Exemplarische Vorgehensweise: Debuggen einer C++ AMP-Anwendung
In diesem Artikel wird veranschaulicht, wie Sie eine Anwendung debuggen, die C++ Accelerated Massive Parallelism (C++ AMP) verwendet, um die Grafikverarbeitungseinheit (GPU) zu nutzen. Es verwendet ein Parallel-Reduction-Programm, das ein großes Array von ganzen Zahlen summiert. In dieser exemplarischen Vorgehensweise werden die folgenden Aufgaben veranschaulicht:
- Starten des GPU-Debuggers.
- Überprüfen von GPU-Threads im GPU-Threads-Fenster.
- Verwenden des Fensters "Parallele Stapel" , um gleichzeitig die Aufrufstapel mehrerer GPU-Threads zu beobachten.
- Verwenden des Fensters " Parallele Überwachung ", um Werte eines einzelnen Ausdrucks über mehrere Threads gleichzeitig zu prüfen.
- Kennzeichnen, Einfrieren, Auftauen und Gruppieren von GPU-Threads
- Ausführen aller Threads einer Kachel an einer bestimmten Stelle im Code.
Voraussetzungen
Bevor Sie mit dieser exemplarischen Vorgehensweise beginnen:
Hinweis
C++AMP-Header sind ab Visual Studio 2022, Version 17.0, veraltet.
Wenn Alle AMP-Header eingeschlossen werden, werden Buildfehler generiert. Definieren Sie _SILENCE_AMP_DEPRECATION_WARNINGS , bevor Sie AMP-Header einschließen, um die Warnungen zu stillen.
- Read C++ AMP Overview.
- Stellen Sie sicher, dass Zeilennummern im Text-Editor angezeigt werden. Weitere Informationen finden Sie unter How to: Display line numbers in the editor.
- Stellen Sie sicher, dass Sie mindestens Windows 8 oder Windows Server 2012 ausführen, um das Debuggen im Softwareemulator zu unterstützen.
Hinweis
Auf Ihrem Computer werden möglicherweise andere Namen oder Speicherorte für die Benutzeroberflächenelemente von Visual Studio angezeigt als die in den folgenden Anweisungen aufgeführten. Diese Elemente sind von der jeweiligen Visual Studio-Version und den verwendeten Einstellungen abhängig. Weitere Informationen finden Sie unter Personalisieren der IDE.
So erstellen Sie das Beispielprojekt
Die Anweisungen zum Erstellen eines Projekts variieren je nachdem, welche Version von Visual Studio Sie verwenden. Stellen Sie sicher, dass die richtige Dokumentationsversion oberhalb des Inhaltsverzeichnisses auf dieser Seite ausgewählt ist.
So erstellen Sie das Beispielprojekt in Visual Studio
Klicken Sie in der Menüleiste auf Datei>Neu>Projekt, um das Dialogfeld Neues Projekt erstellen zu öffnen.
Legen Sie oben im Dialogfeld die Sprache auf C++, die Plattform auf Windows und den Projekttyp auf Konsole fest.
Wählen Sie aus der gefilterten Projekttypliste Konsolen-App aus, und klicken Sie auf Weiter. Geben Sie
AMPMapReduceauf der nächsten Seite das Feld "Name " ein, um einen Namen für das Projekt anzugeben, und geben Sie den Projektspeicherort an, wenn Sie einen anderen namen möchten.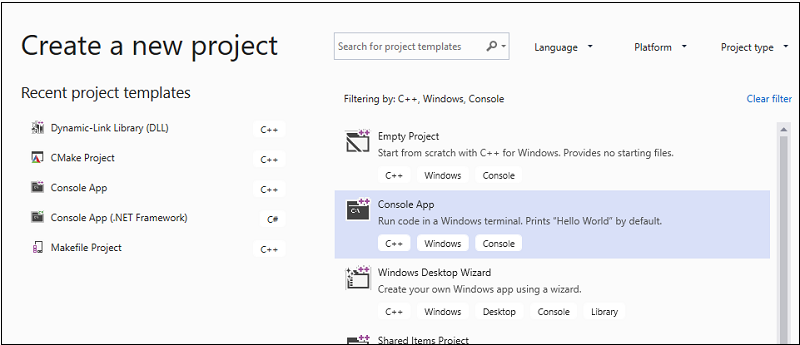
Klicken Sie auf die Schaltfläche Erstellen, um das Clientprojekt zu erstellen.
