Was ist softwaredefinierter Speicher unter Windows Server?
Softwaredefinierter Speicher ist einer der grundlegenden Bausteine von Azure Stack HCI. Anders als bei Hyper-V oder Failoverclustering ist der softwaredefinierte Speicher jedoch keine einzelne Serverrolle oder ein Feature. Stattdessen besteht er aus verschiedenen Technologien, die sich häufig gegenseitig ergänzen. Sie können diese Technologien kombinieren, um verschiedene Speichervirtualisierungsszenarien zu implementieren, z. B. Gastclustering oder HCI. Zu diesen Technologien gehören Speicherplätze, freigegebene Clustervolumes (CSV), Server Message Block (SMB), SMB Multichannel, SMB Direct, Scale Out File Server (SOFS, Dateiserver mit horizontaler Skalierung), Direkte Speicherplätze (S2D) und Speicherreplikat. Um Azure Stack HCI in Ihrer Proof-of-Concept-Umgebung zu verwenden, sind Sie auf die meisten dieser Technologien angewiesen.
Hinweis
Dies ist keine umfassende Liste, aber sie genügt, um ein grundlegendes Verständnis der wichtigsten softwaredefinierten Speicherfunktionen in Azure Stack HCI zu erhalten.
Was ist softwaredefinierter Speicher?
Softwaredefinierter Speicher verwendet Speichervirtualisierung, um die Speicherverwaltung und -darstellung von der zugrunde liegenden physischen Hardware zu trennen. Einer der Hauptvorteile dieses Ansatzes besteht darin, dass die Bereitstellung von und der Zugriff auf Speicherressourcen vereinfacht werden.
Gründe für softwaredefinierten Speicher
Mit softwaredefiniertem Speicher erfordert die Implementierung virtualisierter Workloads keine Konfiguration von LUNs (Logical Unit Numbers, logische Gerätenummern) und SAN-Switches (Storage Area Networks) mehr gemäß den Spezifikationen von Drittanbietern. Stattdessen können Sie Speicher unabhängig von der zugrunde liegenden Hardware auf dieselbe und konsistente Weise verwalten. Darüber hinaus haben Sie die Möglichkeit, proprietäre und kostspielige Technologien durch flexible und wirtschaftliche, hardwarebasierte Lösungen zu ersetzen. Anstatt sich auf dedizierte SANs als hochverfügbaren und hochleistungsfähigen Speicher zu verlassen, können Sie lokale Datenträger einsetzen, indem Sie Verbesserungen in Remotedateifreigabe-Protokollen und Netzwerkverbindungen mit hoher Bandbreite und niedriger Latenz verwenden.
Speicherplätze sind das einfachste Beispiel für softwaredefinierten Speicher in nicht gruppierten Szenarien.
Speicherplätze
Ein Speicherplatz ist eine Speichervirtualisierungsfunktion, die Microsoft in Azure Stack HCI, Windows Server und Windows 10 integriert hat. Dieses Speicherplätzefeature umfasst die folgenden beiden Komponenten:
- Speicherpools sind eine Sammlung physischer Datenträger, die auf einem logischen Datenträger aggregiert sind und die Sie als einzelne Entität verwalten können. Ein Speicherpool kann physische Datenträger jeglichen Typs und beliebiger Größen enthalten.
- Speicherplätze sind virtuelle Datenträger, die Sie aus freiem Speicherplatz in einem Speicherpool erstellen können. Virtuelle Datenträger entsprechen LUNs in einem SAN.
Gründe für die Verwendung von Speicherplätzen
Die häufigsten Gründe für die Verwendung von Speicherplätzen sind:
- Erhöhen des Resilienzniveaus von Speicher, z. B. Spiegelung und Parität. Die Resilienz virtueller Datenträger ähnelt den RAID-Technologien (Redundant Array of Independent Disks).
