Tutorial: Erstellen eines Programms zur Filmempfehlung mithilfe der Matrixfaktorisierung mit ML.NET
Dieses Tutorial zeigt Ihnen, wie Sie mithilfe von ML.NET in einer .NET Core-Konsolenanwendung ein Filmempfehlungssystem erstellen. Für die Schritte verwenden Sie C# und Visual Studio 2019.
In diesem Tutorial lernen Sie, wie die folgenden Aufgaben ausgeführt werden:
- Auswählen eines Machine Learning-Algorithmus
- Vorbereiten und Laden von Daten
- Erstellen und Trainieren eines Modells
- Auswerten eines Modells
- Bereitstellen und Nutzen eines Modells
Sie finden den Quellcode für dieses Tutorial im Repository dotnet/samples.
Machine Learning-Workflow
Die folgenden Schritten eignen sich für diese und alle anderen ML.NET-Aufgaben:
Voraussetzungen
Auswählen der entsprechenden Machine Learning-Aufgabe
Es gibt mehrere Möglichkeiten, ein Empfehlungssystem umzusetzen. Beispielsweise könnten Sie eine Liste mit empfohlenen Filmen oder mit ähnlichen Produkten erstellen. In diesem Szenario sagt Ihr Modell jedoch vorher, wie ein Benutzer einen bestimmten Film auf einer Skala von eins bis fünf bewertet. Falls dieser Wert höher als ein festgelegter Schwellenwert ist, wird der Film empfohlen. Dabei entsprechen höhere Bewertungen auch einer höheren Wahrscheinlichkeit dafür, dass ein Benutzer einen bestimmten Film mag.
Erstellen einer Konsolenanwendung
Erstellen eines Projekts
Erstellen Sie eine C# -Konsolenanwendung mit dem Namen „MovieRecommender“. Klicken Sie auf die Schaltfläche Weiter.
Wählen Sie .NET 6 als zu verwendendes Framework aus. Klicken Sie auf die Schaltfläche Erstellen .
Erstellen Sie ein Verzeichnis mit dem Namen Data in Ihrem Projekt, um das Dataset zu speichern:
Klicken Sie im Projektmappen-Explorer mit der rechten Maustaste auf das Projekt, und wählen Sie Hinzufügen>Neuer Ordner aus. Geben Sie „Data“ ein, und drücken Sie die EINGABETASTE.
Installieren Sie die NuGet-Pakete Microsoft.ML und Microsoft.ML.Recommender:
Hinweis
In diesem Beispiel wird, sofern nicht anders angegeben, die neueste stabile Version der genannten NuGet-Pakete verwendet.
Klicken Sie im Projektmappen-Explorer mit der rechten Maustaste auf das Projekt, und wählen Sie NuGet-Pakete verwalten aus. Wählen Sie als Paketquelle „nuget.org“ aus. Wählen Sie anschließend die Registerkarte Durchsuchen aus, suchen Sie nach Microsoft.ML, und wählen Sie das Paket in der Liste und anschließend die Schaltfläche Installieren aus. Wählen Sie die Schaltfläche OK im Dialogfeld Vorschau der Änderungen und dann die Schaltfläche Ich stimme zu im Dialogfeld Zustimmung zur Lizenz aus, wenn Sie den Lizenzbedingungen für die aufgelisteten Pakete zustimmen. Wiederholen Sie diese Schritte für Microsoft.ML.Recommender.
Fügen Sie am Anfang der Datei Program.cs die folgenden
using-Anweisungen hinzu:using Microsoft.ML; using Microsoft.ML.Trainers; using MovieRecommendation;
Herunterladen der Daten
Laden Sie die beiden Datasets herunter, und speichern Sie sie im Ordner Data, den Sie vorher erstellt haben:
Klicken Sie mit der rechten Maustaste auf recommendation-ratings-train.csv und anschließend auf „Save Link As...“ (Link speichern unter...) oder „Save Target As...“ (Ziel speichern unter...).
Klicken Sie mit der rechten Maustaste auf recommendation-ratings-test.csv und anschließend auf „Save Link As“ (Link speichern unter) oder „Save Target As“ (Ziel speichern unter).
Achten Sie darauf, die CSV-Dateien entweder im Ordner Data zu speichern oder sie in den Ordner Data zu verschieben, nachdem Sie die Dateien an anderer Stelle gespeichert haben.
