Anwendungsresilienzmuster
Tipp
Diese Inhalte sind ein Auszug aus dem E-Book „Architecting Cloud Native .NET Applications for Azure“, verfügbar in der .NET-Dokumentation oder als kostenlos herunterladbare PDF-Datei, die offline gelesen werden kann.

Die Anwendungsresilienz bildet die erste Verteidigungslinie.
Sie könnten zwar viel Zeit in die Entwicklung eines eigenen Resilienzframeworks investieren, aber solche Produkte sind bereits vorhanden. Polly ist eine umfassende .NET-Bibliothek für Resilienz und die Behandlung von vorübergehenden Fehlern, mit deren Hilfe Entwickler Resilienzrichtlinien reibungslos und threadsicher formulieren können. Polly zielt auf Anwendungen ab, die mit .NET Framework oder .NET 7 entwickelt wurden. Die folgende Tabelle beschreibt die in der Polly-Bibliothek verfügbaren Resilienzfunktionen, bezeichnet als policies. Sie können einzeln oder in Gruppen angewendet werden.
| Policy | Erfahrung |
|---|---|
| Erneut versuchen | Konfiguriert die Wiederholungsversuche für festgelegte Vorgänge. |
| Trennschalter | Blockiert angeforderte Vorgänge für einen vordefinierten Zeitraum, wenn Fehler einen konfigurierten Schwellenwert überschreiten. |
| Timeout | Begrenzt die Dauer, die ein Aufrufer auf eine Antwort warten kann. |
| Bulkhead | Beschränkt Aktionen auf einen Ressourcenpool fester Größe, um zu verhindern, dass fehlgeschlagene Aufrufe eine Ressource überlasten. |
| cache | Speichert Antworten automatisch. |
| Fallback | Definiert das strukturierte Verhalten bei einem Fehler. |
Hinweis: In der obigen Abbildung werden die Resilienzrichtlinien unabhängig davon auf Anforderungsnachrichten angewendet, ob diese von einem externen Client oder einem Back-End-Dienst stammen. Das Ziel besteht darin, die Anforderung für einen Dienst zu kompensieren, der möglicherweise vorübergehend nicht zur Verfügung steht. Diese kurzzeitigen Unterbrechungen äußern sich in der Regel durch die in der folgenden Tabelle aufgeführten HTTP-Statuscodes.
| HTTP-Statuscode | Ursache |
|---|---|
| 404 | Nicht gefunden |
| 408 | Anforderungszeitlimit |
| 429 | Zu viele Anforderungen (wahrscheinlich erfolgt eine Drosselung) |
| 502 | Ungültiger Gateway |
| 503 | Dienst nicht verfügbar |
| 504 | Gatewaytimeout |
Frage: Würden Sie einen Vorgang wiederholen, für den HTTP-Statuscode 403 (Verboten) ausgegeben wird? Nein. In diesem Fall arbeitet das System ordnungsgemäß, teilt dem Aufrufer jedoch mit, dass keine Berechtigung zur Durchführung des angeforderten Vorgangs vorliegt. Es muss darauf geachtet werden, nur solche Vorgänge zu wiederholen, die durch Fehler verursacht wurden.
Wie in Kapitel 1 empfohlen, sollten Microsoft-Entwickler cloudnative Anwendungen für die .NET-Plattform entwickeln. Mit Version 2.1 wurde die Bibliothek HTTPClientFactory zur Erstellung von HTTP-Clientinstanzen für die Interaktion mit URL-basierten Ressourcen eingeführt. Die Factory-Klasse, die die ursprüngliche HTTPClient-Klasse ersetzt, unterstützt viele erweiterte Funktionen, unter anderem eine enge Integration in die Polly-Resilienzbibliothek. Damit können Sie in der Startup-Klasse der Anwendung ganz einfach Resilienzrichtlinien definieren, um partielle Ausfälle und Konnektivitätsprobleme zu behandeln.
Als Nächstes gehen wir auf die Retry- und Circuit Breaker-Muster ein.
Wiederholungsmuster
In einer verteilten cloudnativen Umgebung können Aufrufe von Diensten und Cloudressourcen aufgrund vorübergehender (kurzzeitiger) Fehler fehlschlagen, die in der Regel nach einer kurzen Zeitspanne automatisch behoben werden. Die Implementierung einer Wiederholungsstrategie unterstützt einen cloudnativen Dienst dabei, diese Szenarien zu entschärfen.
Das Retry-Muster (Wiederholungsmuster) ermöglicht es einem Dienst, für eine fehlgeschlagene Anforderung eine (konfigurierbare) Anzahl von Wiederholungsversuchen mit einer exponentiell ansteigenden Wartezeit auszuführen. Abbildung 6-2 zeigt einen Wiederholungsversuch in Aktion.
