Erweiterte inkrementelle Aktualisierung und Echtzeitdaten mit dem XMLA-Endpunkt
Semantische Modelle in einer Premium-Kapazität mit aktiviertem XMLA-Endpunkt für Lese- und Schreibvorgänge ermöglichen erweiterte Aktualisierungen, Partitionsverwaltung und reine Metadatenbereitstellungen durch Tool-, Skript- und API-Unterstützung. Darüber hinaus sind Aktualisierungsvorgänge über den XMLA-Endpunkt nicht auf 48 Aktualisierungen pro Tag beschränkt, und das Zeitlimit für geplante Aktualisierungen gilt nicht.
Partitionen
Tabellenpartitionen von semantischen Modellen sind nicht sichtbar und können nicht über Power BI Desktop oder den Power BI-Dienst verwaltet werden. Für Modelle in einem Arbeitsbereich, der einer Premium-Kapazität zugewiesen ist, können Partitionen über den XMLA-Endpunkt mithilfe von Tools wie SQL Server Management Studio (SSMS), dem Open-Source-Tabellen-Editor, per Skript mit Tabular Model Scripting Language (TMSL) und programmgesteuert mit dem Tabellenobjektmodell (TOM) verwaltet werden.
Wenn Sie ein Modell zum ersten Mal im Power BI-Dienst veröffentlichen, hat jede Tabelle im neuen Modell eine Partition. Bei Tabellen ohne Richtlinie für inkrementelle Aktualisierungen enthält eine Partition alle Datenzeilen für diese Tabelle, sofern keine Filter angewendet wurden. Bei Tabellen mit einer Richtlinie für die inkrementelle Aktualisierung ist diese eine Partition nur vorhanden, da die Richtlinie von Power BI noch nicht angewendet wurde. Sie haben die anfängliche Partition in Power BI Desktop konfiguriert, als Sie den Datums-/Uhrzeitbereichsfilter für Ihre Tabelle basierend auf den Parametern RangeStart und RangeEnd sowie ggf. weitere, im Power Query-Editor angewendete Filter definiert haben. Diese anfängliche Partition enthält nur die Datenzeilen, die Ihren Filterkriterien entsprechen.
Wenn Sie den ersten Aktualisierungsvorgang durchführen, werden bei Tabellen ohne Richtlinie für inkrementelle Aktualisierung alle Zeilen aktualisiert, die in der Standardeinzelpartition dieser Tabelle enthalten sind. Bei Tabellen mit einer Richtlinie für inkrementelle Aktualisierung werden automatisch Aktualisierungs- und Verlaufspartitionen erstellt und Zeilen entsprechend dem Datum/der Uhrzeit für jede Zeile in sie geladen. Wenn die Richtlinie für die inkrementelle Aktualisierung das Abrufen von Daten in Echtzeit umfasst, fügt Power BI der Tabelle auch eine DirectQuery-Partition hinzu.
Dieser erste Aktualisierungsvorgang kann je nach Datenmenge, die aus der Datenquelle geladen werden muss, einige Zeit dauern. Auch die Komplexität des Modells kann ein wesentlicher Faktor sein, da für Aktualisierungsvorgänge zusätzliche Verarbeitung und Neuberechnung erforderlich ist. Dieser Vorgang kann per Bootstrap gestartet werden. Weitere Informationen finden Sie unter Verhindern von Timeouts bei der ersten vollständigen Aktualisierung.
Partitionen werden nach Zeitraumgranularität erstellt und benannt: Jahre, Quartale, Monate und Tage. Die als Aktualisierungspartitionen bezeichneten neuesten Partitionen enthalten Zeilen im Aktualisierungszeitraum, den Sie in der Richtlinie festlegen. Verlaufspartitionen enthalten Zeilen nach vollständigem Zeitraum bis zum Aktualisierungszeitraum. Bei aktivierter Echtzeitfunktion werden von einer DirectQuery-Partition alle Datenänderungen erfasst, die nach dem Enddatum des Aktualisierungszeitraums aufgetreten sind. Die Granularität für Aktualisierungs- und Verlaufspartitionen hängt von den Aktualisierungs- und Verlaufszeiträumen (Speicher) ab, die Sie beim Definieren der Richtlinie auswählen.
