Changes to high availability and site resilience over previous versions of Exchange Server
Exchange Server 2013 and later uses DAGs and mailbox database copies (along with other features such as single item recovery, retention policies, and lagged database copies) to provide high availability, site resilience, and Exchange native data protection. The high availability platform, Exchange Information Store, and Extensible Storage Engine (ESE) have all been enhanced since Exchange 2010 to provide availability and less complex management, and to reduce costs. These enhancements include:
Reduction in IOPS: This enables you to use larger disks in terms of capacity and IOPS as efficiently as possible.
Managed availability: With managed availability, internal monitoring and recovery-oriented features are tightly integrated to help prevent failures, proactively restore services, and start server failovers automatically or alert administrators to take action. The focus is on monitoring and managing the end-user experience rather than just server and component uptime to help keep the service continuously available.
Managed Store: The Managed Store is the name of the rewritten Information Store processes in Exchange 2013 or later. The Managed Store is written in C# and tightly integrated with the Microsoft Exchange Replication service (MSExchangeRepl.exe) to provide higher availability through improved resiliency.
Support for multiple databases per disk: Enhancements enable you to support multiple databases (mixtures of active and passive copies) on the same disk, thereby using larger disks in terms of capacity and IOPS as efficiently as possible.
AutoReseed: Automatic reseeding capability enables you to quickly restore database redundancy after disk failure. If a disk fails, the database copy stored on that disk is copied from the active database copy to a spare disk on the same server. If multiple database copies were stored on the failed disk, they can all be automatically reseeded on a spare disk. This enables faster reseeds, as the active databases are likely to be on multiple servers and the data is copied in parallel.
Automatic recovery from storage failures: This feature continues the innovation that was introduced in Exchange 2010 to allow the system to recover from failures that affect resiliency or redundancy. Exchange now includes more recovery behaviors for long I/O times, excessive memory consumption by MSExchangeRepl.exe, and severe cases where the system is in such a bad state that threads can't be scheduled.
Lagged copy enhancements: Lagged copies can now care for themselves to a certain extent using automatic log play down. Lagged copies will automatically play down log files in various situations, such as page patching and low disk space scenarios. If the system detects that page patching is required for a lagged copy, the logs will be automatically replayed into the lagged copy to do page patching. Lagged copies will also invoke this auto replay feature when a low disk space threshold has been reached, and when the lagged copy has been detected as the only available copy for a specific period of time. In addition, lagged copies can use Safety Net, making recovery or activation much easier.
Single copy alert enhancements: The single copy alert introduced in Exchange 2010 is no longer a separate scheduled script. It's now integrated into the managed availability components within the system and is a native function within Exchange.
DAG network auto-configuration: DAG networks can be automatically configured by the system based on configuration settings. In addition to manual configuration options, DAGs can also distinguish between MAPI and replication networks and configure DAG networks automatically.
Reduction in IOPS
In Exchange 2010, passive database copies have a low checkpoint depth, that is required for fast failover. In addition, the passive copy does aggressive pre-reading of data to keep up with a 5 megabyte (MB) checkpoint depth. As a result of using a low checkpoint depth and doing these aggressive pre-read operations, IOPS for a passive database copy is equal to IOPS for an active copy in Exchange 2010.
In Exchange 2013 or later, the system can provide fast failover while using a high checkpoint depth on the passive copy (100 MB). Because passive copies have 100-MB checkpoint depth, they've been de-tuned to no longer be so aggressive. As a result of increasing the checkpoint depth and de-tuning the aggressive pre-reads, IOPS for a passive copy are about 50 percent of the active copy IOPS.
Having a higher checkpoint depth on the passive copy also results in other changes. On failover in Exchange 2010, the database cache is flushed as the database is converted from a passive copy to an active copy. Starting in Exchange 2013, ESE logging was rewritten so that the cache is persisted through the transition from passive to active. Because ESE doesn't need to flush the cache, you get fast failover.
One other change was made to the background database maintenance (BDM) process. BDM now processes around 1-2 MB per second per copy.
