Herstellen einer Verbindung mit einem Big-Data-Cluster für SQL Server mit Azure Data Studio
Gilt für:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
In diesem Artikel wird beschrieben, wie Sie über Azure Data Studio eine Verbindung mit einem SQL Server 2019: Big Data-Cluster herstellen.
Wichtig
Das Microsoft SQL Server 2019-Big Data-Cluster-Add-On wird eingestellt. Der Support für SQL Server 2019-Big Data-Clusters endet am 28. Februar 2025. Alle vorhandenen Benutzer*innen von SQL Server 2019 mit Software Assurance werden auf der Plattform vollständig unterstützt, und die Software wird bis zu diesem Zeitpunkt weiterhin über kumulative SQL Server-Updates verwaltet. Weitere Informationen finden Sie im Ankündigungsblogbeitrag und unter Big Data-Optionen auf der Microsoft SQL Server-Plattform.
Voraussetzungen
- Ein bereitgestellter Big-Data-Cluster für SQL Server 2019.
- Big Data-Tools für SQL Server 2019:
- Azure Data Studio
- Erweiterung von SQL Server 2019
- kubectl
- azdata
Herstellen einer Verbindung mit dem Cluster
Stellen Sie eine neue Verbindung mit der SQL Server-Masterinstanz im Cluster her, um eine Verbindung mit einem Big-Data-Cluster mit Azure Data Studio herzustellen. Gehen Sie dabei folgendermaßen vor:
Suchen Sie den Endpunkt der SQL Server-Masterinstanz:
azdata bdc endpoint list -e sql-server-masterTipp
Weitere Informationen zum Abrufen von Endpunkten finden Sie unter Abrufen von Endpunkten.
Drücken Sie F1>Neue Verbindung in Azure Data Studio.
Wählen Sie unter Verbindungstyp die Option Microsoft SQL Server aus.
Geben Sie den für die SQL Server-Masterinstanz gefundenen Endpunktnamen in das Textfeld bei Servername ein (Beispiel: <IP_Address>,31433).
Wählen Sie einen Authentifizierungstyp aus. Bei der SQL Server-Masterinstanz, die in einem Big Data Cluster ausgeführt wird, werden nur die Windows-Authentifizierung und SQL-Anmeldung unterstützt.
Geben Sie Ihren Benutzernamen und Ihr Kennwort ein, wenn Sie die SQL-Anmeldung verwenden.
Tipp
Der Benutzername SA ist während der Bereitstellung eines Big Data-Clusters standardmäßig deaktiviert. Während der Bereitstellung wird ein neuer sysadmin-Benutzer bereitgestellt, dessen Name und Kennwort den Umgebungsvariablen AZDATA_USERNAME und AZDATA_PASSWORD entsprechen, die entweder vor oder während der Bereitstellung festgelegt wurden.
Ändern Sie den Zieldatenbanknamen in einen ihrer relationalen Datenbanken.
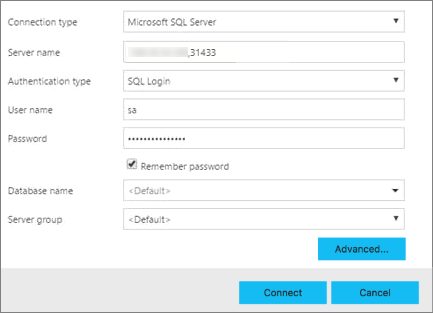
Klicken Sie auf Verbinden, und das Serverdashboard sollte angezeigt werden.
Mit der Azure Data Studio-Version vom Februar 2019 können Sie mit dem Herstellen einer Verbindung mit der SQL Server-Masterinstanz auch mit dem HDFS/Spark-Gateway interagieren. Dies bedeutet, dass Sie keine separate Verbindung für HDFS und Spark verwenden müssen, die im nächsten Abschnitt beschrieben wird.
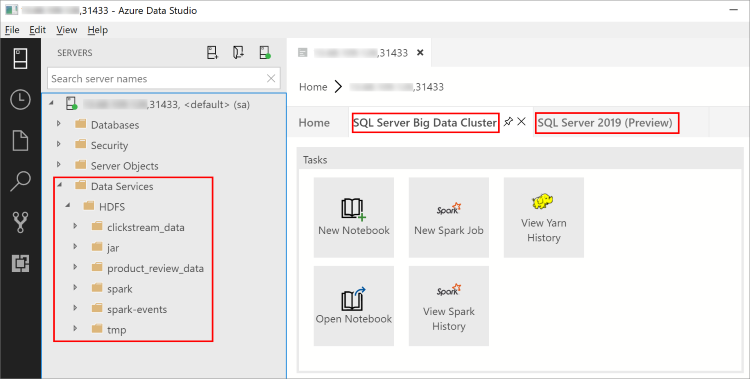
Der Objekt-Explorer enthält jetzt einen neuen Data Services-Knoten für Big-Data-Cluster-Aufgaben (z. B. das Erstellen neuer Notebooks oder das Übermitteln von Spark-Aufträgen), die mit einem Rechtsklick ausgeführt werden können.
Der Data Services-Knoten enthält auch einen HDFS-Ordner, mit dem Sie den Inhalt des HDFS untersuchen und allgemeine Aufgaben im Zusammenhang mit dem HDFS ausführen können (z. B. das Erstellen einer externen Tabelle oder das Öffnen eines Notebooks zum Analysieren des HDFS-Inhalts).
Das Serverdashboard für die Verbindung enthält auch Registerkarten für SQL Server-Big Data Cluster und SQL Server 2019, wenn die Erweiterung installiert ist.
Nächste Schritte
Weitere Informationen zu SQL Server 2019: Big Data-Cluster finden Sie unter Was sind SQL Server 2019: Big Data-Cluster?.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für