Übung: Identifizieren von Komponenten der modernen Data Warehouse-Architektur
Ein Data Warehouse bietet mehr als nur die Speicherung von Unternehmensdaten. Daten wachsen mit jedem Jahr exponentiell. Das bezieht sich nicht nur auf die Menge der Daten, sondern auch auf die Vielzahl der Daten: von strukturierten über teilweise strukturierte bis hin zu größtenteils unstrukturierten Daten, die verwaltet werden müssen. Die Geschwindigkeit und Vielzahl der Daten führt zu Herausforderung bei der Datentechnik hinsichtlich der Erfassung, Transformation und Vorbereitung der Daten für maschinelles Lernen, Berichterstellung und andere Zwecke.
Das moderne Data Warehouse soll diese Herausforderungen bewältigen. Ein gutes Data Warehouse bietet Mehrwert, indem es beispielsweise als zentraler Speicherort für all Ihre Daten fungiert, mit den im Laufe der Zeit wachsenden Daten skaliert und vertraute Tools sowie ein vertrautes Ökosystem für Ihre technischen Fachkräfte für Daten, Data Analysts, wissenschaftliche Fachkräfte für Daten und Entwickler bereitstellt.
Im Folgenden werden diese einzelnen Elemente ausführlicher untersucht.
Ein Ort für all Ihre Daten
Mit einem modernen Data Warehouse verfügen Sie bei der Verwendung von Synapse Analytics über einen Hub für alle Daten.
Synapse Analytics ermöglicht es Ihnen, Daten aus mehreren Datenquellen über die Orchestrierungspipelines zu erfassen.
Wählen Sie den Integrationshub aus.
Im Hub „Integration“ können Sie Integrationspipelines verwalten. Wenn Sie mit Azure Data Factory (ADF) vertraut sind, sollte dieser Hub Ihnen sehr vertraut erscheinen. Die Pipelineerstellung erfolgt genauso wie in Azure Data Factory. Dies stellt eine weitere leistungsstarke Integration in Azure Synapse Analytics dar, durch die die Notwendigkeit entfällt, Azure Data Factory für Datenverschiebungs- und Datentransformationspipelines zu verwenden.
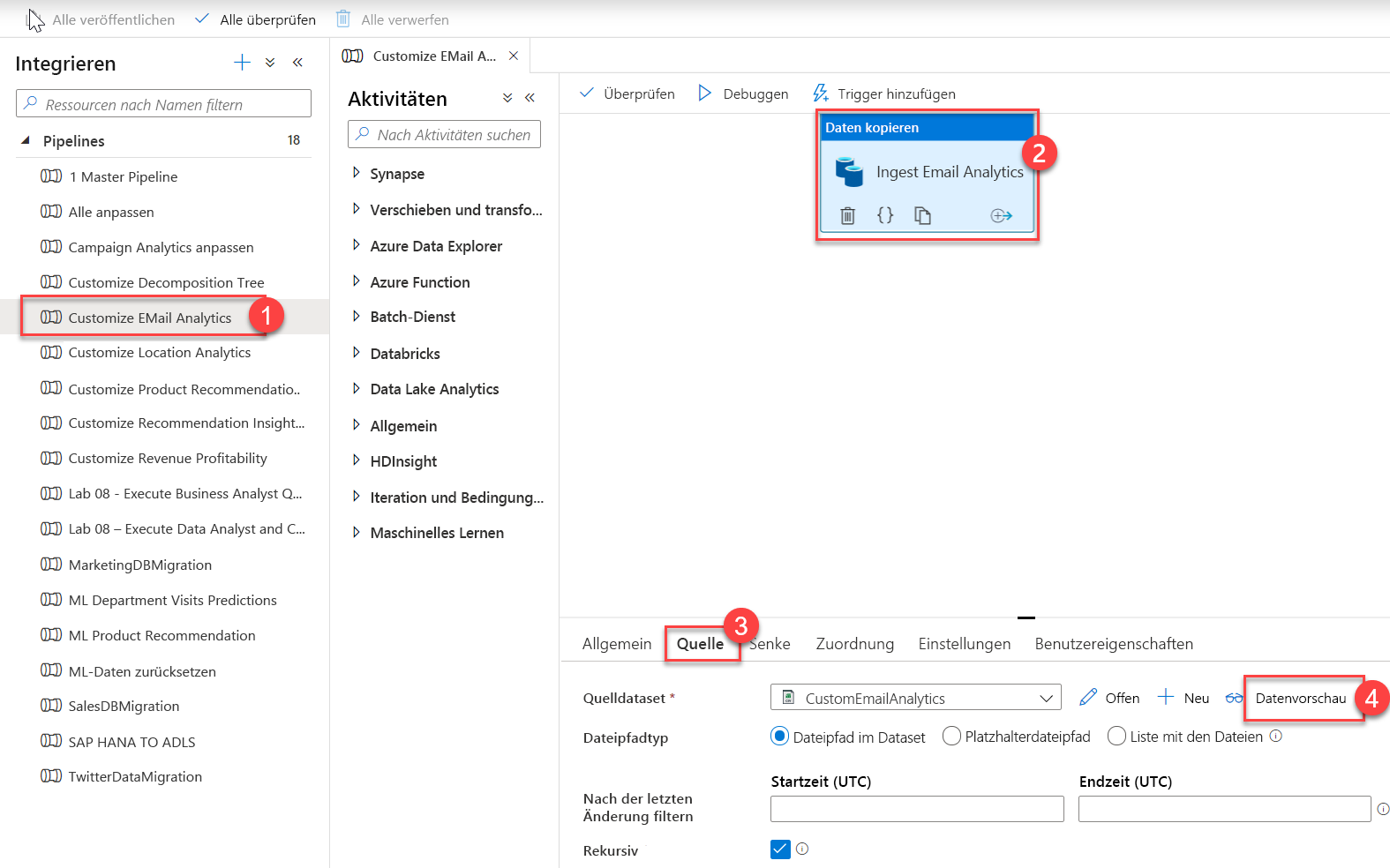
Erweitern Sie „Pipelines“, und klicken Sie auf Customize EMail Analytics (1) (E-Mail-Analyse anpassen). Wählen Sie die Aktivität Daten kopieren auf dem Canvas (2) aus, klicken Sie auf die Registerkarte Quelle(3), und klicken Sie dann auf Datenvorschau (4).
