Bewährte Methoden zum Erstellen eines Dimensionsmodells mithilfe von Dataflows
Das Entwerfen eines dimensionalen Modells ist eine der am häufigsten verwendeten Aufgaben, die Sie mit einem Dataflow ausführen können. In diesem Artikel werden einige der bewährten Methoden zum Erstellen eines dimensionalen Modells mithilfe eines Dataflows erläutert.
Dataflows bereitstellen
Einer der wichtigsten Punkte in jedem Datenintegrationssystem besteht darin, die Anzahl der Lesevorgänge aus dem Quellbetriebssystem zu reduzieren. In der herkömmlichen Datenintegrationsarchitektur wird diese Reduzierung durch Erstellen einer neuen Datenbank, die als Staging-Datenbank bezeichnet wird, durchgeführt. Der Zweck der Staging-Datenbank besteht darin, Daten unverändert aus der Datenquelle regelmäßig in die Staging-Datenbank zu laden.
Der Rest der Datenintegration verwendet dann die Staging-Datenbank als Quelle für die weitere Transformation und Konvertierung in die dimensionale Modellstruktur.
Es wird empfohlen, denselben Ansatz mithilfe von Dataflows zu verfolgen. Erstellen Sie eine Reihe von Dataflows, die nur für das Laden von Daten wie aus dem Quellsystem (und nur für die benötigten Tabellen) verantwortlich sind. Das Ergebnis wird dann in der Speicherstruktur des Dataflows (entweder Azure Data Lake Storage oder Dataverse) gespeichert. Diese Änderung stellt sicher, dass der Lesevorgang aus dem Quellsystem minimal ist.
Als Nächstes können Sie andere Dataflows erstellen, die ihre Daten aus Staging-Dataflows beziehen. Dieser Ansatz bietet folgende Vorteile:
- Verringern der Anzahl der Lesevorgänge aus dem Quellsystem und Verringern der Auslastung des Quellsystems als Ergebnis
- Verringern der Auslastung von Datengateways bei Verwendung einer lokalen Datenquelle
- Besitzen einer Zwischenkopie der Daten zu Abgleichszwecken, falls sich die Quellsystemdaten ändern.
- Transformations-Dataflows quellenunabhängig machen
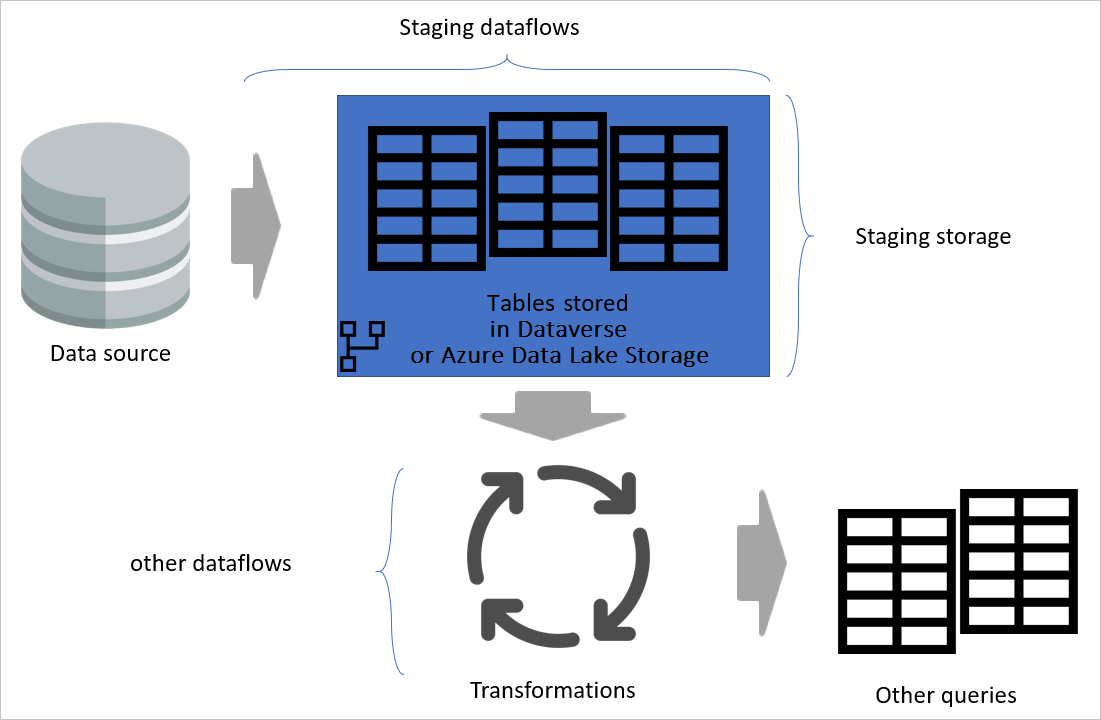
Bild, das die Bereitstellung von Dataflows und Staging-Speicher hervorhebt und zeigt, auf welche Daten über die Datenquelle über den Staging-Dataflow zugegriffen wird, und Tabellen, die entweder in Cadavers oder in Azure Data Lake Storage gespeichert werden. Anschließend wird gezeigt, wie die Tabellen zusammen mit anderen Dataflows transformiert werden, die dann als Abfragen gesendet werden.
