Verwaltete Verfügbarkeit
Die Hauptaufgabe der Administratoren eines Messagingsystems besteht darin, Benutzern eine reibungslose E-Mail-Erfahrung zu ermöglichen. In Ihrer Exchange Server Organisation müssen alle Aspekte des Systems aktiv überwacht werden, und alle erkannten Probleme müssen schnell behoben werden. Hierfür bietet ein Feature mit dem Namen Verwaltete Verfügbarkeit integrierte Überwachungs- und Wiederherstellungsaktionen, die die Benutzerfreundlichkeit aufrecht erhalten.
Verwaltete Verfügbarkeit
Die verwaltete Verfügbarkeit, auch als Aktive Überwachung oder lokale aktive Überwachung bezeichnet, ist die Integration integrierter Überwachungs- und Wiederherstellungsaktionen in die Exchange-Hochverfügbarkeitsplattform. Sie ist dafür vorgesehen, vom System erkannte Probleme sofort zu ermitteln und zu beheben. Im Gegensatz zu früheren externen Überwachungslösungen und -techniken für Exchange versucht die verwaltete Verfügbarkeit nicht, die eigentliche Ursache eines Problems zu ermitteln oder zu kommunizieren. Sie konzentriert sich stattdessen auf Wiederherstellungsaspekte, die drei zentrale Benutzerfragen adressieren:
Verfügbarkeit: Können Benutzer auf den Dienst zugreifen?
Latenz: Wie ist die Erfahrung für Benutzer?
Fehler: Können Benutzer erreichen, was sie wollen?
Die verwaltete Verfügbarkeit bietet eine native Lösung zur Überwachung und Wiederherstellung der Integrität. Es geht weg von der Überwachung einzelner separater Segmente des Systems, um die End-to-End-Benutzererfahrung zu überwachen und die Endbenutzererfahrung durch wiederherstellungsorientierte Aktionen zu schützen.
Verwaltete Verfügbarkeit ist ein interner Prozess, der auf jedem Exchange-Server ausgeführt wird. Dabei werden in jeder Sekunde Hunderte von Integritätsmetriken abgerufen. Wenn Fehler erkannt werden, können diese meist automatisch behoben werden. Es wird jedoch auch immer Probleme geben, die von der verwalteten Verfügbarkeit nicht direkt gelöst werden können. In diesen Fällen eskaliert die verwaltete Verfügbarkeit das Problem an einen Administrator mit Ereignisprotokollierung.
Die verwaltete Verfügbarkeit wird in Form von zwei Diensten implementiert:
Exchange Health Manager Service (MSExchangeHMHost.exe): Dies ist ein Controllerprozess, der zum Verwalten von Arbeitsprozessen verwendet wird. Es wird verwendet, um den Arbeitsprozess nach Bedarf zu erstellen, auszuführen und zu starten und zu beenden. Es wird auch verwendet, um den Arbeitsprozess im Falle eines Fehlers wiederherzustellen, um zu verhindern, dass der Arbeitsprozess ein Single Point of Failure ist.
Exchange Health Manager Worker process (MSExchangeHMWorker.exe): Dies ist der Arbeitsprozess, der für die Ausführung von Laufzeitaufgaben innerhalb des verwalteten Verfügbarkeitsframeworks verantwortlich ist.
Bei der verwalteten Verfügbarkeit wird ein beständiger Speicher verwendet, um die zugehörigen Funktionen auszuführen:
In den XML-Dateien im Ordner "\bin\Monitoring\config" werden Konfigurationseinstellungen für einige der Test- und Überwachungsarbeitsaufgaben gespeichert.
Active Directory wird zum Speichern globaler Außerkraftsetzungen verwendet.
Die Windows-Registrierung wird zum Speichern von Laufzeitdaten, wie z. B. Lesezeichen, und lokalen (serverspezifischen) Außerkraftsetzungen verwendet.
Die Windows-Crimson-Kanal-Ereignisprotokollinfrastruktur wird zum Speichern der Arbeitselementergebnisse verwendet.
Integritätspostfächer werden für Prüfaktivitäten verwendet. In jeder Postfachdatenbank auf dem Server werden mehrere Integritätspostfächer erstellt.
Komponenten der verwalteten Verfügbarkeit
Wie in der folgenden Abbildung veranschaulicht, umfasst die verwaltete Verfügbarkeit drei zentrale asynchrone Komponenten, die permanent aktiv sind.