Nehmen wir beispielsweise an, heute ist der 2. Februar 2021 und die Tabelle FactInternetSales in der Datenquelle enthält Zeilen bis heute. Unsere Richtlinie gibt an, Echtzeitänderungen einzuschließen, Zeilen im letzten eintägigen Aktualisierungszeitraum zu aktualisieren und Zeilen im Verlaufszeitraum der letzten drei Jahre zu speichern. Mit dem ersten Aktualisierungsvorgang wird dann eine DirectQuery-Partition für zukünftige Änderungen erstellt, eine neue Importpartition für die heutigen Zeilen und eine Verlaufspartition für den gesamten gestrigen Tag, den 1. Februar 2021, erstellt. Es werden auch eine Verlaufspartition für den gesamten vorangegangenen Monat (Januar 2021), eine Verlaufspartition für das gesamte vorangegangene Jahr (2020) und Verlaufspartitionen für die gesamten Jahre 2019 und 2018 erstellt. Es werden keine Partitionen für das gesamte Quartal erstellt, da wir das erste vollständige Quartal 2021 noch nicht abgeschlossen haben.

Bei jedem Aktualisierungsvorgang werden nur die Partitionen des Aktualisierungszeitraums aktualisiert, und der Datumsfilter der DirectQuery-Partition wird aktualisiert, um nur Änderungen zu berücksichtigen, die nach dem aktuellen Aktualisierungszeitraum auftreten. Für neue Zeilen mit einem neuen Datum/einer neuen Uhrzeit innerhalb des aktualisierten Aktualisierungszeitraums wird eine neue Aktualisierungspartition erstellt, und bereits vorhandene Zeilen mit einer Datums-/Uhrzeitangabe, die sich bereits in vorhandenen Partitionen im Aktualisierungszeitraum befinden, werden aktualisiert. Zeilen, deren Datum/Uhrzeit älter als der Aktualisierungszeitraum ist, werden nicht mehr aktualisiert.
Wenn ganze Zeiträume geschlossen werden, werden Partitionen zusammengeführt. Wenn in der Richtlinie also beispielsweise ein Aktualisierungszeitraum von einem Tag und ein Speicherzeitraum von drei Jahren angegeben sind, werden alle Tagespartitionen für den vorigen Monat am ersten Tag des Monats in einer Monatspartition zusammengeführt. Am ersten Tag eines neuen Quartals werden alle drei Partitionen des Vormonats in eine Quartalspartition zusammengeführt. Am ersten Tag eines neuen Jahres werden alle vier vorherigen Quartalspartitionen in einer Jahrespartition zusammengeführt.
Ein Modell behält immer Partitionen für den gesamten Verlaufszeitraum des Speichers sowie die Partitionen für den gesamten Zeitraum bis zum aktuellen Aktualisierungszeitraum bei. Im Beispiel werden vollständige Verlaufsdaten aus drei Jahren in Partitionen für 2018, 2019, 2020 und auch Partitionen für den Monatszeitraum 2021Q101, den Tageszeitraum 2021Q10201 und die Partition des Aktualisierungszeitraums des aktuellen Tages aufbewahrt. Da im Beispiel die Verlaufsdaten für drei Jahre beibehalten werden, wird die Partition 2018 bis zur ersten Aktualisierung am 1. Januar 2022 beibehalten.
Mit inkrementeller Aktualisierung und Echtzeitdaten von Power BI nimmt Ihnen der Dienst basierend auf der Richtlinie die Partitionsverwaltung ab. Der Dienst kann alle Aufgaben der Partitionsverwaltung für Sie erledigen, und über den XMLA-Endpunkt können Sie Partitionen mithilfe von Tools selektiv einzeln, sequenziell oder parallel aktualisieren.
Aktualisieren der Verwaltung mit SQL Server Management Studio
Mit SQL Server Management Studio (SSMS) können Partitionen angezeigt und verwaltet werden, die durch die Anwendung von Richtlinien für die inkrementelle Aktualisierung generiert wurden. Sie können mithilfe von SSMS beispielsweise eine bestimmte vergangene Partition außerhalb des Zeitraums der inkrementellen Aktualisierung aktualisieren, um eine rückwirkende Aktualisierung ohne gleichzeitige Aktualisierung aller Verlaufsdaten auszuführen. SSMS kann auch beim Bootstrapping verwendet werden, um Verlaufsdaten für große Modelle durch inkrementelles Hinzufügen/Aktualisieren von Verlaufspartitionen in Batches zu laden.

