Kapazitätsplanung für Active Directory Domain Services
Dieses Thema wurde ursprünglich von Ken Brumfield geschrieben, Program Manager bei Microsoft, und enthält Empfehlungen zur Kapazitätsplanung für Active Directory Domain Services (AD DS).
Ziele der Kapazitätsplanung
Kapazitätsplanung ist nicht identisch mit der Problembehandlung bei Leistungsvorfällen. Sie sind eng miteinander verbunden, aber sehr unterschiedlich. Die Ziele der Kapazitätsplanung sind:
- Ordnungsgemäßes Implementieren und Betreiben einer Umgebung
- Minimieren Sie den Zeitaufwand für die Behandlung von Leistungsproblemen.
Bei der Kapazitätsplanung kann eine Organisation ein Basisziel von 40 % Prozessorauslastung in Spitzenzeiten erzielen, um die Anforderungen an die Clientleistung zu erfüllen und die für das Upgrade der Hardware im Rechenzentrum erforderliche Zeit zu berücksichtigen. Zur Benachrichtigung bei ungewöhnlichen Leistungsvorfällen kann ein Überwachungswarnungs-Schwellenwert über ein Intervall von fünf Minuten auf 90 % festgelegt werden.
Der Unterschied ist: Bei ständiger Überschreitung eines Schwellenwerts für die Kapazitätsverwaltung (ein einmaliges Ereignis ist nicht von Belang) wäre das Hinzufügen von Kapazität (d. h. Hinzufügen weiterer oder schnellerer Prozessoren) oder die mehrere Server übergreifende Skalierung des Dienstes eine Lösung. Schwellenwerte für Leistungswarnungen geben an, dass die Clienterfahrung derzeit beeinträchtigt wird und sofortige Schritte erforderlich sind, um das Problem zu beheben.
Zur Veranschaulichung: Die Kapazitätsverwaltung entspricht den Maßnahmen, einen Autounfall zu verhindern (defensives Fahren, Sicherstellen, dass die Bremsen ordnungsgemäß funktionieren usw.), während die Leistungsproblembehandlung dem entspricht, was Polizei, Feuerwehr und Notfallmediziner nach einem Unfall leisten. Hier geht es um „defensives Fahren“, im Active Directory-Stil.
In den letzten Jahren hat sich die Kapazitätsplanungsanleitung für Hochskalierungssysteme erheblich verändert. Die folgenden Änderungen in Systemarchitekturen haben grundlegende Annahmen zum Entwerfen und Skalieren eines Diensts in Frage gestellt:
- 64-Bit-Serverplattformen
- Virtualisierung
- Kritischere Betrachtung des Stromverbrauchs
- SSD-Speicher
- Cloudszenarien
Darüber hinaus verschiebt sich der Ansatz von einer serverbasierten Kapazitätsplanungsübung zu einer dienstbasierten Kapazitätsplanungsübung. Active Directory Domain Services (AD DS), ein ausgereifter verteilter Dienst, den viele Microsoft- und Drittanbieterprodukte als Back-End verwenden, wird zu einem der wichtigsten Produkte für die richtige Planung, um die erforderliche Kapazität für die Ausführung anderer Anwendungen sicherzustellen.
Grundlegende Anforderungen für die Anleitung zur Kapazitätsplanung
In diesem Artikel gelten die folgenden grundlegenden Anforderungen:
- Die Leser haben die Richtlinien zur Leistungsoptimierung für Windows Server 2012 R2 gelesen und kennen sie.
- Die Windows Server-Plattform ist eine x64-basierte Architektur. Aber auch wenn Ihre Active Directory-Umgebung unter Windows Server 2003 x86 (jetzt über das Ende des Supportlebenszyklus hinaus) installiert ist und über eine Verzeichnisinformationsstruktur (Directory Information Tree, DIT) verfügt, die weniger als 1,5 GB groß ist und problemlos im Arbeitsspeicher gespeichert werden kann, gelten die Richtlinien aus diesem Artikel weiterhin.
- Die Kapazitätsplanung ist ein kontinuierlicher Prozess, und Sie sollten regelmäßig überprüfen, wie gut die Umgebung die Erwartungen erfüllt.
- Die Optimierung erfolgt über mehrere Hardwarelebenszyklen, da sich die Hardwarekosten ändern. Beispielsweise wird Arbeitsspeicher billiger, die Kosten pro Kern sinken, oder der Preis für verschiedene Speicheroptionen ändert sich.
- Planen Sie die Spitzenlastperiode des Tages. Sie sollten dies in Intervallen von 30 Minuten oder Stunden betrachten. Alles, was darüber liegt, kann die tatsächlichen Spitzen verbergen, und alles, was darunter liegt, kann durch „vorübergehende Spitzen“ verzerrt werden.
- Planen Sie das Wachstum im Laufe des Hardwarelebenszyklus für das Unternehmen. Dies kann eine Strategie des gestaffelten Aktualisierens oder Hinzufügens von Hardware oder eine vollständige Aktualisierung alle drei bis fünf Jahre beinhalten. Jedes erfordert eine „Schätzung“, wie stark die Last in Active Directory wächst. Bei dieser Bewertung helfen verlaufsbezogene Daten, wenn sie erfasst werden.
- Planen Sie Fehlertoleranz ein. Sobald eine Schätzung N abgeleitet wurde, planen Sie Szenarien ein, die N – 1, N – 2, N – x enthalten.
Fügen Sie zusätzliche Server entsprechend den Anforderungen der Organisation hinzu, um sicherzustellen, dass der Verlust eines einzelnen Servers oder mehrerer Server die maximalen Spitzenkapazitätsschätzungen nicht überschreitet.
Berücksichtigen Sie auch, dass der Wachstumsplan und der Fehlertoleranzplan integriert werden müssen. Wenn beispielsweise ein Domänencontroller erforderlich ist, um die Last zu unterstützen, die Last jedoch schätzungsweise im nächsten Jahr verdoppelt wird und insgesamt zwei Domänencontroller erforderlich werden, ist nicht genügend Kapazität vorhanden, um die Fehlertoleranz zu unterstützen. Die Lösung wäre, mit drei Domänencontrollern zu beginnen. Sie könnten auch planen, den dritten Domänencontroller nach 3 oder 6 Monaten hinzuzufügen, wenn die Budgets knapp sind.
Hinweis
Das Hinzufügen von Anwendungen mit Active Directory-Unterstützung kann spürbare Auswirkungen auf die Domänencontroller-Last haben, unabhängig davon, ob die Last von den Anwendungsservern oder Clients ausgeht.
Dreistufiger Prozess für den Kapazitätsplanungszyklus
Entscheiden Sie bei der Kapazitätsplanung zunächst, welche Dienstqualität benötigt wird. Ein Kernrechenzentrum unterstützt beispielsweise ein höheres Maß an Parallelität und erfordert eine konsistentere Erfahrung für Benutzer*innen und nutzende Anwendungen, was eine größere Aufmerksamkeit auf Redundanz und Minimierung von System- und Infrastrukturengpässen erfordert. Im Gegensatz dazu benötigt ein Satellitenstandort mit einer Handvoll Benutzer*innen nicht die gleiche Parallelitäts- oder Fehlertoleranz. Daher benötigt das Satellitenbüro möglicherweise nicht so viel Aufmerksamkeit für die Optimierung der zugrunde liegenden Hardware und Infrastruktur, was zu Kosteneinsparungen führen kann. Alle hier vorliegenden Empfehlungen und Anleitungen dienen der optimalen Leistung und können für Szenarien mit weniger anspruchsvollen Anforderungen selektiv gelockert werden.
Die nächste Frage lautet: virtualisiert oder physisch? Aus Kapazitätsplanungssicht gibt es keine richtige oder falsche Antwort; es gibt nur einen anderen Satz von Variablen, mit denen sie arbeiten. Virtualisierungsszenarien laufen auf eine von zwei Optionen hinaus:
- „Direkte Zuordnung“ mit einem Gast pro Host (wobei Virtualisierung nur vorhanden ist, um die physische Hardware vom Server abzustrahieren)
- „Freigegebener Host“
Test- und Produktionsszenarien zeigen, dass das Szenario „direkte Zuordnung“ wie ein physischer Host behandelt werden kann. „Freigegebener Host“ bringt jedoch eine Reihe von Überlegungen mit sich, die später ausführlicher beschrieben werden. Das Szenario „freigegebener Host“ bedeutet, dass AD DS auch um Ressourcen konkurriert, und dies ist mit Einschränkungen und Optimierungsüberlegungen verbunden.
Unter Berücksichtigung dieser Überlegungen ist der Kapazitätsplanungszyklus ein iterativer dreistufiger Prozess:
- Messen Sie die vorhandene Umgebung, ermitteln Sie, wo sich die Systemengpässe derzeit befinden, und ermitteln Sie Umgebungsgrundlagen, die zum Planen der benötigten Kapazität erforderlich sind.
- Ermitteln Sie die erforderliche Hardware gemäß den in Schritt 1 beschriebenen Kriterien.
- Überwachen und überprüfen Sie, ob die implementierte Infrastruktur gemäß den Spezifikationen funktioniert. Einige in diesem Schritt gesammelte Daten werden für den nächsten Zyklus der Kapazitätsplanung zur Baseline.
Anwenden des Prozesses
Stellen Sie zum Optimieren der Leistung sicher, dass diese Hauptkomponenten ordnungsgemäß ausgewählt und auf die Anwendungslasten abgestimmt sind:
- Arbeitsspeicher
- Netzwerk
- Storage
- Prozessor
- Netzwerkanmeldung
Die grundlegenden Speicheranforderungen von AD DS und das allgemeine Verhalten gut geschriebener Clientsoftware ermöglichen Umgebungen mit 10.000 bis 20.000 Benutzer*innen, auf hohe Investitionen in die Kapazitätsplanung in Bezug auf physische Hardware zu verzichten, da fast jedes moderne Serverklassensystem die Last bewältigen wird. In der folgenden Tabelle wird zusammengefasst, wie eine vorhandene Umgebung ausgewertet wird, um die richtige Hardware auszuwählen. Jede Komponente wird in den nachfolgenden Abschnitten ausführlich analysiert, um AD DS-Administrator*innen bei der Bewertung ihrer Infrastruktur mithilfe von Basisempfehlungen und umgebungsspezifischen Prinzipien zu unterstützen.
Im Allgemeinen:
- Jede auf aktuellen Daten basierende Größenanpassung ist nur für die aktuelle Umgebung korrekt.
- Bei Schätzungen sollte erwartet werden, dass die Nachfrage im Laufe des Lebenszyklus der Hardware steigt.
- Bestimmen Sie, ob Sie heute zu groß werden und in die größere Umgebung hineinwachsen oder im Laufe des Lebenszyklus die Kapazität erweitern möchten.
- Für die Virtualisierung gelten dieselben Prinzipien und Methoden für die Kapazitätsplanung, mit der Ausnahme, dass der Mehraufwand für die Virtualisierung allen domänenbezogenen Elementen hinzugefügt werden muss.
- Kapazitätsplanung ist wie jeder Versuch, Prognosen zu machen, KEINE genaue Wissenschaft. Erwarten Sie nicht, dass die Dinge perfekt und mit einer Genauigkeit von 100 % berechnet werden. Diese Anleitung hier ist die Minimalempfehlung; fügen Sie zusätzliche Kapazität für zusätzliche Sicherheit hinzu, und überprüfen Sie kontinuierlich, ob die Zielvorgabe für die Umgebung eingehalten wird.
Übersichtstabellen zur Datensammlung
Neue Umgebung
| Komponente | Schätzungen |
|---|---|
| Größe des Speichers/der Datenbank | 40 KB bis 60 KB für jeden Benutzer |
| RAM | Datenbankgröße Basisbetriebssystemempfehlungen Drittanbieteranwendungen |
| Netzwerk | 1 GB |
| CPU | 1.000 gleichzeitige Benutzer für jeden Kern |
Allgemeine Bewertungskriterien
| Komponente | Auswertungskriterien | Planungsaspekte |
|---|---|---|
| Größe des Speichers/der Datenbank | Der Abschnitt „So aktivieren Sie die Protokollierung durch Defragmentierung freigegeben Datenträgerspeicherplatzes“ unter Speichergrenzwerte | |
| Leistung des Speichers/der Datenbank |
|
|
| RAM |
|
|
| Netzwerk |
|
|
| CPU |
|
|
| Anmeldedienst |
|
|
Planung
Die Community hat lange für die Dimensionierung von AD DS empfohlen, „so viel RAM einzusetzen, wie es der Datenbankgröße entspricht“. In den meisten Fällen war diese Empfehlung alles, worüber sich die meisten Umgebungen Sorgen machen mussten. Aber das Ökosystem, das AD DS nutzt, ist seit seiner Einführung im Jahr 1999 viel größer geworden, ebenso wie die AD DS-Umgebungen selbst. Der Anstieg der Computeleistung und der Wechsel von x86-Architekturen zu x64-Architekturen hat zwar die subtileren Aspekte der Größenanpassung für die Leistung für eine größere Gruppe von Kund*innen, die AD DS auf physischer Hardware ausführen, irrelevant gemacht hat, aber die zunehmende Virtualisierung hat dazu geführt, dass die Optimierungsaspekte wieder für eine größere Zielgruppe als zuvor interessant geworden sind.
In der folgenden Anleitung geht es daher darum, die Anforderungen von Active Directory als Dienst unabhängig davon zu bestimmen und zu planen, ob es in einem physischen, einem gemischt virtuellen/physischen oder einem rein virtualisierten Szenario bereitgestellt wird. Daher werden wir die Auswertung auf jede der vier Hauptkomponenten aufteilen: Speicher, Arbeitsspeicher, Netzwerk und Prozessor. Kurz gesagt, um die Leistung auf AD DS zu maximieren, besteht das Ziel darin, so nahe wie möglich am Prozessor zu sein.
RAM
Ganz einfach: Je mehr im RAM zwischengespeichert werden kann, desto weniger ist es notwendig, auf den Datenträger zu wechseln. Um die Skalierbarkeit des Servers zu maximieren, sollte die minimale RAM-Menge der Summe der aktuellen Datenbankgröße, der SYSVOL-Gesamtgröße, der empfohlenen Menge des Betriebssystems und der Herstellerempfehlungen für die Agents (Antivirus, Überwachung, Sicherung usw.) entsprechen. Eine zusätzliche Menge sollte hinzugefügt werden, um das Wachstum über die Lebensdauer des Servers zu berücksichtigen. Dies wird auf der Grundlage von Schätzungen des Datenbankwachstums basierend auf Umgebungsveränderungen der Umgebung gemäß subjektiv sein.
Für Umgebungen (z. B. Satellitenstandorte), in denen die Maximierung der RAM-Menge nicht kosteneffizient oder nicht möglich ist (DIT ist zu groß), ziehen Sie den Abschnitt „Speicher“ zu Rate, um sicherzustellen, dass der Speicher ordnungsgemäß entworfen wird.
Eine logische Konsequenz, die im allgemeinen Kontext bei der Größenanpassung des Arbeitsspeichers auftritt, ist die Größenanpassung der Auslagerungsdatei. Im gleichen Kontext wie alles andere, was den Arbeitsspeicher betrifft, ist das Ziel, den Wechsel zum viel langsameren Datenträger zu minimieren. Daher sollte sich die Frage von „Wie sollte die Auslagerungsdatei dimensioniert sein?“ ändern in „Wie viel RAM ist erforderlich, um das Paging zu minimieren?“. Die Antwort auf die letztgenannte Frage wird im weiteren Verlauf dieses Abschnitts beschrieben. Dadurch bleibt der Großteil der Diskussion über die Dimensionierung der Auslagerungsdatei im Bereich der allgemeinen Betriebssystemempfehlungen und der Notwendigkeit, das System für Speicherabbilder zu konfigurieren, die nicht mit der AD DS-Leistung zusammenhängen.
Auswerten
Die Menge an RAM, die ein Domänencontroller (DC) benötigt, ist aus diesen Gründen eigentlich eine komplexe Übung:
- Der Versuch, ein vorhandenes System zu verwenden, um zu messen, wie viel RAM benötigt wird, birgt in sich ein hohes Fehlerpotenzial, da LSASS unter Speicherdruckbedingungen Kürzungen vornimmt, wodurch der Bedarf künstlich verringert wird.
- Die subjektive Tatsache ist, dass ein einzelner Domänencontroller nur zwischenspeichern muss, was für seine Clients „interessant“ ist. Dies bedeutet, dass die Daten, die auf einem Domänencontroller an einem Standort mit nur einem Exchange-Server zwischengespeichert werden müssen, sich stark von den Daten unterscheiden, die auf einem Domänencontroller zwischengespeichert werden müssen, der nur Benutzer authentifiziert.
- Die Arbeit zum Auswerten des RAM für jeden Domänencontroller von Fall zu Fall ist kostenintensiv und ändert sich, wenn sich die Umgebung ändert.
- Die Kriterien hinter der Empfehlung unterstützen das Treffen fundierter Entscheidungen:
- Je mehr im RAM zwischengespeichert werden kann, desto weniger ist es notwendig, auf den Datenträger zu wechseln.
- Speicher ist bei weitem die langsamste Komponente eines Computers. Der Datenzugriff auf spindelbasierten und SSD-Speichermedien ist etwa 1.000.000-mal langsamer als der Zugriff auf Daten im RAM.
Um die Skalierbarkeit des Servers zu maximieren, ist darum die minimale RAM-Menge die Summe der aktuellen Datenbankgröße, der SYSVOL-Gesamtgröße, der empfohlenen Menge des Betriebssystems und der Herstellerempfehlungen für die Agents (Antivirus, Überwachung, Sicherung usw.). Fügen Sie zusätzliche Mengen hinzu, um das Wachstum über die Lebensdauer des Servers zu berücksichtigen. Dies wird auf der Grundlage von Schätzungen des Datenbankwachstums der Umgebung gemäß subjektiv sein. Für Satellitenstandorte mit einer kleinen Gruppe von Endbenutzer*innen können diese Anforderungen jedoch gelockert werden, da diese Standorte nicht so viel zwischenspeichern müssen, um die meisten Anforderungen zu erfüllen.
Für Umgebungen, in denen die Maximierung der RAM-Menge nicht kosteneffizient (z. B. Satellitenstandorte) oder nicht möglich ist (DIT ist zu groß), ziehen Sie den Abschnitt „Speicher“ zu Rate, um sicherzustellen, dass der Speicher ordnungsgemäß dimensioniert ist.
Hinweis
Eine logische Konsequenz bei der Größenanpassung des Arbeitsspeichers ist die Größenanpassung der Auslagerungsdatei. Da das Ziel darin besteht, den Zugriff auf den viel langsameren Datenträger zu minimieren, ändert sich die Frage von „Wie sollte die Auslagerungsdatei dimensioniert sein?“ in „Wie viel RAM ist erforderlich, um das Paging zu minimieren?“. Die Antwort auf die letztgenannte Frage wird im weiteren Verlauf dieses Abschnitts beschrieben. Dadurch bleibt der Großteil der Diskussion über die Dimensionierung der Auslagerungsdatei im Bereich der allgemeinen Betriebssystemempfehlungen und der Notwendigkeit, das System für Speicherabbilder zu konfigurieren, die nicht mit der AD DS-Leistung zusammenhängen.
Virtualisierungsüberlegungen zum RAM
Vermeiden Sie übermäßige Arbeitsspeicherbelegung auf dem Host. Das grundlegende Ziel bei der Optimierung der RAM-Menge ist, den Zeitaufwand für den Zugriff auf den Datenträger zu minimieren. In Virtualisierungsszenarien besteht das Konzept der übermäßigen Arbeitsspeicherbelegung darin, den Gästen mehr RAM zuzuweisen, als auf dem physischen Computer vorhanden ist. Dies ist an und für sich kein Problem. Es wird zu einem Problem, wenn der gesamte von allen Gästen aktiv genutzte Arbeitsspeicher die RAM-Menge auf dem Host überschreitet, und der zugrunde liegende Host mit der Auslagerung beginnt. Die Leistung wird datenträgergebunden, wenn der Domänencontroller zu „NTDS.dit“ wechselt, um Daten abzurufen, oder zur Auslagerungsdatei wechselt, um Daten abzurufen, oder der Host zum Datenträger wechselt, um Daten abzurufen, von denen der Gast annimmt, dass sie sich im RAM befinden.
