DBCC SHOW_STATISTICS (Transact-SQL)
Gilt für:![]() SQL Server
SQL Server![]() Azure SQL-Datenbank
Azure SQL-Datenbank![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() Azure Synapse Analytics
Azure Synapse Analytics![]() Analytics Platform System (PDW)
Analytics Platform System (PDW)![]() SQL Analytics-Endpunkt in Microsoft Fabric
SQL Analytics-Endpunkt in Microsoft Fabric![]() Warehouse in Microsoft Fabric
Warehouse in Microsoft Fabric
So wird die aktuelle Abfrageoptimierungsstatistik für eine Tabelle oder eine indizierte Sicht angezeigt. Der Abfrageoptimierer verwendet Statistiken zur Schätzung der Kardinalität oder Zeilenanzahl im Abfrageergebnis und ermöglicht somit dem Abfrageoptimierer, einen Abfrageplan von hoher Qualität zu erstellen. Beispielsweise kann der Abfrageoptimierer Kardinalitätsschätzungen verwenden, um im Abfrageplan statt des Index Scan-Operators den Index Seek-Operator auszuwählen und so die Abfrageleistung zu verbessern, indem ein ressourcenintensiver Indexscan vermieden wird.
Der Abfrageoptimierer speichert die Statistiken für eine Tabelle oder indizierte Sicht in einem Statistikobjekt. Für eine Tabelle wird das Statistikobjekt entweder für einen Index oder eine Liste mit Tabellenspalten erstellt. Das Statistikobjekt enthält einen Header mit Metadaten über die Statistik, ein Histogramm mit der Verteilung der Werte in der ersten Schlüsselspalte des Statistikobjekts sowie einen Dichtevektor zum Messen der Korrelation zwischen Spalten. Die Datenbank-Engine kann Kardinalitätsschätzungen mit beliebigen Daten des Statistikobjekts berechnen. Weitere Informationen finden Sie unter Statistik und Kardinalitätsschätzung (SQL Server).
DBCC SHOW_STATISTICS zeigt den Header, das Histogramm und den Dichtevektor auf der Grundlage von Daten an, die im Statistikobjekt gespeichert sind. Die Syntax ermöglicht es Ihnen, eine Tabelle oder indizierte Sicht zusammen mit einem Zielindexnamen, Statistiknamen oder Spaltennamen anzugeben.
Wichtige Updates in früheren Versionen von SQL Server:
Ab SQL Server 2012 (11.x) Service Pack 1 steht die dynamische Verwaltungssicht sys.dm_db_stats_properties zur Verfügung, um die im Statistikobjekt enthaltenen Headerinformationen für nicht inkrementelle Statistiken programmgesteuert abzurufen.
Ab SQL Server 2014 (12.x) Service Pack 2 und SQL Server 2012 (11.x) Service Pack 1 steht die dynamische Verwaltungssicht sys.dm_db_incremental_stats_properties zur Verfügung, um die im Statistikobjekt enthaltenen Headerinformationen für inkrementelle Statistiken programmgesteuert abzurufen.
Ab SQL Server 2016 (13.x) Service Pack 1 CU 2 steht die dynamische Verwaltungssicht sys.dm_db_stats_histogram zur Verfügung, um Histogramminformationen, die im Statistikobjekt enthalten sind, programmgesteuert abzurufen.
-
Diese Syntax wird vom serverlosen SQL-Pool in Azure Synapse Analytics nicht unterstützt.
Weitere Informationen zu Statistiken in Microsoft Fabric finden Sie unter Statistiken.
