Überwachen der Leistung mithilfe des Abfragespeichers
Gilt für:![]() SQL Server 2016 (13.x) und höher
SQL Server 2016 (13.x) und höher![]() Azure SQL-Datenbank
Azure SQL-Datenbank![]() Azure SQL verwaltete Instanz
Azure SQL verwaltete Instanz![]() Azure Synapse Analytics (nur dedizierter SQL-Pool)
Azure Synapse Analytics (nur dedizierter SQL-Pool)
Das Feature „Abfragespeicher“ bietet Einblicke in die Auswahl und Leistung von Abfrageplänen für SQL Server, Azure SQL-Datenbank, Azure SQL Managed Instance und Azure Synapse Analytics. Der Abfragespeicher ermöglicht das schnelle Auffinden von Leistungsabweichungen, die auf Änderungen an Abfrageplänen zurückzuführen sind, und vereinfacht so die Behandlung von Leistungsproblemen. Der Abfragespeicher erfasst automatisch einen Verlauf der Abfragen, Pläne und Laufzeitstatistiken und bewahrt diese zur Überprüfung auf. Es unterteilt die Daten nach Zeitfenstern, sodass Sie Verwendungsmuster für Datenbanken erkennen können und verstehen, wann Abfrageplanänderungen auf dem Server aufgetreten sind. Sie können den Abfragespeicher mit der Option ALTER DATABASE SET konfigurieren.
- Informationen zum Betrieb des Abfragespeichers in Azure SQL-Datenbank finden Sie unter Betrieb des Abfragespeichers in Azure SQL-Datenbank.
- Informationen zum Ermitteln von handlungsrelevanten Informationen und zur Optimierung der Leistung mit dem Abfragespeicher finden Sie unter Optimieren der Leistung mit dem Abfragespeicher.
- Informationen zum Gestalten von Abfrageplänen ohne Änderung des Anwendungscodes finden Sie unter Abfragespeicherhinweise (Vorschau).
Wichtig
Wenn Sie Abfragespeicher für just in time Workload Insights in SQL Server 2016 (13.x) verwenden, planen Sie, die Leistungsskalierbarkeitskorrekturen in KB-4340759 so schnell wie möglich zu installieren.
Aktivieren des Abfragespeichers
- Der Abfragespeicher ist für neue Azure SQL-Datenbank-Instanzen und für neue Azure SQL Managed Instance-Datenbanken standardmäßig aktiviert.
- Abfragespeicher ist für SQL Server 2016 (13.x), SQL Server 2017 (14.x), SQL Server 2019 (15.x) nicht standardmäßig aktiviert. Sie ist standardmäßig im
READ_WRITEModus für neue Datenbanken ab SQL Server 2022 (16.x) aktiviert. Um Features zum besseren Nachverfolgen des Leistungsverlaufs, zur Problembehandlung im Zusammenhang mit Abfrageplänen und zum Aktivieren neuer Funktionen in SQL Server 2022 (16.x) zu ermöglichen, empfehlen wir, Abfragespeicher für alle Datenbanken zu aktivieren. - Der Abfragespeicher ist für neue Azure Synapse Analytics-Datenbanken nicht standardmäßig aktiviert.
Verwenden der Seite „Abfragespeicher“ in SQL Server Management Studio
Klicken Sie im Objekt-Explorer mit der rechten Maustaste auf eine Datenbank und anschließend auf Eigenschaften.
Hinweis
Erfordert mindestens Version 16 von Management Studio.
Wählen Sie im Dialogfeld Datenbankeigenschaften die Seite Abfragespeicher aus.
Wählen Sie im Feld Betriebsmodus (angefordert) die Option Lesen und schreiben aus.