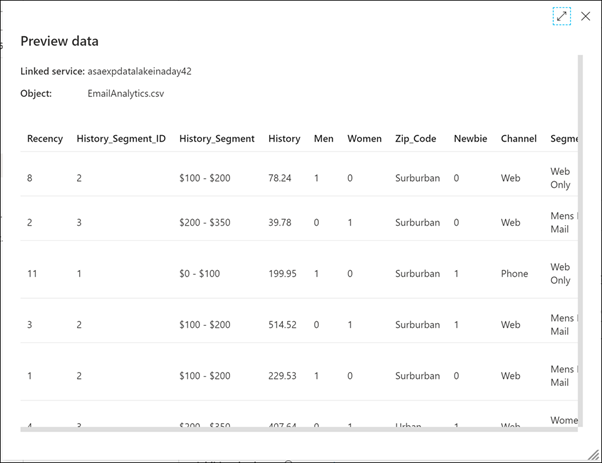
Hier sehen Sie die CSV-Quelldaten, die von der Pipeline erfasst werden.
Schließen Sie die Vorschau, und klicken Sie neben dem Quelldataset CustomEmailAnalytics auf Öffnen.
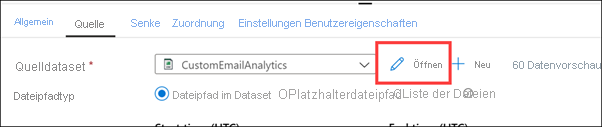
Zeigen Sie den Verknüpften Dienst, der der Datasetverbindung zugeordnet ist, und den CSV-Dateipfad (1) an. Schließen (2) Sie das Dataset, um zur Pipeline zurückzukehren.
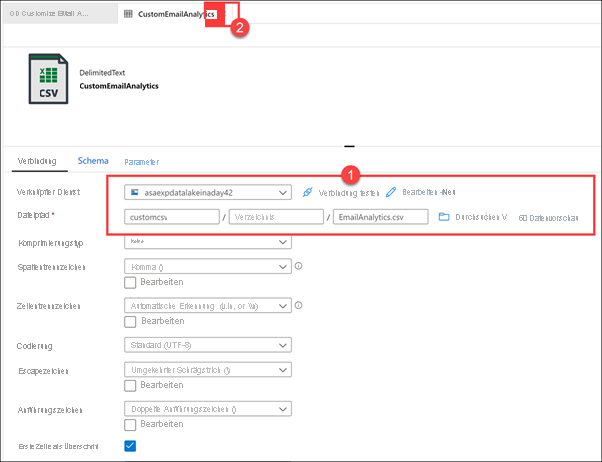
Wählen Sie in der Pipeline die Registerkarte Senke(1) aus. Die Kopiermethode mit Masseneinfügung wird ausgewählt und ein Skript liegt vor, das vor dem Kopiervorgang aus der CSV-Quelle (2) ausgeführt wird und die Tabelle EmailAnalytics kürzt. Klicken Sie neben dem EmailAnalytics-Senkendataset (3) auf Öffnen.
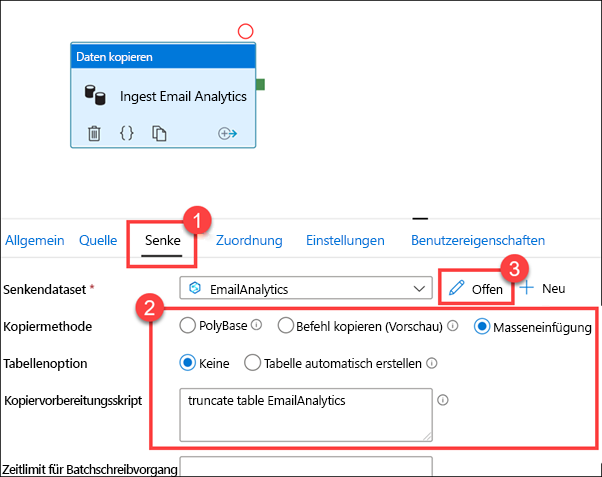
Bei dem verknüpften Dienst handelt es sich um den SQL-Pool von Azure Synapse Analytics und bei der Tabelle um EmailAnalytics (1). Die Aktivität „Daten kopieren“ in der Pipeline verwendet die Verbindungsdetails in diesem Dataset, um Daten aus der CSV-Datenquelle in den SQL-Pool zu kopieren. Klicken Sie auf Datenvorschau (2).
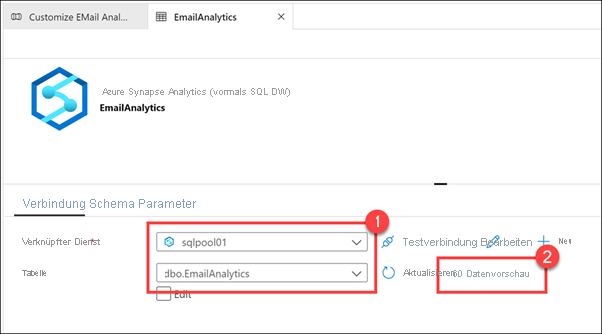
Sie sollten sehen können, dass die Tabelle bereits Daten enthält. Das bedeutet, die Pipeline wurde bereits erfolgreich ausgeführt.

Schließen Sie das EmailAnalytics-Dataset.
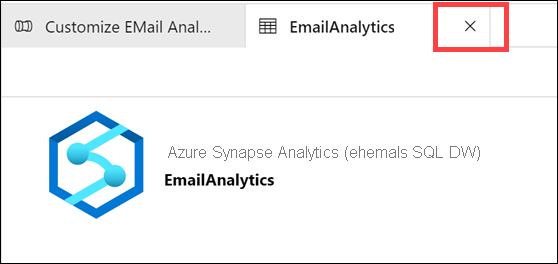
Wählen Sie die Registerkarte Zuordnung aus. Hier konfigurieren Sie die Zuordnung der Quellen- und Senkendatasets. Mit der Schaltfläche Import schemas (Schemas importieren) wird versucht, das Schema für Ihre Datasets abzuleiten, wenn sie auf unstrukturierten oder teilweise strukturierten Datenquellen wie CSV- oder JSON-Dateien basieren. Das Schema wird auch aus strukturierten Datenquellen wie SQL-Pools von Synapse Analytics gelesen. Sie können Ihre Schemazuordnung auch manuell erstellen, indem Sie auf + Neue Zuordnung klicken oder die Datentypen ändern.
