Monitor Azure Data Explorer performance, health, and usage with metrics
Azure Data Explorer metrics provide key indicators as to the health and performance of the Azure Data Explorer cluster resources. Use the metrics that are detailed in this article to monitor Azure Data Explorer cluster usage, health, and performance in your specific scenario as standalone metrics. You can also use metrics as the basis for operational Azure Dashboards and Azure Alerts.
For more information about Azure Metrics Explorer, see Metrics Explorer.
Prerequisites
- An Azure subscription. Create a free Azure account.
- An Azure Data Explorer cluster and database. Create a cluster and database.
Use metrics to monitor your Azure Data Explorer resources
- Sign in to the Azure portal.
- In the left-hand pane of your Azure Data Explorer cluster, search for metrics.
- Select Metrics to open the metrics pane and begin analysis on your cluster.

Work in the metrics pane
In the metrics pane, select specific metrics to track, choose how to aggregate your data, and create metric charts to view on your dashboard.
The Resource and Metric Namespace pickers are pre-selected for your Azure Data Explorer cluster. The numbers in the following image correspond to the numbered list below. They guide you through different options in setting up and viewing your metrics.
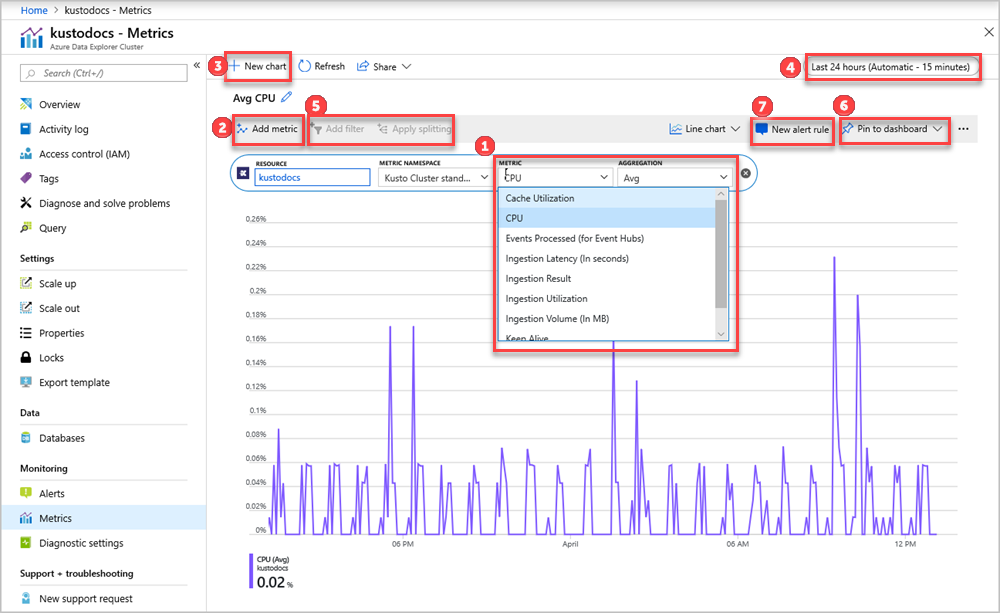
- To create a metric chart, select Metric name and relevant Aggregation per metric. For more information about different metrics, see supported Azure Data Explorer metrics.
- Select Add metric to see multiple metrics plotted in the same chart.
- Select + New chart to see multiple charts in one view.
- Use the time picker to change the time range (default: past 24 hours).
- Use Add filter and Apply splitting for metrics that have dimensions.
- Select Pin to dashboard to add your chart configuration to the dashboards so that you can view it again.
- Set New alert rule to visualize your metrics using the set criteria. The new alerting rule will include your target resource, metric, splitting, and filter dimensions from your chart. Modify these settings in the alert rule creation pane.
Supported Azure Data Explorer metrics
The Azure Data Explorer metrics give insight into both overall performance and use of your resources, as well as information about specific actions, such as ingestion or query. The metrics in this article have been grouped by usage type.
The types of metrics are:
- Cluster metrics
- Export metrics
- Ingestion metrics
- Streaming ingest metrics
- Query metrics
- Materialized view metrics
For an alphabetical list of Azure Monitor's metrics for Azure Data Explorers, see supported Azure Data Explorer cluster metrics.
Cluster metrics
The cluster metrics track the general health of the cluster. For example, resource and ingestion use and responsiveness.