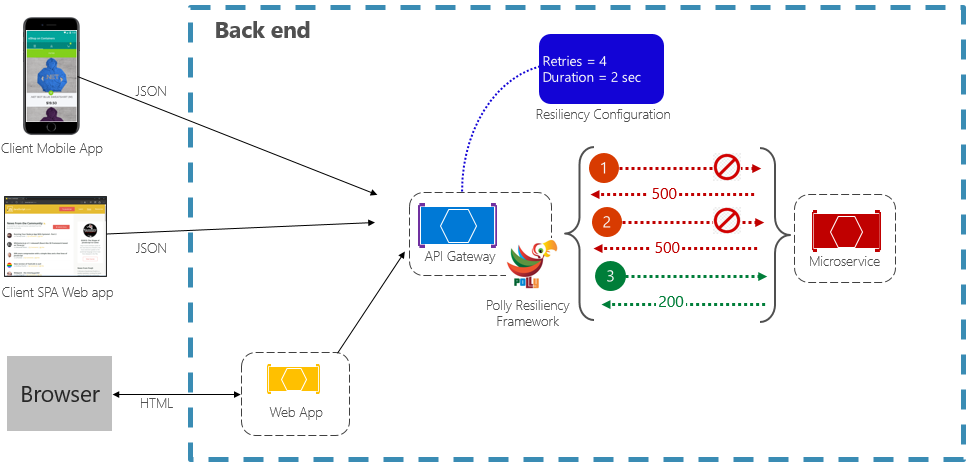
Abbildung 6-2. Retry-Muster in Aktion
In der obigen Abbildung wurde ein Wiederholungsmuster für einen Anforderungsvorgang implementiert. Er ist so konfiguriert, dass bis zu vier Wiederholungsversuche zugelassen werden, bevor ein Fehler auftritt. Das Backoffintervall (Wartezeit) beginnt bei zwei Sekunden und verdoppelt sich exponentiell für jeden weiteren Versuch.
- Der erste Aufruf schlägt fehl und gibt den HTTP-Statuscode 500 zurück. Die Anwendung wartet zwei Sekunden lang und wiederholt den Aufruf.
- Der zweite Aufruf schlägt ebenfalls fehl und gibt den HTTP-Statuscode 500 zurück. Die Anwendung verdoppelt nun das Backoffintervall auf vier Sekunden und wiederholt den Aufruf.
- Der dritte Aufruf ist schließlich erfolgreich.
- In diesem Szenario können bis zu vier Wiederholungsversuche bei gleichzeitiger Verdopplung der Backoffdauer durchgeführt werden, bevor der Aufruf als fehlgeschlagen eingestuft wird.
- Wenn auch der 4. Wiederholungsversuch erfolglos bleibt, wird eine Fallbackrichtlinie aufgerufen, um das Problem ordnungsgemäß zu lösen.
Es ist wichtig, vor einem erneuten Aufruf den Backoffzeitraum zu erhöhen, damit der Dienst Zeit zur Selbstkorrektur erhält. Es empfiehlt sich, ein exponentiell ansteigendes Backoff zu implementieren (Verdoppelung des Zeitraums bei jedem Wiederholungsversuch), um eine angemessene Korrekturzeit zu ermöglichen.
Muster „Trennschalter“
Das Wiederholungsmuster kann zur erfolgreichen Ausführung von Anforderungen beitragen, die von einem Teilausfall betroffen sind. Es gibt jedoch Situationen, in denen Ausfälle durch unvorhergesehene Ereignisse verursacht werden, deren Behebung längere Zeit in Anspruch nimmt. Zu unterscheiden sind unterschiedliche Schweregrade, die von einem Teilverlust der Konnektivität bis hin zum vollständigen Ausfall des Diensts reichen können. In diesen Situationen ist es nicht sinnvoll, dass die Anwendung fortlaufend einen Vorgang wiederholt, dessen Erfolg unwahrscheinlich ist.
Erschwerend kommt hinzu, dass die fortgesetzte Ausführung von Wiederholungsversuchen bei einem nicht reagierenden Dienst zu einem selbstverschuldeten Denial-of-Service-Szenario führen kann: Sie überfluten Ihren Dienst mit fortwährenden Aufrufen, durch die Ressourcen wie Arbeitsspeicher, Threads und Datenbankverbindungen erschöpft werden. Dies wiederum kann zu Ausfällen in nicht verwandten Teilen des Systems führen, die dieselben Ressourcen nutzen.
In solchen Situationen wäre es sinnvoller, den Vorgang sofort als fehlgeschlagen einzustufen und den Dienst nur dann aufzurufen, wenn eine Aussicht auf Erfolg besteht.