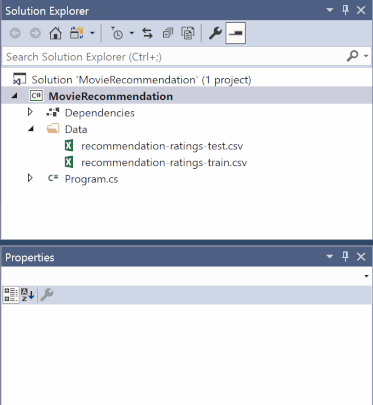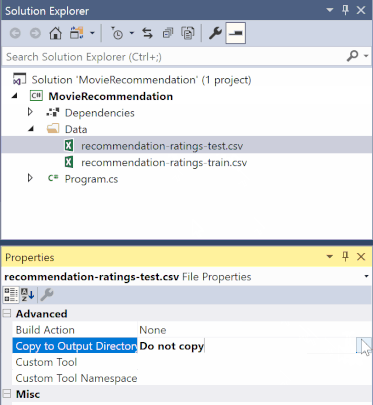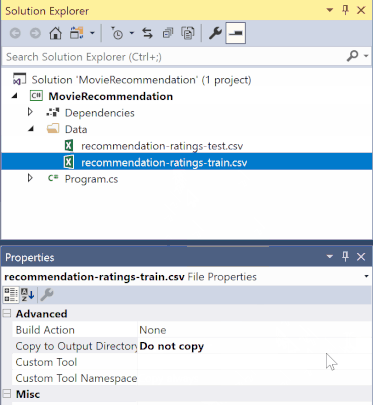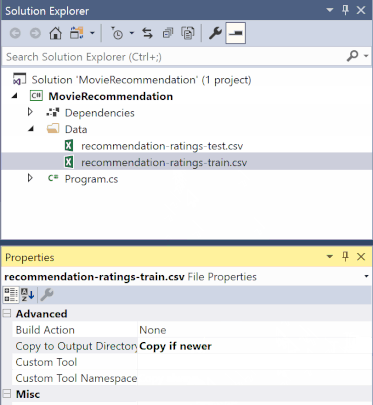
Klicken Sie im Projektmappen-Explorer mit der rechten Maustaste auf die „.csv“-Dateien, und wählen Sie Eigenschaften aus. Ändern Sie unter Erweitert den Wert von In Ausgabeverzeichnis kopieren in Kopieren, wenn neuer.
Laden von Daten
Der erste Schritt im ML.NET-Prozess besteht darin, die Modelltrainings- und Testdaten vorzubereiten und zu laden.
Die Empfehlungsbewertungsdaten werden in die Datasets Train und Test unterteilt. Die Train-Daten werden verwendet, um das Modell anzupassen. Die Test-Daten werden verwendet, um mit dem trainierten Modell Vorhersagen zu treffen und die Modellleistung auszuwerten. Train- und Test-Daten werden üblicherweise im Verhältnis 80 zu 20 aufgeteilt.
Unten sehen Sie eine Vorschau der Daten aus den CSV-Dateien:
In den CSV-Dateien befinden sich vier Spalten:
userIdmovieIdratingtimestamp
Im Machine Learning-Kontext heißen Spalten, mit denen eine Vorhersage getroffen wird, Features. Die Spalte mit der zurückgegebenen Vorhersage wird als Label bezeichnet.
Da Sie Filmbewertungen vorhersagen möchten, ist Label die Bewertungsspalte. Die anderen drei Spalten userId, movieId und timestamp sind alle Features, mit denen das Label vorhergesagt wird.
| Features | Bezeichnung |
|---|---|
userId |
rating |
movieId |
|
timestamp |
Sie müssen selbst entscheiden, welche Features Sie verwenden möchten, um das Label vorherzusagen. Sie können auch Methoden wie Permutation Feature Importance verwenden, um die Auswahl der besten Features zu unterstützen.
In diesem Tutorial sollten Sie die timestamp-Spalte nicht als Feature festlegen, da der Zeitstempel nicht beeinflusst, wie ein Benutzer einen Film bewertet, und daher nicht zu einer genaueren Vorhersage beitragen würde.
| Features | Bezeichnung |
|---|---|
userId |
rating |
movieId |
Als Nächstes müssen Sie die Datenstruktur für die Eingabeklasse definieren.