Beispiel für die Berechnungszusammenfassung
| Komponente | Geschätzter Arbeitsspeicher (Beispiel) |
|---|---|
| Empfohlener RAM des Basisbetriebssystems (Windows Server 2008) | 2 GB |
| Interne LSASS-Aufgaben | 200 MB |
| Überwachungs-Agent | 100 MB |
| Virenschutz | 100 MB |
| Datenbank (Globaler Katalog) | 8,5 GB |
| Polster für die Ausführung der Sicherung, Administrator*innen können sich ohne Auswirkungen anmelden | 1 GB |
| Gesamt | 12 GB |
Empfohlen: 16 GB
Es kann davon ausgegangen werden, dass im Laufe der Zeit der Datenbank weitere Daten hinzugefügt werden und der Server wahrscheinlich 3 bis 5 Jahre in Produktion sein wird. Basierend auf einer Schätzung des Wachstums von 33 % wären 16 GB eine angemessene Menge an RAM für einen physischen Server. Angesichts der Leichtigkeit, mit der Einstellungen geändert werden können und RAM der VM hinzugefügt werden kann, ist es angemessen, auf einem virtuellen Computer ab 12 GB mit dem Plan für die zukünftige Überwachung und das Upgrade zu beginnen.
Netzwerk
Auswerten
In diesem Abschnitt geht es weniger um die Bewertung der Anforderungen an den Replikationsdatenverkehr, der sich auf den Datenverkehr durch das WAN konzentriert und gründlich in Active Directory-Replikationsdatenverkehr behandelt wird, als um die Bewertung der insgesamt benötigten Bandbreite und Netzwerkkapazität, einschließlich Clientabfragen, Gruppenrichtlinieanwendungen usw. Für vorhandene Umgebungen kann dies mithilfe der Leistungsindikatoren „Netzwerkschnittstelle(*)\Empfangene Bytes/s“ und „Netzwerkschnittstelle(*)\Gesendete Bytes/s“erfasst werden. Beispielintervalle für Netzwerkschnittstellen-Leistungsindikatoren sind 15, 30 oder 60 Minuten. Alles darunter ist in der Regel zu flüchtig für gute Messungen; alles darüber glättet die täglichen Spitzen übermäßig.
Hinweis
Im Allgemeinen ist der Großteil des Netzwerkdatenverkehrs auf einem Domänencontroller ausgehend, da der Domänencontroller auf Clientabfragen antwortet. Dies ist der Grund für den Fokus auf ausgehenden Datenverkehr, obwohl jede Umgebung auch auf eingehenden Datenverkehr ausgewertet werden sollte. Dieselben Ansätze können verwendet werden, um die Anforderungen an eingehenden Netzwerkdatenverkehr zu berücksichtigen und zu überprüfen. Weitere Informationen finden Sie im Knowledge Base-Artikel 929851: Der dynamische Portbereich für TCP/IP hat sich in Windows Vista und Windows Server 2008 geändert.
Bandbreitenbedarf
Die Planung der Netzwerkskalierbarkeit umfasst zwei verschiedene Kategorien: die Menge des Datenverkehrs und die CPU-Last des Netzwerkdatenverkehrs. Jedes dieser Szenarien ist im Vergleich zu einigen anderen Themen in diesem Artikel einfach.
Zur Bewertung, wie viel Datenverkehr unterstützt werden muss, gibt es zwei eindeutige Kategorien der Kapazitätsplanung für AD DS in Bezug auf den Netzwerkdatenverkehr. Die erste ist der Replikationsdatenverkehr, der zwischen Domänencontrollern durchläuft und in der Referenz Active Directory-Replikationsdatenverkehr gründlich behandelt wird und für die aktuellen Versionen von AD DS weiterhin relevant ist. Die zweite ist der standortinterne Client-zu-Server-Datenverkehr. Eines der einfacheren Szenarien für die Planung: Der interne Datenverkehr empfängt hauptsächlich kleine Anforderungen von Clients im Verhältnis zu den großen Datenmengen, die an die Clients zurückgesendet werden. 100 MB sind in Umgebungen mit bis zu 5.000 Benutzer*innen pro Server an einem Standort in der Regel ausreichend. Die Verwendung eines Netzwerkadapters mit 1 GB und der Unterstützung für die RSS-Skalierung (Receive Side Scaling) wird für alle Anwendungen über 5.000 Benutzer*innen empfohlen. Um dieses Szenario zu überprüfen, insbesondere im Fall von Serverkonsolidierungsszenarien, sehen Sie sich „Netzwerkschnittstelle(*)\Bytes/s“ für alle Domänencontroller an einem Standort an, addieren Sie sie, und dividieren Sie sie durch die Zielanzahl von Domänencontrollern, um sicherzustellen, dass ausreichende Kapazität vorhanden ist. Die einfachste Möglichkeit hierfür ist die Verwendung der Ansicht „Gestapelte Fläche“ in Windows Reliability und Systemmonitor (früher bekannt als Perfmon), um sicherzustellen, dass alle Leistungsindikatoren gleich skaliert sind.
Betrachten Sie das folgende Beispiel (auch bekannt als eine wirklich komplexe Methode, um zu überprüfen, ob die allgemeine Regel auf eine bestimmte Umgebung anwendbar ist). Die folgenden Annahmen werden getroffen:
- Ziel ist es, den Speicherbedarf auf so wenige Server wie möglich zu reduzieren. Im Idealfall trägt ein Server die Last, und ein zusätzlicher Server wird zur Redundanz bereitgestellt („N + 1“-Szenario).
- In diesem Szenario unterstützt der aktuelle Netzwerkadapter nur 100 MB und befindet sich in einer Switch-Umgebung. Die maximale Auslastung der Zielnetzwerkbandbreite beträgt in einem N-Szenario 60 % (Verlust eines Domänencontrollers).
- Mit jedem Server sind etwa 10.000 Clients verbunden.
Erkenntnisse aus den Daten im Diagramm (Netzwerkschnittstelle(*)\Gesendete Bytes/s):
- Der Geschäftstag beginnt um 5:30 Uhr und geht um 19:00 Uhr zu Ende.
- Der Zeitraum der stärksten Nutzung ist von 8:00 Uhr bis 8:15 Uhr, wobei mehr als 25 Bytes pro Sekunde auf dem am meisten genutzten Domänencontroller gesendet werden.
Hinweis
Alle Leistungsdaten sind Verlaufsdaten. So gibt der Spitzendatenpunkt um 8:15 Uhr die Last von 8:00 bis 8:15 Uhr an.
- Es gibt Spitzen vor 4:00 Uhr mit mehr als 20 gesendeten Bytes/s auf dem am meisten genutzten Domänencontroller, was entweder auf die Auslastung aus verschiedenen Zeitzonen oder auf Infrastrukturaktivitäten im Hintergrund wie Sicherungen hinweisen kann. Da der Höchstwert um 8:00 Uhr diese Aktivität überschreitet, ist er nicht relevant.
- Es gibt fünf Domänencontroller an diesem Standort.
- Die maximale Auslastung beträgt etwa 5,5 MB/s pro Domänencontroller, was 44 % der 100 MB-Verbindung entspricht. Anhand dieser Daten kann geschätzt werden, dass die zwischen 8:00 Uhr und 8:15 Uhr benötigte Gesamtbandbreite 28 MB/s beträgt.
Hinweis
Achten Sie darauf, dass die Sende-/Empfangszähler der Netzwerkschnittstelle in Bytes angegeben werden, während die Netzwerkbandbreite in Bits gemessen wird. 100 MB ÷ 8 = 12,5 MB, 1 GB ÷ 8 = 128 MB.
Schlussfolgerungen:
- Diese aktuelle Umgebung erfüllt die Fehlertoleranzstufe N+1 bei einer Zielauslastung von 60 %. Wenn ein System offline geschaltet wird, wird die Bandbreite pro Server von etwa 5,5 MB/s (44 %) auf etwa 7 MB/s (56 %) verschoben.
- Basierend auf dem zuvor genannten Ziel der Konsolidierung auf einen Server überschreitet dies sowohl die maximale Zielauslastung als auch theoretisch die mögliche Auslastung einer 100-MB-Verbindung.
- Bei einer Verbindung mit 1 GB entspricht dies 22 % der Gesamtkapazität.
- Unter normalen Betriebsbedingungen im Szenario N +1 ist die Clientlast mit etwa 14 MB/s pro Server oder 11 % der Gesamtkapazität relativ gleichmäßig verteilt.
- Um sicherzustellen, dass die Kapazität während der Nichtverfügbarkeit eines Domänencontrollers ausreicht, würden die normalen Betriebsziele pro Server etwa 30 % Netzwerkauslastung oder 38 MB/s pro Server betragen. Failoverziele wären 60 % Netzwerkauslastung oder 72 MB/s pro Server.
Kurz gesagt, die endgültige Bereitstellung von Systemen muss über einen 1-GB-Netzwerkadapter verfügen und mit einer Netzwerkinfrastruktur verbunden sein, die diese Last unterstützt. Ein weiterer Hinweis: Angesichts der Menge des generierten Netzwerkdatenverkehrs kann die CPU-Last von der Netzwerkkommunikation erhebliche Auswirkungen haben und die maximale Skalierbarkeit von AD DS einschränken kann. Derselbe Prozess kann verwendet werden, um die Menge der eingehenden Kommunikation des Domänencontrollers abzuschätzen. Angesichts der Dominanz des ausgehenden Datenverkehrs im Verhältnis zum eingehenden Datenverkehr ist dies jedoch für die meisten Umgebungen eine akademische Übung. Die Hardwareunterstützung für RSS sicherzustellen ist in Umgebungen mit mehr als 5.000 Benutzer*innen pro Server wichtig. In Szenarien mit hohem Netzwerkdatenverkehr kann der Ausgleich der Interruptlast ein Engpass sein. Dies kann daran erkannt werden, dass „Prozessor(*)% Interruptzeit“ ungleichmäßig auf CPUs verteilt ist. Netzwerkadapter mit RSS-Unterstützung können diese Einschränkung verringern und die Skalierbarkeit erhöhen.
Hinweis
Ein ähnlicher Ansatz kann verwendet werden, um die zusätzliche Kapazität zu schätzen, die beim Konsolidieren von Rechenzentren erforderlich ist, oder wenn ein Domänencontroller an einem Satellitenstandort eingestellt wird. Erfassen Sie einfach den ausgehenden und eingehenden Datenverkehr mit Clients, und das ist die Datenverkehrsmenge, die jetzt auf den WAN-Links vorhanden ist.
In einigen Fällen tritt möglicherweise mehr Datenverkehr als erwartet auf, da der Datenverkehr langsamer ist, z. B. wenn die Zertifikatüberprüfung keinen aggressiven Timeouts im WAN gerecht wird. Aus diesem Grund sollten die WAN-Größenanpassung und -nutzung ein iterativer, fortlaufender Prozess sein.
Überlegungen zur Virtualisierung für die Netzwerkbandbreite
Es ist einfach, Empfehlungen für einen physischen Server zu geben: 1 GB für Server, die mehr als 5.000 Benutzer*innen unterstützen. Sobald mehrere Gäste beginnen, eine zugrunde liegende virtuelle Switchinfrastruktur gemeinsam zu nutzen, ist zusätzliche Aufmerksamkeit erforderlich, um sicherzustellen, dass der Host über eine angemessene Netzwerkbandbreite verfügt, um alle Gäste im System zu unterstützen, und daher die zusätzliche Stringenz erfordert. Dies ist nichts anderes als eine Erweiterung der Sicherung der Netzwerkinfrastruktur auf dem Hostcomputer. Dies ist unabhängig davon, ob das Netzwerk den Domänencontroller einbezieht, der als Gast eines virtuellen Computers auf einem Host ausgeführt wird, und der Netzwerkdatenverkehr über einen virtuellen Switch erfolgt, oder ob eine direkte Verbindung mit einem physischen Switch besteht. Der virtuelle Switch ist nur eine weitere Komponente, bei der der Uplink die übertragene Datenmenge unterstützen muss. Daher sollte der mit dem Switch verbundene physische Host-Netzwerkadapter in der Lage sein, die Domänencontroller-Last sowie alle anderen Gäste zu unterstützen, die den virtuellen Switch, der mit dem physischen Netzwerkadapter verbunden ist, gemeinsam nutzen.
Beispiel für die Berechnungszusammenfassung
| System | Spitzenbandbreite |
|---|---|
| DC 1 | 6,5 MB/s |
| DC 2 | 6,25 MB/s |
| DC 3 | 6,25 MB/s |
| DC 4 | 5,75 MB/s |
| DC 5 | 4,75 MB/s |
| Gesamt | 28,5 MB/s |
Empfohlen: 72 MB/s (28,5 MB/s geteilt durch 40 %)
| Anzahl der Zielsysteme | Gesamtbandbreite (von oben) |
|---|---|
| 2 | 28,5 MB/s |
| Resultierendes normales Verhalten | 28,5 ÷ 2 = 14,25 MB/s |
Wie immer kann im Laufe der Zeit davon ausgegangen werden, dass die Clientlast zunehmen wird und dieses Wachstum so gut wie möglich geplant werden sollte. Die für die Planung empfohlene Menge würde ein geschätztes Wachstum des Netzwerkdatenverkehrs von 50 % ermöglichen.
Storage
Die Planung von Speicher besteht aus zwei Komponenten:
- Kapazität oder Speichergröße
- Leistung
Für die Planung der Kapazität wird viel Zeit und Dokumentation aufgewendet, sodass die Leistung oft völlig übersehen wird. Unter Berücksichtigung der derzeitigen Hardwarekosten sind die meisten Umgebungen nicht so groß, dass dies wirklich ein Problem darstellt, und die Empfehlung, dass "der Arbeitsspeicher der Datenbankgröße entsprechen soll", deckt in der Regel den Rest ab, auch wenn dies für Satellitenstandorte in größeren Umgebungen übertrieben sein kann.
Festlegen der Größe
Bewertung für Speicher
Verglichen mit der Einführung von Active Directory vor 13 Jahren, als 4-GB- und 9-GB-Laufwerke die gängigsten Laufwerksgrößen waren, ist die Dimensionierung für Active Directory heute nur noch in den größten Umgebungen ein Thema. Mit den kleinsten verfügbaren Festplattengrößen im Bereich von 180 GB können das gesamte Betriebssystem, SYSVOL und NTDS.dit problemlos auf ein Laufwerk passen. Daher können hohe Investitionen in diesem Bereich als veraltet betrachtet werden.
Als einzige Empfehlung sollte berücksichtigt werden, sicherzustellen, dass 110 % der NTDS.dit-Größe verfügbar sind, um die Defragmentierung zu ermöglichen. Darüber hinaus sollten Anpassungen für das Wachstum während der Lebensdauer der Hardware vorgenommen werden.
Der erste und wichtigste Aspekt ist die Bewertung der Größe von NTDS.dit und SYSVOL. Diese Messungen führen zur Größenanpassung sowohl für feste Datenträger als auch für die RAM-Zuordnung. Aufgrund der (relativ) niedrigen Kosten dieser Komponenten muss die Berechnung nicht streng und präzise sein. Wie dies sowohl für vorhandene als auch neue Umgebungen bewertet werden kann, erfahren Sie in der Datenspeicher-Artikelreihe. Weitere Informationen finden Sie in den folgenden Artikeln:
Für vorhandene Umgebungen: Der Abschnitt „So aktivieren Sie die Protokollierung von Speicherplatz, der durch Defragmentierung freigegeben wird“ im Artikel Speichergrenzwerte.
Für neue Umgebungen: Der Artikel mit dem Titel Wachstumsschätzungen für Active Directory-Benutzer und Organisationseinheiten.
Hinweis
Die Artikel basieren auf Datengrößenschätzungen, die zum Zeitpunkt der Veröffentlichung von Active Directory in Windows 2000 vorgenommen wurden. Verwenden Sie Objektgrößen, die die tatsächliche Größe von Objekten in Ihrer Umgebung widerspiegeln.
Beim Überprüfen vorhandener Umgebungen mit mehreren Domänen kann es zu Abweichungen bei den Datenbankgrößen kommen. Wenn dies der Fall ist, verwenden Sie die kleinsten globalen Kataloggrößen (GC) und Nicht-GC-Größen.
Die Datenbankgröße kann je nach Betriebssystemversion variieren. Domänencontroller, auf denen frühere Betriebssysteme wie Windows Server 2003 ausgeführt werden, haben eine geringere Datenbankgröße als ein Domänencontroller, auf dem ein späteres Betriebssystem wie Windows Server 2008 R2 ausgeführt wird, insbesondere wenn Features wie Active Directory-Papierkorb oder Roaming für Anmeldeinformationen aktiviert sind.
Hinweis
- Beachten Sie für neue Umgebungen, dass den Schätzungen unter „Wachstumsschätzungen für Active Directory-Benutzer und Organisationseinheiten“ zufolge 100.000 Benutzer (in derselben Domäne) etwa 450 MB Speicherplatz verbrauchen. Beachten Sie, dass die aufgefüllten Attribute einen großen Einfluss auf die Gesamtmenge haben können. Attribute werden für viele Objekte von Drittanbieter- und Microsoft-Produkten aufgefüllt, einschließlich Microsoft Exchange Server und Lync. Eine Bewertung auf der Grundlage des Produktportfolios in der Umgebung ist zu bevorzugen, aber der Aufwand für die detaillierte Berechnung und das Testen für präzise Schätzungen ist für alle Umgebungen mit Ausnahme der größten möglicherweise nicht die Zeit und Mühe wert.
- Stellen Sie sicher, dass 110 % der NTDS.dit-Größe als freier Speicherplatz verfügbar sind, um die Offlinedefragmentierung zu ermöglichen, und planen Sie das Wachstum über eine Hardwarelebensdauer von drei bis fünf Jahren. Angesichts des günstigen Speichers ist die Schätzung von Speicher auf 300 % der DIT-Größe als Speicherbelegung sicher, um das Wachstum und den potenziellen Bedarf an Offlinedefragmentierung zu berücksichtigen.
Virtualisierungsüberlegungen zum Speicher
In einem Szenario, in dem mehrere VHD-Dateien (Virtual Hard Disk) einem einzelnen Volume zugeordnet werden, verwenden Sie einen Datenträger mit fester Größe von mindestens 210 % (100 % des DIT + 110 % freien Speicherplatz), um sicherzustellen, dass ausreichend Speicherplatz reserviert ist.
Beispiel für die Berechnungszusammenfassung
| In der Auswertungsphase gesammelte Daten | Size |
|---|---|
| NTDS.dit-Größe | 35 GB |
| Modifizierer, um die Offlinedefragmentierung zuzulassen | 2,1 GB |
| Benötigter Gesamtspeicher | 73,5 GB |
Hinweis
Dieser erforderliche Speicher wird zusätzlich zum Speicher benötigt, der für SYSVOL, Betriebssystem, Auslagerungsdatei, temporäre Dateien, lokale zwischengespeicherte Daten (z. B. Installationsdateien) und Anwendungen erforderlich ist.