- Verbessern der Speicherleistung mithilfe von Speicherebenen. Mithilfe von Speicherebenen können Sie die Verwendung unterschiedlicher Datenträgertypen in einem Speicherplatz optimieren. Beispielsweise können Sie schnelle SSDs (Solid-State Drives), aber mit niedriger Kapazität, zusammen mit langsameren Festplatten, aber mit großer Kapazität, verwenden. Wenn Sie diese Kombination von Datenträgern verwenden, werden Daten, auf die häufig zugegriffen wird, durch Speicherplätze automatisch auf die schnelleren Datenträger verschoben. Anschließend werden Daten, auf die seltener zugegriffen wird, auf die langsameren Datenträger verschoben.
- Verbessern der Speicherleistung mithilfe von Zurückschreibcaches. Der Zweck von Zurückschreibcaches besteht darin, das Schreiben von Daten auf die Datenträger in einem Speicherplatz zu optimieren. Zurückschreibcaches funktionieren mit Speicherebenen. Wenn der Server, auf dem der Speicherplatz ausgeführt wird, eine Spitze bei Schreibaktivitäten auf Datenträgern erkennt, beginnt er automatisch mit dem Schreiben von Daten auf die schnelleren Datenträger.
- Erhöhen der Speichereffizienz mithilfe der schlanken Speicherzuweisung. Die schlanke Speicherzuweisung ermöglicht die sofortige Zuordnung von Speicher nach Bedarf. Bei einer herkömmlichen festen Speicherbelegungsmethode werden große Teile der Speicherkapazität vorab zugeordnet, bleiben aber möglicherweise ungenutzt. Die schlanke Speicherzuweisung optimiert den verfügbaren Speicher, indem nicht mehr benötigter Speicher durch einen sogenannten Trim-Vorgang zurückgewonnen wird.
Das einfachste Beispiel für softwaredefinierten Speicher in Clusterszenarien sind freigegebene Clustervolumes (CSV, Cluster Shared Volumes).
Freigegebene Clustervolumes
Freigegebenes Clustervolumes (CSV) sind ein gruppiertes Dateisystem, das es mehreren Knoten eines Failoverclusters ermöglicht, gleichzeitig aus demselben Satz von Speichervolumes zu lesen und in diese zu schreiben. Die CSV-Volumes werden Unterverzeichnissen im Verzeichnis „C:\ClusterStorage“ auf jedem Clusterknoten zugeordnet. Durch diese Zuordnung können Clusterknoten über denselben Dateisystempfad auf denselben Inhalt zugreifen. Obwohl jeder Knoten unabhängig vom anderen aus einzelnen Dateien auf einem bestimmten Volume lesen und in diese schreiben kann, erfüllt ein einzelner Clusterknoten die besondere Rolle des CSV-Besitzers (oder Coordinator) dieses Volumes. Sie haben die Möglichkeit, einem bestimmten Besitzer ein einzelnes Volume zuzuweisen. Ein Failovercluster verteilt den CSV-Besitz jedoch automatisch zwischen den Clusterknoten.