Verwenden von Transact-SQL-Anweisungen
Verwenden Sie die ALTER DATABASE-Anweisung, um den Abfragespeicher für eine bestimmte Datenbank zu aktivieren. Beispiel:
ALTER DATABASE <database_name>
SET QUERY_STORE = ON (OPERATION_MODE = READ_WRITE);
Aktivieren Sie in Azure Synapse Analytics beispielsweise den Abfragespeicher ohne zusätzliche Optionen:
ALTER DATABASE <database_name>
SET QUERY_STORE = ON;
Weitere Syntaxoptionen im Zusammenhang mit dem Abfragespeicher finden Sie unter ALTER DATABASE SET-Optionen (Transact-SQL).
Hinweis
Der Abfragespeicher kann für die Datenbanken master oder tempdb nicht aktiviert werden.
Wichtig
Informationen zum Aktivieren des Abfragespeichers und dazu, wie Sie ihn an Ihre Arbeitsauslastung angepasst halten, finden Sie unter Bewährte Methoden für den Abfragespeicher.
Informationen im Abfragespeicher
Ausführungspläne für eine bestimmte Abfrage in SQL Server entwickeln sich in der Regel im Laufe der Zeit aufgrund verschiedener Gründe wie Statistikänderungen, Schemaänderungen, Erstellung/Löschung von Indizes usw. Der Prozedurcache (bei dem zwischengespeicherte Abfragepläne gespeichert werden) speichert nur den neuesten Ausführungsplan. Pläne werden auch bei Speicherplatzknappheit aus dem Plancache entfernt. Aus diesem Grund kann die Problembehandlung bei einer Regression der Abfrageleistung schwierig und zeitaufwendig sein.
Da der Abfragespeicher mehrere Ausführungspläne pro Abfrage beibehält, kann er über Richtlinien den Abfrageprozessor anweisen, für eine Abfrage einen bestimmten Ausführungsplan zu verwenden. Dies wird als Planerzwingung bezeichnet. Das Erzwingen eines Plans im Abfragespeicher erfolgt ähnlich wie beim Abfragehinweis USE PLAN , es erfordert jedoch keine Änderung an Benutzeranwendungen. Durch das Erzwingen eines Plans können Sie eine Regression der Abfrageleistung aufgrund einer Änderung des Plans in sehr kurzer Zeit beheben.
Hinweis
Der Abfragespeicher sammelt Pläne für DML-Anweisungen wie SELECT, INSERT, UPDATE, DELETE, MERGE und BULK INSERT.
Standardmäßig sammelt Abfragespeicher keine Pläne für DDL-Anweisungen wie CREATE INDEX usw. Abfragespeicher erfasst den kumulierten Ressourcenverbrauch, indem Pläne für die zugrunde liegenden DML-Anweisungen erfasst werden. Beispielsweise können Abfragespeicher die SELECT- und INSERT-Anweisungen anzeigen, die intern ausgeführt werden, um einen neuen Index aufzufüllen.
Der Abfragespeicher sammelt standardmäßig keine Daten für systemintern kompilierte gespeicherte Prozeduren. Verwenden Sie sys.sp_xtp_control_query_exec_stats, um die Datensammlung für systemintern kompilierte gespeicherte Prozeduren zu aktivieren.
Wait stats are another source of information that helps to troubleshoot performance in the Datenbank-Engine. Lange Zeit waren Wartestatistiken nur auf Instanzebene verfügbar, wodurch es schwierig war, sie einer bestimmten Abfrage zuzuordnen. Ab SQL Server 2017 (14.x) und Azure SQL-Datenbank enthält Abfragespeicher eine Dimension, die Wartezeitstatistiken nachverfolgt. Im folgenden Beispiel wird die Abfragespeicher zum Sammeln von Wartezeitstatistiken aktiviert.
