INDEX
Gilt für:![]() Berechnete Spalte
Berechnete Spalte![]() Berechnete Tabelle
Berechnete Tabelle![]() Measure
Measure![]() Visuelle Berechnung
Visuelle Berechnung
Gibt eine Zeile an einer absoluten Position (angegeben durch den Positionsparameter) innerhalb der angegebenen Partition zurück, sortiert nach der angegebenen Reihenfolge. Falls die aktuelle Partition nicht zu einer einzigen Partition deduziert werden kann, werden möglicherweise mehrere Zeilen zurückgegeben.
Syntax
INDEX(<position>[, <relation> or <axis>][, <orderBy>][, <blanks>][, <partitionBy>][, <matchBy>][, <reset>] )
Parameter
| Begriff | Definition |
|---|---|
| position | Die absolute Position (mit Basis 1), von der aus die Daten bezogen werden sollen: – <position> ist positiv: 1 ist die erste Zeile, 2 ist die zweite Zeile usw. – <position> ist negativ: -1 ist die letzte Zeile, -2 ist die vorletzte Zeile usw. Wenn <position> außerhalb der Begrenzung liegt oder 0 oder BLANK() entspricht, gibt INDEX eine leere Tabelle zurück. Hierbei kann es sich um einen beliebigen DAX-Ausdruck handeln, der einen Skalarwert zurückgibt. |
| relation | (Optional) Ein Tabellenausdruck, über den die Ausgabe zurückgegeben wird. Wenn angegeben, müssen alle Spalten in <partitionBy> von dort oder aus einer zugehörigen Tabelle stammen. Bei Auslassung: – <orderBy> muss explizit angegeben werden. – Alle <orderBy>- und <partitionBy>-Ausdrücke müssen vollqualifizierte Spaltennamen sein und aus einer einzigen Tabelle stammen. – Für alle Spalten in <orderBy> und <partitionBy> wird standardmäßig ALLSELECTED() verwendet. |
| Achse | (Optional) Eine Achse in der visuellen Form. Nur in visuellen Berechnungen verfügbar und ersetzt <relation>. |
| orderBy | (Optional) Eine ORDERBY()-Klausel mit den Ausdrücken, die definieren, wie jede Partition sortiert wird. Bei Auslassung: – <relation> muss explizit angegeben werden. – Standardmäßig erfolgt die Sortierung nach jeder Spalte in <relation>, die nicht bereits in <partitionBy> angegeben ist. |
| Leerzeichen | (Optional) Eine Enumeration, die definiert, wie leere Werte beim Sortieren behandelt werden. Dieser Parameter ist für die zukünftige Verwendung reserviert. Derzeit ist der einzige unterstützte Wert DEFAULT, wobei das Verhalten für numerische Werte darin besteht, dass leere Werte zwischen 0 und negativen Werten angeordnet werden. Bei Zeichenfolgen werden leere Werte vor allen anderen Zeichenfolgen angeordnet, einschließlich leerer Zeichenfolgen. |
| partitionBy | (Optional) Eine PARTITIONBY()-Klausel mit Spalten, die definieren, wie <relation> partitioniert wird. Bei Auslassung wird <relation> als eine einzelne Partition behandelt. |
| matchBy | (Optional) Eine MATCHBY()-Klausel, die die Spalten enthält, die definieren, wie Daten abgeglichen werden und die aktuelle Zeile identifiziert wird. |
| reset | (Optional) Nur in visuellen Berechnungen verfügbar. Gibt an, ob die Berechnung zurückgesetzt wird und auf welcher Ebene der Spaltenhierarchie der visuellen Form. Akzeptierte Werte sind: NONE, LOWESTPARENT, HIGHESTPARENT oder ein Integer. Das Verhalten hängt vom Integervorzeichen ab: – Wenn null oder ausgelassen, wird die Berechnung nicht zurückgesetzt. Gleichbedeutend mit NONE. – Wenn der Integer positiv ist, identifiziert er die Spalte beginnend mit dem höchsten Wert, unabhängig vom Aggregationsintervall. HIGHESTPARENT entspricht 1. – Wenn der Integer negativ ist, identifiziert er die Spalte beginnend mit dem niedrigsten Wert, relativ zum aktuellen Aggregationsintervall. LOWESTPARENT entspricht -1. |
Rückgabewert
Eine Zeile an einer absoluten Position.
