Verwenden von Jupyter Notebooks in Azure Data Studio
Gilt für:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Jupyter Notebook ist eine Open Source-Webanwendung, mit der Sie Dokumente erstellen und freigeben können, die Livecode, Gleichungen, Visualisierungen und beschreibenden Text enthalten. Die Nutzung umfasst Folgendes: Bereinigung und Transformation von Daten, numerische Simulation, statistische Modellierung, Datenvisualisierung und Machine Learning.
In diesem Artikel wird beschrieben, wie Sie in der neuesten Version von Azure Data Studio ein Notebook erstellen und wie Sie mithilfe von verschiedenen Kernels mit der Erstellung eigener Notebooks beginnen.
Sehen Sie sich dieses kurze fünfminütige Video an, um eine Einführung in Notebooks in Azure Data Studio zu erhalten:
Erstellen eines Notebooks
Es gibt mehrere Möglichkeiten, ein neues Notebook zu erstellen. In jedem Fall wird eine neue Datei mit dem Namen Notebook-1.ipynb geöffnet.
Navigieren Sie in Azure Data Studio zum Menü „Datei“ , und klicken Sie auf Neues Notebook.
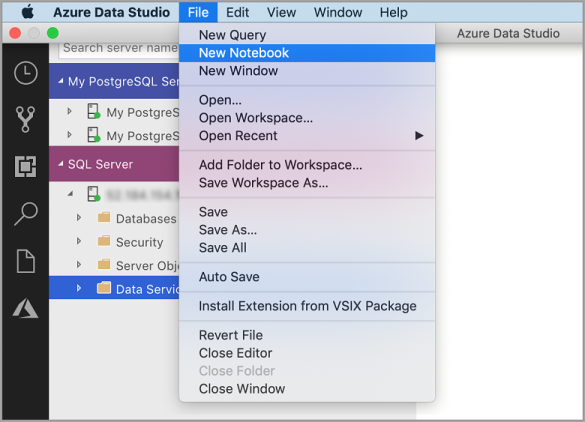
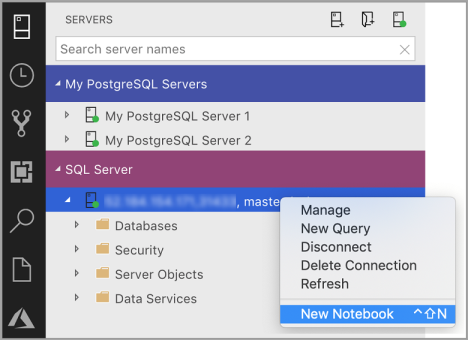
Klicken Sie mit der rechten Maustaste auf eine SQL Server-Verbindung, und klicken Sie auf Neues Notebook.
Öffnen Sie die Befehlspalette (STRG+UMSCHALT+P), geben Sie „Neues Notebook“ ein, und wählen Sie den Befehl Neues Notebook aus.

Herstellen einer Verbindung mit einem Kernel
Azure Data Studio-Notebooks unterstützen eine Reihe unterschiedlicher Kernels, einschließlich SQL Server, Python, PySpark und anderen. Jeder Kernel unterstützt eine andere Sprache in den Codezellen Ihres Notebooks. Wenn Sie z. B. eine Verbindung mit dem SQL Server-Kernel hergestellt haben, können Sie T-SQL-Anweisungen in eine Notebook-Codezelle eingeben und ausführen.
Die Anweisung Anfügen an stellt den Kontext für den Kernel bereit. Wenn Sie z. B. SQL-Kernel verwenden, können Sie die Anweisung „Anfügen an“ für jede der SQL Server-Instanzen verwenden. Wenn Sie Python3-Kernel verwenden, fügen Sie an localhost an, und Sie können diesen Kernel für Ihre lokale Python-Entwicklung verwenden.
Der SQL-Kernel kann auch verwendet werden, um eine Verbindung mit PostgreSQL-Serverinstanzen herzustellen. Wenn Sie ein PostgreSQL-Entwickler sind und eine Verbindung zwischen Ihren Notebooks und Ihrem PostgreSQL-Server herstellen möchten, müssen Sie die PostgreSQL-Erweiterung im Marketplace der Azure Data Studio-Erweiterung herunterladen und mit dem PostgreSQL-Server verbinden.