![]() Transact-SQL-Syntaxkonventionen
Transact-SQL-Syntaxkonventionen
Syntax
Syntax für SQL Server und Azure SQL-Datenbank:
DBCC SHOW_STATISTICS ( table_or_indexed_view_name , target )
[ WITH [ NO_INFOMSGS ] < option > [ , ...n ] ]
< option > ::=
STAT_HEADER | DENSITY_VECTOR | HISTOGRAM | STATS_STREAM
[ ; ]
Syntax für Azure Synapse Analytics, Analytics Platform System (PDW) und Microsoft Fabric:
DBCC SHOW_STATISTICS ( table_name , target )
[ WITH { STAT_HEADER | DENSITY_VECTOR | HISTOGRAM } [ , ...n ] ]
[ ; ]
Hinweis
Informationen zum Anzeigen der Transact-SQL-Syntax für SQL Server 2014 (12.x) oder früher finden Sie unter Dokumentation zu früheren Versionen.
Argumente
table_or_indexed_view_name
Name der Tabelle oder der indizierten Sicht, für die statistische Informationen angezeigt werden sollen.
table_name
Der Name der Tabelle, die die anzuzeigenden Statistiken enthält. Die Tabelle kann keine externe Tabelle sein.
Ziel
Der Name des Indexes, der Statistik oder der Spalte, für die Statistikinformationen angezeigt werden sollen. target wird in Klammern, einzelnen Anführungszeichen oder doppelten Anführungszeichen gesetzt, bzw. es werden keine Anführungszeichen verwendet.
- Wenn target ein Name eines vorhandenen Indexes oder einer vorhandenen Statistik für eine Tabelle oder eine indizierte Sicht ist, werden die Statistikinformationen zu diesem Ziel zurückgegeben.
- Wenn target der Name einer vorhandenen Spalte ist und ein automatisch erstelltes Statistikobjekt für diese Spalte vorhanden ist, werden Informationen zu dieser automatisch erstellten Statistik zurückgegeben.
Wenn keine automatisch erstellte Statistik für ein Spaltenziel vorhanden ist, wird die Fehlermeldung 2767 zurückgegeben.
In Azure Synapse Analytics and Analytics Platform System (PDW) kann target kein Spaltenname sein.
In Warehouse in Microsoft Fabric kann target der Name einer einspaltigen Histogrammstatistik oder einer Spalte sein. Wenn ein Spaltenname für target verwendet wird, gibt dieser Befehl nur Verteilungsinformationen über die automatisch generierte Histogrammstatistik zurück. Um die Informationen zu einer manuell erstellten Histogrammstatistik anzuzeigen, geben Sie den Statistiknamen als target an.
NO_INFOMSGS
Unterdrückt alle Informationsmeldungen mit einem Schweregrad von 0 bis 10.
STAT_HEADER | DENSITY_VECTOR | HISTOGRAM | STATS_STREAM [ , n ]
Wenn mindestens eine dieser Optionen angegeben wird, schränkt dies die Resultsets ein, die von der Anweisung an die angegebene Option oder die angegebenen Optionen zurückgegeben werden. Wenn keine Optionen angegeben sind, werden alle Statistikinformationen zurückgegeben.
STATS_STREAM wird nur für Informationszwecke identifiziert. Wird nicht unterstützt. Zukünftige Kompatibilität wird nicht sichergestellt.
Resultset
In der folgenden Tabelle werden die Spalten beschrieben, die im Resultset zurückgegeben werden, wenn STAT_HEADER angegeben wird.