As a result of these changes, Exchange now provides a significant reduction in IOPS over Exchange 2010.
Managed Availability
Managed Availability is the integration of built-in, active monitoring, and the Exchange high availability platform. With Managed Availability, the system can make a determination on when to fail over a database based on service health. Managed Availability is an internal infrastructure that's deployed in the Client Access (frontend) services and backend services on Mailbox servers. Managed Availability includes three main asynchronous components that are constantly doing work:
The first component is the probe engine, that is responsible for taking measurements on the server and collecting data. The results of those measurements flow into the second component, the monitor.
The monitor contains all of the business logic used by the system based on what is considered healthy on the data collected. Similar to a pattern recognition engine, the monitor looks for the various different patterns on all the collected measurements, and then it decides whether something is considered healthy.
Finally, there's the responder engine, that is responsible for recovery actions.
When something is unhealthy, the first action is to attempt to recover that component. This could include multi-stage recovery actions; for example:
Restart the application pool.
Restart the service.
Restart the server.
Take the server offline so that it no longer accepts traffic.
If the recovery actions are unsuccessful, the system escalates the issue to a human through event log notifications.
Managed availability is implemented in the form of two services:
Exchange Health Manager Service (MSExchangeHMHost.exe): This is a controller process that's used to manage worker processes. It's used to build, execute, and start and stop the worker process as needed. It's also used to recover the worker process in case that process crashes, to prevent the worker process from being a single point of failure.
Exchange Health Manager Worker process (MSExchangeHMWorker.exe): This is the worker process that's responsible for doing the runtime tasks.
Managed availability uses persistent storage to do its functions:
XML configuration files are used to initialize the work item definitions during startup of the worker process.
The registry is used to store runtime data, such as bookmarks.
The crimson channel event log infrastructure is used to store the work item results.
For more information about managed availability, see Managed availability.
Managed Store
Exchange 2010 and earlier versions support running a single instance of the Information Store process (Store.exe) on the Mailbox server role. This single Store instance hosts all databases on the server: active, passive, lagged, and recovery. In these Exchange architectures, there's little, if any, isolation between the different databases hosted on a Mailbox server. An issue with a single mailbox database has the potential to negatively affect all other databases, and crashes resulting from a mailbox corruption can affect service for all users whose databases are hosted on that server.
Another challenge with a single Store instance is the lack of processor scalability with the Extensible Storage Engine (ESE). ESE scales well to 8-12 processor cores, but beyond that, cross-processor communication and cache synchronization issues lead to negative performance. Given today's servers with 16+ core systems available, this would impose the administrative challenge of managing the affinity of 8-12 cores for ESE and using the other cores for non-Store processes (for example, Assistants, Search Foundation, Managed Availability, and so on). Moreover, the previous architecture restricted scale-up for the Store process.
The Store.exe process has evolved considerably throughout the years as Exchange Server itself evolved, but as a single process, ultimately its scalability is limited, and it represents a single point of failure. Because of these limits, Store.exe was removed in Exchange 2013 and replaced by the Managed Store.
For more information, see Managed Store.
Multiple databases per volume
Although the storage improvements in Exchange are designed primarily for just a bunch of disks (JBOD) configurations, they're available for use by all supported storage configurations. One such feature is the ability to host multiple databases on the same volume. This feature is about Exchange optimizing for large disks. These optimizations result in a much more efficient use of large disks in terms of capacity, IOPS, and reseed times, and they're meant to address the challenges associated with running in a JBOD storage configuration:
Database sizes must be manageable.
Reseed operations must be fast and reliable.
Although storage capacity is increasing, IOPS aren't.
Disks hosting passive database copies are underutilized in terms of IOPS.
Lagged copies have asymmetric storage requirements.
Limited agility exists to recover from low disk space conditions.
The trend of increasing storage capacity continues. For example, the Exchange best practice guideline for maximum database size (2 terabytes) on an 8-terabyte drive means you would waste more than 5 terabytes of disk space.
