Set up AutoML to train a time-series forecasting model with SDK and CLI
APPLIES TO:
 Azure CLI ml extension v2 (current)
Python SDK azure-ai-ml v2 (current)
Azure CLI ml extension v2 (current)
Python SDK azure-ai-ml v2 (current)
In this article, you'll learn how to set up AutoML for time-series forecasting with Azure Machine Learning automated ML in the Azure Machine Learning Python SDK.
To do so, you:
- Prepare data for training.
- Configure specific time-series parameters in a Forecasting Job.
- Orchestrate training, inference, and model evaluation using components and pipelines.
For a low code experience, see the Tutorial: Forecast demand with automated machine learning for a time-series forecasting example using automated ML in the Azure Machine Learning studio.
AutoML uses standard machine learning models along with well-known time series models to create forecasts. Our approach incorporates historical information about the target variable, user-provided features in the input data, and automatically engineered features. Model search algorithms then work to find a model with the best predictive accuracy. For more details, see our articles on forecasting methodology and model search.
Prerequisites
For this article you need,
An Azure Machine Learning workspace. To create the workspace, see Create workspace resources.
The ability to launch AutoML training jobs. Follow the how-to guide for setting up AutoML for details.
Training and validation data
Input data for AutoML forecasting must contain valid time series in tabular format. Each variable must have its own corresponding column in the data table. AutoML requires at least two columns: a time column representing the time axis and the target column which is the quantity to forecast. Other columns can serve as predictors. For more details, see how AutoML uses your data.
Important
When training a model for forecasting future values, ensure all the features used in training can be used when running predictions for your intended horizon.
For example, a feature for current stock price could massively increase training accuracy. However, if you intend to forecast with a long horizon, you may not be able to accurately predict future stock values corresponding to future time-series points, and model accuracy could suffer.
AutoML forecasting jobs require that your training data is represented as an MLTable object. An MLTable specifies a data source and steps for loading the data. For more information and use cases, see the MLTable how-to guide. As a simple example, suppose your training data is contained in a CSV file in a local directory, ./train_data/timeseries_train.csv.
You can create an MLTable using the mltable Python SDK as in the following example:
import mltable
paths = [
{'file': './train_data/timeseries_train.csv'}
]
train_table = mltable.from_delimited_files(paths)
train_table.save('./train_data')
This code creates a new file, ./train_data/MLTable, which contains the file format and loading instructions.
You now define an input data object, which is required to start a training job, using the Azure Machine Learning Python SDK as follows:
from azure.ai.ml.constants import AssetTypes
from azure.ai.ml import Input
# Training MLTable defined locally, with local data to be uploaded
my_training_data_input = Input(
type=AssetTypes.MLTABLE, path="./train_data"
)
You specify validation data in a similar way, by creating a MLTable and specifying a validation data input. Alternatively, if you don't supply validation data, AutoML automatically creates cross-validation splits from your training data to use for model selection. See our article on forecasting model selection for more details. Also see training data length requirements for details on how much training data you need to successfully train a forecasting model.
Learn more about how AutoML applies cross validation to prevent over fitting.
Compute to run experiment
AutoML uses Azure Machine Learning Compute, which is a fully managed compute resource, to run the training job. In the following example, a compute cluster named cpu-compute is created:
from azure.ai.ml.entities import AmlCompute
# specify aml compute name.
cpu_compute_target = "cpu-cluster"
try:
ml_client.compute.get(cpu_compute_target)
except Exception:
print("Creating a new cpu compute target...")
compute = AmlCompute(
name=cpu_compute_target, size="STANDARD_D2_V2", min_instances=0, max_instances=4
)
ml_client.compute.begin_create_or_update(compute).result()Configure experiment
You use the automl factory functions to configure forecasting jobs in the Python SDK. The following example shows how to create a forecasting job by setting the primary metric and set limits on the training run:
from azure.ai.ml import automl
# note that the below is a code snippet -- you might have to modify the variable values to run it successfully
forecasting_job = automl.forecasting(
compute="cpu-compute",
experiment_name="sdk-v2-automl-forecasting-job",
training_data=my_training_data_input,
target_column_name=target_column_name,
primary_metric="normalized_root_mean_squared_error",
n_cross_validations="auto",
)
# Limits are all optional
forecasting_job.set_limits(
timeout_minutes=120,
trial_timeout_minutes=30,
max_concurrent_trials=4,
)
Forecasting job settings
Forecasting tasks have many settings that are specific to forecasting. The most basic of these settings are the name of the time column in the training data and the forecast horizon.