ALTER DATABASE <database_name>
SET QUERY_STORE = ON ( WAIT_STATS_CAPTURE_MODE = ON );
Häufige Szenarios für die Verwendung des Abfragespeichers:
- Schnelles Auffinden und Beheben von Regressionen der Planleistung durch Erzwingung des vorherigen Abfrageplans Korrigieren von Abfragen, die in der Vergangenheit aufgrund von Änderungen am Ausführungsplan die Leistung vermindert haben
- Bestimmen der Ausführungshäufigkeit einer Abfrage in einem festgelegten Zeitraum mit Unterstützung eines DBAs bei der Behandlung von Leistungsproblemen mit Ressourcen
- Identifizieren der häufigsten n Abfragen (nach Ausführungszeit, Speicherverbrauch usw.) in den letzten x Stunden.
- Überwachen des Verlaufs von Abfrageplänen für eine bestimmte Abfrage
- Analysieren der Verwendungsmuster einer Ressource (CPU, E/A und Arbeitsspeicher) für eine bestimmte Datenbank
- Identifizieren Sie Top-N-Abfragen, die auf den Ressourcen warten.
- Erhalten Sie Einblick in die Wartedetails einer bestimmten Abfrage oder eines bestimmten Plans.
Der Abfragespeicher enthält drei Speicher:
- einen Planspeicher, der die Informationen zum Ausführungsplan speichert
- einen Speicher für Laufzeitstatistiken, der die Informationen zum Ausführungsstatistiken speichert
- einen Speicher für Wartestatistiken, der die Informationen zum Wartestatistiken speichert
Die Anzahl der eindeutigen Pläne, die für eine Abfrage gespeichert werden können, wird durch die Konfigurationsoption max_plans_per_query begrenzt. Zum Verbessern der Leistung werden diese Informationen asynchron in die Speicher geschrieben. Um die Speicherverwendung zu minimieren, werden die statistischen Daten zur Laufzeitausführung im Speicher für Laufzeitstatistiken über ein festes Zeitintervall aggregiert. Die Informationen in diesen Speichern können durch Abfragen der Katalogsichten für den Abfragespeicher angezeigt werden.
Die folgende Abfrage gibt Informationen über Abfragen und Pläne im Abfragespeicher zurück.
SELECT Txt.query_text_id, Txt.query_sql_text, Pl.plan_id, Qry.*
FROM sys.query_store_plan AS Pl
INNER JOIN sys.query_store_query AS Qry
ON Pl.query_id = Qry.query_id
INNER JOIN sys.query_store_query_text AS Txt
ON Qry.query_text_id = Txt.query_text_id;
Abfragespeicher für sekundäre Replikate
Gilt für: SQL Server (ab SQL Server 2022 (16.x))
Mit dem Abfragespeicher für sekundäre Replikate können die Abfragespeicherfunktionen, die für primäre Replikate zur Verfügung stehen, auch für Workloads sekundärer Replikate verwendet werden. Wenn der Abfragespeicher für sekundäre Replikate aktiviert ist, senden Replikate die Abfrageausführungsinformationen, die normalerweise im Abfragespeicher gespeichert werden, an das primäre Replikat zurück. Das primäre Replikat speichert die Daten dann auf dem Datenträger in seinem eigenen Abfragespeicher. Im Wesentlichen gibt es also einen einzelnen Abfragespeicher, die vom primären Replikat und von allen sekundären Replikaten gemeinsam genutzt wird. Die Abfragespeicher befindet sich im primären Replikat und speichert Daten für alle Replikate an einem Ort.
Vollständige Informationen zu Abfragespeicher für sekundäre Replikate finden Sie unter Abfragespeicher für sekundäre Replikate der AlwaysOn-Verfügbarkeitsgruppe.
Verwenden des Features "Regressed Queries"
Aktualisieren Sie nach der Aktivierung des Abfragespeichers den Datenbankbereich im Objekt-Explorer-Bereich, um den Abschnitt Abfragespeicher hinzuzufügen.
Hinweis
Für Azure Synapse Analytics sind Sichten des Abfragedatenspeichers unter Systemsichten im Datenbankbereich des Objekt-Explorers verfügbar.
