Copy data from SAP HANA using Azure Data Factory or Synapse Analytics
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
Tip
Try out Data Factory in Microsoft Fabric, an all-in-one analytics solution for enterprises. Microsoft Fabric covers everything from data movement to data science, real-time analytics, business intelligence, and reporting. Learn how to start a new trial for free!
This article outlines how to use the Copy Activity in Azure Data Factory and Synapse Analytics pipelines to copy data from an SAP HANA database. It builds on the copy activity overview article that presents a general overview of copy activity.
Tip
To learn about overall support for the SAP data integration scenario, see SAP data integration whitepaper with detailed introduction on each SAP connector, comparison and guidance.
Supported capabilities
This SAP HANA connector is supported for the following capabilities:
| Supported capabilities | IR |
|---|---|
| Copy activity (source/sink) | ② |
| Lookup activity | ② |
① Azure integration runtime ② Self-hosted integration runtime
For a list of data stores supported as sources/sinks by the copy activity, see the Supported data stores table.
Specifically, this SAP HANA connector supports:
- Copying data from any version of SAP HANA database.
- Copying data from HANA information models (such as Analytic and Calculation views) and Row/Column tables.
- Copying data using Basic or Windows authentication.
- Parallel copying from a SAP HANA source. See the Parallel copy from SAP HANA section for details.
Tip
To copy data into SAP HANA data store, use generic ODBC connector. See SAP HANA sink section with details. Note the linked services for SAP HANA connector and ODBC connector are with different type thus cannot be reused.
Prerequisites
To use this SAP HANA connector, you need to:
- Set up a Self-hosted Integration Runtime. See Self-hosted Integration Runtime article for details.
- Install the SAP HANA ODBC driver on the Integration Runtime machine. You can download the SAP HANA ODBC driver from the SAP Software Download Center. Search with the keyword SAP HANA CLIENT for Windows.
Getting started
To perform the Copy activity with a pipeline, you can use one of the following tools or SDKs:
- The Copy Data tool
- The Azure portal
- The .NET SDK
- The Python SDK
- Azure PowerShell
- The REST API
- The Azure Resource Manager template
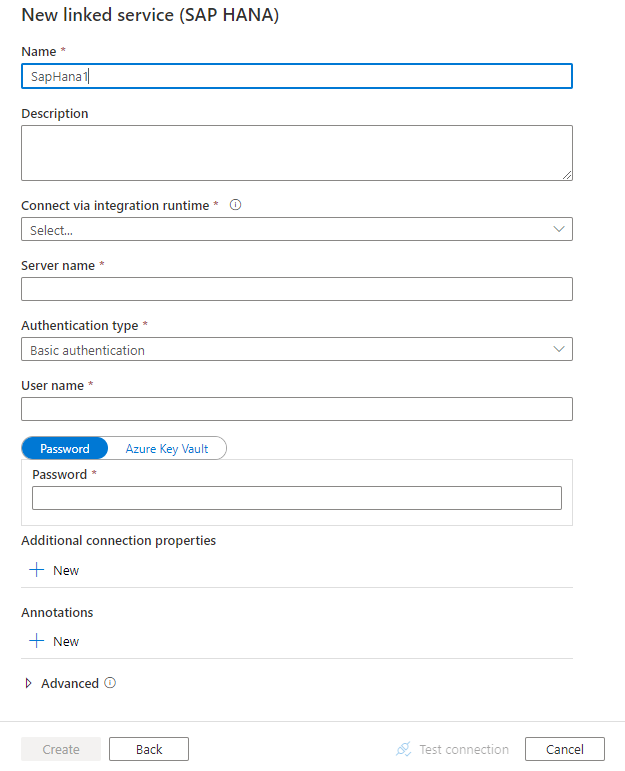
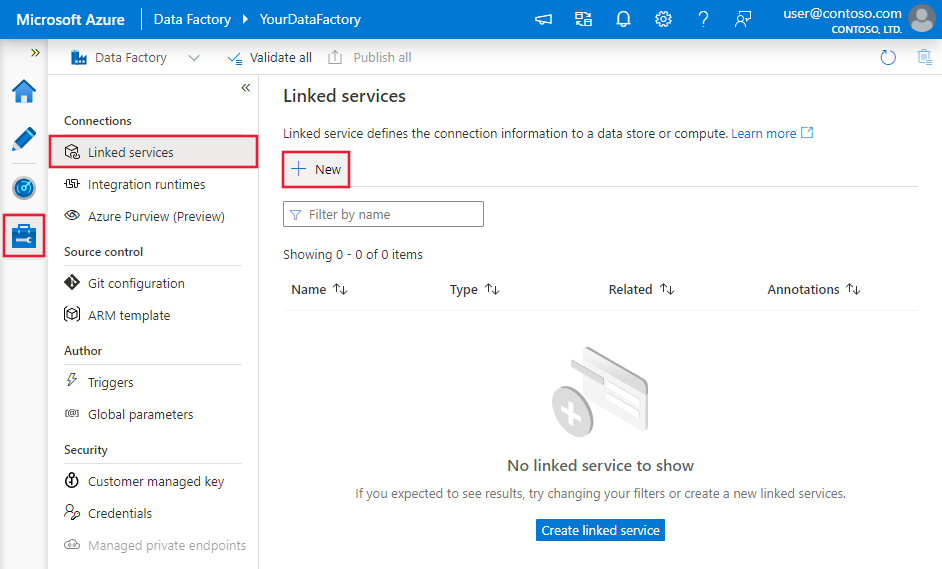