Komponenten der verwalteten Verfügbarkeit
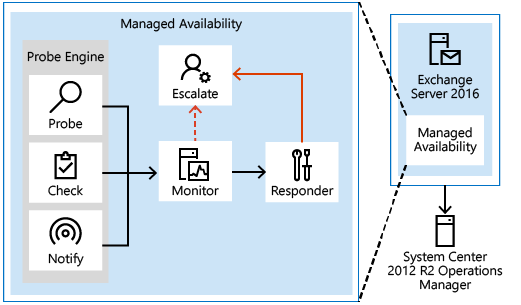
Testmodule
Die erste Komponente wird Testmodul genannt. Testmodule sind für die Durchführung von Messungen auf dem Server und für das Sammeln von Daten verantwortlich.
Es existieren drei wesentliche Testtypen: wiederkehrende Tests, Benachrichtigungen und Prüfungen. Wiederkehrende Tests sind synthetische Transaktionen, die vom System zum Testen der umfassenden Benutzerfreundlichkeit ausgeführt werden. Überprüfungen sind die Infrastruktur, die die Sammlung von Leistungsdaten durchführt, einschließlich Des Benutzerdatenverkehrs. Dadurch kann die Prüfinfrastruktur ermitteln, wann bei den Benutzern Probleme auftreten. Mithilfe der Benachrichtigungslogik kann das System schließlich auf Grundlage eines kritischen Ereignisses Sofortmaßnahmen ergreifen, ohne auf die Ergebnisse der über den Test erfassten Daten warten zu müssen. Hierbei handelt es sich in der Regel um Ausnahmen oder Bedingungen, die ohne große Stichprobe ermittelt und erkannt werden können.
Wiederkehrende Tests werden alle paar Minuten durchgeführt und dienen zur Bewertung einzelner Aspekte der Dienstintegrität. In diesen Tests kann über Exchange ActiveSync eine E-Mail an ein Überwachungspostfach gesendet werden, sie können zur Verbindung mit einem RPC-Endpunkt dienen, oder sie können die Konnektivität für Clientzugriffe auf die Mailbox prüfen.
Alle Tests werden beim Starten des Health Manager-Diensts im crimson-Kanal Microsoft.Exchange.ActiveMonitoring\ProbeDefinition definiert. Jede Testdefinition verfügt über viele Eigenschaften, aber die relevantesten Eigenschaften sind:
Namen Der Name des Tests, der mit einer SampleMask des Monitors des Tests beginnt.
TypeName Der Codeobjekttyp des Tests, der die Testlogik enthält.
ServiceName Der Name des Integritätssatzes, der den Test enthält.
TargetResource Das Objekt, das durch den Test überprüft wird. Dies wird an den Namen des Tests angefügt, wenn er ausgeführt wird, um ein Testergebnis ResultName zu werden.
RecurrenceIntervalSeconds Häufigkeit, in der der Test ausgeführt wird.
TimeoutSeconds Zeit, die der Test wartet, bevor er als fehlgeschlagen gilt.
Es gibt Hunderte von wiederkehrenden Tests. Viele dieser Tests sind datenbankbezogen. Wenn also die Anzahl der Datenbanken sich erhöht, gibt es auch immer mehr Tests, Die meisten dieser Tests werden im Code definiert und sind deshalb nicht direkt erkennbar.
Ein wiederkehrender Test wird auf folgender Grundlage durchgeführt: Er wird alle RecurrenceIntervalSeconds neu gestartet und prüft einige Aspekte der Dienstintegrität. Wenn die betreffende Komponente intakt ist, ist der Test bestanden, und es wird ein Informationsereignis mit dem ResultType 3 an den Kanal Microsoft.Exchange.ActiveMonitoring\ProbeResult gesendet. Wenn die Prüfung fehlschlägt oder eine Zeitüberschreitung auftritt, wird ein Fehlerereignis an denselben Kanal gesendet. Ein ResultType von 4 bedeutet, dass die Überprüfung fehlgeschlagen ist, und ein ResultType von 1 bedeutet, dass ein Timeout aufgetreten ist. Viele Tests werden bei einem Timeout erneut ausgeführt, bis zum Wert der MaxRetryAttempts-Eigenschaft .
Hinweis
Der Crimson-Kanal ProbeResult kann mit Hunderten von Tests, die alle paar Minuten laufen, sowie mit der Protokollierung der entsprechenden Ereignisse sehr beschäftigt sein, so dass sich eine deutliche Auswirkung auf die Leistung Ihres Exchange-Servers ergeben kann, wenn Sie in einer Produktumgebung umfassende Abfragen der Ereignisprotokolle durchführen.