Transformations-Dataflows
Wenn Sie die Transformations-Dataflows von den Staging-Dataflows getrennt haben, ist die Transformation unabhängig von der Quelle. Diese Trennung hilft, wenn Sie das Quellsystem zu einem neuen System migrieren. In diesem Fall müssen Sie lediglich die Staging-Dataflows ändern. Die Transformations-Dataflows funktionieren wahrscheinlich ohne Probleme, da sie nur aus den Staging-Dataflows stammen.
Diese Trennung hilft auch, falls die Quellsystemverbindung langsam ist. Der Transformations-Dataflow muss nicht lange warten, bis Datensätze über eine langsame Verbindung aus dem Quellsystem abgerufen werden. Der Staging-Dataflow hat diesen Teil bereits erledigt und die Daten sind für die Transformationsebene bereit.
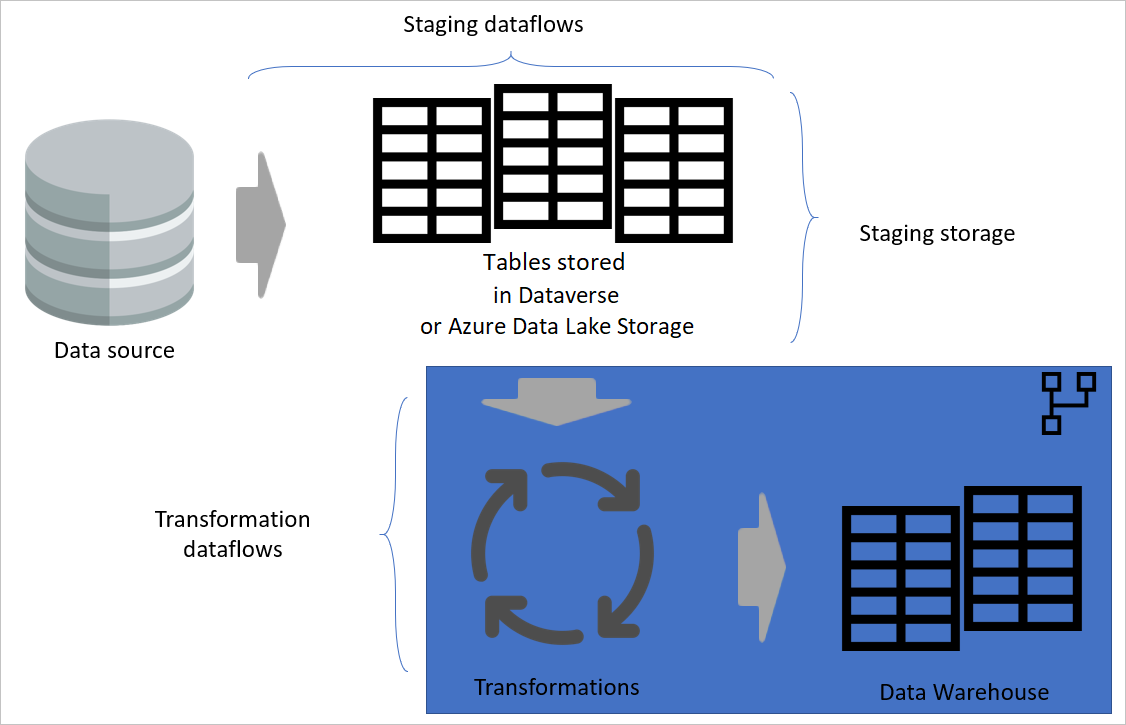
Ebenenarchitektur
Eine Ebenenarchitektur ist eine Architektur, in der Sie Aktionen in separaten Ebenen ausführen. Die Staging- und Transformations-Dataflows können zwei Ebenen einer mehrschichtigen Dataflow-Architektur sein. Durch den Versuch, Aktionen in Ebenen auszuführen, wird ein minimaler Wartungsaufwand sichergestellt. Wenn Sie etwas ändern möchten, müssen Sie es nur in der Ebene ändern, in der es sich befindet. Die anderen Ebenen sollten alle weiterhin einwandfrei funktionieren.