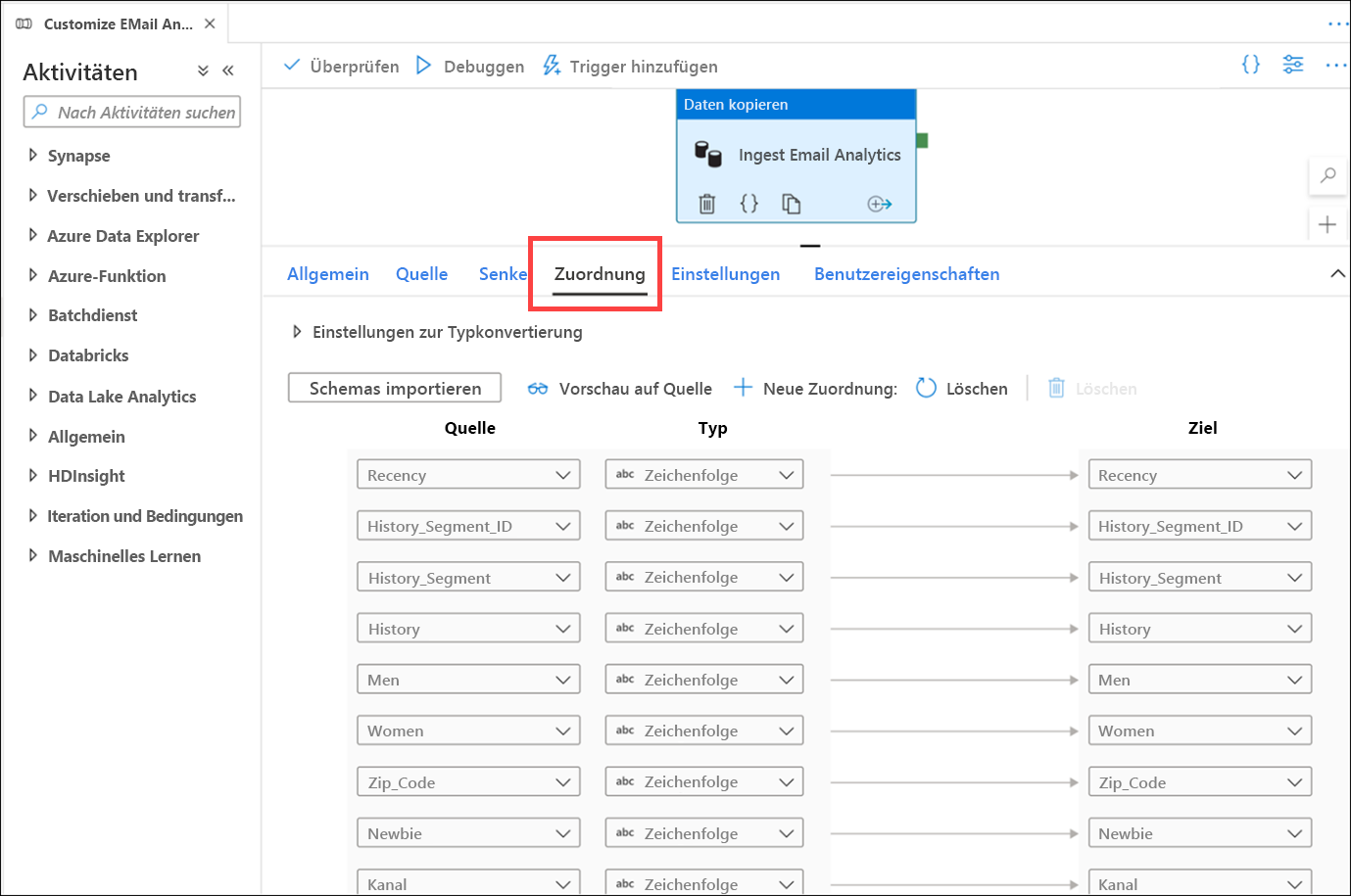
Wählen Sie die Pipeline MarketingDBMigration (1) aus. Sehen Sie sich den Canvas (2) der Pipeline an.