Benachrichtigungen sind Tests, die nicht durch das Framework des Integritätsdiensts, sondern durch andere Dienste auf dem Server durchgeführt werden. Diese Dienste führen ihre eigene Überwachung durch und stellen ihre Daten im Framework für verwaltete Verfügbarkeit bereit, indem Sie die Testergebnisse direkt in dieses schreiben. Diese Tests werden im TestDefinition-Kanal nicht angezeigt, da dieser Kanal nur Tests beschreibt, die vom Managed Availability Framework ausgeführt werden. Der Monitor ServerOneCopyMonitor wird z.B. nur durch Testergebnisse ausgelöst, die vom Dienst MSExchangeDAGMgmt geschrieben werden. Dieser Dienst führt seine eigene Überwachung durch, ermittelt, ob ein Problem vorliegt, und protokolliert das Testergebnis. Die meisten Benachrichtigungstests verfügen über die Kapazität, sowohl rote Ereignisse, die auf eine Fehlerhaftigkeit des Monitors hinweisen, als auch grüne Ereignisse anzuzeigen, mit denen der betreffende Monitorfehler behoben wird.
Prüfungen sind Tests, bei denen Ereignisse nur protokolliert werden, wenn der Leistungsindikator einen bestimmten Schwellenwert über- oder unterschreitet. Diese sind ein wirklich spezieller Fall von Benachrichtigungstest, da ein Dienst die Leistungsindikatoren auf dem Server überwacht und Ereignisse in den Kanal ProbeResult protokolliert, wenn der konfigurierte Schwellenwert erreicht wird.
Um den Indikator und den Schwellenwert zu finden, der als fehlerhaft betrachtet wird, können Sie für diese Prüfung auf den Monitor schauen. Monitore vom Typ Microsoft.Office.Datacenter.ActiveMonitoring.OverallConsecutiveSampleValueAboveThresholdMonitor oder Microsoft.Office.Datacenter.ActiveMonitoring.OverallConsecutiveSampleValueBelowThresholdMonitor bedeuten, dass der überwachte Test ein Überprüfungstest ist.
Überwachen
Die Ergebnisse der von Sonden gesammelten Messungen fließen in die zweite Komponente, den Monitor, ein. Der Monitor enthält die gesamte Geschäftslogik, die vom System für die gesammelten Daten verwendet wird. Ähnlich wie bei einer Mustererkennungs-Engine sucht der Monitor bei allen gesammelten Messungen nach den verschiedenen Mustern und entscheidet dann, ob etwas als fehlerfrei gilt.
Monitore fragen die von Daten ab, um zu ermitteln, ob auf Basis eines vordefinierten Regelsatzes Maßnahmen ergriffen werden müssen. In Abhängigkeit von der Regel oder der Art des Problems kann ein Monitor entweder einen Responder initiieren oder das Problem über einen Ereignisprotokolleintrag an eine Person weiterleiten. Darüber hinaus definieren Monitore, wie lange nach einem Fehler ein Responder ausgeführt wird, und den Workflow der Wiederherstellungsaktion. Monitore können verschiedene Zustände aufweisen. Aus Sicht des Systemstatus verfügen Monitore über zwei Zustände:
Fehlerfrei: Der Monitor funktioniert ordnungsgemäß, und alle gesammelten Metriken liegen innerhalb der normalen Betriebsparameter.
Fehlerhaft: Der Monitor ist nicht fehlerfrei und hat entweder die Wiederherstellung über einen Responder initiiert oder einen Administrator durch Eskalation benachrichtigt.
Aus administrativer Sicht verfügen Monitore über zusätzliche Zustände, die in der Exchange-Verwaltungsshell angezeigt werden:
Heruntergestuft: Wenn sich ein Monitor in einem fehlerhaften Zustand von 0 bis 60 Sekunden befindet, wird er als heruntergestuft betrachtet. Wenn sich der Monitor für mehr als 60 Sekunden im Zustand "Fehlerhaft" befindet, wird er als "Fehlerhaft" betrachtet.
Deaktiviert: Der Monitor wurde von einem Administrator explizit deaktiviert.
Nicht verfügbar: Der Exchange-Integritätsdienst fragt jeden Monitor in regelmäßigen Abständen nach seinem Status ab. Wenn er auf die Abfrage keine Antwort erhält, ändert sich der Zustand des Monitors in "Nicht verfügbar".
