Konzepte für Deep Neural Networks
Bevor Sie lernen, wie Sie Machine Learning-Modelle mit Deep Neural Networks (DNNs) trainieren, wird zunächst darauf eingegangen, was eigentlich das Ziel ist. Maschinelles Lernen befasst sich mit dem Vorhersagen eines Labels basierend auf einigen Merkmalen einer bestimmten Beobachtung. Einfach ausgedrückt ist ein Machine Learning-Modell eine Funktion, die y (die Bezeichnung) aus x (den Merkmalen) berechnet: f(x)=y.
Ein einfaches Klassifizierungsbeispiel
Angenommen, Ihre Beobachtung besteht aus einigen Maßen eines Pinguins.

Dabei handelt es sich um die folgenden Maße:
- Die Schnabellänge des Pinguins
- Die Schnabeltiefe des Pinguins
- Die Flossenlänge des Pinguins
- Das Gewicht des Pinguins
In diesem Fall sind die Merkmale (x) ein Vektor mit vier Werten, oder mathematisch ausgedrückt: x=[x1,x2,x3,x4].
Angenommen die Bezeichnung, die vorhergesagt werden soll (y), steht für die Art des Pinguins, und es gibt drei mögliche Arten:
- Adeliepinguin
- Eselspinguin
- Zügelpinguin
Dies ist ein Beispiel für ein Klassifizierungsproblem, bei dem das Machine Learning-Modell die Klasse vorhersagen muss, zu der die Beobachtung am wahrscheinlichsten gehört. Ein Klassifizierungsmodell erreicht dies durch Vorhersagen eines Labels, das aus der Wahrscheinlichkeit für jede Klasse besteht. Mit anderen Worten: y ist ein Vektor mit drei Wahrscheinlichkeitswerten, einer für jede der möglichen Klassen: y=[P(0),P(1),P(2)].
Sie trainieren das Machine Learning-Modell mit Beobachtungen, für die Sie bereits das richtige Label kennen. Beispiel: Sie verfügen über die folgenden Maße als Merkmale für einen Adeliepinguin:
x=[37.3, 16.8, 19.2, 30.0]
Sie wissen bereits, dass es sich um ein Beispiel für einen Adeliepinguin (Klasse 0) handelt, sodass eine perfekte Klassifizierungsfunktion ein Label mit einer Wahrscheinlichkeit von 100 % für Klasse 0 und einer Wahrscheinlichkeit von 0 % für Klasse 1 und 2 ausgeben sollte:
y=[1, 0, 0]
Modell mit einem Deep Neural Network
Wie würden Sie nun mithilfe von Deep Learning ein Klassifizierungsmodell für Pinguine entwickeln? Betrachten wir dazu ein Beispiel:

Das Deep-Neural-Network-Modell für den Klassifizierer besteht aus mehreren Schichten mit künstlichen Neuronen. In diesem Fall gibt es vier Schichten:
- Eine Eingabeschicht mit einem Neuron für jeden erwarteten Eingabewert (x)
- Zwei sogenannte verborgene Schichten mit jeweils fünf Neuronen
- Eine Ausgabeschicht mit drei Neuronen, eines für jeden Wahrscheinlichkeitswert der Klassen (y), die das Modell vorhersagt
Aufgrund der Schichtarchitektur des Netzes wird diese Art von Modell manchmal auch als mehrschichtiges Perzeptron bezeichnet. Beachten Sie außerdem, dass alle Neuronen in der Eingabeschicht und den verborgenen Schichten mit allen Neuronen in den jeweils darauffolgenden Schichten verbunden sind. Dies ist ein Beispiel für ein vollständig verbundenes Netz.
Wenn Sie ein solches Modell entwickeln, müssen Sie eine Eingabeschicht definieren, die die Anzahl von Merkmalen unterstützt, die Ihr Modell verarbeitet, und eine Ausgabeschicht, die die Anzahl von Ausgaben widerspiegelt, die das Modell generieren soll. Sie können selbst entscheiden, wie viele verborgene Schichten Sie verwenden möchten und wie viele Neuronen diese jeweils enthalten sollen. Die Eingabe- und Ausgabewerte für diese Schichten können Sie jedoch nicht steuern. Diese hängen vom Modelltrainingsprozess ab.