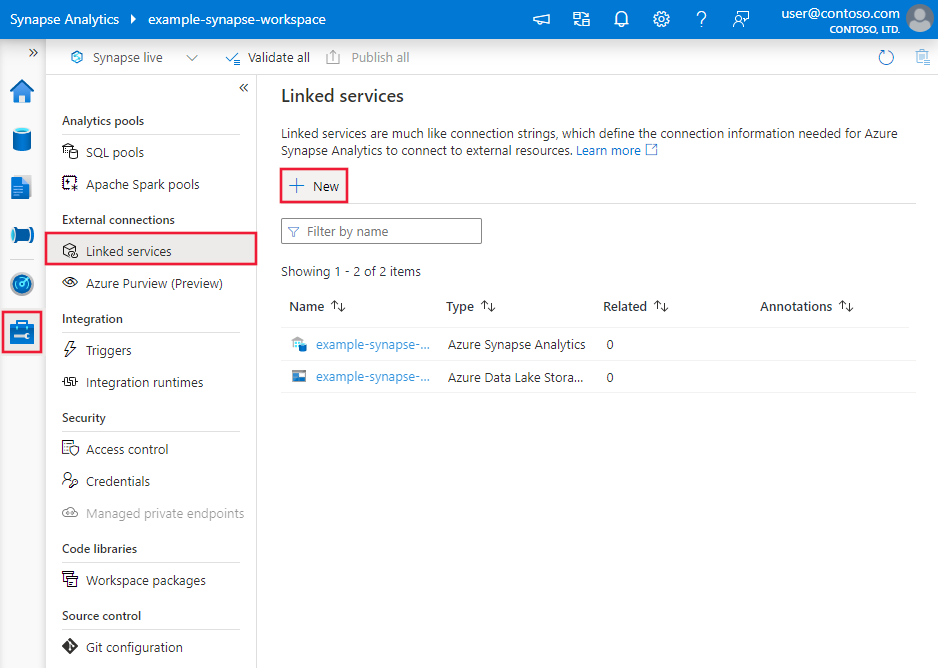
Create a linked service to SAP HANA using UI
Use the following steps to create a linked service to SAP HANA in the Azure portal UI.
Browse to the Manage tab in your Azure Data Factory or Synapse workspace and select Linked Services, then click New:
Search for SAP and select the SAP HANA connector.

Configure the service details, test the connection, and create the new linked service.
Connector configuration details
The following sections provide details about properties that are used to define Data Factory entities specific to SAP HANA connector.
Linked service properties
The following properties are supported for SAP HANA linked service:
| Property | Description | Required |
|---|---|---|
| type | The type property must be set to: SapHana | Yes |
| connectionString | Specify information that's needed to connect to the SAP HANA by using either basic authentication or Windows authentication. Refer to the following samples. In connection string, server/port is mandatory (default port is 30015), and username and password is mandatory when using basic authentication. For additional advanced settings, refer to SAP HANA ODBC Connection Properties You can also put password in Azure Key Vault and pull the password configuration out of the connection string. Refer to Store credentials in Azure Key Vault article with more details. |
Yes |
| userName | Specify user name when using Windows authentication. Example: user@domain.com |
No |
| password | Specify password for the user account. Mark this field as a SecureString to store it securely, or reference a secret stored in Azure Key Vault. | No |
| connectVia | The Integration Runtime to be used to connect to the data store. A Self-hosted Integration Runtime is required as mentioned in Prerequisites. | Yes |
Example: use basic authentication
{
"name": "SapHanaLinkedService",
"properties": {
"type": "SapHana",
"typeProperties": {
"connectionString": "SERVERNODE=<server>:<port (optional)>;UID=<userName>;PWD=<Password>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Example: use Windows authentication
{
"name": "SapHanaLinkedService",
"properties": {
"type": "SapHana",
"typeProperties": {
"connectionString": "SERVERNODE=<server>:<port (optional)>;",
"userName": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
If you were using SAP HANA linked service with the following payload, it is still supported as-is, while you are suggested to use the new one going forward.
