Fehler und Fehlertoleranz
Im Alltag wird meist locker über die Gründe für Systemausfälle gesprochen. Für verschiedene Fehler werden einige Begriffe austauschbar verwendet: Error, Fault, Failure, Bug und Defect. Im Rechenzentrum sollten Experten diese Begriffe nie verwechseln oder austauschbar verwenden. Im Folgenden werden diese Begriffe im Bezug zur Fehlertoleranz ausführlich definiert:
Bug: Dieser Fehler bezeichnet eine Anomalie im Design eines Systems, durch die das Verhalten des Systems konsistent von den Anforderungen oder Erwartungen abweicht. In gewisser Weise ist es ein Fehler im System oder in der Software, durch den die Erwartungen nicht erfüllt werden, aber ein Bug ist kein Systemfehler. Tatsächlich sind viele Bugs das Produkt von Systemen, die genau so funktionieren, wie sie entworfen wurden. Das Schlüsselwort ist hier „konsistent“. Das Verhalten eines Bugs kann in allen Instanzen des Systems reproduziert werden. Das Debuggen bezeichnet die Umgestaltung des Systems zum Entfernen von Bugs.
Fault: Dieser Fehler bezeichnet eine Anomalie in einem System, durch die es sich nicht entwurfsgemäß verhält oder gar nicht mehr reagiert. In diesem Fall liegt womöglich kein Problem mit dem Design des Systems vor, jedoch funktioniert es in einer Implementierung oder Instanz nicht ordnungsgemäß. Diese Art von Fehler führt zu Verhalten, das nicht in anderen Instanzen des Systems reproduziert werden kann. Die Beseitigung dieser Art von Fehler wird als Reparatur bezeichnet. Ein Systemfehler kann sich auf drei verschiedene Weisen ergeben:
Ein permanenter Fehler ist eine Systemunterbrechung, deren Ursache nicht repariert werden kann, ohne die verantwortliche Komponente vollständig zu ersetzen.
Ein vorübergehender Fehler ist eine temporäre, sich in der Regel nicht wiederholende, Systemunterbrechung, deren Ursache direkt repariert oder behoben werden kann. Diese Art von Fehler kann sich auch von selbst lösen.
Ein zeitweiliger Fehler ist eine temporäre, wiederkehrende Systemunterbrechung, die meist durch eine Leistungsminderung oder einen fehlerhaften Entwurf einer Komponente verursacht wird. Diese Art von Fehler kann zu permanenten Fehlern führen, wenn sie nicht behoben werden.
Failure: Diese Art von Fehler bezeichnet den vollständigen Ausfall des gesamten oder eines Teils des Systems und wird meist durch nicht behobene Fehler ausgelöst. In diesem Fall ist der Systemfehler die Ursache und der Ausfall das Ergebnis. Ein fehlertolerantes System ist eines, das sich unter nachteiligen Umständen wie erwartet oder im Einklang mit den Erwartungen gemäß der Vereinbarung zum Servicelevel verhält, auch wenn Fehler auftreten.
Defect: Dieser Fehler bezeichnet eine Anomalie bei der Herstellung einer Hardwarekomponente oder der Instanziierung einer Softwarekomponente, die zu einem Fehler im Betrieb und vermutlich zum Ausfall eines Systems führt, das diese Komponente implementiert. Eine solche Anomalie kann nur durch Ersetzen der Komponente behoben werden.
Error: Diese Art von Fehler ist das Produkt eines Vorgangs, der zu einem unerwünschten oder fehlerhaften Ergebnis führt. Bei einem Computergerät kann ein Fehler dieser Art ein Anzeichen für ein Bug im Design oder ein Fault in der Implementierung sein. Dies kann wiederum ein effektiver Indikator für einen bevorstehenden Ausfall sein.
Für die Wartung fehlertoleranter Systeme ist erforderlich, dass ein IT-Experte, Administrator oder Operator diese Konzepte und ihre Unterschiede versteht. Eine Cloud Computing-Plattform ist definitionsgemäß ein fehlertolerantes System. Diese wurde in Erwartung von Fehlern entworfen und erstellt, und sie dient zur Vermeidung von Dienstausfällen. Aus technischer Sicht ist diese Resilienz der Kern der Konzepts der Cloud. Als Telekommunikationstechniker zuerst eine Wolkenform in ihren Systemdiagrammen verwendeten, stellte diese die Komponenten des Netzwerks dar, die nicht gesehen oder verstanden werden müssen. Diese Servicelevel waren jedoch ausreichend zuverlässig, sodass sie nicht im Diagramm enthalten sein müssen, daher konnten sie von einer Wolke verdeckt werden.
