Azure Cosmos DB bulk executor library overview
APPLIES TO: ![]() NoSQL
NoSQL
Azure Cosmos DB is a fast, flexible, and globally distributed database service that elastically scales out to support:
- Large read and write throughput, on the order of millions of operations per second.
- Storing high volumes of transactional and operational data, on the order of hundreds of terabytes or even more, with predictable millisecond latency.
The bulk executor library helps you use this massive throughput and storage. The bulk executor library allows you to perform bulk operations in Azure Cosmos DB through bulk import and bulk update APIs. You can read more about the features of bulk executor library in the following sections.
Note
Currently, bulk executor library supports import and update operations. Azure Cosmos DB API supports this library for NoSQL and Gremlin accounts only.
Important
The bulk executor library is not currently supported on serverless accounts. On .NET, we recommend that you use the bulk support available in the V3 version of the SDK.
Key features of the bulk executor library
Using the bulk executor library significantly reduces the client-side compute resources needed to saturate the throughput allocated to a container. A single threaded application that writes data using the bulk import API achieves 10 times greater write throughput when compared to a multi-threaded application that writes data in parallel while it saturates the client machine's CPU.
The bulk executor library abstracts away the tedious tasks of writing application logic to handle rate limiting of request, request timeouts, and other transient exceptions. It efficiently handles them within the library.
It provides a simplified mechanism for applications to perform bulk operations to scale out. A single bulk executor instance that runs on an Azure virtual machine can consume greater than 500 K RU/s. You can achieve a higher throughput rate by adding more instances on individual client virtual machines.
The bulk executor library can bulk import more than a terabyte of data within an hour by using a scale-out architecture.
It can bulk update existing data in Azure Cosmos DB containers as patches.
How does the bulk executor operate?
When a bulk operation to import or update documents is triggered with a batch of entities, they're initially shuffled into buckets that correspond to their Azure Cosmos DB partition key range. Within each bucket that corresponds to a partition key range, they're broken down into mini-batches.
Each mini-batch acts as a payload that is committed on the server-side. The bulk executor library has built in optimizations for concurrent execution of the mini-batches both within and across partition key ranges.
The following diagram illustrates how bulk executor batches data into different partition keys:
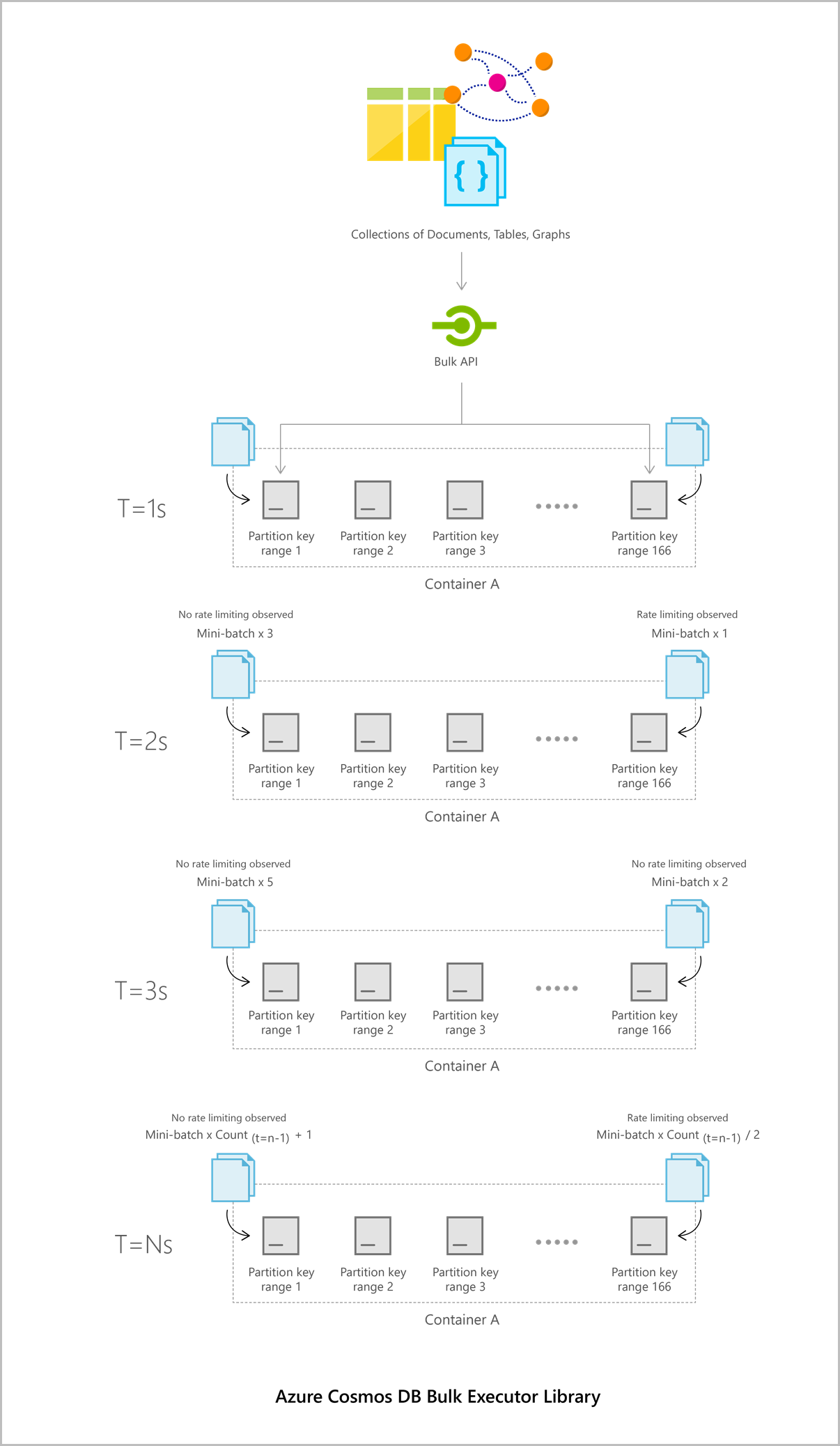
The bulk executor library makes sure to maximally utilize the throughput allocated to a collection. It uses an AIMD-style congestion control mechanism for each Azure Cosmos DB partition key range to efficiently handle rate limiting and timeouts.
For more information about sample applications that consume the bulk executor library, see Use the bulk executor .NET library to perform bulk operations in Azure Cosmos DB and Perform bulk operations on Azure Cosmos DB data.
For reference information, see .NET bulk executor library and Java bulk executor library.
Next steps
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for