Überschreiben des Verhaltens bei der inkrementellen Aktualisierung
Mit SSMS können Sie den Aufruf von Aktualisierungen mithilfe der Tabular Model Scripting Language und des Tabellenobjektmodells auch besser kontrollieren. Klicken Sie beispielsweise in SSMS im Objekt-Explorer mit der rechten Maustaste auf eine Tabelle, wählen Sie dann die Menüoption Tabelle verarbeiten aus, und wählen Sie dann die Schaltfläche Skript aus, um einen TMSL-Aktualisierungsbefehl zu generieren.
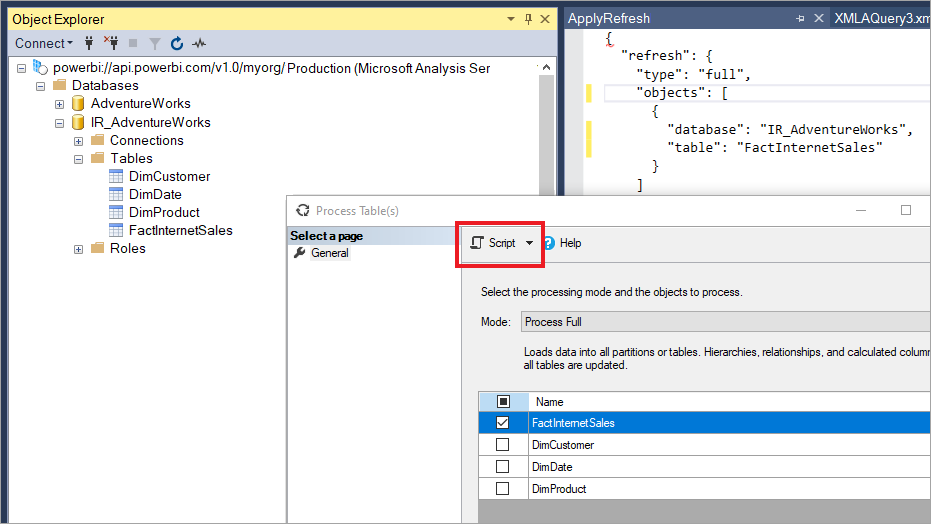
Sie können diese Parameter mit dem TMSL-Aktualisierungsbefehl verwenden, um das Standardverhalten bei der inkrementellen Aktualisierung zu überschreiben.
applyRefreshPolicy. Wenn für eine Tabelle eine inkrementelle Aktualisierungsrichtlinie definiert ist, bestimmt
applyRefreshPolicy, ob die Richtlinie angewendet wird oder nicht. Wird die Richtlinie nicht angewendet, bleiben bei einem „vollständig bearbeiten“-Vorgang die Partitionsdefinitionen unverändert, und alle Partitionen in der Tabelle werden vollständig aktualisiert. Der Standardwert ist true.effectiveDate. Wird eine Richtlinie für die inkrementelle Aktualisierung angewendet, muss das aktuelle Datum bekannt sein, damit Gleitfensterbereiche für die inkrementelle Aktualisierung und Verlaufszeiträume bestimmt werden können. Mit dem Parameter
effectiveDatekönnen Sie das aktuelle Datum überschreiben. Dieser Parameter ist nützlich für Tests, Demos und Geschäftsszenarios, in denen Daten inkrementell bis zu einem Datum in der Vergangenheit oder in der Zukunft aktualisiert werden, z. B. für künftige Budgets. Der Standardwert ist das aktuelle Datum.
{
"refresh": {
"type": "full",
"applyRefreshPolicy": true,
"effectiveDate": "12/31/2013",
"objects": [
{
"database": "IR_AdventureWorks",
"table": "FactInternetSales"
}
]
}
}
Weitere Informationen zum Überschreiben des standardmäßigen inkrementellen Aktualisierungsverhaltens mit TMSL finden Sie unter Refresh-Befehl.