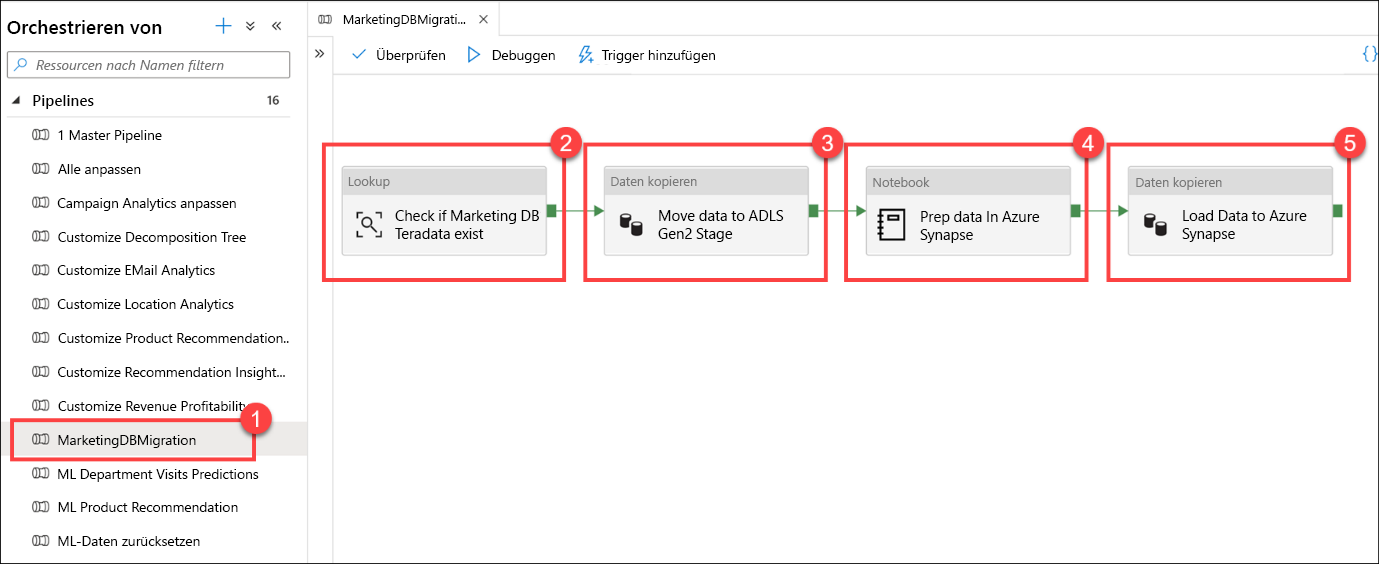
Diese Pipeline ist für das Kopieren von Daten aus einer Teradata-Datenbank verantwortlich. Bei der ersten Aktivität handelt es sich um eine Suche (2), mit der sichergestellt wird, dass die Quelldaten vorhanden sind. Wenn die Daten vorhanden sind, wird die Aktivität Daten kopieren (3) ausgeführt, um die Quelldaten in den Data Lake (primäre ADLS Gen2-Datenquelle) zu verschieben. Der nächste Schritt ist eine Notebook-Aktivität (4), bei der Apache Spark in einem Synapse-Notebook verwendet wird, um Datentechnikaufgaben durchzuführen. Der letzte Schritt ist eine weitere Datenkopieraktivität (5), die die aufbereiteten Daten lädt und in einer SQL-Pooltabelle von Azure Synapse speichert.
Dieser Workflow ist bei der Orchestrierung der Datenverschiebung gängig. Synapse Analytics-Pipelines vereinfachen die Definition der Datenverschiebungs- und Datentransformationsschritte und fassen diese Schritte in einen wiederholbaren Prozess zusammen, den Sie in Ihrem modernen Data Warehouse verwalten und überwachen können.
Wählen Sie die Pipeline SalesDBMigration (1) aus. Sehen Sie sich den Canvas (2) der Pipeline an.
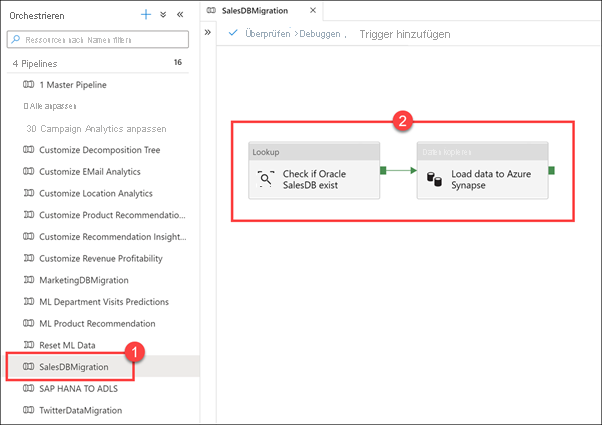
Im Folgenden finden Sie ein weiteres Beispiel für eine Pipeline für die Orchestrierung der Datenverschiebung, die Sie beim Kombinieren externer Datenquellen im Data Warehouse unterstützt. In diesem Fall laden Sie Daten aus einer Oracle-Vertriebsdatenbank in eine Azure Synapse-SQL-Pooltabelle.
Wählen Sie die Pipeline SAP HANA TO ADLS aus. Diese Pipeline kopiert Daten aus einer SAP HANA-Quelle für Finanzdaten in den SQL-Pool.
Klicken Sie oben im Blatt Orchestrieren auf die Schaltfläche+ und dann auf Pipeline, um eine neue Pipeline zu erstellen.
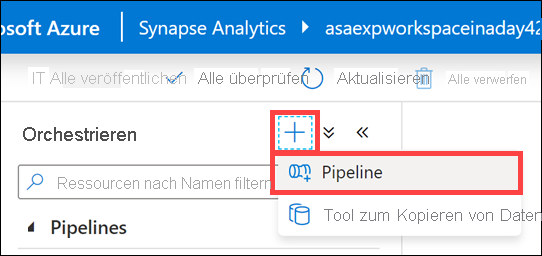
Wenn die neue Pipeline geöffnet wird, wird das Blatt Eigenschaften(1) angezeigt, auf dem Sie die Pipeline benennen können (2).
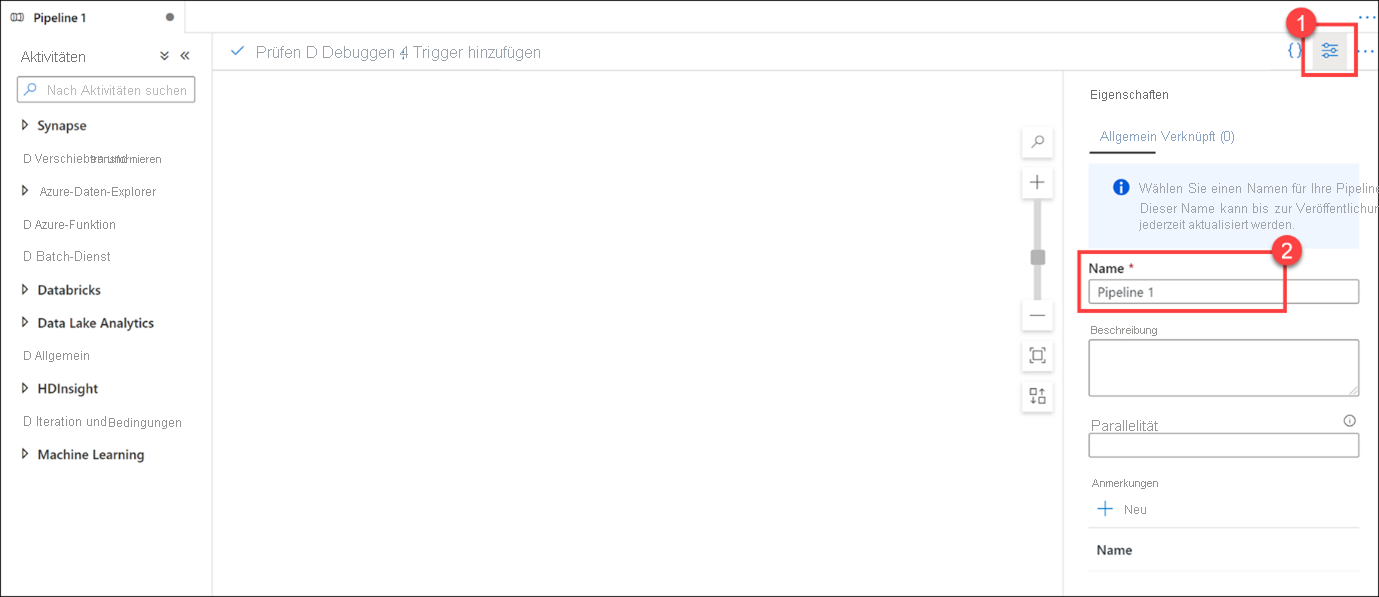
Erweitern Sie die Aktivitätsgruppe „Verschieben und transformieren“, und ziehen Sie dann die Aktivität Daten kopieren auf den Entwurfscanvas (1). Klicken Sie mit ausgewählter Aktivität „Daten kopieren“ auf die Registerkarte Quelle(2), und klicken Sie dann neben dem Quelldataset auf + Neu (3).