A solution would be to grow the databases larger, but that inhibits manageability because it might introduce long reseed times (including operationally unmanageable reseed times) and compromised reliability of copying that amount of data over the network.
In addition, in the Exchange 2010 model, the disk storing a passive copy is underutilized in terms of IOPS. In the case of a lagged passive copy, not only is the disk underutilized in terms of IOPS, but it's also asymmetric in terms of its size, relative to the disks used to store the active and non-lagged passive copies.
Exchange 2013 and later has been optimized to use large disks (8 terabytes) in a JBOD configuration more efficiently. With multiple databases per disk, you can now have the same size disks storing multiple database copies, including lagged copies. The goal is to drive the distribution of users across the number of volumes that exist, providing you with a symmetric design where during normal operations each DAG member hosts a combination of active, passive, and optional lagged copies on the same volumes.
An example of a configuration that uses multiple databases per volume is illustrated below.
Configuration that uses multiple databases per volume
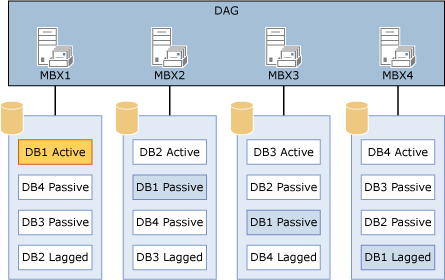
The configuration in the diagram provides a symmetrical design. All four servers have the same four databases all hosted on a single disk per server. The key is that the number of copies of each database that you have should be equal to the number of database copies per disk.
In the configuration in the diagram, there are four copies of each database: one active copy, two passive copies, and one lagged copy. Because there are four copies of each database, the proper configuration is one that has four copies per volume.
In addition, activation preference is configured so that it's balanced across the DAG and across each server. For example:
The active copy will have an activation preference value of 1.
The first passive copy will have an activation preference value of 2.
The second passive copy will have an activation preference value of 3.
The lagged copy will have an activation preference value of 4.
In addition to having a better distribution of users across the existing volumes, another benefit of using multiple databases per disk is a reduction in the amount of time to restore data protection for failures that require a reseed (for example, disk failure).
As a database gets bigger, reseeding the database takes longer. For example, a 2-terabyte database could take 23 hours to reseed, whereas an 8-terabyte database could take as long as 93 hours (almost 4 days). Both seeds would occur at about 20 MB per second. This generally means that a very large database can't be seeded within an operationally reasonable amount of time.
In the case of a single database copy per disk scenario, the seeding operation is effectively source-bound, because it's always seeding the disk from a single source.
By dividing the volume into multiple database copies, and by having the active copy of the passive databases on a specified volume stored on separate DAG members, the system is no longer source bound in the context of reseeding the disk. When a failed disk is replaced, it can be reseeded from multiple sources. This allows the system to reseed and restore data protection for these databases in a much shorter amount of time.
When you use multiple databases per volume, we recommend that you follow these best practices and requirements:
A single logical disk partition per physical disk must be used. Don't create multiple partitions on the disk. Each database copy and its companion files (such as transaction logs and content index) should be hosted in a unique directory on the single partition.
The number of database copies configured per volume should be equal to the number of copies of each database. For example, if you have four copies of your databases, you should use four database copies per volume.
Database copies should have the same neighbors. (For example, they should all share the same disk on each server.)
Activation preference across the DAG should be balanced, such that each database copy on a specified disk has a unique activation preference value.
AutoReseed
Automatic reseed (also known as AutoReseed) is the replacement for what is normally an administrator-driven action in response to a disk failure, database corruption event, or other issue that requires a reseed of a database copy. AutoReseed is designed to automatically restore database redundancy after a disk failure by using spare disks that have been provisioned on the system.
For more information, see AutoReseed. For detailed steps to configure AutoReseed, see Configure AutoReseed for a database availability group.