Wenn ein Informationssystem, z. B. das IT-System eines Unternehmens, Kontakt mit einer öffentlichen Cloudplattform herstellt, ist diese Plattform dazu verpflichtet, sich wie ein fehlertolerantes System zu verhalten. Allerdings kann sie nicht zur Fehlertoleranz des Systems beitragen, mit dem sie kommuniziert. Die Fehlertoleranz stellt weder eine Immunität noch eine Garantie dafür dar, dass keine Fehler in einem System existieren. Genauer gesagt ist ein fehlertolerantes System nicht unbedingt fehlerfrei. Stattdessen bezeichnet die Fehlertoleranz die Fähigkeit eines Systems, die erwarteten Servicelevel beizubehalten, wenn Fehler vorliegen.
Der Zweck eines jeden Informationssystems besteht darin, die Funktionen zu automatisieren, die Informationen nutzen. Die Fehlertoleranz selbst kann nur begrenzt automatisiert werden. Das Internet, in seiner ursprünglichen Fassung als ARPANET, umfasste die Fehlertoleranz als eines der Hauptziele. In einem Notfall könnte die digitale Kommunikation umgeleitet werden, um ein System zu umgehen, dessen Adresse nicht mehr erreichbar ist. Dennoch ist das Internet, ebenso wie kein anderes Informationssystem, kein sich selbst erhaltender Computer.
Für alle Informationssysteme ist kontinuierliche menschliche Bemühung erforderlich, damit die Serviceziele erreicht und beibehalten werden können. Bei den besten Systemen sind der Eingriff und die Wartung für Menschen einfach, sofort und plangemäß.
Fehlertoleranz in Cloudplattformen
Frühe Clouddienstplattformen waren, gelinde gesagt, weniger Fehlertolerant als ihre Architekten es wünschten. Beispielsweise erwies sich die Fähigkeit für Kunden, übermäßige Ressourcen für Dienste bereitzustellen, z. B. mehrere Datenbankinstanzen oder duplizierte Arbeitsspeichercaches, bei unzureichender Überwachung als ineffektiv, da dies in manchen Fällen bei Notfallsituationen zu nicht verfügbaren Sicherungen oder Replikaten führte. Außerdem verstößt die übermäßige Bereitstellung von Ressourcen gegen eines der Grundprinzipien des Cloudgeschäftsmodells: nur für die Ressourcen zu zahlen, die benötigt werden. Eine Organisation kann keine Betriebskosten sparen, wenn sie zusätzliche VM-Instanzen für den Fall beansprucht, dass die primäre VM ausfällt.
Ein fehlertolerantes System ermöglicht Redundanz auf eine vernünftige und dynamische Weise, bei der die Anforderungen und Einschränkungen der Ressourcenverfügbarkeit zum aktuellen Zeitpunkt beachtet werden. In den Zeiten von Clients und Servern wurden gesamte Server regelmäßig gesichert, einschließlich ihrer lokalen Datenspeicher und der Netzwerkspeichervolumes, an die sie angefügt waren. „Alles sichern“ wurde zu einer Unternehmensethik. Sobald öffentliche Clouddienste sowohl bezahlbar als auch praktikabel wurden, nutzten Organisationen sie, um „alles zu sichern“. Mit der Zeit realisierten sie, dass die Cloud zu mehr fähig ist, als nur die alten Methoden fortbestehen zu lassen. Cloudplattformen können von Anfang an für die Fehlertoleranz konzipiert werden, anstatt die Fehlertoleranz nach der Implementierung zu integrieren.
Reaktive Techniken
Unabhängig davon, wie sorgfältig ein System entworfen wird, hängt der Großteil der Fehlertoleranz davon ab, wie gut das System und die Personen, die es verwalten, auf die ersten Anzeichen eines Fehlers reagieren. Im Folgenden werden einige reaktive Techniken aufgeführt, die Organisationen zum Beheben von Fehlern verwenden, wenn sie auftreten.
