Aufbereiten der Daten
In der vorherigen Phase dieses Tutorials haben wir PyTorch auf Ihrem Computer installiert. Nun verwenden wir es, um unseren Code mit den Daten einzurichten, die wir für unser Modell verwenden.
Öffnen Sie ein neues Projekt in Visual Studio.
- Öffnen Sie Visual Studio, und wählen Sie
create a new projectaus.

- Geben Sie in der Suchleiste
Pythonein, und wählen SiePython Applicationals Projektvorlage aus.

- Gehen Sie im Konfigurationsfenster folgendermaßen vor:
- Geben Sie dem Projekt einen Namen. Hier nennen wir es PyTorchTraining.
- Wählen Sie den Speicherort Ihres Projekts aus.
- Wenn Sie VS 2019 verwenden, stellen Sie sicher, dass
Create directory for solutionaktiviert ist. - Wenn Sie VS 2017 verwenden, stellen Sie sicher, dass
Place solution and project in the same directorydeaktiviert ist.

Drücken Sie create, um das Projekt zu erstellen.
Erstellen eines Python-Interpreters
Nun müssen Sie einen neuen Python-Interpreter definieren. Dies muss das PyTorch-Paket enthalten, das Sie vor Kurzem installiert haben.
- Navigieren Sie zur Interpreterauswahl, und wählen Sie
Add environmentaus:
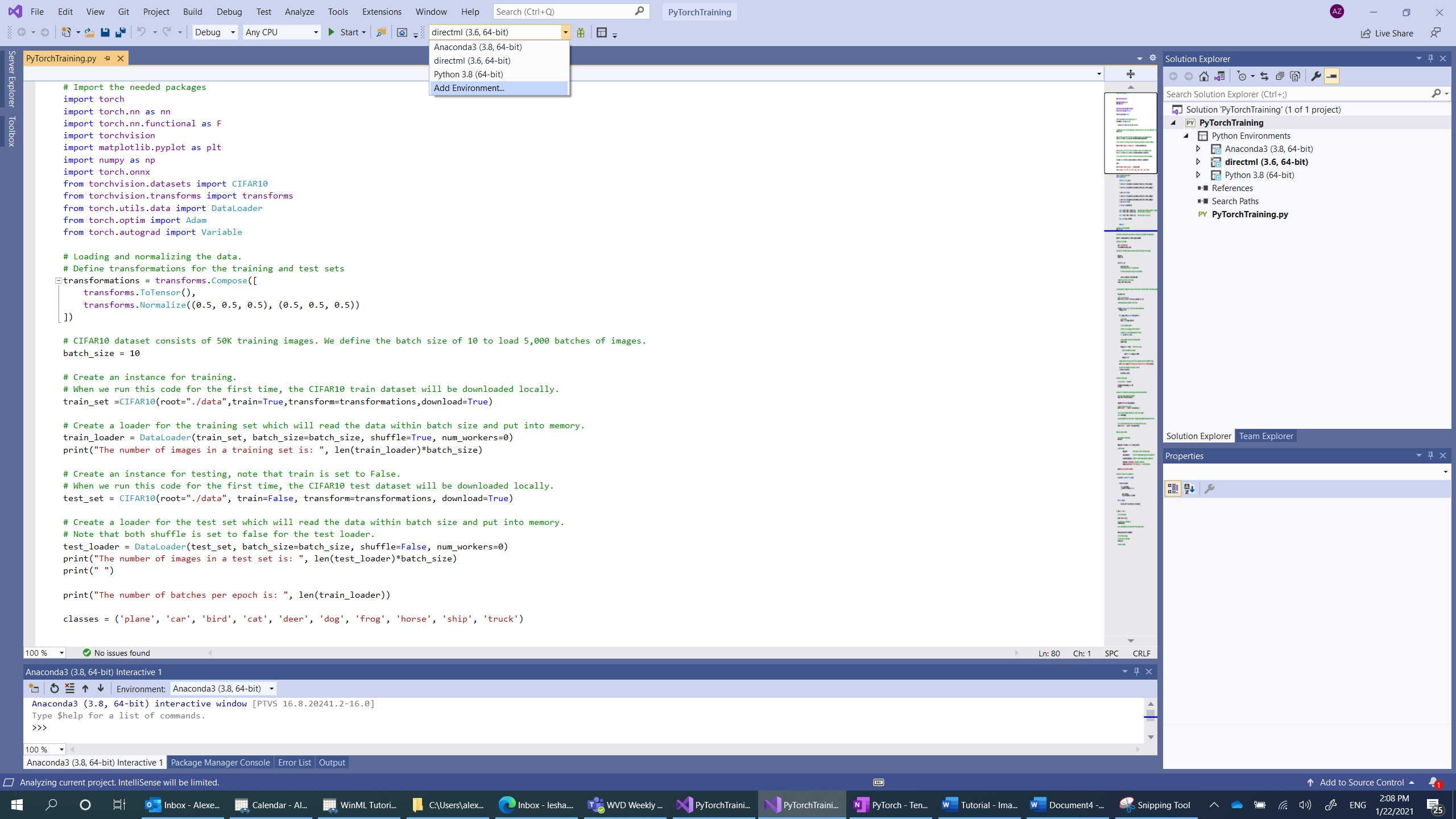
- Wählen Sie im Fenster
Add environmentdie OptionExisting environmentund dannAnaconda3 (3.6, 64-bit)aus. Dies bezieht das PyTorch-Paket mit ein.