Die folgende Abbildung zeigt eine mehrschichtige Architektur für Dataflows, in denen ihre Tabellen dann in semantische Modelle von Power BI verwendet werden.
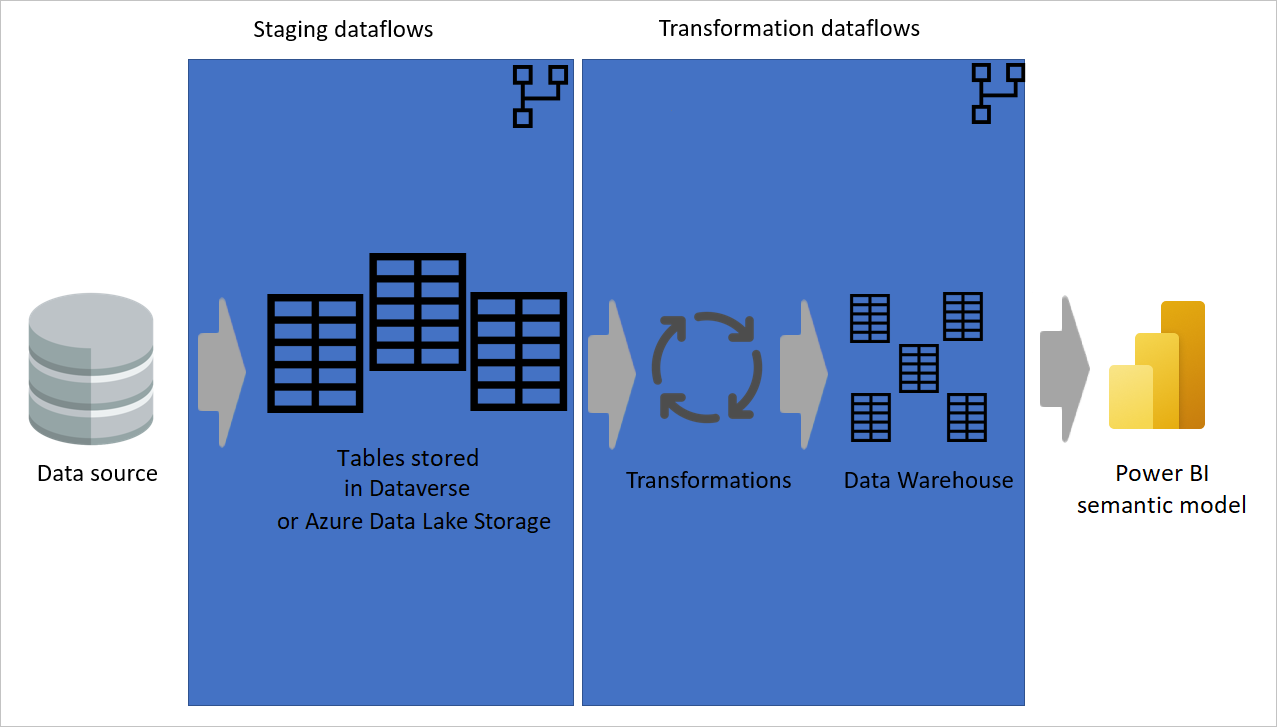
Möglichst eine berechnete Tabelle verwenden
Wenn Sie das Ergebnis eines Dataflows in einem anderen Dataflow verwenden, nutzen Sie das Konzept der berechneten Tabelle, was bedeutet, dass Daten aus einer „bereits verarbeiteten und gespeicherten Tabelle“ abgerufen werden. Dasselbe kann innerhalb eines Dataflows geschehen. Wenn Sie auf eine Tabelle aus einer anderen Tabelle verweisen, können Sie die berechnete Tabelle verwenden. Dies ist hilfreich, wenn Sie über eine Reihe von Transformationen verfügen, die in mehreren Tabellen ausgeführt werden müssen, die als allgemeine Transformationen bezeichnet werden.