| Spaltenname | BESCHREIBUNG |
|---|---|
| Name | Name des Statistikobjekts. |
| Aktualisiert | Datum und Uhrzeit des letzten Updates der Statistik. Die Funktion STATS_DATE ist eine alternative Möglichkeit zum Abrufen dieser Informationen. Weitere Informationen finden Sie im Abschnitt Hinweise dieses Artikels. |
| Zeilen | Gesamtanzahl der Zeilen in der Tabelle oder indizierten Sicht zum Zeitpunkt des letzten Updates der Statistik. Wenn die Statistik gefiltert wird oder einem gefilterten Index entspricht, kann die Anzahl der Zeilen geringer als die Anzahl der Zeilen in der Tabelle sein. Weitere Informationen finden Sie unter Verwalten von Statistiken für Tabellen in SQL Data Warehouse. |
| Rows Sampled | Gesamtzahl der Zeilen, die für die statistischen Berechnungen in die Stichprobe aufgenommen wurden. Wenn Rows Sampled < Rows, sind das angezeigte Histogramm und die Dichteergebnisse Schätzungen auf Grundlage der als Stichprobe entnommenen Zeilen. |
| Schritte | Anzahl der Schritte im Histogramm. Jeder Schritt umfasst einen Bereich von Spaltenwerten gefolgt von einem oberen Spaltengrenzwert. Die Histogrammschritte werden in der Statistik in der ersten Schlüsselspalte definiert. Die maximale Anzahl von Schritten ist 200. |
| Dichte | Berechnet als 1 / verschiedene Werte für alle Werte in der ersten Schlüsselspalte des Statistikobjekts mit Ausnahme der Begrenzungswerte des Histogramms. Dieser Dichtewert wird vom Abfrageoptimierer nicht verwendet und für die Abwärtskompatibilität mit Versionen vor SQL Server 2008 (10.0.x) angezeigt. |
| Average Key Length | Durchschnittliche Anzahl von Bytes pro Wert für alle Schlüsselspalten im Statistikobjekt. |
| String Index | "Ja" gibt an, dass das Statistikobjekt Statistiken über Zusammenfassungen von Zeichenfolgen enthält, um die Kardinalitätsschätzungen für Abfrageprädikate, die den LIKE-Operator verwenden, zu verbessern, z. B. WHERE ProductName LIKE '%Bike'. Statistiken über Zusammenfassungen von Zeichenfolgen werden getrennt vom Histogramm gespeichert und in der ersten Schlüsselspalte des Statistikobjekts erstellt, wenn dieses vom Typ char, varchar, nchar, nvarchar, varchar(max) , nvarchar(max) , text oder ntext ist. |
| Filterausdruck | Prädikat für die Teilmenge von Tabellenzeilen, die im Statistikobjekt enthalten sind. NULL = nicht gefilterte Statistiken Weitere Informationen zu gefilterten Prädikaten finden Sie unter Erstellen gefilterter Indizes. Weitere Informationen zu gefilterten Statistiken finden Sie unter Statistiken. |
| Unfiltered Rows | Gesamtzahl von Zeilen in der Tabelle vor dem Anwenden des Filterausdrucks. Wenn Der Filterausdruck gleich NULL ist, ist Unfiltered Rows gleich Rows. |
| Persistierter Beispielprozentwert | Der persistierte Prozentwert für die Stichprobe wird für Aktualisierungen von Statistiken verwendet, die keinen expliziten Prozentwert für die Stichprobenentnahme angibt. Wenn der Wert 0 (null) ist, wird kein persistierter Prozentwert für diese Statistik festgelegt. Gilt für: SQL Server 2016 (13.x) Service Pack 1 CU 4 |
In der folgenden Tabelle werden die Spalten beschrieben, die beim Angeben von DENSITY_VECTOR im Resultset zurückgegeben werden.
| Spaltenname | BESCHREIBUNG |
|---|---|
| All Density | Die Dichte ist 1 / verschiedene Werte. Die Ergebnisse zeigen die Dichte für jedes Präfix von Spalten im Statistikobjekt mit einer Zeile pro Dichte an. Bei einem unterschiedlichen Wert handelt es sich um eine unterschiedliche Liste der Spaltenwerte pro Zeile und pro Spaltenpräfix. Wenn das Statistikobjekt beispielsweise Schlüsselspalten (A, B, C) enthält, geben die Ergebnisse die Dichte der unterschiedlichen Wertelisten jedes dieser Spaltenpräfixe an: (A), (A,B) und (A, B, C). Mit dem Präfix (A, B, C) ist jede dieser Listen eine Liste unterschiedlicher Werte: (3, 5, 6), (4, 4, 6), (4, 5, 6), (4, 5, 7). Mit dem Präfix (A, B) weisen dieselben Spaltenwerte diese unterschiedlichen Wertelisten auf: (3, 5), (4, 4) und (4, 5) |
| Average Length | Durchschnittliche Länge in Bytes zum Speichern einer Liste der Spaltenwerte für das Spaltenpräfix. Wenn die Werte in der Liste (3, 5, 6) beispielsweise jeweils 4 Bytes erfordern, beträgt die Länge 12 Bytes. |
| Spalten | Namen der Spalten im Präfix, für die All Density und Average Length angezeigt werden. |
Die folgende Tabelle beschreibt die Spalten, die im Resultset zurückgegeben werden, wenn die HISTOGRAM-Option angegeben wird.