Geben Sie den folgenden Code in die Datei PyTorchTraining.py ein, um den neuen Python-Interpreter und das PyTorch-Paket zu testen:
from __future__ import print_function
import torch
x=torch.rand(2, 3)
print(x)
Die Ausgabe sollte ein zufälliger 5x3-Tensor ähnlich dem folgenden sein.

Hinweis
Möchten Sie mehr erfahren? Besuchen Sie die offizielle PyTorch-Website.
Laden des DataSets
Sie verwenden die PyTorch-Klasse torchvision, um die Daten zu laden.
Die Torchvision-Bibliothek enthält mehrere beliebte Datasets wie Imagenet, CIFAR10, MNIST usw., Modellarchitekturen und allgemeine Bildtransformationen für das maschinelle Sehen. Dadurch gestaltet sich das Laden von Daten in PyTorch recht einfach.
CIFAR10
Hier verwenden wir das CIFAR10-Dataset, um das Bildklassifizierungsmodell zu erstellen und zu trainieren. CIFAR10 ist ein weit verbreitetes Dataset für die Machine Learning-Forschung. Es besteht aus 50.000 Trainingsbildern und 10.000 Testbildern. Alle besitzen die Größe 3 x 32 x 32, d. h. 3-Kanal-Farbbilder mit einer Größe von 32 x 32 Pixeln.
Die Bilder werden in zehn Klassen unterteilt: „Flugzeug“ (0), „Automobil“ (1), „Vogel“ (2), „Katze“ (3), „Reh“ (4), „Hund“ (5), „Frosch“ (6), „Pferd“ (7), „Schiff“ (8), „LKW“ (9).
Sie führen drei Schritte aus, um das CIFAR10-Dataset in PyTorch zu laden und zu lesen:
- Definieren Sie Transformationen, die auf das Bild angewendet werden: Um das Modell zu trainieren, müssen Sie die Bilder in Tensors im normalisierten Bereich [-1,1] transformieren.
- Erstellen Sie eine Instanz des verfügbaren Datasets, und laden Sie das Dataset: Zum Laden der Daten verwenden Sie die
torch.utils.data.Dataset-Klasse, eine abstrakte Klasse zum Darstellen eines Datasets. Das Dataset wird nur lokal heruntergeladen, wenn Sie den Code zum ersten Mal ausführen. - Greifen Sie mit DataLoader auf die Daten zu. Um Zugriff auf die Daten zu erhalten und die Daten im Arbeitsspeicher abzulegen, verwenden Sie die
torch.utils.data.DataLoader-Klasse. DataLoader in PyTorch umschließt ein Dataset und bietet Zugriff auf die zugrunde liegenden Daten. Dieser Wrapper hält Batches von Bildern pro definierter Batchgröße bereit.
Sie wiederholen diese drei Schritte für Trainings- und Testsätze.
- Öffnen Sie
PyTorchTraining.py filein Visual Studio, und fügen Sie den folgenden Code hinzu. Damit werden die drei obigen Schritte für die Trainings- und Testdatasets aus dem CIFAR10-Dataset verarbeitet.
from torchvision.datasets import CIFAR10
from torchvision.transforms import transforms
from torch.utils.data import DataLoader
# Loading and normalizing the data.
# Define transformations for the training and test sets
transformations = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# CIFAR10 dataset consists of 50K training images. We define the batch size of 10 to load 5,000 batches of images.
batch_size = 10
number_of_labels = 10
# Create an instance for training.
# When we run this code for the first time, the CIFAR10 train dataset will be downloaded locally.
train_set =CIFAR10(root="./data",train=True,transform=transformations,download=True)
# Create a loader for the training set which will read the data within batch size and put into memory.
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True, num_workers=0)
print("The number of images in a training set is: ", len(train_loader)*batch_size)
# Create an instance for testing, note that train is set to False.
# When we run this code for the first time, the CIFAR10 test dataset will be downloaded locally.
test_set = CIFAR10(root="./data", train=False, transform=transformations, download=True)
# Create a loader for the test set which will read the data within batch size and put into memory.
# Note that each shuffle is set to false for the test loader.
test_loader = DataLoader(test_set, batch_size=batch_size, shuffle=False, num_workers=0)
print("The number of images in a test set is: ", len(test_loader)*batch_size)
print("The number of batches per epoch is: ", len(train_loader))
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
Wenn Sie diesen Code zum ersten Mal ausführen, wird das CIFAR10-Dataset auf Ihr Gerät heruntergeladen.

Nächste Schritte
Wenn die Daten einsatzbereit sind, ist es an der Zeit, unser PyTorch-Modell zu trainieren.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für