Choose a service tier for Azure AI Search
Part of creating a search service is choosing a pricing tier (or SKU) that's fixed for the lifetime of the service. In the portal, tier is specified in the Select Pricing Tier page when you create the service. If you're provisioning through PowerShell or Azure CLI instead, the tier is specified through the -Sku parameter
The tier you select determines:
- Maximum number of indexes and other objects allowed on the service
- Size and speed of partitions (physical storage)
- Billable rate as a fixed monthly cost, but also an incremental cost if you add capacity
In a few instances, the tier you choose determines the availability of premium features.
Pricing - or the estimated monthly cost of running the service - are shown in the portal's Select Pricing Tier page. You should check service pricing to learn about estimated costs.
Note
Search services created after April 3, 2024 have larger partitions and higher vector quotas at almost every tier. For more information, see service limits.
Tier descriptions
Tiers include Free, Basic, Standard, and Storage Optimized. Standard and Storage Optimized are available with several configurations and capacities. The following screenshot from Azure portal shows the available tiers, minus pricing (which you can find in the portal and on the pricing page).
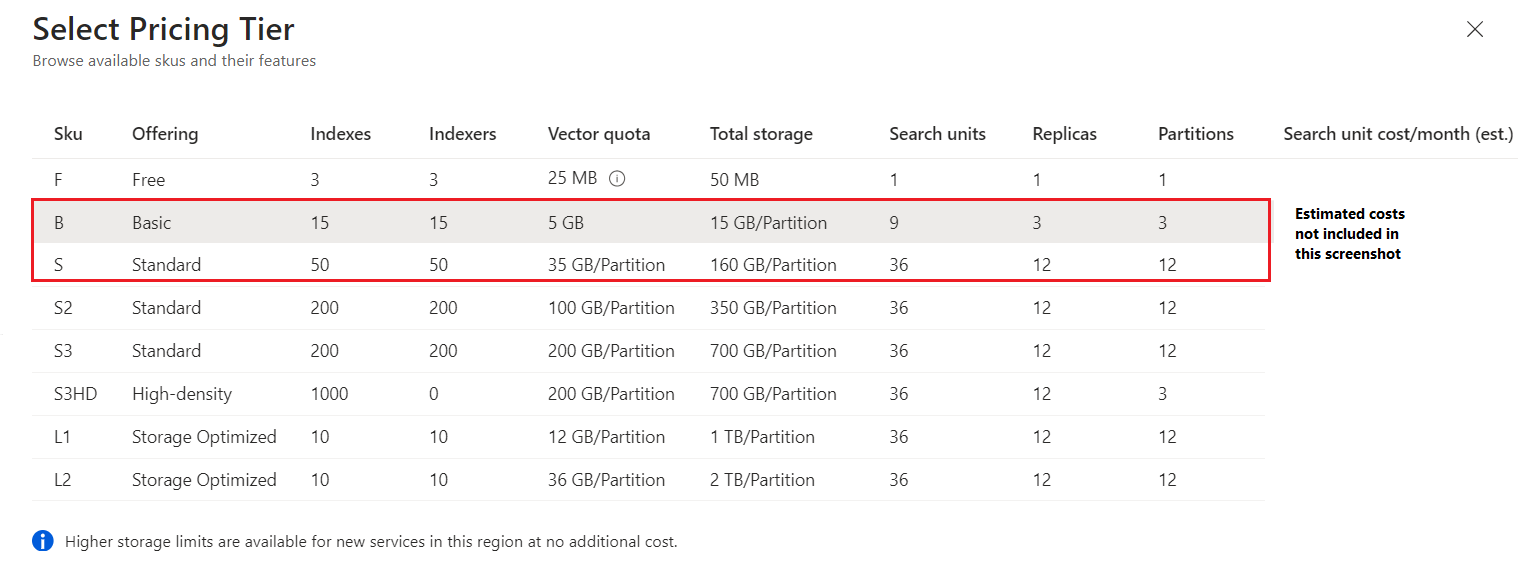
Free creates a limited search service for smaller projects, like running tutorials and code samples. Internally, system resources are shared among multiple subscribers. You can't scale a free service or run significant workloads. You can only have one free search service per Azure subscription.
The most commonly used billable tiers include the following:
Basic has the ability to meet SLA with its support for three replicas.