Fügen Sie dem Projekt eine neue Klasse hinzu:
Klicken Sie im Projektmappen-Explorer mit der rechten Maustaste auf das Projekt, und klicken Sie auf Hinzufügen > Neues Element.
Wählen Sie im Dialogfeld Neues Element hinzufügen die Option Klasse aus, und ändern Sie das Feld Name in MovieRatingData.cs. Wählen Sie dann die Schaltfläche Hinzufügen aus.
Die Datei MovieRatingData.cs wird im Code-Editor geöffnet. Fügen Sie am Anfang der Datei MovieRatingData.cs die folgende using-Anweisung hinzu:
using Microsoft.ML.Data;
Erstellen Sie eine Klasse mit dem Namen MovieRating, indem Sie die vorhandene Klassendefinition entfernen und MovieRatingData.cs den folgenden Code hinzufügen:
public class MovieRating
{
[LoadColumn(0)]
public float userId;
[LoadColumn(1)]
public float movieId;
[LoadColumn(2)]
public float Label;
}
MovieRating ist eine Klasse für Eingabedaten. Das LoadColumn-Attribut legt fest, welche Spalten (durch Angabe des Spaltenindex) im Dataset geladen werden sollen. Die Spalten userId und movieId sind Features, also die Eingaben, die dem Modell übergeben werden, um das Label vorherzusagen. Die Bewertungsspalte ist das vorhergesagte Label, also die Ausgabe des Modells.
Erstellen Sie eine weitere Klasse mit dem Namen MovieRatingPrediction, um die vorhergesagten Ergebnisse darzustellen, indem Sie nach der Klasse MovieRating den folgenden Code in MovieRatingData.cs hinzufügen:
public class MovieRatingPrediction
{
public float Label;
public float Score;
}
Ersetzen Sie Console.WriteLine("Hello World!") in Program.cs durch den folgenden Code:
MLContext mlContext = new MLContext();
Die MLContext-Klasse ist der Startpunkt für alle ML.NET-Vorgänge. Durch das Initialisieren von mlContext wird eine neue ML.NET-Umgebung erstellt, die für mehrere Objekte des Modellerstellungsworkflows verwendet werden kann. Die Klasse ähnelt dem Konzept von DBContext in Entity Framework.
Erstellen Sie unten in der Datei eine Methode namens LoadData():
(IDataView training, IDataView test) LoadData(MLContext mlContext)
{
}
Hinweis
Diese Methode löst zunächst eine Fehlermeldung aus. Dies ändert sich erst, wenn Sie in den folgenden Schritten eine Rückgabeanweisung hinzufügen.
Fügen Sie den unten aufgeführten Code als nächste Codezeilen in LoadData() ein, um die Datenpfadvariablen zu initialisieren, die Daten aus den CSV-Dateien zu laden und die Train- und Test-Daten als IDataView-Objekte zurückzugeben:
var trainingDataPath = Path.Combine(Environment.CurrentDirectory, "Data", "recommendation-ratings-train.csv");
var testDataPath = Path.Combine(Environment.CurrentDirectory, "Data", "recommendation-ratings-test.csv");
IDataView trainingDataView = mlContext.Data.LoadFromTextFile<MovieRating>(trainingDataPath, hasHeader: true, separatorChar: ',');
IDataView testDataView = mlContext.Data.LoadFromTextFile<MovieRating>(testDataPath, hasHeader: true, separatorChar: ',');
return (trainingDataView, testDataView);
Daten im ML.NET werden angezeigt als ein IDataView interface. Mit IDataView können Tabellendaten (Zahlen und Text) flexibel und effizient beschrieben werden. Daten können aus einer Textdatei oder in Echtzeit (z. B. aus einer SQL-Datenbank oder aus Protokolldateien) in ein IDataView-Objekt geladen werden.
Die LoadFromTextFile()-Methode definiert das Datenschema und liest die Datei ein. Diese Methode akzeptiert Datenpfadvariablen und gibt ein IDataView-Objekt zurück. In diesem Tutorial geben Sie den Pfad für die Test- und Train-Dateien, den Textdateiheader (zur korrekten Verwendung der Spaltennamen) und das Komma als Zeichendatentrennzeichen an (das Standardtrennzeichen ist ein Tabstopp).