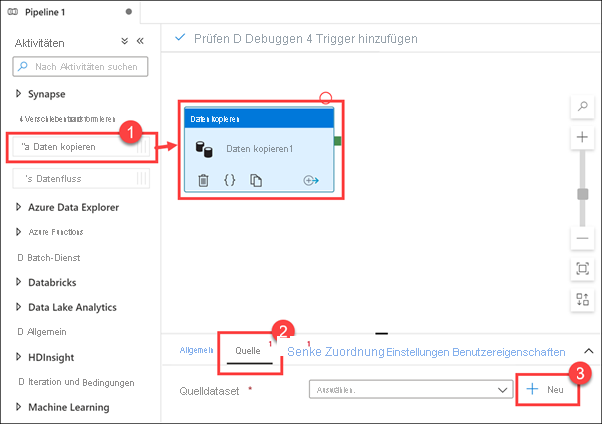
Scrollen Sie durch die Liste der Datasetquellen, um die große Menge der für Sie verfügbaren Datenverbindungen anzuzeigen, und klicken Sie dann auf „Abbrechen“.
Unbegrenzte Datenskalierung
Navigieren Sie zum Hub Verwalten.
Klicken Sie auf SQL-Pools (1). Zeigen Sie auf SQLPool01, und klicken Sie auf Skalieren(2).
Ziehen Sie den Schieberegler Leistungsebene nach rechts und links.

Sie können Computeressourcen horizontal skalieren, indem Sie die Anzahl der Data Warehouse-Einheiten (DWUs) anpassen, die Ihrem SQL-Pool zugewiesen sind. Dadurch wird die Lade- und Abfrageleistung linear angepasst, wenn Sie weitere Einheiten hinzufügen.
Zum Durchführen eines Skalierungsvorgangs löscht der SQL-Pool zunächst alle eingehenden Abfragen und führt dann ein Rollback für die Transaktionen aus, um einen konsistenten Zustand zu gewährleisten. Die Skalierung tritt erst auf, wenn der Transaktionsrollback abgeschlossen ist.
Sie können die SQL-Computeressourcen jederzeit mithilfe dieses Schiebereglers skalieren. Sie können die Data Warehouse-Einheiten auch programmgesteuert anpassen, wodurch Szenarios ermöglicht werden, in denen Sie Ihren Pool automatisch anhand eines Zeitplans oder anderer Faktoren automatisch skalieren können.
Schließen Sie das Dialogfeld „Skalieren“, und klicken Sie dann im linken Menü des Hubs „Verwalten“ auf Apache Spark-Pools (1). Zeigen Sie auf SparkPool01, und klicken Sie dann auf Einstellungen für Autoskalierung(2).
Ziehen Sie den Schieberegler Anzahl der Knoten nach rechts und links.
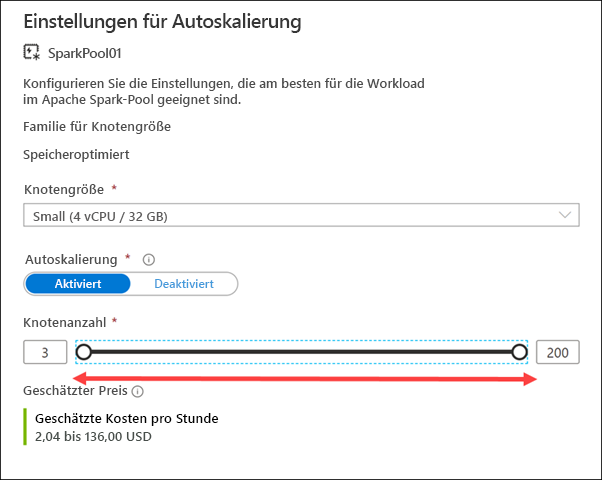
Sie können den Apache Spark-Pool so konfigurieren, dass er eine feste Größe aufweist, indem Sie die Autoskalierungseinstellung deaktivieren. Hier wurden die Autoskalierung aktiviert sowie eine minimale und maximale Knotenanzahl festgelegt, um die angewendete Skalierung zu steuern. Wenn Sie die Autoskalierung aktivieren, überwacht Synapse Analytics die Ressourcenanforderung der Auslastung und skaliert die Anzahl der Knoten hoch oder herunter. Hierzu werden die Metriken für die ausstehende CPU- und Arbeitsspeicherauslastung, die ungenutzten CPU- und Arbeitsspeicherressourcen sowie der pro Knoten genutzte Arbeitsspeicher kontinuierlich überwacht. Diese Metriken werden alle 30 Sekunden überprüft, um Skalierungsentscheidungen anhand der Werte zu treffen.
Es kann 1 bis 5 Minuten dauern, bis ein Skalierungsvorgang abgeschlossen ist.
