SQL Server compilation Gateways and 'RESOURCE_SEMAPHORE_QUERY_COMPILE'
Hi everyone,
In this post, we’ll spend some time exploring the SQL Server mechanism that controls the ongoing compilations and their memory usage, and understand its purpose and consequences on the incoming workload.
Chances are, you ended-up here because of a search against 'RESOURCE_SEMAPHORE_QUERY_COMPILE' or ‘Gateway’ :
· 'RESOURCE_SEMAPHORE_QUERY_COMPILE' will be a waittype observed in SQL Server’s DMV like sys.dm_os_waiting_tasks , at a time when some of your queries are seeing a longer than usual overall execution time.
· Gateway is a term used in DBCC MemoryStatus output in section ‘Optimization’.
How does it all relate, together with slower than usual queries ?
First let’s start with the some existing documentation : the KB 907877 ‘How to use the DBCC MEMORYSTATUS command to monitor memory usage on SQL Server 2005’.
We know it’s the ‘Optimization’ block we want. Extract :
Queries are submitted to the server for compilation. The compilation process includes parsing, algebraization, and optimization. Queries are classified based on the amount of memory that each query will consume during the compilation process.Note This amount does not include the memory that is required to run the query. When a query starts, there is no limit on how many queries can be compiled. As the memory consumption increases and reaches a threshold, the query must pass a gateway to continue. There is a progressively decreasing limit of simultaneously compiled queries after each gateway. The size of each gateway depends on the platform and the load. Gateway sizes are chosen to maximize scalability and throughput.If the query cannot pass a gateway, the query will wait until memory is available. Or, the query will return a time-out error (Error 8628). Additionally, the query may not acquire a gateway if the user cancels the query or if a deadlock is detected. If a query passes several gateways, the query does not release the smaller gateways until the compilation process has completed. This behavior lets only a few memory-intensive compilations occur at the same time. Additionally, this behavior maximizes throughput for smaller queries. |
Most of the information is already in there. We’ll just elaborate some more where needed J
My fellow Michael Garstin also investigated this topic from the Sharepoint point of view using his SQL Server background here.
Purpose :
The whole gateway architecture is a way for SQL Server to keep memory usage for the compilation of incoming queries under control. This includes
· avoiding out-of-memory conditions
· Preventing a few very complex queries from eating up all memory and impact the whole server across the board because they compile at the same time
· Making sure that compiling complex queries does not prevent SQL Server from compiling small ‘standard’ queries.
· Serializing very large consumers to make sure each one succeeds in turn as opposed as all of them starting together and failing because of lack of memory to complete.
You can think of it as a “Quality of Service” for compilation.
Implementation :
· The resource that will drive the compilation throttling is the memory.
o But since we may ultimately limit how many complex queries compile at a given time, this will also in turn limit the usage of other resource, mainly CPU.
o As the KB mentions, we’re talking compile-time memory here, not execution-time memory.
· Based on how much memory is used by the query for its ongoing compilation, the query will need to gain access to gateways :
o There are 3 gateways : small, medium and large.
o Each gateway is associated to a memory threshold.
o Each gateway only allows a given number of queries to compile at a given time (see table below).
o A query asking for a gateway will attempt to grab a 'RESOURCE_SEMAPHORE_QUERY_COMPILE' semaphore.
§ If it asks for a gateway but gateway is full, it will therefore wait for that semaphore, and this reflects in DMVs.
§ There’s only one waittype for all 3 gateways
o The memory consumed by compilation is tracked and updated throughout the compilation duration and gateway requests subsequently occur when applicable.
§ When requesting a larger gateway, lower gateways slots (semaphores) are kept.
o The memory threshold is static based on architecture for the small gateway, and is fully dynamic for medium and large (ie. value depends on current system state and change over time).
o Specific timeouts will prevent queries from waiting forever for a 'RESOURCE_SEMAPHORE_QUERY_COMPILE' semaphore.
o Obviously when a query compilation finishes the gateway semaphores it owns are released.