Reparieren: Ein Administrator legt den Reparaturstatus fest, um dem System anzuzeigen, dass eine Korrekturmaßnahme von einem Menschen ausgeführt wird, wodurch das System und der Mensch zwischen anderen Fehlern unterscheiden können, die gleichzeitig auftreten können, wenn Korrekturmaßnahmen ausgeführt werden (z. B. ein Datenbankkopien-Erneuteinsetzungsvorgang).
Jeder Monitor verfügt über eine SampleMask-Eigenschaft in der Definition. Wenn der Monitor ausgeführt wird, sucht er nach Ereignissen im TestResult-Kanal, die einen ResultName aufweisen, der der SampleMask des Monitors entspricht. Diese Ereignisse können aus wiederkehrenden Tests, Benachrichtigungen oder Prüfungen stammen. Wenn die Schwellenwerte des Monitors erreicht werden, wird Fehlerhaftigkeit festgestellt. Aus der Perspektive des Monitors sind die Testtypen gleich, da sie alle Protokolle in den Kanal ProbeResult schreiben.
Es sollte darauf hingewiesen werden, dass ein einzelner Testfehler nicht unbedingt darauf hindeutet, dass etwas mit dem Server nicht stimmt. Es ist das Design von Monitoren, um richtig zu identifizieren, wenn ein echtes Problem behoben werden muss. Aus diesem Grund haben viele Monitore Schwellenwerte für mehrere Testfehlschläge, bevor Fehlerhaftigkeit festgestellt wird. Aber dennoch können viele dieser Probleme automatisch durch Antwortsender behoben werden, sodass der Crimson-Kanal Microsoft.Exchange.ManagedAvailability\Monitoring der beste Platz für die Suche nach Problemen ist, die eine manuelle Behebung erfordern. Dazu gehört auch der letzte Testfehler.
Responder
Schließlich gibt es Responders, die für Wiederherstellungs- und Eskalationsaktionen verantwortlich sind. Wie der Name schon sagt, führen Responder eine Art Antwort auf eine Warnung aus, die von einem Monitor generiert wurde. Wenn etwas fehlerhaft ist, besteht die erste Aktion darin, diese Komponente wiederherzustellen. Dies kann mehrstufige Wiederherstellungsaktionen umfassen. Der erste Versuch kann beispielsweise darin bestehen, den Anwendungspool neu zu starten, der zweite kann darin bestehen, den Dienst neu zu starten, der dritte Versuch kann darin bestehen, den Server neu zu starten, und der nachfolgende Versuch kann darin bestehen, den Server offline zu schalten, damit er keinen Datenverkehr mehr akzeptiert. Wenn die Wiederherstellungsaktionen nicht erfolgreich sind, eskaliert das System das Problem über Ereignisprotokollbenachrichtigungen an einen Menschen.
Responders führen verschiedene Wiederherstellungsaktionen aus, z. B. das Zurücksetzen eines Anwendungs-Workerpools oder das Neustarten eines Servers. Es gibt verschiedene Arten von Respondern:
Neustart-Responder Beendet einen Dienst und startet ihn neu.
Anwendungspool-Neustart-Responder Beendet einen Anwendungspool in den Internetinformationsdiensten (IIS) und startet ihn neu.
Failover-Responder Initiiert ein Datenbank- oder Serverfailover.
Fehlerprüfungs-Responder Initiiert eine Fehlerprüfung des Servers und verursacht dadurch einen Neustart des Servers.
Offline-Responder Setzt ein Protokoll auf einem Server außer Betrieb (weist Clientanforderungen zurück).
Online-Responder Versetzt ein Protokoll auf einem Server wieder in den Produktionsmodus (akzeptiert Clientanforderungen)
Eskalations-Responder Eskaliert das Problem durch Ereignisprotokollierung an einen Administrator
Zusätzlich zu den aufgeführten Respondern verfügen einige Komponenten über eigene, spezialisierte Responder.
Alle Antwortenden umfassen das Drosselungsverhalten, das einen integrierten Sequenzierungsmechanismus zum Steuern von Reaktionsaktionen bereitstellt. Durch dieses Einschränkungsverhalten soll verhindert werden, dass das System aufgrund von Wiederherstellungsaktionen des Responders beschädigt oder beeinträchtigt wird. Alle Responder werden in irgendeiner Weise eingeschränkt. Wenn eine Einschränkung auftritt, kann die Wiederherstellungsaktion des Responders je nach Aktion entweder übersprungen oder verzögert werden. Beispielsweise wird bei einer Einschränkung des Fehlerprüfungs-Responders die Aktion übersprungen und nicht verzögert.
