High availability concepts in Azure Database for MySQL - Flexible Server
APPLIES TO:  Azure Database for MySQL - Flexible Server
Azure Database for MySQL - Flexible Server
Azure Database for MySQL flexible server allows configuring high availability with automatic failover. The high availability solution is designed to ensure that committed data is never lost because of failures and that the database won't be a single point of failure in your software architecture. When high availability is configured, flexible server automatically provisions and manages a standby replica. You're billed for the provisioned compute and storage for both the primary and secondary replica. There are two high availability architectural models:
Zone-redundant HA. This option is preferred for complete isolation and redundancy of infrastructure across multiple availability zones. It provides the highest level of availability, but it requires you to configure application redundancy across zones. Zone-redundant HA is preferred when you want to achieve the highest level of availability against any infrastructure failure in the availability zone and when latency across the availability zone is acceptable. It can be enabled only when the server is created. Zone-redundant HA is available in a subset of Azure regions where the region supports multiple availability zones and zone-redundant Premium file shares are available.
Same-zone HA. This option is preferred for infrastructure redundancy with lower network latency because the primary and standby servers will be in the same availability zone. It provides high availability without the need to configure application redundancy across zones. Same-zone HA is preferred when you want to achieve the highest level of availability within a single availability zone with the lowest network latency. Same-zone HA is available in all Azure regions where you can use Azure Database for MySQL flexible server.
Zone-redundant HA architecture
When you deploy a server with zone-redundant HA, two servers will be created:
- A primary server in one availability zone.
- A standby replica server that has the same configuration as the primary server (compute tier, compute size, storage size, and network configuration) in another availability zone of the same Azure region.
You can choose the availability zone for the primary and the standby replica. Placing the standby database servers and standby applications in the same zone reduces latency. It also allows you to better prepare for disaster recovery situations and "zone down" scenarios.
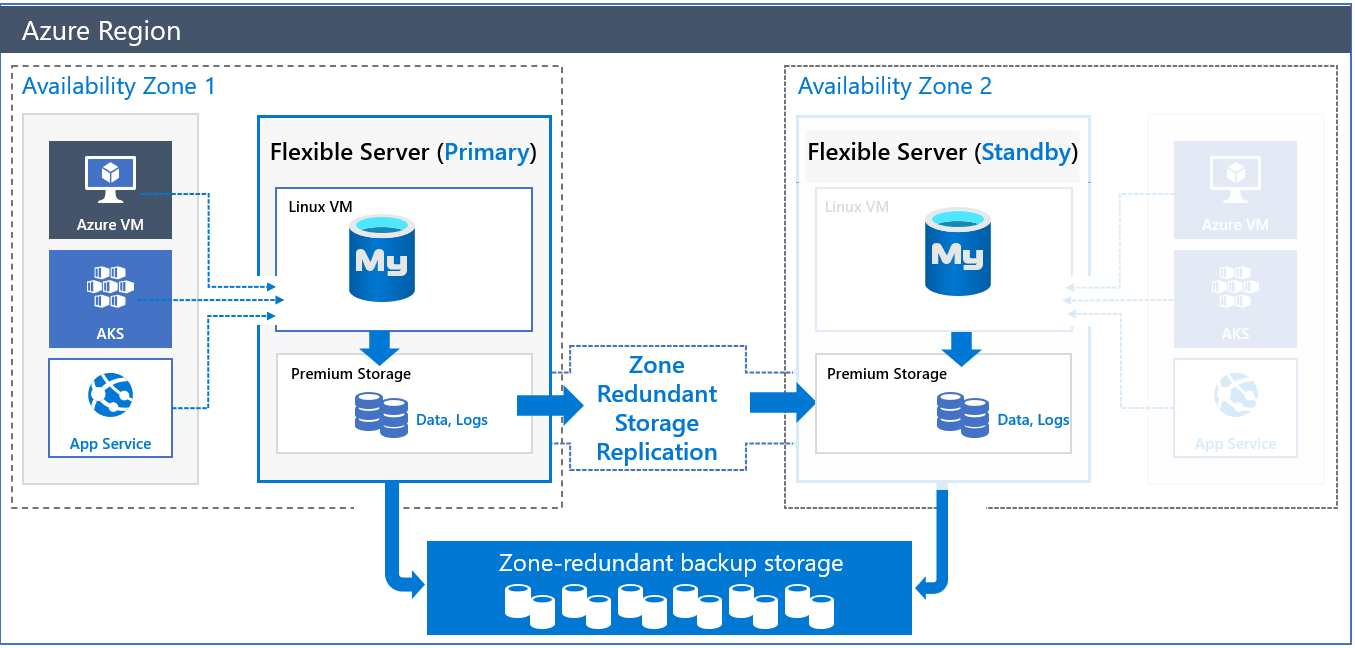
The data and log files are hosted in zone-redundant storage (ZRS). The standby server reads and replay the log files continuously from the primary server’s storage account, which is protected by storage-level replication.