Speicherleistung
Auswerten der Speicherleistung
Als langsamste Komponente auf jedem Computer kann der Speicher die größten negativen Auswirkungen auf die Clienterfahrung haben. In Umgebungen, die so groß sind, dass die Empfehlungen für die Größe des Arbeitsspeichers nicht realisierbar sind, kann es verheerende Folgen haben, wenn die Speicherplanung nicht auf die Leistung abgestimmt ist. Auch die Komplexität und Vielfalt der Speichertechnologie erhöht das Ausfallrisiko, da die langjährige bewährte Praxis „Betriebssystem, Protokolle und Datenbank“ auf getrennten physischen Festplatten unterzubringen, nur noch bedingt sinnvoll ist. Dies liegt daran, dass die seit langem bewährte Methode auf der Annahme basiert, dass ein „Datenträger“ eine dedizierte Spindel ist und dies eine E/A-Isolation ermöglicht. Diese Annahmen, die dies begründen, sind nicht mehr relevant mit der Einführung von Folgendem:
- RAID
- Neue Speichertypen und virtualisierte und freigegebene Speicherszenarien
- Freigegebene Spindeln in einem Storage Area Network (SAN)
- VHD-Datei in einem SAN-Speicher oder Network Attached Storage
- Solid-State-Laufwerke
- Mehrstufige Speicherarchitekturen (d. h. SSD-Speicherebenen-Zwischenspeicherung größerer spindelbasierter Speicher)
Insbesondere kann freigegebener Speicher (RAID, SAN, NAS, JBOD (d. h. Speicherplätze), VHD) von anderen Arbeitslasten, die im Back-End-Speicher platziert werden, überschrieben/überlastet werden. Dazu kommt auch die Herausforderung, dass SAN-/Netzwerk-/Treiberprobleme (alles zwischen dem physischen Datenträger und der AD-Anwendung) zu Drosselungen und/oder Verzögerungen führen können. Zur Klarstellung: Dies sind keine „schlechten“ Konfigurationen, es handelt sich um komplexere Konfigurationen, die erfordern, dass jede Komponente ordnungsgemäß funktioniert, sodass zusätzliche Aufmerksamkeit erforderlich ist, um sicherzustellen, dass die Leistung akzeptabel ist. Ausführlichere Erläuterungen finden Sie unter Anhang C, Unterabschnitt „Einführung in SANs“, und Anhang D weiter unten in diesem Dokument. Auch haben Solid State Drives zwar nicht die Einschränkung rotierender Platten (Festplatten), dass nur jeweils ein E/A-Vorgang verarbeitet werden kann, aber sie haben immer noch E/A-Einschränkungen, und eine Überlastung von SSDs ist möglich. Kurz gesagt, das Endziel aller Speicherleistungsbemühungen besteht unabhängig von der zugrunde liegenden Speicherarchitektur und dem Entwurf darin, sicherzustellen, dass die erforderliche Menge an Eingabe-/Ausgabevorgängen pro Sekunde (IOPS) verfügbar ist, und diese IOPS innerhalb eines akzeptablen Zeitrahmens erfolgen (wie an anderer Stelle in diesem Dokument ausgeführt). Für Szenarien mit lokal angefügtem Speicher finden Sie in Anhang C die Grundlagen zum Entwerfen herkömmlicher lokaler Speicherszenarien. Diese Prinzipien gelten in der Regel für komplexere Speicherebenen und helfen auch beim Dialog mit den Herstellern, die Back-End-Speicherlösungen unterstützen.
- Angesichts der großen Bandbreite verfügbarer Speicheroptionen empfiehlt es sich, das Fachwissen von Hardwaresupportteams oder -anbietern zu nutzen, um sicherzustellen, dass die spezifische Lösung die Anforderungen von AD DS erfüllt. Die folgenden Zahlen sind die Informationen, die den Speicherspezialisten zur Verfügung gestellt würden.
Bestimmen Sie für Umgebungen, in denen die Datenbank zu groß ist, um im RAM gespeichert zu werden, anhand der Leistungsindikatoren, wie viel E/A unterstützt werden muss:
- Logischer Datenträger(*)\Mittlere Sek./Lesevorgänge (Wenn z. B. „NTDS.dit“ auf Laufwerk D:/ gespeichert ist, wäre der vollständige Pfad „Logischer Datenträger(D:)\Mittlere Sek./Lesevorgänge)
- Logischer Datenträger(*)\Mittlere Sek./Schreibvorgänge
- Logischer Datenträger(*)\Mittlere Sek./Übertragung
- Logischer Datenträger(*)\Lesevorgänge/s
- Logischer Datenträger(*)\Schreibvorgänge/s
- Logischer Datenträger(*)\Übertragungen/s
Diese sollten in Intervallen von 15/30/60 Minuten erfasst werden, um einen Vergleichstest der Anforderungen der aktuellen Umgebung durchzuführen.
Auswerten der Ergebnisse
Hinweis
Der Fokus liegt auf Lesevorgängen aus der Datenbank, da dies in der Regel die anspruchsvollste Komponente ist. Dieselbe Logik kann auf Schreibvorgänge in die Protokolldatei angewendet werden, indem „Logischer Datenträger(<NTDS-Protokoll>)\Mittlere Sek./Schreibvorgänge“ und „Logischer Datenträger(<NTDS-Protokoll>)\Schreibvorgänge/s“ ersetzt werden:
- „Logischer Datenträger(<NTDS>)\Mittlere Sek./Lesevorgänge“ gibt an, ob der aktuelle Speicher angemessen dimensioniert ist. Wenn die Ergebnisse ungefähr gleich der Datenträgerzugriffszeit für den Datenträgertyp sind, ist „Logischer Datenträger(<NTDS>)\Lesevorgänge/s“ ein gültiges Maß. Überprüfen Sie die Herstellerspezifikationen für den Speicher im Back-End, aber gute Bereiche für „Logischer Datenträger(<NTDS>)\Mittlere Sek./Lesevorgänge“ wären ungefähr:
- 7.200 – 9 bis 12,5 Millisekunden (ms)
- 10.000 – 6 bis 10 ms
- 15.000 – 4 bis 6 ms
- SSD – 1 bis 3 ms
-
Hinweis
Empfehlungen zufolge wird die Speicherleistung (abhängig von der Quelle) um 15 ms bis 20 ms beeinträchtigt. Der Unterschied zwischen den oben genannten Werten und der anderen Anleitung besteht darin, dass die oben genannten Werte der normale Betriebsbereich sind. Die anderen Empfehlungen sind Anleitungen zur Problembehandlung, um zu ermitteln, wann sich die Clienterfahrung erheblich und spürbar verschlechtert. Ausführlichere Erläuterungen finden Sie in Anhang C.
- „Logischer Datenträger(<NTDS>)\Lesevorgänge/s“ ist die ausgeführte E/A-Menge.
- Wenn „Logischer Datenträger(<NTDS>)\Mittlere Sek./Lesevorgänge“ innerhalb des optimalen Bereichs für den Back-End-Speicher liegt, kann „Logischer Datenträger(<NTDS>)\Lesevorgänge/s“ direkt zur Dimensionierung des Speichers verwendet werden.
- Wenn „Logischer Datenträger(<NTDS>)\Mittlere Sek./Lesevorgänge“ nicht innerhalb des optimalen Bereichs für den Back-End-Speicher liegt, ist zusätzliche E/A gemäß der folgenden Formel erforderlich: (Logischer Datenträger(<NTDS>)\Mittlere Sek./Lesevorgänge) ÷ (Datenträgerzugriffszeit für physische Medien) × (Logischer Datenträger(<NTDS>)\Mittlere Sek./Lesevorgänge)
Überlegungen:
- Beachten Sie, dass diese Werte zu Planungszwecken zu ungenau sind, wenn der Server mit einer suboptimalen RAM-Menge konfiguriert ist. Sie werden fälschlicherweise auf der hohen Seite liegen und können weiterhin als Worst-Case-Szenario verwendet werden.
- Durch das spezielle Hinzufügen/Optimieren von RAM wird die Menge an Lese-E/A-Vorgängen (Logischer Datenträger(<NTDS>)\Lesevorgänge/s) verringert. Dies bedeutet, dass die Speicherlösung möglicherweise nicht so robust sein muss, wie ursprünglich berechnet. Leider ist alles, was genauer als diese allgemeine Aussage ist, umgebungsspezifisch von der Clientlast abhängig, und es kann keine allgemeine Anleitung gegeben werden. Die beste Option ist, die Speicherdimensionierung nach der RAM-Optimierung vorzunehmen.
Virtualisierungsüberlegungen zur Leistung
Ähnlich wie bei allen vorherigen Virtualisierungsdiskussionen liegt der Schlüssel hier darin, sicherzustellen, dass die zugrunde liegende freigegebene Infrastruktur die Domänencontrollerauslastung sowie die anderen Ressourcen unterstützen kann, die die zugrunde liegenden freigegebenen Medien und alle Pfade dazu verwenden. Dies gilt unabhängig davon, ob ein physischer Domänencontroller die gleichen zugrunde liegenden Medien auf einer SAN-, NAS- oder iSCSI-Infrastruktur wie andere Server oder Anwendungen nutzt, unabhängig davon, ob es sich um einen Gast mit Passthrough-Zugriff auf eine SAN-, NAS- oder iSCSI-Infrastruktur handelt, die die zugrunde liegenden Medien verwendet, oder ob der Gast eine VHD-Datei verwendet, die sich lokal auf freigegebenen Medien oder in einer SAN-, NAS- oder iSCSI-Infrastruktur befindet. Bei der Planungsübung geht es darum, sicherzustellen, dass die zugrunde liegenden Medien die Gesamtlast aller Consumer unterstützen können.
Da zusätzliche Codepfade durchlaufen werden müssen, wirkt sich dies aus Sicht des Gastes auch auf die Leistung aus, da der Zugriff auf den Speicher über einen Host erfolgen muss. Es überrascht nicht, dass die Speicherleistungstests zeigen, dass die Virtualisierung einen Einfluss auf den Durchsatz hat, der subjektiv von der Prozessorauslastung des Hostsystems abhängt (siehe Anhang A: Kriterien der CPU-Dimensionierung), die natürlich von den Ressourcen des Hosts beeinflusst wird, die der Gast benötigt. Dies trägt zu den Virtualisierungsüberlegungen hinsichtlich der Verarbeitungsanforderungen in einem virtualisierten Szenario bei (siehe Überlegungen zur Virtualisierung für die Verarbeitung).
Erschwerend kommt hinzu, dass es eine Vielzahl verschiedener Speicheroptionen gibt, die alle unterschiedliche Auswirkungen auf die Leistung haben. Verwenden Sie als sichere Schätzung bei der Migration von physisch zu virtuell einen Multiplikator von 1,10 zur Anpassung an verschiedene Speicheroptionen für virtualisierte Gäste in Hyper-V, z. B. Passthroughspeicher, SCSI-Adapter oder IDE. Die Anpassungen, die bei der Übertragung zwischen den verschiedenen Speicherszenarien vorgenommen werden müssen, sind unabhängig davon, ob es sich um lokalen, SAN-, NAS- oder iSCSI-Speicher handelt.
Beispiel für die Berechnungszusammenfassung
Bestimmen der E/A-Menge, die für ein fehlerfreies System unter normalen Betriebsbedingungen erforderlich ist:
- „Logischer Datenträger(<NTDS-Datenbanklaufwerk>)\Übertragungen/s“ während des Spitzenzeitraums von 15 Minuten
- So ermitteln Sie den E/A-Bedarf für den Speicher, wenn die Kapazität des zugrunde liegenden Speichers überschritten wird:
Erforderliche IOPS = (Logischer Datenträger(<NTDS-Datenbanklaufwerk>)\Mittlere Sek./Lesevorgänge ÷ <Ziel Mittlere Sek./Lesevorgänge>) × Logischer Datenträger(<NTDS-Datenbanklaufwerk>)\Lesevorgänge/s
| Leistungsindikator | Wert |
|---|---|
| Tatsächlicher logischer Datenträger(<NTDS-Datenbanklaufwerk>)\Mittlere Sek./Übertragung | 0,02 Sekunden (20 Millisekunden) |
| Logischer Zieldatenträger(<NTDS-Datenbanklaufwerk>)\Mittlere Sek./Übertragung | 0,01 Sekunden |
| Multiplikator für Änderungen in verfügbarer E/A | 0,02 ÷ 0,01 = 2 |
| Wertname | Wert |
|---|---|
| Logischer Datenträger(<NTDS-Datenbanklaufwerk>)\Übertragungen/s | 400 |
| Multiplikator für Änderungen in verfügbarer E/A | 2 |
| Gesamter IOPS-Bedarf während der Spitzenzeit | 800 |
So bestimmen Sie die Rate, mit der der Cache aufgewärmt werden soll:
- Bestimmen Sie die maximal zulässige Zeit zum Aufwärmen des Caches. Es ist entweder die Zeit, die zum Laden der gesamten Datenbank vom Datenträger benötigt werden sollte, oder in Szenarien, in denen nicht die gesamte Datenbank in den RAM geladen werden kann, wäre dies die maximale Zeit, den RAM zu füllen.
- Bestimmen Sie die Größe der Datenbank, ohne Leerzeichen. Weitere Informationen finden Sie unter Auswerten des Speichers.
- Dividieren Sie die Datenbankgröße durch 8 KB. Dies ist die Gesamtanzahl der E/A-Vorgänge, die zum Laden der Datenbank erforderlich sind.
- Dividieren Sie die Gesamtanzahl der E/A-Vorgänge durch die Anzahl der Sekunden im definierten Zeitrahmen.
Beachten Sie, dass die berechnete Rate zwar präzise ist, aber nicht exakt, da zuvor geladene Seiten verdrängt werden, wenn ESE nicht für eine feste Cachegröße konfiguriert ist, und AD DS standardmäßig eine variable Cachegröße verwendet.
| Zu erfassende Datenpunkte | Werte |
|---|---|
| Maximal zulässige Aufwärmzeit | 10 Minuten (600 Sekunden) |
| Datenbankgröße | 2 GB |
| Berechnungsschritt | Formel | Ergebnis |
|---|---|---|
| Berechnung der Größe der Datenbank in Seiten | (2 GB × 1024 × 1024) = Größe der Datenbank in KB | 2.097.152 KB |
| Berechnung der Anzahl der Seiten in der Datenbank | 2.097.152 KB ÷ 8 KB = Anzahl der Seiten | 262.144 Seiten |
| Berechnung von IOPS, die zum vollständigen Aufwärmen des Caches erforderlich sind | 262.144 Seiten ÷ 600 Sekunden = erforderliche IOPS | 437 IOPS |
Verarbeitung
Auswerten der Active Directory-Prozessornutzung
In den meisten Umgebungen ist die Verwaltung der Verarbeitungskapazität die Komponente, die die meiste Aufmerksamkeit verdient, nachdem Speicher, RAM und Netzwerk wie im Abschnitt „Planung“ beschrieben richtig eingestellt wurden. Bei der Bewertung der benötigten CPU-Kapazität gibt es zwei Herausforderungen:
Ob sich die Anwendungen in der Umgebung in einer Infrastruktur mit gemeinsamen Diensten gut verhalten oder nicht, wird im Abschnitt „Tracking Expensive and Inefficient Searches“ (Nachverfolgen teurer und ineffizienter Suchvorgänge) des Artikels „Creating More Efficient Microsoft Active Directory-Enabled Applications or migrating away from down-level SAM calls to LDAP calls“ (Erstellen effizienterer Anwendungen mit Microsoft Active Directory-Unterstützung oder Migrieren von Downlevel-SAM-Aufrufen zu LDAP-Aufrufen) behandelt.
In größeren Umgebungen ist dies wichtig, da schlecht codierte Anwendungen die Flüchtigkeit der CPU-Auslastung fördern, eine ungeheure Menge an CPU-Zeit von anderen Anwendungen „stehlen“, Kapazitätsanforderungen künstlich erhöhen und die Last ungleichmäßig auf die Domänencontroller verteilen können.
Da AD DS eine verteilte Umgebung mit einer Vielzahl potenzieller Kunden ist, ist die Schätzung der Kosten eines „einzelnen Kunden“ aufgrund von Nutzungsmustern und der Art oder Menge von Anwendungen, die AD DS nutzen, umgebungsspezifisch. Kurz gesagt, ähnlich wie im Netzwerkabschnitt, ist es für eine breite Anwendbarkeit besser, dies aus der Perspektive der Bewertung der gesamten in der Umgebung benötigten Kapazität zu betrachten.
Da die Dimensionierung des Speichers bereits zuvor erörtert wurde, wird bei bestehenden Umgebungen davon ausgegangen, dass der Speicher jetzt richtig dimensioniert ist und die Daten zur Prozessorlast somit gültig sind. Um es noch einmal zu wiederholen, es ist wichtig, sicherzustellen, dass der Engpass im System nicht die Leistung des Speichers ist. Wenn ein Engpass besteht und der Prozessor wartet, gibt es Leerlaufzustände, die verschwinden, sobald der Engpass entfernt wurde. Wenn die Prozessorwartestatus beseitigt werden, steigt die CPU-Auslastung per Definition, da die CPU nicht mehr auf die Daten warten muss. Erfassen Sie daher die Leistungsindikatoren „Logischer Datenträger(<NTDS-Datenbanklaufwerk>)\Mittlere Sek./Lesevorgänge“ und „Prozess(lsass)\% Prozessorzeit“. Die Daten in „Prozess(lsass)\% Prozessorzeit“ sind künstlich niedrig, wenn „Logischer Datenträger(<NTDS-Datenbanklaufwerk>)\Mittlere Sek./Lesevorgänge“ 10 bis 15 ms überschreitet. Dies ist ein allgemeiner Schwellenwert, den der Microsoft-Support zur Behandlung speicherbezogener Leistungsprobleme verwendet. Wie zuvor sollten die Stichprobenintervalle entweder 15, 30 oder 60 Minuten betragen. Alles darunter ist in der Regel zu flüchtig für gute Messungen; alles darüber glättet die täglichen Spitzen übermäßig.
Einführung
Bei der Kapazitätsplanung für Domänencontroller erfordert die Verarbeitungsleistung die meiste Aufmerksamkeit und das meiste Verständnis. Bei der Größenanpassung von Systemen, um eine maximale Leistung sicherzustellen, gibt es immer eine Komponente, die den Engpass darstellt, und in einem ordnungsgemäß dimensionierten Domänencontroller ist dies der Prozessor.
Ähnlich wie im Netzwerkabschnitt, in dem der Bedarf der Umgebung Standort für Standort überprüft wird, muss dies auch für die erforderliche Computekapazität erfolgen. Im Gegensatz zum Netzwerkabschnitt, in dem die verfügbaren Netzwerktechnologien den normalen Bedarf bei weitem übersteigen, sollten Sie mehr auf die Dimensionierung der CPU-Kapazität achten. Wie in jeder Umgebung von auch nur mäßiger Größe kann alles, was über ein paar Tausend gleichzeitige Benutzer hinausgeht, eine erhebliche Belastung für die CPU darstellen.
Aufgrund der enormen Variabilität von Clientanwendungen, die AD nutzen, ist eine allgemeine Schätzung der Benutzer pro CPU für alle Umgebungen leider nicht anwendbar. Insbesondere die Computeanforderungen unterliegen dem Benutzerverhalten und Anwendungsprofil. Daher muss jede Umgebung individuell dimensioniert werden.
Verhaltensprofil des Zielstandorts
Wie bereits erwähnt, verfolgt die Planung der Kapazität für einen gesamten Standort einen Kapazitätsentwurf von N + 1 als Ziel, sodass ein Ausfall eines Systems während der Spitzenzeit die Fortsetzung des Betriebs mit einem angemessenen Qualitätsniveau ermöglicht. Dies bedeutet, dass in einem „N“-Szenario die Auslastung aller Einheiten während der Spitzenzeiten weniger als 100 % (besser noch, weniger als 80 %) betragen sollte.
Wenn die Anwendungen und Clients am Standort bewährte Methoden zum Auffinden von Domänencontrollern verwenden (d. h. mithilfe der DsGetDcName-Funktion), sollten die Clients außerdem relativ gleichmäßig verteilt werden, wobei geringfügige vorübergehende Spitzen aufgrund einer Reihe von Faktoren auftreten.
Im nächsten Beispiel werden die folgenden Annahmen getroffen:
- Jeder der fünf Domänencontroller am Standort verfügt über vier CPUs.
- Die CPU-Zielauslastung während der Geschäftszeiten beträgt unter normalen Betriebsbedingungen 40 % („N + 1“) und andernfalls 60 % („N“). Außerhalb der Geschäftszeiten beträgt die CPU-Zielauslastung 80 %, da von Sicherungssoftware und anderen Wartungsvorgängen erwartet wird, dass sie alle verfügbaren Ressourcen beanspruchen.