Schließen Sie das Dialogfeld für die automatische Skalierung, und klicken Sie dann im linken Menü des Hubs „Verwalten“ auf Verknüpfte Dienste (1). Notieren Sie sich das ADLS Gen2-Speicherkonto WorkspaceDefaultStorage(2).
Wenn Sie einen neuen Azure Synapse Analytics-Arbeitsbereich bereitstellen, definieren Sie das Azure Data Lake Storage Gen2-Standardspeicherkonto. Mit Data Lake Storage Gen2 wird Azure Storage zur Grundlage für das Erstellen von Enterprise Data Lakes in Azure. Data Lake Storage Gen2 wurde eigens für die Verarbeitung mehrerer Petabyte an Informationen bei gleichzeitiger Unterstützung eines Durchsatzes von Hunderten von Gigabit konzipiert und bietet Ihnen eine einfache Möglichkeit, riesige Datenmengen zu verwalten.
Mit dem hierarchischen Namespace werden Dateien in einer Hierarchie von Verzeichnissen organisiert, um einen effizienten Zugriff und präzisere Sicherheit auf Dateiebene zu erreichen.
ADLS Gen2 bietet praktisch unbegrenzte Skalierbarkeit für Ihren Data Lake. Sie können bei Bedarf zusätzliche ADLS Gen2-Konten anfügen, um die Skalierbarkeit und Flexibilität zu erhöhen.
Vertraute Tools und Ökosystem
Wählen Sie den Hub Entwickeln aus.
Erweitern Sie SQL-Skripts, und wählen Sie das Skript 1 SQL Query With Synapse (1) (SQL-Abfrage mit Synapse) aus. Stellen Sie sicher, dass eine Verbindung mit SQLPool01 (2) besteht. Markieren (3) Sie die erste Zeile des Skripts, und führen Sie sie aus. Beachten Sie, dass die Anzahl der Datensätze in der Sales-Tabelle „3.443.486“ (4) lautet.

Wenn Sie die erste Zeile in diesem SQL-Skript ausführen, können Sie sehen, dass fast 3,5 Millionen Zeilen enthalten sind.
Markieren Sie den Rest des Skripts (Zeilen 8 bis 18), und führen Sie ihn aus.
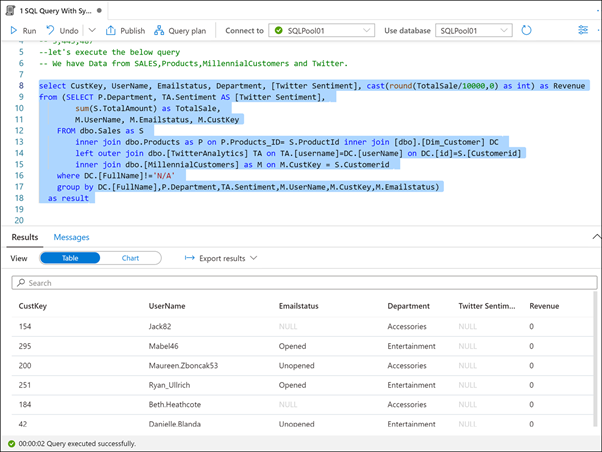
Ein Vorteil der Verwendung eines modernen Data Warehouse wie Synapse Analytics besteht darin, dass Sie all Ihre Daten an einem Ort kombinieren können. Das soeben ausgeführte Skript führt Daten aus einer Vertriebsdatenbank, einem Produktkatalog, aus demografischen Daten extrahierte Kunden der Generation Y und Daten von Twitter zusammen.
Wählen Sie das Skript 2 JSON Extractor (1) aus, und stellen Sie sicher, dass Sie die Verbindung mit SQLPool01 weiterhin besteht. Markieren Sie die erste SELECT-Anweisung (2) (Zeile 3). Beachten Sie, dass die in der Spalte TwitterData(3) gespeicherten Daten das JSON-Format aufweisen.
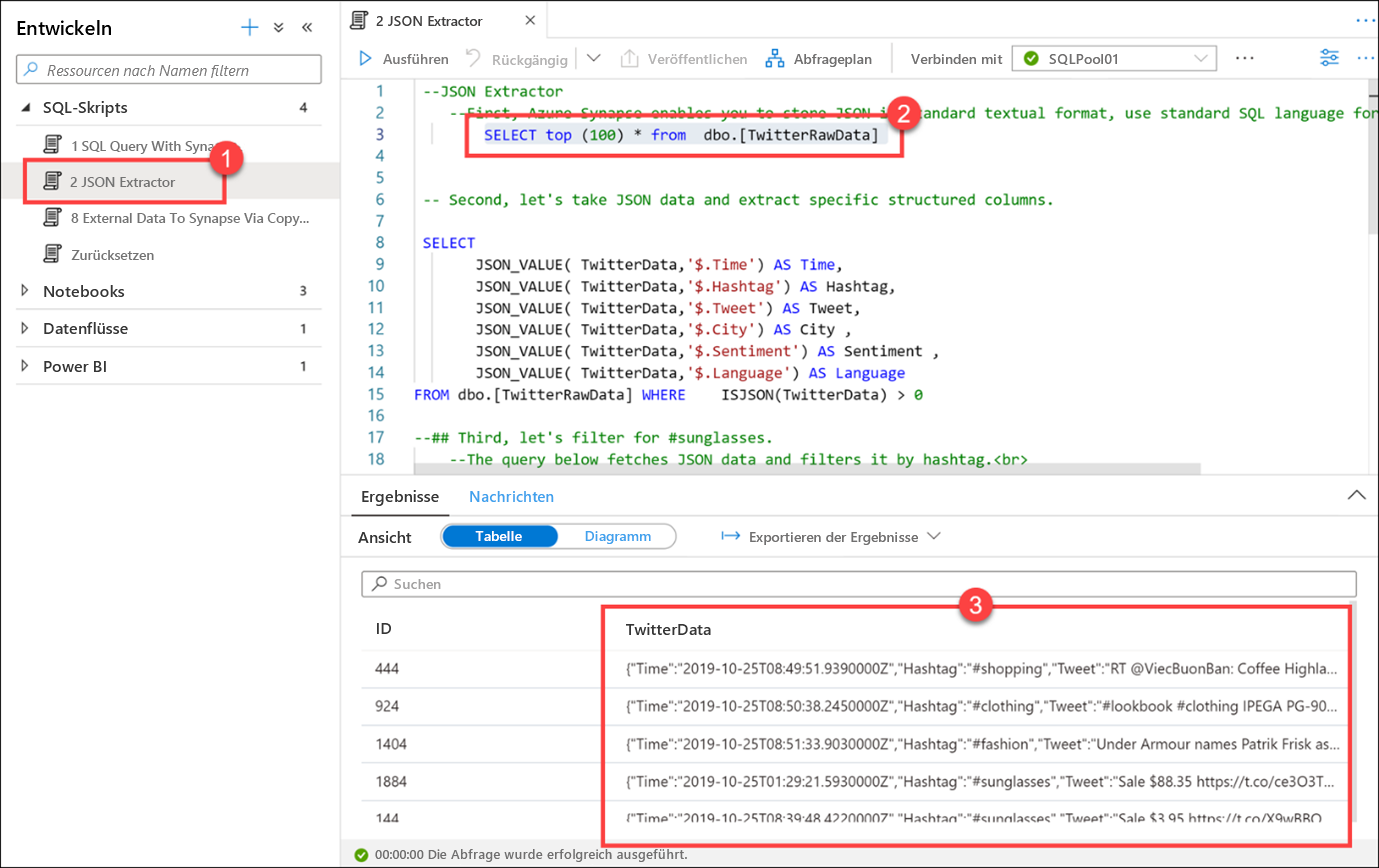
Mit Azure Synapse können Sie JSON-Daten im Standardtextformat speichern. Verwenden Sie die SQL-Standardsprache zum Abfragen von JSON-Daten.