Nicht-vorbeugende Auftragsmigration
Mit dem Verfahren zur nicht-vorbeugenden Auftragsmigration wird sichergestellt, dass der Host einer Workload, bei der offensichtlich ein Fehler aufgetreten ist, nicht zum Hosten derselben Workload zugewiesen wird. Dadurch wird der „Auftrag“ geschützt, obwohl das System daran gehindert werden könnte, wiederholte Instanzen eines Fehlers als Beweis für Systemfehler zu erfassen, was über einen gut protokollierten Pfad einfacher nachverfolgt werden könnte.
Replikation von Tasks
Viele verteilte Informationssysteme führen mehrere Instanzen (bzw. Replikate bei der Kubernetes-Orchestrierung) eines Tasks gleichzeitig aus. Richtlinienbasierte Verwaltungssysteme können so konzipiert werden, dass sie einen Task replizieren, wenn ein offensichtlicher oder vermuteter Systemfehler vorliegt.
Prüfpunkte und Wiederherstellungspunkte
Im Grunde genommen geht es bei Prüfpunkten und Wiederherstellungspunkten darum, Momentaufnahmen eines Systems an verschiedenen Zeitpunkten zu erstellen, wodurch Administratoren einen „Rollback“ auf einen bestimmten Zeitpunkt ausführen können, sollte eine Wiederherstellung erforderlich sein. Diese Strategie wird komplizierter, wenn Transaktionen beteiligt sind, z. B., wenn eine Anwendung mindestens zwei Aktionen für eine Datenbank ausführt, die als Einheit (eine „Transaktion“) erfolgreich ausgeführt werden oder fehlschlagen müssen. Ein gängiges Beispiel sind Anwendungen, die Geld von einem Konto gutschreiben, während sie von einem anderen abbuchen. Diese Vorgänge müssen als Einheit erfolgreich ausgeführt werden oder fehlschlagen, damit keine finanziellen Ressourcen erstellt oder gelöscht werden.
In einem transaktiven Prüfpunktwiederherstellungssystem werden wiederherstellbare Datensätze von Transaktionen in einer Prozessstruktur im Arbeitsspeicher gespeichert. An bestimmten Punkten während einer Transaktionen werden die verwendeten Arbeitsspeicherressourcen repliziert und in einem Wiederherstellungspool abgelegt. Wenn die Protokollanalyse einen möglichen Systemfehler aufgrund von Software angibt, wird die Prozessstruktur verzweigt, der Transaktionsstatus wird auf einen früheren Zeitpunkt zurückgesetzt und eine neue Transaktion wird versucht. Wenn die neue Transaktion bessere Ergebnisse als die fehlerhafte Transaktion erzielt (z. B. wenn ein Fehlerkorrekturtest ohne Ergebnisse zurückgegeben wird), wird der alte Prozessbranch gelöscht und der neue Branch wird ab diesem Punkt weiter in der Struktur verfolgt. Unter Engineers wird dies als Kontextwechsel bezeichnet.1
Eine ausgereifte Version dieser Methodik implementiert ein Nachverfolgungssystem innerhalb der Prozessstruktur, sodass das System den Prozess zur Ursache des Fehlers zurückverfolgen kann, wenn ein Fehler nochmal auftritt. Dann kann ein geeigneter Wiederherstellungspunkt ausgewählt werden, bevor der Fehler ausgelöst wird.[2]
Eine andere Implementierung namens „SGuard“ wurde von Forschern der University of Washington und Microsoft Research für die fehlertolerante Verarbeitung großer Datenströme erstellt. SGuard nutzt HDFS (Hadoop Distributed File System), um das gleichzeitige Schreiben mehrerer Momentaufnahmen von Datenströmen während der Verarbeitung zu planen. Diese Momentaufnahmen werden nach Bedarf in kleinere Teile aufgeteilt, wobei die Datenstromverarbeitung wiederum in kleinere Segmente unterteilt wird. Prüfpunkte werden in HDFS gespeichert. Dieses System hat den Vorteil, dass ein Datensatz von Streamingdatentransaktionen sowie mehrere gültige Replikate von Streamingdaten in weit verstreuten Standorten verwaltet werden. Obwohl für die Implementierung von SGuard ein hohes Maß an Vorbereitungen erforderlich ist, wird die Implementierung dennoch als reaktives Fehlertoleranzverfahren betrachtet, da der Hauptvorgang als Reaktion auf ein Fehlerereignis ausgelöst wird.3
Proaktive Techniken
Proaktive Fehlertoleranztechniken werden angewendet, bevor überhaupt bekannt ist, dass ein Fehler existiert. Ziel ist es, präventiv zu handeln. Allerdings wird dies in der modernen Implementierung eher zu einer Methodik als zu einem Mantra. Im Folgenden sind einige Techniken aufgeführt, die derzeit von modernen Cloudplattformen verwendet werden.