Wählen Sie "Zurückgerückte Abfragen " aus, um den Bereich "Zurückgeschrittene Abfragen " in SQL Server Management Studio zu öffnen. Im Bereich „Regressed Queries“ werden die Abfragen und Pläne im Abfragespeicher angezeigt. Verwenden Sie die Dropdownlistenfelder oben, um Abfragen basierend auf verschiedenen Kriterien zu filtern: Dauer (ms) (Standard), CPU-Zeit (ms), Logische Lesevorgänge (KB), Logische Schreibvorgänge (KB), Physische Lesevorgänge (KB), CLR-Zeit (ms), DOP, Speicherverbrauch (KB), Zeilenanzahl, verwendete Protokollspeicher (KB), Temp DB-Arbeitsspeicher verwendet (KB) und Wartezeit (ms).
Wählen Sie einen Plan aus, um die grafische Darstellung des Abfrageplans anzuzeigen. Schaltflächen stehen zur Verfügung, um die Quellabfrage anzuzeigen, einen Abfrageplan zu erzwingen bzw. seine Erzwingung aufzuheben, zwischen Raster- und Diagrammformaten umzuschalten, ausgewählte Pläne zu vergleichen (wenn mehrere Pläne ausgewählt sind) und die Anzeige zu aktualisieren.
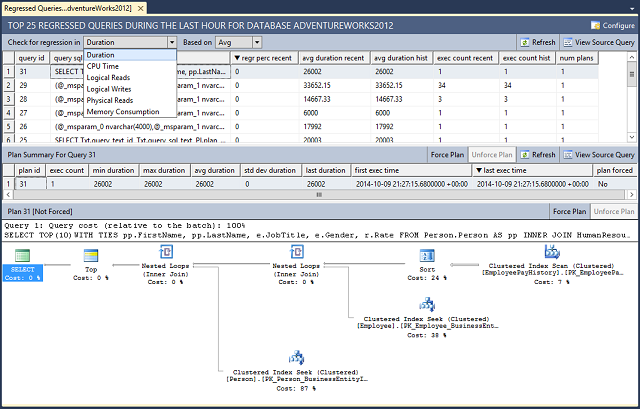
Um einen Plan zu erzwingen, wählen Sie eine Abfrage und einen Plan aus, und klicken Sie anschließend auf Plan erzwingen. Sie können nur Pläne erzwingen, die mit dem Abfrageplanfeature gespeichert wurden und sich noch im Abfrageplancache befinden.
Suchen nach wartenden Abfragen
Ab SQL Server 2017 (14.x) und Azure SQL-Datenbank sind Wartezeitstatistiken pro Abfrage im Laufe der Zeit in Abfragespeicher verfügbar.
Im Abfragespeicher werden Wartetypen in Wartekategorien zusammengefasst. Die Zuordnung von Wartekategorien zu Wartetypen finden Sie unter sys.query_store_wait_stats (Transact-SQL).
Wählen Sie "Abfragewartestatistik" aus, um den Bereich "Abfragewartestatistik " in SQL Server Management Studio v18 oder höher zu öffnen. Der Bereich „Abfragewartestatistiken“ zeigt ein Balkendiagramm mit den wichtigsten Wartekategorien im Abfragespeicher an. Verwenden Sie die Dropdownliste oben, um ein Aggregatkriterium für die Wartezeit auszuwählen: durchschn. Durchschnitt, Max., Min., Std.-Entwicklung und Summe (Standardeinstellung).