So erstellen Sie das Beispielprojekt in Visual Studio 2017 oder Visual Studio 2015
Starten Sie Visual Studio.
Klicken Sie in der Menüleiste auf Datei>Neu>Projekt.
Wählen Sie unter "Installiert " im Vorlagenbereich visual C++ aus.
Wählen Sie "Win32-Konsolenanwendung" aus, geben
AMPMapReduceSie das Feld "Name" ein, und wählen Sie dann die Schaltfläche "OK" aus.Klicken Sie auf Weiter.
Deaktivieren Sie das Kontrollkästchen "Vorkompilierte Kopfzeile ", und wählen Sie dann die Schaltfläche "Fertig stellen " aus.
Löschen Sie in Projektmappen-Explorer "stdafx.h", "targetver.h" und "stdafx.cpp" aus dem Projekt.
Weiter:
Öffnen Sie AMPMapReduce.cpp, und ersetzen Sie den Inhalt durch den folgenden Code.
// AMPMapReduce.cpp defines the entry point for the program. // The program performs a parallel-sum reduction that computes the sum of an array of integers. #include <stdio.h> #include <tchar.h> #include <amp.h> const int BLOCK_DIM = 32; using namespace concurrency; void sum_kernel_tiled(tiled_index<BLOCK_DIM> t_idx, array<int, 1> &A, int stride_size) restrict(amp) { tile_static int localA[BLOCK_DIM]; index<1> globalIdx = t_idx.global * stride_size; index<1> localIdx = t_idx.local; localA[localIdx[0]] = A[globalIdx]; t_idx.barrier.wait(); // Aggregate all elements in one tile into the first element. for (int i = BLOCK_DIM / 2; i > 0; i /= 2) { if (localIdx[0] < i) { localA[localIdx[0]] += localA[localIdx[0] + i]; } t_idx.barrier.wait(); } if (localIdx[0] == 0) { A[globalIdx] = localA[0]; } } int size_after_padding(int n) { // The extent might have to be slightly bigger than num_stride to // be evenly divisible by BLOCK_DIM. You can do this by padding with zeros. // The calculation to do this is BLOCK_DIM * ceil(n / BLOCK_DIM) return ((n - 1) / BLOCK_DIM + 1) * BLOCK_DIM; } int reduction_sum_gpu_kernel(array<int, 1> input) { int len = input.extent[0]; //Tree-based reduction control that uses the CPU. for (int stride_size = 1; stride_size < len; stride_size *= BLOCK_DIM) { // Number of useful values in the array, given the current // stride size. int num_strides = len / stride_size; extent<1> e(size_after_padding(num_strides)); // The sum kernel that uses the GPU. parallel_for_each(extent<1>(e).tile<BLOCK_DIM>(), [&input, stride_size] (tiled_index<BLOCK_DIM> idx) restrict(amp) { sum_kernel_tiled(idx, input, stride_size); }); } array_view<int, 1> output = input.section(extent<1>(1)); return output[0]; } int cpu_sum(const std::vector<int> &arr) { int sum = 0; for (size_t i = 0; i < arr.size(); i++) { sum += arr[i]; } return sum; } std::vector<int> rand_vector(unsigned int size) { srand(2011); std::vector<int> vec(size); for (size_t i = 0; i < size; i++) { vec[i] = rand(); } return vec; } array<int, 1> vector_to_array(const std::vector<int> &vec) { array<int, 1> arr(vec.size()); copy(vec.begin(), vec.end(), arr); return arr; } int _tmain(int argc, _TCHAR* argv[]) { std::vector<int> vec = rand_vector(10000); array<int, 1> arr = vector_to_array(vec); int expected = cpu_sum(vec); int actual = reduction_sum_gpu_kernel(arr); bool passed = (expected == actual); if (!passed) { printf("Actual (GPU): %d, Expected (CPU): %d", actual, expected); } printf("sum: %s\n", passed ? "Passed!" : "Failed!"); getchar(); return 0; }Klicken Sie in der Menüleiste auf Datei>Alle speichern.
