Erkennungsgitterstruktur
Erkennungsmodule, die für die Verwendung mit Windows Vista und Windows XP Tablet PC Edition erstellt wurden, verwenden eine Reihe von Strukturen, von denen jede als Gitter bezeichnet wird, um Erkennungsergebnisse an Tablet-PC-Plattformbibliotheken zurückzugeben. Die Tablet PC-Plattform kopiert dann die Informationen in diesen Strukturen in das IInkRecognitionResult-Objekt , die IInkRecognitionAlternates-Auflistung und das IInkRecognitionAlternate-Objekt .
Ein Zeiger auf das Gitter sollte von der Erkennung zurückgegeben werden, wenn die Plattform die GetLatticePtr-Funktion für das HRECOCONTEXT-Handle aufruft.
In diesem Abschnitt wird die Gitterstruktur ausführlich beschrieben. Eine Übersicht über Erkennungen und verwandte Konzepte finden Sie unter Informationen zur Handschrifterkennung.
Die Notwendigkeit eines Gitters
Eine Erkennung kann mehrere Möglichkeiten finden, um eine Reihe von Freihandstrichen in Erkennungssegmente zu unterteilen. Was die Erkennung als Erkennungssegment verwendet, hängt vom Typ der Erkennung ab. Englische Spracherkennungen verwenden in der Regel Wörter als Erkennungssegment. Andere Erkennungsmodule können Zeichen, Formen oder Gesten als Erkennungssegment verwenden. Die Flexibilität der Gitterstrukturen ermöglicht eine logische Verwaltung der großen Anzahl von Erkennungsergebnissen, die in komplexen Beziehungen kombiniert werden können.
Intern verwenden Erkennungsmodule ein Gitter, um grundlegende Erkennungseinheiten für ein bestimmtes Stück Freihand aufzunehmen. Das Gitter enthält auch die Bewertung oder das Konfidenzniveau des kombinierten Ergebnisses. Darüber hinaus speichert das Gitter die Zuordnung von Segmenten zu den ursprünglichen Freihandstrichen.
Die Gitterstrukturen werden in der Headerdatei RecTypes.h definiert. Die Gitterstrukturen umfassen die folgenden Strukturen:
Gitterkomponenten
In den folgenden Beispielen werden die Striche für das Wort "zusammen" verwendet, wie in der folgenden Abbildung dargestellt. In den Beispielen werden die Segmente als ein oder mehrere Wörter ausgewertet. Die Zahlen stellen die einzelnen Striche im ausgewerteten Segment dar. Beachten Sie, dass jedes t-Zeichen zwei Striche enthält.
Ein Gitter besteht aus einer oder mehreren Spalten, eine für jedes Segment. Jede Spalte enthält wiederum ein oder mehrere Elemente. Ein Element enthält eine separate Erkennungs-Alternative. Weitere Informationen zu Spalten finden Sie in der RECO_LATTICE_COLUMN-Struktur . Weitere Informationen zu Elementen finden Sie in der RECO_LATTICE_ELEMENT-Struktur .
Die Erkennung gibt möglicherweise ein einzelnes Segment zurück, wenn das im vorherigen Beispiel gezeigte Freihandbeispiel ausgewertet wird. In diesem Fall enthält das Gitter eine einzelne Spalte mit einem einzelnen Element.
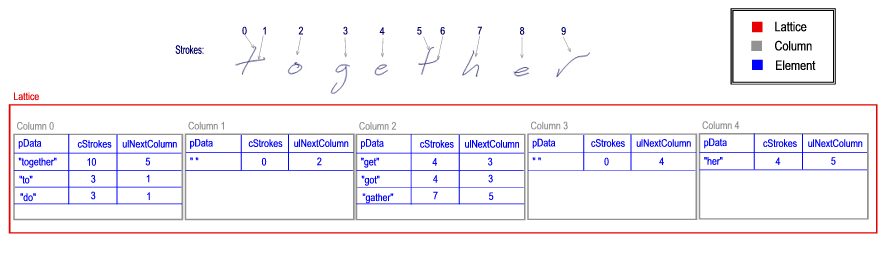
Ein komplexeres Beispiel wird angezeigt, wenn die Erkennung das Freihandbeispiel auswertet und für jedes Segment mehrere Segmente und mehrere Alternativen enthält.
Die Anzahl der Alternativen zur Erkennung kann auch bei einer kleinen Freihandprobe erschreckend sein. Beispielsweise kann "t o g e t h e r" die folgenden Ergebnisse ergeben:
- "to get her" (plus Alternative für jedes Wort)
- "to gather" (plus Alternative für jedes Wort)
- "to got her" (plus Alternative für jedes Wort)
- "zusammen" (plus Alternativen für das Wort)
In diesem Fall kann eine Erkennung die folgende Gitterstruktur erstellen.
Hinweis
Jede Spalte verwendet dieselbe Strichreihenfolge, da sie alle auf dieselbe InkStrokes-Auflistung verweisen.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für