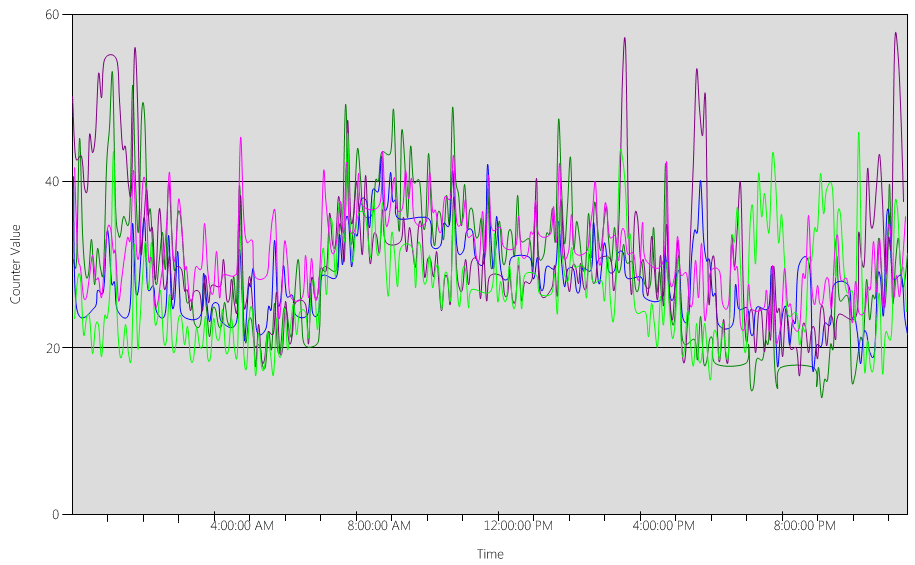
Analysieren der Daten im Diagramm (Processor Information(_Total)\% Processor Utility) für die einzelnen Domänencontroller:
In den meisten Fällen ist die Last relativ gleichmäßig verteilt, was erwartet wird, wenn Clients den Domänencontroller-Locator verwenden und über gut geschriebene Suchvorgänge verfügen.
Es gibt eine Anzahl von fünfminütigen Spitzen von 10 %, von denen einige bis zu 20 % betragen. Im Allgemeinen lohnt es sich nicht, sie zu untersuchen, es sei denn, sie führen zu einer Überschreitung des Kapazitätsplanziels.
Die Spitzenzeit für alle Systeme liegt zwischen ca. 8:00 Uhr und 9:15 Uhr. Mit dem reibungslosen Übergang von ca. 5:00 Uhr bis ca. 17:00 Uhr ist dies in der Regel ein Hinweis auf den Geschäftszyklus. Die mehr zufälligen Spitzen der CPU-Auslastung in einem Box-by-Box-Szenario zwischen 17:00 Uhr und 4:00 Uhr lägen außerhalb der Kapazitätsplanungsaspekte.
Hinweis
Auf einem gut verwalteten System könnten diese Spitzen vielleicht auf ausgeführte Sicherungssoftware, Virenscans des gesamten Systems, Hardware- oder Softwareinventur, Software- oder Patchbereitstellung usw. zurückzuführen sein. Da sie außerhalb des Spitzengeschäftszyklus liegen, werden die Ziele nicht überschritten.
Da jedes System bei 40 % liegt und alle Systeme über die gleiche Anzahl von CPUs verfügen, würden die verbleibenden Systeme bei Ausfall oder Abschaltung eines Systems mit geschätzten 53 % ausgeführt werden (die 40 %-Last von System D wird gleichmäßig aufgeteilt und der vorhandenen 40 %-Last von System A und System C hinzugefügt). Aus einer Reihe von Gründen ist diese lineare Annahme NICHT ganz genau, aber genau genug zum Messen.
Alternatives Szenario: Zwei Domänencontroller, die mit 40 % ausgeführt werden: Ein Domänencontroller fällt aus, die CPU auf dem verbleibenden Domänencontroller wird schätzungsweise mit 80 % ausgeführt. Dies überschreitet die oben für den Kapazitätsplan beschriebenen Schwellenwerte bei weitem und beginnt auch, den Umfang des Spielraums für die 10 % bis 20 % im obigen Auslastungsprofil stark einzuschränken, was bedeutet, dass die Spitzen den Domänencontroller während des „N“-Szenarios auf 90 % bis 100 % treiben und die Reaktionsfähigkeit definitiv beeinträchtigen würden.
Berechnen von CPU-Anforderungen
Der Leistungsindikator „Prozess\% Prozessorzeit“ summiert die Gesamtzeit, für die alle Threads einer Anwendung die CPU beanspruchen, und dividiert sie durch die gesamte verstrichene Systemzeit. Dies hat zur Folge, dass eine Multithreadanwendung auf einem Multi-CPU-System 100 % CPU-Zeit überschreiten kann und SEHR anders interpretiert wird als „Prozessorinformationen\% Prozessor-Hilfsprogramm“. In der Praxis kann „Prozess(lsass)\% Prozessorzeit“ als die Anzahl der zu 100 % ausgeführten CPUs angesehen werden, die zur Unterstützung der Anforderungen des Prozesses erforderlich sind. Ein Wert von 200 % bedeutet, dass 2 CPUs mit jeweils 100 % erforderlich sind, um die vollständige AD DS-Auslastung zu unterstützen. Eine CPU, die mit einer Kapazität von 100 % ausgeführt wird, ist unter dem Gesichtspunkt der Ausgaben für CPUs sowie des Stromverbrauchs zwar am kostengünstigsten, aber ein Multithreadsystem weist aus einer Reihe von Gründen, die in Anhang A beschrieben sind, eine bessere Reaktionsfähigkeit auf, wenn das System nicht zu 100 % ausgeführt wird.
Um vorübergehende Spitzen der Clientlast zu bewältigen, sollte eine CPU-Spitzenzeit von 40 % bis 60 % der Systemkapazität angestrebt werden. Im obigen Beispiel würde dies bedeuten, dass zwischen 3,33 (Ziel 60 %) und 5 (Ziel 40 %) CPUs für die AD DS-Last (lsass-Prozess) benötigt würden. Zusätzliche Kapazität sollte entsprechend den Anforderungen des Basisbetriebssystems und anderer erforderlicher Agents (z. B. Virenschutz, Sicherung, Überwachung usw.) hinzugefügt werden. Obwohl die Auswirkungen von Agents der Umgebung entsprechend ausgewertet werden müssen, ist eine Schätzung zwischen 5 % und 10 % einer einzelnen CPU möglich. Im aktuellen Beispiel würde dies darauf hindeuten, dass in Spitzenzeiten zwischen 3,43 CPUs (Ziel 60 %) und 5,1 (Ziel 40 %) erforderlich sind.
Die einfachste Möglichkeit hierfür ist die Verwendung der Ansicht „Gestapelte Fläche“ in Windows Reliability und Systemmonitor, um sicherzustellen, dass alle Leistungsindikatoren gleich skaliert sind.
Voraussetzungen:
- Ziel ist es, den Speicherbedarf auf so wenige Server wie möglich zu reduzieren. Im Idealfall trägt ein Server die Last, und ein zusätzlicher Server wird zur Redundanz hinzugefügt („N + 1“-Szenario).
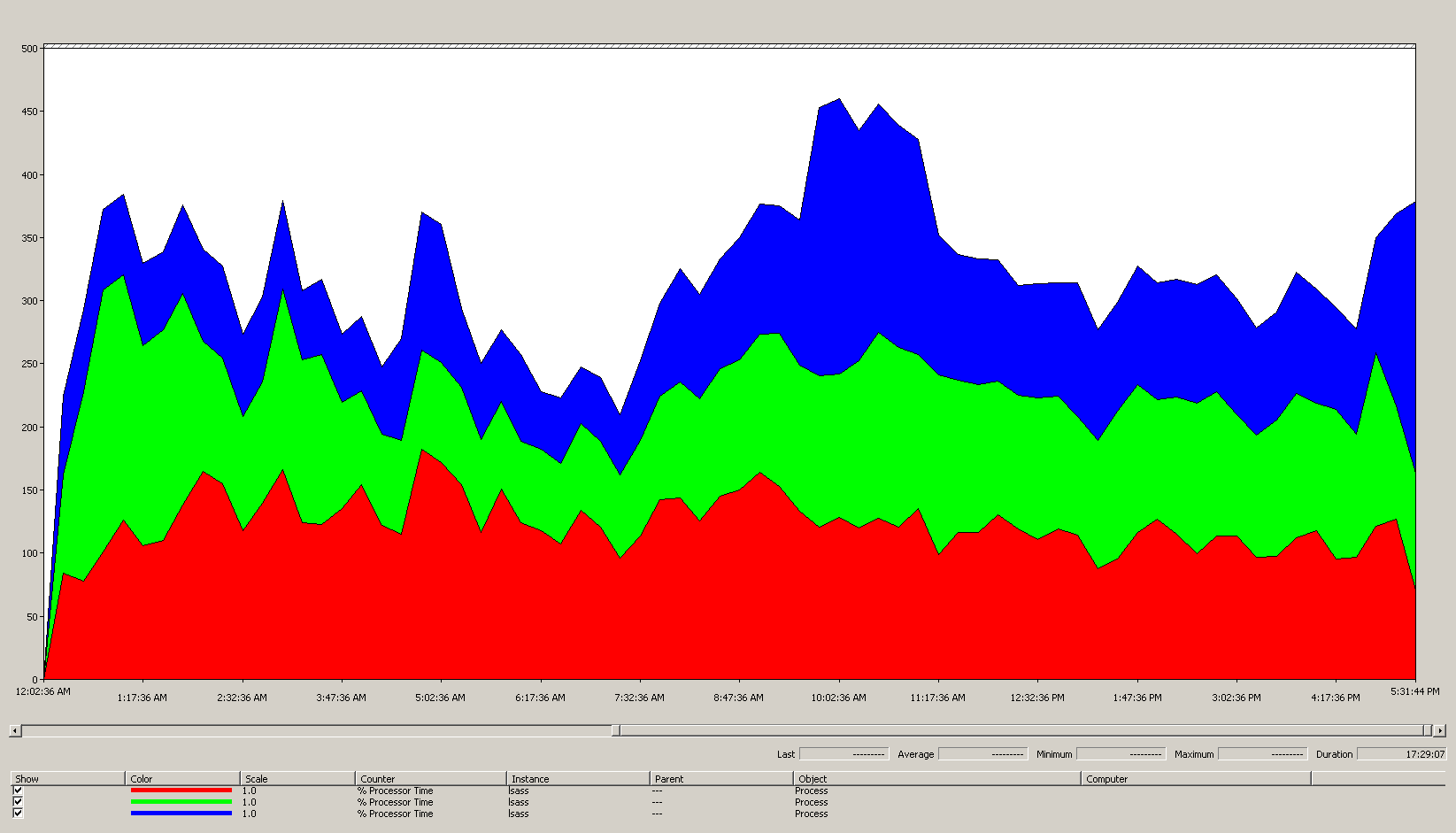
Erkenntnisse aus den Daten im Diagramm (Prozess(lsass)\% Prozessorzeit):
- Der Geschäftstag beginnt um 7:00 Uhr und geht um 17:00 Uhr zu Ende.
- Der Zeitraum der stärksten Nutzung ist von 9:30 Uhr bis 11:00 Uhr.
Hinweis
Alle Leistungsdaten sind Verlaufsdaten. Der Spitzendatenpunkt um 9:15 Uhr gibt die Last von 9:00 bis 9:15 Uhr an.
- Es gibt Spitzen vor 7:00 Uhr, was entweder auf die Auslastung aus verschiedenen Zeitzonen oder auf Infrastrukturaktivitäten im Hintergrund wie Sicherungen hinweisen kann. Da der Höchstwert um 9:30 Uhr diese Aktivität überschreitet, ist er nicht relevant.
- Es gibt drei Domänencontroller an diesem Standort.
Bei maximaler Auslastung verbraucht lsass etwa 485 % einer CPU oder 4,85 CPUs, die zu 100 % ausgeführt werden. Gemäß der obigen Berechnung bedeutet dies, dass der Standort etwa 12,25 CPUs für AD DS benötigt. Fügen Sie die obigen Vorschläge von 5 % bis 10 % für Hintergrundprozesse hinzu. Dies bedeutet, dass für einen Austausch des Servers heute ungefähr 12,30 bis 12,35 CPUs nötig wären, um die gleiche Last zu unterstützen. Eine Umgebunsschätzung für das Wachstum muss nun einbezogen werden.
Wann eine Optimierung der LDAP-Gewichtung erforderlich ist
Es gibt mehrere Szenarien, in denen die Optimierung von LdapSrvWeight in Betracht gezogen werden sollte. Im Rahmen der Kapazitätsplanung erfolgt dies, wenn die Anwendungs- oder Benutzerlasten nicht gleichmäßig ausbalanciert sind oder die zugrunde liegenden Systeme hinsichtlich ihrer Leistungsfähigkeit nicht gleichmäßig ausbalanciert sind. Gründe, die über die Kapazitätsplanung hinausgehen, liegen außerhalb des Rahmens dieses Artikels.
Es gibt zwei häufige Gründe für die Optimierung von LDAP-Gewichtungen:
- Der PDC-Emulator ist ein Beispiel, das jede Umgebung betrifft, in der das Benutzer- oder Anwendungslastverhalten nicht gleichmäßig verteilt ist. Da bestimmte Tools und Aktionen auf den PDC-Emulator abzielen, z. B. die Gruppenrichtlinien-Verwaltungstools, zweite Versuche bei Authentifizierungsfehlern, Vertrauensstellung usw., sind CPU-Ressourcen im PDC-Emulator möglicherweise stärker gefragt als an anderer Stelle des Standorts.
- Es ist nur sinnvoll, dies zu optimieren, wenn es einen spürbaren Unterschied in der CPU-Auslastung gibt, um die Last des PDC-Emulators zu reduzieren, und durch Erhöhen der Last auf anderen Domänencontrollern wird eine gleichmäßigere Lastverteilung ermöglicht.
- Legen Sie in diesem Fall LDAPSrvWeight für den PDC-Emulator zwischen 50 und 75 fest.
- Server mit unterschiedlicher Anzahl von CPUs (und Geschwindigkeiten) an einem Standort. Angenommen, es gibt zwei Server mit acht Kernen und einen Server mit vier Kernen. Der letzte Server verfügt über die Hälfte der Prozessoren der anderen beiden Server. Dies bedeutet, dass eine gut verteilte Clientlast die durchschnittliche CPU-Auslastung der Einheit mit vier Kernen auf etwa das Doppelte der Einheiten mit acht Kernen erhöht.
- Beispielsweise würden die beiden Einheiten mit acht Kernen zu 40 % und die Einheit mit vier Kernen zu 80 % ausgeführt werden.
- Berücksichtigen Sie auch die Auswirkungen des Verlusts eines Feldes mit acht Kernen in diesem Szenario, insbesondere die Tatsache, dass das Feld mit vier Kernen jetzt überlastet wäre.
Beispiel 1: PDC
| System | Auslastung mit Standardwerten | Neues LdapSrvWeight | Geschätzte neue Auslastung |
|---|---|---|---|
| DC1 (PDC-Emulator) | 53 % | 57 | 40% |
| DC 2 | 33 % | 100 | 40% |
| DC 3 | 33 % | 100 | 40% |
Der Haken dabei ist: Wenn die PDC-Emulatorrolle übertragen oder übernommen wird, insbesondere auf einen anderen Domänencontroller am Standort, wird der neue PDC-Emulator drastisch erhöht.
Anhand des Beispiels aus dem Abschnitt Verhaltensprofil des Zielstandorts wurde davon ausgegangen, dass alle drei Domänencontroller am Standort über vier CPUs verfügen. Was sollte unter normalen Bedingungen passieren, wenn einer der Domänencontroller über acht CPUs verfügt? Es würde zwei Domänencontroller mit einer Auslastung von 40 % und einen mit einer Auslastung von 20 % geben. Dies ist zwar nicht schlecht, aber es gibt eine Möglichkeit, die Last ein wenig besser auszugleichen. Nutzen Sie dazu LDAP-Gewichtungen. Ein Beispielszenario wäre:
Beispiel 2: Unterschiedliche CPU-Anzahl
| System | Prozessorinformationen\ % Prozessor-Hilfsprogramm(_Gesamt) Auslastung mit Standardwerten |
Neues LdapSrvWeight | Geschätzte neue Auslastung |
|---|---|---|---|
| 4-CPU DC 1 | 40 | 100 | 30 % |
| 4-CPU DC 2 | 40 | 100 | 30 % |
| 8-CPU DC 3 | 20 | 200 | 30 % |
Seien Sie bei diesen Szenarien jedoch sehr vorsichtig. Auf dem Papier sieht die Berechnung wirklich gut aus. In diesem Artikel ist die Planung eines „N + 1“-Szenarios jedoch von größter Bedeutung. Die Auswirkungen eines offline geschalteten Domänencontrollers müssen für jedes Szenario berechnet werden. In dem unmittelbar vorangegangenen Szenario, in dem die Last gleichmäßig auf alle Server verteilt ist, um eine 60 %ige Last in einem „N“-Szenario zu gewährleisten, wird die Verteilung in Ordnung sein, da die Verhältnisse gleich bleiben. Bei Betrachtung des Szenarios zur Optimierung des PDC-Emulators und im Allgemeinen jedes Szenarios, in dem die Benutzer- oder Anwendungslast nicht ausgeglichen ist, ist die Auswirkung sehr unterschiedlich:
| System | Optimierte Auslastung | Neues LdapSrvWeight | Geschätzte neue Auslastung |
|---|---|---|---|
| DC1 (PDC-Emulator) | 40% | 85 | 47 % |
| DC 2 | 40% | 100 | 53 % |
| DC 3 | 40% | 100 | 53 % |
Überlegungen zur Virtualisierung für die Verarbeitung
Es gibt zwei Ebenen der Kapazitätsplanung, die in einer virtualisierten Umgebung berücksichtigt werden müssen. Auf Hostebene müssen ähnlich wie bei dem zuvor für die Domänencontrollerverarbeitung beschriebenen Geschäftszyklus Schwellenwerte während der Spitzenzeit identifiziert werden. Da die zugrunde liegenden Prinzipien für einen Hostcomputer, der Gastthreads auf der CPU plant, und für das Abrufen von AD DS-Threads auf der CPU identisch sind, wird dasselbe Ziel von 40 % bis 60 % auf dem zugrunde liegenden Host empfohlen. Auf der nächsten Ebene, der Gastebene, liegt das Ziel innerhalb des Gasts im Bereich von 40 % bis 60 %, da sich die Prinzipien der Threadplanung nicht geändert haben.
In einem direkt zugeordneten Szenario, einem Gast pro Host, muss die gesamte Kapazitätsplanung bis zu diesem Punkt den Anforderungen (RAM, Datenträger, Netzwerk) des zugrunde liegenden Hostbetriebssystems hinzugefügt werden. In einem Szenario mit gemeinsam genutztem Host zeigen Tests an, dass sich die Effizienz der zugrunde liegenden Prozessoren zu 10 % auswirkt. Das bedeutet, wenn ein Standort 10 CPUs bei einem Ziel von 40 % benötigt, ist die empfohlene Anzahl virtueller CPUs, die allen „N“-Gästen zugeordnet werden sollen, 11. An einem Standort mit einer gemischten Verteilung aus physischen und virtuellen Servern gilt der Modifizierer nur für die VMs. Wenn ein Standort beispielsweise das Szenario „N + 1“ aufweist, entspricht ein physischer oder direkt zugeordneter Server mit 10 CPUs ungefähr einem Gast mit 11 CPUs auf einem Host, wobei 11 CPUs für den Domänencontroller reserviert sind.