Markieren Sie die nächste SQL-Anweisung (Zeilen 8 bis 15), und führen Sie sie aus.
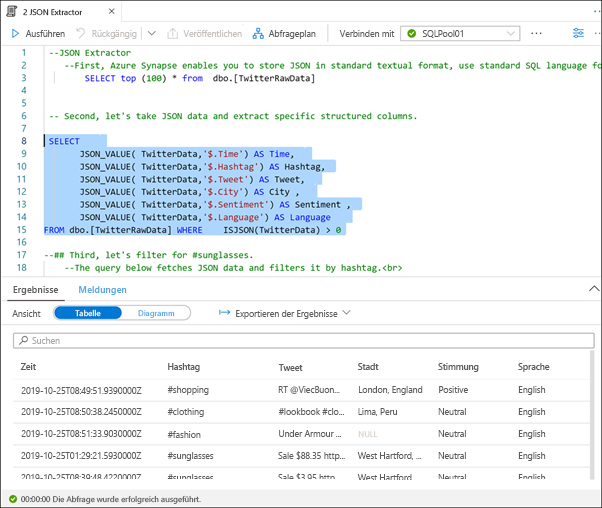
Sie können JSON-Funktionen wie JSON_VALUE und ISJSON verwenden, um die JSON-Daten in spezifische strukturierte Spalten zu extrahieren.
Markieren Sie die nächste SQL-Anweisung (Zeilen 21 bis 29), und führen Sie sie aus.

Sie müssen nach dem Hashtag #sunglasses filtern. Diese Abfrage ruft die JSON-Daten ab und extrahiert diese in strukturierte Spalten. Anschließend wird die abgeleitete Hashtag-Spalte gefiltert.
Das letzte Skript führt dieselben Aktionen mit einem Unterabfragenformat durch.
Wählen Sie das Skript 8 External Data To Synapse Via Copy Into (1) (Externe Daten für Synapse über Kopiervorgang) aus. FÜHREN SIE DAS SKRIPT NICHT AUS. Scrollen Sie in der Skriptdatei nach unten, und lesen Sie unten, welche Aktionen das Skript ausführt.
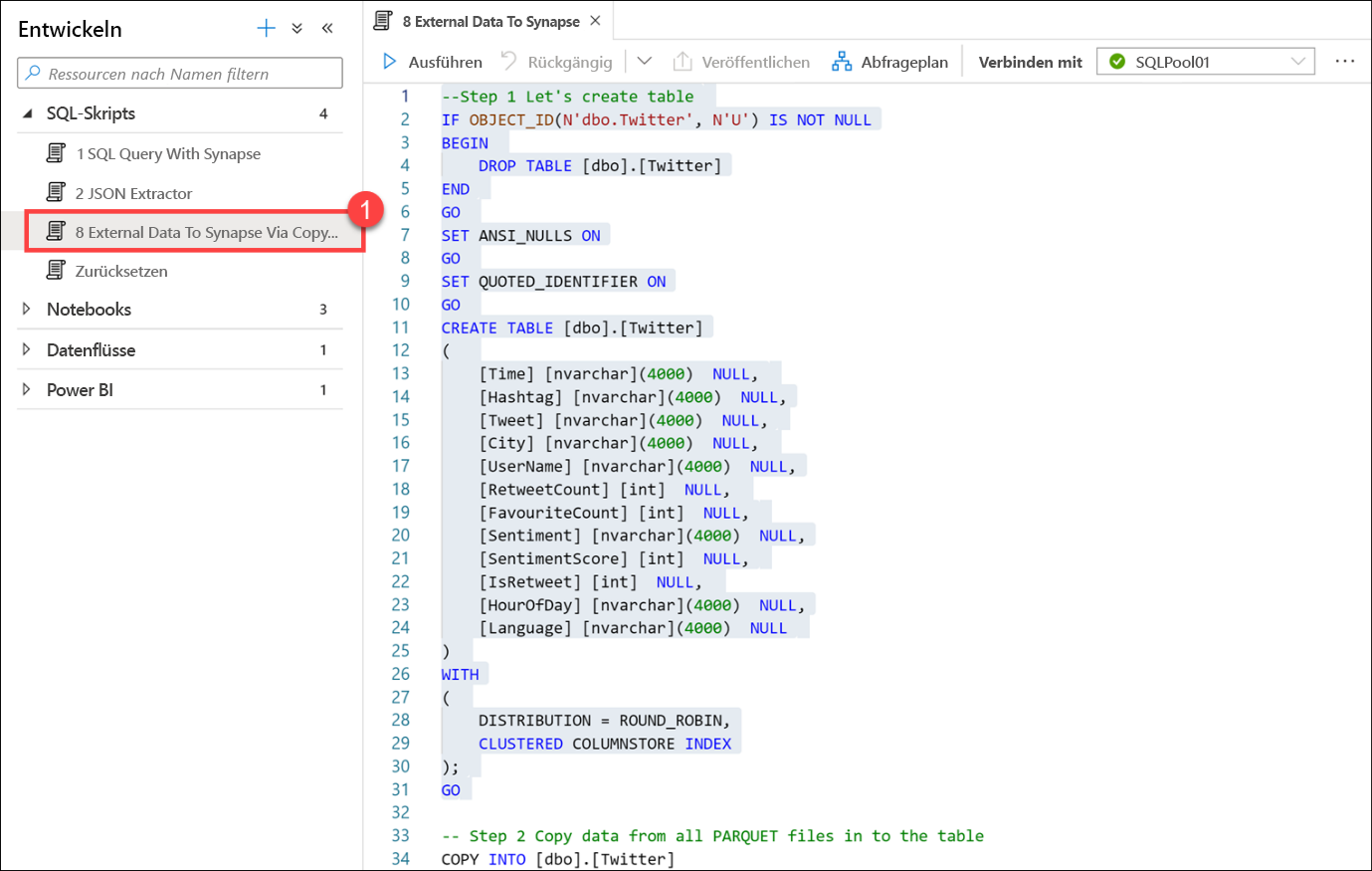
In diesem Skript wird eine Tabelle erstellt, um gespeicherte Twitter-Daten in Parquet-Dateien zu speichern. Der COPY-Befehl wird verwendet, um alle in Parquet-Dateien gespeicherten Daten schnell und effizient in eine neue Tabelle zu laden.
Schließlich werden die ersten 10 Zeilen ausgewählt, um das Laden der Daten zu überprüfen.
Der COPY-Befehl und PolyBase können dazu verwendet werden, Daten mit verschiedenen Formaten in dem SQL-Pool zu importieren. Hierzu werden entweder wie hier gezeigt T-SQL-Skripts oder Orchestrierungspipelines verwendet.
Wählen Sie den Hub Daten aus.