Automatic recovery from storage failures
Automatic recovery from storage failures allows the system to recover from failures that affect resiliency or redundancy. In addition to the bugcheck behaviors introduced in Exchange 2010, Exchange now includes additional recovery behaviors for long I/O times, excessive memory consumption by the Microsoft Exchange Replication service (MSExchangeRepl.exe), and severe cases where threads can't be scheduled.
Even in JBOD environments, storage array controllers can have issues, such as crashing or hanging. The following table lists features that provide hung I/O detection and recovery features that provide enhanced resilience.
| Name | Check | Action | Threshold |
|---|---|---|---|
| ESE Database Hung IO Detection | ESE checks for outstanding I/Os | Generates a failure item in the crimson channel to restart the server | 240 seconds |
| Failure Item Channel Heartbeat | Ensures failure items can be written to and read from crimson channel | Replication service heartbeats crimson channel and restart server on failures | 30 seconds |
| System Disk Heartbeat | Verifies server's system disk state | Periodically sends unbuffered I/O to system disk; restarts server on heartbeat time out | 120 seconds |
Exchange 2013 and later enhances server and storage resilience by including behaviors for other serious conditions. These conditions and behaviors are described in the following table.
| Name | Check | Action | Threshold |
|---|---|---|---|
| System bad state | No threads, including non-managed threads, can be scheduled | Restart the server | 302 seconds |
| Long I/O times | I/O operation latency measurements | Restart the server | 41 seconds |
| Replication service memory use | Measure the working set of MSExchangeRepl.exe | 1: Log event 4395 in the crimson channel with a service termination request 2: Initiate termination of MSExchangeRepl.exe 3: If service termination fails, restart the server |
4 gigabyte (GB) |
| System Event 129 (Bus reset) | Check for Event 129 in System event log | Restart the server | When event occurs |
| Cluster database hang | Global Update Manager updates are blocked | Restart the server | When event occurs |
Lagged copy enhancements
Lagged copy enhancements include integration with Safety Net and automatic play down of log files in certain scenarios. Safety Net was introduced in Exchange 2013 to replace the Exchange 2010 feature known as the transport dumpster. Safety Net is similar to the transport dumpster, in that it's a delivery queue that's associated with the Transport service on a Mailbox server. This queue stores copies of messages that were successfully delivered to the active mailbox database on the Mailbox server. Each active mailbox database on the Mailbox server has its own queue that stores copies of the delivered messages. You can specify how long Safety Net stores copies of the successfully delivered messages before they expire and are automatically deleted.
Safety Net takes some responsibility from shadow redundancy in DAG environments. In DAG environments, shadow redundancy doesn't need to keep another copy of the delivered message in a shadow queue while it waits for the delivered message to replicate to the passive copies of mailbox databases on the other Mailbox servers in the DAG. The copy of the delivered message is already stored in Safety Net, so shadow redundancy can redeliver the message from Safety Net if necessary.
With Safety Net, activating a lagged database copy becomes easier. For example, consider a lagged copy that has a 2-day replay lag. In that case, you would configure Safety Net for a period of 2 days. If you encounter a situation in which you need to use your lagged copy, you can:
Suspend replication to it.
Copy it twice (to preserve the lagged nature of the database and to create an extra copy in case you need it).
Take a copy and discard all the log files, except for those in the required range.
Mount the copy, which triggers an automatic request to Safety Net to redeliver the last two days of mail.
With Safety Net, you don't need to hunt for where the point of corruption was introduced. You get the last two days mail, minus the data ordinarily lost on a lossy failover.
Lagged copies can now care for themselves by invoking automatic log replay to play down the log files in certain scenarios:
When a low disk space threshold is reached
When the lagged copy has physical corruption and needs to be page patched
When there are fewer than three available healthy copies (active or passive only; lagged database copies are not counted) for more than 24 hours
In Exchange 2010, page patching wasn't available for lagged copies. In Exchange 2013 or later, page patching is available for lagged copies through this automatic play down feature. If the system detects that page patching is required for a lagged copy, the logs are automatically replayed into the lagged copy to perform page patching. Lagged copies also invoke this auto replay feature when a low disk space threshold has been reached, and when the lagged copy has been detected as the only available copy for a specific period of time.