If there's a failover:
- The standby replica is activated.
- The binary log files of the primary server continue to apply to the standby server to bring it online to the last committed transaction on the primary.
Logs in ZRS are accessible even when the primary server is unavailable. This availability helps to ensure there's no loss of data. After the standby replica is activated and binary logs are applied, the current standby replica server takes the role of the primary server. DNS is updated so that client connections are directed to the new primary when the client reconnects. The failover is fully transparent from the client application and doesn't require any action from you. The HA solution then brings back the old primary server when possible and places it as a standby.
The database server name is used to connect applications to the primary server. Standby replica information isn't exposed for direct access. Commits and writes are acknowledged after the log files are flushed at the primary server's ZRS. Because of the sync replication technology used in ZRS storage, you can expect 5-10 percent increased latency for application writes and commits.
Automatic backups, both snapshots and log backups, are performed on zone-redundant storage from the primary database server.
Same-zone HA architecture
When you deploy a server with same-zone HA, two servers will be created in the same zone:
- A primary server
- A standby replica server that has the same configuration as the primary server (compute tier, compute size, storage size, and network configuration)
The standby server offers infrastructure redundancy with a separate virtual machine (compute). This redundancy reduces failover time and network latency between the application and the database server because of colocation.
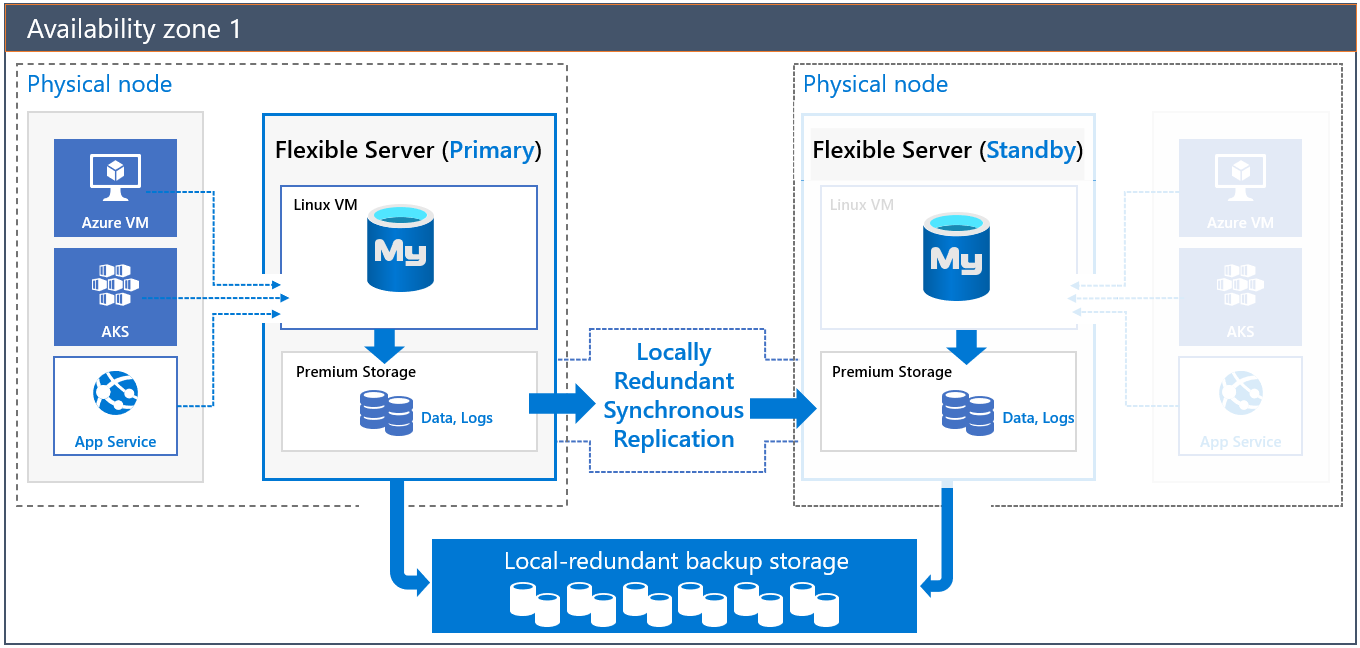
The data and log files are hosted in locally redundant storage (LRS). The standby server reads and replay the log files continuously from the primary server’s storage account, which is protected by storage-level replication.