Use the ForecastingJob methods to configure these settings:
# Forecasting specific configuration
forecasting_job.set_forecast_settings(
time_column_name=time_column_name,
forecast_horizon=24
)
The time column name is a required setting and you should generally set the forecast horizon according to your prediction scenario. If your data contains multiple time series, you can specify the names of the time series ID columns. These columns, when grouped, define the individual series. For example, suppose that you have data consisting of hourly sales from different stores and brands. The following sample shows how to set the time series ID columns assuming the data contains columns named "store" and "brand":
# Forecasting specific configuration
# Add time series IDs for store and brand
forecasting_job.set_forecast_settings(
..., # other settings
time_series_id_column_names=['store', 'brand']
)
AutoML tries to automatically detect time series ID columns in your data if none are specified.
Other settings are optional and reviewed in the next section.
Optional forecasting job settings
Optional configurations are available for forecasting tasks, such as enabling deep learning and specifying a target rolling window aggregation. A complete list of parameters is available in the forecasting reference documentation documentation.
Model search settings
There are two optional settings that control the model space where AutoML searches for the best model, allowed_training_algorithms and blocked_training_algorithms. To restrict the search space to a given set of model classes, use the allowed_training_algorithms parameter as in the following sample:
# Only search ExponentialSmoothing and ElasticNet models
forecasting_job.set_training(
allowed_training_algorithms=["ExponentialSmoothing", "ElasticNet"]
)
In this case, the forecasting job only searches over Exponential Smoothing and Elastic Net model classes. To remove a given set of model classes from the search space, use the blocked_training_algorithms as in the following sample:
# Search over all model classes except Prophet
forecasting_job.set_training(
blocked_training_algorithms=["Prophet"]
)
Now, the job searches over all model classes except Prophet. For a list of forecasting model names that are accepted in allowed_training_algorithms and blocked_training_algorithms, see the training properties reference documentation. Either, but not both, of allowed_training_algorithms and blocked_training_algorithms can be applied to a training run.
Enable deep learning
AutoML ships with a custom deep neural network (DNN) model called TCNForecaster. This model is a temporal convolutional network, or TCN, that applies common imaging task methods to time series modeling. Namely, one-dimensional "causal" convolutions form the backbone of the network and enable the model to learn complex patterns over long durations in the training history. For more details, see our TCNForecaster article.
