Übung: Verwenden von Abfragen zum Untersuchen von Trends
Sie haben sich mit den Rohdaten und dem Bereich eines unbekannten meteorologischen Datasets beschäftigt. In dieser Lerneinheit werden Sie visuelle Elemente verwenden, um zu prüfen, wie die Daten verteilt sind.
Zeitdiagramm
Erinnern Sie sich, dass einige Datenspalten, die Sie in der letzten Lerneinheit gesehen haben, vom Typ DateTime waren und Start- und Endzeiten für Sturmereignisse darstellten. Sie können die Anzahl der Einträge in Abhängigkeit von der Zeit plotten, um zu sehen, bei welchen Datumsangaben Sturmereignisse aufgetreten sind.
Beachten Sie, dass die vorherige Lerneinheit eine Teilmenge von 50 Datenzeilen verwendet hat, während diese Lerneinheit das gesamte Dataset verwenden wird.
Mit der folgenden Abfrage erstellen Sie ein Zeitdiagramm mit der Anzahl der Sturmereignisse pro 8-Stunden-Intervall als Funktion der Zeit.
Führen Sie die folgende Abfrage aus:
StormEvents | summarize Count = count() by bin (StartTime, 8h) | render timechartSie sollten Ergebnisse erhalten, die wie in der folgenden Abbildung aussehen:
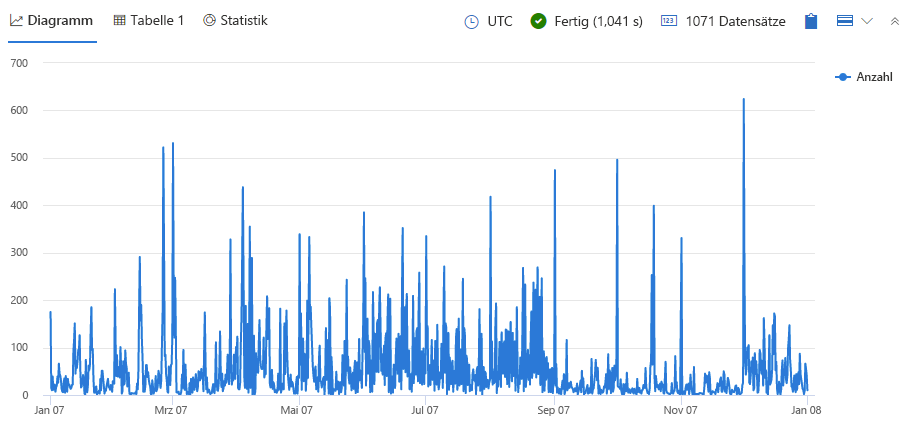
Werfen Sie einen Blick auf das resultierende Diagramm. Sehen Sie offensichtliche Lücken oder Anomalien?
Ereignisse nach Bundesstaat
Eine andere Möglichkeit, die Datenverteilung zu betrachten, ist die Gruppierung nach Ereignisort, in diesem Fall nach Bundesstaat, um zu prüfen, welche Art von Trends sich aus der Verteilung ableiten lassen.
Führen Sie die folgende Abfrage aus:
StormEvents | summarize event = count() by State | sort by event | render barchartSie sollten Ergebnisse erhalten, die wie in der folgenden Abbildung aussehen:
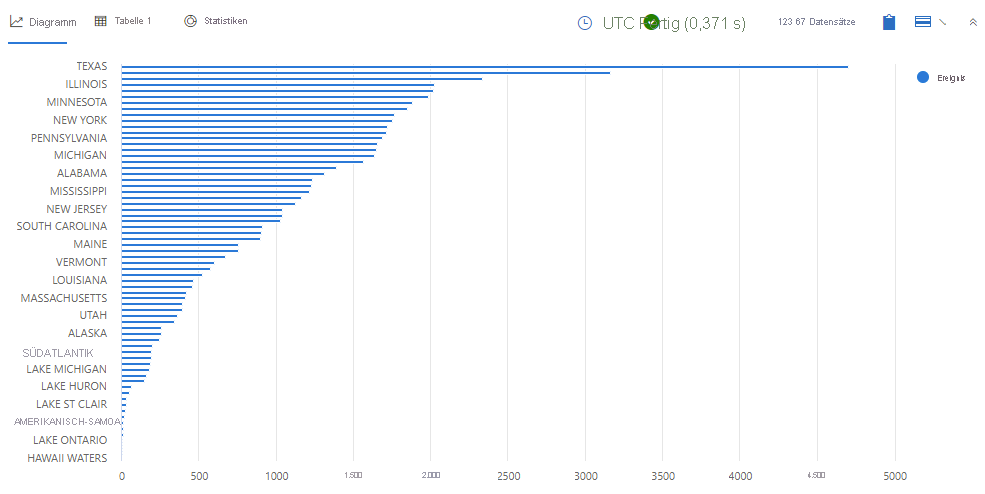
Werfen Sie einen Blick auf das resultierende Diagramm. Die Liste enthält 67 verschiedene Bundesstaaten – darunter auch solche, die keine offiziellen US-Bundesstaaten sind, z. B. „Amerikanisch-Samoa“ und „Hawaii-Gewässer“. Ist diese Art der geografischen Verteilung des Sturms sinnvoll?
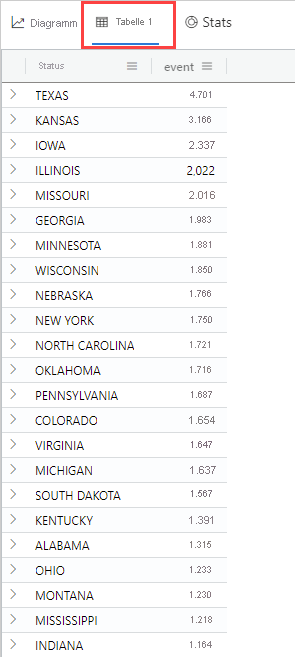
Sie können sich die zugrunde liegenden Daten ansehen, indem Sie auf die Registerkarte Tabelle oberhalb des Diagramms klicken. Helfen Ihnen die tatsächlichen Zahlen, die Datenverteilung besser zu verstehen?
Ereignisse nach geografischem Standort
Sie haben gesehen, wie die Anzahl der Ereignisse je nach Zeit und Bundesstaat variiert. Erinnern Sie sich daran, dass die Schemazuordnung gezeigt hat, dass jeder Eintrag zu einem Sturmereignis Informationen zum Breiten- und Längengrad enthält. Schauen wir uns an, wie die Daten auf einer Karte angeordnet sind.
Die folgende Abfrage gruppiert Ereignisse nach geografischen Zellen und zählt die Anzahl der Ereignisse in jeder Zelle. Diese Ergebnisse werden auf einer Karte angezeigt, wobei die Größe des Kreises der Anzahl der Ereignisse in dieser Zelle entspricht. Führen Sie die folgende Abfrage aus:
StormEvents | project BeginLon, BeginLat | where isnotnull(BeginLat) and isnotnull(BeginLon) | summarize count_summary=count() by hash = geo_point_to_s2cell(BeginLon, BeginLat,6) | project geo_s2cell_to_central_point(hash), count_summary | extend Events = "count" | render piechart with (kind = map)Sie sollten Ergebnisse erhalten, die wie in der folgenden Abbildung aussehen:

Versuchen Sie zu zoomen, indem Sie STRG+ drücken. Nachdem Sie jetzt die dargestellten Arten von Stürmen gesehen haben, ist es sinnvoll, dass es im Nordosten der USA und im Golf von Mexiko mehr dieser Arten von Stürmen gibt?