow = t_idx.global[0];
descriptions[t_idx].globalColumn = t_idx.global[1];
descriptions[t_idx].tileRow = t_idx.tile[0];
descriptions[t_idx].tileColumn = t_idx.tile[1];
descriptions[t_idx].localRow = t_idx.local[0];
descriptions[t_idx].localColumn= t_idx.local[1];
});
// Print out the Description structure for each element in the matrix.
// Tiles are displayed in red and green to distinguish them from each other.
SetConsoleSize(100, 150);
for (int row = 0; row < ROWS; row++) {
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Value: " << std::setw(2) << descriptions(row, column).value << " ";
}
std::cout << "\n";
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Tile: " << "(" << descriptions(row, column).tileRow << "," << descriptions(row, column).tileColumn << ") ";
}
std::cout << "\n";
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Global: " << "(" << descriptions(row, column).globalRow << "," << descriptions(row, column).globalColumn << ") ";
}
std::cout << "\n";
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Local: " << "(" << descriptions(row, column).localRow << "," << descriptions(row, column).localColumn << ") ";
}
std::cout << "\n";
std::cout << "\n";
}
}
int main() {
TilingDescription();
char wait;
std::cin >> wait;
}
Die Hauptarbeit des Beispiels steckt in der Definition des array_view-Objekts und im Aufruf von parallel_for_each.
Der Vektor der
Description-Strukturen wird in ein 8 x 9-array_view-Objekt kopiert.Die
parallel_for_each-Methode wird mit einemtiled_extent-Objekt als Berechnungsdomäne aufgerufen. Dastiled_extent-Objekt wird durch den Aufruf derextent::tile()-Methode derdescriptions-Variablen erstellt. Die Typparameter des Aufrufs vonextent::tile(),<2,3>geben an, dass 2 x 3 Kacheln erstellt werden. Daher wird die 8 x 9-Matrix in 12 Kacheln in vier Zeilen und drei Spalten unterteilt.Die
parallel_for_each-Methode wird aufgerufen, indem eintiled_index<2,3>-Objekt (t_idx) als Index verwendet wird. Die Typparameter des Index (t_idx) müssen den Typparametern der Berechnungsdomäne (descriptions.extent.tile< 2, 3>()) entsprechen.Beim Ausführen jedes Threads gibt der
t_idx-Index Informationen zurück, in welcher Unterteilung sich der Thread befindet (tiled_index::tile-Eigenschaft) und an welcher Position sich der Thread in der Kachel befindet (tiled_index::local-Eigenschaft).
Synchronisieren der Unterteilungen – „tile_static“ und „tile_barrier::wait“
Im vorherigen Beispiel wurde das Kachellayout und -indizes veranschaulicht, es ist jedoch nicht an sich sehr nützlich. Eine Unterteilung wird dann nützlich, wenn die Kacheln fest mit dem Algorithmus und den tile_static-Variablen verbunden sind. Da alle Threads in einer Kachel über Zugriff auf tile_static-Variablen verfügen, werden Aufrufe an tile_barrier::wait verwendet, um den Zugriff auf die Variablen tile_static zu synchronisieren. Obwohl alle Threads in einer Kachel Zugriff auf die tile_static-Variablen haben, gibt es keine festgelegte Reihenfolge der Ausführung der Threads in der Kachel. Das folgende Beispiel zeigt, wie tile_static-Variablen und die tile_barrier::wait-Methode verwendet werden, um den Durchschnittswert der einzelnen Kacheln zu berechnen. Die Schlüssel zum Verständnis des Beispiels sind:
Die rawData werden in einer 8 x 8-Matrix gespeichert.