Wenn Sie mit dem Big Data-Cluster von SQL Server 2019 verbunden sind, ist die Standardanweisung Anfügen an der Endpunkt des Clusters. Sie können Python-, Scala-und R-Code über Spark-Compute des Clusters verwenden.
| Kernel | BESCHREIBUNG |
|---|---|
| SQL-Kernel | Schreiben Sie SQL-Code für Ihre relationale Datenbank. |
| PySpark3- und PySpark-Kernel | Schreiben Sie Python-Code mithilfe von Spark-Computing aus dem Cluster. |
| Spark-Kernel | Schreiben Sie Scala- und R-Code mithilfe von Spark-Computing aus dem Cluster. |
| Python-Kernel | Schreiben Sie Python-Code für die lokale Entwicklung. |
Weitere Informationen zu bestimmten Kernels finden Sie unter:
- Erstellen und Ausführen eines SQL Server-Notebooks
- Erstellen und Ausführen eines Python-Notebooks
- Kqlmagic-Erweiterung in Azure Data Studio – Dadurch werden die Funktionen des Python-Kernels erweitert.
Hinzufügen einer Codezelle
Mit Codezellen können Sie Code innerhalb des Notebooks interaktiv ausführen.
Fügen Sie eine neue Codezelle hinzu, indem Sie auf der Symbolleiste auf den Befehl +Zelle klicken und Codezelle auswählen. Nach der aktuell ausgewählten Zelle wird eine neue Codezelle hinzugefügt.
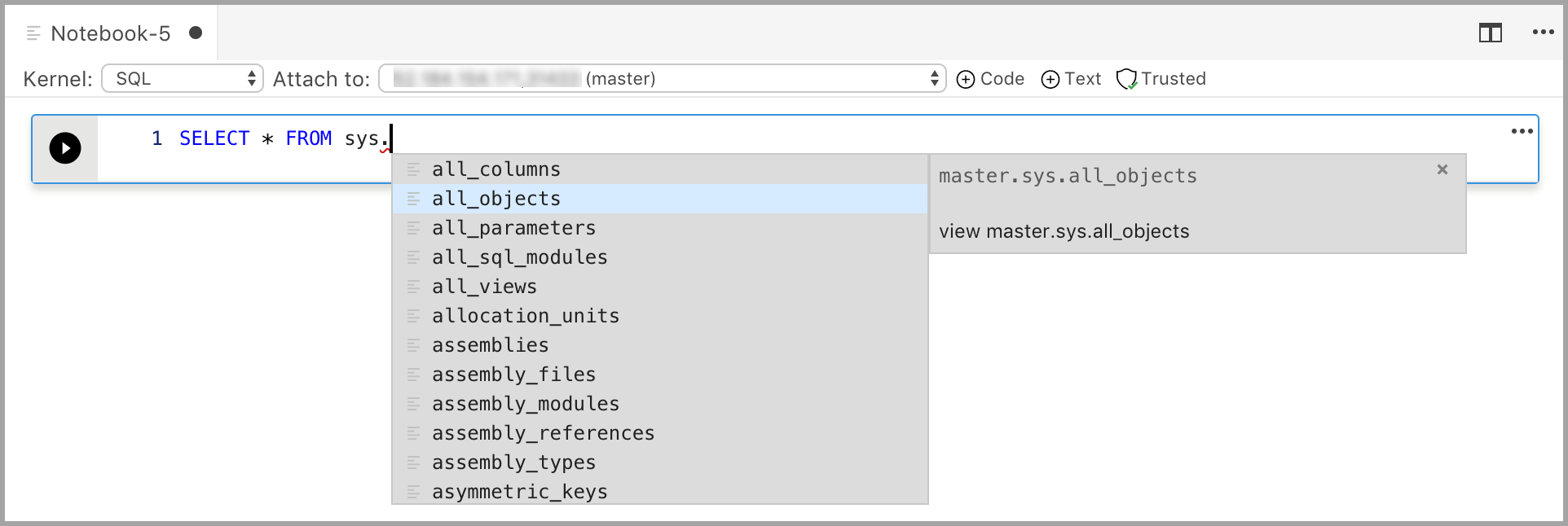
Geben Sie den Code für den ausgewählten Kernel in die Zelle ein. Wenn Sie z. B. den SQL-Kernel verwenden, können Sie T-SQL-Befehle in die Codezelle eingeben.