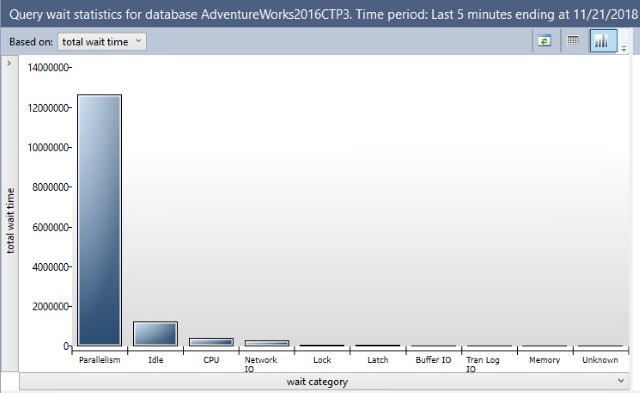
Wählen Sie eine Wartekategorie aus, indem Sie auf der Leiste und in der ausgewählten Wartekategorie eine Detailansicht auswählen. Dieses neue Balkendiagramm enthält die Abfragen, die zu dieser Wartekategorie beigetragen haben.

Verwenden Sie das Dropdownlistenfeld oben, um Abfragen basierend auf verschiedenen Wartezeitkriterien für die ausgewählte Wartekategorie zu filtern: durchschnittliche, max, min, std dev und total (Standard). Wählen Sie einen Plan aus, um die grafische Darstellung des Abfrageplans anzuzeigen. Über verschiedene Schaltflächen können Sie die Quellabfrage anzeigen, einen Abfrageplan erzwingen und die Erzwingung wieder aufheben und die Ansicht aktualisieren.
Wartekategorien fassen mehrere Wartetypen in Buckets zusammen, die sich in ihrer Art ähneln. Verschiedene Wartekategorien erfordern verschiedene Analysen zur Problembehebung. Wartetypen aus der gleichen Kategorien führen jedoch zu sehr ähnlichen Problembehebungsvorgängen. Wenn nun die betroffenen Abfrage in den Wartezuständen bereitgestellt wird, können die meisten Überprüfungen erfolgreich abgeschlossen werden.
Im folgenden finden Sie einige Beispiele, wie Sie ausführlicheren Einblick in Ihre Workload erhalten, bevor oder nachdem Wartekategorien im Abfragespeicher eingefügt wurden:
| Frühere Erfahrung | Neue Erfahrung | Aktion |
|---|---|---|
| Lange Wartezustände von RESOURCE_SEMAPHORE pro Datenbank | Lange Speicherwartezustände im Abfragespeicher für bestimmte Abfragen | Suchen Sie die im Abfragespeicher die speicherintensivsten Abfragen. Diese Abfragen verzögern wahrscheinlich zusätzlich den Fortschritt der betroffen Abfragen. Ziehen Sie in Betracht, den Abfragehinweis „MAX_GRANT_PERCENT“ für diese Abfragen oder für die betroffene Abfrage zu verwenden. |
| Lange Wartezustände von LCK_M_X pro Datenbank | Lange Sperrwartezustände im Abfragespeicher für bestimmte Abfragen | Überprüfen Sie die Abfragetexte der betroffenen Abfragen, und identifizieren Sie die Zielentitäten. Suchen Sie im Abfragespeicher nach anderen Abfragen, die die gleiche Entität modifizieren und die häufig ausgeführt werden bzw. oder eine lange Dauer haben. Nachdem Sie diese Abfragen ermittelt haben, ändern Sie ggf. die Anwendungslogik, um die Parallelität zu verbessern, oder verwenden Sie eine weniger restriktive Isolationsstufe. |
| Lange Wartezustände von PAGEIOLATCH_SH pro Datenbank | Lange Wartezustände der Puffer-E/A im Abfragespeicher für bestimmte Abfragen | Suchen Sie die Abfragen mit einer hohen Anzahl an physischen Lesevorgängen im Abfragespeicher. Wenn Sie mit den Abfragen mit langen E/A-Wartezuständen übereinstimmen, denken Sie darüber nach, einen Index auf der zugrunde liegenden Entität einzufügen, damit Suchvorgänge statt Scanvorgängen durchgeführt werden und damit der E/A-Aufwand der Abfragen gesenkt wird. |
| Lange Wartezustände von SOS_SCHEDULER_YIELD pro Datenbank | Lange CPU-Wartezustände im Abfragespeicher für bestimmte Abfragen | Machen Sie die Abfragen im Abfragespeicher ausfindig, die am meisten CPU nutzen. Bestimmen Sie dann, welche dieser Abfragen sowohl eine hohe CPU-Auslastung als auch lange CPU-Wartezustände für die betroffenen Abfragen aufweisen. Konzentrieren Sie sich darauf, diese Abfragen zu optimieren: möglicherweise gibt es eine Planregression, oder es fehlt ein Index. |
Konfigurationsoptionen
Weitere Informationen zu den verfügbaren Konfigurationsoptionen für Abfragespeicherparameter finden Sie unter ALTER DATABASE SET-Optionen (Transact-SQL).