| Metric | Unit | Aggregation | Metric description | Dimensions |
|---|---|---|---|---|
| Cache utilization (deprecated) | Percent | Avg, Max, Min | Percentage of allocated cache resources currently in use by the cluster. Cache is the size of SSD allocated for user activity according to the defined cache policy. An average cache utilization of 80% or less is a sustainable state for a cluster. If the average cache utilization is above 80%, the cluster should be scaled up to a storage-optimized pricing tier or scaled out to more instances. Alternatively, adapt the cache policy to fewer days in cache. If cache utilization is over 100%, the size of data to be cached is larger than the total size of cache on the cluster. This metric is deprecated and presented for backward compatibility only. Use the ‘Cache utilization factor’ metric instead. |
None |
| Cache utilization factor | Percent | Avg, Max, Min | Percentage of utilized disk space dedicated for hot cache in the cluster. 100% means that the disk space assigned to hot data is optimally utilized. No action is needed, and the cluster is completely fine. Less than 100% means that the disk space assigned for hot data is not fully utilized. More than 100% means that the cluster's disk space is not large enough to accommodate the hot data, as defined by your caching policies. To ensure that sufficient space is available for all the hot data, the amount of hot data needs to be reduced or the cluster needs to be scaled out. We recommend enabling auto scale. |
None |
| CPU | Percent | Avg, Max, Min | Percentage of allocated compute resources currently in use by machines in the cluster. An average CPU of 80% or less is sustainable for a cluster. The maximum value of CPU is 100%, which means there are no additional compute resources to process data. When a cluster isn't performing well, check the maximum value of the CPU to determine if there are specific CPUs that are blocked. |
None |
| Ingestion utilization | Percent | Avg, Max, Min | Percentage of actual resources used to ingest data from the total resources allocated, in the capacity policy, to perform ingestion. The default capacity policy is no more than 512 concurrent ingestion operations or 75% of the cluster resources invested in ingestion. Average ingestion utilization of 80% or less is a sustainable state for a cluster. Maximum value of ingestion utilization is 100%, which means all cluster ingestion ability is used and an ingestion queue may result. |
None |
| InstanceCount | Count | Avg | Total instance count. | |
| Keep alive | Count | Avg | Tracks the responsiveness of the cluster. A fully responsive cluster returns value 1 and a blocked or disconnected cluster returns 0. |
|
| Total number of throttled commands | Count | Avg, Max, Min, Sum | The number of throttled (rejected) commands in the cluster, since the maximum allowed number of concurrent (parallel) commands was reached. | None |
| Total number of extents | Count | Avg, Max, Min, Sum | Total number of data extents in the cluster. Changes in this metric can imply massive data structure changes and high load on the cluster, since merging data extents is a CPU-heavy activity. |
None |
| Follower latency | Milliseconds | Avg, Max, Min | The follower databases synchronize changes in the leader databases. Because of the synchronization, there’s a data lag of a few seconds to a few minutes in data availability. This metric measures the length of the time lag. The time lag depends on several factors like: the overall size and rate of the ingested data to the leader, the number of databases followed, the rate of internal operations performed on the leader (merge/rebuild operations). This is a cluster level metrics: the followers catch metadata of all databases that are followed. This metric represents the latency of the process. |
None |
Export metrics
Export metrics track the general health and performance of export operations like lateness, results, number of records, and utilization.
| Metric | Unit | Aggregation | Metric description | Dimensions |
|---|---|---|---|---|
| Continuous export number of exported records | Count | Sum | The number of exported records in all continuous export jobs. | ContinuousExportName |
| Continuous export max lateness | Count | Max | The lateness (in minutes) reported by the continuous export jobs in the cluster. | None |
| Continuous export pending count | Count | Max | The number of pending continuous export jobs. These jobs are ready to run but waiting in a queue, possibly due to insufficient capacity). | |
| Continuous export result | Count | Count | The Failure/Success result of each continuous export run. | ContinuousExportName |
| Export utilization | Percent | Max | Export capacity used, out of the total export capacity in the cluster (between 0 and 100). | None |
Ingestion metrics
Ingestion metrics track the general health and performance of ingestion operations like latency, results, and volume. To refine your analysis:
- Apply filters to charts to plot partial data by dimensions. For example, explore ingestion to a specific
Database. - Apply splitting to a chart to visualize data by different components. This process is useful for analyzing metrics that are reported by each step of the ingestion pipeline, for example
Blobs received.
