How to use Hive metastore with Apache Spark™ cluster
Important
This feature is currently in preview. The Supplemental Terms of Use for Microsoft Azure Previews include more legal terms that apply to Azure features that are in beta, in preview, or otherwise not yet released into general availability. For information about this specific preview, see Azure HDInsight on AKS preview information. For questions or feature suggestions, please submit a request on AskHDInsight with the details and follow us for more updates on Azure HDInsight Community.
It's essential to share the data and metastore across multiple services. One of the commonly used metastore in HIVE metastore. HDInsight on AKS allows users to connect to external metastore. This step enables the HDInsight users to seamlessly connect to other services in the ecosystem.
Azure HDInsight on AKS supports custom meta stores, which are recommended for production clusters. The key steps involved are
- Create Azure SQL database
- Create a key vault for storing the credentials
- Configure Metastore while you create a HDInsight on AKS cluster with Apache Spark™
- Operate on External Metastore (Shows databases and do a select limit 1).
While you create the cluster, HDInsight service needs to connect to the external metastore and verify your credentials.
Create Azure SQL database
Create or have an existing Azure SQL Database before setting up a custom Hive metastore for an HDInsight cluster.
Note
Currently, we support only Azure SQL Database for HIVE metastore. Due to Hive limitation, "-" (hyphen) character in metastore database name is not supported.
Create a key vault for storing the credentials
Create an Azure Key Vault.
The purpose of the Key Vault is to allow you to store the SQL Server admin password set during SQL database creation. HDInsight on AKS platform doesn’t deal with the credential directly. Hence, it's necessary to store your important credentials in Azure Key Vault. Learn the steps to create an Azure Key Vault.
Post the creation of Azure Key Vault assign the following roles
Object Role Remarks User Assigned Managed Identity(the same UAMI as used by the HDInsight cluster) Key Vault Secrets User Learn how to Assign role to UAMI User(who creates secret in Azure Key Vault) Key Vault Administrator Learn how to Assign role to user. Note
Without this role, user can't create a secret.
-
This step allows you to keep your SQL server admin password as a secret in Azure Key Vault. Add your password(same password as provided in the SQL DB for admin) in the “Value” field while adding a secret.
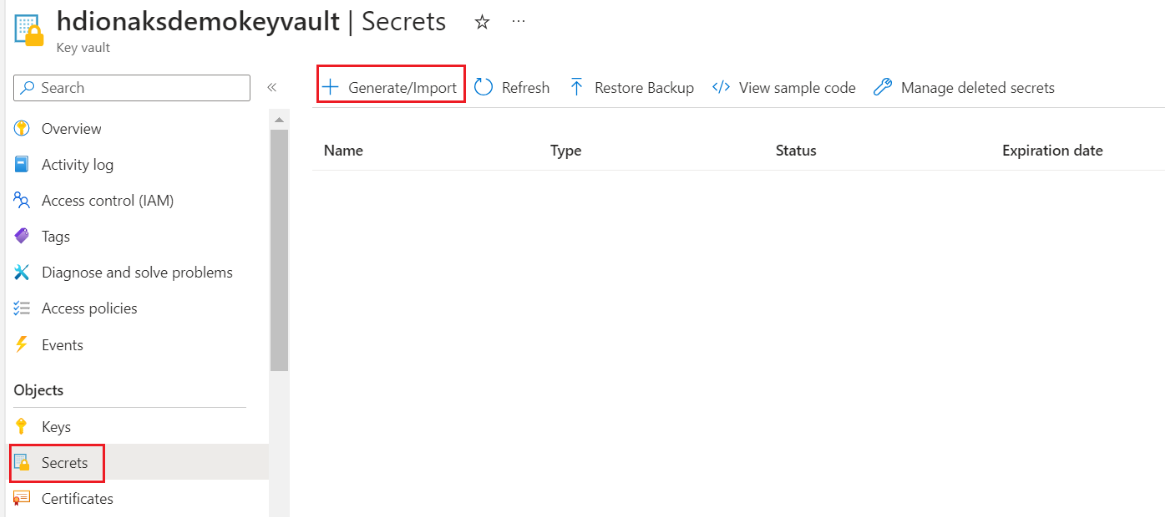
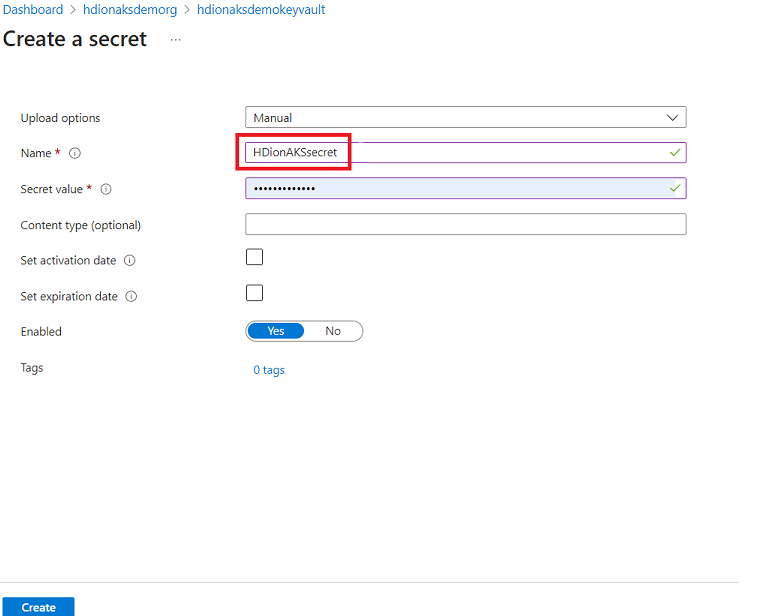
Note
Make sure to note the secret name, as you'll need this during cluster creation.