Integritätssätze
Bezüglich der Berichterstellung umfasst die verwaltete Verfügbarkeit zwei Ansichten der Integrität: eine interne und eine externe.
Die interne Ansicht verwendet Integritätssätze. Jede Komponente in Exchange Server (z. B. Outlook im Web, Exchange ActiveSync, der Informationsspeicherdienst, Inhaltsindizierung, Transportdienste usw.) wird mithilfe von Tests, Monitoren und Antworten durch verwaltete Verfügbarkeit überwacht. Eine Gruppe von Tests, Monitoren und Antworten für eine bestimmte Komponente wird als Integritätssatz bezeichnet. Ein Integritätssatz ist eine Gruppe von Tests, Monitoren und Antwortern, die bestimmen, ob diese Komponente fehlerfrei ist. Der aktuelle Zustand eines Integritätssatzes (z. B. ob er fehlerfrei oder fehlerhaft ist) wird mithilfe des Zustands der Monitore des Integritätssatzes bestimmt. Wenn alle Monitore eines Integritätssatzes fehlerfrei sind, befindet sich der Integritätssatz in einem fehlerfreien Zustand. Wenn sich ein Monitor nicht in einem fehlerfreien Zustand befindet, wird der Zustand des Integritätssatzes durch den am wenigsten fehlerfreien Monitor bestimmt.
Detaillierte Anweisungen zum Anzeigen des Status der Serverintegrität oder des Integritätssatzes finden Sie unter Manage health sets and server health.
Integritätsgruppen
Die externe Ansicht der verwalteten Verfügbarkeit besteht aus Integritätsgruppen. Integritätsgruppen sind für System Center Operations Manager 2012 R2 verfügbar.
Es gibt vier primäre Integritätsgruppen:
Kontaktpunkte für Kunden Komponenten, die sich auf Echtzeit-Benutzerinteraktionen auswirken, wie Protokolle oder der Informationsspeicher.
Dienstkomponenten Komponenten ohne direkte Echtzeit-Benutzerinteraktionen, wie z. B. der Microsoft Exchange-Postfachreplikationsdienst oder der Offlineadressbuch-Generierungsprozess (OABGen).
Serverkomponenten Die physischen Ressourcen des Servers, z. B. Speicherplatz, Arbeitsspeicher und Netzwerk.
Verfügbarkeit von Abhängigkeiten Die Fähigkeit des Servers, auf erforderliche Abhängigkeiten wie Active Directory, DNS usw. zuzugreifen.
Wenn das Exchange Management Pack installiert ist, dient System Center Operations Manager (SCOM) als Integritätsportal zum Anzeigen von Informationen bezüglich der Exchange-Umgebung. Das SCOM-Dashboard enthält drei Ansichten der Exchange-Serverintegrität:
Aktive Warnungen Eskalations-Responder schreiben Ereignisse in das Windows-Ereignisprotokoll, die vom Monitor in SCOM verwendet werden. Diese werden als Warnungen in der Ansicht "Aktive Warnungen" angezeigt.
Organisationsintegrität In dieser Ansicht wird eine Rollupzusammenfassung der Gesamtintegrität der Exchange-Organisation angezeigt. Diese Rollups enthalten Anzeigen der Integrität für einzelne Datenbank-Verfügbarkeitsgruppen und für bestimmte Active Directory-Standorte.
Serverintegrität In dieser Ansicht werden verwandte Integritätssätze zu Integritätsgruppen kombiniert und zusammengefasst.
Außerkraftsetzungen
Außerkraftsetzungen ermöglichen es einem Administrator, einige Aspekte der Tests, Monitore und Responder für die verwaltete Verfügbarkeit zu konfigurieren. Mit Außerkraftsetzungen können einige der von der verwalteten Verfügbarkeit verwendeten Schwellenwerte angepasst werden. Zudem können hiermit Notfallaktionen für unerwartete Ereignisse aktiviert werden, die andere Konfigurationseinstellungen als die Standardvorgaben erfordern.
Außerkraftsetzungen können auf einem einzelnen Server erstellt und angewendet werden (dies wird als Serveraußerkraftsetzung bezeichnet), oder sie können auf eine Gruppe von Servern angewendet werden (dies wird als globale Außerkraftsetzung bezeichnet). Konfigurationsdaten für Serveraußerkraftsetzungen werden in der Windows-Registrierung auf dem Server gespeichert, auf dem die Außerkraftsetzung angewendet wird. Konfigurationsdaten für globale Außerkraftsetzungen werden in Active Directory gespeichert.