Das Circuit Breaker-Muster kann eine Anwendung an der wiederholten Ausführung eines Vorgangs hindern, der höchstwahrscheinlich fehlschlagen wird. Nach einer vordefinierten Anzahl fehlgeschlagener Aufrufe wird der gesamte Datenverkehr an diesen Dienst blockiert. In regelmäßigen Abständen wird mithilfe eines Testaufrufs ermittelt, ob der Fehler behoben wurde. Abbildung 6-3 zeigt das Circuit Breaker-Muster in Aktion.
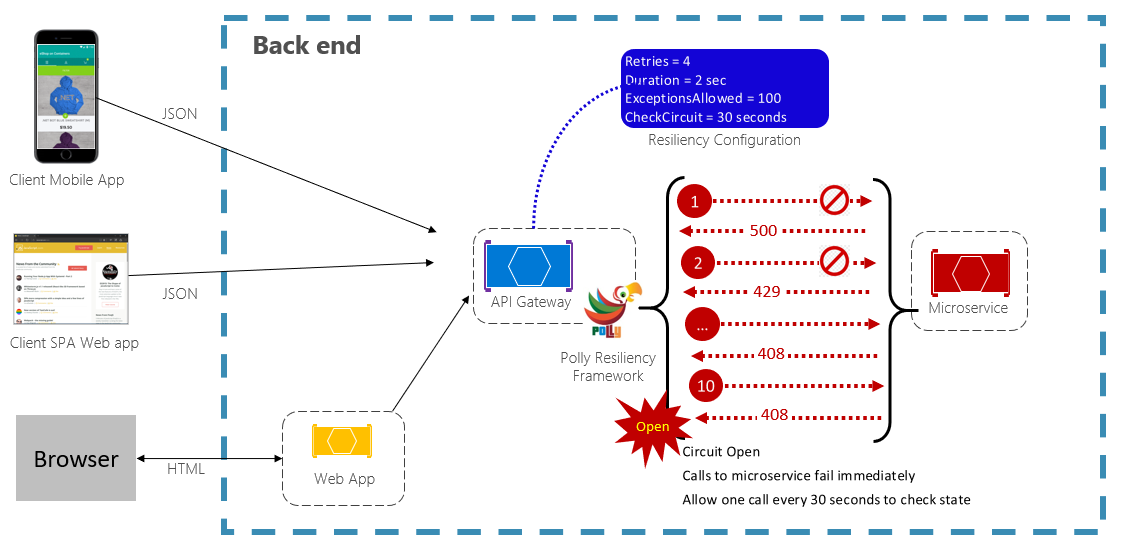
Abbildung 6-3. Circuit Breaker-Muster in Aktion
In der obigen Abbildung wurde dem ursprünglichen Wiederholungsmuster ein Circuit Breaker-Muster hinzugefügt. Beachten Sie, dass nach 100 fehlgeschlagenen Aufrufen das Circuit Breaker-Muster greift und keine weiteren Aufrufe des Diensts mehr zugelassen werden. Der auf 30 Sekunden festgelegte CheckCircuit-Wert gibt an, wie oft die Bibliothek eine Anforderung an den Dienst weiterleiten darf. Ist dieser Aufruf erfolgreich, wird die Verbindung geschlossen, und der Dienst ist wieder für Datenverkehr verfügbar.
Beachten Sie, dass das Circuit Breaker-Muster einen anderen Zweck verfolgt als das Retry-Muster. Mithilfe des Wiederholungsmusters kann eine Anwendung einen Vorgang in der Annahme wiederholen, dass dieser erfolgreich ausgeführt wird. Das Circuit Breaker-Muster hindert eine Anwendung daran, einen Vorgang auszuführen, der vermutlich fehlschlagen wird. In der Regel werden diese beiden Muster in einer Anwendung kombiniert, indem sie das Wiederholungsmuster zum Aufrufen eines Circuit Breaker-Vorgangs verwendet.
Testen mit Blick auf Resilienz
Resilienztests können nicht immer auf dieselbe Weise durchgeführt werden wie Tests der Anwendungsfunktionalität (durch Ausführung von Komponententests, Integrationstests usw.). Stattdessen müssen Sie testen, wie sich die End-to-End-Workload unter Fehlerbedingungen verhält, die nur zeitweise auftreten. Zum Beispiel: Einschleusen von Fehlern durch abstürzende Prozesse, abgelaufene Zertifikate, Nichtverfügbarkeit abhängiger Dienste usw. Für solche Chaostests können Frameworks wie chaos-monkey genutzt werden.
Die Anwendungsresilienz ist eine Grundvoraussetzung für die Behandlung problematischer Anforderungsvorgänge. Das ist jedoch nur die halbe Wahrheit. Als Nächstes befassen wir uns mit den Resilienzfunktionen, die in der Azure-Cloud verfügbar sind.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für