| Spaltenname | BESCHREIBUNG |
|---|---|
| RANGE_HI_KEY | Oberer Spaltengrenzwert für einen Histogrammschritt. Der Spaltenwert wird auch als Schlüsselwert bezeichnet. |
| RANGE_ROWS | Geschätzte Anzahl von Zeilen, deren Spaltenwerte innerhalb eines Histogrammschritts liegen, ohne den oberen Grenzwert. |
| EQ_ROWS | Geschätzte Anzahl von Zeilen, deren Spaltenwerte der Obergrenze des Histogrammschritts entsprechen. |
| DISTINCT_RANGE_ROWS | Geschätzte Anzahl von Zeilen mit einem unterschiedlichen Spaltenwert innerhalb eines Histogrammschritts ohne den oberen Grenzwert. |
| AVG_RANGE_ROWS | Durchschnittliche Anzahl von Zeilen mit einem duplizierten Spaltenwert innerhalb eines Histogrammschritts ohne den oberen Grenzwert. Wenn DISTINCT_RANGE_ROWS größer als 0 ist, wird AVG_RANGE_ROWS berechnet, indem RANGE_ROWS durch DISTINCT_RANGE_ROWS dividiert wird. Wenn DISTINCT_RANGE_ROWS 0 ist, gibt AVG_RANGE_ROWS 1 für den Histogrammschritt zurück. |
Hinweise
Das Aktualisierungsdatum für die Statistiken befindet sich gemeinsam mit dem Histogramm und Dichtevektor nicht in den Metadaten, sondern im Statistik-Blobobjekt. Wenn für das Generieren von Statistikdaten keine Daten gelesen werden, wird das Statistik-Blob nicht erstellt, das Datum nicht verfügbar und die Spalte aktualisiert ist NULL. Dies ist der Fall bei gefilterten Statistiken oder neuen und leeren Tabellen, für die das Prädikat keine Zeilen zurückgibt.
Histogramm
Ein Histogramm misst die Häufigkeit des Vorkommens für jeden unterschiedlichen Wert in einem Dataset. Der Abfrageoptimierer berechnet ein Histogramm für die Spaltenwerte in der ersten Schlüsselspalte des Statistikobjekts und wählt die Spaltenwerte aus, indem statistische Zeilenstichproben entnommen werden oder indem ein vollständiger Scan aller Zeilen in der Tabelle oder Sicht ausgeführt wird. Wenn das Histogramm anhand einer Gruppe von Zeilenstichproben erstellt wird, handelt es sich bei der gespeicherten Gesamtzahl von Zeilen und unterschiedlichen Werten um Schätzungen, die keine ganzen Zahlen sein müssen.
Zum Erstellen des Histogramms sortiert der Abfrageoptimierer die Spaltenwerte, berechnet die Anzahl der Werte, die den einzelnen unterschiedlichen Spaltenwerten entsprechen, und aggregiert die Spaltenwerte dann in maximal 200 zusammenhängenden Histogrammschritten. Jeder Schritt enthält einen Bereich von Spaltenwerten gefolgt von einem oberen Spaltengrenzwert. Der Bereich enthält alle möglichen Spaltenwerte zwischen den Begrenzungswerten, ohne die Begrenzungswerte selbst. Der niedrigste der sortierten Spaltenwerte ist der obere Grenzwert für den ersten Histogrammschritt.
Das folgende Diagramm zeigt ein Histogramm mit sechs Schritten. Der Bereich links vom ersten oberen Grenzwert ist der erste Schritt.