Example:
{
"name": "SapHanaLinkedService",
"properties": {
"type": "SapHana",
"typeProperties": {
"server": "<server>:<port (optional)>",
"authenticationType": "Basic",
"userName": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Dataset properties
For a full list of sections and properties available for defining datasets, see the datasets article. This section provides a list of properties supported by SAP HANA dataset.
To copy data from SAP HANA, the following properties are supported:
| Property | Description | Required |
|---|---|---|
| type | The type property of the dataset must be set to: SapHanaTable | Yes |
| schema | Name of the schema in the SAP HANA database. | No (if "query" in activity source is specified) |
| table | Name of the table in the SAP HANA database. | No (if "query" in activity source is specified) |
Example:
{
"name": "SAPHANADataset",
"properties": {
"type": "SapHanaTable",
"typeProperties": {
"schema": "<schema name>",
"table": "<table name>"
},
"schema": [],
"linkedServiceName": {
"referenceName": "<SAP HANA linked service name>",
"type": "LinkedServiceReference"
}
}
}
If you were using RelationalTable typed dataset, it is still supported as-is, while you are suggested to use the new one going forward.
Copy activity properties
For a full list of sections and properties available for defining activities, see the Pipelines article. This section provides a list of properties supported by SAP HANA source.
SAP HANA as source
Tip
To ingest data from SAP HANA efficiently by using data partitioning, learn more from Parallel copy from SAP HANA section.
To copy data from SAP HANA, the following properties are supported in the copy activity source section:
| Property | Description | Required |
|---|---|---|
| type | The type property of the copy activity source must be set to: SapHanaSource | Yes |
| query | Specifies the SQL query to read data from the SAP HANA instance. | Yes |
| partitionOptions | Specifies the data partitioning options used to ingest data from SAP HANA. Learn more from Parallel copy from SAP HANA section. Allow values are: None (default), PhysicalPartitionsOfTable, SapHanaDynamicRange. Learn more from Parallel copy from SAP HANA section. PhysicalPartitionsOfTable can only be used when copying data from a table but not query. When a partition option is enabled (that is, not None), the degree of parallelism to concurrently load data from SAP HANA is controlled by the parallelCopies setting on the copy activity. |
False |
| partitionSettings | Specify the group of the settings for data partitioning. Apply when partition option is SapHanaDynamicRange. |
False |
| partitionColumnName | Specify the name of the source column that will be used by partition for parallel copy. If not specified, the index or the primary key of the table is auto-detected and used as the partition column. Apply when the partition option is SapHanaDynamicRange. If you use a query to retrieve the source data, hook ?AdfHanaDynamicRangePartitionCondition in WHERE clause. See example in Parallel copy from SAP HANA section. |
Yes when using SapHanaDynamicRange partition. |
| packetSize | Specifies the network packet size (in Kilobytes) to split data to multiple blocks. If you have large amount of data to copy, increasing packet size can increase reading speed from SAP HANA in most cases. Performance testing is recommended when adjusting the packet size. | No. Default value is 2048 (2MB). |
Example:
"activities":[
{
"name": "CopyFromSAPHANA",
"type": "Copy",
"inputs": [
{
"referenceName": "<SAP HANA input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SapHanaSource",
"query": "<SQL query for SAP HANA>"
},
"sink": {
"type": "<sink type>"
}
}
}
]
If you were using RelationalSource typed copy source, it is still supported as-is, while you are suggested to use the new one going forward.
Parallel copy from SAP HANA
The SAP HANA connector provides built-in data partitioning to copy data from SAP HANA in parallel. You can find data partitioning options on the Source table of the copy activity.
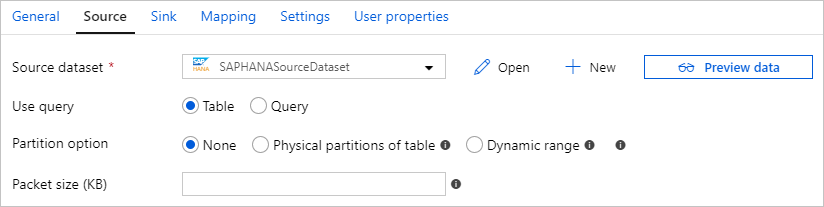
When you enable partitioned copy, the service runs parallel queries against your SAP HANA source to retrieve data by partitions. The parallel degree is controlled by the parallelCopies setting on the copy activity. For example, if you set parallelCopies to four, the service concurrently generates and runs four queries based on your specified partition option and settings, and each query retrieves a portion of data from your SAP HANA.