Bei der Analyse und Berechnung der CPU-Mengen, die zur Unterstützung der AD DS-Last erforderlich sind, kann die Anzahl der CPUs im Sinne physischer Hardware nicht unbedingt eindeutig bestimmt werden. Bei der Virtualisierung entfällt die Notwendigkeit, aufzurunden. Virtualisierung verringert den erforderlichen Aufwand, einem Standort Computekapazität hinzuzufügen, wenn man bedenkt, wie leicht eine CPU einem virtuellen Computer hinzugefügt werden kann. Dennoch muss die erforderliche Computeleistung genau bewertet werden, damit die zugrunde liegende Hardware verfügbar ist, wenn den Gästen zusätzliche CPUs hinzugefügt werden müssen. Denken Sie wie immer daran, das Wachstum der Nachfrage zu planen und zu überwachen.
Beispiel für die Berechnungszusammenfassung
| System | Höchstwert für CPU |
|---|---|
| DC 1 | 120 % |
| DC 2 | 147 % |
| DC 3 | 218 % |
| Gesamte CPU-Nutzung | 485 % |
| Anzahl der Zielsysteme | Gesamtbandbreite (von oben) |
|---|---|
| Bei einem Ziel von 40 % erforderliche CPUs | 4,85 ÷ 0,4 = 12,25 |
Zur Wiederholung, weil dieser Punkt so wichtig ist: Denken Sie daran, das Wachstum zu planen. Bei einem angenommenen Wachstum von 50 % in den nächsten drei Jahren wird diese Umgebung 18,375 CPUs (12,25 × 1,5) an der Dreijahresmarke benötigen. Ein alternativer Plan wäre, nach dem ersten Jahr eine Überprüfung durchzuführen und bei Bedarf zusätzliche Kapazität hinzuzufügen.
Vertrauenswürdige Clientauthentifizierungslast für NTLM
Auswerten der Last der vertrauenswürdigen Clientauthentifizierung
Viele Umgebungen verfügen möglicherweise über eine oder mehrere Domänen, die durch eine Vertrauensstellung verbunden sind. Eine Authentifizierungsanforderung für eine Identität in einer anderen Domäne, die keine Kerberos-Authentifizierung verwendet, muss eine Vertrauensstellung über den sicheren Kanal des Domänencontrollers zu einem anderen Domänencontroller durchlaufen, entweder in der Zieldomäne oder in der nächsten Domäne im Pfad zur Zieldomäne. Die Anzahl gleichzeitiger Aufrufe über den sicheren Kanal, die ein Domänencontroller an einen Domänencontroller in einer vertrauenswürdigen Domäne richten kann, wird durch die Einstellung MaxConcurrentAPI gesteuert. Für Domänencontroller wird durch einen von zwei Ansätzen sichergestellt, dass der sichere Kanal die Lastmenge verarbeiten kann: Optimierung von MaxConcurrentAPI oder, innerhalb einer Gesamtstruktur, das Erstellen von Vertrauensstellungsabkürzungen. Informationen zum Messen des Datenverkehrsvolumens einer einzelnen Vertrauensstellung finden Sie unter Leistungsoptimierung für NTLM-Authentifizierung mithilfe der Einstellung MaxConcurrentApi.
Während der Datensammlung muss dies, wie bei allen anderen Szenarien, während der Spitzenzeiten des Tages erfasst werden, damit die Daten nützlich sind.
Hinweis
Gesamstrukturinterne und die Gesamtstruktur übergreifende Szenarien können dazu führen, dass die Authentifizierung mehrere Vertrauensstellungen durchläuft, und jede Phase muss optimiert werden.
Planung
Es gibt eine Reihe von Anwendungen, die die NTLM-Authentifizierung standardmäßig oder in einem bestimmten Konfigurationsszenario verwenden. Anwendungsserver nehmen an Kapazität zu und bedienen immer mehr aktive Clients. Es gibt auch den Trend, dass Clients Sitzungen für eine begrenzte Zeit geöffnet lassen und eher regelmäßig erneut eine Verbindung herstellen (z. B. E-Mail-Pullsynchronisierung). Ein weiteres häufiges Beispiel für hohe NTLM-Auslastung sind Webproxyserver, die eine Authentifizierung für den Internetzugriff erfordern.
Diese Anwendungen können eine erhebliche Last für die NTLM-Authentifizierung verursachen, was die Domänencontroller erheblich belasten kann, insbesondere wenn sich Benutzer*innen und Ressourcen in verschiedenen Domänen befinden.
Es gibt mehrere Ansätze für die Verwaltung von vertrauenswürdiger Last, die in der Praxis in Verbindung und nicht in einem exklusiven „Entweder-oder“-Szenario verwendet werden. Folgende Optionen sind möglich:
- Reduzieren Sie die vertrauenswürdige Clientauthentifizierung, indem Sie die Dienste suchen, die Benutzer*innen in derselben Domäne nutzen, in der sie sich befinden.
- Erhöhen Sie die Anzahl der verfügbaren sicheren Kanäle. Dies ist für den gesamstrukturinternen und die Gesamtstruktur übergreifenden Datenverkehr relevant und wird als „Vertrauensstellungsabkürzungen“ bezeichnet.
- Optimieren Sie die Standardeinstellungen für MaxConcurrentAPI.
Für die Optimierung von MaxConcurrentAPI auf einem vorhandenen Server lautet die Gleichung:
Neue_MaxConcurrentApi-Einstellung ≥ (Semaphor_erwirbt + Semaphortimeouts) × Durchschnittliche_Semaphorenhaltezeit ÷ Dauer_der_Zeiterfassung
Weitere Informationen hierzu finden Sie unter KB-Artikel 2688798: Leistungsoptimierung für NTLM-Authentifizierung mithilfe der Einstellung MaxConcurrentApi.
Virtualisierung: Überlegungen
Keine, dies ist eine Einstellung zur Betriebssystemoptimierung.
Beispiel für die Berechnungszusammenfassung
| Datentyp | Wert |
|---|---|
| Semaphor erwirbt (Minimum) | 6.161 |
| Semaphor erwirbt (Maximum) | 6.762 |
| Semaphortimeouts | 0 |
| Durchschnittliche Semaphorenhaltezeit | 0,012 |
| Sammlungsdauer (Sekunden) | 1:11 Minuten (71 Sekunden) |
| Formel (von KB 2688798) | ((6762 – 6161) + 0) × 0,012 / |
| Mindestwert für MaxConcurrentAPI | ((6762 – 6161) + 0) × 0,012 ÷ 71 = 0,101 |
Für dieses System und diesen Zeitraum sind die Standardwerte akzeptabel.
Überwachung der Einhaltung der Ziele für die Kapazitätsplanung
In diesem Artikel wurde erläutert, dass Planung und Skalierung sich an den Nutzungszielen orientieren. Im Folgenden finden Sie ein zusammenfassendes Diagramm der empfohlenen Schwellenwerte, die überwacht werden müssen, um sicherzustellen, dass die Systeme innerhalb angemessener Kapazitätsschwellenwerte arbeiten. Beachten Sie, dass es sich dabei nicht um Leistungsschwellenwerte handelt, sondern um Schwellenwerte für die Kapazitätsplanung. Ein Server, der diese Schwellenwerte überschreitet, funktioniert, aber dann sollte überprüft werden, ob sich alle Anwendungen gut verhalten. Wenn sich diese Anwendungen gut verhalten, sollte mit der Auswertung von Hardwareupgrades oder anderen Konfigurationsänderungen begonnen werden.
| Category | Leistungsindikator | Intervall/Stichprobenentnahme | Ziel | Warnung |
|---|---|---|---|---|
| Prozessor | Prozessorinformationen(_Gesamt)\% Prozessor-Hilfsprogramm | 60 Min. | 40% | 60% |
| RAM (Windows Server 2008 R2 oder früher) | Arbeitsspeicher\Verfügbare MB | < 100 MB | – | < 100 MB |
| RAM (Windows Server 2012) | Arbeitsspeicher\Langfristige durchschnittliche Lebensdauer im Standbycache | 30 Min. | Muss getestet werden | Muss getestet werden |
| Netzwerk | Netzwerkschnittstelle(*)\Gesendete Bytes/s Netzwerkschnittstelle(*)\Empfangene Bytes/s |
30 Min. | 40% | 60% |
| Storage | Logischer Datenträger(<NTDS-Datenbanklaufwerk>)\Mittlere Sek./Lesevorgänge Logischer Datenträger(<NTDS-Datenbanklaufwerk>)\Mittlere Sek./Schreibvorgänge |
60 Min. | 10 ms | 15 ms |
| AD-Dienste | Netlogon(*)\Durchschnittliche Semaphorenhaltezeit | 60 Min. | 0 | 1 Sekunde |
Anhang A: Kriterien der CPU-Dimensionierung
Definitionen
Prozessor (Mikroprozessor): eine Komponente, die Programmanweisungen liest und ausführt
CPU: Zentralprozessor
Mehrkernprozessor: mehrere CPUs auf demselben IC
Multi-CPU: mehrere CPUs, nicht auf demselben IC
Logischer Prozessor: eine logische Computing-Engine aus Sicht des Betriebssystems
Dies umfasst Hyperthreading, einen Kern eines Mehrkernprozessors oder einen Prozessor mit einem einzelnen Kern.
Da die heutigen Serversysteme über mehrere Prozessoren, mehrere Mehrkernprozessoren und Hyperthreading verfügen, sind diese Informationen verallgemeinert, um beide Szenarien abzudecken. Daher wird der Begriff „logischer Prozessor“ verwendet, da er die Betriebssystem- und Anwendungsperspektive der verfügbaren Computing-Engines darstellt.
Parallelität auf Threadebene
Jeder Thread ist ein unabhängiger Task, da jeder Thread über einen eigenen Stapel und eigene Anweisungen verfügt. Da AD DS Multithreading einsetzt und die Anzahl der verfügbaren Threads mithilfe von Anzeigen und Festlegen einer LDAP-Richtlinie in Active Directory mithilfe von Ntdsutil.exe optimiert werden kann, ist eine mehrere logische Prozessoren übergreifende Skalierung gut machbar.
Parallelität auf Datenebene
Dies umfasst die mehrere Threads übergreifende gemeinsame Nutzung von Daten innerhalb eines Prozesses (im Fall des AD DS-Prozesses allein) und mehrere Threads in mehreren Prozessen übergreifend (im Allgemeinen). Um den Fall nicht zu sehr zu vereinfachen: Dies bedeutet, dass alle Änderungen an Daten in allen ausgeführten Threads in allen verschiedenen Cacheebenen (L1, L2, L3) alle Kerne übergreifend, die diese Threads ausführen, sowie im Aktualisieren des freigegebenen Arbeitsspeichers widergespiegelt werden. Die Leistung kann während Schreibvorgängen beeinträchtigt werden, während alle verschiedenen Arbeitsspeicherorte konsistent sind, bevor die Verarbeitung der Anweisungen fortgesetzt werden kann.
Überlegungen zur CPU-Geschwindigkeit in Verbindung mit mehreren Kernen
Die allgemeine Faustregel ist, dass schnellere logische Prozessoren die zum Verarbeiten einer Reihe von Anweisungen benötigte Zeit reduzieren, während mehr logische Prozessoren bedeuten, dass mehr Aufgaben gleichzeitig ausgeführt werden können. Diese Faustregeln versagen, wenn die Szenarien von Natur aus komplexer werden, wobei Überlegungen zum Abrufen von Daten aus freigegebenem Arbeitsspeicher, zum Warten auf Parallelität auf Datenebene und zum Mehraufwand für die Verwaltung mehrerer Threads erforderlich sind. Dies ist auch der Grund, warum Skalierbarkeit in Systemen mit mehreren Kernen nicht linear ist.
Betrachten Sie die folgenden Analogien in diesen Überlegungen: Stellen Sie sich eine Autobahn vor, wobei jeder Thread ein einzelnes Auto ist, jede Spur ein Kern und das Tempolimit die Taktgeschwindigkeit.
- Wenn nur ein Auto auf der Autobahn ist, spielt es keine Rolle, ob zwei oder 12 Spuren verfügbar sind. Dieses Auto wird nur so schnell fahren, wie es das Tempolimit zulässt.
- Angenommen, die vom Thread benötigten Daten sind nicht sofort verfügbar. Die Analogie wäre, dass ein Straßenabschnitt gesperrt ist. Wenn nur ein Auto auf der Autobahn ist, spielt es keine Rolle, wie hoch die Geschwindigkeitsbegrenzung ist, bis die Spur wieder geöffnet wird (Daten werden aus dem Speicher abgerufen).
- Wenn die Anzahl der Autos steigt, steigt der Mehraufwand für die Verwaltung der Anzahl der Autos. Vergleichen Sie die Erfahrung des Fahrens und die erforderliche Aufmerksamkeit, wenn die Straße praktisch leer ist (z. B. am späten Abend) mit dem starken Verkehr (z. B. nachmittags, aber nicht zur Hauptverkehrszeit). Berücksichtigen Sie auch die erforderliche Aufmerksamkeit, wenn Sie auf einer zweispurigen Autobahn fahren, wo nur auf einer anderen Spur die Aktionen der Fahrer*innen beachtet werden müssen, im Gegensatz zu einer sechsspurigen Autobahn, wo viele andere Fahrer*innen Aufmerksamkeit erfordern.
Hinweis
Die Analogie zum Hauptverkehrszeitszenario wird im nächsten Abschnitt erweitert: Antwortzeit/Wie sich die Systemlast auf die Leistung auswirkt.
Infolgedessen sind Angaben über mehr oder schnellere Prozessoren in hohem Maße vom Anwendungsverhalten abhängig, das im Falle von AD DS sehr umgebungsspezifisch ist und sogar innerhalb einer Umgebung von Server zu Server variiert. Aus diesem Grund wird bei den Verweisen weiter oben im Artikel nicht beharrlich auf übermäßige Präzision gepocht, und eine Sicherheitsmarge wird in die Berechnungen einbezogen. Bei budgetorientierten Kaufentscheidungen sollte die Nutzung der Prozessoren zunächst auf 40 % (oder die für die Umgebung gewünschte Anzahl) optimiert werden, bevor der Kauf schnellerer Prozessoren erwogen wird. Die höhere mehrere Prozessoren übergreifende Synchronisierung verringert den wahren Nutzen von mehr Prozessoren durch die lineare Progression (die doppelte Anzahl Prozessoren bietet weniger als die doppelte verfügbare Computeleistung).
Hinweis
Amdahl-Gesetz und Gustafson-Gesetz sind hier die relevanten Konzepte.
Antwortzeit/Wie sich die Systemlast auf die Leistung auswirkt
Die Warteschlangentheorie ist die mathematische Untersuchung von Wartelinien (Warteschlangen). In der Warteschlangentheorie wird das Nutzungsgesetz durch diese Gleichung dargestellt:
U k = B ÷ T
Dabei ist U k der Auslastungsprozentsatz, B die benötigte Zeit und T die Gesamtzeit, für die das System beobachtet wurde. In den Kontext von Windows übersetzt bedeutet dies die Anzahl der 100-Nanosekunden-Intervallthreads (ns), die sich im Ausführungszustand befinden, dividiert durch die Anzahl von 100-ns-Intervallen, die in einem bestimmten Zeitintervall verfügbar waren. Dies ist genau die Formel für die Berechnung von „% Prozessor-Hilfsprogramm“ (Referenz Prozessorobjekt und PERF_100NSEC_TIMER_INV).
Die Warteschlangentheorie bietet auch die Formel: N = U k ÷ (1 – U k), um die Anzahl der wartenden Elemente basierend auf der Auslastung zu schätzen ( N ist die Länge der Warteschlange). Die Diagrammerstellung für alle Auslastungsintervalle liefert die folgenden Schätzungen, wie lange die Warteschlange für den Prozessorzugriff bei einer bestimmten CPU-Auslastung ist.
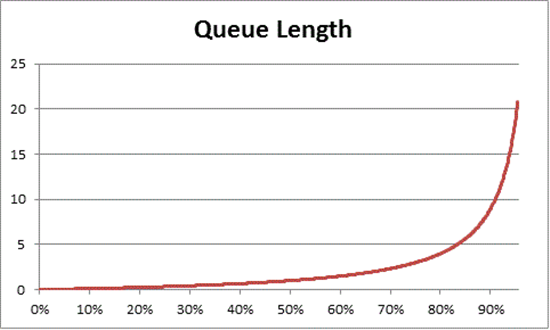
Es ist zu beobachten, dass nach 50 % CPU-Auslastung im Durchschnitt immer mit einem spürbaren schnellen Anstieg nach etwa 70 % CPU-Auslastung auf ein anderes Element in der Warteschlange gewartet wird.
Wir kehren nun zur weiter oben in diesem Abschnitt verwendeten Fahranalogie zurück:
- Die geschäftigen Zeiten des „Nachmittags“ würden hypothetisch irgendwo in den Bereich von 40 % bis 70 % fallen. Das Verkehrsaufkommen ist so, dass die Fähigkeit, eine Spur zu wählen, nicht wesentlich eingeschränkt ist, und die Wahrscheinlichkeit, dass ein anderer Fahrer im Weg ist, zwar hoch ist, jedoch nicht den Aufwand erfordert, eine sichere Lücke zwischen anderen Autos auf der Straße finden zu müssen.
- Wenn die Hauptverkehrszeit näher rückt, ist festzustellen, dass die Auslastung des Straßennetzes sich der 100 %-Marke nähert. Der Wechsel von Fahrspuren kann sehr schwierig werden, weil Autos so nah beieinander sind, dass erhöhte Vorsicht geboten ist.
Aus diesem Grund bieten die langfristigen Durchschnittswerte für die Kapazität, die konservativ auf 40 % geschätzt werden, einen Spielraum für anormale Lastspitzen, unabhängig davon, ob es sich um vorübergehende Spitzen handelt (z. B. schlecht codierte Abfragen, die einige Minuten lang laufen), oder um anormale Bursts in der allgemeinen Last (der Morgen des ersten Tages nach einem langen Wochenende).
In der obigen Aussage wird die Berechnung der prozentualen Prozessorzeit zur Vereinfachung für die Leser*innen mit dem Nutzungsgesetz gleichgesetzt. Für die mathematisch eher Hartgesottenen:
- Übersetzen von PERF_100NSEC_TIMER_INV
- B = Die Anzahl der 100-ns-Intervalle, die der „Leerlauf“-Thread auf dem logischen Prozessor verbringt. Die Änderung der Variablen „X“ in der PERF_100NSEC_TIMER_INV-Berechnung.
- T = die Gesamtzahl der 100-ns-Intervalle in einem bestimmten Zeitbereich. Die Änderung der Variablen „Y“ in der PERF_100NSEC_TIMER_INV-Berechnung.
- U k = Der Auslastungsprozentsatz des logischen Prozessors durch den „Leerlaufthread“ oder % Leerlaufzeit.
- Ausarbeiten der Berechnung:
- U k = 1 – %Prozessorzeit
- %Prozessorzeit = 1 – U k
- %Prozessorzeit = 1 – B / T
- %Prozessorzeit = 1 – X1 – X0 / Y1 – Y0
Anwenden der Konzepte auf die Kapazitätsplanung
Die vorangehende Berechnung kann den Eindruck erwecken, dass die Bestimmung der Anzahl der in einem System benötigten logischen Prozessoren überwältigend komplex ist. Aus diesem Grund konzentriert sich der Ansatz zur Größenanpassung der Systeme darauf, die maximale Zielauslastung auf der aktuellen Last basierend zu bestimmen und die Anzahl der logischen Prozessoren zu berechnen, die hierzu erforderlich sind. Außerdem: Die Geschwindigkeiten logischer Prozessoren haben zwar erhebliche Auswirkungen auf die Leistung, aber Cacheeffizienz, Anforderungen an die Speicherkohärenz, Threadplanung und -synchronisierung sowie unvollkommen ausbalancierte Clientlast haben ebenfalls bedeutende Auswirkungen auf die Leistung, die von Server zu Server variieren. Mit den relativ niedrigen Kosten für Computeleistung wird der Versuch, die perfekte Anzahl der benötigten CPUs zu analysieren und zu ermitteln, eher zu einer akademischen Übung als zu einem geschäftlichen Nutzen.