Sicherstellen einer optimalen Leistung
Bei jedem Aktualisierungsvorgang sendet der Power BI-Dienst möglicherweise für jede Partition mit inkrementeller Aktualisierung Initialisierungsabfragen an die Datenquelle. Möglicherweise können Sie die Leistung der inkrementellen Aktualisierung verbessern, indem Sie die Anzahl der Initialisierungsabfragen reduzieren. Stellen Sie dazu folgende Konfiguration sicher:
- Die Tabelle, für die Sie die inkrementelle Aktualisierung konfigurieren, sollte Daten aus einer einzelnen Datenquelle abrufen. Wenn die Tabelle Daten aus mehreren Datenquellen erhält, wird die Anzahl von Abfragen, die vom Dienst für jeden Aktualisierungsvorgang gesendet werden, mit der Anzahl der Datenquellen multipliziert, wodurch sich möglicherweise die Aktualisierungsleistung verringert. Stellen Sie sicher, dass die Abfrage für die Tabelle für inkrementelle Aktualisierungen für eine einzelne Datenquelle gilt.
- Bei Lösungen, die sowohl eine inkrementelle Aktualisierung von Importpartitionen als auch Echtzeitdaten mit Direct Query vorsehen, müssen alle Partitionen Daten aus einer einzigen Datenquelle abfragen.
- Wenn Ihre Sicherheitsanforderungen dies zulassen, legen Sie die Datenschutzebene der Datenquelle auf Organisation oder Öffentlich fest. Standardmäßig ist die Datenschutzebene auf Privat festgelegt. Diese Ebene kann jedoch verhindern, dass Daten mit anderen Cloudquellen ausgetauscht werden. Um die Datenschutzstufe festzulegen, wählen Sie das Menü Weitere Optionen und dann Einstellungen>Datenquellen-Anmeldeinformationen>Bearbeiten>Datenschutzebene für diese Datenquelle aus. Wenn die Datenschutzebene im Power BI Desktop-Modell vor der Veröffentlichung im Dienst festgelegt ist, wird sie beim Veröffentlichen nicht an den Dienst übertragen. Sie müssen dies trotzdem in den Einstellungen des semantischen Modells im Dienst festlegen. Weitere Informationen finden Sie unter Datenschutzebenen.
- Wenn Sie ein lokales Datengateway verwenden, stellen Sie sicher, dass Sie Version 3000.77.3 oder höher verwenden.
Verhindern von Timeouts bei der ersten vollständigen Aktualisierung
Nach der Veröffentlichung im Power BI-Dienst erstellt der erste vollständige Aktualisierungsvorgang für das Modell Partitionen für die Tabelle für inkrementelle Aktualisierungen und lädt und verarbeitet Verlaufsdaten für den gesamten Zeitraum, der in der Richtlinie für die inkrementelle Aktualisierung definiert ist. Bei einigen Modellen, die große Datenmengen laden und verarbeiten, kann die Zeit, die der erste Aktualisierungsvorgang benötigt, das vom Dienst bzw. von der Datenquelle bestimmte Aktualisierungszeitlimit überschreiten.
Ein Bootstrapping des ersten Aktualisierungsvorgangs ermöglicht dem Dienst das Erstellen von Partitionsobjekten für die Tabelle für inkrementelle Aktualisierungen, aber nicht das Laden und Verarbeiten von Verlaufsdaten in eine der Partitionen. Anschließend wird SSMS verwendet, um Partitionen selektiv zu verarbeiten. Abhängig von der für jede Partition geladenen Datenmenge können Sie jede Partition sequenziell oder in kleinen Batches verarbeiten, um das Risiko zu verringern, dass eine oder mehrere dieser Partitionen zu einem Timeout führen. Die folgenden Methoden funktionieren für jede Datenquelle.
Anwenden der Aktualisierungsrichtlinie
Das Open-Source-Tool Tabular Editor 2 bietet eine einfache Möglichkeit für das Bootstrapping des ersten Aktualisierungsvorgangs. Nachdem Sie ein Modell mit einer von Power BI Desktop für den Dienst definierten Richtlinie für inkrementelle Aktualisierungen veröffentlicht haben, stellen Sie mithilfe des XMLA-Endpunkts im Lese-/Schreibmodus eine Verbindung mit dem Modell her. Führen Sie Apply Refresh Policy (Aktualisierungsrichtlinie anwenden) für die Tabelle für inkrementelle Aktualisierungen aus. Wenn nur die Richtlinie angewendet wird, werden Partitionen erstellt, aber keine Daten in diese geladen. Stellen Sie dann eine Verbindung mit SSMS her, um die Partitionen sequenziell oder in Batches zu aktualisieren und die Daten zu laden und zu verarbeiten. Weitere Informationen finden Sie unter Inkrementelle Aktualisierung in der Dokumentation von Tabular Editor.