Configure Metastore while you create a HDInsight Spark cluster
Navigate to HDInsight on AKS Cluster pool to create clusters.
Enable the toggle button to add external hive metastore and fill in the following details.
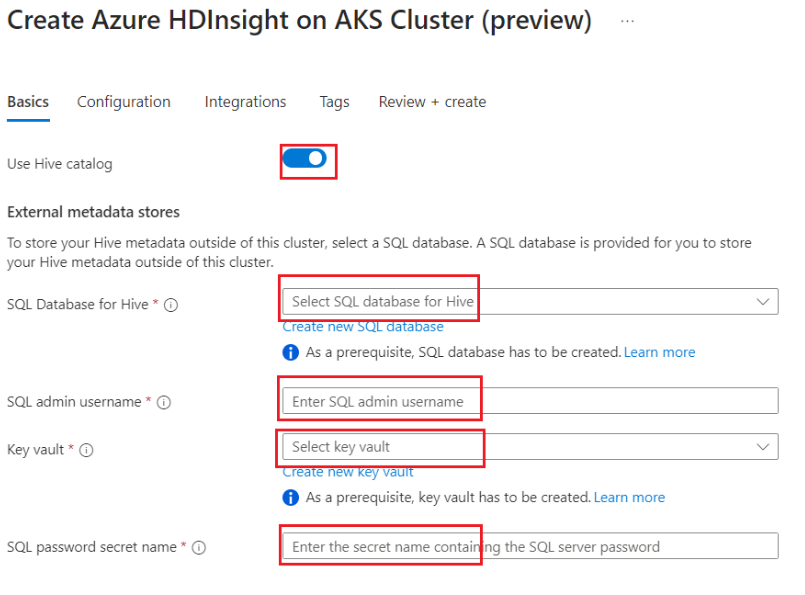
The rest of the details are to be filled in as per the cluster creation rules for Apache Spark cluster in HDInsight on AKS.
Click on Review and Create.

Note
- The lifecycle of the metastore isn't tied to a clusters lifecycle, so you can create and delete clusters without losing metadata. Metadata such as your Hive schemas persist even after you delete and re-create the HDInsight cluster.
- A custom metastore lets you attach multiple clusters and cluster types to that metastore.



Operate on External Metastore
Create a table
>> spark.sql("CREATE TABLE sampleTable (number Int, word String)")
Add data on the table
>> spark.sql("INSERT INTO sampleTable VALUES (123, \"HDIonAKS\")");\
Read the table
>> spark.sql("select * from sampleTable").show()



Reference
- Apache, Apache Spark, Spark, and associated open source project names are trademarks of the Apache Software Foundation (ASF).
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for