Die Eingabe von Code mit dem SQL-Kernel ähnelt einem SQL-Abfrage-Editor. Die Codezelle unterstützt ein modernes SQL-Programmierverfahren mit integrierten Features, wie einem umfangreichen SQL-Editor, IntelliSense und integrierten Codeausschnitten. Mit Codeausschnitten können Sie die richtige SQL-Syntax zum Erstellen von Datenbanken, Tabellen, Ansichten, gespeicherten Prozeduren und zum Aktualisieren vorhandener Datenbankobjekte generieren. Verwenden Sie Codeausschnitte, um schnell Kopien der Datenbank zu Entwicklungs- oder Testzwecken zu erstellen und Skripts zu generieren und auszuführen.
Hinzufügen einer Textzelle
Mithilfe von Textzellen können Sie Ihren Code dokumentieren, indem Sie zwischen Codezellen Markdowntextblöcke hinzufügen.
Fügen Sie eine neue Textzelle hinzu, indem Sie auf der Symbolleiste auf den Befehl +Zelle klicken und Textzelle auswählen.
Die Zelle beginnt im Bearbeitungsmodus, in dem Sie Markdowntext eingeben können. Während Sie die Eingabe vornehmen, erscheint eine Vorschau.
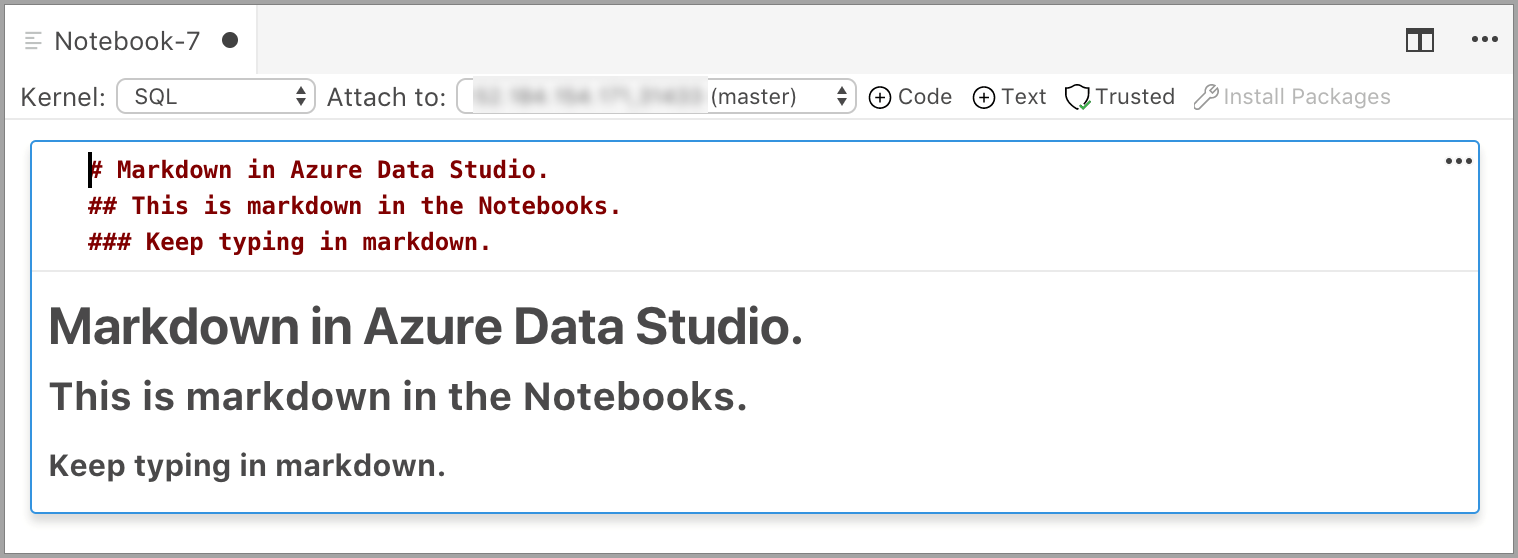
Wenn Sie außerhalb der Textzelle klicken, wird der Markdowntext angezeigt.