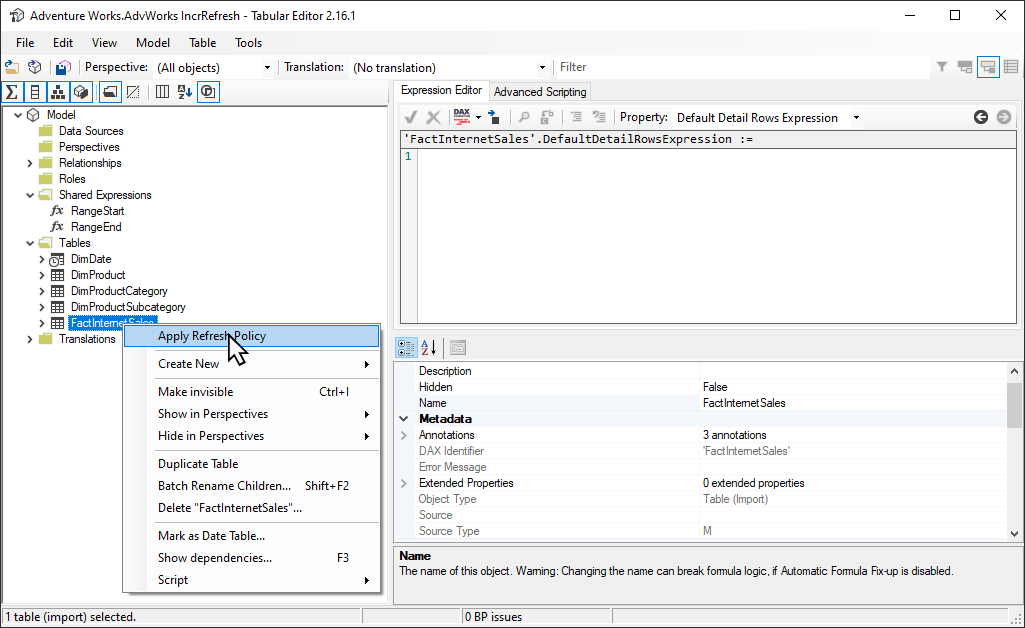
Power Query-Filter für leere Partitionen
Fügen Sie vor dem Veröffentlichen des Modells im Dienst im Power Query-Editor einen weiteren Filter zur Spalte ProductKey hinzu, der einen anderen Wert als 0 herausfiltert, um effektiv alle Daten aus der Tabelle FactInternetSales herauszufiltern.

Nachdem Sie im Power Query-Editor auf Schließen und anwenden angeklickt, die Richtlinie für die inkrementelle Aktualisierung definiert und das Modell gespeichert haben, wird das Modell im Dienst veröffentlicht. Der erste Aktualisierungsvorgang für das Modell wird vom Dienst ausgeführt. Partitionen für die Tabelle FactInternetSales werden gemäß der Richtlinie erstellt, aber keine Daten werden geladen und verarbeitet, da alle Daten herausgefiltert werden.
Nach Abschluss des ersten Aktualisierungsvorgangs wird der andere Filter für die ProductKey-Spalte im Power Query-Editor entfernt. Nachdem Sie im Power Query-Editor auf Schließen und anwenden angeklickt und das Modell gespeichert haben, wird das Modell nicht nochmal veröffentlicht. Bei einer wiederholten Veröffentlichung des Modells überschreibt es die Richtlinieneinstellungen für inkrementelle Aktualisierungen und erzwingt eine vollständige Aktualisierung für das Modell, wenn ein nachfolgender Aktualisierungsvorgang vom Dienst ausgeführt wird. Führen Sie stattdessen eine reine Metadatenbereitstellung mithilfe des ALM-Toolkits (Application Lifecycle Management) durch, bei der der Filter für die Spalte ProductKey aus dem Modell entfernt wird. SSMS kann dann verwendet werden, um Partitionen selektiv zu verarbeiten. Wenn alle Partitionen in SSMS vollständig verarbeitet wurden, was eine Neuberechnung des Prozesses für alle Partitionen umfassen muss, aktualisieren nachfolgende Aktualisierungsvorgänge für das Modell im Dienst nur die Partitionen für inkrementelle Aktualisierungen.