A picture is worth a thousand words, here’s the ‘vision’ I offer for the concept :
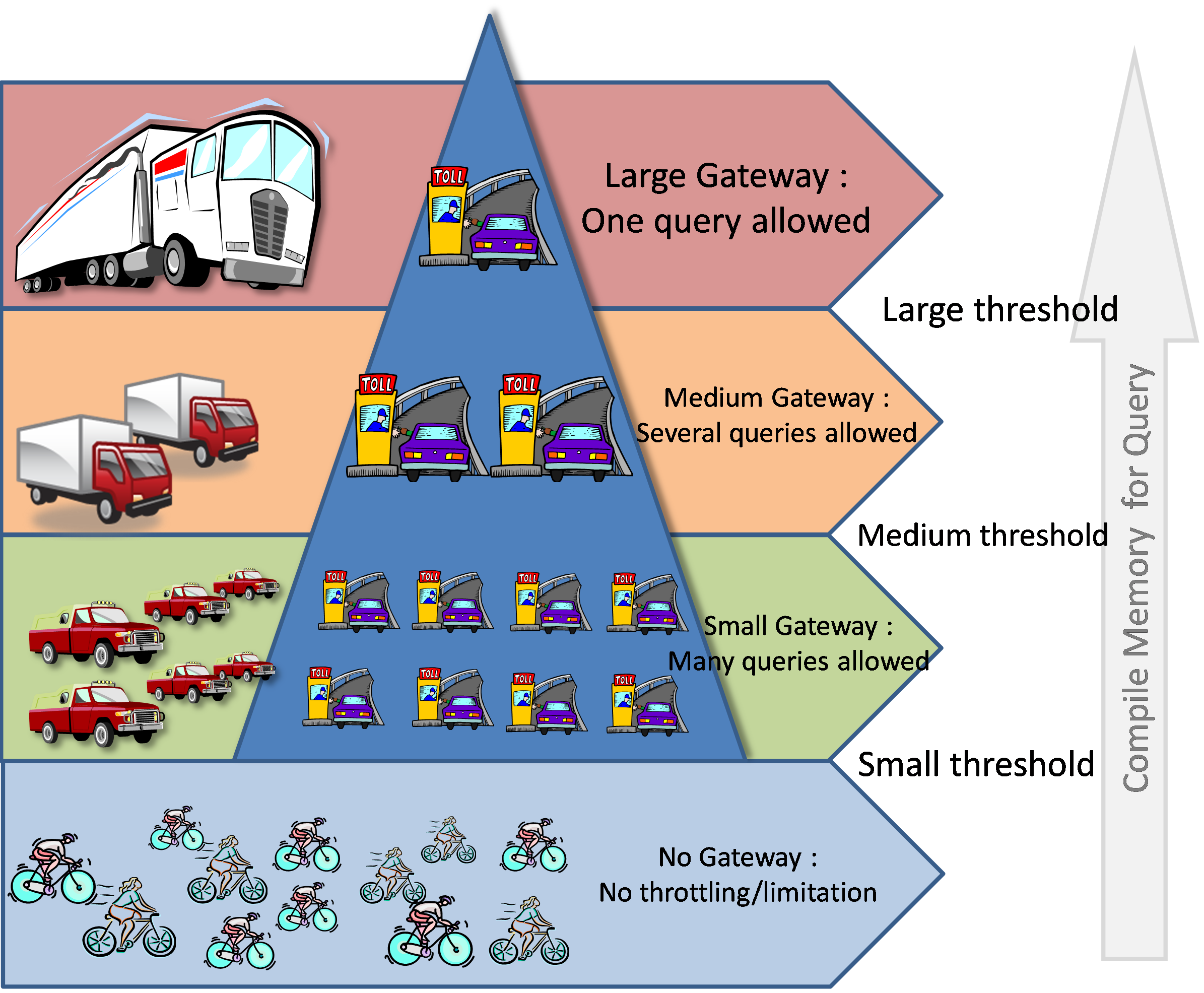
Now that we have this picture in mind, let’s look at numbers :
Gateway Type |
Small |
Medium |
Large |
Number of simultaneous query allowed. |
4 x Number of logical CPUs allocated to SQL Server. |
Number of logical CPUs allocated to SQL Server. |
1 |
Because the medium and large thresholds are dynamic (in a nutshell, they get lower when server load increases), that means that there will be little throttling on a lightly loaded system, therefore we maximize resource usage (no “hardcoded” thresholds). That also means that the performance of a given set of queries (with big compilation memory footprint) might vary based on concurrent workload (the switch to large gateway means full serialization of selected queries, which can certainly have some impact...).