Fügen Sie den folgenden Code hinzu, um Ihre LoadData()-Methode aufzurufen und die Train- und Test-Daten zurückzugeben:
(IDataView trainingDataView, IDataView testDataView) = LoadData(mlContext);
Erstellen und Trainieren des Modells
Erstellen Sie die BuildAndTrainModel()-Methode mit dem folgenden Code direkt nach der LoadData()-Methode:
ITransformer BuildAndTrainModel(MLContext mlContext, IDataView trainingDataView)
{
}
Hinweis
Diese Methode löst zunächst eine Fehlermeldung aus. Dies ändert sich erst, wenn Sie in den folgenden Schritten eine Rückgabeanweisung hinzufügen.
Fügen Sie BuildAndTrainModel() folgenden Code hinzu, um die Datentransformationen zu definieren:
IEstimator<ITransformer> estimator = mlContext.Transforms.Conversion.MapValueToKey(outputColumnName: "userIdEncoded", inputColumnName: "userId")
.Append(mlContext.Transforms.Conversion.MapValueToKey(outputColumnName: "movieIdEncoded", inputColumnName: "movieId"));
Da userId und movieId keine reellen Zahlen, sondern Benutzer und Filmtitel darstellen, verwenden Sie die MapValueToKey()-Methode, um jede userId und movieId in eine Feature-Spalte mit einem numerischen Schlüsseltyp (also in ein Format, das von Empfehlungsalgorithmen akzeptiert wird) zu transformieren. Anschließend fügen Sie die Werte als neue Datasetspalten ein:
| userId | movieId | Bezeichnung | userIdEncoded | movieIdEncoded |
|---|---|---|---|---|
| 1 | 1 | 4 | userKey1 | movieKey1 |
| 1 | 3 | 4 | userKey1 | movieKey2 |
| 1 | 6 | 4 | userKey1 | movieKey3 |
Fügen Sie den unten aufgeführten Code als nächste Codezeilen in BuildAndTrainModel() ein, um den Machine Learning-Algorithmus festzulegen und ihn an die Datentransformationsdefinitionen anzufügen:
var options = new MatrixFactorizationTrainer.Options
{
MatrixColumnIndexColumnName = "userIdEncoded",
MatrixRowIndexColumnName = "movieIdEncoded",
LabelColumnName = "Label",
NumberOfIterations = 20,
ApproximationRank = 100
};
var trainerEstimator = estimator.Append(mlContext.Recommendation().Trainers.MatrixFactorization(options));
Als Trainingsalgorithmus für Empfehlungen wird der MatrixFactorizationTrainer verwendet. Die Matrixfaktorisierung wird häufig für Empfehlungen eingesetzt, wenn Daten dazu vorliegen, wie Benutzer Produkte in der Vergangenheit bewertet haben. Dies trifft auf die Datasets dieses Tutorials zu. Falls andere Daten verfügbar sind, können noch mehr Empfehlungsalgorithmen eingesetzt werden. Weitere Informationen dazu finden Sie im Abschnitt Weitere Empfehlungsalgorithmen weiter unten.
In diesem Tutorial verwendet der Matrix Factorization-Algorithmus kollaborative Filter. Dabei wird Folgendes angenommen: Wenn Benutzer 1 zu einem bestimmten Thema die gleiche Meinung wie Benutzer 2 hat, vertritt Benutzer 1 zu einem anderen Thema mit höherer Wahrscheinlichkeit die gleiche Meinung wie Benutzer 2.
Wenn beispielsweise Benutzer 1 und Benutzer 2 Filme ähnlich bewerten, gefällt Benutzer 2 mit höherer Wahrscheinlichkeit ein Film, den Benutzer 1 angesehen und hoch bewertet hat:
Incredibles 2 (2018) |
The Avengers (2012) |
Guardians of the Galaxy (2014) |
|
|---|---|---|---|
| Benutzer 1 | Hat den Film gesehen und ihn gemocht | Hat den Film gesehen und ihn gemocht | Hat den Film gesehen und ihn gemocht |
| Benutzer 2 | Hat den Film gesehen und ihn gemocht | Hat den Film gesehen und ihn gemocht | Hat den Film nicht gesehen; Film wird empfohlen |
Der Matrix Factorization-Trainer kann durch mehrere Optionen angepasst werden. Weitere Informationen zu diesen finden Sie im Abschnitt Hyperparameter für Algorithmen weiter unten.