Tipp
Sehen Sie sich unbedingt Videos, Blogs und mehr an, die von der Power BI-Community von BI-Experten bereitgestellt werden.
Weitere Informationen zum Verarbeiten von Tabellen und Partitionen in SSMS finden Sie unter Verarbeiten von Datenbanken, Tabellen oder Partitionen (Analysis Services). Weitere Informationen zum Verarbeiten von Modellen, Tabellen und Partitionen mit TMSL finden Sie unter Aktualisierungsbefehl (TMSL).
Benutzerdefinierte Abfragen zum Erkennen von Datenänderungen
Mit TMSL und TOM können Sie ein erkanntes Datenänderungsverhalten überschreiben. Mit dieser Methode können Sie etwa vermeiden, dass die Spalte „Letzte Aktualisierung“ im In-Memory-Cache beibehalten wird. Des Weiteren werden Szenarios ermöglicht, in denen mit ETL-Vorgängen (extrahieren, transformieren und laden) eine Konfigurations- oder Anweisungstabelle vorbereitet wird, durch die nur diejenigen Partitionen gekennzeichnet werden, die aktualisiert werden müssen. Diese Methode ermöglicht einen effizienteren Ablauf der inkrementellen Aktualisierung, da nur die benötigten Zeiträume aktualisiert werden, unabhängig vom Zeitpunkt der zuletzt durchgeführten Datenaktualisierung.
Der Parameter pollingExpression soll als einfacher M-Ausdruck oder Name einer anderen M-Abfrage dienen. Er gibt einen Skalarwert zurück und wird für jede Partition ausgeführt. Unterscheidet sich der zurückgegebene Wert vom Wert der letzten inkrementellen Aktualisierung, wird die Partition für eine vollständige Verarbeitung gekennzeichnet.
Das folgende Beispiel umfasst alle 120 Monate des Verlaufszeitraums für rückwirkende Änderungen. Durch die Angabe von 120 Monaten anstelle von 10 Jahren ist die Datenkomprimierung möglicherweise weniger effizient. Doch damit wird verhindert, dass ein gesamtes historisches Jahr aktualisiert werden muss, was teurer wäre, wenn auch ein Monat für eine rückwirkende Änderung ausreichend wäre.
"refreshPolicy": {
"policyType": "basic",
"rollingWindowGranularity": "month",
"rollingWindowPeriods": 120,
"incrementalGranularity": "month",
"incrementalPeriods": 120,
"pollingExpression": "<M expression or name of custom polling query>",
"sourceExpression": [
"let ..."
]
}
Tipp
Sehen Sie sich unbedingt Videos, Blogs und mehr an, die von der Power BI-Community von BI-Experten bereitgestellt werden.
Reine Metadatenbereitstellung
Wenn Sie eine neue Version einer PBIX-Datei aus Power BI Desktop in einem Arbeitsbereich veröffentlichen und ein Modell mit demselben Namen bereits vorhanden ist, werden Sie dazu aufgefordert, das vorhandene Modell zu ersetzen.
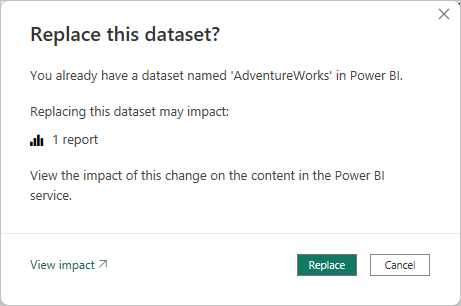
In einigen Fällen möchten Sie das Modell eventuell nicht ersetzen, insbesondere bei inkrementellen Aktualisierungen. Das Modell in Power BI Desktop könnte viel kleiner sein als das Modell im Power BI-Dienst. Gilt für das Modell im Power BI-Dienst eine Richtlinie für die inkrementelle Aktualisierung, enthält es möglicherweise mehrere Jahre zurückreichende Verlaufsdaten, die beim Ersetzen des Modells verloren gingen. Das Aktualisieren aller Verlaufsdaten könnte Stunden dauern und zu Systemausfallzeiten beim Benutzer führen.