| Metric | Unit | Aggregation | Metric description | Dimensions |
|---|---|---|---|---|
| Batch blob count | Count | Avg, Max, Min | Number of data sources in a completed batch for ingestion. | Database |
| Batch duration | Seconds | Avg, Max, Min | The duration of the batching phase in the ingestion flow. | Database |
| Batch size | Bytes | Avg, Max, Min | Uncompressed expected data size in an aggregated batch for ingestion. | Database |
| Batches processed | Count | Sum, Max, Min | Number of batches completed for ingestion. Batching Type: The trigger for sealing a batch. For a complete list of batching types, see Batching types. |
Database, Batching Type |
| Blobs received | Count | Sum, Max, Min | Number of blobs received from input stream by a component. Use apply splitting to analyze each component. |
Database, Component Type, Component Name |
| Blobs processed | Count | Sum, Max, Min | Number of blobs processed by a component. Use apply splitting to analyze each component. |
Database, Component Type, Component Name |
| Blobs dropped | Count | Sum, Max, Min | Number of blobs permanently dropped by a component. For each such blob, an Ingestion result metric with a failure reason is sent. Use apply splitting to analyze each component. |
Database, Component Type, Component Name |
| Discovery latency | Seconds | Avg | Time from data enqueue until discovery by data connections. This time isn't included in the Stage latency or in the Ingestion latency metrics. Discovery latency may increase in the following situations:
|
Component Type, Component Name |
| Events received | Count | Sum, Max, Min | Number of events received by data connections from input stream. | Component Type, Component Name |
| Events processed | Count | Sum, Max, Min | Number of events processed by data connections. | Component Type, Component Name |
| Events dropped | Count | Sum, Max, Min | Number of events permanently dropped by data connections. For each such event, an Ingestion result metric with a failure reason is sent. |
Component Type, Component Name |
| Events processed (for Event/IoT Hubs) (deprecated) | Count | Max, Min, Sum | Total number of events read from Event Hub/ IoT Hub and processed by the cluster. These events can be split by the status: Received, Rejected, Processed. This metric is deprecated and presented for backward compatibility only. Use ‘Events received’, ‘Events processed’ and ‘Events dropped’ metrics instead. |
Status |
| Ingestion latency | Seconds | Avg, Max, Min | Latency of data ingested, from the time the data was received in the cluster until it's ready for query. The ingestion latency period depends on the ingestion scenario.Ingestion Kind: Streaming Ingestion or Queued Ingestion |
Ingestion Kind |
| Ingestion result | Count | Sum | Total number of sources that either failed or succeeded to be ingested.Status: Success for successful ingestion or the failure category for failures. For a complete list of possible failure categories see Ingestion error codes in Azure Data Explorer. Failure Status Type: Whether the failure is permanent or transient. For successful ingestion, this dimension is None.Note:
|
Status, Failure Status Type |
| Ingestion volume (in MB) | Count | Max, Sum | The total size of data ingested to the cluster (in MB) before compression. | Database |
| Queue length | Count | Avg | Number of pending messages in a component's input queue. The batching manager component has one message per blob. The ingestion manager component has one message per batch. A batch is a single ingest command with one or more blobs. | Component Type |
| Queue oldest message | Seconds | Avg | Time in seconds from when the oldest message in a component's input queue has been inserted. | Component Type |
| Received data size bytes | Bytes | Avg, Sum | Size of data received by data connections from input stream. | Component Type, Component Name |
| Stage latency | Seconds | Avg | Time from when a message is accepted by Azure Data Explorer, until its content is received by an ingestion component for processing. Use apply filters and select Component Type > StorageEngine to show the total ingestion latency. |
Database, Component Type |
Streaming ingest metrics
Streaming ingest metrics track streaming ingestion data and request rate, duration, and results.
| Metric | Unit | Aggregation | Metric description | Dimensions |
|---|---|---|---|---|
| Streaming Ingest Data Rate | Count | RateRequestsPerSecond | Total volume of data ingested to the cluster. | None |
| Streaming Ingest Duration | Milliseconds | Avg, Max, Min | Total duration of all streaming ingestion requests. | None |
| Streaming Ingest Request Rate | Count | Count, Avg, Max, Min, Sum | Total number of streaming ingestion requests. | None |
| Streaming Ingest Result | Count | Avg | Total number of streaming ingestion requests by result type. | Result |
Query metrics
Query performance metrics track query duration and total number of concurrent or throttled queries.
| Metric | Unit | Aggregation | Metric description | Dimensions |
|---|---|---|---|---|
| Query duration | Milliseconds | Avg, Min, Max, Sum | Total time until query results are received (doesn't include network latency). | QueryStatus |
| QueryResult | Count | Count | Total number of queries. | QueryStatus |
| Total number of concurrent queries | Count | Avg, Max, Min, Sum | The number of queries run in parallel in the cluster. This metric is a good way to estimate the load on the cluster. | None |
| Total number of throttled queries | Count | Avg, Max, Min, Sum | The number of throttled (rejected) queries in the cluster. The maximum number of concurrent (parallel) queries allowed is defined in the request rate limit policy. | None |
Materialized view metrics
| Metric | Unit | Aggregation | Metric description | Dimensions |
|---|---|---|---|---|
| MaterializedViewHealth | 1, 0 | Avg | Value is 1 if the view is considered healthy, otherwise 0. | Database, MaterializedViewName |
| MaterializedViewAgeSeconds | Seconds | Avg | The age of the view is defined by the current time minus the last ingestion time processed by the view. Metric value is time in seconds (the lower the value is, the view is "healthier"). |
Database, MaterializedViewName |
| MaterializedViewResult | 1 | Avg | Metric includes a Result dimension indicating the result of the last materialization cycle (see the MaterializedViewResult metric for details about possible values). Metric value always equals 1. |
Database, MaterializedViewName, Result |
| MaterializedViewRecordsInDelta | Records count | Avg | The number of records currently in the non-processed part of the source table. For more information, see how materialized views work | Database, MaterializedViewName |
| MaterializedViewExtentsRebuild | Extents count | Avg | The number of extents that required updates in the materialization cycle. | Database, MaterializedViewName |
| MaterializedViewDataLoss | 1 | Max | Metric is fired when unprocessed source data is approaching retention. Indicates that the materialized view is unhealthy. | Database, MaterializedViewName, Kind |
Related content
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for