Trainieren eines Deep Neural Network
Der Trainingsprozess für ein Deep Neural Network besteht aus mehreren Iterationen, die Epochen genannt werden. Für die erste Epoche beginnen Sie, indem Sie zufällige Initialisierungswerte für Gewichts- (w) und Verzerrungswerte b zuweisen. Der weitere Prozess sieht wie folgt aus:
- Merkmale für Datenbeobachtungen mit bekannten Labelwerten werden an die Eingabeschicht übermittelt. Im Allgemeinen werden diese Beobachtungen in Batches gruppiert (oft auch als Minibatches bezeichnet).
- Die Neuronen wenden dann ihre Funktion an und übergeben, wenn sie aktiviert werden, das Ergebnis an die nächste Schicht, bis die Ausgabeschicht eine Vorhersage erzeugt.
- Diese Vorhersage wird mit dem tatsächlichen bekannten Wert verglichen, und die Abweichung zwischen den vorhergesagten Werten und den richtigen Werten (Verlust genannt) wird berechnet.
- Basierend auf den Ergebnissen werden korrigierte Werte für Gewicht und Bias berechnet, um den Verlust zu verringern. Diese Anpassungen werden dann per Backpropagation zurück an die Neuronen in den Netzschichten geleitet.
- Bei der nächsten Epoche wird das Batchtraining mit Vorwärtsweitergabe mit den korrigierten Werten für Gewicht und Bias wiederholt, wobei sich hoffentlich (durch Reduzierung des Verlusts) die Genauigkeit des Modells verbessert.
Hinweis
Durch die Verarbeitung der Trainingsmerkmale als Batch wird die Effizienz des Trainingsprozesses verbessert, indem mehrere Beobachtungen gleichzeitig als Merkmalsmatrix mit Vektoren mit Gewichts- und Biaswerten verarbeitet werden. Lineare algebraische Funktionen, die mit Matrizen und Vektoren arbeiten, werden auch bei der Verarbeitung von 3D-Grafiken verwendet. Daher bieten Computer mit Grafikprozessoren (GPUs) eine deutlich bessere Leistung beim Trainieren von Deep Learning-Modellen als Computer, die nur über Zentralprozessoren (CPUs) verfügen.
Genauere Betrachtung der Verlustfunktionen und der Backpropagation
In der vorherigen Beschreibung des Deep-Learning-Trainingsprozesses wurde erwähnt, dass der Verlust für das Modell berechnet und zum Anpassen der Gewichts- und Biaswerte verwendet wird. Wie das funktioniert?
Berechnen des Verlusts
Angenommen, eines der für den Trainingsprozess verwendeten Beispiele enthält Merkmale eines Adeliepinguins (Klasse 0). Die richtige Ausgabe des Netzes wäre [1, 0, 0]. Stellen Sie sich nun vor, die vom Netz erzeugte Ausgabe ist [0.4, 0.3, 0.3]. Wenn Sie diese beiden Ausgaben vergleichen, können Sie als absolute Abweichung für die einzelnen Elemente (mit anderen Worten, wie weit der vorhergesagte Wert vom richtigen Wert entfernt ist) Folgendes ausrechnen: [0.6, 0.3, 0.3].
Da in der Praxis mehrere Beobachtungen verarbeitet werden, wird die Abweichung in der Regel aggregiert, z. B. indem die einzelnen Abweichungswerte mit 2 potenziert werden und dann der Durchschnitt berechnet wird, sodass Sie am Ende über einen einzelnen durchschnittlichen Verlustwert verfügen, z. B. 0.18.