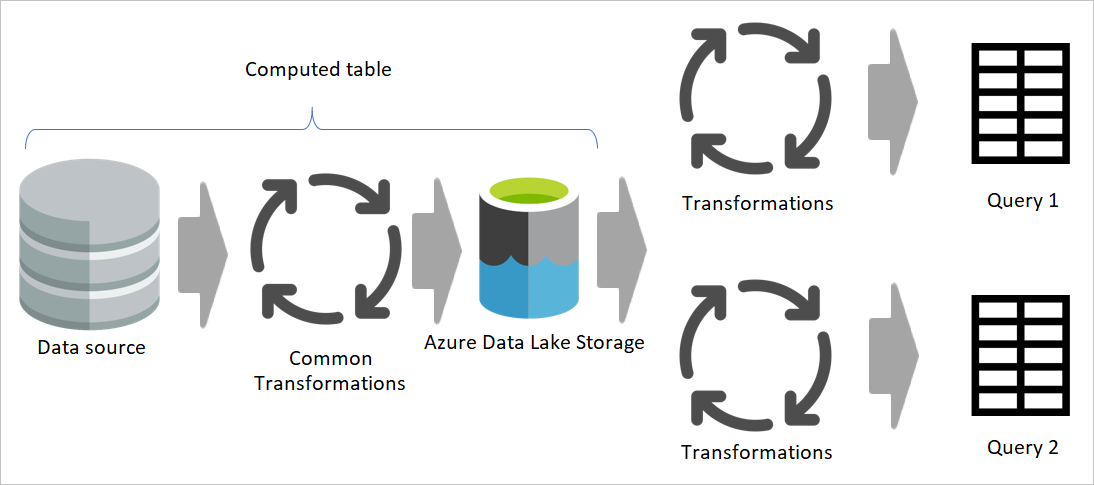
In der vorherigen Abbildung ruft die berechnete Tabelle die Daten direkt aus der Quelle ab. In der Architektur von Staging- und Transformations-Dataflows ist es jedoch wahrscheinlich, dass die berechneten Tabellen aus den Staging-Dataflows stammen.
