Convolutional Neural Networks
Deep-Learning-Modelle können zwar für jede Art von maschinellem Lernen verwendet werden, sind aber besonders nützlich bei Daten, die aus großen Arrays mit numerischen Werten bestehen, z. B. bei Bildern. Machine Learning-Modelle, die mit Bildern arbeiten, bilden die Grundlage für einen Bereich der künstlichen Intelligenz namens maschinelles Sehen, in dem Deep-Learning-Techniken in den letzten Jahren ein Treiber für erstaunliche Fortschritte waren.
Maßgeblich verantwortlich für den Erfolg von Deep Learning in diesem Bereich ist eine Art von Modell, die Convolutional Neural Network oder CNN genannt wird. In der Regel funktioniert ein CNN so, dass es Merkmale aus Bildern extrahiert und diese dann als Eingabe an ein vollständig verbundenes neuronales Netz sendet, um eine Vorhersage zu generieren. Durch die Schichten für die Merkmalsextraktion im Netz wird die Anzahl der Merkmale im potenziell riesigen Array mit einzelnen Pixelwerten auf eine kleinere Gruppe von Merkmalen reduziert, die die Vorhersage von Labels unterstützt.
Schichten in einem CNN
CNNs bestehen aus verschiedenen Schichten, von denen jede eine bestimmte Aufgabe beim Extrahieren von Merkmalen oder Vorhersagen von Labels erfüllt.
Faltungsschichten
Eine der Hauptarten von Schichten ist die Faltungsschicht, die wichtige Merkmale in Bildern extrahiert. Faltungsschichten wenden einen Filter auf Bilder an. Dieser wird über einen Kern definiert, der aus einer Matrix mit Gewichtswerten besteht.
Ein 3×3-Filter kann z. B. wie folgt definiert sein:
1 -1 1
-1 0 -1
1 -1 1
Ein Bild ist nichts anderes als eine Matrix mit Pixelwerten. Zum Anwenden des Filters wird dieser über ein Bild „gelegt“, und eine gewichtete Summe der entsprechenden Bildpixelwerte unter dem Filterkern wird berechnet. Das Ergebnis wird dann der mittleren Zelle eines entsprechenden 3×3-Abschnitts in einer neuen Matrix mit Werten zugewiesen, die genauso groß ist wie das Bild. Nehmen wir beispielsweise an, ein 6×6-Bild weist die folgenden Pixelwerte auf:
255 255 255 255 255 255
255 255 100 255 255 255
255 100 100 100 255 255
100 100 100 100 100 255
255 255 255 255 255 255
255 255 255 255 255 255
Das Anwenden des Filters auf den 3×3-Abschnitt in der linken oberen Ecke des Bilds würde dann wie folgt funktionieren:
255 255 255 1 -1 1 (255 x 1)+(255 x -1)+(255 x 1) +
255 255 100 x -1 0 -1 = (255 x -1)+(255 x 0)+(100 x -1) + = 155
255 100 100 1 -1 1 (255 x1 )+(100 x -1)+(100 x 1)
Das Ergebnis wird dem entsprechenden Pixelwert in der neuen Matrix wie folgt zugewiesen:
? ? ? ? ? ?
? 155 ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
Nun wird der Filter verschoben (gefaltet). Üblicherweise wird hierfür eine Schrittgröße von 1 verwendet (d. h., er wird um ein Pixel nach rechts verschoben), und der Wert für das nächste Pixel wird berechnet.
255 255 255 1 -1 1 (255 x 1)+(255 x -1)+(255 x 1) +
255 100 255 x -1 0 -1 = (255 x -1)+(100 x 0)+(255 x -1) + = -155
100 100 100 1 -1 1 (100 x1 )+(100 x -1)+(100 x 1)
Nun kann der nächste Wert der neuen Matrix ausgefüllt werden.
? ? ? ? ? ?
? 155 -155 ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
Dieser Prozess wird wiederholt, bis der Filter auf alle 3×3-Abschnitte des Bilds angewendet wurde, um wie folgt eine neue Matrix mit Werten zu erstellen:
? ? ? ? ? ?
? 155 -155 155 -155 ?
? -155 310 -155 155 ?
? 310 155 310 0 ?
? -155 -155 -155 0 ?
? ? ? ? ? ?