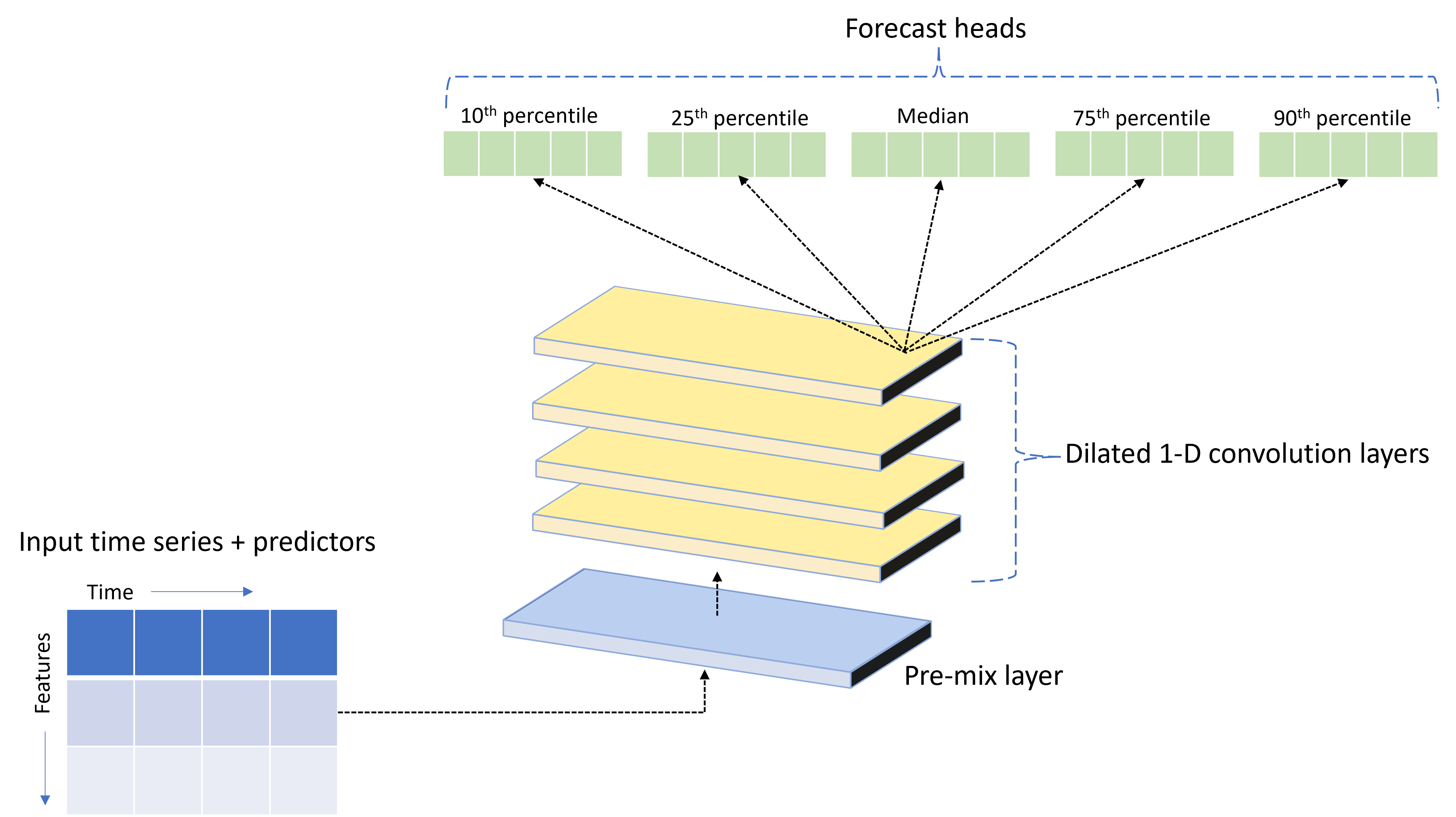
The TCNForecaster often achieves higher accuracy than standard time series models when there are thousands or more observations in the training history. However, it also takes longer to train and sweep over TCNForecaster models due to their higher capacity.
You can enable the TCNForecaster in AutoML by setting the enable_dnn_training flag in the training configuration as follows:
# Include TCNForecaster models in the model search
forecasting_job.set_training(
enable_dnn_training=True
)
By default, TCNForecaster training is limited to a single compute node and a single GPU, if available, per model trial. For large data scenarios, we recommend distributing each TCNForecaster trial over multiple cores/GPUs and nodes. See our distributed training article section for more information and code samples.
To enable DNN for an AutoML experiment created in the Azure Machine Learning studio, see the task type settings in the studio UI how-to.
Note
- When you enable DNN for experiments created with the SDK, best model explanations are disabled.
- DNN support for forecasting in Automated Machine Learning is not supported for runs initiated in Databricks.
- GPU compute types are recommended when DNN training is enabled
Lag and rolling window features
Recent values of the target are often impactful features in a forecasting model. Accordingly, AutoML can create time-lagged and rolling window aggregation features to potentially improve model accuracy.
Consider an energy demand forecasting scenario where weather data and historical demand are available. The table shows resulting feature engineering that occurs when window aggregation is applied over the most recent three hours. Columns for minimum, maximum, and sum are generated on a sliding window of three hours based on the defined settings. For instance, for the observation valid on September 8, 2017 4:00am, the maximum, minimum, and sum values are calculated using the demand values for September 8, 2017 1:00AM - 3:00AM. This window of three hours shifts along to populate data for the remaining rows. For more details and examples, see the lag feature article.

You can enable lag and rolling window aggregation features for the target by setting the rolling window size, which was three in the previous example, and the lag orders you want to create. You can also enable lags for features with the feature_lags setting. In the following sample, we set all of these settings to auto so that AutoML will automatically determine settings by analyzing the correlation structure of your data:
forecasting_job.set_forecast_settings(
..., # other settings
target_lags='auto',
target_rolling_window_size='auto',
feature_lags='auto'
)
Short series handling
Automated ML considers a time series a short series if there aren't enough data points to conduct the train and validation phases of model development. See training data length requirements for more details on length requirements.