Vierzig Prozent sind keine harte und unverrückbare Anforderung, sondern ein vernünftiger Anfang. Verschiedene Nutzer*innen von Active Directory benötigen unterschiedliche Reaktionsstufen. Es kann Szenarien geben, in denen Umgebungen mit einer Auslastung von 80 % oder 90 % als dauerhafter Durchschnitt ausgeführt werden können, da sich die erhöhten Wartezeiten für den Zugriff auf den Prozessor nicht spürbar auf die Clientleistung auswirken. Es muss einfach erneut betont werden, dass viele Bereiche im System viel langsamer sind als der logische Prozessor, einschließlich RAM-Zugriff, Datenträgerzugriff und Übertragung der Antwort über das Netzwerk. Alle diese Elemente müssen zusammen optimiert werden. Beispiele:
- Das Hinzufügen weiterer Prozessoren zu einem System, auf dem 90 % auf dem Datenträger ausgeführt werden, wird die Leistung wahrscheinlich nicht wesentlich verbessern. Eine tiefere Analyse des Systems wird wahrscheinlich ergeben, dass viele Threads nicht einmal auf den Prozessor gelangen, weil sie auf den Abschluss der E/A-Vorgänge warten.
- Die datenträgergebundenen Probleme zu behandeln, bedeutet möglicherweise, dass Threads, die sich zuvor lange in einem Wartezustand befanden, nicht mehr in einem E/A-Wartezustand befinden und es einen intensiveren Wettbewerb um die CPU-Zeit gibt, was bedeutet, dass die Auslastung von 90 % im vorherigen Beispiel auf 100 % steigt (da sie nicht höher gehen kann). Beide Komponenten müssen zusammen optimiert werden.
Hinweis
„Prozessorinformationen(*)\% Prozessor-Hilfsprogramm“ kann bei Systemen mit „Turbo“-Modus 100 % überschreiten. Hier überschreitet die CPU für kurze Zeiträume die bewertete Prozessorgeschwindigkeit. Weitere Informationen finden Sie in der Dokumentation des CPU-Herstellers und der Beschreibung des Leistungsindikators.
Wenn Überlegungen zur gesamten Systemauslastung erläutert werden, werden auch die Konversationsdomänencontroller als virtualisierte Gäste berücksichtigt. Antwortzeit/Wie sich die Systemlast auf die Leistung auswirkt gilt sowohl für den Host als auch den Gast in einem virtualisierten Szenario. Darum weist ein Domänencontroller (und im Allgemeinen jedes System) in einem Host mit nur einem Gast nahezu dieselbe Leistung wie auf physischer Hardware auf. Das Hinzufügen zusätzlicher Gäste zu den Hosts erhöht die Auslastung des zugrunde liegenden Hosts und dadurch die Wartezeiten, um Zugriff auf die Prozessoren zu erhalten, wie zuvor erläutert. Kurz gesagt, die Auslastung des logischen Prozessors muss sowohl auf Host- als auch auf Gastebene verwaltet werden.
Wenn Sie die vorherigen Analogien erweitern und die Autobahn als physische Hardware betrachten, entspricht die Gast-VM einem Bus (einem Expressbus, der direkt zum gewünschten Ziel fährt). Stellen Sie sich die folgenden vier Szenarien vor:
- Es ist außerhalb der Geschäftszeit, ein Fahrgast steigt in einen Bus, der fast leer ist, und der Bus fährt auf eine Straße, die auch fast leer ist. Da das Verkehrsaufkommen gering ist, hat der Fahrgast eine schöne angenehme Fahrt und kommt genauso schnell ans Ziel, als ob er selbst gefahren wäre. Die Fahrzeiten des Fahrgasts sind weiterhin durch die Geschwindigkeitsbegrenzung eingeschränkt.
- Es ist außerhalb der Geschäftszeiten, sodass der Bus fast leer ist, aber die meisten Fahrspuren auf der Straße sind gesperrt, so dass die Autobahn immer noch überlastet ist. Der Fahrgast befindet sich in einem fast leeren Bus auf einer überlasteten Straße. Während der Fahrgast nicht um einen Sitzplatz kämpfen muss, wird die Gesamtfahrzeit immer noch durch den übrigen Verkehr draußen diktiert.
- Es ist Hauptverkehrszeit, sodass die Autobahn und der Bus überlastet sind. Die Fahrt dauert nicht nur länger, sondern auch das Ein- und Aussteigen aus dem Bus ist kein Vergnügen, weil die Leute Schulter an Schulter stehen, und auf der Autobahn sieht es nicht viel besser aus. Mehr Busse einzusetzen (logische Prozessoren für den Gast) bedeutet nicht, dass sie leichter auf die Straße passen können, oder dass die Fahrt verkürzt wird.
- Das letzte Szenario, obwohl es die Analogie vielleicht ein wenig überstrapaziert, ist, dass der Bus voll ist, aber die Straße nicht verstopft. Während die Fahrgäste immer noch Probleme beim Ein- und Aussteigen haben, ist die Fahrt effizient, sobald der Bus auf der Straße ist. Dies ist das einzige Szenario, in dem das Einsetzen weiterer Busse (logische Prozessoren für den Gast) die Gastleistung verbessert.
Von dort aus lässt sich relativ einfach extrapolieren, dass zwischen den Auslastungszuständen 0 % und 100 % der Straße und den Auslastungszuständen 0 % und 100 % des Busses Szenarien mit unterschiedlichen Auswirkungen liegen.
Die Anwendung der obigen Prinzipien oberhalb von 40 % CPU als angemessenes Ziel für den Host und den Gast ist aus dem gleichen Grund wie oben, dem Warteschlangenaufkommen, ein vernünftiger Anfang.
Anhang B: Überlegungen zu unterschiedlichen Prozessorgeschwindigkeiten und den Auswirkungen der Prozessorleistungsverwaltung auf Prozessorgeschwindigkeiten
In den Abschnitten zur Prozessorauswahl wird davon ausgegangen, dass der Prozessor während der gesamten Datenerfassung mit 100 % der Taktgeschwindigkeit ausgeführt wird und die Ersatzsysteme über Prozessoren mit identischer Geschwindigkeit verfügen. Obwohl beide Annahmen in der Praxis falsch sind, insbesondere bei Windows Server 2008 R2 und höher, wo der Standardleistungsplan Ausgeglichen ist, wird die Methodik aufrechterhalten, da dies der konservative Ansatz ist. Die potenzielle Fehlerrate kann zwar zunehmen, aber die Sicherheitsmarge wird nur erhöht, wenn die Prozessorgeschwindigkeiten steigen.
- In einem Szenario, in dem 11,25 CPUs erforderlich sind und die Prozessoren bei der Datenerfassung mit halber Geschwindigkeit ausgeführt wurden, könnte die genauere Schätzung z. B. 5,125 ÷ 2 lauten.
- Es ist unmöglich, zu garantieren, dass die Verdoppelung der Taktgeschwindigkeiten die Verarbeitungsmenge in einem bestimmten Zeitraum verdoppeln würde. Dies liegt daran, dass die Zeit, die die Prozessoren damit verbringen, auf RAM oder andere Systemkomponenten zu warten, gleich bleiben könnte. Der Nettoeffekt besteht darin, dass die schnelleren Prozessoren möglicherweise einen größeren Prozentsatz der Zeit im Leerlauf verbringen, während sie auf die abgerufenen Daten warten. Auch hier wird empfohlen, konservativ zu sein und auf dem kleinsten gemeinsamen Nenner zu bleiben, und den Versuch zu vermeiden, einen potenziell falschen Genauigkeitsgrad durch Voraussetzung eines linearen Vergleichs zwischen Prozessorgeschwindigkeiten zu berechnen.
Wenn die Prozessorgeschwindigkeiten bei Ersatzhardware niedriger als bei der aktuellen Hardware sind, wäre es alternativ auch sicher, die Schätzung der benötigten Prozessoren um einen proportionalen Betrag zu erhöhen. Beispielsweise wird berechnet, dass 10 Prozessoren benötigt werden, um die Last an einem Standort aufrechtzuerhalten, und die aktuellen Prozessoren werden mit 3,3 GHz und Ersatzprozessoren mit 2,6 Ghz ausgeführt. Dies ist eine Geschwindigkeitsabnahme von 21 %. In diesem Fall wären 12 Prozessoren die empfohlene Menge.
Allerdings würde diese Variabilität die Auslastungsziele des Kapazitätsverwaltungsprozessors nicht ändern. Da die Prozessortaktgeschwindigkeiten dynamisch basierend auf der benötigten Last angepasst werden, erzeugt die Ausführung des Systems unter höheren Lasten ein Szenario, in dem die CPU mehr Zeit in einem Zustand mit höherer Taktgeschwindigkeit verbringt, sodass das ultimative Ziel bei einer Auslastung von 40 % in einem Geschwindigkeitszustand von 100 % zu Spitzenzeiten liegt. Alles darunter führt zu Energieeinsparungen, da die CPU-Geschwindigkeiten außerhalb von Spitzenszenarien wieder gedrosselt werden.
Hinweis
Eine Option wäre, die Energieverwaltung auf den Prozessoren zu deaktivieren (Festlegen des Energiesparplans auf Hochleistung), während Daten gesammelt werden. Dadurch würde der CPU-Verbrauch auf dem Zielserver genauer dargestellt.
Um die Schätzungen für verschiedene Prozessoren anzupassen, war es früher sicher, mit Ausnahme anderer oben beschriebener Systemengpässe, davon auszugehen, dass die Verdoppelung der Prozessorgeschwindigkeiten die potenzielle Verarbeitungsmenge verdoppelte. Heute ist die interne Architektur von Prozessoren so unterschiedlich, dass eine sicherere Möglichkeit zum Messen der Auswirkungen der Verwendung anderer Prozessoren als der, von denen die Daten erfasst wurden, darin besteht, den SPECint_rate2006-Benchmark von Standard Performance Evaluation Corporation zu nutzen.
Suchen Sie die SPECint_rate2006-Bewertungen für den verwendeten Prozessor und den zu verwendenden Plan.
- Wählen Sie auf der Website der Standard Performance Evaluation Corporation die Option Results (Ergebnisse) aus, markieren Sie CPU2006, und wählen Sie Search all SPECint_rate2006 results (Alle SPECint_rate2006-Ergebnisse suchen) aus.
- Geben Sie unter Simple Request (Einfache Anforderung) die Suchkriterien für den Zielprozessor ein, z. B. Processor Matches E5-2630 (baselinetarget) (Prozessor entspricht E5-2630 (Baselineziel)) und Processor Matches E5-2650 (baseline) (Prozessor entspricht E5-2650 (Baseline)).
- Suchen Sie die zu verwendende Server- und Prozessorkonfiguration (oder etwas Annäherndes, wenn keine genaue Übereinstimmung verfügbar ist), und notieren Sie sich den Wert in den Spalten Result (Ergebnis) und # Cores (Anzahl Kerne).
Verwenden Sie die folgende Gleichung, um den Modifizierer zu bestimmen:
((Wert der Zielplattform pro Kern) × (MHz pro Kern der Baselineplattform)) ÷ ((Baseline-Wert pro Kern) × (MHz pro Kern der Zielplattform))
Verwenden des obigen Beispiels:
(35,83 × 2000) ÷ (33,75 × 2300) = 0,92
Multiplizieren Sie die geschätzte Anzahl von Prozessoren mit dem Modifizierer. Um im obigen Fall vom E5-2650-Prozessor zum E5-2630-Prozessor zu wechseln, rechnen Sie folgendermaßen: 11,25 CPUs × 0,92 = 10,35 erforderliche Prozessoren.
Anhang C: Grundlagen zur Interaktion des Betriebssystems mit Speicher
Die Konzepte der Warteschlangentheorie, die unter Antwortzeit/Wie sich die Systemlast auf die Leistung auswirkt beschrieben werden, gelten auch für den Speicher. Für die Anwendung dieser Konzepte muss die E/A-Handhabung durch das Betriebssystem bekannt sein. Im Microsoft Windows-Betriebssystem wird für jeden physischen Datenträger eine Warteschlange für die E/A-Anforderungen erstellt. Es ist jedoch eine Klarstellung zu physischen Datenträgern erforderlich. Arraycontroller und SANs stellen Aggregationen von Spindeln für das Betriebssystem als einzelne physische Datenträger dar. Darüber hinaus können Arraycontroller und SANs mehrere Datenträger zu einem Arraysatz aggregieren und diesen Arraysatz dann in mehrere „Partitionen“ aufteilen, die wiederum dem Betriebssystem als mehrere physische Datenträger dargestellt werden (siehe Abbildung).
In dieser Abbildung werden die beiden Spindeln gespiegelt und in logische Bereiche für die Datenspeicherung (Data 1 und Data 2) unterteilt. Diese logischen Bereiche werden vom Betriebssystem als separate physische Datenträger betrachtet.
Obwohl dies sehr verwirrend sein kann, wird in diesem Anhang die folgende Terminologie verwendet, um die verschiedenen Entitäten zu identifizieren:
- Spindel: das physisch auf dem Server installierte Gerät.
- Array: eine Sammlung vom Controller aggregierter Spindeln.
- Arraypartition: eine Partitionierung des aggregierten Arrays.
- LUN: ein beim Verweis auf SANs verwendetes Array.
- Datenträger: vom Betriebssystem als einzelner physischer Datenträger betrachtet.
- Partition: eine logische Partitionierung dessen, was vom Betriebssystem als einzelner physischer Datenträger betrachtet wird.
Überlegungen zur Architektur des Betriebssystems
Das Betriebssystem erstellt eine FIFO-E/A-Warteschlange (First In/First Out) für jeden beobachteten Datenträger. Dieser Datenträger kann eine Spindel, ein Array oder eine Arraypartition darstellen. Aus Sicht des Betriebssystems sollten im Hinblick auf die E/A-Verarbeitung so viel aktive Warteschlangen wie möglich vorhanden sein. Da eine FIFO-Warteschlange serialisiert wird, müssen alle auf das Speichersubsystem zielenden E/A-Vorgänge in der Reihenfolge verarbeitet werden, in der die Anforderungen eingegangen sind. Indem alle vom Betriebssystem beobachteten Datenträger mit einer Spindel/einem Array korreliert werden, verwaltet das Betriebssystem nun eine E/A-Warteschlange für jeden eindeutigen Satz von Datenträgern, wodurch Konflikte um knappe E/A-Ressourcen datenträgerübergreifend beseitigt werden und die E/A-Nachfrage auf einen einzelnen Datenträger isoliert wird. Als Ausnahme führt Windows Server 2008 das Konzept der E/A-Priorisierung ein, und Anwendungen, die für die Verwendung der „Low“-Priorität entwickelt wurden, fallen aus dieser normalen Reihenfolge heraus und treten in den Hintergrund. Anwendungen, die nicht speziell codiert sind, um die „Low“-Priorität zu nutzen, werden standardmäßig auf „Normal“ gesetzt.
Einführung einfacher Speichersubsysteme
Beginnend mit einem einfachen Beispiel (einer einzelnen Festplatte in einem Computer) wird eine Analyse Komponente für Komponente ausgeführt. Unterteilt in die wichtigsten Komponenten des Speichersubsystems, besteht das System aus:
- 1 10.000 U/min Ultra Fast SCSI-HD (Ultra Fast SCSI hat eine Übertragungsrate von 20 MB/s)
- 1 SCSI-Bus (das Kabel)
- 1 Ultra Fast SCSI-Adapter
- 1 32-Bit 33 MHz-PCI-Bus
Sobald die Komponenten identifiziert sind, kann berechnet werden, wie viele Daten das System durchlaufen bzw. wie viele E/A-Vorgänge verarbeitet werden können. Beachten Sie, dass die E/A-Menge und die Menge der Daten, die das System durchlaufen können, korreliert, aber nicht identisch sind. Diese Korrelation hängt davon ab, ob die E/A des Datenträgers zufällig oder sequenziell ist, und von der Blockgröße. (Alle Daten werden als Block auf den Datenträger geschrieben, aber verschiedene Anwendungen verwenden unterschiedliche Blockgrößen.) Komponente für Komponente:
Die Festplatte Die durchschnittliche Festplatte mit 10.000 U/min hat eine Suchzeit von 7 Millisekunden (ms) und eine Zugriffszeit von 3 ms. Die Suchzeit ist die durchschnittliche Zeit, die der Lese-/Schreibkopf benötigt, um an eine Position auf der Platte zu wechseln. Die Zugriffszeit ist die durchschnittliche Zeit, die zum Lesen der Daten vom Datenträger oder Schreiben darauf benötigt wird, sobald sich der Kopf an der richtigen Position befindet. Die durchschnittliche Lesezeit für einen eindeutigen Datenblock auf einer HD mit 10.000 U/min setzt sich also aus Suche und Zugriff zusammen und beträgt insgesamt ca. 10 ms (oder 0,010 Sekunden) pro Datenblock.
Wenn jeder Datenträgerzugriff eine Bewegung des Kopfes an einen neuen Speicherort auf dem Datenträger erfordert, wird das Lese-/Schreibverhalten als „wahlfrei“ bezeichnet. Wenn also alle E/A-Vorgänge wahlfrei sind, kann eine HD mit 10.000 U/min ungefähr 100 E/A-Vorgänge pro Sekunde (IOPS) verarbeiten (die Formel ist 1000 ms pro Sekunde geteilt durch 10 ms pro E/A-Vorgang oder 1000/10=100 IOPS).
Wenn alle E/A-Vorgänge von benachbarten Sektoren auf der HD erfolgen, wird dies auch als sequenzielle E/A bezeichnet. Sequenzielle E/A hat keine Suchzeit, da sich der Lese-/Schreibkopf nach Abschluss der ersten E/A am Anfang der Stelle befindet, wo der nächste Datenblock auf der HD gespeichert wird. Eine HD mit 10.000 U/min kann also ca. 333 E/A pro Sekunde verarbeiten (1000 ms pro Sekunde dividiert durch 3 ms pro E/A).
Hinweis
Dieses Beispiel spiegelt nicht den Datenträgercache wider, in dem die Daten eines Zylinders normalerweise gespeichert werden. In diesem Fall werden die 10 ms für die erste E/A benötigt, und der Datenträger liest den gesamten Zylinder. Alle anderen sequenziellen E/A-Vorgänge werden aus dem Cache bedient. Daher können Datenträgercaches die sequenzielle E/A-Leistung verbessern.
Bisher war die Übertragungsrate der Festplatte irrelevant. Unabhängig davon, ob es sich um eine 20 MB/s Ultra Wide- oder Ultra3 160 MB/s-Festplatte handelt, beträgt die tatsächliche Menge an IOPS, die von der 10.000-U/min-HD verarbeitet werden können, ~100 wahlfreie oder ~300 sequenzielle E/A-Vorgänge. Wenn sich die Blockgrößen basierend auf der Anwendung ändern, die auf das Laufwerk schreibt, ist die pro E/A gepullte Datenmenge unterschiedlich. Wenn die Blockgröße beispielsweise 8 KB beträgt, werden bei 100 E/A-Vorgängen insgesamt 800 KB von der Festplatte gelesen oder darauf geschrieben. Wenn die Blockgröße jedoch 32 KB beträgt, werden bei 100 E/A-Vorgängen 3.200 KB (3,2 MB) von der Festplatte gelesen oder darauf geschrieben. Solange die SCSI-Übertragungsrate über der Gesamtmenge der übertragenen Daten liegt, ist mit einem Laufwerk mit „höherer“ Übertragungsrate nichts gewonnen. Vergleiche finden Sie in den folgenden Tabellen.