Fügen Sie den unten aufgeführten Code als nächste Codezeilen in die BuildAndTrainModel()-Methode ein, um das Modell an die Train-Daten anzupassen und das trainierte Modell zurückzugeben:
Console.WriteLine("=============== Training the model ===============");
ITransformer model = trainerEstimator.Fit(trainingDataView);
return model;
Die Fit()-Methode trainiert das Modell mit dem bereitgestellten Trainingsdataset. Sie führt die Estimator-Definitionen aus, indem sie die Daten transformiert und das Training durchführt. Anschließend gibt sie das trainierte Modell als Transformer zurück.
Weitere Informationen zum Workflow für das Modelltraining in ML.NET finden Sie unter Was ist ML.NET und wie funktioniert es?.
Fügen Sie die folgende Zeile als nächste Codezeile unter dem Aufruf der LoadData()-Methode hinzu, um Ihre BuildAndTrainModel()-Methode aufzurufen und das trainierte Modell zurückzugeben:
ITransformer model = BuildAndTrainModel(mlContext, trainingDataView);
Auswerten des Modells
Nachdem Sie Ihr Modell trainiert haben, werten Sie mit den Testdaten die Modellleistung aus.
Erstellen Sie die EvaluateModel()-Methode mit dem folgenden Code direkt nach der BuildAndTrainModel()-Methode:
void EvaluateModel(MLContext mlContext, IDataView testDataView, ITransformer model)
{
}
Fügen Sie EvaluateModel() den folgenden Code hinzu, um die Test-Daten zu transformieren:
Console.WriteLine("=============== Evaluating the model ===============");
var prediction = model.Transform(testDataView);
Die Transform()-Methode trifft Vorhersagen für mehrere bereitgestellte Eingabezeilen eines Testdatasets.
Fügen Sie den unten aufgeführten Code als nächste Codezeile in die EvaluateModel()-Methode ein, um das Modell auszuwerten:
var metrics = mlContext.Regression.Evaluate(prediction, labelColumnName: "Label", scoreColumnName: "Score");
Nach der Vorhersagekonfiguration wertet die Evaluate()-Methode das Modell aus. Dabei werden die Vorhersagewerte mit den tatsächlichen Labels im Testdataset verglichen und die Leistungsmetriken für das Modell zurückgegeben.
Fügen Sie den unten aufgeführten Code als nächste Codezeilen in die EvaluateModel()-Methode ein, um die Auswertungsmetriken auf der Konsole auszugeben:
Console.WriteLine("Root Mean Squared Error : " + metrics.RootMeanSquaredError.ToString());
Console.WriteLine("RSquared: " + metrics.RSquared.ToString());
Fügen Sie die folgende Zeile als nächste Codezeile unter dem Aufruf der BuildAndTrainModel()-Methode hinzu, um Ihre EvaluateModel()-Methode aufzurufen:
EvaluateModel(mlContext, testDataView, model);
Bis hierhin sollte die Ausgabe in etwa wie folgt aussehen:
=============== Training the model ===============
iter tr_rmse obj
0 1.5403 3.1262e+05
1 0.9221 1.6030e+05
2 0.8687 1.5046e+05
3 0.8416 1.4584e+05
4 0.8142 1.4209e+05
5 0.7849 1.3907e+05
6 0.7544 1.3594e+05
7 0.7266 1.3361e+05
8 0.6987 1.3110e+05
9 0.6751 1.2948e+05
10 0.6530 1.2766e+05
11 0.6350 1.2644e+05
12 0.6197 1.2541e+05
13 0.6067 1.2470e+05
14 0.5953 1.2382e+05
15 0.5871 1.2342e+05
16 0.5781 1.2279e+05
17 0.5713 1.2240e+05
18 0.5660 1.2230e+05
19 0.5592 1.2179e+05
=============== Evaluating the model ===============
Rms: 0.994051469730769
RSquared: 0.412556298844873
Diese Ausgabe enthält 20 Iterationen. Bei jeder Iteration verringert sich der Fehlermesswert und nähert sich immer mehr 0 an.