AutoML has several actions it can take for short series. These actions are configurable with the short_series_handling_config setting. The default value is "auto." The following table describes the settings:
| Setting | Description |
|---|---|
auto |
The default value for short series handling. - If all series are short, pad the data. - If not all series are short, drop the short series. |
pad |
If short_series_handling_config = pad, then automated ML adds random values to each short series found. The following lists the column types and what they're padded with: - Object columns with NaNs - Numeric columns with 0 - Boolean/logic columns with False - The target column is padded with white noise. |
drop |
If short_series_handling_config = drop, then automated ML drops the short series, and it will not be used for training or prediction. Predictions for these series will return NaN's. |
None |
No series is padded or dropped |
In the following example, we set the short series handling so that all short series are padded to the minimum length:
forecasting_job.set_forecast_settings(
..., # other settings
short_series_handling_config='pad'
)
Warning
Padding may impact the accuracy of the resulting model, since we are introducing artificial data to avoid training failures. If many of the series are short, then you may also see some impact in explainability results
Frequency & target data aggregation
Use the frequency and data aggregation options to avoid failures caused by irregular data. Your data is irregular if it doesn't follow a set cadence in time, like hourly or daily. Point-of-sales data is a good example of irregular data. In these cases, AutoML can aggregate your data to a desired frequency and then build a forecasting model from the aggregates.
You need to set the frequency and target_aggregate_function settings to handle irregular data. The frequency setting accepts Pandas DateOffset strings as input. Supported values for the aggregation function are:
| Function | Description |
|---|---|
sum |
Sum of target values |
mean |
Mean or average of target values |
min |
Minimum value of a target |
max |
Maximum value of a target |
- The target column values are aggregated according to the specified operation. Typically, sum is appropriate for most scenarios.
- Numerical predictor columns in your data are aggregated by sum, mean, minimum value, and maximum value. As a result, automated ML generates new columns suffixed with the aggregation function name and applies the selected aggregate operation.
- For categorical predictor columns, the data is aggregated by mode, the most prominent category in the window.
- Date predictor columns are aggregated by minimum value, maximum value and mode.
The following example sets the frequency to hourly and the aggregation function to summation:
# Aggregate the data to hourly frequency
forecasting_job.set_forecast_settings(
..., # other settings
frequency='H',
target_aggregate_function='sum'
)
Custom cross-validation settings
There are two customizable settings that control cross-validation for forecasting jobs: the number of folds, n_cross_validations, and the step size defining the time offset between folds, cv_step_size. See forecasting model selection for more information on the meaning of these parameters. By default, AutoML sets both settings automatically based on characteristics of your data, but advanced users may want to set them manually. For example, suppose you have daily sales data and you want your validation setup to consist of five folds with a seven-day offset between adjacent folds. The following code sample shows how to set these:
from azure.ai.ml import automl
# Create a job with five CV folds
forecasting_job = automl.forecasting(
..., # other training parameters
n_cross_validations=5,
)
# Set the step size between folds to seven days
forecasting_job.set_forecast_settings(
..., # other settings
cv_step_size=7
)
Custom featurization
By default, AutoML augments training data with engineered features to increase the accuracy of the models. See automated feature engineering for more information. Some of the preprocessing steps can be customized using the featurization configuration of the forecasting job.
Supported customizations for forecasting are in the following table:
| Customization | Description | Options |
|---|---|---|
| Column purpose update | Override the auto-detected feature type for the specified column. | "Categorical", "DateTime", "Numeric" |
| Transformer parameter update | Update the parameters for the specified imputer. | {"strategy": "constant", "fill_value": <value>}, {"strategy": "median"}, {"strategy": "ffill"} |
For example, suppose you have a retail demand scenario where the data includes prices, an "on sale" flag, and a product type. The following sample shows how you can set customized types and imputers for these features:
from azure.ai.ml.automl import ColumnTransformer
# Customize imputation methods for price and is_on_sale features
# Median value imputation for price, constant value of zero for is_on_sale
transformer_params = {
"imputer": [
ColumnTransformer(fields=["price"], parameters={"strategy": "median"}),
ColumnTransformer(fields=["is_on_sale"], parameters={"strategy": "constant", "fill_value": 0}),
],
}
# Set the featurization
# Ensure that product_type feature is interpreted as categorical
forecasting_job.set_featurization(
mode="custom",
transformer_params=transformer_params,
column_name_and_types={"product_type": "Categorical"},
)
If you're using the Azure Machine Learning studio for your experiment, see how to customize featurization in the studio.
Submitting a forecasting job
After all settings are configured, you launch the forecasting job as follows:
# Submit the AutoML job
returned_job = ml_client.jobs.create_or_update(
forecasting_job
)
print(f"Created job: {returned_job}")
# Get a URL for the job in the AML studio user interface
returned_job.services["Studio"].endpoint
Once the job is submitted, AutoML will provision compute resources, apply featurization and other preparation steps to the input data, then begin sweeping over forecasting models. For more details, see our articles on forecasting methodology and model search.