Öffnen Sie in Projektmappen-Explorer das Kontextmenü für AMPMapReduce, und wählen Sie dann "Eigenschaften" aus.
Wählen Sie im Dialogfeld "Eigenschaftenseiten" unter "Konfigurationseigenschaften" die Option "C/C++>-Vorkompilierte Kopfzeilen" aus.
Wählen Sie für die Eigenschaft "Vorkompilierte Kopfzeilen " die Option "Keine vorkompilierten Kopfzeilen" aus, und klicken Sie dann auf die Schaltfläche "OK ".
Wählen Sie auf der Menüleiste Erstellen>Projektmappe erstellen aus.
Debuggen des CPU-Codes
In diesem Verfahren verwenden Sie den lokalen Windows-Debugger, um sicherzustellen, dass der CPU-Code in dieser Anwendung korrekt ist. Das Segment des CPU-Codes in dieser Anwendung, das besonders interessant ist, ist die for Schleife in der reduction_sum_gpu_kernel Funktion. Sie steuert die strukturbasierte parallele Reduzierung, die auf der GPU ausgeführt wird.
So debuggen Sie den CPU-Code
Öffnen Sie in Projektmappen-Explorer das Kontextmenü für AMPMapReduce, und wählen Sie dann "Eigenschaften" aus.
Wählen Sie im Dialogfeld "Eigenschaftenseiten" unter "Konfigurationseigenschaften" die Option "Debuggen" aus. Vergewissern Sie sich, dass der lokale Windows-Debugger in der Liste "Debugger zum Starten " ausgewählt ist.
Kehren Sie zum Code-Editor zurück.
Legen Sie Haltepunkte in den Codezeilen fest, die in der folgenden Abbildung dargestellt sind (etwa Zeilen 67 Zeile 70).

CPU-HaltepunkteKlicken Sie in der Menüleiste auf Debuggen>Debuggen starten.
Beobachten Sie im Fenster "Lokal" den Wert,
stride_sizebis der Haltepunkt in Zeile 70 erreicht ist.Klicken Sie in der Menüleiste auf Debuggen>Debuggen beenden aus.
Debuggen des GPU-Codes
In diesem Abschnitt wird gezeigt, wie Sie den GPU-Code debuggen, bei dem es sich um den code handelt, der in der sum_kernel_tiled Funktion enthalten ist. Der GPU-Code berechnet die Summe der ganzen Zahlen für jeden "Block" parallel.
So debuggen Sie den GPU-Code
Öffnen Sie in Projektmappen-Explorer das Kontextmenü für AMPMapReduce, und wählen Sie dann "Eigenschaften" aus.
Wählen Sie im Dialogfeld "Eigenschaftenseiten" unter "Konfigurationseigenschaften" die Option "Debuggen" aus.
Wählen Sie in der Liste Zu startender Debugger die Option Lokaler Windows-Debugger aus.
Überprüfen Sie in der Liste "Debuggertyp ", ob "Auto" ausgewählt ist.
Auto ist der Standardwert. In Versionen vor Windows 10 ist GPU nur der erforderliche Wert anstelle von Auto.
Klicken Sie auf die Schaltfläche OK .
Legen Sie einen Haltepunkt in Zeile 30 fest, wie in der folgenden Abbildung dargestellt.

GPU-HaltepunktKlicken Sie in der Menüleiste auf Debuggen>Debuggen starten. Die Haltepunkte im CPU-Code in den Zeilen 67 und 70 werden während des GPU-Debuggings nicht ausgeführt, da diese Codezeilen auf der CPU ausgeführt werden.
So verwenden Sie das GPU-Threads-Fenster
Um das Fenster "GPU-Threads" zu öffnen, wählen Sie auf der Menüleiste "Windows-GPU-Threads> debuggen">aus.
Sie können den Zustand der GPU-Threads im angezeigten GPU-Threads-Fenster überprüfen.