Die Kachelgröße ist 2 x 2. Dies erstellt ein 4 x 4-Raster von Kacheln und die Durchschnittswerte können in einer 4 x 4-Matrix durch die Verwendung eines
array-Objekts gespeichert werden. Es gibt nur eine begrenzte Anzahl von Typen, die Sie als Verweis in einer eingeschränkten AMP-Funktion aufzeichnen können. Diearray-Klasse gehört dazu.Die Matrix- und Samplegrößen werden durch
#define-Anweisungen definiert, da die Typparameter vonarray,array_view,extentundtiled_indexkonstante Werte sein müssen. Sie können auchconst int static-Deklarationen verwenden. Ein weiterer Vorteil ist die Einfachheit des Änderns der Samplegröße, um den Durchschnittswert einer 4 x 4-Kachelgruppe zu berechnen.Ein 2 x 2-
tile_static-Array von Gleitkommawerten wird für jede Kachel deklariert. Obwohl die Deklaration im Codepfad für jeden Thread vorliegt, wird nur ein Array für jede Kachel in der Matrix erstellt.Es gibt eine Codezeile zum Kopieren der Werte in einer Kachel in das
tile_static-Array. Bei jedem Thread wird die Ausführung nach dem Kopieren des Werts in das Array aufgrund des Aufrufs vontile_barrier::waitunterbrochen.Wenn alle Threads in einer Kachel die Grenze erreicht haben, kann der Durchschnitt berechnet werden. Da der Code für jeden Thread ausgeführt wird, gibt es eine
if-Anweisung, den Durchschnittswert nur für einen Thread zu berechnen. Der Durchschnittswert wird in der entsprechenden Variable gespeichert. Die Grenze ist im Wesentlichen das Konstrukt, das Berechnungen einer Kachel durchführt, so wie Sie einefor-Schleife verwenden.Die Daten in der
averages-Variablen müssen auf den Host zurück kopiert werden, da es sich um einarray-Objekt handelt. Dieses Beispiel verwendet den Vektorkonvertierungsoperator.Im vollständigen Beispiel können Sie SAMPLESIZE bis auf 4 ändern und der Code wird ordnungsgemäß ohne andere Änderungen ausgeführt.
#include <iostream>
#include <amp.h>
using namespace concurrency;
#define SAMPLESIZE 2
#define MATRIXSIZE 8
void SamplingExample() {
// Create data and array_view for the matrix.
std::vector<float> rawData;
for (int i = 0; i < MATRIXSIZE * MATRIXSIZE; i++) {
rawData.push_back((float)i);
}
extent<2> dataExtent(MATRIXSIZE, MATRIXSIZE);
array_view<float, 2> matrix(dataExtent, rawData);
// Create the array for the averages.
// There is one element in the output for each tile in the data.
std::vector<float> outputData;
int outputSize = MATRIXSIZE / SAMPLESIZE;
for (int j = 0; j < outputSize * outputSize; j++) {
outputData.push_back((float)0);
}
extent<2> outputExtent(MATRIXSIZE / SAMPLESIZE, MATRIXSIZE / SAMPLESIZE);
array<float, 2> averages(outputExtent, outputData.begin(), outputData.end());
// Use tiles that are SAMPLESIZE x SAMPLESIZE.
// Find the average of the values in each tile.
// The only reference-type variable you can pass into the parallel_for_each call
// is a concurrency::array.
parallel_for_each(matrix.extent.tile<SAMPLESIZE, SAMPLESIZE>(),
[=, &averages] (tiled_index<SAMPLESIZE, SAMPLESIZE> t_idx) restrict(amp)
{
// Copy the values of the tile into a tile-sized array.
tile_static float tileValues[SAMPLESIZE][SAMPLESIZE];
tileValues[t_idx.local[0]][t_idx.local[1]] = matrix[t_idx];
// Wait for the tile-sized array to load before you calculate the average.
t_idx.barrier.wait();
// If you remove the if statement, then the calculation executes for every
// thread in the tile, and makes the same assignment to averages each time.
if (t_idx.local[0] == 0 && t_idx.local[1] == 0) {
for (int trow = 0; trow < SAMPLESIZE; trow++) {
for (int tcol = 0; tcol < SAMPLESIZE; tcol++) {
averages(t_idx.tile[0],t_idx.tile[1]) += tileValues[trow][tcol];
}
}
averages(t_idx.tile[0],t_idx.tile[1]) /= (float) (SAMPLESIZE * SAMPLESIZE);
}
});
// Print out the results.
// You cannot access the values in averages directly. You must copy them
// back to a CPU variable.
outputData = averages;
for (int row = 0; row < outputSize; row++) {
for (int col = 0; col < outputSize; col++) {
std::cout << outputData[row*outputSize + col] << " ";
}
std::cout << "\n";
}
// Output for SAMPLESIZE = 2 is:
// 4.5 6.5 8.5 10.5
// 20.5 22.5 24.5 26.5
// 36.5 38.5 40.5 42.5
// 52.5 54.5 56.5 58.5
// Output for SAMPLESIZE = 4 is:
// 13.5 17.5
// 45.5 49.5
}
int main() {
SamplingExample();
}
Racebedingungen
Es könnte verlockend sein, eine tile_static-Variable mit dem Namen total zu erstellen und diese Variable für jeden Thread so zu inkrementieren:
// Do not do this.
tile_static float total;
total += matrix[t_idx];
t_idx.barrier.wait();
averages(t_idx.tile[0],t_idx.tile[1]) /= (float) (SAMPLESIZE* SAMPLESIZE);
Das erste Problem mit diesem Ansatz ist, dass tile_static-Variablen keine Initialisierer haben können. Das zweite Problem besteht darin, dass eine Racebedingung für die Zuweisung zu total gibt, da alle Threads in der Kachel über Zugriff auf die Variable in keiner bestimmten Reihenfolge verfügen. Sie könnten einen Algorithmus programmieren, um nur einem einzelnen Thread bei jeder Grenze den Zugriff auf die Summe zu ermöglichen, wie als Nächstes gezeigt wird. Diese Projektmappe ist jedoch nicht erweiterbar.