Replikation von Ressourcen
Der Schlüssel zu einer wirksamen Replikationsstrategie für Ressourcen ist möglicherweise nicht, einfach „alles zu sichern“. Systemanalysten sollten in der Lage sein, zu erkennen, welche Ressourcen in einem System (z. B. Datenbank-Engine, Webserver oder virtueller Netzwerkrouter) sich nach einem Ausfall selbst wiederherstellen können und welche möglicherweise nicht wiederherstellbar sind. Eine durchdachte Replikation kann die erste Verteidigungslinie in einem fehlertoleranten System sein.
Es gibt vier gängige Strategien zur Implementierung der Replikation von Ressourcen, die alle in Abbildung 1 dargestellt sind:
Aktive Replikation: Alle replizierten Ressourcen sind gleichzeitig aktiv, wobei jede davon über einen eigenen, unabhängigen Zustand verfügt – ihre eigenen lokalen Daten, die dafür sorgen, dass sie funktioniert. Diese Eigenschaft sorgt dafür, dass Anforderungen von Clients von allen replizierten Ressourcen in einer Klasse empfangen werden und alle Ressourcen eine Antwort verarbeiten. Allerdings wird nur die Antwort der als primäre Ressource in dieser Klasse festgelegten Ressource an den Client übermittelt. Wenn eine Ressource ausfällt, auch wenn es sich dabei um den primären Knoten handelt, wird ein anderer Knoten als Nachfolger festgelegt. Für dieses System ist erforderlich, dass die Verarbeitung durch den primären Knoten und die entsprechenden Replikatknoten deterministisch ist. Sie muss zeitgleich und nach einem festgelegten Muster erfolgen.
Semiaktive Replikation: Die semiaktive Replikation ähnelt der aktiven Replikation, wobei der Unterschied darin besteht, dass Replikatknoten Anforderungen möglicherweise nicht deterministisch oder nicht zeitgleich mit dem primären Knoten verarbeiten. Die Ausgabe der sekundären Ressourcen wird unterdrückt und protokolliert, und es kann zu diesen Ressourcen gewechselt werden, wenn die primäre Ressource ausfällt.
Passive Replikation: Nur der primäre Ressourcenknoten verarbeitet Anforderungen, während die anderen (die Replikate) ihren Zustand beibehalten und darauf warten, dass sie bei einem Ausfall als primäre Knoten festgelegt werden. Die primäre Ressource, mit der der Client kommuniziert, übermittelt Zustandsänderungen an alle Replikate. Alle Originale und Replikate, die zu einer Klasse gehören, werden als „Mitglieder“ einer Gruppe angesehen, und Mitglieder können aus der Gruppe entfernt werden, wenn es so wirkt, als sei das entsprechende Mitglied ausgefallen (auch wenn dies nicht tatsächlich der Fall ist). Es ist möglich, dass es bei Ausfällen zu Wartezeiten oder einer Verschlechterung der Dienstqualität kommt, auch wenn die passive Replikation im normalen Betrieb weniger Ressourcen verbraucht.
Semipassive Replikation: Bei dieser Methode ist das Beziehungsmuster dasselbe wie bei der passiven Replikation bis auf die Tatsache, dass es keine ständige primäre Ressource gibt. Stattdessen wird die Rolle des Koordinators allen Ressourcen im Wechsel zugewiesen, wobei der Wechsel mithilfe eines Tokenweitergabemodells koordiniert wird, welches als Rotating Coordinator Paradigm (Paradigma des wechselnden Koordinators) bezeichnet wird.