Bemerkungen
Jede <partitionBy> und <matchBy>-Spalte muss einen entsprechenden äußeren Wert aufweisen, um die aktuelle Partition zu definieren, die verarbeitet werden soll. Dies geschieht durch das folgende Verhalten:
- Wenn es genau eine entsprechende äußere Spalte gibt, wird deren Wert verwendet.
- Wenn keine entsprechende äußere Spalte vorhanden ist, lautet das Vorgehen wie folgt:
- INDEX ermittelt zunächst alle <partitionBy>- und <matchBy>Spalten, die nicht über eine entsprechende äußere Spalte verfügen.
- Für jede Kombination vorhandener Werte für diese Spalten im übergeordneten Kontext von INDEX wird INDEX ausgewertet, und es wird eine Zeile zurückgegeben.
- Die endgültige Ausgabe von INDEX ist eine Vereinigung dieser Zeilen.
- Wenn es mehr als eine entsprechende äußere Spalte gibt, wird ein Fehler zurückgegeben.
Wenn <matchBy> vorhanden ist, versucht INDEX, die Spalten <matchBy> und <partitionBy> zu verwenden, um die Zeile zu identifizieren.
Wenn <matchBy> nicht vorhanden ist, und die in <orderBy> und <partitionBy> angegebenen Spalten nicht jede Zeile in <relation> eindeutig identifizieren können, gilt Folgendes:
- INDEX versucht, die kleinstmögliche Anzahl zusätzlicher Spalten zu finden, die zur eindeutigen Identifizierung jeder Zeile erforderlich sind.
- Wenn solche Spalten gefunden werden, fügt INDEX diese neuen Spalten automatisch an <orderBy> an, und jede Partition wird anhand dieses neuen Satzes von orderBy-Spalten sortiert.
- Wenn keine solchen Spalten gefunden werden, wird ein Fehler zurückgegeben.
In den folgenden Fällen wird eine leere Tabelle zurückgegeben:
- In <relation> ist kein entsprechender äußerer Wert einer PartitionBy-Spalte vorhanden.
- Der <position>-Wert bezieht sich auf eine Position, die innerhalb der Partition nicht vorhanden ist.
Wenn INDEX innerhalb einer berechneten Spalte verwendet wird, die in derselben Tabelle wie <relation> definiert ist, und <orderBy> nicht angegeben ist, wird ein Fehler zurückgegeben.
<reset> kann nur in visuellen Berechnungen verwendet werden und kann nicht in Kombination mit <orderBy> oder <partitionBy> verwendet werden. Wenn <reset> vorhanden ist, kann <axis> angegeben werden, aber <relation> kann nicht angegeben werden.