Standard (S1, S2, S3) is the default. It gives you more flexibility in scaling for workloads. You can scale both partitions and replicas. With dedicated resources under your control, you can deploy larger projects, optimize performance, and increase capacity.
Some tiers are designed for certain types of work:
Standard 3 High Density (S3 HD) is a hosting mode for S3, where the underlying hardware is optimized for a large number of smaller indexes and is intended for multitenancy scenarios. S3 HD has the same per-unit charge as S3, but the hardware is optimized for fast file reads on a large number of smaller indexes.
Storage Optimized (L1, L2) tiers offer larger storage capacity at a lower price per TB than the Standard tiers. These tiers are designed for large indexes that don't change very often. The primary tradeoff is higher query latency, which you should validate for your specific application requirements.
You can find out more about the various tiers on the pricing page, in the Service limits in Azure AI Search article, and on the portal page when you're provisioning a service.
Feature availability by tier
Most features are available on all tiers, including the free tier. In a few cases, the tier determines the availability of a feature. The following table describes the constraints.
| Feature | Limitations |
|---|---|
| indexers | Indexers aren't available on S3 HD. Indexers have more limitations on the free tier. |
| AI enrichment | Runs on the Free tier but not recommended. |
| Managed or trusted identities for outbound (indexer) access | Not available on the Free tier. |
| Customer-managed encryption keys | Not available on the Free tier. |
| IP firewall access | Not available on the Free tier. |
| Private endpoint (integration with Azure Private Link) | For inbound connections to a search service, not available on the Free tier. For outbound connections by indexers to other Azure resources, not available on Free or S3 HD. For indexers that use skillsets, not available on Free, Basic, S1, or S3 HD. |
| Availability Zones | Not available on the Free or Basic tier. |
| Semantic ranker | Not available on the Free tier. |
Resource-intensive features might not work well unless you give it sufficient capacity. For example, AI enrichment has long-running skills that time out on a Free service unless the dataset is small.
Upper limits
Tiers determine the maximum storage of the service itself, as well as the maximum number of indexes, indexers, data sources, skillsets, and synonym maps that you can create. For a full break out of all limits, see Service limits in Azure AI Search.
Partition size and speed
Tier pricing includes details about per-partition storage that ranges from 15 GB for Basic, up to 2 TB for Storage Optimized (L2) tiers. Other hardware characteristics, such as speed of operations, latency, and transfer rates, aren't published, but tiers that are designed for specific solution architectures are built on hardware that has the features to support those scenarios. For more information about partitions, see Estimate and manage capacity and Reliability in Azure AI Search.
Billing rates
Tiers have different billing rates, with higher rates for tiers that run on more expensive hardware or provide more expensive features. The tier billing rate can be found in the Azure pricing pages for Azure AI Search.
Once you create a service, the billing rate becomes both a fixed cost of running the service around the clock, and an incremental cost if you choose to add more capacity.
Search services are allocated computing resources in the form of partitions (for storage), and replicas (instances of the query engine). Initially, a service is created with one of each, and the billing rate is inclusive of both resources. However, if you scale capacity, the costs go up or down in increments of the billable rate.
The following example provides an illustration. Assume a hypothetical billing rate of $100 per month. If you keep the search service at its initial capacity of one partition and one replica, then $100 is what you can expect to pay at the end of the month. However, if you add two more replicas to achieve high availability, the monthly bill increases to $300 ($100 for the first replica-partition pair, followed by $200 for the two replicas).
This billing model is based on the concept of applying the billing rate to the number search units (SU) used by a search service. All services are initially provisioned at one SU, but you can increase the SUs by adding either partitions or replicas to handle larger workloads. For more information, see How to estimate costs of a search service.
Tier upgrade or downgrade
There is no built-in support to upgrade or downgrade tiers. If you want to switch to a different tier, the approach is:
Create a new search service at the new tier.
Deploy your search content onto the new service. Follow this checklist to make sure you have all of the content.
Delete the old search service once you're sure it's no longer needed.
For large indexes that you don't want to rebuild from scratch, consider using the backup and restore sample to move them.
Next steps
The best way to choose a pricing tier is to start with a least-cost tier, and then allow experience and testing inform your decision to keep the service or create a new one at a higher tier. For next steps, we recommend that you create a search service at a tier that can accommodate the level of testing you propose to do, and then review the following guidance for recommendations on estimating cost and capacity.
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for