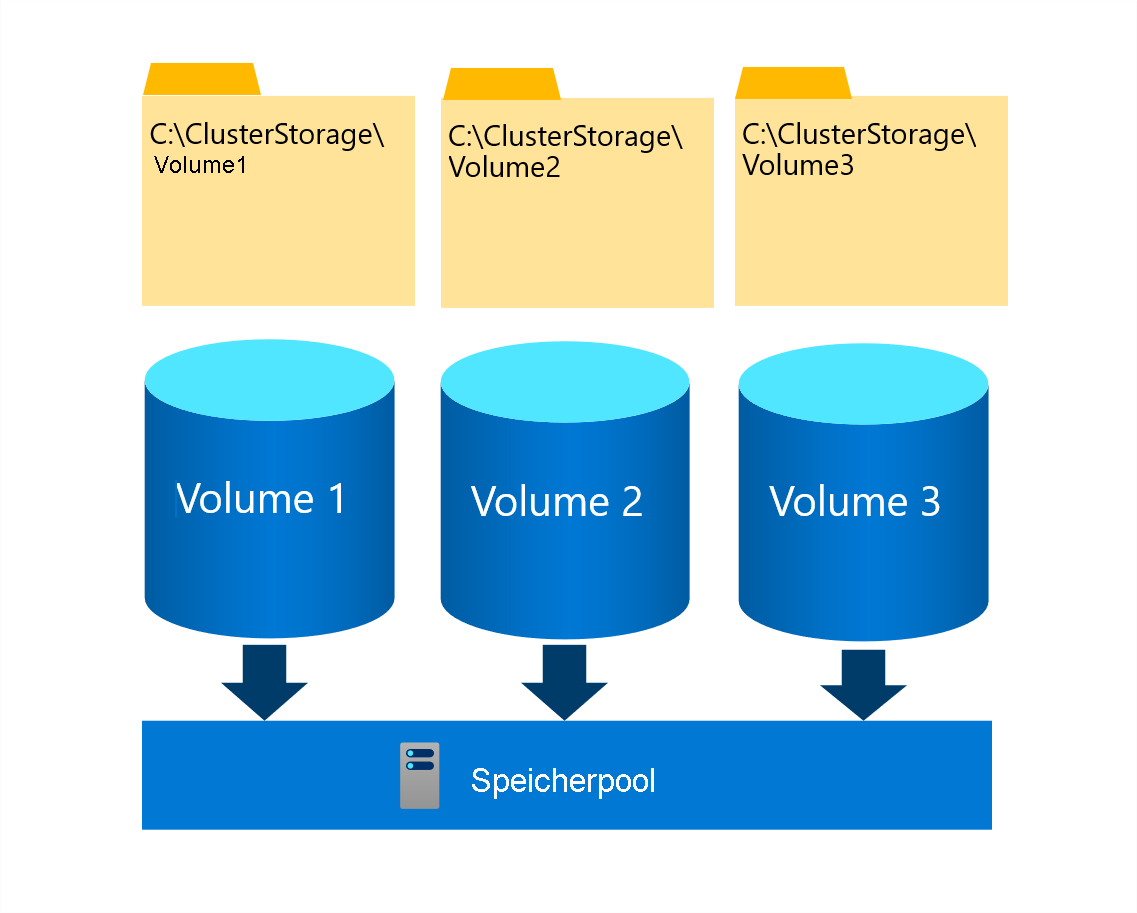
Wenn Änderungen an den Dateisystem-Metadaten auf einem CSV-Volume stattfinden, ist der Besitzer für deren Implementierung, die Verwaltung ihrer Orchestrierung und ihre Synchronisierung auf allen Clusterknoten mit Zugriff auf dieses Volume verantwortlich. Solche Änderungen umfassen das Erstellen oder Löschen einer Datei. Standardschreib- und -lesevorgänge zum Öffnen von Dateien auf einem CSV-Volume wirken sich jedoch nicht auf Metadaten aus. Effektiv kann jeder Clusterknoten mit direkter Verbindung zum zugrunde liegenden Speicher diese unabhängig ausführen, ohne sich auf den CSV-Besitzer dieses Volumes verlassen zu müssen.
Gründe für die Verwendung freigegebener Clustervolumes (CSV)
CSV wird am häufigsten für Folgendes verwendet:
- Gruppierte Hyper-V-VMs
- Horizontale Skalierung von Dateifreigaben, die Anwendungsdaten hosten, die über SMB 3.x zugänglich sind.
Server Message Block 3.x (SMB)
Das SMB-Protokoll ist ein Netzwerk-Dateifreigabeprotokoll, das Zugriff auf Dateien über ein herkömmliches Ethernet-Netzwerk mittels TCP/IP-Transportprotokoll bereitstellt. SMB dient als eine der Kernkomponenten softwaredefinierter Speichertechnologien. Microsoft hat SMB, Version 3.0, in Windows Server 2012 eingeführt und es in nachfolgenden Versionen immer wieder verbessert.