Let’s map this to DBCC MEMORYSTATYS output :
Medium Gateway (internal) Value --------------------------------------- ----------- Configured Units 1 Available Units 1 Acquires 0 Waiters 0 Threshold Factor 12 Threshold -1 |
=> total number of slots for gateway => gateways slots available/free => gateways slots in use
=> This is the memory value in byte that is the threshold for a compiling query to become candidate for current gateway. Value (-1) is returned when no activity is taking place at gateway just below current level, as in that case the value is irrelevant : no use for n-level threshold when there’s no (n-1)level candidates.
|
Now let’s use some real example (2 logical CPU server):
Optimization Queue (default) Value ---------------------------------------- ----------- Overall Memory 576012288 Target Memory 436043776 Last Notification 0 Timeout 6 Early Termination Factor 5
Small Gateway (default) Value ---------------------------------------- ----------- Configured Units 8 Available Units 6 Acquires 2 Waiters 0 Threshold Factor 380000 Threshold 380000
Medium Gateway (default) Value ---------------------------------------- ----------- Configured Units 2 Available Units 0 Acquires 2 Waiters 0 Threshold Factor 12 Threshold 18168490
Big Gateway (default) Value ---------------------------------------- ----------- Configured Units 1 Available Units 0 Acquires 1 Waiters 1 Threshold Factor 8 Threshold 27252736 |
<= 2 CPU for SQL = 4x2 Units for small <= 6 small units left as 2 are acquired
<= 2 CPU for SQL = 2 Units for medium
<= Threshold value is now populated (with dynamic value) as the small gateway has active queries.
<= one big query currently compiled <= one big query currently waiting for compilation <= Threshold value is now populated (with dynamic value) as the medium gateway has active queries. |
This was taken on a server with two complex queries being compiled and nothing else. One can confirm that the complex queries have gone up all the way to the Big Gateway but have kept their ‘acquires’ of the Small and Medium ones.
Gateways and SQL Server Resource Governor
Notice that we’ve only considered ‘Small Gateway (default)’ where default means the default resource pool.
You will notice an ‘(internal)’ pool in MEMORYSTATUS which is used for (surprise...) internal queries. We won’t go deeper here as this is usually not a problematic area.
Also, if you create new Resource Governor pools, then you will see a new group of gateways related to that group in MEMORYSTATUS.
|
“Optimization” section MemoryStatus with 2 configured pools and 2 large ongoing compilations |
|
|
Optimization Queue (default) Value ---------------------------------------- ----------- Overall Memory 552'230'912 Target Memory 287'244'288 Last Notification 1 Timeout 6 Early Termination Factor 5
Small Gateway (default) Value ---------------------------------------- ----------- Configured Units 8 Available Units 7 Acquires 1 Waiters 0 Threshold Factor 380000 Threshold 380000
Medium Gateway (default) Value ---------------------------------------- ----------- Configured Units 2 Available Units 1 Acquires 1 Waiters 0 Threshold Factor 12 Threshold 23937024
Big Gateway (default) Value ---------------------------------------- ----------- Configured Units 1 Available Units 0 Acquires 1 Waiters 0 Threshold Factor 8 Threshold 35’905’536
Optimization Queue (Pool2) Value ---------------------------------------- ----------- Overall Memory 552'230'912 Target Memory 506'281'984 Last Notification 1 Timeout 6 Early Termination Factor 5
Small Gateway (Pool2) Value ---------------------------------------- ----------- Configured Units 8 Available Units 7 Acquires 1 Waiters 0 Threshold Factor 380000 Threshold 380000
Medium Gateway (Pool2) Value ---------------------------------------- ----------- Configured Units 2 Available Units 1 Acquires 1 Waiters 0 Threshold Factor 12 Threshold 42190165
Big Gateway (Pool2) Value ---------------------------------------- ----------- Configured Units 1 Available Units 0 Acquires 1 Waiters 0 Threshold Factor 8 Threshold 63’285’248
|
<= Notice target value is noticeably lower than pool2’s
<= One large acquire in default pool
<= Notice lower threshold
<= One large acquire in Pool2 |
As you can see, there are interesting consequences to this : you get a fresh new set of Gateways for each of your pools ! Does that mean creating pools can bypass the whole gateway architecture ?