Die Wurzel der mittleren Fehlerquadratsumme (root of mean squared error; auch als RMS oder RMSE bezeichnet) wird verwendet, um die Unterschiede zwischen den vom Modell vorhergesagten Werten und den Beobachtungswerten des Testdatasets zu messen. Es handelt sich dabei um die Quadratwurzel der durchschnittlichen Fehlerquadrate. Je niedriger sie ausfällt, desto besser ist das Modell.
R Squared gibt an, wie gut Daten zu einem Modell passen. Die Werte liegen zwischen 0 und 1. Der Wert 0 bedeutet, dass die Daten zufällig sind oder nicht an das Modell angepasst werden können. Ein Wert von 1 bedeutet, dass das Modell exakt mit den Daten übereinstimmt. Der Wert von R Squared sollte möglichst nahe bei 1 liegen.
Erfolgreiche Modelle zu erstellen ist ein iterativer Prozess. Dieses Modell hat erst geringere Qualität, da das Tutorial kleine Datasets verwendet, um schnelles Modelltraining zu ermöglichen. Wenn Sie nicht mit der Modellqualität zufrieden sind, können Sie versuchen, sie durch die Bereitstellung größerer Trainingsdatasets oder die Auswahl anderer Trainingsalgorithmen mit anderen Hyperparametern für jeden Algorithmus zu verbessern. Weitere Informationen finden Sie im Abschnitt Verbessern des Modells weiter unten.
Verwenden Ihres Modells
Nun können Sie mit dem trainierten Modell Vorhersagen für neue Daten treffen.
Erstellen Sie die UseModelForSinglePrediction()-Methode mit dem folgenden Code direkt nach der EvaluateModel()-Methode:
void UseModelForSinglePrediction(MLContext mlContext, ITransformer model)
{
}
Fügen Sie UseModelForSinglePrediction() den folgenden Code hinzu, um mit PredictionEngine die Bewertung vorherzusagen:
Console.WriteLine("=============== Making a prediction ===============");
var predictionEngine = mlContext.Model.CreatePredictionEngine<MovieRating, MovieRatingPrediction>(model);
Die PredictionEngine ist eine Hilfs-API, mit der Sie eine Vorhersage für eine einzelne Instanz der Daten treffen können. PredictionEngine ist nicht threadsicher. Die Verwendung in Singlethread-oder Prototypumgebungen ist zulässig. Zur Verbesserung der Leistung und Threadsicherheit in Produktionsumgebungen verwenden Sie den PredictionEnginePool-Dienst, der einen ObjectPool aus PredictionEngine-Objekten für die Verwendung in Ihrer gesamten Anwendung erstellt. Informationen zur Verwendung von PredictionEnginePool in einer ASP.NET Core-Web-API finden Sie in dieser Anleitung.
Hinweis
Die PredictionEnginePool-Diensterweiterung ist derzeit als Vorschauversion verfügbar.
Fügen Sie den unten aufgeführten Code als nächste Codezeilen in die UseModelForSinglePrediction()-Methode ein, um eine Instanz von MovieRating mit dem Namen testInput zu erstellen und diese der PredictionEngine-Klasse zu übergeben:
var testInput = new MovieRating { userId = 6, movieId = 10 };
var movieRatingPrediction = predictionEngine.Predict(testInput);
Die Predict()-Funktion trifft eine Vorhersage für eine einzelne Datenspalte.
Anschließend können Sie mit dem Score (der vorhergesagten Bewertung) bestimmen, ob der Film mit der movieId 10 Benutzer 6 empfohlen werden soll. Je höher der Score, desto höher ist die Wahrscheinlichkeit, dass einem Benutzer ein bestimmter Film gefällt. In diesem Tutorial wird festgelegt, dass Filme mit einer höheren Bewertung als > 3,5 empfohlen werden.
Fügen Sie den unten aufgeführten Code als nächste Codezeilen in die UseModelForSinglePrediction()-Methode ein, um die Ergebnisse auszugeben:
if (Math.Round(movieRatingPrediction.Score, 1) > 3.5)
{
Console.WriteLine("Movie " + testInput.movieId + " is recommended for user " + testInput.userId);
}
else
{
Console.WriteLine("Movie " + testInput.movieId + " is not recommended for user " + testInput.userId);
}
Fügen Sie die folgende Zeile als nächste Codezeile nach dem Aufruf der EvaluateModel()-Methode hinzu, um Ihre UseModelForSinglePrediction()-Methode aufzurufen:
UseModelForSinglePrediction(mlContext, model);
Die Ausgabe dieser Methode sollte in etwa wie folgt aussehen:
=============== Making a prediction ===============
Movie 10 is recommended for user 6
Speichern des Modells
Sie müssen das Modell zuerst speichern, um damit Vorhersagen in Endbenutzeranwendungen treffen zu können.