Gründe für die Verwendung von SMB
SMB wird am häufigsten für Folgendes verwendet:
- Speicher für VM-Datenträgerdateien (Hyper-V über SMB) Hyper-V kann VM-Dateien wie Konfigurations- VM-Datenträgerdateien und Prüfpunkte über das SMB 3.x-Protokoll in Dateifreigaben speichern. Sie können diese VM-Dateien sowohl für eigenständige Dateiserver als auch für gruppierte Dateiserver verwenden, die Hyper-V zusammen mit freigegebenem Dateispeicher für den Cluster verwenden.
- Microsoft SQL Server über SMB. SQL Server kann Benutzerdatenbankdateien auf SMB-Dateifreigaben speichern.
- Herkömmlicher Speicher für Endbenutzerdaten. Das SMB 3.x-Protokoll unterstützt die herkömmlichen Worker-Workloads.
SMB 3.x bietet Unterstützung für SMB Multichannel und SMB Direct.
SMB Multichannel
SMB Multichannel ist Teil der Implementierung des SMB 3.x-Protokolls, wodurch Netzwerkleistung und Verfügbarkeit von Geräten, auf denen Windows Server oder Azure Stack HCI-Clusterknoten, die als Dateiserver fungieren, ausgeführt werden, erheblich verbessert wird. SMB Multichannel ermöglicht es solchen Servern, mehrere Netzwerkverbindungen zu nutzen, um die folgenden Funktionen bereitzustellen:
- Erhöhter Durchsatz. Der Dateiserver kann mithilfe mehrerer Verbindungen gleichzeitig mehr Daten übertragen. SMB Multichannel ist von Vorteil, wenn Sie Server mit mehreren Hochgeschwindigkeits-Netzwerkadaptern verwenden.
- Automatische Konfiguration: SMB Multichannel erkennt automatisch mehrere verfügbare Netzwerkpfade und fügt Verbindungen nach Bedarf dynamisch hinzu.
- Netzwerkfehlertoleranz: Wenn eine vorhandene Verbindung aufgrund eines Problems entlang eines der Netzwerkpfade zu einem SMB 3.x-Server beendet wird, verfügen SMB 3.x-Clients über eine integrierte Möglichkeit, automatisch ein Failover auf einen anderen Pfad zu ausführen.
SMB Direct
SMB Direct optimiert die Verwendung von RDMA-Netzwerkadaptern (Remote Direct Memory Access, direkter Remotespeicherzugriff) für SMB-Datenverkehr, sodass sie bei sehr niedriger Latenz und geringer CPU-Auslastung mit voller Geschwindigkeit arbeiten können. Dadurch eignet sich SMB Direct für Szenarien, in denen Workloads wie Hyper-V oder Microsoft SQL Server SMB 3.x-Remotedateiserver verwenden, um lokalen Speicher zu emulieren. SMB Direct ist standardmäßig für alle derzeit unterstützten Versionen von Windows Server und Azure Stack HCI verfügbar und aktiviert.
SMB Multichannel ist verantwortlich für das Erkennen der RDMA-Funktionen von Netzwerkadaptern, die zum Aktivieren von SMB Direct erforderlich sind. Es erstellt automatisch zwei RDMA-Verbindungen pro Schnittstelle. SMB-Clients erkennen und verwenden automatisch mehrere Netzwerkverbindungen, wenn eine entsprechende Konfiguration identifiziert wird.
SMB 3.x-Technologien und CSV dienen als Basis für SOFS.