BESCHREIBUNG 7.200 U/min, 9 ms Suche, 4 ms Zugriff 10.000 U/min, 7 ms Suche, 3 ms Zugriff 15.000 U/min, 4 ms Suche, 2 ms Zugriff Zufällige E/A 80 100 150 Sequenzielle E/A 250 300 500 Laufwerk mit 10.000 U/min Blockgröße von 8 KB (Active Directory Jet) Zufällige E/A 800 KB/s Sequenzielle E/A 2.400 KB/s SCSI-Backplane (Bus) Um zu verstehen, wie sich „SCSI-Backplane (Bus)“ oder in diesem Szenario das Flachbandkabel, auf den Durchsatz des Speichersubsystems auswirkt, muss die Blockgröße bekannt sein. Im Wesentlichen wäre die Frage, wie viel E/A der Bus verarbeiten kann, wenn die E/A in Blöcken von 8 KB erfolgt? In diesem Szenario leistet der SCSI-Bus 20 MB/s oder 20.480 KB/s. 20.480 KB/s geteilt durch 8-KB-Blöcke ergibt ein vom SCSI-Bus unterstütztes Maximum von ca. 2.500 IOPS.
Hinweis
Die Abbildungen in der folgenden Tabelle stellen ein Beispiel dar. Die meisten angeschlossenen Speichergeräte verwenden derzeit PCI Express, was einen viel höheren Durchsatz bietet.
Vom SCSI-Bus pro Blockgröße unterstützte E/A-Vorgänge 2 KB Blockgröße 8 KB Blockgröße (AD Jet) (SQL Server 7.0/SQL Server 2000) 20 MB/s 10.000 2\.500 40 MB/s 20.000 5\.000 128 MB/s 65.536 16.384 320 MB/s 160.000 40.000 Wie dieses Diagramm zeigt, wird der Bus im dargestellten Szenario unabhängig von der Verwendung nie ein Engpass sein, da das Spindelmaximum 100 E/A beträgt und damit deutlich unter einem der oben genannten Schwellenwerte liegt.
Hinweis
Dabei wird vorausgesetzt, dass der SCSI-Bus zu 100 % effizient ist.
SCSI-Adapter Um zu bestimmen, wie viele E/A-Vorgänge damit verarbeitet werden können, müssen die Herstellerspezifikationen überprüft werden. Für die Weiterleitung von E/A-Anforderungen an das entsprechende Gerät ist eine bestimmte Verarbeitung erforderlich. Daher hängt die Menge der E/A-Vorgänge, die verarbeitet werden können, vom Prozessor des SCSI-Adapters (oder Arraycontrollers) ab.
In diesem Beispiel wird davon ausgegangen, dass 1.000 E/A-Vorgänge verarbeitet werden können.
PCI-Bus Diese Komponente wird häufig übersehen. In diesem Beispiel ist sie nicht der Engpass. Wenn Systeme jedoch hochskaliert werden, kann sie zu einem Engpass werden. Als Referenz: Ein 32-Bit-PCI-Bus, der mit 33 MHz betrieben wird, kann theoretisch 133 MB/s übertragen. Es folgt die Gleichung:
32 Bits ÷ 8 Bits pro Byte × 33 MHz = 133 MB/s.
Beachten Sie, dass dies die theoretische Grenze ist; tatsächlich werden nur etwa 50 % des Höchstwerts erreicht, obwohl in bestimmten Burstszenarien für kurze Zeiträume eine Effizienz von 75 % erreicht werden kann.
Ein 64-Bit-PCI-Bus mit 66 MHz kann ein theoretisches Maximum von (64 Bits ÷ 8 Bits pro Byte × 66 MHz) = 528 MB/s unterstützen. Darüber hinaus verringert jedes andere Gerät (z. B. Netzwerkadapter, zweiter SCSI-Controller usw.) die verfügbare Bandbreite, da die Bandbreite gemeinsam genutzt wird und die Geräte um die begrenzten Ressourcen konkurrieren.
Nach der Analyse der Komponenten dieses Speichersubsystems ist die Spindel der begrenzende Faktor für die E/A-Menge, die angefordert werden kann, und damit die Datenmenge, die das System durchlaufen kann. In einem AD DS-Szenario sind dies konkret 100 wahlfreie E/A-Vorgänge pro Sekunde in 8-KB-Inkrementen für insgesamt 800 KB pro Sekunde beim Zugriff auf die Jet-Datenbank. Alternativ würde der maximale Durchsatz für eine Spindel, die ausschließlich Protokolldateien zugeordnet ist, die folgenden Einschränkungen aufweisen: 300 sequenzielle E/A-Vorgänge pro Sekunde in 8-KB-Inkrementen für insgesamt 2.400 KB (2,4 MB) pro Sekunde.
Nachdem Sie nun eine einfache Konfiguration analysiert haben, zeigt die folgende Tabelle, wo der Engpass auftritt, wenn Komponenten im Speichersubsystem geändert oder hinzugefügt werden.
| Notizen | Engpassanalyse | Datenträger | Bus | Adapter | PCI-Bus |
|---|---|---|---|---|---|
| Dies ist die Domänencontrollerkonfiguration nach dem Hinzufügen eines zweiten Datenträgers. Die Datenträgerkonfiguration stellt den Engpass bei 800 KB/s dar. | Hinzufügen von 1 Datenträger (Gesamtmenge=2) E/A ist wahlfrei 4 KB Blockgröße 10.000 U/min-HD |
200 E/A-Vorgänge insgesamt 800 KB/s insgesamt |
|||
| Nach dem Hinzufügen von 7 Datenträgern stellt die Datenträgerkonfiguration bei 3.200 KB/s weiterhin den Engpass dar. | Hinzufügen von 7 Datenträgern (Gesamtmenge=8) E/A ist wahlfrei 4 KB Blockgröße 10.000 U/min-HD |
800 E/A-Vorgänge insgesamt 3.200 KB/s insgesamt |
|||
| Nach dem Ändern der E/A in sequenziell wird der Netzwerkadapter zum Engpass, da er auf 1.000 IOPS beschränkt ist. | Hinzufügen von 7 Datenträgern (Gesamtmenge=8) E/A ist sequenziell 4 KB Blockgröße 10.000 U/min-HD |
2.400 E/A-Vorgänge (Lesen/Schreiben) pro Sekunde auf dem Datenträger, Controller auf 1.000 IOPS beschränkt | |||
| Nach dem Ersetzen des Netzwerkadapters durch einen SCSI-Adapter, der 10.000 IOPS unterstützt, liegt der Engpass wieder bei der Datenträgerkonfiguration. | Hinzufügen von 7 Datenträgern (Gesamtmenge=8) E/A ist wahlfrei 4 KB Blockgröße 10.000 U/min-HD Upgrade des SCSI-Adapters (unterstützt jetzt 10.000 E/A) |
800 E/A-Vorgänge insgesamt 3.200 KB/s insgesamt |
|||
| Nach dem Erhöhen der Blockgröße auf 32 KB wird der Bus zum Engpass, da er nur 20 MB/s unterstützt. | Hinzufügen von 7 Datenträgern (Gesamtmenge=8) E/A ist wahlfrei 32 KB Blockgröße 10.000 U/min-HD |
800 E/A-Vorgänge insgesamt 25.600 KB/s (25 MB/s) können vom Datenträger gelesen/darauf geschrieben werden. Der Bus unterstützt nur 20 MB/s. |
|||
| Nach dem Upgrade des Busses und dem Hinzufügen weiterer Datenträger bleibt der Datenträger der Engpass. | Hinzufügen von 13 Datenträgern (Gesamtmenge=14) Hinzufügen eines zweiten SCSI-Adapters mit 14 Datenträgern E/A ist wahlfrei 4 KB Blockgröße 10.000 U/min-HD Upgrade auf SCSI-Bus mit 320 MB/s |
2.800 E/A 11.200 KB/s (10,9 MB/s) |
|||
| Nach dem Ändern der E/A in sequenziell bleibt der Datenträger der Engpass. | Hinzufügen von 13 Datenträgern (Gesamtmenge=14) Hinzufügen eines zweiten SCSI-Adapters mit 14 Datenträgern E/A ist sequenziell 4 KB Blockgröße 10.000 U/min-HD Upgrade auf SCSI-Bus mit 320 MB/s |
8.400 E/A 33,600 KB/s (32,8 MB/s) |
|||
| Nach dem Hinzufügen schnellerer Festplatten bleibt der Datenträger der Engpass. | Hinzufügen von 13 Datenträgern (Gesamtmenge=14) Hinzufügen eines zweiten SCSI-Adapters mit 14 Datenträgern E/A ist sequenziell 4 KB Blockgröße 15.000 U/min-HD Upgrade auf SCSI-Bus mit 320 MB/s |
14.000 E/A 56.000 KB/s (54,7 MB/s) |
|||
| Nach dem Erhöhen der Blockgröße auf 32 KB wird der PCI-Bus zum Engpass. | Hinzufügen von 13 Datenträgern (Gesamtmenge=14) Hinzufügen eines zweiten SCSI-Adapters mit 14 Datenträgern E/A ist sequenziell 32 KB Blockgröße 15.000 U/min-HD Upgrade auf SCSI-Bus mit 320 MB/s |
14.000 E/A 448.000 KB/s (437 MB/s) ist die Lese-/Schreibgrenze für die Spindel. Der PCI-Bus unterstützt ein theoretisches Maximum von 133 MB/s (bestenfalls zu 75 % effizient). |
Einführung von RAID
Die Art eines Speichersubsystems ändert sich nicht wesentlich, wenn ein Arraycontroller eingeführt wird. Er ersetzt lediglich den SCSI-Adapter in den Berechnungen. Was sich ändert, sind die Kosten für das Lesen und Schreiben von Daten auf den Datenträger, wenn die verschiedenen Arrayebenen (z. B. RAID 0, RAID 1 oder RAID 5) verwendet werden.
Bei RAID 0 werden die Daten über alle Festplatten des RAID-Satzes verteilt. Dies bedeutet, dass während eines Lese- oder Schreibvorgangs ein Teil der Daten von jedem Datenträger gepullt oder darauf gepusht wird, wodurch die Datenmenge erhöht wird, die das System während des gleichen Zeitraums übertragen kann. So können in einer Sekunde auf jeder Spindel (wiederum bei 10.000-U/min-Laufwerken) 100 E/A-Vorgänge ausgeführt werden. Insgesamt kann eine E/A-Menge von N Spindeln mal 100 E/A-Vorgänge pro Sekunde und Spindel (ergibt 100*N E/A-Vorgänge pro Sekunde) unterstützt werden.

In RAID 1 werden die Daten zur Redundanz auf einem Spindelpaar gespiegelt (dupliziert). Wenn also ein Lese-E/A-Vorgang ausgeführt wird, können Daten von beiden Spindeln im Satz gelesen werden. Dadurch wird die E/A-Kapazität beider Datenträger während eines Lesevorgangs effektiv verfügbar. Der Nachteil ist, dass bei Schreibvorgängen in RAID 1 kein Leistungsvorteil erzielt wird. Dies liegt daran, dass dieselben Daten aus Gründen der Redundanz auf beide Laufwerke geschrieben werden müssen. Dies dauert zwar nicht länger, da die Daten gleichzeitig auf beide Spindeln geschrieben werden, aber weil beide Spindeln zum Duplizieren der Daten belegt sind, verhindert ein Schreib-E/A-Vorgang im Wesentlichen das Ausführen von zwei Lesevorgängen. Jeder E/A-Schreibvorgang kostet also zwei E/A-Lesevorgänge. Anhand dieser Informationen kann eine Formel erstellt werden, um die Gesamtzahl der ausgeführten E/A-Vorgänge zu bestimmen:
Lese-E/A + 2 × Schreib-E/A = Insgesamt verbrauchte verfügbare Datenträger-E/A
Wenn das Verhältnis von Lesevorgängen zu Schreibvorgängen und die Anzahl der Spindeln bekannt sind, kann die folgende Gleichung aus der obigen Gleichung abgeleitet werden, um das E/A-Maximum zu identifizieren, das vom Array unterstützt werden kann:
Maximale IOPS pro Spindel × 2 Spindeln × [(%Lesevorgänge + %Schreibvorgänge) ÷ (%Lesevorgänge + 2 × %Schreibvorgänge)] = IOPS insgesamt
RAID 1+ 0 verhält sich hinsichtlich des Lese- und Schreibaufwands genau wie RAID 1. Die E/A wird jetzt jedoch auf alle Spiegelsätze verteilt. Wenn
Maximale IOPS pro Spindel × 2 Spindeln × [(%Lesevorgänge + %Schreibvorgänge) ÷ (%Lesevorgänge + 2 × %Schreibvorgänge)] = Gesamt-E/A
Wenn bei RAID 1-Sätzen eine Verteilung auf mehrere (N) RAID 1-Sätze erfolgt, entspricht die E/A-Gesamtmenge, die verarbeitet werden kann, N × E/A pro RAID 1-Satz:
N × {Maximale IOPS pro Spindel × 2 Spindeln × [(%Lesevorgänge + %Schreibvorgänge) ÷ (%Lesevorgänge + 2 × %Schreibvorgänge)] = IOPS insgesamt
In RAID 5, manchmal auch als N + 1 RAID bezeichnet, werden die Daten über N Spindeln verteilt, und Paritätsinformationen werden in die Spindel „+ 1“ geschrieben. RAID 5 ist jedoch bei der Ausführung eines E/A-Schreibvorgangs wesentlich teurer als RAID 1 oder 1 + 0. RAID 5 führt bei jeder Übermittlung eines E/A-Schreibvorgangs an das Array folgenden Prozess aus:
- Lesen der alten Daten
- Lesen der alten Parität
- Schreiben der neuen Daten
- Schreiben der neuen Parität
Da für jede Schreib-E/A-Anforderung, die vom Betriebssystem an den Arraycontroller übermittelt wird, vier E/A-Vorgänge erforderlich sind, dauert die Ausführung von gesendeten Schreibanforderungen viermal so lange wie ein einzelner E/A-Lesevorgang. So leiten Sie eine Formel ab, mit der E/A-Anforderungen aus Betriebssystemperspektive in die Perspektive der Spindeln übersetzt werden:
Lese-E/A + 4 × Schreib-E/A = Gesamt-E/A
Wenn in einem RAID 1-Satz das Verhältnis von Lesevorgängen zu Schreibvorgängen und die Anzahl der Spindeln bekannt sind, kann ebenso die folgende Gleichung aus der obigen Gleichung abgeleitet werden, um das E/A-Maximum zu identifizieren, das vom Array unterstützt werden kann (beachten Sie, dass die Gesamtzahl der Spindeln nicht das „Laufwerk“ enthält, das an die Parität verloren gegangen ist):
IOPS pro Spindel × (Spindeln – 1) × [(%Lesevorgänge + %Schreibvorgänge) ÷ (%Lesevorgänge + 4 × %Schreibvorgänge)] = IOPS insgesamt
Einführung von SANs
Durch die höhere Komplexität des Speichersubsystems bei Einführung eines SAN in die Umgebung ändern sich die beschriebenen Grundprinzipien nicht, jedoch muss das E/A-Verhalten für alle mit dem SAN verbundenen Systeme berücksichtigt werden. Da zusätzliche Redundanz gegenüber intern oder extern angefügtem Speicher einer der Hauptvorteile bei der Verwendung eines SAN ist, müssen bei der Kapazitätsplanung jetzt die Anforderungen an die Fehlertoleranz berücksichtigt werden. Außerdem werden weitere Komponenten eingeführt, die ausgewertet werden müssen. Aufteilen eines SAN in die Komponententeile:
- SCSI- oder Fibre Channel-Festplatte
- Speichereinheitskanal-Backplane
- Speichereinheiten
- Speichercontrollermodul
- SAN-Switch(es)
- HBA(s)
- Der PCI-Bus
Beim redundanzbetonten Entwurf eines Systems werden zusätzliche Komponenten eingeschlossen, um das Ausfallpotenzial zu berücksichtigen. Bei der Kapazitätsplanung ist es sehr wichtig, die redundante Komponente von den verfügbaren Ressourcen auszuschließen. Wenn das SAN beispielsweise über zwei Controllermodule verfügt, sollte ausschließlich die E/A-Kapazität eines Controllermoduls für den gesamten E/A-Durchsatz verwendet werden, der dem System zur Verfügung steht. Dies ist notwendig, weil bei einem Ausfall eines Controllers die von allen verbundenen Systemen benötigte gesamte E/A-Last vom verbleibenden Controller verarbeitet werden muss. Da die gesamte Kapazitätsplanung für Spitzenauslastungs-Zeiträume erfolgt, sollten redundante Komponenten nicht in die verfügbaren Ressourcen eingeschlossen werden, und die geplante Spitzenauslastung sollte die Sättigung des Systems von 80 % nicht überschreiten (um Bursts oder anomales Systemverhalten zu berücksichtigen). Ebenso sollten der redundante SAN-Switch, die Speichereinheit und die Spindeln nicht in die E/A-Berechnungen einbezogen werden.
Bei der Analyse des Verhaltens der SCSI- oder Fibre Channel-Festplatte ändert sich die zuvor beschriebene Methode zur Analyse des Verhaltens nicht. Obwohl jedes Protokoll bestimmte Vor- und Nachteile hat, ist der begrenzende Faktor pro Datenträger die mechanische Einschränkung der Festplatte.
Die Analyse des Kanals in der Speichereinheit entspricht genau der Berechnung der verfügbaren Ressourcen im SCSI-Bus oder der Bandbreite (z. B. 20 MB/s) dividiert durch die Blockgröße (z. B. 8 KB). Dies weicht in der Aggregation mehrerer Kanäle vom einfachen vorherigen Beispiel ab. Wenn beispielsweise von 6 Kanälen jeder eine maximale Übertragungsrate von 20 MB/s unterstützt, beträgt die verfügbare E/A- und Datenübertragungsgesamtmenge 100 MB/s (dies ist richtig, es sind keine 120 MB/s). Auch hier ist die Fehlertoleranz ein wichtiger Aspekt in der Berechnung, beim Verlust eines gesamten Kanals bleiben dem System nur 5 funktionierende Kanäle. Um sicherzustellen, dass die Leistungserwartungen bei einem Ausfall weiterhin erfüllt werden, sollte also der Gesamtdurchsatz für alle Speicherkanäle 100 MB/s nicht überschreiten (dies setzt voraus, dass Last und Fehlertoleranz gleichmäßig auf alle Kanäle verteilt sind). Dies in ein E/A-Profil umzuwandeln, hängt vom Verhalten der Anwendung ab. Im Fall der Active Directory Jet-E/A würde dies etwa 12.500 E/A-Vorgängen pro Sekunde (100 MB/s ÷ 8 KB pro E/A) entsprechen.
Als Nächstes muss anhand der Herstellerspezifikationen für die Controllermodule ermittelt werden, welchen Durchsatz jedes Modul unterstützen kann. In diesem Beispiel verfügt das SAN über zwei Controllermodule, die jeweils 7.500 E/A-Vorgänge unterstützen. Der Gesamtdurchsatz des Systems kann 15.000 IOPS betragen, wenn Redundanz nicht gewünscht ist. Bei der Berechnung des maximalen Durchsatzes bei einem Ausfall ist die Beschränkung der Durchsatz eines Controllers, d. h. 7.500 IOPS. Dieser Schwellenwert liegt deutlich unter dem Maximalwert von 12.500 IOPS (bei einer Blockgröße von 4 KB), der von allen Speicherkanälen unterstützt werden kann, und ist daher derzeit der Engpass in der Analyse. Aus Planungsgründen würde die gewünschte maximale E/A-Leistung 10.400 E/A-Vorgänge betragen.
Wenn die Daten das Controllermodul verlassen, werden sie über eine Fibre Channel-Verbindung mit einer Rate von 1 GB/s (oder 1 Gigabit pro Sekunde) übertragen. Um dies mit den anderen Metriken zu korrelieren, wird 1 GB/s in 128 MB/s (1 GB/s ÷ 8 Bits/Byte) umgewandelt. Da dies die Gesamtbandbreite aller Kanäle in der Speichereinheit (100 MB/s) übersteigt, stellt es keinen Engpass im System dar. Weil dies nur einer der beiden Kanäle ist (die zusätzliche Fibre Channel-Verbindung von 1 GB/s dient zur Redundanz), verfügt die verbleibende Verbindung außerdem bei einem Ausfall einer Verbindung weiterhin über genügend Kapazität, um alle benötigten Datenübertragungen zu verarbeiten.