Stattdessen ist es besser, eine reine Metadatenbereitstellung durchzuführen, die die Bereitstellung neuer Objekte ermöglicht, ohne die Verlaufsdaten zu verlieren. Wenn Sie beispielsweise einige Measures hinzugefügt haben, können Sie nur diese bereitstellen, ohne gleichzeitig die Daten zu aktualisieren. So sparen Sie Zeit.
Für Arbeitsbereiche, die einer Premium-Kapazität zugewiesen sind, die für den XMLA-Endpunkt für Lese-/Schreibvorgänge konfiguriert ist, ermöglichen kompatible Tools eine reine Metadatenbereitstellung. Das ALM-Toolkit ist beispielsweise ein Schemavergleichstool für Power BI-Modelle, das für eine reine Metadatenbereitstellung verwendet werden kann.
Laden Sie die neueste Version des ALM-Toolkits aus dem Analysis Services-Git-Repository herunter, und installieren Sie diese. Eine Schritt-für-Schritt-Anleitung zur Verwendung des ALM Toolkits ist nicht in der Microsoft-Dokumentation enthalten. Dokumentationslinks für das ALM-Toolkit und Informationen zur Unterstützung finden Sie über das Hilfe-Menüband. Führen Sie für eine reine Metadatenbereitstellung einen Vergleich aus. Wählen Sie dabei die aktuell ausgeführte Instanz von Power BI Desktop als Quelle und das vorhandene Modell im Power BI-Dienst als Ziel aus. Sehen Sie sich die angezeigten Unterschiede an. Überspringen Sie die Aktualisierung der Tabelle mit Partitionen für die inkrementelle Aktualisierung, oder behalten Sie Partitionen zur Tabellenaktualisierung mithilfe des Dialogfelds Optionen bei. Überprüfen Sie die Auswahl, um die Integrität des Zielmodells sicherzustellen. Führen Sie anschließend die Aktualisierung aus.

Programmgesteuertes Hinzufügen einer Richtlinie für die inkrementelle Aktualisierung sowie von Echtzeitdaten
Sie können auch TMSL und TOM verwenden, um einem vorhandenen Modell über den XMLA-Endpunkt eine Richtlinie für die inkrementelle Aktualisierung hinzuzufügen.
Hinweis
Achten Sie zur Vermeidung von Kompatibilitätsproblemen darauf, dass Sie die neueste Version der Analysis Services-Clientbibliotheken verwenden. Für die Verwendung von Hybridrichtlinien ist beispielsweise mindestens die Version 19.27.1.8 erforderlich.
Der Prozess umfasst die folgenden Schritte:
Stellen Sie sicher, dass das Zielmodell über den erforderlichen Mindestkompatibilitätsgrad verfügt. Klicken Sie in SSMS mit der rechten Maustaste auf [Modellname]>Eigenschaften>Kompatibilitätsgrad. Um den Kompatibilitätsgrad zu erhöhen, können Sie entweder ein TMSL-Skript vom Typ „createOrReplace“ verwenden oder sich den folgenden TOM-Beispielcode ansehen:
a. Import policy - 1550 b. Hybrid policy - 1565Fügen Sie den Modellausdrücken die Parameter
RangeStartundRangeEndhinzu. Fügen Sie bei Bedarf auch eine Funktion hinzu, um Datums-/Uhrzeitwerte in Datumsschlüssel zu konvertieren.Definieren Sie ein Objekt vom Typ
RefreshPolicymit den gewünschten Zeiträumen für die Archivierung (rollierendes Zeitfenster) und für die inkrementelle Aktualisierung sowie einen Quellausdruck, durch den die Zieltabelle basierend auf den ParameternRangeStartundRangeEndgefiltert wird. Legen Sie den Modus der Aktualisierungsrichtlinie abhängig von Ihren Echtzeitdatenanforderungen auf Import oder Hybrid fest. Bei „Hybrid“ fügt Power BI der Tabelle eine DirectQuery-Partition hinzu, um die neuesten Änderungen aus der Datenquelle abzurufen, die nach der letzten Aktualisierung aufgetreten sind.Fügen Sie der Tabelle die Aktualisierungsrichtlinie hinzu, und führen Sie eine vollständige Aktualisierung durch, damit die Tabelle gemäß Ihren Anforderungen partitioniert wird.