Orchestrating training, inference, and evaluation with components and pipelines
Important
This feature is currently in public preview. This preview version is provided without a service-level agreement, and we don't recommend it for production workloads. Certain features might not be supported or might have constrained capabilities.
For more information, see Supplemental Terms of Use for Microsoft Azure Previews.
Your ML workflow likely requires more than just training. Inference, or retrieving model predictions on newer data, and evaluation of model accuracy on a test set with known target values are other common tasks that you can orchestrate in AzureML along with training jobs. To support inference and evaluation tasks, AzureML provides components, which are self-contained pieces of code that do one step in an AzureML pipeline.
In the following example, we retrieve component code from a client registry:
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
# Get a credential for access to the AzureML registry
try:
credential = DefaultAzureCredential()
# Check if we can get token successfully.
credential.get_token("https://management.azure.com/.default")
except Exception as ex:
# Fall back to InteractiveBrowserCredential in case DefaultAzureCredential fails
credential = InteractiveBrowserCredential()
# Create a client for accessing assets in the AzureML preview registry
ml_client_registry = MLClient(
credential=credential,
registry_name="azureml-preview"
)
# Create a client for accessing assets in the AzureML preview registry
ml_client_metrics_registry = MLClient(
credential=credential,
registry_name="azureml"
)
# Get an inference component from the registry
inference_component = ml_client_registry.components.get(
name="automl_forecasting_inference",
label="latest"
)
# Get a component for computing evaluation metrics from the registry
compute_metrics_component = ml_client_metrics_registry.components.get(
name="compute_metrics",
label="latest"
)
Next, we define a factory function that creates pipelines orchestrating training, inference, and metric computation. See the training configuration section for more details on training settings.
from azure.ai.ml import automl
from azure.ai.ml.constants import AssetTypes
from azure.ai.ml.dsl import pipeline
@pipeline(description="AutoML Forecasting Pipeline")
def forecasting_train_and_evaluate_factory(
train_data_input,
test_data_input,
target_column_name,
time_column_name,
forecast_horizon,
primary_metric='normalized_root_mean_squared_error',
cv_folds='auto'
):
# Configure the training node of the pipeline
training_node = automl.forecasting(
training_data=train_data_input,
target_column_name=target_column_name,
primary_metric=primary_metric,
n_cross_validations=cv_folds,
outputs={"best_model": Output(type=AssetTypes.MLFLOW_MODEL)},
)
training_node.set_forecasting_settings(
time_column_name=time_column_name,
forecast_horizon=max_horizon,
frequency=frequency,
# other settings
...
)
training_node.set_training(
# training parameters
...
)
training_node.set_limits(
# limit settings
...
)
# Configure the inference node to make rolling forecasts on the test set
inference_node = inference_component(
test_data=test_data_input,
model_path=training_node.outputs.best_model,
target_column_name=target_column_name,
forecast_mode='rolling',
forecast_step=1
)
# Configure the metrics calculation node
compute_metrics_node = compute_metrics_component(
task="tabular-forecasting",
ground_truth=inference_node.outputs.inference_output_file,
prediction=inference_node.outputs.inference_output_file,
evaluation_config=inference_node.outputs.evaluation_config_output_file
)
# return a dictionary with the evaluation metrics and the raw test set forecasts
return {
"metrics_result": compute_metrics_node.outputs.evaluation_result,
"rolling_fcst_result": inference_node.outputs.inference_output_file
}
Now, we define train and test data inputs assuming that they're contained in local folders, ./train_data and ./test_data:
my_train_data_input = Input(
type=AssetTypes.MLTABLE,
path="./train_data"
)
my_test_data_input = Input(
type=AssetTypes.URI_FOLDER,
path='./test_data',
)
Finally, we construct the pipeline, set its default compute and submit the job:
pipeline_job = forecasting_train_and_evaluate_factory(
my_train_data_input,
my_test_data_input,
target_column_name,
time_column_name,
forecast_horizon
)
# set pipeline level compute
pipeline_job.settings.default_compute = compute_name
# submit the pipeline job
returned_pipeline_job = ml_client.jobs.create_or_update(
pipeline_job,
experiment_name=experiment_name
)
returned_pipeline_job
Once submitted, the pipeline runs AutoML training, rolling evaluation inference, and metric calculation in sequence. You can monitor and inspect the run in the studio UI. When the run is finished, the rolling forecasts and the evaluation metrics can be downloaded to the local working directory:
# Download the metrics json
ml_client.jobs.download(returned_pipeline_job.name, download_path=".", output_name='metrics_result')
# Download the rolling forecasts
ml_client.jobs.download(returned_pipeline_job.name, download_path=".", output_name='rolling_fcst_result')
Then, you can find the metrics results in ./named-outputs/metrics_results/evaluationResult/metrics.json and the forecasts, in JSON lines format, in ./named-outputs/rolling_fcst_result/inference_output_file.