If there's a failover:
- The standby replica is activated.
- The binary log files of the primary server continue to apply to the standby server to bring it online to the last committed transaction on the primary.
Logs in LRS are accessible even when the primary server is unavailable. This availability helps to ensure there's no loss of data. After the standby replica is activated and binary logs are applied, the current standby replica takes the role of the primary server. DNS is updated to redirect connections to the new primary when the client reconnects. The failover is fully transparent from the client application and doesn't require any action from you. The HA solution then brings back the old primary server when possible and places it as a standby.
The database server name is used to connect applications to the primary server. Standby replica information isn't exposed for direct access. Commits and writes are acknowledged after the log files are flushed at the primary server's LRS. Because the primary and the standby replica are in the same zone, there's less replication lag and lower latency between the application server and the database server. The same-zone setup doesn't provide high availability when dependent infrastructures are down for the specific availability zone. There will be downtime until all dependent services are back online for that availability zone.
Automatic backups, both snapshots and log backups, are performed on locally redundant storage from the primary database server.
Note
For both zone-redundant and same-zone HA:
- If there's a failure, the time needed for the standby replica to take over the role of primary depends on the time it takes to replay the binary log from the primary storage account to the standby. So we recommend that you use primary keys on all tables to reduce failover time. Failover times are typically between 60 and 120 seconds.
- The standby server isn't available for read or write operations. It's a passive standby to enable fast failover.
- Always use a fully qualified domain name (FQDN) to connect to your primary server. Avoid using an IP address to connect. If there's a failover, after the primary and standby server roles are switched, a DNS A record might change. That change would prevent the application from connecting to the new primary server if an IP address is used in the connection string.
Failover process
Planned: Forced failover
Azure Database for MySQL flexible server forced failover enables you to manually force a failover. This capability allows you to test the functionality with your application scenarios and helps make you ready for outages.
Forced failover triggers a failover that activates the standby replica to become the primary server with the same database server name by updating the DNS record. The original primary server is restarted and switched to the standby replica. Client connections are disconnected and need to be reconnected to resume their operations.
The overall failover time depends on the current workload and the last checkpoint. In general, it's expected to take between 60 and 120 seconds.
Note
Azure Resource Health event is generated in the event of planned failover, representing the failover time during which server was unavailable. The triggered events can be seen when clicked on "Resource Health" in the left pane. User initiated/ Manual failover is represented by status as "Unavailable" and tagged as "Planned". Example - "A failover operation was triggered by an authorized user (Planned)". If your resource remains in this state for an extended period of time, please open a support ticket and we will assist you.
Unplanned: Automatic failover
Unplanned service downtime can be caused by software bugs or infrastructure faults like compute, network, or storage failures, or power outages that affect the availability of the database. If the database becomes unavailable, replication to the standby replica is severed and the standby replica is activated as the primary database. DNS is updated, and clients reconnect to the database server and resume their operations.
The overall failover time is expected to be between 60 and 120 seconds. But, depending on the activity in the primary database server at the time of the failover (like large transactions and recovery time), the failover might take longer.
Note
Azure Resource Health event is generated in the event of unplanned failover, representing the failover time during which server was unavailable. The triggered events can be seen when clicked on "Resource Health" in the left pane. Automatic failover is represented by status as "Unavailable" and tagged as "Unplanned". Example - "Unavailable : A failover operation was triggered automatically (Unplanned)". If your resource remains in this state for an extended period of time, please open a support ticket and we will assist you.