Für jeden Histogrammschritt gilt:
- Eine fett formatierte Zeile stellt den oberen Grenzwert (RANGE_HI_KEY) und die Häufigkeit des Vorkommens dar (EQ_ROWS).
- Der einfarbige Bereich links von RANGE_HI_KEY stellt den Bereich der Spaltenwerte und die durchschnittliche Häufigkeit des Vorkommens der einzelnen Spaltenwerte (AVG_RANGE_ROWS) dar. AVG_RANGE_ROWS ist für den ersten Histogrammschritt immer 0.
- Gepunktete Linien stellen die als Stichprobe entnommenen Werte dar, die zum Schätzen der Gesamtanzahl der unterschiedlichen Werte im Bereich (DISTINCT_RANGE_ROWS) verwendet werden, sowie die Gesamtanzahl der Werte im Bereich (RANGE_ROWS). Der Abfrageoptimierer verwendet RANGE_ROWS und DISTINCT_RANGE_ROWS, um AVG_RANGE_ROWS zu berechnen. Die als Stichprobe entnommenen Werte werden nicht gespeichert.
Der Abfrageoptimierer definiert die Histogrammschritte gemäß ihrer statistischen Bedeutung. Dabei wird ein Algorithmus für die maximale Differenz verwendet, um die Anzahl der Schritte im Histogramm zu minimieren und gleichzeitig die Differenz zwischen den Begrenzungswerten zu maximieren. Die maximale Anzahl von Schritten ist 200. Die Anzahl von Histogrammschritten kann geringer sein als die Anzahl unterschiedlicher Werte, auch bei Spalten mit weniger als 200 Grenzpunkten. Beispielsweise kann eine Spalte mit 100 unterschiedlichen Werten ein Histogramm mit weniger als 100 Grenzpunkten aufweisen.
Dichtevektor
Der Abfrageoptimierer verwendet Dichten, um Kardinalitätsschätzungen für Abfragen zu erweitern, die mehrere Spalten aus derselben Tabelle oder indizierten Sicht zurückgeben. Der Dichtevektor enthält eine Dichte für jedes Präfix von Spalten im Statistikobjekt. Wenn ein Statistikobjekt beispielsweise die Schlüsselspalten CustomerId, ItemId und Price enthält, wird die Dichte für jedes der folgenden Spaltenpräfixe berechnet:
| Spaltenpräfix | Dichte berechnet für |
|---|---|
(CustomerId) |
Zeilen mit übereinstimmenden Werten für CustomerId |
(CustomerId, ItemId) |
Zeilen mit übereinstimmenden Werten für CustomerId und ItemId |
(CustomerId, ItemId, Price) |
Zeilen mit übereinstimmenden Werten für CustomerId, ItemId und Price |
Begrenzungen
DBCC SHOW_STATISTICS stellt keine Statistik für räumliche Indizes oder speicheroptimierte Columnstore-Indizes bereit.
Berechtigungen für SQL Server und SQL-Datenbank
Zum Anzeigen des Statistikobjekts muss der Benutzer über die SELECT-Berechtigung für die Tabelle verfügen.
Die folgenden Voraussetzungen müssen erfüllt sein, damit der Befehl erfolgreich mit SELECT-Berechtigung ausgeführt werden kann:
- Die Benutzer benötigen eine Zugriffsberechtigung für alle Spalten im Statistikobjekt.
- Die Benutzer benötigen eine Zugriffsberechtigung für alle Spalten in einer Filterbedingung (falls vorhanden).
- Die Tabelle kann keine Sicherheitsrichtlinie auf Zeilenebene haben.
- Wenn eine der Spalten innerhalb eines Statistikobjekts mit dynamischen Datenmaskierungsregeln maskiert ist, muss der Benutzer neben der
SELECT-Berechtigung über dieUNMASK-Berechtigung verfügen oder ein Mitglied der Rolle db_ddladmin sein.
In Versionen vor SQL Server 2012 (11.x) Service Pack 1 müssen Benutzer*innen die Tabelle besitzen oder Mitglieder der festen Serverrolle sysadmin, der festen Datenbankrollen db_owner oder db_ddladmin sein.