Erstellen Sie die SaveModel()-Methode mit dem folgenden Code direkt nach der UseModelForSinglePrediction()-Methode:
void SaveModel(MLContext mlContext, DataViewSchema trainingDataViewSchema, ITransformer model)
{
}
Fügen Sie der SaveModel()-Methode folgenden Code hinzu, um das trainierte Modell zu speichern:
var modelPath = Path.Combine(Environment.CurrentDirectory, "Data", "MovieRecommenderModel.zip");
Console.WriteLine("=============== Saving the model to a file ===============");
mlContext.Model.Save(model, trainingDataViewSchema, modelPath);
Diese Methode speichert das trainierte Modell in einer ZIP-Datei (im Ordner „Data“), die anschließend in anderen .NET-Anwendungen für Vorhersagen verwendet werden kann.
Fügen Sie die folgende Zeile als nächste Codezeile nach dem Aufruf der UseModelForSinglePrediction()-Methode hinzu, um Ihre SaveModel()-Methode aufzurufen:
SaveModel(mlContext, trainingDataView.Schema, model);
Verwenden des gespeicherten Modells
Nachdem Sie Ihr trainiertes Modell gespeichert haben, können Sie das Modell in verschiedenen Umgebungen nutzen. Weitere Informationen zum Nutzbarmachen eines trainierten Machine Learning-Modells in Apps finden Sie unter Speichern und Laden trainierter Modelle.
Ergebnisse
Nachdem Sie die obigen Schritte durchgeführt haben, können Sie nun die Konsolen-App ausführen (STRG+F5). Die Ergebnisse der obigen Vorhersage sollten in etwa wie folgt aussehen. Möglicherweise werden Warnungen oder Verarbeitungsnachrichten angezeigt. Diese wurden jedoch aus Gründen der Übersichtlichkeit aus den folgenden Ergebnissen entfernt.
=============== Training the model ===============
iter tr_rmse obj
0 1.5382 3.1213e+05
1 0.9223 1.6051e+05
2 0.8691 1.5050e+05
3 0.8413 1.4576e+05
4 0.8145 1.4208e+05
5 0.7848 1.3895e+05
6 0.7552 1.3613e+05
7 0.7259 1.3357e+05
8 0.6987 1.3121e+05
9 0.6747 1.2949e+05
10 0.6533 1.2766e+05
11 0.6353 1.2636e+05
12 0.6209 1.2561e+05
13 0.6072 1.2462e+05
14 0.5965 1.2394e+05
15 0.5868 1.2352e+05
16 0.5782 1.2279e+05
17 0.5713 1.2227e+05
18 0.5637 1.2190e+05
19 0.5604 1.2178e+05
=============== Evaluating the model ===============
Rms: 0.977175077487166
RSquared: 0.43233349213192
=============== Making a prediction ===============
Movie 10 is recommended for user 6
=============== Saving the model to a file ===============
Herzlichen Glückwunsch! Sie haben ein Machine Learning-Modell zur Empfehlung von Filmen erstellt. Sie finden den Quellcode für dieses Tutorial im Repository dotnet/samples.
Verbessern des Modells
Es gibt mehrere Möglichkeiten, die Leistung des Modells zu verbessern, um so genauere Vorhersagen treffen zu können.
Daten
Wenn Sie mehr Trainingsdaten mit ausreichend Beispielen für jeden Benutzer und für jede movieId hinzufügen, kann die Qualität des Empfehlungsmodells gesteigert werden.
Die Kreuzvalidierung ist eine Methode zur Auswertung von Modellen, bei der nicht –wie in diesem Tutorial – Testdaten aus dem Dataset extrahiert, sondern stattdessen nach dem Zufallsprinzip Daten in Teilmengen aufgeteilt werden. Anschließend werden einige Gruppen als Trainingsdaten und einige als Testdaten verwendet. Diese Methode führt im Vergleich zur Aufteilung von Daten in Trainings- und Testdatasets zu einer höheren Modellqualität.