Dateiserver mit horizontaler Skalierung (SOFS)
SOFS ist ein CSV-basiertes Failoverclusteringfeature. Wenn Sie die Serverrolle „Dateidienste“ als Clusterrolle konfigurieren, können Sie sie als Dateiserver für die allgemeine Verwendung oder als Dateiserver mit horizontaler Skalierung für Anwendungsdaten einrichten. Die erste Option implementiert hochverfügbare freigegebene Ordner, auf die über einen der Clusterknoten zugegriffen werden kann. Wenn dieser Knoten ausfällt, übernimmt ein anderer Knoten den Besitz der Rolle und ihrer zugehörigen Ressourcen und erhält die Verfügbarkeit der freigegebenen Ordner aufrecht. Clients greifen jedoch immer über einen einzelnen Knoten auf sie zu. SOFS implementiert einen anderen Ansatz, bei dem sich freigegebene Ordner auf einem CSV-basierten Volume befinden.
Gründe für die Verwendung von SOFS
SOFS bietet folgende Vorteile:
- Verbesserte Skalierbarkeit Da Clients über mehrere Knoten auf freigegebene Ordner zugreifen, wenn die Menge an Zugriffsanforderungen zunimmt, können Sie dem SOFS einen zusätzlichen Knoten hinzufügen.
- Nutzung mit Lastenausgleich Alle Failoverclusterknoten können Clientlese- und -schreibanforderungen für einen oder mehrere SOFS akzeptieren und verarbeiten. Wenn Sie deren Bandbreite und die Prozessorleistung kombinieren, können Sie höhere Auslastungsraten erreichen, als bei jedem einzelnen Knoten. Ein einzelner Clusterknoten stellt keinen potenziellen Engpass mehr dar, weil SOFS so viele Clients unterstützen kann, wie alle Clusterknoten gemeinsam nutzen können.
- Unterbrechungsfreie Wartung, Updates und Knotenfehler Das Beheben von Problemen durch beschädigte Datenträger, das Durchführen von Wartungen sowie das Aktualisieren oder Neustarten eines Failoverclusterknotens wirken sich nicht auf die Verfügbarkeit eines SOFS aus. SOFS bieten auch transparentes Failover, das von einem Knotenausfall ausgelöst wird.
Sie können SOFS auch verwenden, um Gastclustering zu implementieren.
Gastclustering
Sie konfigurieren Gastfailoverclustering ähnlich wie Failoverclustering für physische Server, mit der Ausnahme, dass die Cluster Knoten virtuelle Computer (VMs) sind. In diesem Szenario erstellen Sie zwei oder mehr VMs und implementieren Failoverclustering in den Gastbetriebssystemen. Die Anwendung oder der Dienst kann dann die Hochverfügbarkeit zwischen den VMs nutzen. Obwohl Sie die VMs auf einem einzelnen Host platzieren können, sollten Sie in Produktionsszenarien separates Failoverclustering – aktivierte Hyper-V-Hostcomputer verwenden. Nachdem Sie Failoverclustering sowohl auf Host- als auch auf VM-Ebene implementiert haben, können Sie die Ressource auch dann neu starten, wenn eine VM oder ein Hostknoten ausfällt.
Hyper-V-VMs können freigegebenen Speicher verwenden, mit dem Sie mithilfe von Fibre Channel oder Internet SCSI (iSCSI) von den gruppierten VMs aus eine Verbindung herstellen können. Alternativ können Sie freigegebenen Speicher auf den gruppierten Hyper-V-Hosts mithilfe der Funktion für freigegebene virtuelle Festplatten konfigurieren und dann die freigegebenen Datenträger an gruppierte VMs anfügen.
Sie können freigegebene virtuelle Festplatten in den folgenden Szenarien nutzen:
- CSV auf dem Hyper-V-Hostcluster In diesem Szenario werden alle Dateien des virtuellen Computers, einschließlich der freigegebenen virtuellen Festplattendateien, in einem CSV gespeichert, das als freigegebener Speicher für gruppierte VMs konfiguriert ist.