Hinweis
Verwenden Sie das Ablaufverfolgungsflag 9485, um das Verhalten vor SQL Server 2012 (11.x) Service Pack 1 wiederherzustellen.
Berechtigungen für Azure Synapse Analytics und Analytics Platform System (PDW)
DBCC SHOW_STATISTICS erfordert die SELECT-Berechtigung für die Tabelle oder Mitgliedschaft in der festen Serverrolle sysadmin, der festen Datenbankrolle db_owner oder der festen Datenbankrolle db_ddladmin.
Einschränkungen für Azure Synapse Analytics und Analytics-Plattformsystem (PDW)
DBCC SHOW_STATISTICS zeigt Statistiken an, die in der Shell-Datenbank auf der Ebene des Steuerelements gespeichert sind. Statistiken die automatisch von SQL Server auf den Computeknoten erstellt wurden, werden nicht angezeigt.
DBCC SHOW_STATISTICS wird für externe Tabellen nicht unterstützt.
In Microsoft Fabric zeigt DBCC SHOW_STATISTICS nur Ergebnisse für Histogrammstatistiken, keine ACE-*-Statistiken an.
Beispiele: SQL Server und Azure SQL-Datenbank
A. Zurückgeben aller Statistikinformationen
Im folgenden Beispiel werden alle Statistikinformationen für den Index AK_Address_rowguid der Tabelle Person.Address in der AdventureWorks2022-Datenbank angezeigt.
DBCC SHOW_STATISTICS ("Person.Address", AK_Address_rowguid);
GO
B. Angeben der HISTOGRAM-Option
Dies beschränkt die für Customer_LastName angezeigten Statistikinformationen auf die HISTOGRAM-Daten.
DBCC SHOW_STATISTICS ("dbo.DimCustomer", Customer_LastName) WITH HISTOGRAM;
GO
Beispiele: Azure Synapse Analytics und Analytics-Plattformsystem (PDW)
C. Anzeigen der Inhalte eine Statistikobjekts
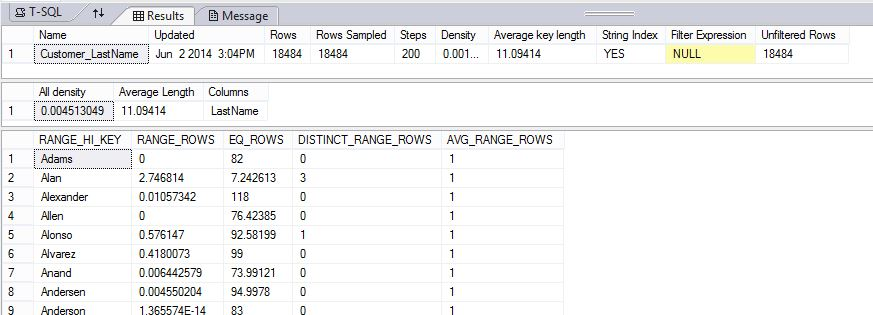
Im folgenden Beispiel wird ein Statistikobjekt erstellt und anschließend der Inhalt der Customer_LastName-Statistiken in der DimCustomer-Tabelle der Beispieldatenbank AdventureWorksPDW2022 angezeigt.
-- Uses AdventureWorksPDW
--First, create a statistics object
CREATE STATISTICS Customer_LastName
ON AdventureWorksPDW2012.dbo.DimCustomer (LastName);
GO
DBCC SHOW_STATISTICS ("dbo.DimCustomer", Customer_LastName);
GO
Die Ergebnisse zeigen den Header, den Dichtevektor und einen Teil des Histogramms an.
Siehe auch
- Statistik
- Statistiken in Microsoft Fabric
- sys.dm_db_stats_properties (Transact-SQL)
- sys.dm_db_stats_histogram (Transact-SQL)
- sys.dm_db_incremental_stats_properties (Transact-SQL)
Nächste Schritte
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für