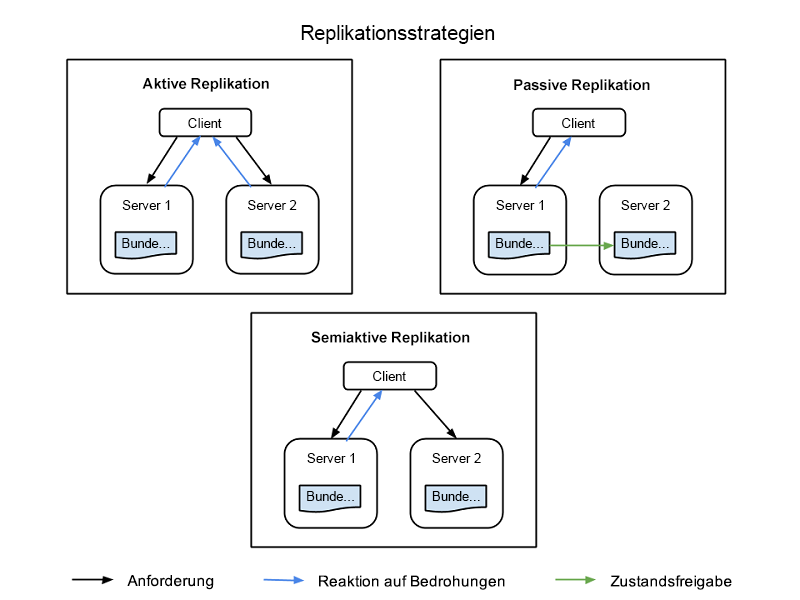
Abbildung 1: Clientknoten, primäre Knoten und Replikatknoten in einem replizierten Informationssystem
Lastenausgleich
Lastenausgleiche verteilen Anforderungen verschiedener Clients auf mehrere Server, auf denen die gleiche Anwendung ausgeführt wird, wodurch die Arbeitsauslastung verteilt und die Belastung für die einzelnen Systemkomponenten reduziert wird. Ein positiver Nebeneffekt der Verwendung von Lastenausgleichen ist, dass manche den Datenverkehr automatisch von nicht reagierenden Servern fernhalten, wodurch die Wahrscheinlichkeit eines Totalausfalls verringert wird. In moderneren Varianten, bei denen die Software so gestaltet ist, dass sie über eine Cloudplattform verteilt ist, (z. B. Microservices) werden Workloads auf verschiedene separate Funktionen aufgeteilt, die wiederum auf serverseitige Prozessoren verteilt sind, um eine gleichmäßige Verteilung und ein moderates Auslastungsniveau zu erreichen.
Virtualisierung (das Hauptmerkmal von Cloud Computing) ermöglicht eine gleichmäßigere Verteilung von Workloads auf Prozessoren, indem es sie portierbar macht, sodass sie auf den physischen Prozessor verschoben werden können, der sie optimal nutzen kann. Diese Technik wird durch Containerisierung verbessert, indem virtualisierte Workloads von virtuellen Prozessoren getrennt werden, sodass sie sich in dem Serverknoten befinden, dessen Betriebssystem am besten für sie geeignet ist. Dieses Prinzip ist essenziell für die Orchestrierung von Workloads, wie sie in Systemen wie Kubernetes erfolgt.
Verjüngung und Neukonfiguration
In Informationssystemen, in denen Softwareinstanzen für längere Zeiträume bereitgestellt werden, wird möglicherweise ein Neustart dieser Software erforderlich. Während manche früheren Cloudplattformen das Servicelevel von Softwareinstanzen im Laufe der Zeit stichprobenartig überprüften, um festzustellen, wann ein Neustart erforderlich war, wurde bei neueren Cloudplattformen auf die einfachere Methode der Planung regelmäßiger Neustarts umgestiegen. Während dieser Neustartphasen werden Konfigurationsdateien für den Start möglicherweise automatisch angepasst, um geänderte Systembedingungen zu berücksichtigen oder einen möglichen Ausfall nach dem Start zu verhindern.