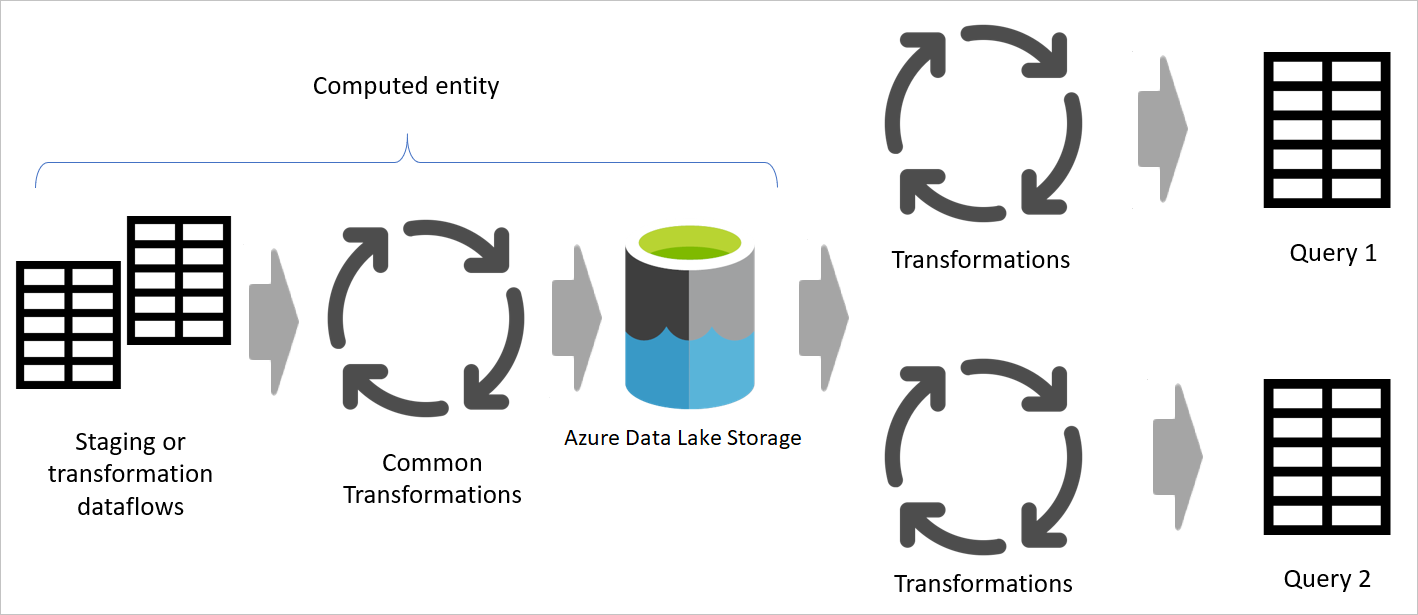
Ein Sternschema erstellen
Das beste dimensionale Modell ist ein Sternschemamodell, dessen Dimensionen und Faktentabellen so gestaltet sind, dass die Zeit zum Abfragen der Daten aus dem Modell minimiert wird und es außerdem für den Datenvisualisierer leicht verständlich ist.
Es ist nicht optimal, Daten im gleichen Layout des Betriebssystems in ein BI-System zu übertragen. Die Datentabellen sollten umgestaltet werden. Einige der Tabellen sollten in Form einer Dimensionstabelle verwendet werden, die die beschreibenden Informationen enthält. Einige der Tabellen sollten in Form einer Faktentabelle verwendet werden, um die aggregierbaren Daten beizubehalten. Das beste Layout für Faktentabellen und Dimensionstabellen ist ein Sternschema. Weitere Informationen: Informationen zum Sternschema und der Wichtigkeit für Power BI
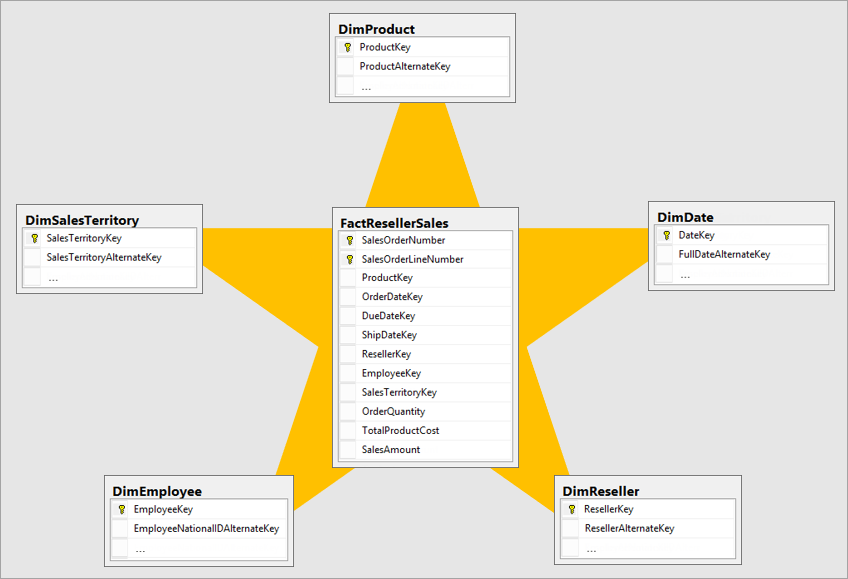
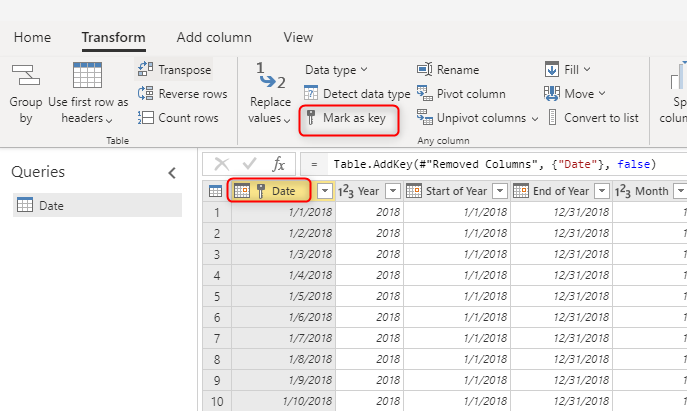
Einen eindeutigen Schlüsselwert für Dimensionen verwenden
Stellen Sie beim Erstellen von Dimensionstabellen sicher, dass Sie jeweils über einen Schlüssel verfügen. Dieser Schlüssel stellt sicher, dass zwischen Dimensionen keine m:n-Beziehungen (oder mit anderen Worten „schwache“) Beziehungen vorhanden sind. Sie können den Schlüssel erstellen, indem Sie eine Transformation anwenden, um sicherzustellen, dass eine Spalte oder eine Kombination von Spalten eindeutige Zeilen in der Dimension zurückgibt. Anschließend kann diese Kombination von Spalten als Schlüssel in der Tabelle im Dataflow markiert werden.