Aufgrund der Größe des Filterkerns können die Werte für die Pixel am Rand nicht ausgerechnet werden. Daher wird in der Regel einfach ein Auffüllungswert eingefügt (oft 0):
0 0 0 0 0 0
0 155 -155 155 -155 0
0 -155 310 -155 155 0
0 310 155 310 0 0
0 -155 -155 -155 0 0
0 0 0 0 0 0
Die Ausgabe der Faltung wird üblicherweise an eine Aktivierungsfunktion übergeben. Dabei handelt es sich häufig um eine ReLU-Funktion (Rectified Linear Unit), die sicherstellt, dass negative Werte auf 0 gesetzt werden:
0 0 0 0 0 0
0 155 0 155 0 0
0 0 310 0 155 0
0 310 155 310 0 0
0 0 0 0 0 0
0 0 0 0 0 0
Die resultierende Matrix ist eine Merkmalszuordnung mit Merkmalswerten, die zum Trainieren eines Machine Learning-Modells verwendet werden kann.
Hinweis: Die Werte in der Merkmalszuordnung können größer sein als der maximale Wert für ein Pixel (255). Wenn Sie die Merkmalszuordnung visualisieren möchten, müssten Sie folglich die Merkmalswerte auf zwischen 0 und 255 normalisieren.
Die folgende Animation veranschaulicht den Faltungsprozess.

- Ein Bild wird an die Faltungsschicht übermittelt. In diesem Fall ist das Bild eine einfache geometrische Figur.
- Das Bild besteht aus einem Array mit Pixeln, die Werte zwischen 0 und 255 aufweisen (bei Farbbildern handelt es sich normalerweise um ein dreidimensionales Array mit Werten für den roten, grünen und blauen Kanal).
- Im Allgemeinen wird ein Filterkern mit zufälligen Gewichten initialisiert. (In diesem Beispiel wurden Werte gewählt, die die möglichen Auswirkungen eines Filters auf Pixelwerte verdeutlichen. In einem echten CNN würden die anfänglichen Gewichte in der Regel basierend auf einer zufälligen Gaußschen Verteilung generiert.) Mit diesem Filter wird eine Merkmalszuordnung aus den Bilddaten extrahiert.
- Der Filter wird über das Bild gefaltet und rechnet dabei Merkmalswerte aus, indem er eine Summe der Gewichte anwendet, die mit den entsprechenden Pixelwerten an den einzelnen Positionen multipliziert wird. Eine ReLU-Aktivierungsfunktion (Rectified Linear Unit) wird angewendet, um sicherzustellen, dass negative Werte auf 0 gesetzt werden.
- Nach der Faltung enthält die Merkmalszuordnung die extrahierten Merkmalswerte, die oft wichtige visuelle Attribute des Bilds hervorheben. In diesem Fall ist dies bei den Kanten und Ecken des Dreiecks im Bild zu beobachten.
In der Regel wendet eine Faltungsschicht mehrere Filterkerne an. Jeder Filter erzeugt eine andere Merkmalszuordnung, und alle Zuordnungen werden an die nächste Schicht des Netzes weitergegeben.
Poolingschichten
Nach dem Extrahieren von Merkmalswerten aus Bildern wird mit Poolingschichten (auch Komprimierungsschichten genannt) die Anzahl der Merkmalswerte verringert, wobei die wichtigsten extrahierten Unterscheidungsmerkmale erhalten bleiben.
Eine der gängigsten Arten von Pooling ist das Maxpooling, bei dem ein Filter auf das Bild angewendet und nur der maximale Pixelwert im Filterbereich beibehalten wird. Wenn Sie z. B. einen 2×2-Poolingkern auf den folgenden Abschnitt eines Bilds anwenden, wäre das Ergebnis 155.
0 0
0 155
Beachten Sie, dass der 2×2-Poolingfilter die Anzahl der Werte von 4 auf 1 verringert.
Wie Faltungsschichten, funktionieren Poolingschichten so, dass der Filter auf die gesamte Merkmalszuordnung angewendet wird. Die folgende Animation zeigt ein Beispiel für Maxpooling für eine Zuordnung eines Bilds.

- Die von einem Filter in einer Faltungsschicht extrahierte Merkmalszuordnung enthält ein Array mit Merkmalswerten.
- Mit einem Poolingkern wird die Anzahl der Merkmalswerte reduziert. In diesem Fall ist die Kerngröße 2×2, sodass ein Array mit einem Viertel der Merkmalswerte erzeugt wird.