Docken Sie das FENSTER "GPU-Threads " am unteren Rand von Visual Studio an. Wählen Sie die Schaltfläche "Threadwechsel erweitern" aus, um die Kachel- und Threadtextfelder anzuzeigen. Das Fenster "GPU-Threads " zeigt die Gesamtanzahl der aktiven und blockierten GPU-Threads an, wie in der folgenden Abbildung dargestellt.

Fenster GPU-Threads313 Kacheln werden für diese Berechnung zugewiesen. Jede Kachel enthält 32 Threads. Da das lokale GPU-Debugging in einem Softwareemulator auftritt, gibt es vier aktive GPU-Threads. Die vier Threads führen die Anweisungen gleichzeitig aus und fahren dann mit der nächsten Anweisung fort.
Im Fenster "GPU-Threads" sind vier GPU-Threads aktiv und 28 GPU-Threads an der tile_barrier::wait-Anweisung blockiert, die in etwa zeile 21 (
t_idx.barrier.wait();) definiert ist. Alle 32 GPU-Threads gehören zur ersten Kachel.tile[0]Ein Pfeil zeigt auf die Zeile, die den aktuellen Thread enthält. Verwenden Sie eine der folgenden Methoden, um zu einem anderen Thread zu wechseln:Öffnen Sie in der Zeile für den Thread, zu dem im FENSTER GPU-Threads gewechselt werden soll, das Kontextmenü, und wählen Sie " Zu Thread wechseln" aus. Wenn die Zeile mehr als einen Thread darstellt, wechseln Sie entsprechend den Threadkoordinaten zum ersten Thread.
Geben Sie die Kachel- und Threadwerte des Threads in die entsprechenden Textfelder ein, und wählen Sie dann die Schaltfläche "Thread wechseln" aus.
Im Fenster "Aufrufstapel" wird der Aufrufstapel des aktuellen GPU-Threads angezeigt.
So verwenden Sie das Fenster "Parallele Stapel"
Um das Fenster "Parallele Stapel" zu öffnen, wählen Sie auf der Menüleiste "Windows>Parallel Stacks debuggen>" aus.
Sie können das Fenster "Parallele Stapel" verwenden, um die Stapelframes mehrerer GPU-Threads gleichzeitig zu prüfen.
Andocken Sie das Fenster "Parallele Stapel" am unteren Rand von Visual Studio.
Stellen Sie sicher, dass Threads in der Liste in der oberen linken Ecke ausgewählt sind. In der folgenden Abbildung zeigt das Fenster "Parallele Stapel" eine aufrufstapelorientierte Ansicht der GPU-Threads, die Sie im Fenster "GPU-Threads " gesehen haben.

Fenster Parallele Stapel32 Threads gingen von
_kernel_stubder Lambda-Anweisung imparallel_for_eachFunktionsaufruf und dann zursum_kernel_tiledFunktion, wo die parallele Reduzierung auftritt. 28 von den 32 Threads sind zu dertile_barrier::waitAnweisung vorangekommen und wieder Standard an Zeile 22 blockiert, während die anderen vier Threads wieder Standard in dersum_kernel_tiledFunktion in Zeile 30 aktiv sind.Sie können die Eigenschaften eines GPU-Threads überprüfen. Sie sind im Fenster "GPU-Threads" in der umfangreichen Dateninfo des Fensters "Parallele Stapel" verfügbar. Um sie anzuzeigen, zeigen Sie mit dem Mauszeiger auf den Stapelrahmen von
sum_kernel_tiled. Die folgende Abbildung zeigt die Dateninfo.
GPU-Thread-DateninfoWeitere Informationen zum Fenster "Parallele Stapel" finden Sie unter Verwenden des Fensters "Parallele Stapel".
So verwenden Sie das Fenster "Parallele Überwachung"
Um das Fenster "Parallele Überwachung" zu öffnen, wählen Sie auf der Menüleiste "Parallel Watch>1 debuggen">>aus.
Sie können das Fenster "Parallele Überwachung " verwenden, um die Werte eines Ausdrucks über mehrere Threads zu prüfen.