Das folgende Codebeispiel veranschaulicht die Ausführung der vorherigen Schritte mithilfe von TOM. Wenn Sie dieses Beispiel in der vorliegenden Form verwenden möchten, müssen Sie über eine Kopie der Datenbank „AdventureWorksDW“ verfügen und die Tabelle FactInternetSales in ein Modell importieren. Im Codebeispiel wird davon ausgegangen, dass die Parameter RangeStart und RangeEnd sowie die Funktion DateKey nicht im Modell enthalten sind. Importieren Sie einfach die Tabelle FactInternetSales, und veröffentlichen Sie das Modell in einem Arbeitsbereich in Power BI Premium. Aktualisieren Sie dann workspaceUrl, damit das Codebeispiel eine Verbindung mit Ihrem Modell herstellen kann. Aktualisieren Sie ggf. weitere Codezeilen nach Bedarf.
using System;
using TOM = Microsoft.AnalysisServices.Tabular;
namespace Hybrid_Tables
{
class Program
{
static string workspaceUrl = "<Enter your Workspace URL here>";
static string databaseName = "AdventureWorks";
static string tableName = "FactInternetSales";
static void Main(string[] args)
{
using (var server = new TOM.Server())
{
// Connect to the dataset.
server.Connect(workspaceUrl);
TOM.Database database = server.Databases.FindByName(databaseName);
if (database == null)
{
throw new ApplicationException("Database cannot be found!");
}
if(database.CompatibilityLevel < 1565)
{
database.CompatibilityLevel = 1565;
database.Update();
}
TOM.Model model = database.Model;
// Add RangeStart, RangeEnd, and DateKey function.
model.Expressions.Add(new TOM.NamedExpression {
Name = "RangeStart",
Kind = TOM.ExpressionKind.M,
Expression = "#datetime(2021, 12, 30, 0, 0, 0) meta [IsParameterQuery=true, Type=\"DateTime\", IsParameterQueryRequired=true]"
});
model.Expressions.Add(new TOM.NamedExpression
{
Name = "RangeEnd",
Kind = TOM.ExpressionKind.M,
Expression = "#datetime(2021, 12, 31, 0, 0, 0) meta [IsParameterQuery=true, Type=\"DateTime\", IsParameterQueryRequired=true]"
});
model.Expressions.Add(new TOM.NamedExpression
{
Name = "DateKey",
Kind = TOM.ExpressionKind.M,
Expression =
"let\n" +
" Source = (x as datetime) => Date.Year(x)*10000 + Date.Month(x)*100 + Date.Day(x)\n" +
"in\n" +
" Source"
});
// Apply a RefreshPolicy with Real-Time to the target table.
TOM.Table salesTable = model.Tables[tableName];
TOM.RefreshPolicy hybridPolicy = new TOM.BasicRefreshPolicy
{
Mode = TOM.RefreshPolicyMode.Hybrid,
IncrementalPeriodsOffset = -1,
RollingWindowPeriods = 1,
RollingWindowGranularity = TOM.RefreshGranularityType.Year,
IncrementalPeriods = 1,
IncrementalGranularity = TOM.RefreshGranularityType.Day,
SourceExpression =
"let\n" +
" Source = Sql.Database(\"demopm.database.windows.net\", \"AdventureWorksDW\"),\n" +
" dbo_FactInternetSales = Source{[Schema=\"dbo\",Item=\"FactInternetSales\"]}[Data],\n" +
" #\"Filtered Rows\" = Table.SelectRows(dbo_FactInternetSales, each [OrderDateKey] >= DateKey(RangeStart) and [OrderDateKey] < DateKey(RangeEnd))\n" +
"in\n" +
" #\"Filtered Rows\""
};
salesTable.RefreshPolicy = hybridPolicy;
model.RequestRefresh(TOM.RefreshType.Full);
model.SaveChanges();
}
Console.WriteLine("{0}{1}", Environment.NewLine, "Press [Enter] to exit...");
Console.ReadLine();
}
}
}