How automatic failover detection works in HA enabled servers
The primary server and the secondary server has two network endpoints,
- Customer Endpoint: Customer connects and runs query on the instance using this endpoint.
- Management Endpoint: Used internally for service communications to management components and to connect to backend storage.
The health monitor component continuously does the following checks
- The monitor pings to the nodes Management network Endpoint. If this check fails two times continuously, it triggers automatic failover operation. The scenario like node is unavailable/not responding because of OS issue, networking issue between management components and nodes etc. will be addressed by this health check.
- The monitor also runs a simple query on the Instance. If the queries fail to run, automatic failover will be triggered. The scenarios like MySQL demon crashed/ stopped/hung, Backend storage issue etc., will be addressed by this health check.
Note
If there are any networking issue between the application and the customer networking endpoint (Private/Public access), either in networking path , on the endpoint or DNS issues in client side, the health check does not monitor this scenario. If you are using private access, make sure that the NSG rules for the VNet does not block the communication to the instance customer networking endpoint on port 3306. For public access make sure that the firewall rules are set and network traffic is allowed on port 3306 (if network path has any other firewalls). The DNS resolution from the client application side also needs to be taken care of.
Monitoring for high availability
The High Availability Status located in the server’s High Availability pane in portal can be used to determine the server’s HA configuration status.
| Status | Description |
|---|---|
| NotEnabled | HA isn't enabled. |
| ReplicatingData | Standby server is in the process of synchronizing with the primary server at the time of HA server provisioning or when HA option is enabled. |
| FailingOver | The database server is in the process of failing over from the primary to the standby. |
| Healthy | HA option is enabled. |
| RemovingStandby | When the HA option is disabled, and the deletion process is underway. |
You can also use the below metrics to monitor the health of the HA server.
| Metric display name | Metric | Unit | Description |
|---|---|---|---|
| HA IO Status | ha_io_running | State | HA IO Status indicates the state of HA replication. Metric value is 1 if the I/O thread is running and 0 if not. |
| HA SQL Status | ha_sql_running | State | HA SQL Status indicates the state of HA replication. Metric value is 1 if the SQL thread is running and 0 if not. |
| HA Replication Lag | replication_lag | Seconds | Replication lag is the number of seconds the standby is behind in replaying the transactions received at the primary server. |
Limitations
Here are some considerations to keep in mind when you use high availability:
- Zone-redundant high availability can be set only when the flexible server is created.
- High availability isn't supported in the burstable compute tier.
- Restarting the primary database server to pick up static parameter changes also restarts the standby replica.
- GTID mode will be turned on as the HA solution uses GTID. Check whether your workload has restrictions or limitations on replication with GTIDs.
Note
If you are enabling same-zone HA post the server create, you need to make sure the server parameters enforce_gtid_consistency” and “gtid_mode” is set to ON before enabling HA.
Note
Storage autogrow is default enabled for a High-Availability configured server and can not to be disabled.
Frequently asked questions (FAQ)
What are the SLAs for same-zone vs zone-redundant HA enabled Flexible server?
SLA information for Azure Database for MySQL flexible server can be found at SLA for Azure Database for MySQL.
How am I billed for high available (HA) servers? Servers enabled with HA have a primary and secondary replica. Secondary replica can be in same zone or zone redundant. You're billed for the provisioned compute and storage for both the primary and secondary replica. For example, if you have a primary with 4 vCores of compute and 512 GB of provisioned storage, your secondary replica will also have 4 vCores and 512 GB of provisioned storage. Your zone redundant HA server will be billed for 8 vCores and 1,024 GB of storage. Depending on your backup storage volume, you may also be billed for backup storage.
Can I use the standby replica for read or write operations? The standby server isn't available for read or write operations. It's a passive standby to enable fast failover.
Will I have data loss when failover happens? Logs in ZRS are accessible even when the primary server is unavailable. This availability helps to ensure there's no loss of data. After the standby replica is activated and binary logs are applied, it takes the role of the primary server.
Do I need to take any action after a failover? Failovers are fully transparent from the client application. You don't need to take any action. Applications should just use the retry logic for their connections.