- SOFS auf einem gesonderten Speichercluster Dieses Szenario verwendet SMB-dateibasierten Speicher als Speicherort für die freigegebenen virtuellen Festplattendateien.
In beiden Szenarien können Sie mithilfe von „Direkte Speicherplätze“ Speicher implementieren.
Speicherplätze direkt
„Direkte Speicherplätze“ ist die Weiterentwicklung von Speicherplätzen. Dieses Feature nutzt Speicherplätze, Failoverclustering, CSVs und SMB 3.x, um virtualisierten, hochverfügbaren Clusterspeicher mithilfe lokaler Datenträger auf den einzelnen Clusterknoten von „Direkte Speicherplätze“ zu implementieren. Es eignet sich für das Hosting hochverfügbarer Workloads, einschließlich VMs und SQL Server-Datenbanken. Durch „Direkte Speicherplätze“ entfällt die Notwendigkeit, in Failoverclustering-Szenarien Speichergeräte an mehrere Clusterknoten anzufügen.
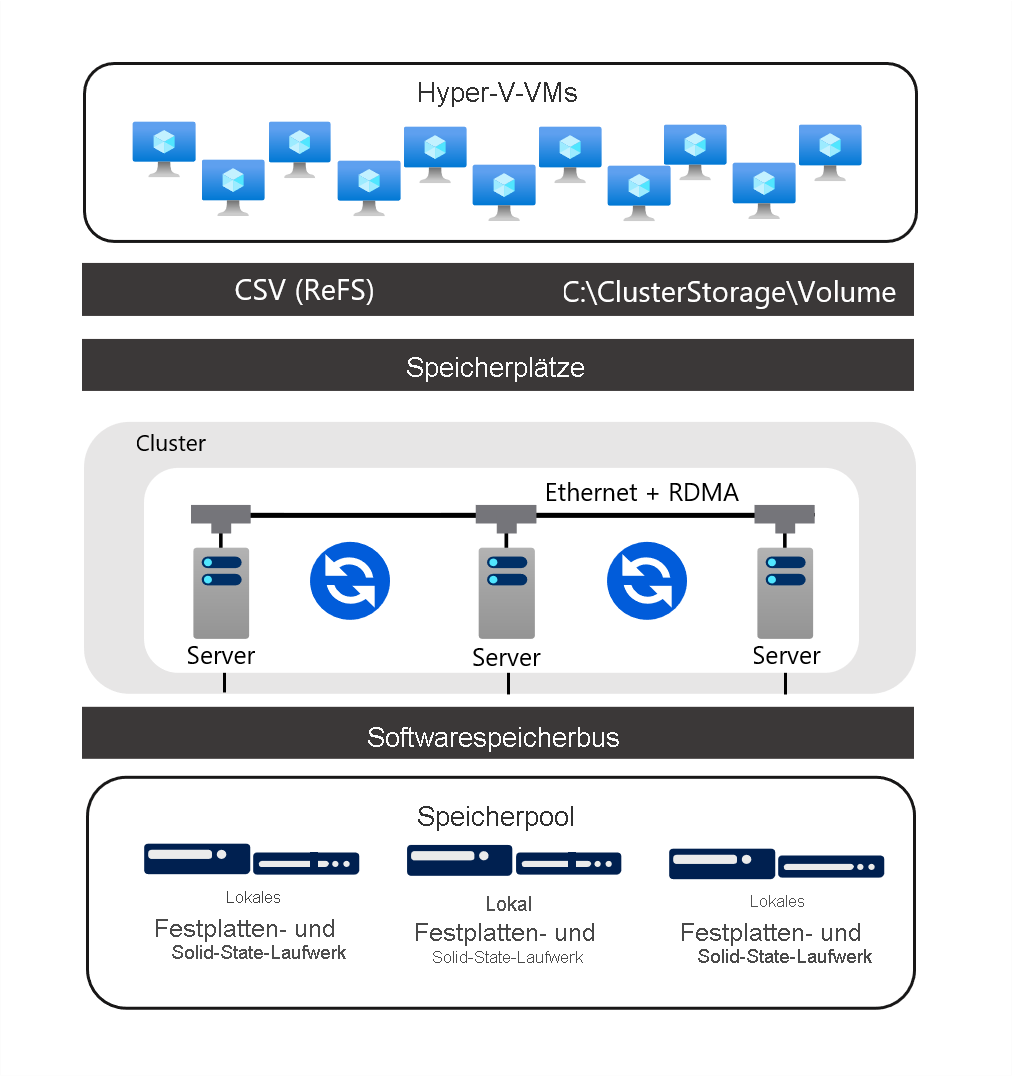
Die Verwendung von lokalen Datenträgern auf diese Weise erfordert ein Netzwerk mit hoher Bandbreite und niedriger Latenz zwischen den Knoten. Um diese Anforderung zu erfüllen, sollten Sie redundante Netzwerkverbindungen in Kombination mit High-End-RDMA-Netzwerkadaptern bereitstellen. Durch diese Architektur können Sie von Technologien wie SMB 3.x, SMB Direct und SMB Multichannel profitieren, um schnellen, CPU-effizienten Speicherzugriff mit geringer Latenz zu ermöglichen.
Hyper-V-Workloadmodelle von „Direkte Speicherplätze“
Es gibt zwei Bereitstellungsmodelle für Hyper-V-Workloads mithilfe von „Direkte Speicherplätze“:
- Verteilt In dem verteilten Modell befinden sich die Hyper-V-Hosts (Compute) in einem von den „Direkte Speicherplätze“-Hosts (Speicher) getrennten Cluster. Sie konfigurieren Hyper-V-VMs so, dass ihre Dateien im Speichercluster gespeichert werden. Hierzu verwenden Sie SOFS, sodass Sie den Hyper-V-Cluster (Compute) und den S2D-basierten Cluster (Speicher) unabhängig voneinander skalieren können.