Beispiel 1 – berechnete Spalte
Die folgende DAX-Abfrage:
EVALUATE INDEX(1, ALL(DimDate[CalendarYear]))
Gibt die folgende Tabelle zurück:
| DimDate[CalendarYear] |
|---|
| 2005 |
Beispiel 2 – berechnete Spalte
Die folgende DAX-Abfrage:
EVALUATE
SUMMARIZECOLUMNS (
FactInternetSales[ProductKey],
DimDate[MonthNumberOfYear],
FILTER (
VALUES(FactInternetSales[ProductKey]),
[ProductKey] < 222
),
"CurrentSales", SUM(FactInternetSales[SalesAmount]),
"LastMonthSales",
CALCULATE (
SUM(FactInternetSales[SalesAmount]),
INDEX(-1, ORDERBY(DimDate[MonthNumberOfYear]))
)
)
ORDER BY [ProductKey], [MonthNumberOfYear]
Gibt die folgende Tabelle zurück:
| FactInternetSales[ProductKey] | DimDate[MonthNumberOfYear] | [CurrentSales] | [LastMonthSales] |
|---|---|---|---|
| 214 | 1 | 5423.45 | 8047.7 |
| 214 | 2 | 4968.58 | 8047.7 |
| 214 | 3 | 5598.4 | 8047.7 |
| 214 | 4 | 5073.55 | 8047.7 |
| 214 | 5 | 5248.5 | 8047.7 |
| 214 | 6 | 7487.86 | 8047.7 |
| 214 | 7 | 7382.89 | 8047.7 |
| 214 | 8 | 6543.13 | 8047.7 |
| 214 | 9 | 6788.06 | 8047.7 |
| 214 | 10 | 6858.04 | 8047.7 |
| 214 | 11 | 8607.54 | 8047.7 |
| 214 | 12 | 8047.7 | 8047.7 |
| 217 | 1 | 5353.47 | 7767.78 |
| 217 | 2 | 4268.78 | 7767.78 |
| 217 | 3 | 5773.35 | 7767.78 |
| 217 | 4 | 5738.36 | 7767.78 |
| 217 | 5 | 6158.24 | 7767.78 |
| 217 | 6 | 6998 | 7767.78 |
| 217 | 7 | 5563.41 | 7767.78 |
| 217 | 8 | 5913.31 | 7767.78 |
| 217 | 9 | 5913.31 | 7767.78 |
| 217 | 10 | 6823.05 | 7767.78 |
| 217 | 11 | 6683.09 | 7767.78 |
| 217 | 12 | 7767.78 | 7767.78 |
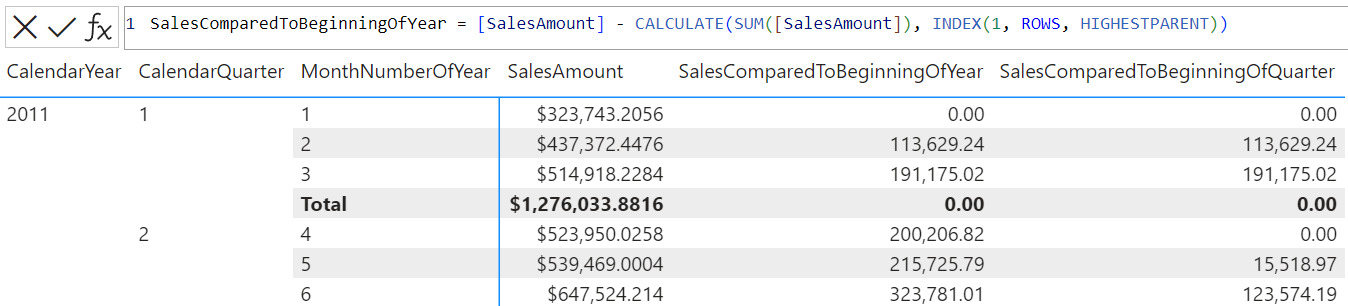
Beispiel 3 – visuelle Berechnung
Die folgenden DAX-Abfragen für die visuelle Berechnung:
SalesComparedToBeginningOfYear = [SalesAmount] - CALCULATE(SUM([SalesAmount]), INDEX(1, ROWS, HIGHESTPARENT))
SalesComparedToBeginningOfQuarter = [SalesAmount] - CALCULATE(SUM([SalesAmount]), INDEX(1, , -1))
erweitern eine Tabelle so, dass sie für jeden Monat enthält: – die Gesamtsumme der Verkäufe; – die Differenz zum ersten Monat des jeweiligen Jahres; – und die Differenz zum ersten Monat des jeweiligen Quartals.
Der folgende Screenshot zeigt die visuelle Matrix und den ersten Ausdruck der visuellen Berechnung:
Zugehöriger Inhalt
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für