What happens when I don't choose a specific zone for my standby replica? Can I change the zone later? If you don't choose a zone, one will be randomly selected. It will be the one used for the primary server. To change the zone later, you can set High Availability to Disabled on the High Availability pane, and then set it back to Zone Redundant and choose a zone.
Is replication between the primary and standby replicas synchronous? The replication between the primary and the standby is similar to semisynchronous mode in MySQL. When a transaction is committed, it doesn't necessarily commit to the standby. But when the primary is unavailable, the standby does replicate all data changes from the primary to make sure there's no data loss.
Is there a failover to the standby replica for all unplanned failures? If there's a database crash or node failure, the Flexible Server VM is restarted on the same node. At the same time, an automatic failover is triggered. If the Flexible Server VM restart is successful before the failover finishes, the failover operation will be canceled. The determination of which server to use as the primary replica depends on the process that finishes first.
Is there a performance impact when I use HA? For zone-redundant HA, while there is no major performance impact for read workloads across availability zones, there might be up to 40 percent drop in write-query latency. The increase in write-latency is due to synchronous replication across Availability zone. The write latency impact is generally twice in zone redundant HA compared to the same zone HA. For same-zone HA, because the primary and the standby replica is in the same zone, the replication latency and consequently the synchronous write latency is lower. In summary, if write-latency is more critical for you compared to availability, you may want to choose same-zone HA but if availability and resiliency of your data is more critical for you at the expense of write-latency drop, you must choose zone-redundant HA. To measure the accurate impact of the latency drop in HA setup, we recommend you to perform performance testing for your workload to take an informed decision.
How does maintenance of my HA server happen? Planned events like scaling of compute and minor version upgrades happen on the original standby instance first, and followed by triggering a planned failover operation, and then operate on the original primary instance. You can set the scheduled maintenance window for HA servers as you do for flexible servers. The amount of downtime will be the same as the downtime for the Azure Database for MySQL flexible server instance when HA is disabled.
Can I do a point-in-time restore (PITR) of my HA server? You can do a PITR for an HA-enabled Azure Database for MySQL flexible server instance to a new Azure Database for MySQL flexible server instance that has HA disabled. If the source server was created with zone-redundant HA, you can enable zone-redundant HA or same-zone HA on the restored server later. If the source server was created with same-zone HA, you can enable only same-zone HA on the restored server.
Can I enable HA on a server after I create the server? Zone-redundant HA needs to be enabled when the server is created. You can enable same-zone HA after you create the server. Before enabling same zone HA make sure you that the server parameters enforce_gtid_consistency” and “gtid_mode” is set to ON
Can I disable HA for a server after I create it? You can disable HA on a server after you create it. Billing stops immediately.
How can I mitigate downtime? You need to be able to mitigate downtime for your application even when you're not using HA. Service downtime, like scheduled patches, minor version upgrades, or customer-initiated operations like scaling of compute can be performed during scheduled maintenance windows. To mitigate application impact for Azure-initiated maintenance tasks, you can schedule them on a day of the week and time that minimizes the impact on the application.
Can I use a read replica for an HA-enabled server? Yes, read replicas are supported for HA servers.
Can I use Data-in Replication for HA servers? Support for data-in replication for high availability (HA) enabled server is available only through GTID-based replication. The stored procedure for replication using GTID is available on all HA-enabled servers by the name
mysql.az_replication_with_gtid.To reduce downtime, can I fail over to the standby server during server restarts or while scaling up or down? Currently, Azure Database for MySQL flexible server has utlized Planned Failover to optmize the HA operations including scaling up/down, and planned maintenance to help reduce the downtime. When such operations started, it would operate on the original standby instance first, followed by triggering a planned failover operation, and then operate on the original primary instance.
Can we change the availability mode (Zone-redundant HA/same-zone) of server If you create the server with Zone-redundant HA mode enabled then you can change from Zone-redundant HA to same-zone and vice versa. To change the availability mode, you can set High Availability to Disabled on the High Availability pane, and then set it back to Zone Redundant or same-zone and choose High Availability Mode.
Next steps
- Learn about business continuity.
- Learn about zone-redundant high availability.
- Learn about backup and recovery.
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for