Wählen Sie die Registerkarte Verknüpft (1) aus, erweitern Sie die Azure Data Lake Storage Gen2-Gruppe, erweitern Sie das primäre Speicherkonto, und wählen Sie dann den Container twitterdata(2) aus. Klicken Sie mit der rechten Maustaste auf die Datei dbo.TwitterAnalytics.parquet (3), und klicken Sie dann auf Neues Notebook (4).
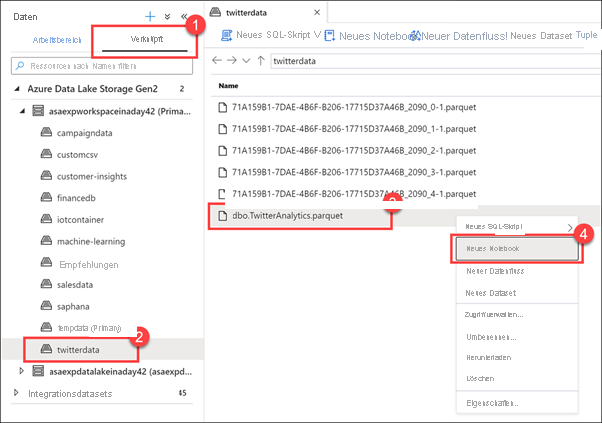
Synapse Studio bietet mehrere Optionen für die Arbeit mit Dateien, die in angefügten Speicherkonten gespeichert sind, z. B. das Erstellen eines neuen SQL-Skripts, eines Notebooks, eines Datenflusses oder eines neuen Datasets.
Mit Synapse-Notebooks können Sie die Leistungsfähigkeit von Apache Spark nutzen, um Daten zu untersuchen und zu analysieren, Datentechnikaufgaben auszuführen und Data Science durchzuführen. Die Authentifizierung und Autorisierung bei verknüpften Diensten wie dem primären Data Lake-Speicherkonto sind vollständig integriert, was es Ihnen ermöglicht, sofort mit der Arbeit mit Dateien zu beginnen, ohne dass Sie sich mit Kontoanmeldeinformationen beschäftigen müssen.
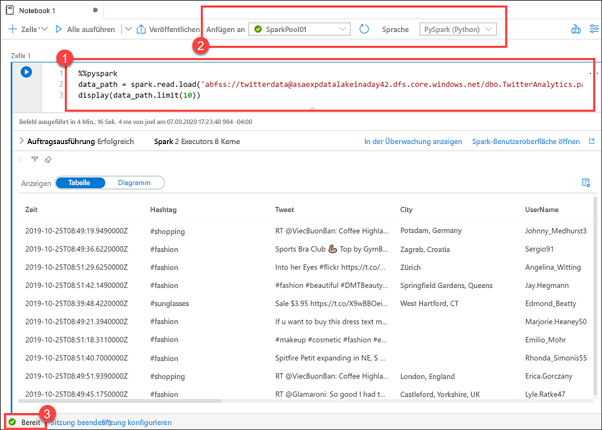
Im Folgenden wird ein neues Notebook veranschaulicht, das ein Spark-Dataframe (1) mit der Parquet-Datei lädt, auf die Sie im Hub „Daten“ mit der rechten Maustaste geklickt haben. In nur wenigen einfachen Schritten können Sie mit der Untersuchung der Dateiinhalte beginnen. Ganz oben im Notebook wird angegeben, dass es an den Spark-Pool SparkPool01 angefügt und dass Python (2) als Notebook-Sprache festgelegt ist.
Führen Sie das Notebook nicht aus, es sei denn, der Spark-Pool ist bereit (3). Das Starten des Pools kann bis zu 5 Minuten dauern, wenn er sich im Leerlauf befindet. Alternativ können Sie das Notebook ausführen und später zurückkehren, um die Ergebnisse anzuzeigen.