// Do not do this.
tile_static float total;
if (t_idx.local[0] == 0&& t_idx.local[1] == 0) {
total = matrix[t_idx];
}
t_idx.barrier.wait();
if (t_idx.local[0] == 0&& t_idx.local[1] == 1) {
total += matrix[t_idx];
}
t_idx.barrier.wait();
// etc.
Arbeitsspeicher-Fences
Es gibt zwei Arten von Speicherzugriffen, die synchronisiert werden müssen: globale Speicherzugriffe und tile_static-Speicherzugriffe. Ein concurrency::array-Objekt belegt ausschließlich globalen Arbeitsspeicher. Ein concurrency::array_view kann auf globalen Arbeitsspeicher, tile_static-Arbeitsspeicher oder beide verweisen, abhängig von der Art der Erstellung. Es gibt zwei Arten von Arbeitsspeicher, die synchronisiert werden müssen:
globaler Arbeitsspeicher
tile_static
Ein Speicherzaun stellt sicher, dass Speicherzugriffe für andere Threads in der Threadkachel verfügbar sind und dass Speicherzugriffe gemäß der Programmreihenfolge ausgeführt werden. Um dies sicherzustellen, ordnen Compiler und Prozessoren die Lese- und Schreibzugriffe fenceübergreifend nicht neu. In C++ AMP wird ein Arbeitsspeicher-Fence durch einen Aufruf eine dieser Methoden erstellt:
tile_barrier::wait-Methode: Erstellt einen Zaun sowohl um den globalen als
tile_staticauch den Arbeitsspeicher.tile_barrier::wait_with_all_memory_fence-Methode: Erstellt einen Zaun um global und
tile_staticarbeitsspeicher.tile_barrier::wait_with_global_memory_fence-Methode: Erstellt einen Zaun nur um den globalen Speicher.
tile_barrier::wait_with_tile_static_memory_fence-Methode: Erstellt einen Zaun nur
tile_staticum den Arbeitsspeicher.
Das Aufrufen eines bestimmten von Ihnen benötigten Fence kann die Leistung Ihrer App verbessern. Der Grenztyp hat Auswirkungen auf die neue Anordnung von Anweisungen durch Compiler und Hardware. Wenn Sie beispielsweise einen globalen Arbeitsspeicher-Fence verwenden, gilt er nur für globale Speicherzugriffe und daher werden Compiler und Hardware möglicherweise Lese- und Schreibvorgänge in tile_static-Variablen auf beiden Seiten des Fence neu anordnen.
Im folgenden Beispiel synchronisiert die Grenze die Schreibvorgänge in tileValues, einer tile_static-Variable. In diesem Beispiel wird tile_barrier::wait_with_tile_static_memory_fence anstelle von tile_barrier::wait aufgerufen.
// Using a tile_static memory fence.
parallel_for_each(matrix.extent.tile<SAMPLESIZE, SAMPLESIZE>(),
[=, &averages] (tiled_index<SAMPLESIZE, SAMPLESIZE> t_idx) restrict(amp)
{
// Copy the values of the tile into a tile-sized array.
tile_static float tileValues[SAMPLESIZE][SAMPLESIZE];
tileValues[t_idx.local[0]][t_idx.local[1]] = matrix[t_idx];
// Wait for the tile-sized array to load before calculating the average.
t_idx.barrier.wait_with_tile_static_memory_fence();
// If you remove the if statement, then the calculation executes
// for every thread in the tile, and makes the same assignment to
// averages each time.
if (t_idx.local[0] == 0&& t_idx.local[1] == 0) {
for (int trow = 0; trow <SAMPLESIZE; trow++) {
for (int tcol = 0; tcol <SAMPLESIZE; tcol++) {
averages(t_idx.tile[0],t_idx.tile[1]) += tileValues[trow][tcol];
}
}
averages(t_idx.tile[0],t_idx.tile[1]) /= (float) (SAMPLESIZE* SAMPLESIZE);
}
});
Siehe auch
C++ AMP (C++ Accelerated Massive Parallelism)
tile_static-Schlüsselwort
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für