How to select algorithms for Azure Machine Learning
If you're wondering which machine learning algorithm to use, the answer depends primarily on two aspects of your data science scenario:
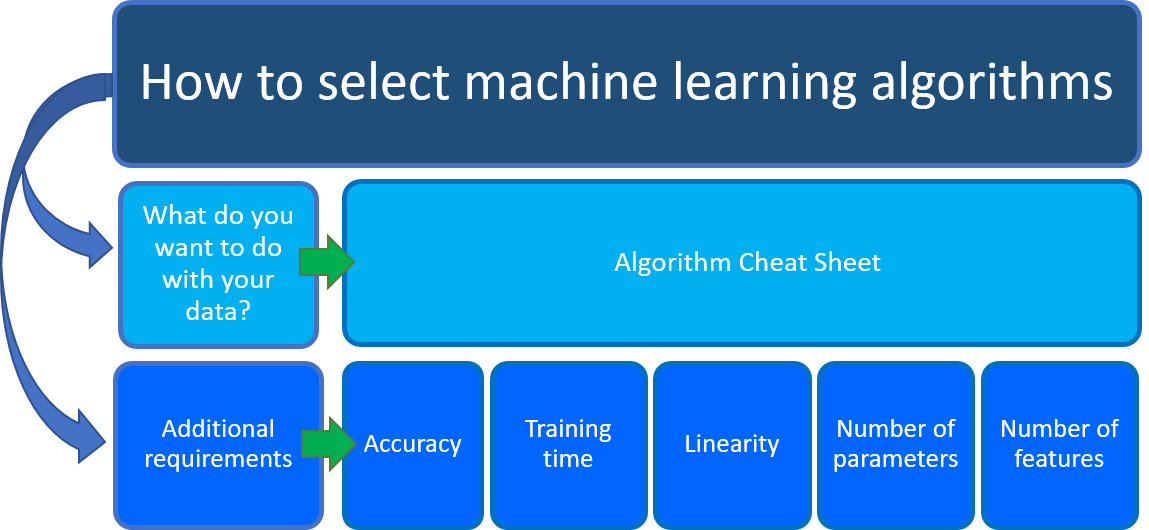
What do you want to do with your data? Specifically, what's the business question you want to answer by learning from your past data?
What are the requirements of your data science scenario? What are the features, accuracy, training time, linearity, and parameters that your solution supports?
Note
The Azure Machine Learning designer supports two types of components: classic prebuilt components (v1) and custom components (v2). These two types of components are NOT compatible.
Classic prebuilt components are primarily for data processing and traditional machine learning tasks like regression and classification. This type of component continues to be supported but will not have any new components added.
Custom components allow you to wrap your own code as a component. They support sharing components across workspaces and seamless authoring across Studio, CLI v2, and SDK v2 interfaces.
For new projects, we strongly advise that you use custom components, which are compatible with AzureML V2 and will keep receiving new updates.
This article applies to classic prebuilt components and isn't compatible with CLI v2 and SDK v2.
Azure Machine Learning Algorithm Cheat Sheet
The Azure Machine Learning Algorithm Cheat Sheet helps you with the first consideration: What you want to do with your data? On the cheat sheet, look for the task you want to do and then find an Azure Machine Learning designer algorithm for the predictive analytics solution.
Note
You can download the Machine Learning Algorithm Cheat Sheet.
The designer provides a comprehensive portfolio of algorithms, such as Multiclass Decision Forest, Recommendation systems, Neural Network Regression, Multiclass Neural Network, and K-Means Clustering. Each algorithm is designed to address a different type of machine learning problem. See the algorithm and component reference for a complete list along with documentation about how each algorithm works and how to tune parameters to optimize the algorithm.
Along with this guidance, keep other requirements in mind when choosing a machine learning algorithm. Following are additional factors to consider, such as the accuracy, training time, linearity, number of parameters and number of features.
Comparison of machine learning algorithms
Some algorithms make particular assumptions about the structure of the data or the desired results. If you can find one that fits your needs, it can give you more useful results, more accurate predictions, or faster training times.