Präemptive Migration
Als Virtualisierung in Rechenzentren erstmals üblich wurde, wurde präemptive Migration als Methode vorgeschlagen, um eine gleichmäßige Verteilung der Belastung der Serverhardware durch Rotieren der den Prozessoren zugewiesenen Workloads zu erreichen, zum Beispiel reihum. Cloudplattformen verteilen Workloads innerhalb der virtuellen Infrastruktur so oft neu, dass diese Methode weitgehend überflüssig geworden ist. Allerdings ist dieses Thema in aktuellen Diskussionen im Zusammenhang mit Methoden für das Vorhersagen von Arbeitsauslastungen in diversen Informationssystemen mithilfe von künstlicher Intelligenz wieder aufgekommen. Solche Systeme könnten ihre eigenen Regeln erstellen, um kritischere Workloads von Serverknoten, für die eine höhere Ausfallwahrscheinlichkeit vorhergesagt wird, fernzuhalten.
Selbstreparatur
In weit verteilten Informationssystemen wie Content Delivery Networks (CDNs) oder Social-Media-Plattformen sind die Funktionen einzelner Server möglicherweise auf zahlreiche Adressen verteilt, typischerweise an verschiedenen Standorten oder in verschiedenen Rechenzentren. Selbstreparierende Netzwerke überprüfen regelmäßig den Datenverkehrsfluss und die Reaktionsfähigkeit der verschiedenen Verbindungen (wie eine Leistungsverwaltungsplattform). Immer wenn Soll- und Ist-Leistung nicht übereinstimmen, können Router Anforderungen an die verdächtigen Komponenten an andere Komponenten umleiten und so schließlich den Datenverkehrsfluss durch die verdächtigen Komponenten stoppen. Anschließend kann der Betriebszustand dieser Komponente auf Anzeichen von Fehlern getestet werden. Die Komponente kann dann neu gestartet werden, um zu überprüfen, ob das Verhalten fortbesteht, und wird nur in den aktiven Zustand zurückversetzt, wenn es der Diagnose zufolge nicht wahrscheinlich ist, dass ein Fehler auftritt. Diese Art von automatisierter Transaktionsreaktionsfähigkeit ist ein aktuelles Beispiel für die Selbstreparatur in Rechenzentren, die weit verteilt sind.4
Tauschbasierte Prozessplanung
Cloudplattformen (was öffentliche cloudbasierte Dienste umfasst, aber auch lokale Infrastruktur umfassen kann) können auf eine einzigartige Weise ihren eigenen Zustand melden. Als Amazon 2009 damit begann, ein überarbeitetes SaaS-Modell zu implementieren, entwickelten die Entwickler ein Konzept namens Spot Instance Scheduling (Spot-Instance-Planung). In diesem System kündigt ein für den Kunden agierender stummer Proxy die Ressourcenanforderungen für einen bestimmten Vorgang an und übermittelt eine Art „Ausschreibung“, die sich insbesondere an Serverknoten in der Cloudplattform richtet. Jeder Knoten meldet, ob er selbst die Anforderungen dieses Auftrags in Bezug auf Zeit und verwendete Ressourcen erfüllen kann. Der günstigste Bieter bekommt den Vertrag und wird als Spot-Instance (SI) für den Vorgang ausgewählt. Diese Art der Planung ist aktuell für Amazon Elastic Compute Cloud verfügbar.5
References
Ioana, Cristescu. A Record-and-Replay Fault Tolerant System for Multithreading Applications (Ein auf Aufzeichnung und Wiedergabe basierendes fehlertolerantes System für Multithreadinganwendungen). Technische Universität Klausenburg. http://scholar.harvard.edu/files/cristescu/files/paper.pdf.
Sidiroglou, Stelios, et al.ASSURE: Automatic Software Self-healing Using Rescue Points (Automatische Software-Selbstreparatur mithilfe von Rettungspunkten) University, 2009.
Kwon Yong-Chul, et al. Fault-tolerant Stream Processing Using a Distributed, Replicated File System (Fehlertolerante Verarbeitung von Datenströmen mithilfe eines verteilten replizierten Dateisystems). Association for Computing Machinery, 2008. https://db.cs.washington.edu/projects/moirae/moirae-vldb08.pdf.
Yang, Chen. Checkpoint and Restoration of Micro-service in Docker Containers (Prüfpunkte und Wiederherstellung von Microservices in Docker-Containern). School of Information Security Engineering, Shanghai Jiao Tong University, China, 2015. https://download.atlantis-press.com/article/25844460.pdf.
Amazon Web Services, Inc. Spot Instance Requests (Spot-Instance-Anfragen) Amazon, 2020. https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/spot-requests.html.