Features
In diesem Tutorial verwenden Sie nur die drei Features (user id, movie id und rating), die vom Dataset bereitgestellt werden.
Dies ist für den Anfang ausreichend. In einem echten Szenario sollten Sie jedoch weitere Attribute oder Features (beispielsweise Alter, Geschlecht, Standort usw.) hinzufügen, falls diese im Dataset enthalten sind. Durch das Hinzufügen relevanter Features können Sie die Leistung des Empfehlungsmodells verbessern.
Wenn Sie nicht genau wissen, welche Features für Ihre Machine Learning-Aufgabe am relevantesten sind, können Sie auch die Methoden Feature Contribution Calculation (FCC) und Permutation Feature Importance verwenden, die ML.NET zur Ermittlung der wichtigsten Features bereitstellt.
Hyperparameter für Algorithmen
ML.NET stellt viele effiziente Trainingsalgorithmen bereit. Sie können die Leistung allerdings noch weiter optimieren, indem Sie die Hyperparameter des Algorithmus anpassen.
Bei Matrix Factorization können Sie mit Hyperparametern wie NumberOfIterations und ApproximationRank experimentieren, um möglicherweise bessere Ergebnisse zu erzielen.
In diesem Tutorial werden beispielsweise folgende Algorithmusoptionen verwendet:
var options = new MatrixFactorizationTrainer.Options
{
MatrixColumnIndexColumnName = "userIdEncoded",
MatrixRowIndexColumnName = "movieIdEncoded",
LabelColumnName = "Label",
NumberOfIterations = 20,
ApproximationRank = 100
};
Weitere Empfehlungsalgorithmen
Der Algorithmus zur Matrixfaktorisierung mit kollaborativen Filtern ist nur eine Möglichkeit für Filmempfehlungen. In vielen Fällen verfügen Sie möglicherweise nicht über die Bewertungsdaten, sondern nur über den Filmverlauf der Benutzer. In anderen Fällen sind eventuell zusätzlich zu den Bewertungsdaten der Benutzer noch weitere Daten verfügbar.
| Algorithmus | Szenario | Beispiel |
|---|---|---|
| One Class Matrix Factorization (Matrixfaktorisierung mit einer Klasse) | Verwenden Sie diesen Algorithmus, wenn nur userId und movieId zur Verfügung stehen. Diese Empfehlungsstrategie wird für Szenarios eingesetzt, in denen Produkte oft zusammen gekauft werden. Kunden werden auf diese Weise empfohlene Produkte auf Grundlage des eigenen Bestellverlaufs angezeigt. | >Legen Sie los! |
| Field Aware Factorization Machines (Faktorisierungsverfahren mit Berücksichtigung von Feldern) | Verwenden Sie diesen Algorithmus für Empfehlungen, wenn zusätzlich zur userId, productId und Bewertung noch weitere Features wie eine Produktbeschreibung oder ein Produktpreis vorhanden sind. Auch bei dieser Methode kommen kollaborative Filter zum Einsatz. | >Legen Sie los! |
Szenario mit neuen Benutzern
Bei kollaborativen Filtern tritt häufig das sogenannte Kaltstartproblem auf. Hierbei müssen für neue Benutzer Rückschlüsse gezogen werden, obwohl noch keine Datengrundlage vorhanden ist. Das Problem wird oft dadurch gelöst, dass neue Benutzer aufgefordert werden, ein Profil zu erstellen und z. B. bereits gesehene Filme zu bewerten. Diese Methode stellt zwar für Benutzer einen gewissen Aufwand dar, liefert jedoch zumindest einige Startdaten für neue Benutzer ohne Bewertungsverlauf.
Ressourcen
Die Daten aus diesem Tutorial stammen aus dem MovieLens-Dataset.
Nächste Schritte
In diesem Tutorial haben Sie gelernt, wie die folgenden Aufgaben ausgeführt werden:
- Auswählen eines Machine Learning-Algorithmus
- Vorbereiten und Laden von Daten
- Erstellen und Trainieren eines Modells
- Auswerten eines Modells
- Bereitstellen und Nutzen eines Modells
Wechseln Sie zum nächsten Tutorial, um mehr zu erfahren.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für