Lagged copy play down behavior is disabled by default, and can be enabled by running the following command.
Set-DatabaseAvailabilityGroup <DAGName> -ReplayLagManagerEnabled $true
After being enabled, play down occurs when there are fewer than three copies. You can change the default value of 3, by modifying the following DWORD registry value.
HKLM\Software\Microsoft\ExchangeServer\v15\Replay\Parameters\ReplayLagManagerNumAvailableCopies
To enable play down for low disk space thresholds, you must configure the following registry entry.
HKLM\Software\Microsoft\ExchangeServer\v15\Replay\Parameters\ReplayLagLowSpacePlaydownThresholdInMB
After configuring either of these registry settings, restart the Microsoft Exchange DAG Management service for the changes to take effect.
As an example, consider an environment where a given database has four copies (three highly available copies and one lagged copy), and the default setting is used for ReplayLagManagerNumAvailableCopies. If a non-lagged copy is out-of-service for any reason (for example, it is suspended, etc.) then the lagged copy will automatically play down its log files in 24 hours.
Single copy alert enhancements
Ensuring that your servers are operating reliably and that your mailbox database copies are healthy are primary objectives of daily Exchange messaging operations. You must actively monitor the hardware, the Windows operating system, and the Exchange services.
But in an Exchange mailbox resiliency environment, it's important that you monitor the health and status of the DAG and your mailbox database copies. It's especially vital to perform data redundancy risk management and monitor for periods in which a replicated database is down to just a single copy. This is critical in environments that don't use Redundant Array of Independent Disks (RAID) and instead deploy JBOD configurations. In a RAID environment, a single disk failure doesn't affect an active mailbox database copy. However, in a JBOD environment, a single disk failure will trigger a database failover.
The CheckDatabaseRedundancy.ps1 script was introduced in Exchange 2010. As its name implies, the purpose of the script was to monitor the redundancy of replicated mailbox databases by validating that there is at least two configured, healthy, and current copies, and to alert an administrator through event log generation when only a single healthy copy of a replicated database exists. In this case, both active and passive copies are counted when determining redundancy.
Single copy conditions include, but aren't limited to:
Failure of an active copy to replicate to any passive copy.
Failure of all passive copies, which includes FailedAndSuspended and Failed states in addition to healthy states where the copy is behind in log copying or replay. Lagged copies aren't considered behind if they're within 10 minutes in replaying their logs to their lag period.
Failure of the system to accurately know the current log generation of the active copy.
Because it's a top priority for administrators to know when they're down to a single healthy copy of a database, the CheckDatabaseRedundancy.ps1 script has been replaced with integrated, native functionality that's part of managed availability's DataProtection Health Set.
The native functionality still alerts administrators through event log notifications, and to distinguish Exchange 2013 or later alerts from Exchange 2010, Exchange now uses the following Event IDs:
Event 4138 (Red Alert)
Event 4139 (Green Alert)
The native functionality has been enhanced to reduce alert noise that occurs when multiple databases on the same server enter into a single copy condition. In Exchange 2010, single copy alerts were generated on a per-database level. As a result, a server-wide issue that affected multiple databases and multiple database copies could cause alert storms. Because several failures are server-wide (for example, controller or memory problems), there was a good chance that an alert storm would occur for each server incident.
Alerts are now generated on a per-server basis. When an outage affects an entire server and data redundancy becomes at risk for multiple database copies, a single per-server alert is generated.
DAG network auto-configuration
A DAG network is a collection of one or more subnets used for either replication traffic or MAPI traffic. Each DAG contains a maximum of one MAPI network and zero or more replication networks.
In Exchange 2010, the initial DAG networks (for example, DAGNetwork01 and DAGNetwork02) were created by the system based on the subnets that were enumerated by the Cluster service. If you had multiple networks and the interfaces for a specified network (for example, the MAPI network) were on the same subnet, there was little additional configuration required. However, if the interfaces for a specified network were on multiple subnets, you needed to perform a task known as collapsing DAG networks.