You are suggested to enable parallel copy with data partitioning especially when you ingest large amount of data from your SAP HANA. The following are suggested configurations for different scenarios. When copying data into file-based data store, it's recommended to write to a folder as multiple files (only specify folder name), in which case the performance is better than writing to a single file.
| Scenario | Suggested settings |
|---|---|
| Full load from large table. | Partition option: Physical partitions of table. During execution, the service automatically detects the physical partition type of the specified SAP HANA table, and choose the corresponding partition strategy: - Range Partitioning: Get the partition column and partition ranges defined for the table, then copy the data by range. - Hash Partitioning: Use hash partition key as partition column, then partition and copy the data based on ranges calculated by the service. - Round-Robin Partitioning or No Partition: Use primary key as partition column, then partition and copy the data based on ranges calculated by the service. |
| Load large amount of data by using a custom query. | Partition option: Dynamic range partition. Query: SELECT * FROM <TABLENAME> WHERE ?AdfHanaDynamicRangePartitionCondition AND <your_additional_where_clause>.Partition column: Specify the column used to apply dynamic range partition. During execution, the service first calculates the value ranges of the specified partition column, by evenly distributes the rows in a number of buckets according to the number of distinct partition column values the parallel copy setting, then replaces ?AdfHanaDynamicRangePartitionCondition with filtering the partition column value range for each partition, and sends to SAP HANA.If you want to use multiple columns as partition column, you can concatenate the values of each column as one column in the query and specify it as the partition column, like SELECT * FROM (SELECT *, CONCAT(<KeyColumn1>, <KeyColumn2>) AS PARTITIONCOLUMN FROM <TABLENAME>) WHERE ?AdfHanaDynamicRangePartitionCondition. |
Example: query with physical partitions of a table
"source": {
"type": "SapHanaSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
Example: query with dynamic range partition
"source": {
"type": "SapHanaSource",
"query": "SELECT * FROM <TABLENAME> WHERE ?AdfHanaDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "SapHanaDynamicRange",
"partitionSettings": {
"partitionColumnName": "<Partition_column_name>"
}
}
Data type mapping for SAP HANA
When copying data from SAP HANA, the following mappings are used from SAP HANA data types to interim data types used internally within the service. See Schema and data type mappings to learn about how copy activity maps the source schema and data type to the sink.
| SAP HANA data type | Interim service data type |
|---|---|
| ALPHANUM | String |
| BIGINT | Int64 |
| BINARY | Byte[] |
| BINTEXT | String |
| BLOB | Byte[] |
| BOOL | Byte |
| CLOB | String |
| DATE | DateTime |
| DECIMAL | Decimal |
| DOUBLE | Double |
| FLOAT | Double |
| INTEGER | Int32 |
| NCLOB | String |
| NVARCHAR | String |
| REAL | Single |
| SECONDDATE | DateTime |
| SHORTTEXT | String |
| SMALLDECIMAL | Decimal |
| SMALLINT | Int16 |
| STGEOMETRYTYPE | Byte[] |
| STPOINTTYPE | Byte[] |
| TEXT | String |
| TIME | TimeSpan |
| TINYINT | Byte |
| VARCHAR | String |
| TIMESTAMP | DateTime |
| VARBINARY | Byte[] |
SAP HANA sink
Currently, the SAP HANA connector is not supported as sink, while you can use generic ODBC connector with SAP HANA driver to write data into SAP HANA.
Follow the Prerequisites to set up Self-hosted Integration Runtime and install SAP HANA ODBC driver first. Create an ODBC linked service to connect to your SAP HANA data store as shown in the following example, then create dataset and copy activity sink with ODBC type accordingly. Learn more from ODBC connector article.
{
"name": "SAPHANAViaODBCLinkedService",
"properties": {
"type": "Odbc",
"typeProperties": {
"connectionString": "Driver={HDBODBC};servernode=<HANA server>.clouddatahub-int.net:30015",
"authenticationType": "Basic",
"userName": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Lookup activity properties
To learn details about the properties, check Lookup activity.
Related content
For a list of data stores supported as sources and sinks by the copy activity, see supported data stores.
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for