For more details on rolling evaluation, see our forecasting model evaluation article.
Forecasting at scale: many models
Important
This feature is currently in public preview. This preview version is provided without a service-level agreement, and we don't recommend it for production workloads. Certain features might not be supported or might have constrained capabilities.
For more information, see Supplemental Terms of Use for Microsoft Azure Previews.
The many models components in AutoML enable you to train and manage millions of models in parallel. For more information on many models concepts, see the many models article section.
Many models training configuration
The many models training component accepts a YAML format configuration file of AutoML training settings. The component applies these settings to each AutoML instance it launches. This YAML file has the same specification as the Forecasting Job plus additional parameters partition_column_names and allow_multi_partitions.
| Parameter | Description |
|---|---|
| partition_column_names | Column names in the data that, when grouped, define the data partitions. The many models training component launches an independent training job on each partition. |
| allow_multi_partitions | An optional flag that allows training one model per partition when each partition contains more than one unique time series. The default value is False. |
The following sample provides a configuration template:
$schema: https://azuremlsdk2.blob.core.windows.net/preview/0.0.1/autoMLJob.schema.json
type: automl
description: A time series forecasting job config
compute: azureml:<cluster-name>
task: forecasting
primary_metric: normalized_root_mean_squared_error
target_column_name: sales
n_cross_validations: 3
forecasting:
time_column_name: date
time_series_id_column_names: ["state", "store"]
forecast_horizon: 28
training:
blocked_training_algorithms: ["ExtremeRandomTrees"]
limits:
timeout_minutes: 15
max_trials: 10
max_concurrent_trials: 4
max_cores_per_trial: -1
trial_timeout_minutes: 15
enable_early_termination: true
partition_column_names: ["state", "store"]
allow_multi_partitions: false
In subsequent examples, we assume that the configuration is stored at the path, ./automl_settings_mm.yml.
Many models pipeline
Next, we define a factory function that creates pipelines for orchestration of many models training, inference, and metric computation. The parameters of this factory function are detailed in the following table:
| Parameter | Description |
|---|---|
| max_nodes | Number of compute nodes to use in the training job |
| max_concurrency_per_node | Number of AutoML processes to run on each node. Hence, the total concurrency of a many models jobs is max_nodes * max_concurrency_per_node. |
| parallel_step_timeout_in_seconds | Many models component timeout given in number of seconds. |
| retrain_failed_models | Flag to enable re-training for failed models. This is useful if you've done previous many models runs that resulted in failed AutoML jobs on some data partitions. When this flag is enabled, many models will only launch training jobs for previously failed partitions. |
| forecast_mode | Inference mode for model evaluation. Valid values are "recursive" and "rolling". See the model evaluation article for more information. |
| forecast_step | Step size for rolling forecast. See the model evaluation article for more information. |
The following sample illustrates a factory method for constructing many models training and model evaluation pipelines:
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
# Get a credential for access to the AzureML registry
try:
credential = DefaultAzureCredential()