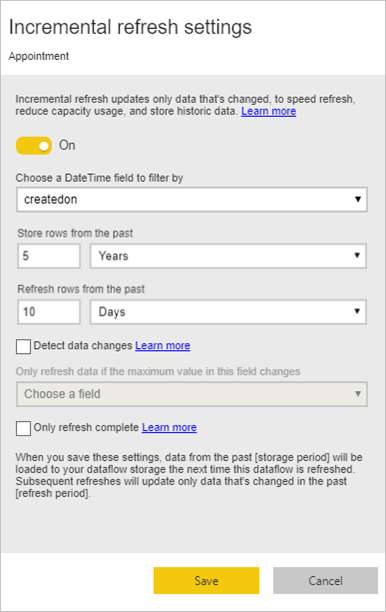
Eine inkrementelle Aktualisierung für große Faktentabellen durchführen
Faktentabellen sind immer die größten Tabellen im dimensionalen Modell. Wir empfehlen Ihnen, die Anzahl der übertragenen Zeilen für diese Tabellen zu reduzieren. Wenn Sie über eine sehr große Faktentabelle verfügen, stellen Sie sicher, dass Sie die inkrementelle Aktualisierung für diese Tabelle verwenden. Eine inkrementelle Aktualisierung kann im semantischen Modell von Power BI und auch in den Dataflow-Tabellen erfolgen.
Sie können die inkrementelle Aktualisierung verwenden, um nur einen Teil der Daten zu aktualisieren, nämlich den Teil, der sich geändert hat. Es gibt mehrere Optionen, um auszuwählen, welcher Teil der Daten aktualisiert und welcher Teil beibehalten werden soll. Weitere Informationen: Inkrementelle Aktualisierung mit Power BI-Dataflows verwenden
Auf das Erstellen von Dimensionen und Faktentabellen verweisen
Im Quellsystem verfügen Sie häufig über eine Tabelle, die Sie zum Generieren von Fakten- und Dimensionstabellen im Data Warehouse verwenden. Diese Tabellen sind geeignete Kandidaten für berechnete Tabellen und auch Zwischen-Dataflows. Der allgemeine Teil des Prozesses – etwa die Datenbereinigung und das Entfernen zusätzlicher Zeilen und Spalten – kann einmal durchgeführt werden. Mithilfe eines Verweises aus der Ausgabe dieser Aktionen können Sie die Dimensions- und Faktentabellen erstellen. Bei diesem Ansatz wird die berechnete Tabelle für die allgemeinen Transformationen verwendet.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für