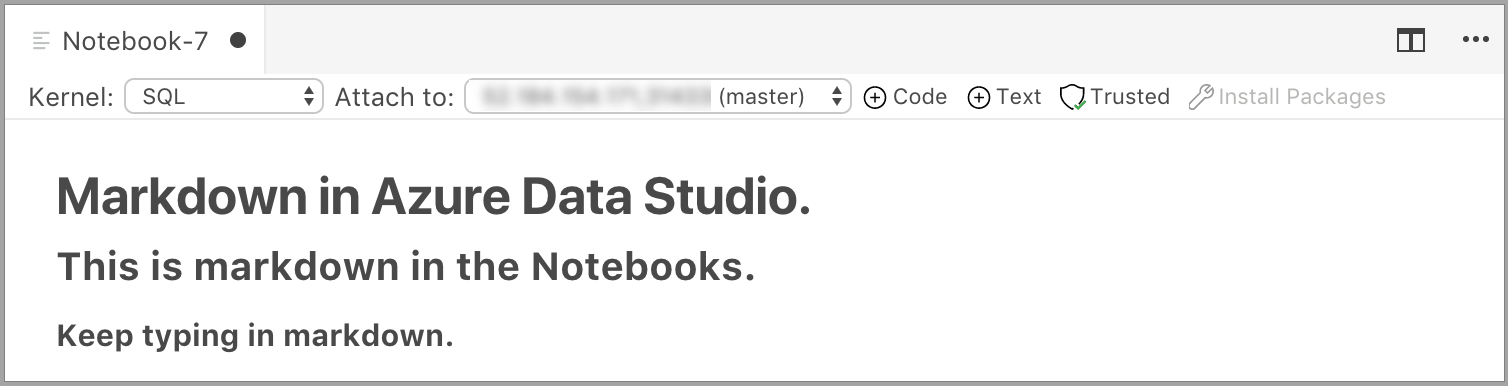
Wenn Sie noch mal in die Textzelle klicken, wird in den Bearbeitungsmodus gewechselt.
Ausführen einer Zelle
Klicken Sie zur Ausführung einer einzelnen Zelle auf Zelle ausführen (der runde schwarze Pfeil) links neben der Zelle, oder wählen Sie die Zelle aus, und drücken Sie F5. Sie können alle Zellen im Notebook ausführen, indem Sie auf Alle ausführen auf der Symbolleiste klicken. Die Zellen werden nacheinander ausgeführt, und die Ausführung wird beendet, wenn ein Fehler in einer Zelle auftritt.
Die Ergebnisse aus der Zelle werden unterhalb der Zelle angezeigt. Klicken Sie auf der Symbolleiste auf die Schaltfläche Ergebnisse löschen, wenn Sie die Ergebnisse aller ausgeführten Zellen im Notebook löschen möchten.
Speichern eines Notebooks
Führen Sie zum Speichern eines Notebooks eine der folgenden Aktionen aus.
- Drücken Sie STRG+S.
- Wählen Sie im Menü „Datei“ die Option Speichern aus.
- Wählen Sie im Menü „Datei“ die Option Speichern unter aus.
- Wählen Sie im Menü „Datei“ die Option Alle speichern aus. Dadurch werden alle offenen Notebooks gespeichert.
- Geben Sie in der Befehlspalette Datei: Speichern ein.
Notebooks werden als .ipynb-Dateien gespeichert.
Vertrauenswürdig und nicht vertrauenswürdig
In Azure Data Studio geöffnete Notebooks gelten standardmäßig als Vertrauenswürdig.
Wenn Sie ein Notebook aus einer anderen Quelle öffnen, wird es im Modus Nicht vertrauenswürdig geöffnet, und Sie können es dann als Vertrauenswürdig einstufen.
Beispiele
In den folgenden Beispielen wird die Verwendung verschiedener Kernel zum Ausführen eines einfachen Hallo Welt-Befehls veranschaulicht. Wählen Sie den Kernel aus, geben Sie den Beispielcode in eine Zelle ein, und klicken Sie auf Zelle ausführen.
PySpark
Spark | Scala-Sprache

Spark | R-Sprache
Python 3

Nächste Schritte
- Erstellen und Ausführen eines SQL Server-Notebooks
- Erstellen und Ausführen eines Python-Notebooks
- Ausführen von Python- und R-Skripts in Azure Data Studio-Notebooks mit SQL Server Machine Learning Services
- Bereitstellen eines Big Data-Clusters für SQL Server mit einem Azure Data Studio-Notebook
- Verwalten von SQL Server-Big Data-Clustern mit Azure Data Studio-Notebooks
- Ausführen eines Beispielnotebooks mithilfe von Spark
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für