Docken Sie das Fenster "Parallel Watch 1 " am unteren Rand von Visual Studio an. Es gibt 32 Zeilen in der Tabelle des Fensters "Parallele Überwachung ". Jedes entspricht einem GPU-Thread, der sowohl im Fenster "GPU-Threads" als auch im Fenster "Parallele Stapel" angezeigt wurde. Jetzt können Sie Ausdrücke eingeben, deren Werte Sie über alle 32 GPU-Threads prüfen möchten.
Wählen Sie die Spaltenüberschrift "Überwachung hinzufügen", geben Sie
localIdxdie EINGABETASTE ein, und wählen Sie dann die EINGABETASTE aus.Wählen Sie die Spaltenüberschrift "Überwachung hinzufügen" erneut aus, geben
globalIdxSie ein, und wählen Sie dann die EINGABETASTE aus.Wählen Sie die Spaltenüberschrift "Überwachung hinzufügen" erneut aus, geben
localA[localIdx[0]]Sie ein, und wählen Sie dann die EINGABETASTE aus.Sie können nach einem angegebenen Ausdruck sortieren, indem Sie die entsprechende Spaltenüberschrift auswählen.
Wählen Sie die localA[localIdx[0]] Spaltenüberschrift aus, um die Spalte zu sortieren. Die folgende Abbildung zeigt die Ergebnisse der Sortierung nach localA[localIdx[0]].

SortierergebnisseSie können den Inhalt im Fenster "Parallele Überwachung" nach Excel exportieren, indem Sie dieExcel-Schaltfläche und dann "In Excel öffnen" auswählen. Wenn Excel auf Ihrem Entwicklungscomputer installiert ist, öffnet die Schaltfläche ein Excel-Arbeitsblatt, das den Inhalt enthält.
In der oberen rechten Ecke des Fensters "Parallele Überwachung " gibt es ein Filtersteuerelement, mit dem Sie den Inhalt mithilfe von booleschen Ausdrücken filtern können. Geben Sie
localA[localIdx[0]] > 20000das Textfeld des Filtersteuerelements ein, und wählen Sie dann die EINGABETASTE aus.Das Fenster enthält jetzt nur Threads, auf denen der
localA[localIdx[0]]Wert größer als 20000 ist. Der Inhalt wird weiterhin nach derlocalA[localIdx[0]]Spalte sortiert, bei der es sich um die zuvor ausgewählte Sortieraktion handelt.
Kennzeichnen von GPU-Threads
Sie können bestimmte GPU-Threads markieren, indem Sie sie im FENSTER "GPU-Threads", im Fenster "Parallele Überwachung" oder "Dateninfo" im Fenster "Parallele Stapel" kennzeichnen. Wenn eine Zeile im GPU-Threads-Fenster mehr als einen Thread enthält, kennzeichnet diese Zeile alle Threads, die in der Zeile enthalten sind.
So kennzeichnen Sie GPU-Threads
Wählen Sie die Spaltenüberschrift [Thread] im Fenster Parallel Watch 1 aus, um nach Kachelindex und Threadindex zu sortieren.
Wählen Sie auf der Menüleiste "Debug>Continue" aus, wodurch die vier Threads, die aktiv waren, zur nächsten Barriere wechseln (definiert in Zeile 32 von AMPMapReduce.cpp).
Wählen Sie das Kennzeichnungssymbol auf der linken Seite der Zeile aus, das die vier threads enthält, die jetzt aktiv sind.
Die folgende Abbildung zeigt die vier aktiven gekennzeichneten Threads im GPU-Threads-Fenster .

Aktive Threads im GPU-ThreadfensterDas Fenster "Parallele Überwachung " und die Dateninfo des Fensters "Parallele Stapel" geben beide die gekennzeichneten Threads an.
Wenn Sie sich auf die vier von Ihnen gekennzeichneten Threads konzentrieren möchten, können Sie auswählen, dass nur die gekennzeichneten Threads angezeigt werden. Sie schränkt die Anzeige in den GPU-Threads, parallelen Überwachungs- und Parallelstapelfenstern ein.
Wählen Sie die Schaltfläche "Nur anzeigen" in einem der Fenster oder auf der Symbolleiste "Debugspeicherort " aus. Die folgende Abbildung zeigt die Schaltfläche "Nur gekennzeichnet anzeigen" auf der Symbolleiste "Debugspeicherort ".