Fragen Sie die Sicht sys.database_query_store_options ab, um die aktuellen Optionen des Abfragespeichers zu ermitteln. Weitere Informationen zu den Werten finden Sie unter sys.database_query_store_options.
Beispiele für das Festlegen der Konfigurationsoptionen mit Transact-SQL-Anweisungen finden Sie unter Optionsverwaltung.
Hinweis
Für Azure Synapse Analytics kann der Abfragespeicher wie auf anderen Plattformen auch aktiviert werden, aber zusätzliche Konfigurationsoptionen werden nicht unterstützt.
Verwandte Sichten, Funktionen und Prozeduren
Anzeigen und Verwalten von Abfragespeicher über Management Studio oder mithilfe der folgenden Ansichten und Verfahren.
Funktionen des Abfragespeichers
Funktionen unterstützen Sie bei den Vorgängen des Abfragespeichers.
Katalogsichten des Abfragespeichers
Katalogsichten stellen Informationen über den Abfragespeicher bereit.
Gespeicherte Prozeduren für den Abfragespeicher
Gespeicherte Prozeduren ermöglichen das Konfigurieren des Abfragespeichers.
sp_query_store_consistency_check (Transact-SQL)1
1 In extremen Szenarien kann der Abfragespeicher aufgrund interner Fehler in den Zustand FEHLER geraten. Falls dies eintritt, kann der Abfragespeicher ab SQL Server 2017 (14.x) wiederhergestellt werden, indem in der betroffenen Datenbank die gespeicherte Prozedur sp_query_store_consistency_check ausgeführt wird. Weitere Einzelheiten finden Sie unter sys.database_query_store_options in der Beschreibung der Spalte actual_state_desc.
Abfragespeicher Standard tenance
Bewährte Methoden und Empfehlungen für Standard Tenance und Verwaltung der Abfragespeicher wurden in diesem Artikel erweitert: Bewährte Methoden für die Verwaltung der Abfragespeicher.
Leistungsüberwachung und Problembehandlung
Weitere Informationen zur Leistungsoptimierung mit dem Abfragespeicher finden Sie unter Optimieren der Leistung mit dem Abfragespeicher.
Weitere leistungsbezogene Themen:
Siehe auch
- Gespeicherte Prozeduren für den Abfragespeicher (Transact-SQL)
- Query Store Catalog Views (Transact-SQL)
- sys.database_query_store_options (Transact-SQL)
- Live-Abfragestatistik
- Aktivitätsmonitor
- So werden Daten im Abfragespeicher gesammelt
- Überwachen und Optimieren der Leistung
- Tools für die Leistungsüberwachung und -optimierung
- Verwenden des Abfragespeichers mit In-Memory-OLTP
Nächste Schritte
- Bewährte Methoden mit dem Abfragespeicher
- Bewährte Methoden zum Verwalten der Abfragespeicher
- Optimieren der Leistung mit dem Abfragespeicher
- Abfragespeicherhinweise
- Query Store Usage Scenarios (Verwendungsszenarien für den Abfragespeicher)
- Öffnen des Aktivitätsmonitors (SQL Server Management Studio)
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für