In Exchange 2013 or later, collapsing DAG networks is no longer necessary. Exchange still uses the same detection mechanisms to distinguish between the MAPI and replication networks, but it now automatically collapses DAG networks as appropriate.
In addition, by default, DAG networks are now automatically managed by the system. To view DAG network properties using the Exchange admin center (EAC), you must configure the DAG for manual network control by modifying the properties of the DAG using EAC, or by using the Set-DatabaseAvailabilityGroup cmdlet to set the ManualDagNetworkConfiguration parameter to $true.
Changes to best copy selection
Best copy selection (BCS) is an internal algorithm process for finding the best copy of an individual database to activate, given a list of potential copies for activation and their health and status. Active Manager selects the best available (and unblocked) copy to become the new active database copy when the existing active database copy fails or when an administrator performs a targetless switchover. In Exchange 2010, the BCS process evaluated several aspects of each database copy to determine the best copy to activate. These included:
Copy queue length
Replay queue length
Database status
Content index status
In Exchange 2013 or later, Active Manager performs the same BCS checks and phases to determine replication health, but it now also includes the use of a constraint of the decreasing order of health states. As a result of these changes, BCS is now called best copy and server selection (BCSS).
BCSS includes several new health checks that are now part of the built-in managed availability monitoring components in Exchange. There are four additional checks performed by Active Manager (listed in the order in which they're performed):
All Healthy: Checks for a server hosting a copy of the affected database that has all monitoring components in a healthy state.
Up to Normal Healthy: Checks for a server hosting a copy of the affected database that has all monitoring components with Normal priority in a healthy state.
All Better than Source: Checks for a server hosting a copy of the affected database that has monitoring components in a state that's better than the current server hosting the affected copy.
Same as Source: Checks for a server hosting a copy of the affected database that has monitoring components in a state that's the same as the current server hosting the affected copy.
If BCSS is invoked as a result of a failover that's triggered by a managed availability monitoring component (for example, via a Failover responder), an additional mandatory constraint is enforced where the target server's component health must be better than the server on which the failover occurred. For example, if a failure of Outlook on the web (formerly known as Outlook Web App) triggers a managed availability failover via a Failover responder, BCSS must select a server hosting a copy of the affected database on which Outlook on the web is healthy.
DAG Management Service
Exchange 2013 CU2 or later includes the Microsoft Exchange DAG Management Service (MSExchangeDAGMgmt). This service contains the internal DAG monitoring functionality that was previously inside the Microsoft Exchange Replication service (MSExchangeRepl).
DAGs without a cluster administrative access point
All DAGs on Exchange servers running Windows Server 2008 R2 or Windows Server 2012 require at least one IP address on every subnet included in the MAPI network. The IP address(es) assigned to the DAG are used by the DAG's cluster with the cluster's administrative access point (also known as the cluster network name) to enable name resolution and connectivity to the cluster (or more precisely, connectivity to the cluster member that currently owns the cluster core resource group) using the cluster name.
Windows Server 2012 R2 or later enables you to create a failover cluster without an administrative access point. Windows failover clusters without administrative access points have the following characteristics:
No IP address is assigned to the cluster, so there's no IP Address Resource in the cluster core resource group.
No network name is assigned to the cluster, so there's no Network Name Resource in the cluster core resource group.
The name of the cluster isn't registered in DNS and the cluster name isn't resolvable on the network.
A cluster name object (CNO) isn't created in Active Directory.
You can't manage the Windows failover cluster using the Failover Cluster Management tool. Instead, you need to use Windows PowerShell and you need to run the PowerShell cmdlets against the individual cluster members.
Exchange 2013 SP1 or later running on Exchange on Windows Server 2012 R2 or later enables you to create a DAG without a cluster administrative access point. For more information, see Creating DAGs and Create a database availability group.