# Check if we can get token successfully.
credential.get_token("https://management.azure.com/.default")
except Exception as ex:
# Fall back to InteractiveBrowserCredential in case DefaultAzureCredential fails
credential = InteractiveBrowserCredential()
# Get a many models training component
mm_train_component = ml_client_registry.components.get(
name='automl_many_models_training',
version='latest'
)
# Get a many models inference component
mm_inference_component = ml_client_registry.components.get(
name='automl_many_models_inference',
version='latest'
)
# Get a component for computing evaluation metrics
compute_metrics_component = ml_client_metrics_registry.components.get(
name="compute_metrics",
label="latest"
)
@pipeline(description="AutoML Many Models Forecasting Pipeline")
def many_models_train_evaluate_factory(
train_data_input,
test_data_input,
automl_config_input,
compute_name,
max_concurrency_per_node=4,
parallel_step_timeout_in_seconds=3700,
max_nodes=4,
retrain_failed_model=False,
forecast_mode="rolling",
forecast_step=1
):
mm_train_node = mm_train_component(
raw_data=train_data_input,
automl_config=automl_config_input,
max_nodes=max_nodes,
max_concurrency_per_node=max_concurrency_per_node,
parallel_step_timeout_in_seconds=parallel_step_timeout_in_seconds,
retrain_failed_model=retrain_failed_model,
compute_name=compute_name
)
mm_inference_node = mm_inference_component(
raw_data=test_data_input,
max_nodes=max_nodes,
max_concurrency_per_node=max_concurrency_per_node,
parallel_step_timeout_in_seconds=parallel_step_timeout_in_seconds,
optional_train_metadata=mm_train_node.outputs.run_output,
forecast_mode=forecast_mode,
forecast_step=forecast_step,
compute_name=compute_name
)
compute_metrics_node = compute_metrics_component(
task="tabular-forecasting",
prediction=mm_inference_node.outputs.evaluation_data,
ground_truth=mm_inference_node.outputs.evaluation_data,
evaluation_config=mm_inference_node.outputs.evaluation_configs
)
# Return the metrics results from the rolling evaluation
return {
"metrics_result": compute_metrics_node.outputs.evaluation_result
}
Now, we construct the pipeline via the factory function, assuming the training and test data are in local folders, ./data/train and ./data/test, respectively. Finally, we set the default compute and submit the job as in the following sample:
pipeline_job = many_models_train_evaluate_factory(
train_data_input=Input(
type="uri_folder",
path="./data/train"
),
test_data_input=Input(
type="uri_folder",
path="./data/test"
),
automl_config=Input(
type="uri_file",
path="./automl_settings_mm.yml"
),
compute_name="<cluster name>"
)
pipeline_job.settings.default_compute = "<cluster name>"
returned_pipeline_job = ml_client.jobs.create_or_update(
pipeline_job,
experiment_name=experiment_name,
)
ml_client.jobs.stream(returned_pipeline_job.name)
After the job finishes, the evaluation metrics can be downloaded locally using the same procedure as in the single training run pipeline.
Also see the demand forecasting with many models notebook for a more detailed example.
Note
The many models training and inference components conditionally partition your data according to the partition_column_names setting so that each partition is in its own file. This process can be very slow or fail when data is very large. In this case, we recommend partitioning your data manually before running many models training or inference.
Forecasting at scale: hierarchical time series
Important
This feature is currently in public preview. This preview version is provided without a service-level agreement, and we don't recommend it for production workloads. Certain features might not be supported or might have constrained capabilities.
For more information, see Supplemental Terms of Use for Microsoft Azure Previews.
The hierarchical time series (HTS) components in AutoML enable you to train a large number of models on data with hierarchical structure. For more information, see the HTS article section.
HTS training configuration
The HTS training component accepts a YAML format configuration file of AutoML training settings. The component applies these settings to each AutoML instance it launches. This YAML file has the same specification as the Forecasting Job plus additional parameters related to the hierarchy information:
| Parameter | Description |
|---|---|
| hierarchy_column_names | A list of column names in the data that define the hierarchical structure of the data. The order of the columns in this list determines the hierarchy levels; the degree of aggregation decreases with the list index. That is, the last column in the list defines the leaf (most disaggregated) level of the hierarchy. |
| hierarchy_training_level | The hierarchy level to use for forecast model training. |
The following shows a sample configuration:
$schema: https://azuremlsdk2.blob.core.windows.net/preview/0.0.1/autoMLJob.schema.json
type: automl
description: A time series forecasting job config
compute: azureml:cluster-name
task: forecasting
primary_metric: normalized_root_mean_squared_error
log_verbosity: info
target_column_name: sales
n_cross_validations: 3
forecasting:
time_column_name: "date"
time_series_id_column_names: ["state", "store", "SKU"]
forecast_horizon: 28
training:
blocked_training_algorithms: ["ExtremeRandomTrees"]
limits:
timeout_minutes: 15
max_trials: 10
max_concurrent_trials: 4
max_cores_per_trial: -1
trial_timeout_minutes: 15
enable_early_termination: true
hierarchy_column_names: ["state", "store", "SKU"]
hierarchy_training_level: "store"
In subsequent examples, we assume that the configuration is stored at the path, ./automl_settings_hts.yml.