The following table summarizes some of the most important characteristics of algorithms from the classification, regression, and clustering families:
| Algorithm | Accuracy | Training time | Linearity | Parameters | Notes |
|---|---|---|---|---|---|
| Classification family | |||||
| Two-class logistic regression | Good | Fast | Yes | 4 | |
| Two-class decision forest | Excellent | Moderate | No | 5 | Shows slower scoring times. We suggest not working with One-vs-All Multiclass, because of slower scoring times caused by tread locking in accumulating tree predictions |
| Two-class boosted decision tree | Excellent | Moderate | No | 6 | Large memory footprint |
| Two-class neural network | Good | Moderate | No | 8 | |
| Two-class averaged perceptron | Good | Moderate | Yes | 4 | |
| Two-class support vector machine | Good | Fast | Yes | 5 | Good for large feature sets |
| Multiclass logistic regression | Good | Fast | Yes | 4 | |
| Multiclass decision forest | Excellent | Moderate | No | 5 | Shows slower scoring times |
| Multiclass boosted decision tree | Excellent | Moderate | No | 6 | Tends to improve accuracy with some small risk of less coverage |
| Multiclass neural network | Good | Moderate | No | 8 | |
| One-vs-all multiclass | - | - | - | - | See properties of the two-class method selected |
| Regression family | |||||
| Linear regression | Good | Fast | Yes | 4 | |
| Decision forest regression | Excellent | Moderate | No | 5 | |
| Boosted decision tree regression | Excellent | Moderate | No | 6 | Large memory footprint |
| Neural network regression | Good | Moderate | No | 8 | |
| Clustering family | |||||
| K-means clustering | Excellent | Moderate | Yes | 8 | A clustering algorithm |
Data science scenario requirements
Once you know what you want to do with your data, you need to determine other requirements for your data science scenario.
Make choices and possibly trade-offs for the following requirements:
- Accuracy
- Training time
- Linearity
- Number of parameters
- Number of features
Accuracy
Accuracy in machine learning measures the effectiveness of a model as the proportion of true results to total cases. In the designer, the Evaluate Model component computes a set of industry-standard evaluation metrics. You can use this component to measure the accuracy of a trained model.
Getting the most accurate answer possible isn’t always necessary. Sometimes an approximation is adequate, depending on what you want to use it for. If that's the case, you might be able to cut your processing time dramatically by sticking with more approximate methods. Approximate methods also naturally tend to avoid overfitting.
There are three ways to use the Evaluate Model component:
- Generate scores over your training data in order to evaluate the model.
- Generate scores on the model, but compare those scores to scores on a reserved testing set.
- Compare scores for two different but related models, using the same set of data.
For a complete list of metrics and approaches you can use to evaluate the accuracy of machine learning models, see Evaluate Model component.
Training time
In supervised learning, training means using historical data to build a machine learning model that minimizes errors. The number of minutes or hours necessary to train a model varies a great deal between algorithms. Training time is often closely tied to accuracy; one typically accompanies the other.
In addition, some algorithms are more sensitive to the number of data points than others. You might choose a specific algorithm because you have a time limitation, especially when the data set is large.
In the designer, creating and using a machine learning model is typically a three-step process:
Configure a model, by choosing a particular type of algorithm, and then defining its parameters or hyperparameters.
Provide a dataset that's labeled and has data compatible with the algorithm. Connect both the data and the model to the Train Model component.
After training is completed, use the trained model with one of the scoring components to make predictions on new data.
Linearity
Linearity in statistics and machine learning means that there's a linear relationship between a variable and a constant in your dataset. For example, linear classification algorithms assume that classes can be separated by a straight line (or its higher-dimensional analog).
Lots of machine learning algorithms make use of linearity. In Azure Machine Learning designer, they include:
Linear regression algorithms assume that data trends follow a straight line. This assumption isn't bad for some problems, but for others it reduces accuracy. Despite their drawbacks, linear algorithms are popular as a first strategy. They tend to be algorithmically simple and fast to train.