- Der Poolingkern wird über die Merkmalszuordnung gefaltet, wobei bei jeder Position nur der höchste Pixelwert beibehalten wird.
Entfernungsschichten
Eine der größten Herausforderungen in einem CNN ist die Vermeidung von Überanpassung. Hierbei funktioniert das resultierende Modell gut mit den Trainingsdaten, kann aber nicht gut auf neue Daten generalisieren, mit denen es nicht trainiert wurde. Eine mögliche Methode zur Behebung von Überanpassung besteht darin, Schichten hinzuzufügen, in denen der Trainingsprozess zufällig Merkmalszuordnungen ausschließt (oder „entfernt“). Dies mag widersinnig erscheinen, ist aber eine effektive Methode, um sicherzustellen, dass das Modell keine übermäßige Abhängigkeit von den Trainingsbildern erlernt.
Andere Techniken, die Sie zur Behebung von Überanpassung verwenden können, sind das zufällige Drehen, Spiegeln oder Neigen der Trainingsbilder, um variierende Daten in den einzelnen Trainingsepochen zu generieren.
Vereinfachungsschichten
Nach dem Extrahieren der wichtigsten Merkmale auf den Bildern mit Faltungs- und Poolingschichten handelt es sich bei den daraus resultierenden Merkmalszuordnungen um mehrdimensionale Arrays mit Pixelwerten. Mit einer Vereinfachungsschicht werden die Merkmalszuordnungen zu einem Vektor mit Werten vereinfacht, der als Eingabe für eine vollständig verbundene Schicht verwendet werden kann.
Vollständig verbundene Schichten
In der Regel bildet ein vollständig verbundenes Netz, in dem die Merkmalswerte an eine Eingabeschicht übergeben werden, eine oder mehrere verborgene Schichten durchlaufen und vorhergesagte Werte in einer Ausgabeschicht generiert werden, den Abschluss eines CNN.
Eine einfache CNN-Architektur könnte in etwa so aussehen:
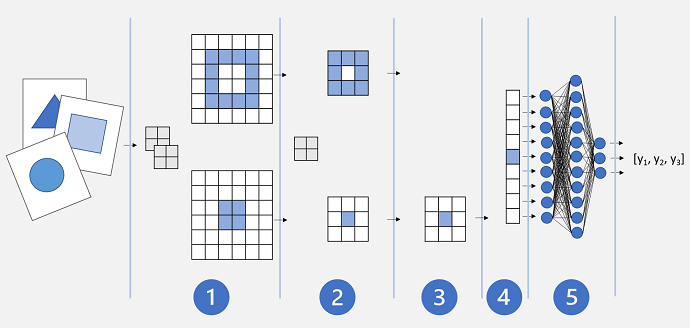
- Bilder werden als Eingabe an eine Faltungsschicht gesendet. In diesem Fall verfügt die Schicht über zwei Filter, sodass für jedes Bild zwei Merkmalszuordnungen erstellt werden.
- Die Merkmalszuordnungen werden an eine Poolingschicht weitergegeben, in der ein 2×2-Poolingkern ihre Größe reduziert.
- Eine Entfernungsschicht entfernt einige der Merkmalszuordnungen nach dem Zufallsprinzip. Dies hilft dabei, eine Überanpassung zu verhindern.
- In einer Vereinfachungsschicht werden die übrigen Merkmalszuordnungsarrays zu einem Vektor vereinfacht.
- Die Vektorelemente werden an ein vollständig verbundenes Netz gesendet, das die Vorhersagen generiert. In diesem Fall handelt es sich bei dem Netz um ein Klassifizierungsmodell, das Wahrscheinlichkeiten für drei mögliche Bildklassen vorhersagt (Dreieck, Quadrat und Kreis).
Trainieren eines CNN-Modells
Wie alle Deep Neural Networks werden CNNs trainiert, indem Batches mit Trainingsdaten das Netz in mehreren Epochen durchlaufen und die Gewichts- und Biaswerte basierend auf dem für jede Epoche berechneten Verlust angepasst werden. Im Fall eines CNN umfasst die Backpropagation von angepassten Gewichten Filterkerngewichte, die in Faltungsschichten verwendet werden, sowie die in vollständig verbundenen Schichten verwendeten Gewichte.