- Hyperkonvergent In dem hyperkonvergenten Modell fungieren die Clusterknoten sowohl als Hyper-V-Hosts (Compute) als auch als „Direkte Speicherplätze“-Hosts (Speicher). Bei diesem Bereitstellungsmodell befinden sich Compute und Speicher zusammen in derselben Gruppe von Clusterknoten. Um den Cluster hochzuskalieren, müssen Sie die Anzahl seiner Knoten erhöhen.
Hinweis
Azure Stack HCI ist ein Beispiel für das hyperkonvergente Modell, das keine SOFS verwendet.
Um zusätzliche Resilienz für Ihre Hyper-V-Workloads bereitzustellen, können Sie Speicherreplikate verwenden.
Speicherreplikat
Das Speicherreplikat ermöglicht eine speicheragnostische, synchrone oder asynchrone Replikation auf Blockebene zwischen Servern oder Clustern über verschiedene physische Standorte hinweg.
Gründe für die Verwendung des Speicherreplikats
Mithilfe des Speicherreplikats können Sie gestreckte Failovercluster erstellen, die sich über zwei unterschiedliche physische Standorte erstrecken, wobei alle Knoten synchron bleiben. Bei der synchronen Replikation werden Volumes zwischen Standorten in relativer Nähe zueinander repliziert. Replikation ist absturzkonsistent, was dabei hilft, sicherzustellen, dass es bei einem Failover auf Dateisystemebene zu keinen Datenverlusten kommt. Die asynchrone Replikation ermöglicht die Replikation über größere Entfernungen hinweg in Fällen, in denen die Netzwerkroundtrip-Latenz 5 Millisekunden (ms) überschreitet. Hierbei können allerdings Datenverluste auftreten. Der Umfang der Datenverluste hängt von der Verzögerung der Replikation zwischen den Quell- und Zielvolumes ab.
Hinweis
Gestreckte Azure Stack HCI-Cluster verwenden Speicherreplikate.