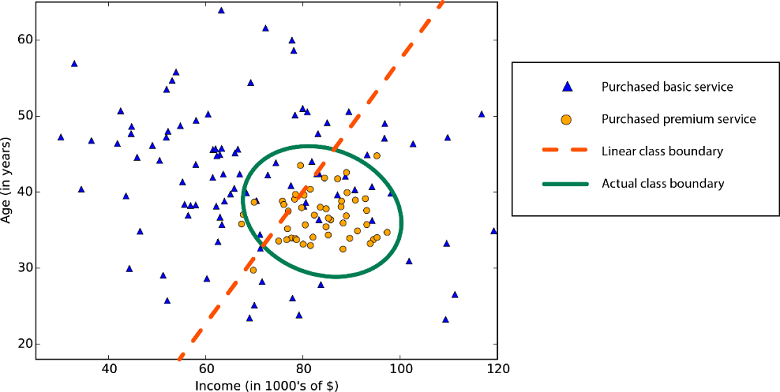
Nonlinear class boundary: Relying on a linear classification algorithm would result in low accuracy.
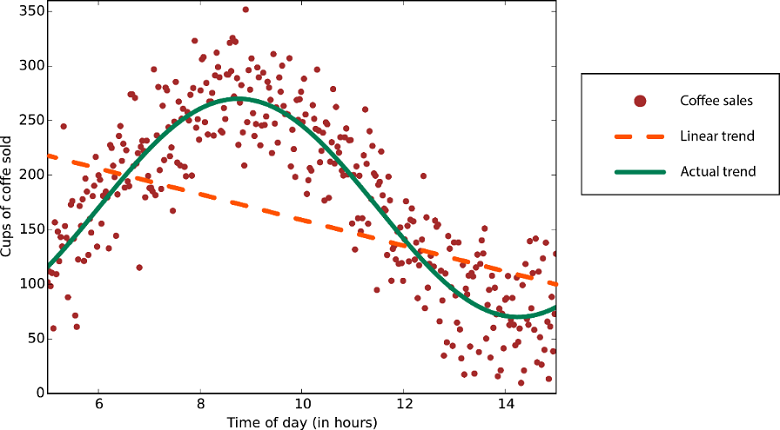
Data with a nonlinear trend: Using a linear regression method would generate much larger errors than necessary.
Number of parameters
Parameters are the knobs that a data scientist gets to turn when setting up an algorithm. They're numbers that affect the algorithm’s behavior, such as error tolerance or number of iterations, or options between variants of how the algorithm behaves. The training time and accuracy of the algorithm can sometimes be sensitive to getting just the right settings. Typically, algorithms with large numbers of parameters require the most trial and error to find a good combination.
Alternatively, there's the Tune Model Hyperparameters component in the designer. The goal of this component is to determine the optimum hyperparameters for a machine learning model. The component builds and tests multiple models by using different combinations of settings. It compares metrics over all models to get the combinations of settings.
While this is a great way to make sure you spanned the parameter space, the time required to train a model increases exponentially with the number of parameters. The upside is that having many parameters typically indicates that an algorithm has greater flexibility. It can often achieve very good accuracy, provided you can find the right combination of parameter settings.
Number of features
In machine learning, a feature is a quantifiable variable of the phenomenon you're trying to analyze. For certain types of data, the number of features can be very large compared to the number of data points. This is often the case with genetics or textual data.
A large number of features can bog down some learning algorithms, making training time unfeasibly long. Support vector machines are well suited to scenarios with a high number of features. For this reason, they have been used in many applications from information retrieval to text and image classification. Support vector machines can be used for both classification and regression tasks.
Feature selection refers to the process of applying statistical tests to inputs, given a specified output. The goal is to determine which columns are more predictive of the output. The Filter Based Feature Selection component in the designer provides multiple feature selection algorithms to choose from. The component includes correlation methods such as Pearson correlation and chi-squared values.
You can also use the Permutation Feature Importance component to compute a set of feature importance scores for your dataset. You can then use these scores to help you determine the best features to use in a model.
Related content
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for