HTS pipeline
Next, we define a factory function that creates pipelines for orchestration of HTS training, inference, and metric computation. The parameters of this factory function are detailed in the following table:
| Parameter | Description |
|---|---|
| forecast_level | The level of the hierarchy to retrieve forecasts for |
| allocation_method | Allocation method to use when forecasts are disaggregated. Valid values are "proportions_of_historical_average" and "average_historical_proportions". |
| max_nodes | Number of compute nodes to use in the training job |
| max_concurrency_per_node | Number of AutoML processes to run on each node. Hence, the total concurrency of an HTS job is max_nodes * max_concurrency_per_node. |
| parallel_step_timeout_in_seconds | Many models component timeout given in number of seconds. |
| forecast_mode | Inference mode for model evaluation. Valid values are "recursive" and "rolling". See the model evaluation article for more information. |
| forecast_step | Step size for rolling forecast. See the model evaluation article for more information. |
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
# Get a credential for access to the AzureML registry
try:
credential = DefaultAzureCredential()
# Check if we can get token successfully.
credential.get_token("https://management.azure.com/.default")
except Exception as ex:
# Fall back to InteractiveBrowserCredential in case DefaultAzureCredential fails
credential = InteractiveBrowserCredential()
# Get a HTS training component
hts_train_component = ml_client_registry.components.get(
name='automl_hts_training',
version='latest'
)
# Get a HTS inference component
hts_inference_component = ml_client_registry.components.get(
name='automl_hts_inference',
version='latest'
)
# Get a component for computing evaluation metrics
compute_metrics_component = ml_client_metrics_registry.components.get(
name="compute_metrics",
label="latest"
)
@pipeline(description="AutoML HTS Forecasting Pipeline")
def hts_train_evaluate_factory(
train_data_input,
test_data_input,
automl_config_input,
max_concurrency_per_node=4,
parallel_step_timeout_in_seconds=3700,
max_nodes=4,
forecast_mode="rolling",
forecast_step=1,
forecast_level="SKU",
allocation_method='proportions_of_historical_average'
):
hts_train = hts_train_component(
raw_data=train_data_input,
automl_config=automl_config_input,
max_concurrency_per_node=max_concurrency_per_node,
parallel_step_timeout_in_seconds=parallel_step_timeout_in_seconds,
max_nodes=max_nodes
)
hts_inference = hts_inference_component(
raw_data=test_data_input,
max_nodes=max_nodes,
max_concurrency_per_node=max_concurrency_per_node,
parallel_step_timeout_in_seconds=parallel_step_timeout_in_seconds,
optional_train_metadata=hts_train.outputs.run_output,
forecast_level=forecast_level,
allocation_method=allocation_method,
forecast_mode=forecast_mode,
forecast_step=forecast_step
)
compute_metrics_node = compute_metrics_component(
task="tabular-forecasting",
prediction=hts_inference.outputs.evaluation_data,
ground_truth=hts_inference.outputs.evaluation_data,
evaluation_config=hts_inference.outputs.evaluation_configs
)
# Return the metrics results from the rolling evaluation
return {
"metrics_result": compute_metrics_node.outputs.evaluation_result
}
Now, we construct the pipeline via the factory function, assuming the training and test data are in local folders, ./data/train and ./data/test, respectively. Finally, we set the default compute and submit the job as in the following sample:
pipeline_job = hts_train_evaluate_factory(
train_data_input=Input(
type="uri_folder",
path="./data/train"
),
test_data_input=Input(
type="uri_folder",
path="./data/test"
),
automl_config=Input(
type="uri_file",
path="./automl_settings_hts.yml"
)
)
pipeline_job.settings.default_compute = "cluster-name"
returned_pipeline_job = ml_client.jobs.create_or_update(
pipeline_job,
experiment_name=experiment_name,
)
ml_client.jobs.stream(returned_pipeline_job.name)
After the job finishes, the evaluation metrics can be downloaded locally using the same procedure as in the single training run pipeline.
Also see the demand forecasting with hierarchical time series notebook for a more detailed example.
Note
The HTS training and inference components conditionally partition your data according to the hierarchy_column_names setting so that each partition is in its own file. This process can be very slow or fail when data is very large. In this case, we recommend partitioning your data manually before running HTS training or inference.
Forecasting at scale: distributed DNN training
- To learn how distributed training works for forecasting tasks, see our forecasting at scale article.
- See our setup distributed training for tabular data article section for code samples.
Example notebooks
See the forecasting sample notebooks for detailed code examples of advanced forecasting configuration including:
- Demand forecasting pipeline examples
- Deep learning models
- Holiday detection and featurization
- Manual configuration for lags and rolling window aggregation features
Next steps
- Learn more about How to deploy an AutoML model to an online endpoint.
- Learn about Interpretability: model explanations in automated machine learning (preview).
- Learn about how AutoML builds forecasting models.
- Learn about forecasting at scale.
- Learn how to configure AutoML for various forecasting scenarios.
- Learn about inference and evaluation of forecasting models.
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for