Auf dem Weg zum Server werden die Daten höchstwahrscheinlich einen SAN-Switch durchqueren. Da der SAN-Switch die eingehende E/A-Anforderung verarbeiten und an den entsprechenden Port weiterleiten muss, gilt für den Switch eine Beschränkung der E/A-Menge, die verarbeitet werden kann. Dieser Grenzwert muss jedoch anhand der Herstellerspezifikationen bestimmt werden. Wenn beispielsweise zwei Switches vorhanden sind und jeder Switch 10.000 IOPS verarbeiten kann, beträgt der Gesamtdurchsatz 20.000 IOPS. Auch hier ist die Fehlertoleranz ein Problem. Wenn ein Switch ausfällt, beträgt der Gesamtdurchsatz des Systems 10.000 IOPS. Da die Auslastung im Normalbetrieb 80 % nicht überschreiten soll, sollte die Verwendung von höchstens 8.000 E/A-Vorgängen das Ziel sein.
Schließlich würde für den auf dem Server installierten HBA auch eine Beschränkung der E/A-Menge gelten, die er verarbeiten kann. Normalerweise wird aus Redundanzgründen ein zweiter HBA installiert, aber genau wie beim SAN-Switch entspricht bei der Berechnung der maximalen E/A-Menge, die verarbeitet werden kann, der Gesamtdurchsatz von N – 1 HBAs der maximalen Skalierbarkeit des Systems.
Überlegungen zur Zwischenspeicherung
Caches sind eine der Komponenten, die sich an jedem Punkt im Speichersystem erheblich auf die Gesamtleistung auswirken können. Detaillierte Analysen zu Zwischenspeicherungsalgorithmen sprengen den Rahmen dieses Artikels. Einige grundlegende Aussagen zum Zwischenspeichern auf Datenträgersubsystemen sollten jedoch erwähnt werden:
Das Zwischenspeichern verbessert die dauerhafte sequenzielle Schreib-E/A, da viele kleinere Schreibvorgänge in größeren E/A-Blöcke gepuffert und in weniger, aber größeren Blöcken in den Speicher ausgelagert werden können. Dies reduziert die Gesamtzahl der wahlfreien E/A- und sequenziellen E/A-Vorgänge, wodurch eine größere Ressourcenverfügbarkeit für andere E/A-Vorgänge ermöglicht wird.
Zwischenspeicherung verbessert den dauerhaften Schreib-E/A-Durchsatz des Speichersubsystems nicht. Die Schreibvorgänge können nur gepuffert werden, bis die Spindeln zum Commit der Daten verfügbar sind. Wenn alle verfügbaren E/A-Spindeln im Speichersubsystem über einen längeren Zeitraum gesättigt sind, füllt sich der Cache schließlich. Um den Cache zu leeren, müssen genügend Zeit zwischen Bursts oder zusätzliche Spindeln zugewiesen werden, um genügend E/A-Potenzial bereitzustellen, damit der Cache geleert werden kann.
Bei größeren Caches können nur mehr Daten gepuffert werden. Dies bedeutet, dass längere Sättigungszeiten berücksichtigt werden können.
In einem normal ausgeführten Speichersubsystem wird die Schreibleistung des Betriebssystems verbessert, da die Daten nur in den Cache geschrieben werden müssen. Sobald die zugrunde liegenden Medien mit E/A-Vorgängen gesättigt sind, füllt sich der Cache, und die Schreibleistung wird auf die Datenträgergeschwindigkeit zurückgesetzt.
Bei der Zwischenspeicherung von E/A-Lesevorgängen bietet der Cache die meisten Vorteile, wenn die Daten sequenziell auf der Festplatte gespeichert werden und der Cache Read-Ahead-Aktionen durchführen kann (er geht davon aus, dass der nächste Sektor die Daten enthält, die als nächstes angefordert werden).
Wenn die E/A-Lesevorgänge wahlfrei sind, ist es unwahrscheinlich, dass das Zwischenspeichern auf dem Laufwerkscontroller die Datenmenge erhöht, die vom Datenträger gelesen werden kann. Wenn die Cachegröße des Betriebssystems oder der Anwendung die hardwarebasierte Cachegröße überschreitet, gibt es keine Verbesserung.
Im Fall von Active Directory ist der Cache nur durch die RAM-Größe begrenzt.
Überlegungen zu SSD
SSDs sind völlig anders als spindelbasierte Festplatten. Die beiden wichtigsten Kriterien bleiben jedoch bestehen: „Wie viele IOPS können bewältigt werden?“ und „Wie hoch ist die Latenz für diese IOPS?“ Im Vergleich zu spindelbasierten Festplatten können SSDs höhere E/A-Mengen verarbeiten und geringere Latenzen aufweisen. Generell und zum Zeitpunkt des Verfassens dieses Artikels sind SSDs im Vergleich der Kosten pro Gigabyte zwar immer noch teuer, aber in Bezug auf die Kosten pro E/A-Vorgang sind sie sehr günstig und verdienen in Bezug auf die Speicherleistung große Beachtung.
Überlegungen:
- Sowohl die IOPS als auch die Latenzzeiten hängen stark vom Design des Herstellers ab, und in einigen Fällen wurde festgestellt, dass die Leistung schlechter ist als bei spindelbasierten Technologien. Kurz gesagt, es ist wichtiger, die Herstellerspezifikationen Laufwerk für Laufwerk zu überprüfen und zu validieren und keine Verallgemeinerungen anzustellen.
- IOPS-Typen können sehr unterschiedliche Zahlen aufweisen, je nachdem, ob es sich um Lese- oder Schreibvorgänge handelt. Im Allgemeinen überwiegend lesebasierte AD DS-Dienste sind weniger betroffen als einige andere Anwendungsszenarien.
- „Schreibbelastbarkeit“ – es herrscht die Vorstellung, dass SSD-Zellen irgendwann abgenutzt werden. Verschiedene Hersteller stellen sich dieser Herausforderung in unterschiedlicher Weise. Zumindest für das Datenbanklaufwerk ermöglicht das überwiegende Lese-E/A-Profil, die Bedeutung dieser Bedenken zu verharmlosen, da die Daten nicht sehr flüchtig sind.
Zusammenfassung
Stellen Sie sich beim Nachdenken über den Speicher Sanitärinstallationen im Haushalt vor. Denken Sie in Verbindung mit den IOPS der Medien, auf denen die Daten gespeichert sind, an den Hauptabfluss im Haushalt. Wenn er verstopft ist oder unterdimensioniert (er bewältigt die Abwassermenge nicht), kommt das Wasser in allen Abflüssen im Haushalt wieder hoch, wenn zu viel Wasser verbraucht wird (zu viele Gäste). Dies entspricht perfekt einer freigegebenen Umgebung, in der mindestens ein System gemeinsam genutzten Speicher auf einem SAN/NAS/iSCSI mit denselben zugrunde liegenden Medien nutzt. Die verschiedenen Szenarien können mit verschiedenen Ansätzen gelöst werden:
- Ein verstopfter oder unterdimensionierter Abfluss erfordert einen vollständigen Ersatz und eine Korrektur. Dies wäre vergleichbar mit dem Hinzufügen neuer Hardware oder der Neuverteilung der Systeme, die den freigegebenen Speicher in der gesamten Infrastruktur verwenden.
- Ein „verstopftes“ Rohr erfordert in der Regel die Identifizierung eines oder mehrerer auslösender Probleme und deren Beseitigung. In einem Speicherszenario könnte es sich dabei um die Ausführung von Sicherungen auf Speicher- oder Systemebene, synchronisierten Antiviren-Scans auf allen Servern und synchronisierter Defragmentierungssoftware in Spitzenzeiten handeln.
Bei jedem Abflussdesign werden mehrere Abflüsse in den Hauptabfluss eingespeist. Wenn einer dieser Abflüsse oder eine Verzweigung verstopft wird, staut sich nur das auf, was sich hinter dieser Verzweigung befindet. In einem Speicherszenario entspräche dies einem überlasteten Switch (SAN/NAS/iSCSI-Szenario), Treiberkompatibilitätsproblemen (falsche Kombination von Treiber/HBA-Firmware/storport.sys) oder Sicherung/Antiviren-Scan/Defragmentierung. Um zu ermitteln, ob das Speicher-„Rohr“ groß genug ist, müssen IOPS und E/A-Menge gemessen werden. Addieren Sie sie an jeder Verzweigung, um einen ausreichenden „Rohrdurchmesser“ zu gewährleisten.
Anhang D – Erläuterung zur Speicherproblembehandlung – Umgebungen, in denen die Bereitstellung einer mindestens der Datenbankgröße entsprechenden RAM-Größe keine praktikable Option ist
Es ist hilfreich, den Sinn dieser Empfehlungen zu verstehen, damit die Änderungen in der Speichertechnologie berücksichtigt werden können. Diese Empfehlungen gibt es aus zwei Gründen. Der erste ist die Isolation von E/A, sodass Leistungsprobleme (d. h. Auslagern) auf der Betriebssystemspindel keine Auswirkungen auf die Leistung der Datenbank- und E/A-Profile haben. Der zweite ist, dass Protokolldateien für AD DS (und die meisten Datenbanken) sequenziell sind, und spindelbasierte Festplatten und Caches im Vergleich zu den mehr zufälligen E/A-Mustern des Betriebssystems und fast rein zufälligen E/A-Mustern des AD DS-Datenbanklaufwerks einen enormen Leistungsvorteil haben, wenn sie mit sequenzieller E/A verwendet werden. Durch Isolieren der sequenziellen E/A auf einem separaten physischen Laufwerk kann der Durchsatz erhöht werden. Die Herausforderung der heutigen Speicheroptionen besteht darin, dass die grundlegenden Annahmen, die hinter diesen Empfehlungen stehen, nicht mehr wahr sind. In vielen virtualisierten Speicherszenarien, z. B. iSCSI-, SAN-, NAS- und Virtual Disk-Imagedateien, werden die zugrunde liegenden Speichermedien auf mehreren Hosts gemeinsam genutzt, sodass sowohl die Aspekte „Isolation von E/A“ als auch „Optimierung der sequenziellen E/A“ vollständig negiert werden. Tatsächlich sorgen diese Szenarien für eine zusätzliche Komplexitätsebene, da andere Hosts, die auf die freigegebenen Medien zugreifen, die Fähigkeit zur Reaktion auf den Domänencontroller beeinträchtigen können.
Bei der Planung der Speicherleistung müssen drei Kategorien berücksichtigt werden: Kalter Cachezustand, aufgewärmter Cachezustand und Sicherung/Wiederherstellung. Der kalte Cachezustand tritt in Szenarien auf, wenn z. B. der Domänencontroller anfänglich neu gestartet wird, oder der Active Directory-Dienst neu gestartet wird, und keine Active Directory-Daten im RAM vorhanden sind. Im Status „warmer Cache“ ist der Domänencontroller stabil, und die Datenbank wird zwischengespeichert. Dies muss beachtet werden, da es zu sehr unterschiedlichen Leistungsprofilen führt, und genügend RAM für den Cache der gesamten Datenbank trägt nicht zur Leistung bei, wenn der Cache kalt ist. Das Leistungsdesign für diese beiden Szenarien lässt sich mit der folgenden Analogie veranschaulichen: Die Erwärmung des kalten Caches ist ein „Sprint“, der Betrieb eines Servers mit einem warmen Cache ist ein „Marathon“.
Sowohl für das Szenario „kalter Cache“ als auch „warmer Cache“ stellt sich die Frage, wie schnell der Speicher die Daten vom Datenträger in den Arbeitsspeicher verschieben kann. Das Erwärmen des Caches ist ein Szenario, in dem sich die Leistung im Laufe der Zeit verbessert, wenn mehr Abfragen Daten wiederverwenden, die Cachetrefferrate zunimmt und die Notwendigkeit, auf den Datenträger wechseln zu müssen, abnimmt. Dadurch verringern sich die negativen Auswirkungen auf die Leistung durch Wechsel zum Datenträger. Jede Beeinträchtigung der Leistung ist nur vorübergehend, während darauf gewartet wird, dass sich der Cache erwärmt und auf die maximale, systemabhängige zulässige Größe anwächst. Die Konversation lässt sich darauf reduzieren, wie schnell die Daten von der Festplatte geholt werden können, und ist ein einfaches Maß für die IOPS, die Active Directory zur Verfügung stehen, was davon abhängt, wieviel IOPS der zugrunde liegende Speicher verfügbar macht. Aus planungstechnischer Sicht gibt es keine allgemeinen Empfehlungen, da die Erwärmung des Caches und Sicherungs-/Wiederherstellungsszenarien auf einer außergewöhnlichen Basis erfolgen, normalerweise außerhalb der Geschäftszeiten auftreten und subjektiv für die Auslastung des Domänencontrollers sind, es sei denn, diese Aktivitäten werden für Zeiträume außerhalb der Spitzenzeiten geplant.
AD DS führt in den meisten Szenarien überwiegend E/A-Lesevorgänge aus, in der Regel sind es zu 90 % Lese- und zu 10 %-Schreibzugriffe. E/A-Lesevorgänge sind häufig der Engpass für die Benutzererfahrung, und bei E/A-Schreibvorgängen wird die Schreibleistung beeinträchtigt. Da die E/A auf NTDS.dit überwiegend wahlfrei erfolgt, bieten Caches in der Regel nur minimale Vorteile für die Lese-E/A. Umso wichtiger ist es, den Speicher für das Lese-E/A-Profil richtig zu konfigurieren.
Bei normalen Betriebsbedingungen besteht das Speicherplanungsziel in der Minimierung der Wartezeiten, bis der Datenträger auf eine Anforderung von AD DS reagiert. Dies bedeutet im Wesentlichen, dass die Anzahl der ausstehenden E/A-Vorgänge kleiner oder gleich der Anzahl der Pfade zum Datenträger ist. Es gibt verschiedene Formen, dies zu messen. In einem Leistungsüberwachungsszenario wird allgemein empfohlen, dass „Logischer Datenträger(<NTDS-Datenbanklaufwerk>)\Mittlere Sek./Lesevorgänge“ weniger als 20 ms beträgt. Der gewünschte Betriebsschwellenwert muss je nach Speichertyp wesentlich niedriger sein, vorzugsweise so nahe wie möglich an der Geschwindigkeit des Speichers, im Bereich von 2 bis 6 Millisekunden (0,002 bis 0,006 Sekunden).
Beispiel:
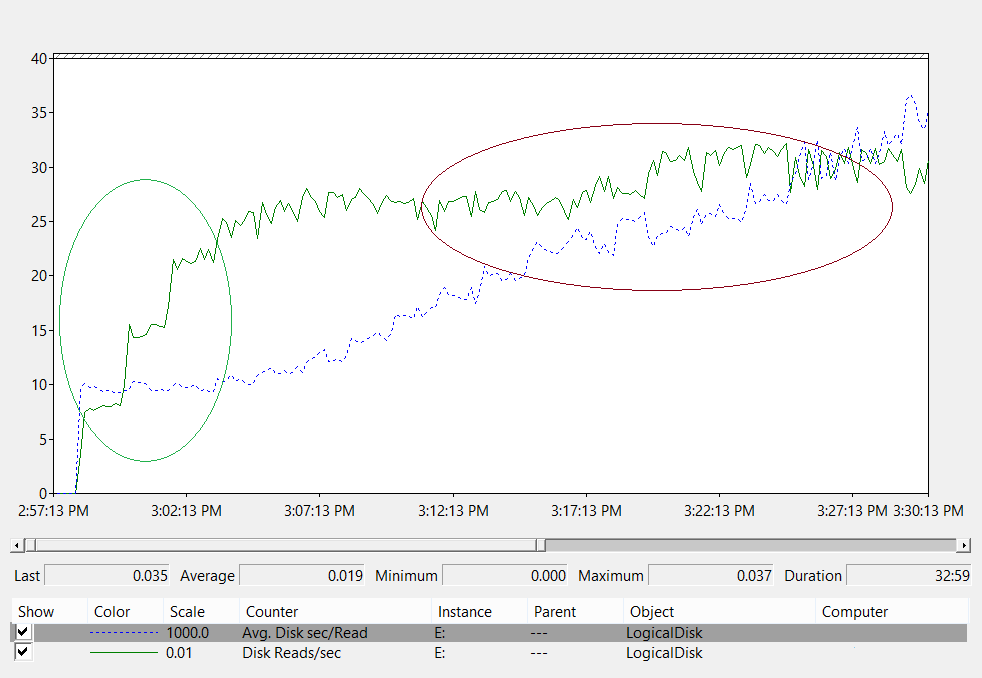
Analyse des Diagramms:
- Grünes Oval links – Die Latenz bleibt bei 10 ms konsistent. Die Last steigt von 800 IOPS auf 2400 IOPS. Dies ist der absolute Grund dafür, wie schnell eine E/A-Anforderung vom zugrunde liegenden Speicher verarbeitet werden kann. Dies unterliegt den Besonderheiten der Speicherlösung.
- Burgunderrotes Oval auf der rechten Seite – Der Durchsatz bleibt vom Verlassen des grünen Kreises bis zum Ende der Datensammlung flach, während die Latenz weiter zunimmt. Dies zeigt, dass die Anforderungen umso länger in der Warteschlange stehen und darauf warten, an das Speichersubsystem weitergeleitet zu werden, wenn das Anforderungsvolumen die physischen Einschränkungen des zugrundeliegenden Speichers überschreitet.
Anwenden dieses Wissens:
- Auswirkung auf Benutzer*innen, die die Mitgliedschaft einer großen Gruppe abfragen – Wenn dies das Lesen von 1 MB an Daten vom Datenträger erfordert, können E/A-Menge und Dauer wie folgt ausgewertet werden:
- Active Directory-Datenbankseiten sind 8 KB groß.
- Es müssen mindestens 128 Seiten vom Datenträger eingelesen werden.
- Angenommen, dass nichts zwischengespeichert wird, dauert es am Ausgangspunkt (10 ms) mindestens 1,28 Sekunden, um die Daten von der Festplatte zu laden, um sie an den Client zurückzugeben. Bei 20 ms, wo der Datendurchsatz auf dem Speicher längst am Maximum angelangt ist und auch dem empfohlenen Maximum entspricht, dauert es 2,5 Sekunden, die Daten von der Festplatte zu holen, um sie Endbenutzer*innen zurückzugeben.
- Mit welcher Geschwindigkeit wird der Cache aufgewärmt – Angenommen, dass die Clientlast den Durchsatz für dieses Speicherbeispiel maximiert, wird der Cache mit einer Rate von 2400 IOPS × 8 KB pro E/A aufgewärmt. Alternativ ca. 20 MB/s pro Sekunde, wobei alle 53 Sekunden etwa 1 GB der Datenbank in den RAM geladen werden.
Hinweis
Es ist für kurze Zeiträume normal, dass die Wartezeiten steigen, wenn Komponenten aggressiv vom Datenträger lesen oder darauf schreiben, z. B. wenn das System gesichert wird oder AD DS die Garbage Collection ausführt. Ergänzend zu den Berechnungen sollte zusätzlicher Spielraum bereitgestellt werden, um diese periodischen Ereignisse zu berücksichtigen. Ziel ist es, genügend Durchsatz für diese Szenarien bereitzustellen, ohne die normale Funktion zu beeinträchtigen.
Wie zu sehen ist, gibt es eine auf dem Speicherentwurf basierende physische Grenze, um zu bestimmen, wie schnell sich der Cache möglicherweise aufwärmen kann. Was den Cache aufwärmt, sind eingehende Clientanforderungen bis zu der Rate, die der zugrunde liegende Speicher bereitstellen kann. Wenn Sie Skripts ausführen, um den Cache während der Spitzenzeiten „vorzuwärmen“, entsteht damit eine Konkurrenz zur durch echte Clientanforderungen verursachten Last. Dies kann sich negativ auf die Bereitstellung von Daten auswirken, die Clients zuerst benötigen, da es standardmäßig einen Wettbewerb um knappe Datenträgerressourcen hervorruft, da künstliche Versuche, den Cache zu erwärmen, Daten laden, die für die Clients, die den Domänencontroller kontaktieren, nicht relevant sind.