Optimierer
Jetzt kommt der clevere Teil. Der Verlust wird mit einer Funktion berechnet, die auf die Ergebnisse der letzten Schicht des Netzes angewendet wird, bei der es sich ebenfalls um eine Funktion handelt. Die letzte Schicht des Netzes wird wiederum auf die Ausgaben der vorherigen Schichten angewendet, die auch Funktionen sind. Folglich ist das gesamte Modell im Endeffekt von der Eingabeschicht bis hin zur Verlustberechnung lediglich eine große geschachtelte Funktion. Funktionen verfügen über einige sehr nützliche Eigenschaften, z. B. die folgenden:
- Sie können Funktionen als gezeichnete Linien darstellen und ihre Ausgabe mit den einzelnen Variablen vergleichen.
- Mit Differenzialrechnung können Sie die Ableitung der Funktion für deren Variablen an einem beliebigen Punkt berechnen.
Betrachten wir zunächst die erste dieser beiden Möglichkeiten näher. Sie können die Linie für die Funktion zeichnen, um anzuzeigen, wie ein einzelner Gewichtswert sich im Vergleich zum Verlust verhält, und auf dieser Linie den Punkt markieren, an dem der aktuelle Gewichtswert mit dem aktuellen Verlustwert übereinstimmt.
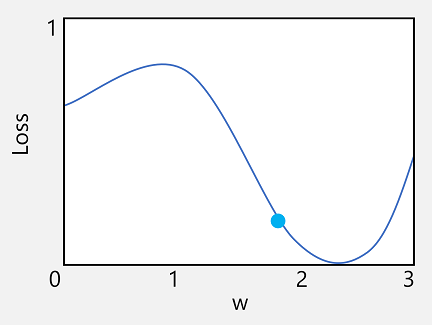
Lassen Sie uns nun die zweite Eigenschaft von Funktionen nutzen. Die Ableitung einer Funktion an einem bestimmten Punkt gibt an, ob die Steigung (oder der Gradient) der Funktionsausgabe (in diesem Fall der Verlust) für eine Funktionsvariable (in diesem Fall der Wert des Gewichts) positiv oder negativ ist. Eine positive Ableitung zeigt, dass die Funktion steigt und eine negative, dass sie fällt. In diesem Fall verfügt die Funktion am eingezeichneten Punkt für den aktuellen Gewichtswert über einen fallenden Gradienten. Anders gesagt: Das Erhöhen des Gewichts führt zu einer Verringerung des Verlusts.
Mit einem Optimierer wird dieser Trick auf alle Gewichts- und Biasvariablen im Modell angewendet und ermittelt, in welche Richtung diese Variablen angepasst werden müssen (nach oben oder unten), um den Gesamtverlust im Modell zu verringern. Es gibt viele häufig verwendete Optimierungsalgorithmen, z. B. den stochastischen Gradientenabstieg (Stochastic Gradient Descent, SGD), die adaptive Lernrate (Adaptive Learning Rate, ADADELTA) und die adaptive Momentschätzung (Adaptive Momentum Estimation, Adam). Alle davon sind dafür konzipiert, herauszufinden, wie Gewicht und Bias angepasst werden müssen, um den Verlust zu minimieren.
Learning rate (Lernrate)
Die offensichtliche nächste Frage ist nun, um wie viel der Optimierer die Gewichts- und Biaswerte anpassen soll. Bei einem Blick auf den Plot für den Gewichtswert sehen Sie, dass bei einer leichten Erhöhung des Gewichts die Funktionslinie fällt (Verringerung des Verlusts). Wenn der Wert jedoch zu sehr erhöht wird, beginnt die Funktionslinie, wieder zu steigen, sodass der Verlust möglicherweise sogar erhöht wird. Es kann sein, dass sich nach der nächsten Epoche herausstellt, dass das Gewicht verringert werden muss.
Die Größe der Anpassung wird durch einen Parameter gesteuert, den Sie für das Training festgelegt haben, die sogenannte Lernrate. Eine niedrige Lernrate führt zu geringfügigen Anpassungen (sodass für das Minimieren des Verlusts mehr Epochen erforderlich sein können), während eine hohe Lernrate zu großen Anpassungen führt (sodass das Minimum möglicherweise gar nicht erreicht wird).