Answer is no (are you surprised? J), even though it might change how your SQL Server throttles a bit. SQL Server memory manager will adjust each other pools’ gateway thresholds based on the consumption of memory in each of the pools.
NB : This is in the situation where maximum memory for pools is left at 100%.
Remember that the purpose of the Gateway is to keep compile memory usage in check. By creating new pools you allow more simultaneous ‘Large queries’ but at the same time you potentially decrease the threshold that defines a “large query”. Therefore former “medium” queries (throttled at 1 per logical CPU within a pool) may become large queries (throttled at one per resource governor pool). All in all the actual change to how your server reacts will be limited and is rather difficult to predict. This is not even considering that the criteria available in Classifier Functions to split your workload in the various pools are restricted and may not allow for a split/dispatch of your large compilations across pools.
I have 'RESOURCE_SEMAPHORE_QUERY_COMPILE' contention what do I do ?
Ok your whole workload is sluggish, your DMVs are filled with 'RESOURCE_SEMAPHORE_QUERY_COMPILE' waittypes and the DBCC MEMORYSTATUS shows long queues for each or some of the Gateways : you have compilation contention.
The first thing to understand is that compilation contention is about complex queries, i.e. queries that make the optimizer work a lot. This not tied to the size of the resultset. A very simple query could return terabytes of data but would compile in a blink and therefore likely under the small threshold. Conversely, a query may very well return a single row but consume hundreds of MB during compilation, therefore hitting the Large gateway.
Then, if your server suffers from this contention over time (ie. not a spike tied to first compilation of a plan which is then cached), this means that there’s a recurrent flow of new large compilations. This is not really the common case. It is advised to embed most of query logic and especially query logic that is expensive to compile in Stored Procedures, precisely to enable plan caching to take place and avoid new compilations.
High compile rates generally come from three main scenarios :
· Resources (mainly memory) are too low and don’t allow for storing all plans in cache even for stored procedures.
o This usually means you’ve a lot of different plans involved and/or memory pressure is really high.
· Recompiles : for some reasons even though you’re using stored procedures and their plans are cached, for some reasons you get a lot of recompiles
· Very heavy “adhoc” TSQL activity, in other words you hammer SQL Server with big TSQL statements (no stored procedure) with high variability (that defeats auto parameterization).
o This is about the worse you can do to your (poor) SQL Server as it defeats most of its performance features
o If you end up in this scenario during early/development phase, then consider moving away from it !
o Unfortunately, some middle tiers or applications will generate this kind of workload and SQL Server has to live with it.
o In this last case, if you’re able to identify some stable and recurring adhoc queries then you can use plan guides to avoid the compilation altogether (once you’ve confirmed that the compilation cost is not tied to, say, suboptimal indexing).
The analyses of those situations have already been extensively covered, see for example TechNet or this blog post.
In every case, it is not possible to remove the gateway throttling. It is here to protect SQL Server from a process-wide collapse. As described above, the situation where the gateways are limiting is not the common case and should trigger an investigation and an understanding of why the compilations costs are 1°high 2° recurrent.
G.F.