Außerkraftsetzungen können für eine unendliche oder für eine beschränkte Dauer konfiguriert werden. Zudem können globale Außerkraftsetzungen für die Anwendung auf allen Servern oder nur auf Servern mit einer bestimmten Version von Exchange konfiguriert werden.
Wenn Sie eine Außerkraftsetzung konfigurieren, wird sie nicht sofort wirksam. Der Microsoft Exchange-Integritätsdienst nimmt alle 10 Minuten eine Prüfung auf aktualisierte Konfigurationsdaten vor. Darüber hinaus sind globale Außerkraftsetzungen von der Replikationslatenz von Active Directory abhängig.
Ausführliche Schritte zum Anzeigen oder Konfigurieren von Server- oder globalen Außerkraftsetzungen finden Sie unter Konfigurieren von Außerkraftsetzungen für verwaltete Verfügbarkeit.
Verwaltungsaufgaben und Verwaltungs-Cmdlets
Es gibt drei primäre operative Aufgaben, die Administratoren in der Regel im Hinblick auf die verwaltete Verfügbarkeit ausführen:
Extrahieren oder Anzeigen der Systemintegrität
Anzeigen von Integritätssätzen und Details zu Tests, Monitoren und Respondern
Verwalten von Außerkraftsetzungen
Die beiden primären Verwaltungstools für die verwaltete Verfügbarkeit sind das Windows-Ereignisprotokoll und die Exchange-Verwaltungsshell. Die verwaltete Verfügbarkeit protokolliert eine große Menge von Informationen in den Ereignisprotokollen Exchange ActiveMonitoring und ManagedAvailability crimson channel, z. B.:
Test-, Monitor- und Responderdefinitionen, die in den jeweiligen Ereignisprotokollen "*Definition" aufgezeichnet werden.
Test-, Monitor- und Responderergebnisse, die in den jeweiligen Ereignisprotokollen "*Results" aufgezeichnet werden.
Details zu Wiederherstellungsaktionen des Responders, einschließlich des Starts der Wiederherstellungsaktion, und sie gilt als abgeschlossen (ob erfolgreich oder nicht), die im RecoveryActionResults-Ereignisprotokoll protokolliert werden.
Für die verwaltete Verfügbarkeit stehen 12 Cmdlets zur Verfügung, die in der folgenden Tabelle beschrieben werden.
| Cmdlet | Beschreibung |
|---|---|
| Get-ServerHealth | Dient zum Abruf unverarbeiteter Serverintegritätsinformationen, z. B. von Integritätssätzen und deren aktuellem Zustand (fehlerfrei oder fehlerhaft), Integritätssatzmonitoren, Serverkomponenten, Zielressourcen für Tests, Zeitstempeln im Zusammenhang mit Start- bzw. Endzeiten von Tests und Monitoren sowie Zustandsübergangszeiten. |
| Get-HealthReport | Dient zum Abruf einer zusammenfassenden Integritätsansicht mit Integritätssätzen und deren aktuellem Status. |
| Get-MonitoringItemIdentity | Dient zum Anzeigen der Tests, Monitore und Responder für einen bestimmten Integritätssatz. |
| Get-MonitoringItemHelp | Dient zum Anzeigen von Beschreibungen einiger Eigenschaften von Tests, Monitoren und Respondern. |
| Add-ServerMonitoringOverride | Dient zum Erstellen einer lokalen, serverspezifischen Außerkraftsetzung eines Tests, Monitors oder Responders. |
| Get-ServerMonitoringOverride | Dient zum Anzeigen einer Liste lokaler Außerkraftsetzungen auf dem angegebenen Server. |
| Remove-ServerMonitoringOverride | Dient zum Entfernen einer lokalen Außerkraftsetzung von einem bestimmten Server. |
| Add-GlobalMonitoringOverride | Dient zum Erstellen einer globalen Außerkraftsetzung für eine Gruppe von Servern. |
| Get-GlobalMonitoringOverride | Dient zum Anzeigen einer Liste globaler Außerkraftsetzungen in der Organisation. |
| Remove-GlobalMonitoringOverride | Dient zum Entfernen einer globalen Außerkraftsetzung. |
| Set-ServerComponentState | Dient zum Konfigurieren des Status einer oder mehrerer Komponenten. |
| Get-ServerComponentState | Dient zum Anzeigen des Status einer oder mehrerer Komponenten. |