Schaltfläche "Nur gekennzeichnet" anzeigenJetzt werden in den Fenstern GPU-Threads, parallele Überwachung und parallele Stapel nur die gekennzeichneten Threads angezeigt.
Einfrieren und Auftauen von GPU-Threads
Sie können GPU-Threads aus dem FENSTER "GPU-Threads" oder aus dem Fenster "Parallele Überwachung" fixieren (anhalten) und "Schleppen" (Fortsetzen) von GPU-Threads fixieren. Sie können CPU-Threads auf die gleiche Weise fixieren und abtauen. Weitere Informationen finden Sie unter How to: Use the Threads Window.
So fixieren und tauen Sie GPU-Threads
Wählen Sie die Schaltfläche "Nur gekennzeichnet anzeigen" aus, um alle Threads anzuzeigen.
Wählen Sie auf der Menüleiste "Debug>Continue" aus.
Öffnen Sie das Kontextmenü für die aktive Zeile, und wählen Sie dann "Fixieren" aus.
Die folgende Abbildung des GPU-Threads-Fensters zeigt, dass alle vier Threads fixiert sind.

Fixierte Threads im GPU-Threads-FensterEbenso zeigt das Fenster "Parallele Überwachung " an, dass alle vier Threads fixiert sind.
Wählen Sie auf der Menüleiste "Debuggen>fortsetzen" aus, damit die nächsten vier GPU-Threads an der Barriere in Zeile 22 vorbeikommen und den Haltepunkt in Zeile 30 erreichen können. Das Fenster "GPU-Threads" zeigt, dass die vier zuvor fixierten Threads erneut fixiert sind Standard fixiert und im aktiven Zustand.
Wählen Sie auf der Menüleiste " Debuggen" aus, "Weiter".
Im Fenster "Parallele Überwachung" können Sie auch einzelne oder mehrere GPU-Threads auftauen.
So gruppieren Sie GPU-Threads
Wählen Sie im Kontextmenü für einen der Threads im FENSTER "GPU-Threads " die Option "Gruppieren nach", "Adresse" aus.
Die Threads im FENSTER "GPU-Threads " werden nach Adresse gruppiert. Die Adresse entspricht der Anweisung bei der Demontage, in der sich jede Gruppe von Threads befindet. 24 Threads befinden sich in Zeile 22, wobei die tile_barrier::wait-Methode ausgeführt wird. 12 Threads befinden sich an der Anweisung für die Barriere in Zeile 32. Vier dieser Threads werden gekennzeichnet. Acht Threads befinden sich am Haltepunkt in Zeile 30. Vier dieser Threads sind fixiert. Die folgende Abbildung zeigt die gruppierten Threads im GPU-Threads-Fenster .

Gruppierte Threads im GPU-Threads-FensterSie können den Vorgang "Gruppieren nach " auch ausführen, indem Sie das Kontextmenü für das Datenraster des Parallel Watch-Fensters öffnen. Wählen Sie "Gruppieren nach" und dann das Menüelement aus, das der Gruppieren der Threads entspricht.
Ausführen aller Threads an einer bestimmten Position im Code
Sie führen alle Threads in einer bestimmten Kachel mit der Zeile aus, die den Cursor enthält, mithilfe des Cursors "Aktuelle Kachel an Cursor ausführen".
So führen Sie alle Threads an der Position aus, die vom Cursor markiert ist
Wählen Sie im Kontextmenü für die fixierten Threads "Thaw" aus.
Setzen Sie im Code-Editor den Cursor in Zeile 30.
Wählen Sie im Kontextmenü für den Code-Editor die Option "Aktuelle Kachel an Cursor ausführen" aus.
Die 24 Threads, die zuvor an der Barriere in Zeile 21 blockiert wurden, sind in Zeile 32 vorangekommen. Sie wird im FENSTER "GPU-Threads " angezeigt.
Siehe auch
Übersicht über C++ AMP
Debuggen von GPU-Code
Gewusst wie: Verwenden des Fensters „GPU-Threads“
How to: Verwenden des Fensters „Parallele Überwachung“
Analysieren von C++-AMP-Code mit der Parallelitätsschnellansicht
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für